블로그로 돌아가기
PINN물리 정보 신경망딥러닝시뮬레이션과학 AI수치해석
AI에게 물리법칙을 가르치다 — Physics-Informed Neural Networks의 모든 것
데이터만으로는 부족하고, 시뮬레이션만으로는 느리다. 물리법칙을 손실함수에 녹인 PINN이 과학과 공학의 난제를 어떻게 풀어가는지, 탄생 배경부터 최신 사례까지 쉽고 깊게 살펴본다.
코어닷투데이2026-02-2842분
데이터만으로는 부족하고, 시뮬레이션만으로는 느리다. 물리법칙을 손실함수에 녹인 PINN이 과학과 공학의 난제를 어떻게 풀어가는지, 탄생 배경부터 최신 사례까지 쉽고 깊게 살펴본다.

2024년, 한 항공 엔지니어가 컨퍼런스에서 이런 질문을 던졌다.
"딥러닝이 설계한 날개 구조를 아무런 물리 검증 없이 신뢰할 수 있습니까?"
이 질문은 AI 시대의 핵심 딜레마를 관통한다. 딥러닝은 이미지 인식, 자연어 처리, 단백질 구조 예측까지 눈부신 성과를 냈다. 하지만 물리 세계의 문제 — 유체가 어떻게 흐르는지, 열이 어떻게 전달되는지, 구조물이 어떤 하중에서 무너지는지 — 를 풀 때는 사정이 다르다. 데이터만으로 학습한 AI는 뉴턴의 운동법칙을 위반하는 결과를 태연하게 내놓을 수 있다.
그렇다면 AI에게 물리법칙 자체를 가르치면 어떨까?
이것이 바로 Physics-Informed Neural Networks(PINN)의 핵심 아이디어다. 신경망의 손실함수에 편미분방정식(PDE)을 직접 녹여 넣어, 데이터에서 배우는 동시에 물리법칙을 따르도록 강제하는 것이다.
이 글에서는 PINN이 왜 등장했는지, 어떤 원리로 작동하는지, 그리고 지금 어디에 쓰이고 있는지를 역사부터 최신 사례까지 하나씩 풀어본다.

과학과 공학에서 현실 세계를 이해하는 방법은 크게 두 가지였다.
뉴턴 역학, 나비에-스토크스 방정식, 맥스웰 방정식 같은 물리법칙을 컴퓨터로 직접 푸는 방식이다. 유한요소법(FEM), 유한차분법(FDM), 유한체적법(FVM) 같은 수치해석 기법을 사용한다.
장점은 명확하다 — 물리적으로 정확하다. 수백 년간 검증된 방정식에 기반하므로, 결과가 물리법칙을 위반할 일이 없다.
하지만 문제가 있다.
대량의 실험·관측 데이터를 신경망에 학습시키는 방식이다. 한번 학습하면 예측이 밀리초 단위로 빠르다.
하지만 이쪽에도 치명적 약점이 있다.
이상적인 해결책은 두 세계의 장점을 결합하는 것이다 — 딥러닝의 속도와 유연성, 물리 시뮬레이션의 정확성과 일반화 능력을 동시에 가져오는 것. 바로 이 간극에서 PINN이 탄생했다.
신경망으로 미분방정식을 푸는 아이디어의 기원은 의외로 오래됐다. 1998년, 그리스 이오아니나 대학의 Isaac Lagaris와 동료들이 발표한 논문 "Artificial Neural Networks for Solving Ordinary and Partial Differential Equations" (IEEE Transactions on Neural Networks)가 이 분야의 씨앗이었다.
Lagaris의 핵심 아이디어는 단순하면서도 우아했다.
미분방정식의 해를 신경망으로 근사하되, 시행 해(trial solution) 자체가 경계조건을 자동으로 만족하도록 구성하자.
예를 들어, 라는 경계조건이 있으면, 시행 해를 형태로 설계했다. 여기서 는 신경망의 출력이다. 이면 가 자동으로 성립한다. 영리한 구조다.
하지만 이 방법은 단순한 기하학에서만 작동했고, 당시 컴퓨팅 파워의 한계와 딥러닝 이론의 미성숙으로 인해 주류가 되지 못했다. 그럼에도 "신경망이 물리를 배울 수 있다"는 가능성을 최초로 보여준 중요한 이정표였다.
20년의 공백 후, 결정적 전환이 찾아왔다. 2019년, Brown University의 Maziar Raissi, Paris Perdikaris, George Em Karniadakis가 Journal of Computational Physics에 발표한 논문이 판도를 바꿨다.
"Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations"
이 논문이 혁명적이었던 이유는 무엇일까?
