블로그로 돌아가기
DeepONet신경 연산자딥러닝시뮬레이션보편 근사FNOPINN
함수를 먹고 함수를 뱉는다 — DeepONet 완전 해부
1995년 증명된 '신경망으로 임의의 연산자를 근사할 수 있다'는 정리가, 25년 뒤 DeepONet으로 실현됐다. Branch Net과 Trunk Net의 우아한 이중 구조가 함수에서 함수로의 매핑을 학습하는 원리를 완전 해부한다.
코어닷투데이2026-03-0356분
1995년 증명된 '신경망으로 임의의 연산자를 근사할 수 있다'는 정리가, 25년 뒤 DeepONet으로 실현됐다. Branch Net과 Trunk Net의 우아한 이중 구조가 함수에서 함수로의 매핑을 학습하는 원리를 완전 해부한다.
일반적인 신경망은 숫자를 먹고 숫자를 뱉는다. 이미지(픽셀 값 벡터)를 넣으면 클래스(확률 벡터)를 돌려준다. 문장(토큰 시퀀스)을 넣으면 다음 토큰을 예측한다. 입력과 출력 모두 유한 차원의 벡터다.
하지만 과학과 공학의 핵심 문제는 다르다.
함수를 먹고 함수를 뱉는 매핑. 수학에서는 이것을 연산자(operator) 라고 부른다. 계산기가 숫자를 받아 숫자를 돌려주듯, 연산자는 곡선 전체를 받아 곡선 전체를 돌려준다.
만약 신경망이 이 연산자를 학습할 수 있다면? 초기조건이 바뀌든, 경계조건이 달라지든, 한 번 학습한 모델로 즉시 답할 수 있다면?
1995년, 한 편의 정리(theorem)가 이것이 이론적으로 가능하다는 것을 증명했다. 그리고 25년의 침묵 뒤, 2021년 Nature Machine Intelligence에 실린 한 편의 논문이 이 정리를 현실로 만들었다.
그 이름이 DeepONet — Deep Operator Network이다.
딥러닝의 이론적 기반 중 하나인 보편 근사 정리(Universal Approximation Theorem) 는 잘 알려져 있다. 1989년 Hornik, Stinchcombe, White가 증명한 이 정리의 핵심은:
충분히 넓은 단일 은닉층 신경망은 인 임의의 연속 함수를 원하는 정밀도로 근사할 수 있다.
수학적으로 표현하면, 컴팩트 집합 위에서 정의된 임의의 연속 함수 에 대해:
을 만족하는 신경망 이 존재한다. 하지만 이것은 벡터에서 벡터로의 매핑 — 유한 차원의 이야기다.
1995년, Tianping Chen과 Hong Chen은 IEEE Transactions on Neural Networks에서 이 정리를 무한 차원으로 확장했다. 논문 제목은:
"Approximation of continuous functionals by neural networks with application to dynamic systems"
핵심 결과를 현대적 표기로 정리하면:
가 컴팩트 집합 위에서 정의된 임의의 연속 비선형 연산자일 때, 적절한 구조의 신경망 이 존재하여 모든 에 대해 을 만족한다.
여기서 는 함수 공간 에서 함수 공간 로의 매핑이다. 즉, 신경망으로 임의의 연속 연산자를 근사할 수 있다.
이론적으로는 1995년에 이미 증명되었지만, 실제로 이를 구현하기에는 당시의 기술이 부족했다.
그렇게 25년 동안 이 정리는 수학 논문 속에 잠들어 있었다.
2021년, Brown University의 George Em Karniadakis 교수 그룹이 이 25년 된 정리를 현대 딥러닝으로 부활시켰다.
"Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators" — Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, George Em Karniadakis Nature Machine Intelligence, 3, 218–229 (2021)
George Em Karniadakis는 PINN의 공동 창시자이기도 하다 — Raissi, Perdikaris와 함께 2019년 Journal of Computational Physics에서 PINN을 발표한 바로 그 연구자다. 그가 PINN의 한계를 직접 목격한 후, 연산자 학습이라는 더 근본적인 해법을 추구한 것이 DeepONet이다.
Lu Lu(루 루) 는 당시 Brown University 박사후연구원으로, 이후 DeepXDE 라이브러리를 개발하며 과학 머신러닝 생태계의 핵심 인물이 되었다.
