#딥러닝
17개의 포스트

AI는 입구, 구조화된 데이터가 출구 — DX를 위한 AI/ML 이해의 기술
DX 전문가 로드맵 4편 — 1959년 Arthur Samuel의 체커 프로그램부터 2026년 AI 에이전트까지. 88%의 기업이 AI를 활용하지만 실제 성과를 내는 기업은 6%에 불과한 이유. AI를 '도구'로 이해하는 DX 전문가의 시각을 총정리한다.
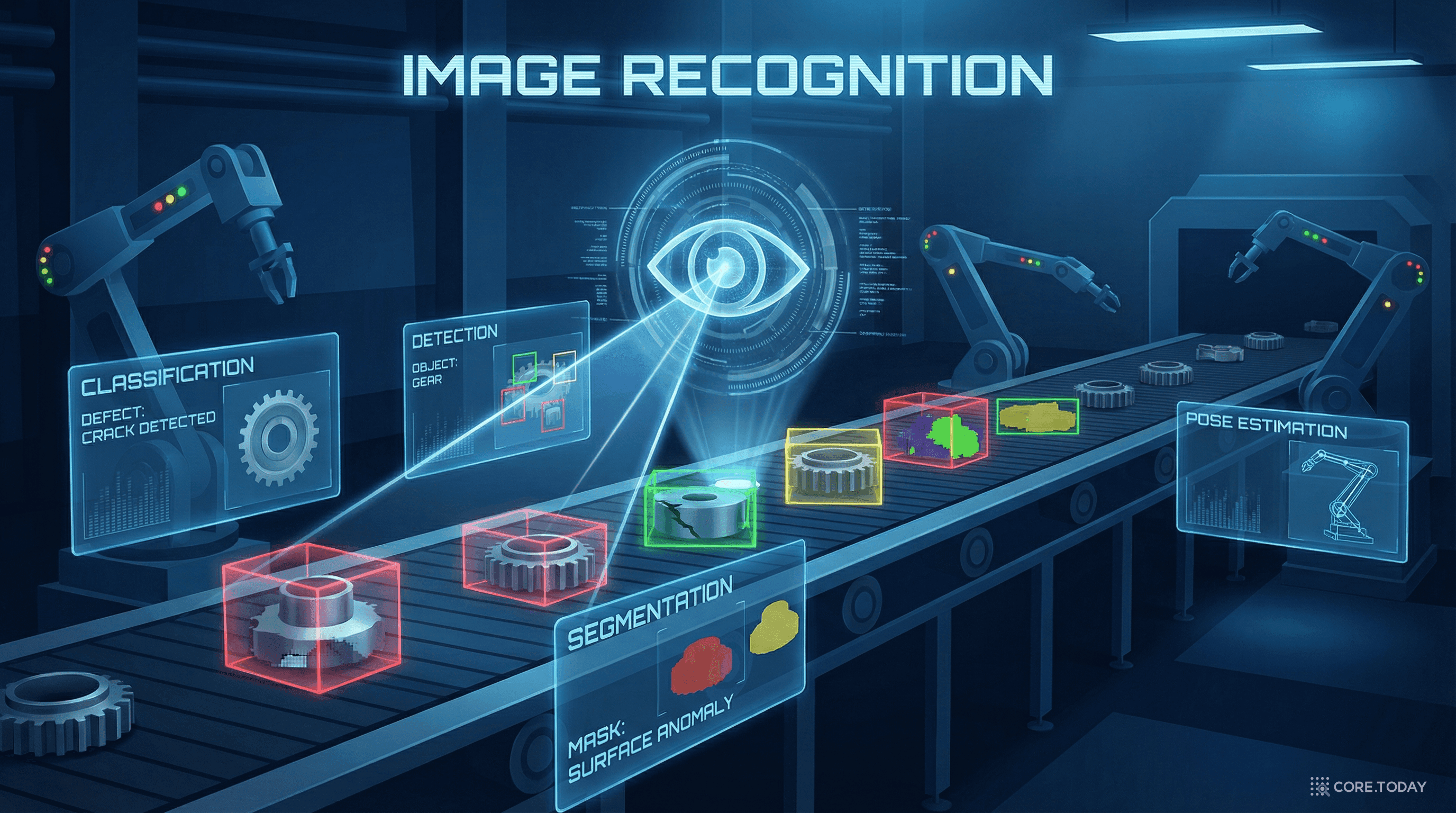
이미지 객체 인식 완전 가이드: 컴퓨터에게 '보는 법'을 가르친 25년 — 공장에서 자율주행까지
얼굴 검출에서 시작해 반도체 결함 검사까지 — 이미지 객체 인식의 역사, 네 가지 핵심 태스크, 그리고 제조·자동차·식품 산업에서의 실전 활용법을 풍부한 사례와 함께 완전 해설한다.