Lagaris와 달리 Raissi는 자동 미분(automatic differentiation) — 딥러닝 프레임워크가 이미 가지고 있는 기능 — 을 활용해 물리 잔차(physics residual)를 계산했다. 별도의 수치 미분이 필요 없었다. TensorFlow나 PyTorch의 역전파 메커니즘이 편미분방정식의 잔차를 정확하게 계산해 준 것이다.
게다가 Raissi는 두 가지 문제를 동시에 풀 수 있음을 보였다.
특히 역문제 해결 능력은 기존 수치해석에서는 매우 어려운 영역이었기 때문에, PINN의 가치를 크게 부각시켰다.
2019년 논문 발표 이후, PINN 관련 연구는 기하급수적으로 증가했다. Google Scholar 기준으로 원 논문의 피인용 수는 2026년 현재 12,000회를 초과한다. 이는 계산과학 분야에서 이례적인 수치다.
주요 이정표를 정리하면:
2021년은 특히 중요한 해였다. Karniadakis 등이 Nature Reviews Physics에 발표한 종합 리뷰 "Physics-informed machine learning" 이 물리학, 화학, 생물학, 공학 전반에 걸친 PINN의 가능성을 체계적으로 정리하면서, 각 분야 연구자들의 대규모 유입이 시작됐다.

PINN의 핵심은 놀라울 정도로 단순하다.
일반 신경망의 손실함수에 "물리법칙 위반 정도"를 추가한다.
일반적인 딥러닝에서 손실함수는 이렇게 생겼다:
여기서 는 신경망의 예측, 는 실제 관측 데이터다. "예측과 데이터가 얼마나 다른지"만 측정한다.
PINN은 여기에 물리 잔차(physics residual) 항을 추가한다:
각 항이 무엇을 의미하는지 하나씩 보자.
1. 데이터 손실 (): 실험이나 관측에서 얻은 데이터와의 차이. 전통적 지도학습과 같다.
2. 물리 손실 (): 이것이 PINN의 심장이다. 지배 방정식(governing equation)의 잔차를 계산한다.
예를 들어 어떤 물리 시스템이 편미분방정식 을 따른다고 하자. (은 미분 연산자.) 신경망이 출력한 를 이 방정식에 대입했을 때, 잔차 가 0에 가까워야 한다:
3. 경계·초기 조건 손실 (): 문제의 경계조건과 초기조건을 만족하도록 강제한다.
와 는 각 항의 가중치다. "물리를 얼마나 엄격하게 따를지"를 조절하는 노브라고 생각하면 된다.

여기서 자연스러운 의문이 든다. 편미분을 어떻게 계산하는가?
전통적 수치해석에서는 격자(mesh) 위에서 유한차분으로 미분을 근사한다. 하지만 PINN은 딥러닝 프레임워크의 자동 미분(Automatic Differentiation) 을 사용한다.
신경망 의 출력을 입력 나 에 대해 미분하는 것은 역전파(backpropagation)의 기본 연산이다. PyTorch에서는 torch.autograd.grad를, TensorFlow에서는 tf.GradientTape를 사용하면 기계 정밀도 수준의 정확한 미분을 얻을 수 있다. 수치 미분의 근사 오차가 없다.
이것이 바로 Raissi의 통찰이었다. 딥러닝이 이미 가지고 있는 자동 미분이라는 도구가, 편미분방정식의 잔차를 계산하는 데 자연스럽게 쓰일 수 있다는 것이다.
1차원 버거스 방정식(Burgers' equation)은 PINN 논문의 대표적 벤치마크 문제다:
여기서 는 속도, 는 점성 계수다.
PINN의 물리 잔차는 다음과 같이 정의된다:
신경망이 완벽한 해를 출력하면 이 된다. 학습 과정에서 이 잔차를 0에 가깝게 만들면, 신경망은 자연스럽게 버거스 방정식을 만족하는 해를 학습하게 된다.
Raissi의 원 논문에서 이 방정식은 경계 데이터 단 몇백 개만으로 전체 시공간 영역의 해를 정확하게 복원했다. 데이터가 희소한 상황에서도 물리법칙이 강력한 정규화(regularization) 역할을 한 것이다.
핵심을 요약하면: PINN은 메시 없이(mesh-free) 작동한다. 도메인 내부에 무작위로 뿌린 점들(collocation points)에서 물리 잔차를 계산하기 때문에, 복잡한 형상에 대한 메시 생성이 불필요하다. 이것이 유한요소법 대비 PINN의 가장 큰 구조적 장점 중 하나다.
PINN의 진가는 실전에서 드러난다. 다양한 분야의 사례를 살펴보자.