DeepONet이 왜 필요한지를 이해하려면, PINN의 구조적 한계를 먼저 짚어야 한다.
PINN은 좌표 를 입력받아 해당 점에서의 물리량 를 출력한다. 하나의 PINN 모델은 하나의 특정 문제 인스턴스(특정 초기조건, 특정 경계조건, 특정 파라미터)에 대한 해를 학습한다.
문제: 초기조건이 에서 으로 바뀌면? PINN을 처음부터 다시 학습해야 한다.
이것은 마치 덧셈 공식을 모르는 채로, "3 + 5 = 8"을 외우고, "3 + 6"이 나오면 다시 처음부터 외우는 것과 같다.
DeepONet은 다르다. 덧셈이라는 연산 자체를 학습한다. 어떤 숫자 쌍이 들어오든 즉시 합을 계산할 수 있는 것처럼, 어떤 초기조건이 들어오든 즉시 해를 예측한다.
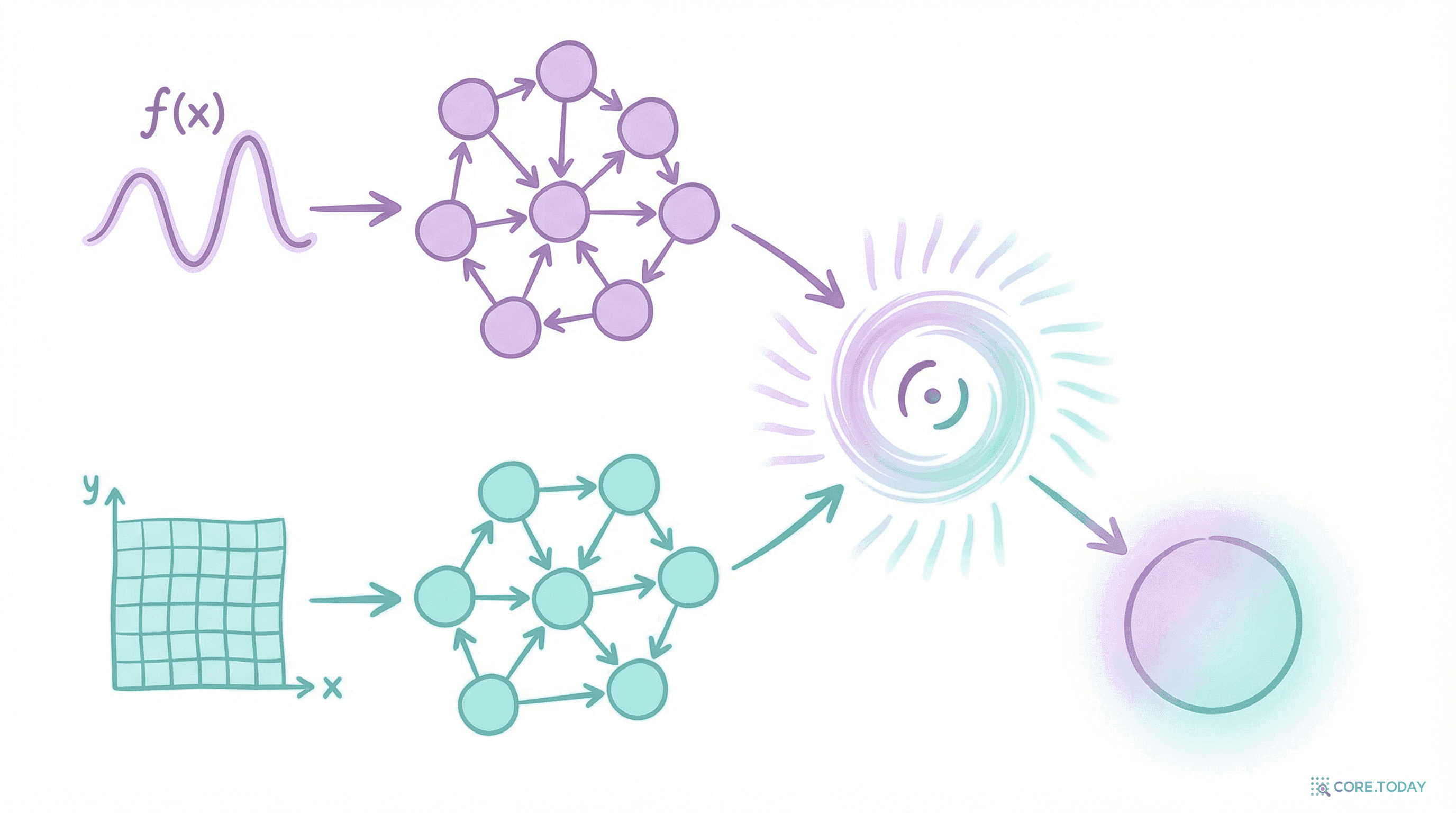
DeepONet의 아키텍처는 놀랍도록 우아하다. 두 개의 하위 네트워크가 서로 다른 역할을 분담하고, 그 출력의 내적(dot product)이 최종 결과를 만든다.