Depth Separation 특집: 왜 '넓고 얕은' AI보다 '좁고 깊은' AI가 압도적으로 효율적인가
종이 한 장을 42번 접으면 달에 닿는다. 신경망도 마찬가지다 — 뉴런을 '옆으로 늘리는' 대신 '위로 쌓으면' 지수적으로 효율적이다. 1989년 보편 근사 정리가 약속한 '무한한 가능성'의 이면에 숨겨진 비용, 그리고 2016년 수학자들이 증명한 '깊이의 압도적 승리'까지. ResNet에서 Transformer, LoRA까지 — 현대 AI의 모든 혁신이 깊이에 빚지고 있는 이유를 파헤친다.
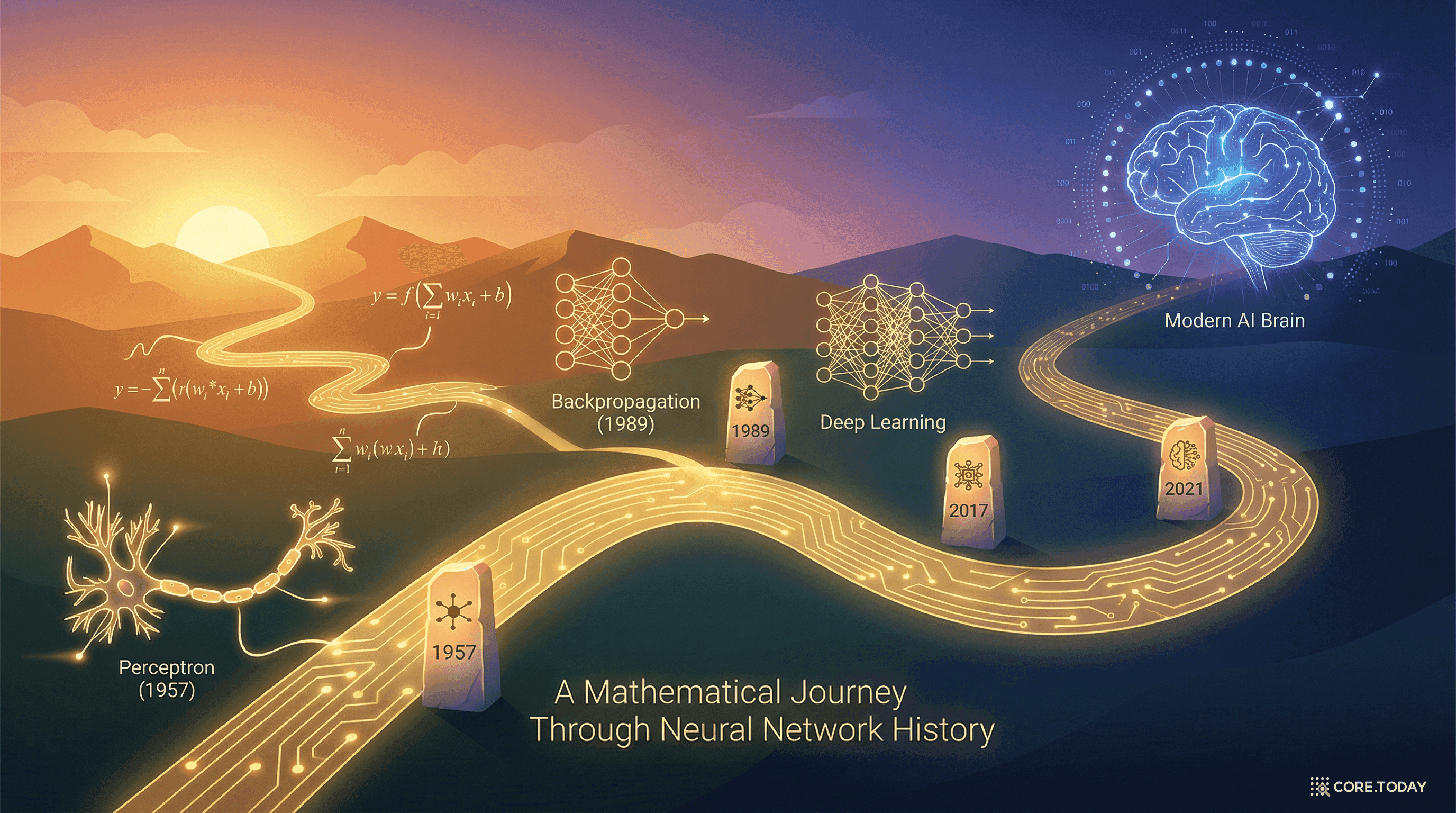
UAT에서 LoRA까지: 신경망이 세상을 배우는 수학적 여정
1989년, 한 수학 정리가 증명했다 — 뉴런이 충분하면 어떤 함수든 흉내 낼 수 있다. 이 '보편 근사 정리'에서 출발하여, 깊이의 혁명, Transformer, 스케일링 법칙을 거쳐 LoRA까지 — 신경망이 세상의 모든 것을 배우는 수학적 여정을 따라간다.