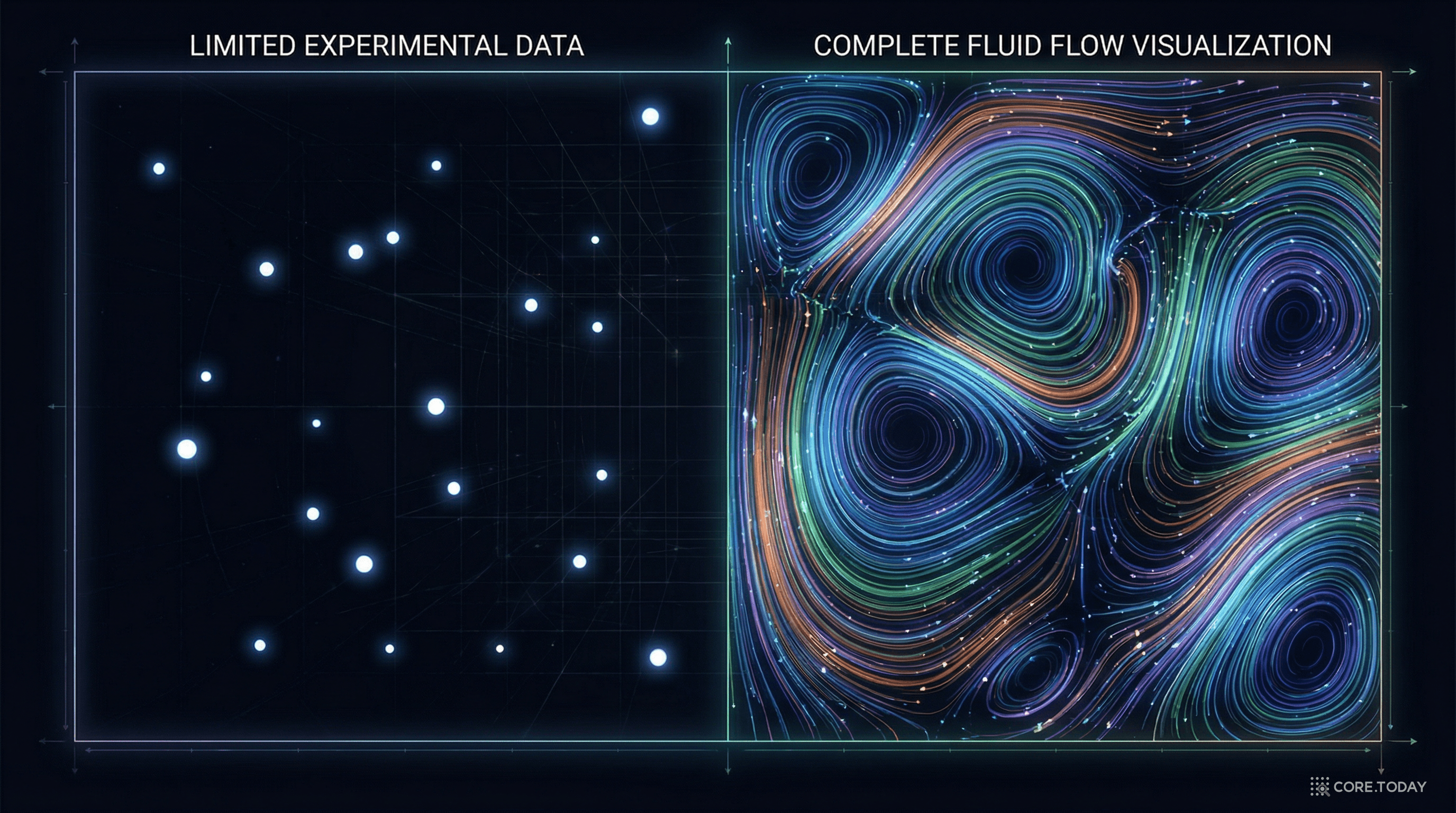
문제: 항공기, 자동차, 발전소 터빈의 설계에서 유체 유동(flow)을 정확히 아는 것은 필수적이다. 하지만 3D 나비에-스토크스 방정식을 직접 풀면 슈퍼컴퓨터 수천 시간이 소요된다.
PINN 적용: Raissi et al. (2020)은 Science에 발표한 후속 연구 "Hidden fluid mechanics" 에서, 유동 가시화 실험의 농도 데이터만으로 속도장과 압력장을 동시에 복원했다. 실험에서 직접 측정하기 어려운 압력 분포를 나비에-스토크스 방정식이라는 물리적 제약을 통해 추론한 것이다.