우리가 학습하려는 연산자는 이다. 예를 들어, 열방정식의 초기조건 에서 시간 후의 온도 분포 로의 매핑이다.
DeepONet의 출력은:
여기서:
벡터 표기로 더 간결하게 쓰면:
와 의 내적에 바이어스 를 더한 것이다.
Branch Network는 입력 함수의 정체를 인코딩한다.
입력 함수 를 직접 받을 수는 없다 — 함수는 무한 차원이므로. 대신, 미리 정해진 개의 센서 포인트 에서의 함수값 벡터 를 유한 차원 입력으로 사용한다.
직관: Branch Net은 입력 함수의 "지문(fingerprint)"을 추출한다. 와 은 센서 포인트에서의 값 패턴이 다르고, Branch Net은 이 차이를 개의 계수로 인코딩한다.
Trunk Network는 출력을 평가할 위치를 인코딩한다.
여기서 는 출력 함수를 알고 싶은 점의 좌표다. 는 출력 도메인의 차원(1D, 2D, 3D 등)이다.
직관: Trunk Net은 출력 공간의 기저 함수(basis functions) 를 학습한다. 푸리에 급수에서 , 가 기저 함수 역할을 하듯, Trunk Net이 데이터로부터 최적의 기저를 스스로 학습한다.
최종 출력은 Branch 출력(계수)과 Trunk 출력(기저 함수값)의 내적이다.
이것은 함수 근사의 고전적 형태와 정확히 일치한다. 푸리에 급수를 떠올려 보자:
푸리에 급수에서 기저 함수 는 사인/코사인으로 고정되어 있고, 계수 만 함수마다 달라진다. DeepONet에서는 기저 함수도 학습하고, 계수도 학습한다. 그래서 더 효율적이다.
DeepONet의 아키텍처가 우아한 이유는 "어떤 함수인가"(Branch) 와 "어디서 평가하는가"(Trunk) 를 완전히 분리했기 때문이다.
이 분리 덕분에:
DeepONet의 학습 데이터는 (입력 함수, 출력 함수) 쌍으로 구성된다.
구체적으로, 학습 데이터셋은:
여기서 각 입력 함수 는 센서 포인트에서의 값 으로 표현되고, 출력 함수 는 여러 위치 에서의 값으로 제공된다.
가장 기본적인 손실 함수는 평균제곱오차(MSE)다:
여기서 는 DeepONet의 예측값이다. 은 학습에 사용한 입력 함수의 수, 는 각 출력 함수를 평가한 점의 수다.
학습 데이터를 생성하는 주된 방법은:
DeepONet과 FNO는 모두 신경 연산자(neural operator) 라는 같은 목표를 추구하지만, 접근 방식이 근본적으로 다르다. 둘 다 2021년에 발표되어 과학 머신러닝의 양대 산맥을 이루고 있다.

FNO는 입력 함수를 균일 격자 위의 이산화된 형태로 받아, 푸리에 변환 → 주파수 필터링 → 역변환을 반복하여 출력 함수를 생성한다. 주파수 공간에서 전역적 상호작용을 학습하는 것이 핵심이다.
DeepONet은 입력 함수를 센서 포인트에서의 값으로 받고(Branch), 출력 위치를 별도로 받아(Trunk), 두 정보의 내적으로 출력을 생성한다. 함수를 계수와 기저로 분해하는 것이 핵심이다.