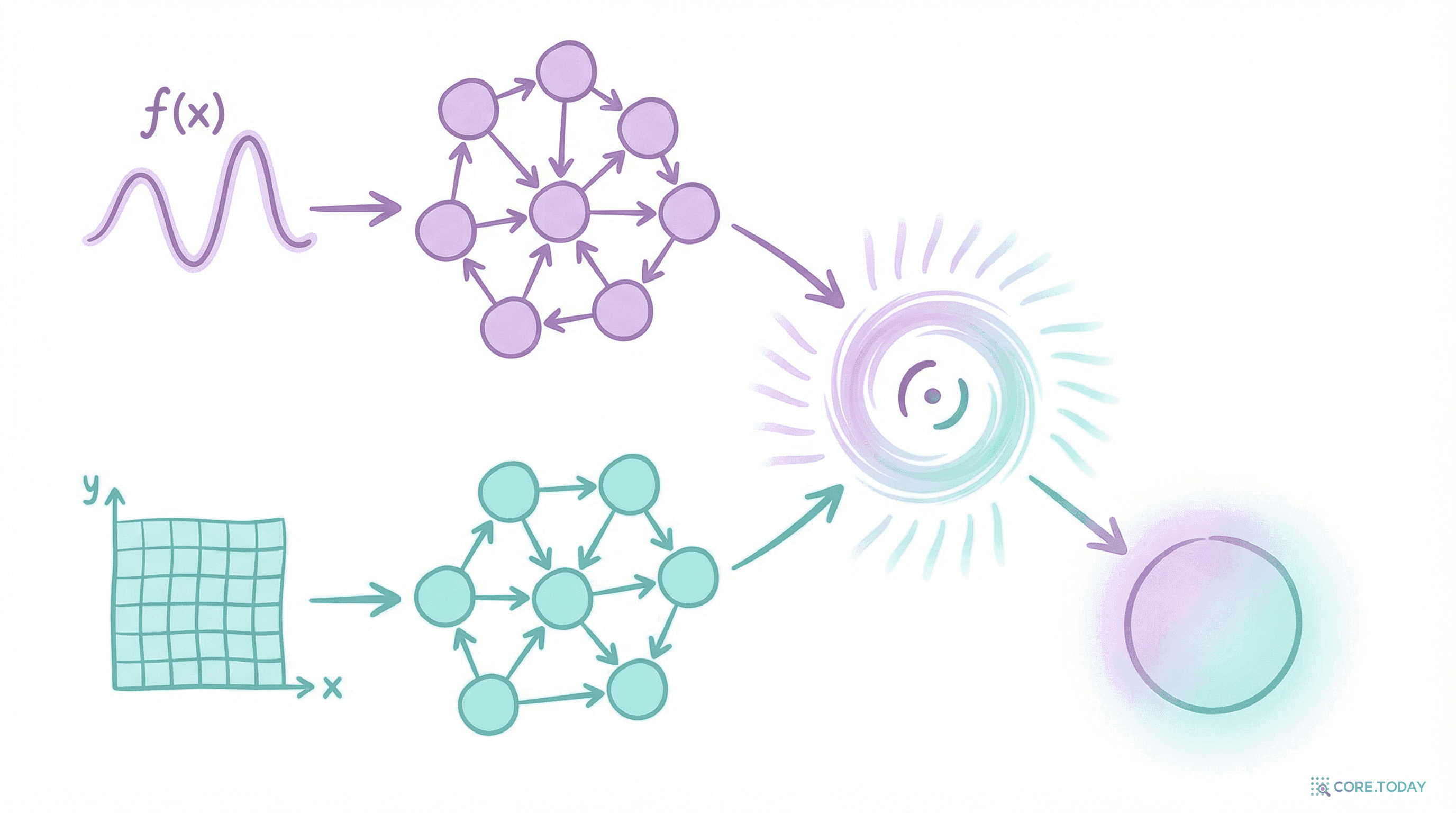
함수를 먹고 함수를 뱉는다 — DeepONet 완전 해부
1995년 증명된 '신경망으로 임의의 연산자를 근사할 수 있다'는 정리가, 25년 뒤 DeepONet으로 실현됐다. Branch Net과 Trunk Net의 우아한 이중 구조가 함수에서 함수로의 매핑을 학습하는 원리를 완전 해부한다.
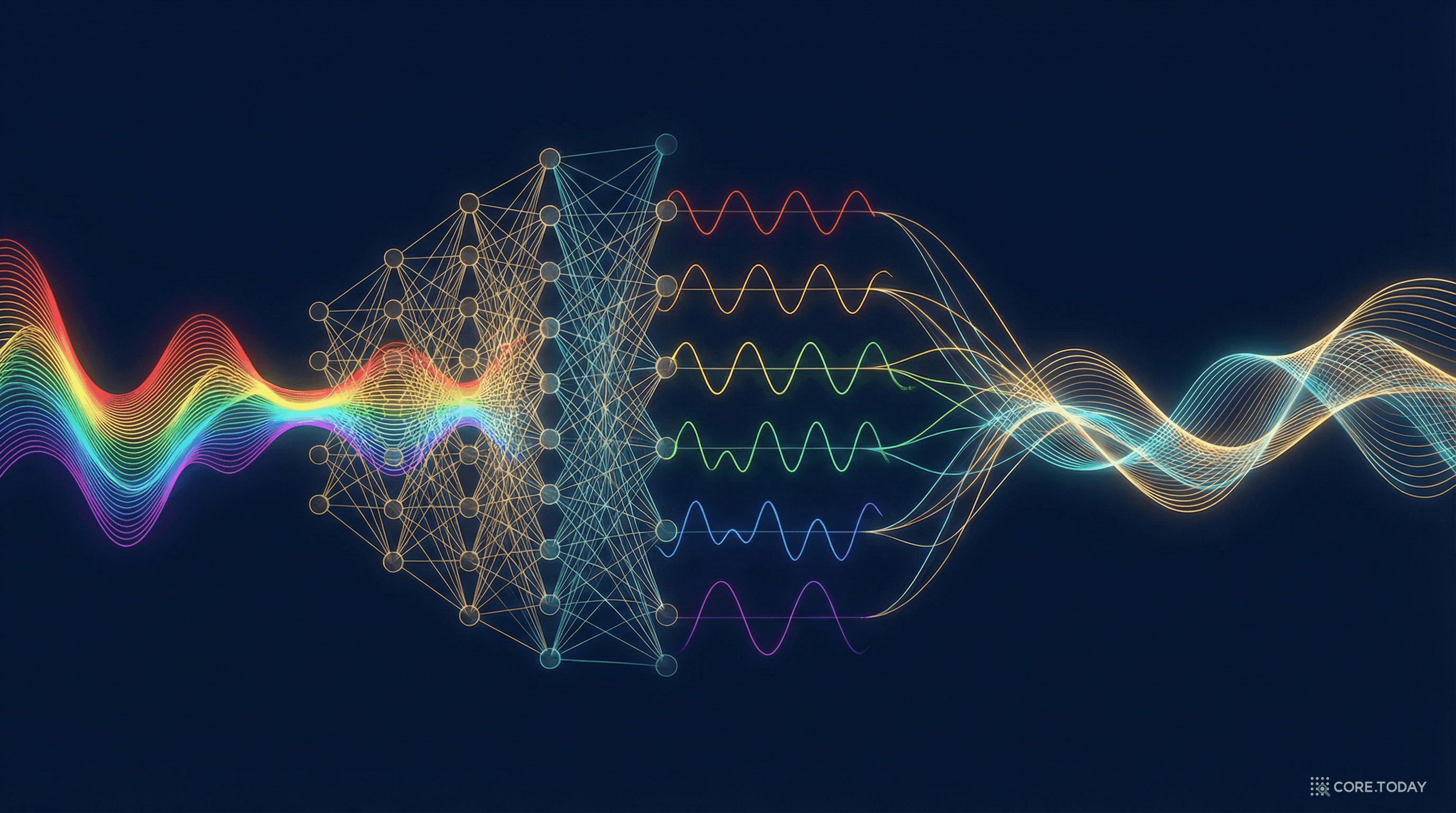
주파수의 눈으로 물리를 본다 — Fourier Neural Operator 완전 해부
하나의 PDE를 푸는 데 수 시간이 걸리던 시뮬레이션을, 학습 한 번으로 수천 가지 조건에 대해 밀리초 만에 답하게 만든 FNO. 푸리에 변환의 직관부터 아키텍처의 핵심, 실전 사례까지 빠짐없이 풀어본다.
AI에게 물리법칙을 가르치다 — Physics-Informed Neural Networks의 모든 것