이것은 마치 의사가 CT 단면 사진 몇 장으로 3D 장기 구조를 재구성하는 것과 비슷하다. 부분적 관측에서 전체를 복원하는 데 물리법칙이 "빠진 정보를 채우는 접착제" 역할을 한다.
영향: 풍동 실험 비용의 대폭 절감이 가능해졌으며, 실험 측정이 불가능한 영역(예: 인체 내 혈류)의 유동 분석에도 길이 열렸다.
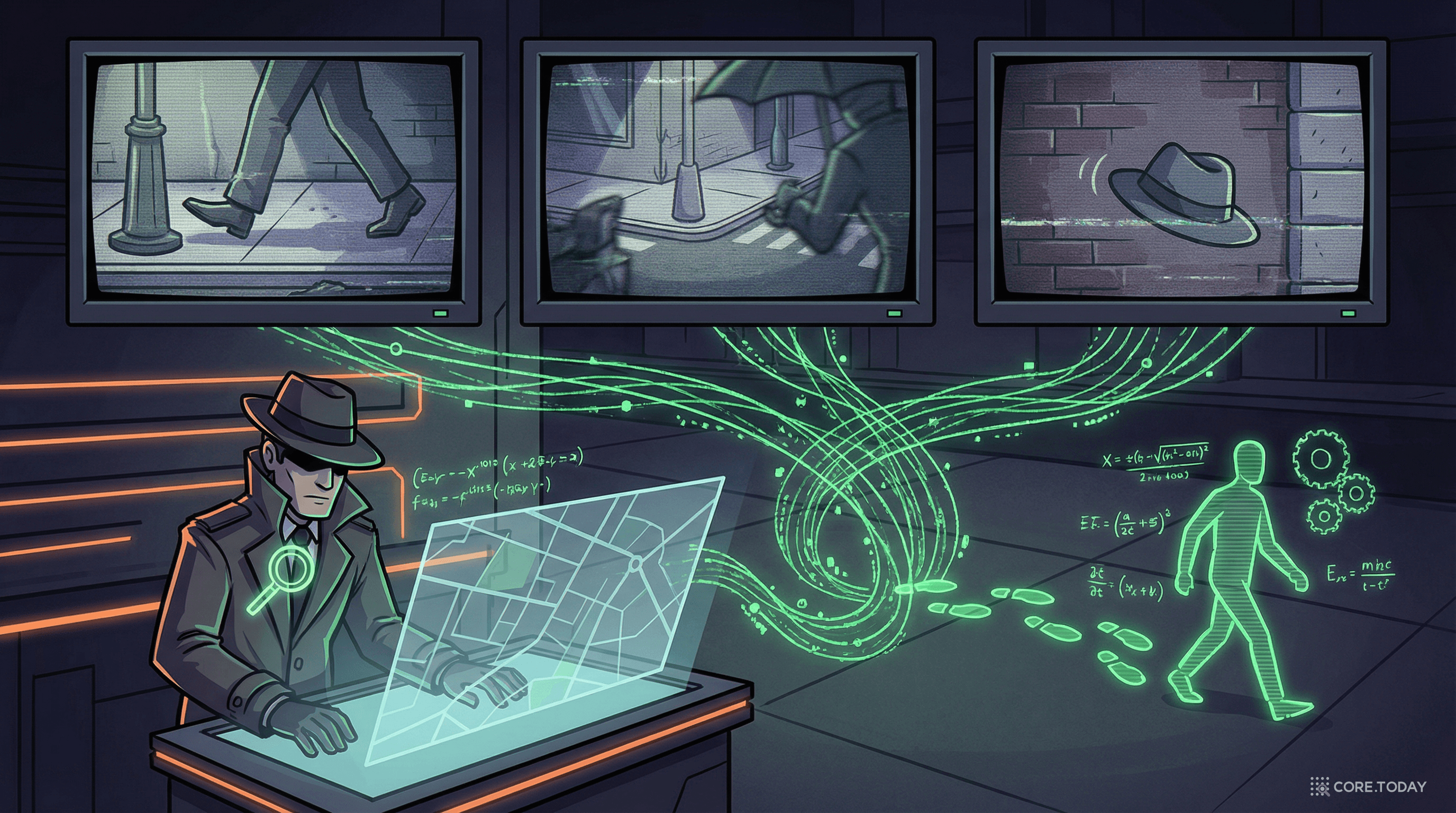
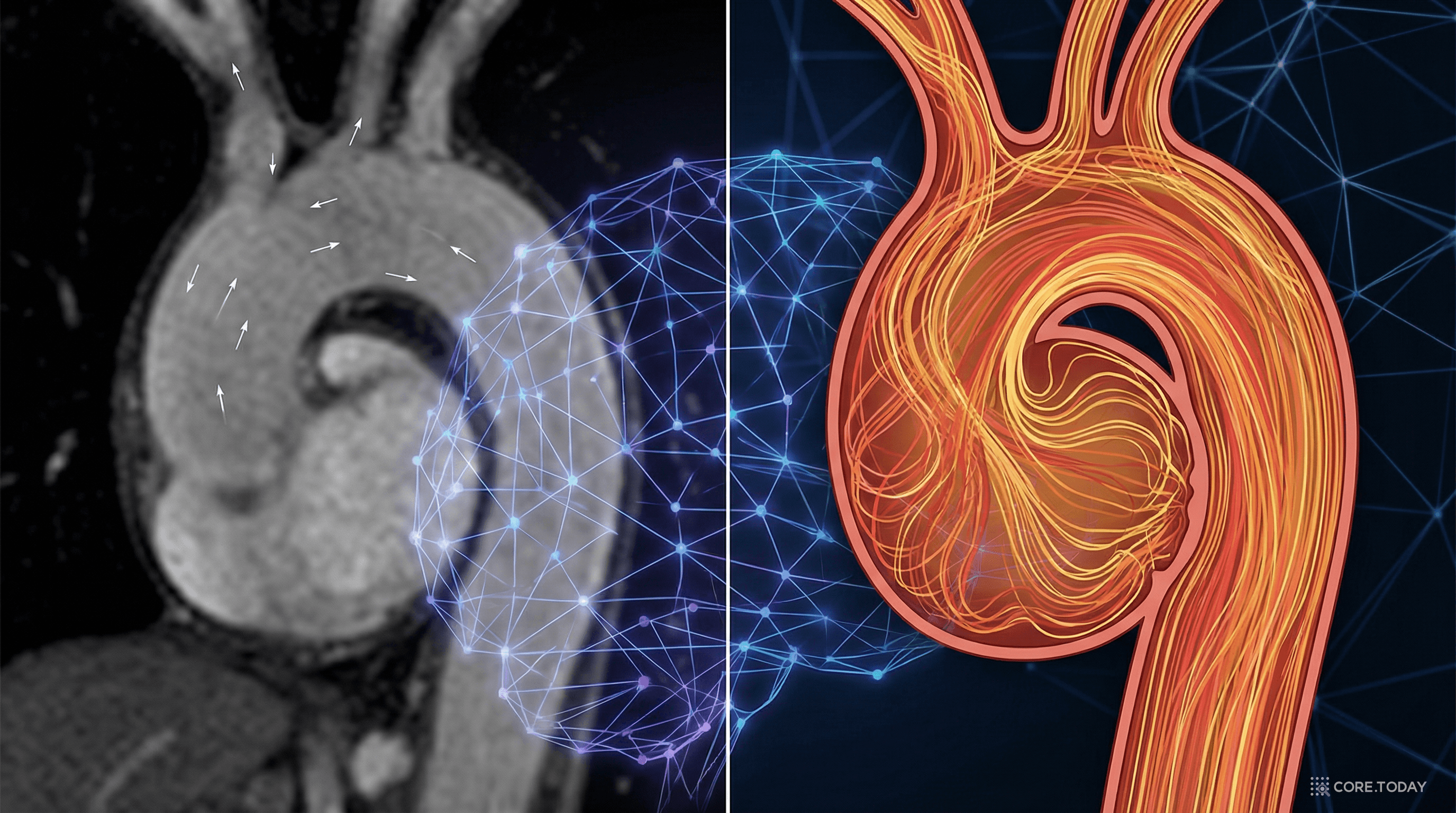
문제: 심혈관 질환 진단에서 혈관 내 압력 분포와 벽면 전단 응력(wall shear stress)은 핵심 지표다. 하지만 이를 직접 측정하려면 침습적 카테터 삽입이 필요하다.
PINN 적용: Kissas et al. (2020)은 4D-Flow MRI 데이터와 나비에-스토크스 방정식을 결합한 PINN을 사용해, MRI 영상만으로 대동맥의 혈압, 속도장, 벽면 전단 응력을 동시에 추정했다.
MRI가 제공하는 것은 비교적 저해상도의 속도 데이터뿐이다. 하지만 PINN이 "이 혈류는 나비에-스토크스 방정식을 따라야 한다"는 제약을 가함으로써, 잡음을 걸러내고 측정할 수 없던 압력까지 추정할 수 있었다.
비유: 범죄 현장의 불완전한 CCTV 영상에서, "물리법칙"이라는 사전 지식을 활용해 사건의 전체 경과를 재구성하는 것과 같다.