FNO의 핵심 연산 — 푸리에 레이어:
FFT를 통해 복잡도로 전역 상호작용을 포착한다. 하지만 FFT는 균일 격자를 요구한다.
DeepONet의 핵심 연산 — 내적:
입력과 출력의 위치가 완전히 자유롭다. 센서 포인트 와 평가 포인트 가 균일 격자일 필요가 없다. 비행기 날개, 심장 혈관, 지질 구조 같은 불규칙한 기하학에서 DeepONet이 자연스러운 이유다.
FNO를 선택할 때:
DeepONet을 선택할 때:
원조 DeepONet 이후, 한계를 극복하고 성능을 높이는 다양한 변형이 등장했다.
Wang, Wang & Perdikaris (2021)가 제안. PINN의 물리 제약을 DeepONet에 결합한 가장 중요한 변형이다.
핵심 아이디어: 데이터 손실에 PDE 잔차 손실을 추가한다.
여기서 은 PDE의 잔차 연산자다. 예를 들어, 열방정식 에 대해:
장점: 라벨이 붙은 학습 데이터가 적어도 물리 법칙이 정규화(regularization) 역할을 하여, 데이터 효율이 크게 향상된다. 페어 데이터 없이 PDE만으로 학습하는 것도 가능하다.
Lu et al. (2022)이 제안. 고유직교분해(Proper Orthogonal Decomposition, POD) 를 Trunk Network 대신 사용한다.
기본 DeepONet의 Trunk Net이 기저 함수를 학습하는 대신, 학습 데이터에서 SVD를 통해 추출한 POD 기저를 사용한다:
여기서 는 데이터에서 추출한 POD 기저로, 학습하지 않는 고정된 기저다. Branch Net만 학습하면 되므로 학습이 더 빠르고 안정적이다.
출력이 스칼라가 아닌 벡터장(vector field) 인 경우를 위한 확장이다. 예를 들어, 유체역학에서 속도장 과 압력 를 동시에 예측할 때:
여러 Branch Net이 Trunk Net을 공유하는 구조다. 공유된 기저 함수가 출력 변수들 사이의 상관관계를 자연스럽게 포착한다.
Transformer의 어텐션 메커니즘을 DeepONet에 결합한 변형. Branch와 Trunk의 상호작용을 단순 내적에서 크로스 어텐션(cross-attention) 으로 확장한다. 복잡한 비선형 연산자에서 표현력이 향상된다.
문제: 전자 부품의 열 관리에서, 히트싱크 형상이 바뀔 때마다 열 전달 시뮬레이션을 다시 수행해야 한다. 형상 후보가 수백 개라면 비용이 막대하다.
DeepONet 적용: 히트싱크 표면의 온도 분포(입력 함수)에서 정상상태 온도장(출력 함수)으로의 연산자를 학습한다. 비정규 메시 위의 데이터를 자연스럽게 처리할 수 있으므로, 복잡한 핀(fin) 기하학에 바로 적용 가능하다.
효과: 새로운 히트싱크 형상에 대해 밀리초 단위의 열 예측이 가능하여, 설계 최적화 루프가 수백 배 가속된다.
문제: 원자로 냉각수, 화학 반응기 등에서 기포(bubble)의 생성·성장·합체·붕괴 역학을 예측하는 것은 CFD에서도 가장 어려운 문제 중 하나다. 계면 추적(interface tracking)에 엄청난 계산 비용이 든다.
DeepONet 적용: Lin et al. (2021)은 기포 역학의 연산자를 DeepONet으로 학습시켜, 초기 기포 형상에서 시간에 따른 기포 형태 변화를 예측했다. Branch Net이 초기 기포 형상의 함수값을 인코딩하고, Trunk Net이 시공간 좌표를 처리한다.
문제: 교량이나 건물에 작용하는 하중은 시간에 따라 변한다(바람, 지진, 교통 등). 각 하중 시나리오에 대해 구조의 동적 응답을 예측하려면 반복적인 유한요소 해석이 필요하다.
DeepONet 적용: 하중 함수 (시간에 따른 외력)를 입력으로, 변위 함수 (위치와 시간에 따른 구조 변위)를 출력으로 하는 연산자를 학습한다.