데이터만으로는 부족하고, 시뮬레이션만으로는 느리다. 물리법칙을 손실함수에 녹인 PINN이 과학과 공학의 난제를 어떻게 풀어가는지, 탄생 배경부터 최신 사례까지 쉽고 깊게 살펴본다.

CNN 완전 이해: 고양이 한 마리가 바꾼 컴퓨터 비전의 역사
고양이 뉴런 실험에서 자율주행까지 — 합성곱 신경망이 어떻게 탄생했고, 왜 작동하며, 2026년에도 여전히 중요한지를 논문과 사례로 풀어본다.

Transformer 특집: 순서를 기억하는 기계에서 모든 것을 한눈에 보는 기계로
RNN의 순차 처리 한계에서 Attention의 탄생, 그리고 'Attention Is All You Need' 한 편의 논문이 GPT, BERT, 오늘의 LLM 시대 전부를 만들어낸 이야기를 수식과 사례로 풀어본다.

어려운 문제는 쪼개서 푼다 — Augmented PINN(APINN)의 모든 것
PINN이 복잡한 문제 앞에서 좌절할 때, 수학자들은 수백 년 된 전략을 꺼내들었다 — '나눠서 정복하라.' 도메인 분해와 신경망을 결합한 APINN이 왜, 어떻게 PINN의 한계를 돌파하는지를 쉽고 깊게 풀어본다.

Learning Rate Schedule의 역사: 1951년 수학 정리에서 GPT의 코사인 스케줄까지
딥러닝에서 가장 중요한 하이퍼파라미터, 학습률. 1951년 Robbins-Monro의 수렴 조건에서 시작해, AlexNet의 계단식 감소, 코사인 어닐링, 워밍업, 그리고 GPT가 사용하는 현대적 스케줄까지 — 75년의 역사를 논문과 사례로 추적한다.

Gradient Clipping 완전 해부: 딥러닝의 안전벨트는 어떻게 탄생했는가
1991년, 독일어로 쓴 석사 논문 하나가 딥러닝의 근본 문제를 발견했다. 기울기가 폭발하거나 소멸한다. 22년 뒤, 세 명의 연구자가 해법을 제시했다 — Gradient Clipping. GPT-3부터 LLaMA까지, 모든 대형 모델의 훈련에 쓰이는 이 기법의 역사와 원리를 처음부터 파헤친다.