문제: 신소재나 복합재료의 물성(탄성 계수, 열전도율 등)을 정확히 측정하려면 수많은 파괴 시험이 필요하다.
PINN 적용: PINN은 역문제(inverse problem) 해결에 특히 강력하다. 구조물의 변형 데이터를 관측한 뒤, 탄성 방정식을 물리 제약으로 활용해 미지의 재료 상수를 역추정할 수 있다.
Zhang et al. (2020)은 균열이 있는 구조물의 변위 데이터와 선형 탄성 방정식을 결합해, 균열 주변의 응력 확대 계수를 정확하게 추정했다. 기존 역문제 해법에 비해 계산 비용이 10분의 1 이하로 줄었다.
문제: 전통적 수치 기상 예측(NWP)은 대기 물리법칙에 기반하지만, 격자 해상도의 한계로 구름 규모의 현상을 제대로 포착하지 못한다.
PINN 적용: Kashinath et al. (2021)은 Philosophical Transactions of the Royal Society A에서 "Physics-informed machine learning: case studies for weather and climate modelling"을 발표하며, 데이터 기반 기상 예측에 물리 제약을 부여하는 것이 예측 정확도와 물리적 일관성을 동시에 향상시킴을 보였다.
특히 대기의 에너지 보존, 질량 보존, 수분 보존 같은 기본 보존 법칙을 PINN에 포함시키면, 비물리적 예측(예: 음수 습도, 에너지 생성)을 원천적으로 방지할 수 있다.
문제: 석유·가스 탐사와 지진 위험 평가에서 지하 속도 구조를 아는 것은 핵심이다. 하지만 이를 직접 관측할 수 없으므로, 지표면에서 기록된 지진파 데이터로 역추정해야 한다.
PINN 적용: Song et al. (2021)은 PINN을 사용해 지진 파동 방정식의 역문제를 풀었다. 지표면 관측 데이터와 파동 방정식을 결합하여 지하의 P파 속도 분포를 추정한 것이다. 기존 방법 대비 초기 모델 의존도가 크게 줄었고, 적은 수의 관측점으로도 합리적인 결과를 산출했다.
문제: 반도체 칩의 고집적화로 열 관리가 갈수록 중요해지고 있다. 칩 내부의 온도 분포를 정확히 예측해야 설계 최적화가 가능하다.
PINN 적용: Cai et al. (2021)은 열전도 방정식을 물리 제약으로 사용하여, 표면 온도 측정 데이터 몇 점만으로 칩 내부의 3D 온도 분포를 재구성했다. 유한요소법(FEM) 시뮬레이션 대비 100배 이상 빠른 추론 속도를 달성하면서도, 온도 예측 오차는 2% 이내였다.
원조 PINN 이후, 다양한 한계를 극복하기 위한 변종들이 쏟아졌다.
일반 PINN은 보존 법칙을 연성 제약(soft constraint) 으로 부과한다. 즉, 손실함수를 최소화하지만, 완벽하게 0으로 만드는 것을 보장하지는 않는다. Jagtap et al. (2020)이 제안한 cPINN은 도메인을 부분 영역으로 나누고, 인접 영역 간의 플럭스 연속성(flux continuity) 을 명시적으로 부과해 보존 법칙의 준수율을 높였다.
Jagtap & Karniadakis (2020)이 제안한 XPINN은 공간 분해(domain decomposition) 기법을 도입해 각 영역에 별도의 신경망을 배치했다. 이를 통해 급격한 물리 변화가 있는 영역(충격파, 경계층 등)을 더 정밀하게 포착할 수 있다.
PINN의 사촌이라 할 수 있는 연산자 학습(operator learning) 접근법도 주목할 만하다.
Fourier Neural Operator (FNO): Li et al. (2021)이 제안. 푸리에 공간에서 연산자를 학습해, 하나의 학습으로 다양한 초기·경계조건에 대한 해를 한꺼번에 근사한다. 전통적 PINN이 하나의 문제 인스턴스를 풀 때마다 재학습이 필요한 반면, FNO는 한 번 학습 후 새로운 조건에 대해 즉시 예측 가능하다.
DeepONet: Lu et al. (2021)이 제안. Chen & Chen (1995)의 보편 근사 정리를 기반으로, 함수에서 함수로의 매핑(연산자)을 학습하는 아키텍처다. 분기 네트워크(branch net)와 트렁크 네트워크(trunk net)의 조합으로 구성된다.
이들은 PINN과 경쟁이 아니라 상보적 관계에 있다. 물리 제약을 FNO나 DeepONet의 학습에도 결합할 수 있기 때문이다.