핵심 이점: 하중의 형태가 임의적이어도 — 정현파든, 임펄스든, 지진파든 — 학습된 DeepONet이 즉시 구조 응답을 예측한다. 구조 건전성 모니터링(SHM) 의 실시간 디지털 트윈에 직접 활용 가능하다.
문제: 토카막(tokamak) 핵융합 장치에서 플라즈마를 안정적으로 가둬두려면, 자기장 코일의 전류를 실시간으로 조절해야 한다. 플라즈마의 MHD(자기유체역학) 방정식을 실시간으로 풀기에는 너무 느리다.
DeepONet 적용: 코일 전류 프로파일(입력 함수)에서 플라즈마 평형 상태(출력 함수)로의 연산자를 DeepONet으로 학습한다. 마이크로초 단위의 추론이 가능하여, MHD 시뮬레이션 대신 실시간 피드백 제어 루프에 투입할 수 있다.
DeepMind의 2022년 Nature 논문(Degrave et al.)이 강화학습으로 토카막 플라즈마를 제어한 것과 유사한 맥락이지만, DeepONet은 물리 방정식의 연산자를 직접 학습한다는 점에서 해석 가능성이 더 높다.
문제: 환자의 체내에서 약물 농도가 시간에 따라 어떻게 변하는지는 약동학 ODE 시스템으로 모델링된다. 환자마다 체중, 대사율, 간 기능 등 파라미터가 다르므로, 개인화된 약물 용량을 계산하려면 각 환자에 대해 ODE를 다시 풀어야 한다.
DeepONet 적용: 약물 투여 스케줄(입력 함수 — 시간에 따른 투여량)에서 혈중 농도 곡선(출력 함수)으로의 연산자를 학습한다. 환자 파라미터는 Branch Net의 추가 입력으로 처리한다.
효과: 새로운 환자에 대해 다양한 투여 스케줄의 결과를 즉시 시뮬레이션하여, 개인맞춤형 최적 용량을 실시간으로 결정할 수 있다.
DeepXDE는 Lu Lu가 개발한 오픈소스 Python 라이브러리로, DeepONet과 PINN을 통합적으로 지원하는 과학 머신러닝의 핵심 도구다.
Lu, L., Meng, X., Mao, Z., & Karniadakis, G. E. (2021). DeepXDE: A deep learning library for solving differential equations. SIAM Review, 63(1), 208–228.
DeepXDE는 SIAM Review에 게재되었다 — 응용수학 분야 최고 권위의 리뷰 저널이다. 이는 이 라이브러리가 단순한 소프트웨어가 아니라, 방법론적 기여로 인정받았음을 의미한다.
DeepXDE로 DeepONet을 구현하는 것이 얼마나 간결한지 보자. 다음은 항-미분(antiderivative) 연산자 를 학습하는 예다:
import deepxde as dde
import numpy as np
# 1. 데이터 생성 — 가우시안 랜덤 필드에서 입력 함수 샘플링
m = 100 # 센서 포인트 수
num_train = 10000
num_test = 1000
X_train, y_train = dde.data.triple_to_pair(
*gen_antiderivative_data(num_train, m)
)
X_test, y_test = dde.data.triple_to_pair(
*gen_antiderivative_data(num_test, m)
)
data = dde.data.TripleCartesianProd(
X_train, y_train, X_test, y_test
)
# 2. DeepONet 정의 — Branch와 Trunk 아키텍처
net = dde.nn.DeepONetCartesianProd(
[m, 128, 128, 128], # Branch: 입력 m → 128 → 128 → 128
[1, 128, 128, 128], # Trunk: 입력 1(좌표 y) → 128 → 128 → 128
activation="relu",
)
# 3. 모델 컴파일 및 학습
model = dde.Model(data, net)
model.compile("adam", lr=1e-3, metrics=["mean l2 relative error"])
model.train(epochs=50000)
Branch Net의 입력 차원이 (센서 수), Trunk Net의 입력 차원이 1(평가 위치 )이다. 두 네트워크의 최종 은닉층 크기가 128로 같아야 내적이 가능하다.
Branch Net은 고정된 센서 포인트 에서의 함수값을 입력으로 받는다. 이 센서 위치가 학습 시 결정되면, 추론 시에도 정확히 같은 위치에서 입력 함수를 평가해야 한다.