Wang et al. (2021)은 PINN 학습의 고질적 어려움 — 물리 손실과 데이터 손실의 스케일 불균형 — 을 분석하고, NTK(Neural Tangent Kernel) 이론을 활용한 적응적 가중치 조절 기법을 제안했다. 이 연구는 PINN이 왜 때때로 학습에 실패하는지를 이론적으로 설명한 첫 번째 논문 중 하나였다.
PINN이 만능은 아니다. 현재 알려진 주요 한계를 정직하게 짚어보자.
PINN의 손실함수는 여러 항의 합이다. 이 항들의 스케일이 크게 다를 수 있으며, 한 항의 최소화가 다른 항을 악화시키는 경쟁 구도가 발생한다. Wang et al. (2022)은 이를 "다중 목적 최적화 딜레마"로 설명했다.
난류(turbulence), 충격파(shock wave) 같은 불연속적이고 다중 스케일인 현상에서는 PINN의 정확도가 크게 떨어질 수 있다. 매끄러운 해를 가정하는 신경망의 특성상, 급격한 변화를 포착하기 어렵다.
PINN은 학습 단계에서 콜로케이션 포인트마다 자동 미분을 수행해야 하므로, 학습 자체가 느릴 수 있다. 특히 고차 PDE에서는 미분 계산의 비용이 급격히 증가한다.
하나의 문제 인스턴스에 대해 학습한 PINN은 조건이 바뀌면 재학습이 필요하다. 이것이 FNO 같은 연산자 학습 접근법이 등장한 배경이기도 하다.
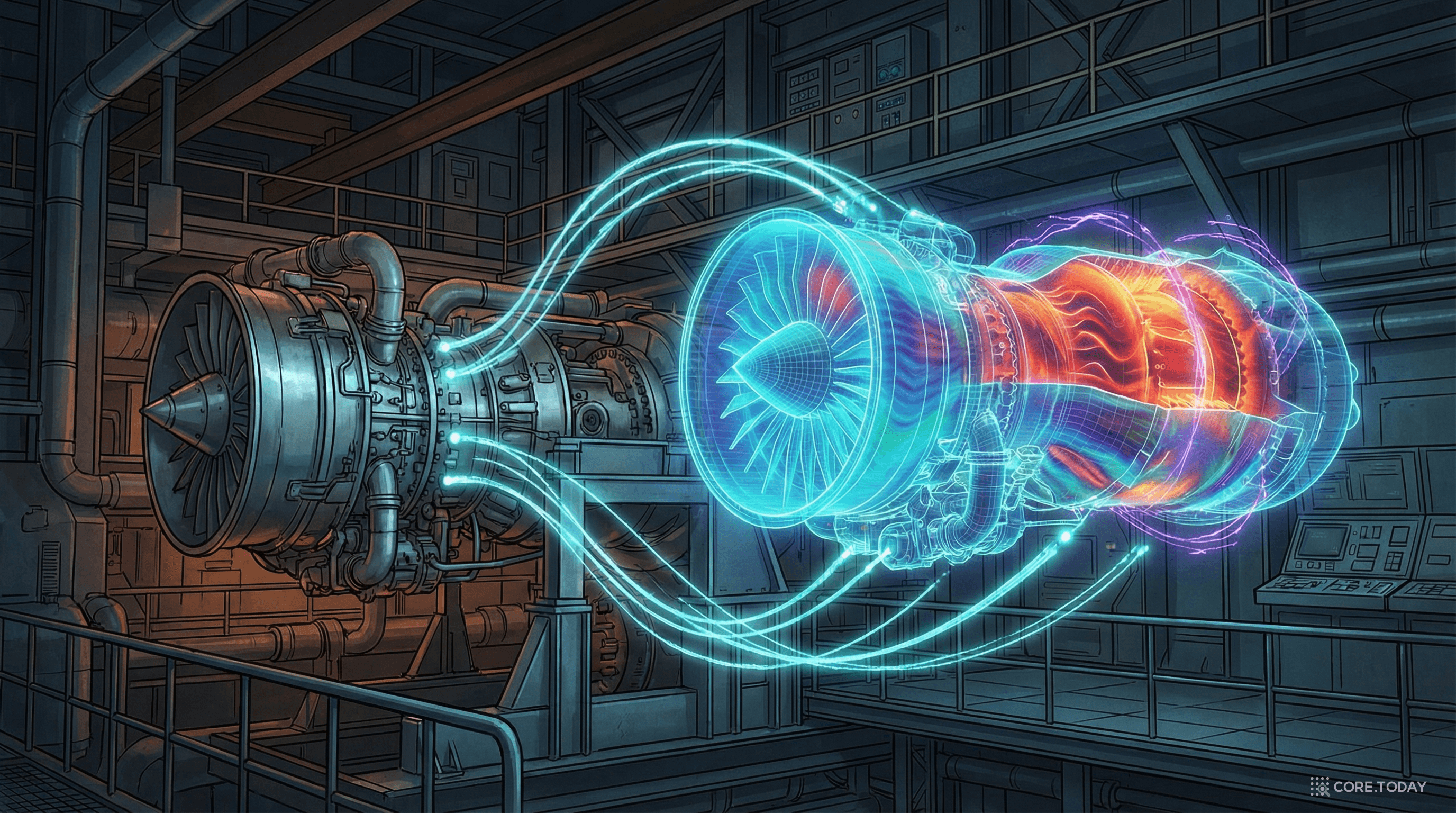
LLM이 자연어의 기초 모델이 되었듯, 과학 시뮬레이션의 기초 모델을 만들려는 시도가 활발하다. NVIDIA의 Modulus는 PINN과 연산자 학습을 결합한 산업용 AI 시뮬레이션 플랫폼으로, 2024년부터 항공·에너지·기상 분야에서 실증을 진행하고 있다.