현실적 문제:
이는 FNO와의 결정적 차이점이다. FNO는 임의 해상도의 균일 격자를 받을 수 있어 이 문제가 없다(대신 균일 격자라는 제약이 있다).
입력 함수의 도메인이 고차원(3D 공간 + 시간 등)이면, 센서 포인트 수 이 기하급수적으로 증가해야 함수를 충분히 표현할 수 있다. 예를 들어, 3D 도메인을 각 축 10개 점으로 이산화하면 , 각 축 20개 점이면 이다. Branch Net의 입력 차원이 수천~수만이 되면 학습이 어려워진다.
FNO와 공유하는 한계다. DeepONet을 학습시키려면 (입력 함수, 출력 함수) 쌍이 수천 개 필요하고, 이 데이터는 대부분 비싼 수치 시뮬레이션으로 생성한다. PI-DeepONet이 이를 완화하지만, 복잡한 비선형 문제에서는 여전히 데이터가 필요하다.
Trunk Net이 출력하는 기저 함수의 수 는 하이퍼파라미터다. 가 너무 작으면 표현력이 부족하고, 너무 크면 과적합(overfitting) 위험이 있다. 최적의 를 결정하는 체계적 방법은 아직 연구 중이다.
세 가지 접근법은 경쟁이 아니라 상호 보완이다. 각각이 다른 상황에서 최적의 선택이 되며, 결합했을 때 가장 강력해진다.
LLM이 자연어의 기초 모델이라면, 신경 연산자는 물리 시뮬레이션의 기초 모델을 향한 핵심 빌딩 블록이다. Karniadakis 그룹은 2024년 이후 다중 물리(multi-physics) 연산자 학습 — 열, 유동, 구조, 전자기를 하나의 모델에서 동시에 다루는 — 을 연구하고 있다.
이 비전이 실현되면:
확산 모델(diffusion model)과 DeepONet의 결합도 주목할 만하다. 결정론적 예측 대신 확률 분포로서의 해를 학습하면, 불확실성 정량화가 자연스럽게 따라온다.
단일 점 추정이 아닌, "이 초기조건에서 해는 95% 확률로 이 범위 안에 있다"는 신뢰 구간을 제공할 수 있다.
2026년 현재, 가장 활발한 응용은 디지털 트윈이다. 물리 시스템(발전소, 항공기 엔진, 건축물 등)의 디지털 복제에 DeepONet이 실시간 물리 예측 엔진으로 들어간다.

센서가 온도, 압력, 변형률 데이터를 실시간으로 보내면, DeepONet이 이를 Branch Net의 입력으로 받아 시스템 전체의 물리적 상태를 밀리초 안에 예측한다. 전통적 시뮬레이션은 "사후 분석"에 머물렀지만, DeepONet의 속도는 "실시간 의사결정" 을 가능하게 한다.
1995년, Chen & Chen은 증명했다 — 신경망으로 임의의 연산자를 근사할 수 있다고. 하지만 그것은 종이 위의 정리일 뿐이었다. GPU도, PyTorch도, Adam 옵티마이저도 없던 시절이었다.
25년 뒤, Lu Lu와 Karniadakis는 이 정리를 깨워 DeepONet을 만들었다. Branch Net과 Trunk Net이라는 우아한 이중 구조로, 함수에서 함수로의 매핑을 학습하는 방법을 실현했다.
DeepONet의 핵심은 이것이다:
"어떤 함수인가"와 "어디서 평가하는가"를 분리하라.
이 단순한 분리가 연산자 학습을 가능하게 했고, 비정규 도메인에서의 자유를 선사했으며, 과학 시뮬레이션의 패러다임을 바꾸고 있다.
FNO가 주파수의 눈으로 물리를 보았다면, DeepONet은 기저 함수의 눈으로 물리를 본다. 둘은 경쟁이 아니라 쌍벽(雙璧) — 과학 머신러닝이라는 성벽의 두 기둥이다.
1995년의 정리가 2021년에 꽃피기까지 25년. 수학적 진리는 때때로 기술이 따라오기를 기다린다. 그리고 기술이 준비되었을 때, 그 폭발력은 25년의 기다림에 비례한다.