디지털 트윈(Digital Twin) — 물리 시스템의 실시간 가상 복제본 — 에서 PINN은 핵심 기술로 자리잡고 있다. 센서 데이터가 들어올 때마다 PINN이 물리 모델을 실시간으로 업데이트해, 구조물의 건전성 모니터링, 공정 최적화, 예지 정비(predictive maintenance) 에 활용된다.
Siemens, GE, Rolls-Royce 같은 기업들이 가스터빈, 제트엔진의 디지털 트윈에 PINN 기반 모델을 적용하고 있다.
PINN은 "다음에 어디를 측정해야 가장 많은 정보를 얻을 수 있는가?"라는 질문에도 답할 수 있다. 물리 잔차의 불확실성이 높은 영역을 식별해 능동적 학습(active learning)과 결합하면, 최소한의 실험으로 최대한의 정보를 추출하는 자동화된 실험 설계가 가능해진다.
Cerebras, Graphcore 같은 AI 칩 회사들이 PINN의 자동 미분 연산에 최적화된 하드웨어를 개발하고 있다. 특히 Cerebras의 WSE(Wafer Scale Engine)는 PINN의 콜로케이션 포인트 병렬 처리에 이상적인 구조를 가지고 있어, 전통 GPU 대비 수십 배의 학습 속도 향상이 보고되고 있다.
PINN의 가치는 단순히 "더 빠른 시뮬레이션"에 있지 않다. 더 근본적인 수준에서 과학 연구의 패러다임을 바꾸고 있다.
전통적 과학은 이렇게 진행됐다:
PINN이 가능하게 하는 새로운 패러다임:
즉, PINN은 데이터에서 물리를 발견하는 도구이기도 하다. 관측 데이터에 숨겨진 지배 방정식을 찾아내는 역문제 해결 능력은, 복잡계 과학, 생물학, 기후과학 같은 분야에서 아직 알려지지 않은 물리법칙을 탐색하는 데 활용될 수 있다.
Karniadakis는 2021년 Nature Reviews Physics 리뷰에서 이렇게 썼다:
"Physics-informed machine learning은 데이터 과학과 계산 과학의 '제3의 기둥'이 될 수 있다."
첫 번째 기둥은 이론(방정식), 두 번째 기둥은 데이터(실험·관측), 그리고 세 번째 기둥이 이 둘을 융합하는 PINN 같은 하이브리드 접근법이라는 뜻이다.
이 글의 처음으로 돌아가 보자. "AI가 설계한 날개를 신뢰할 수 있는가?"
PINN의 답은 이렇다: 물리법칙을 모르는 AI는 신뢰할 수 없지만, 물리법칙을 학습한 AI는 다르다.
PINN은 "데이터 vs 물리"라는 이분법을 해체했다. 데이터가 충분하지 않아도 물리가 보완하고, 물리만으로 풀 수 없는 복잡한 문제도 데이터가 돕는다. 이 상보적 관계가 PINN의 본질이다.
물론 PINN은 아직 완성형이 아니다. 난류, 다중 스케일 문제, 학습 안정성 등 풀어야 할 과제가 남아 있다. 하지만 30년 전 Lagaris의 소박한 실험에서 시작해 지금은 디지털 트윈, 의료영상, 기상예측, 재료설계까지 확장된 PINN의 궤적을 보면, 하나의 방향은 분명하다.
과학과 AI의 미래는 분리가 아니라 융합이다.

그리고 그 융합의 가장 성공적인 실현이, 바로 PINN이다.