들어가며: 절벽에서 떨어지지 않는 법
딥러닝 모델을 훈련할 때, 가끔 이런 일이 벌어진다:
- 손실(loss)이 갑자기 NaN이 된다
- 가중치가 무한대로 발산한다
- 잘 학습되던 모델이 갑자기 폭주한다
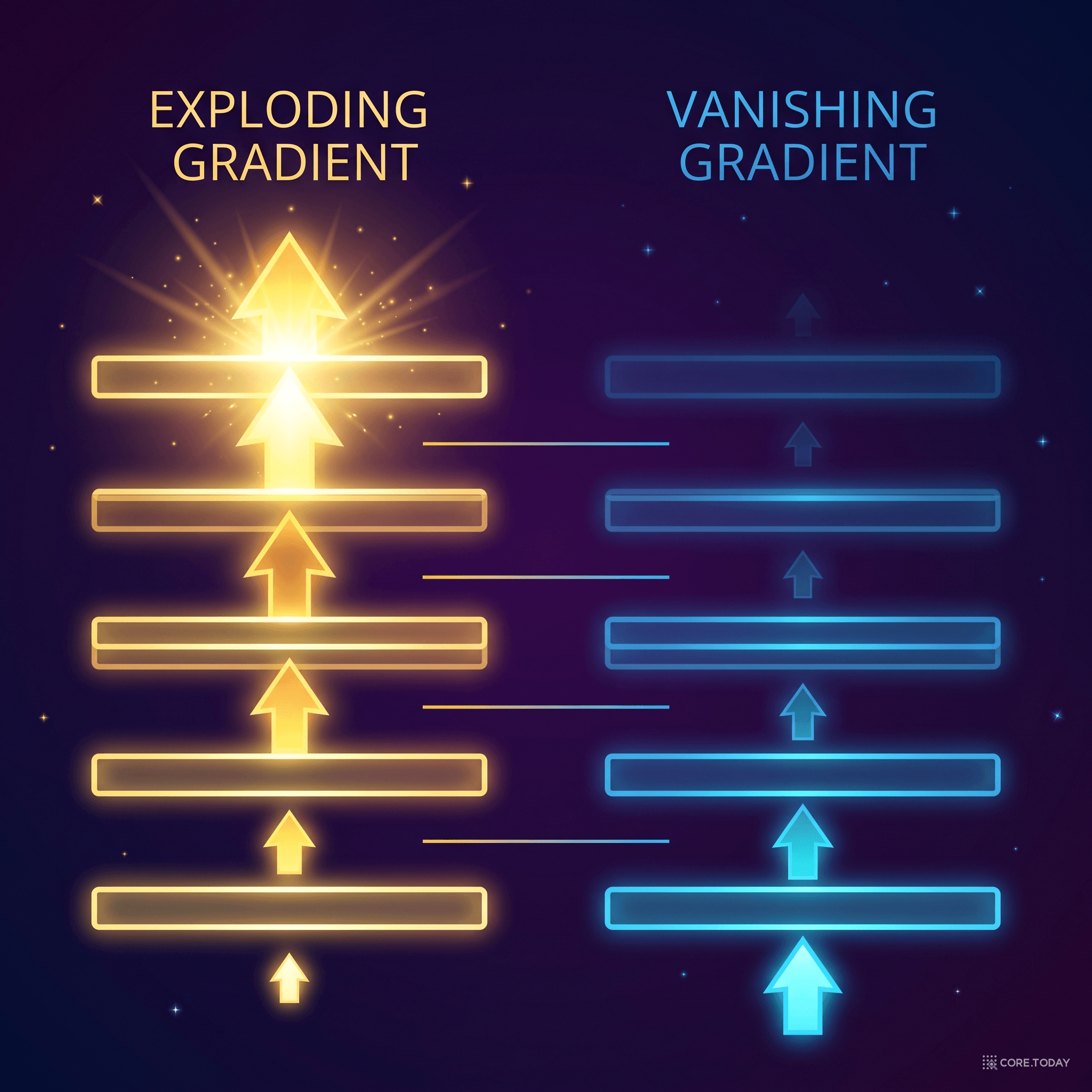
이것은 기울기 폭발(Exploding Gradient)이다. 역전파 과정에서 기울기가 층을 거칠 때마다 곱해지면서 기하급수적으로 커지는 현상이다.
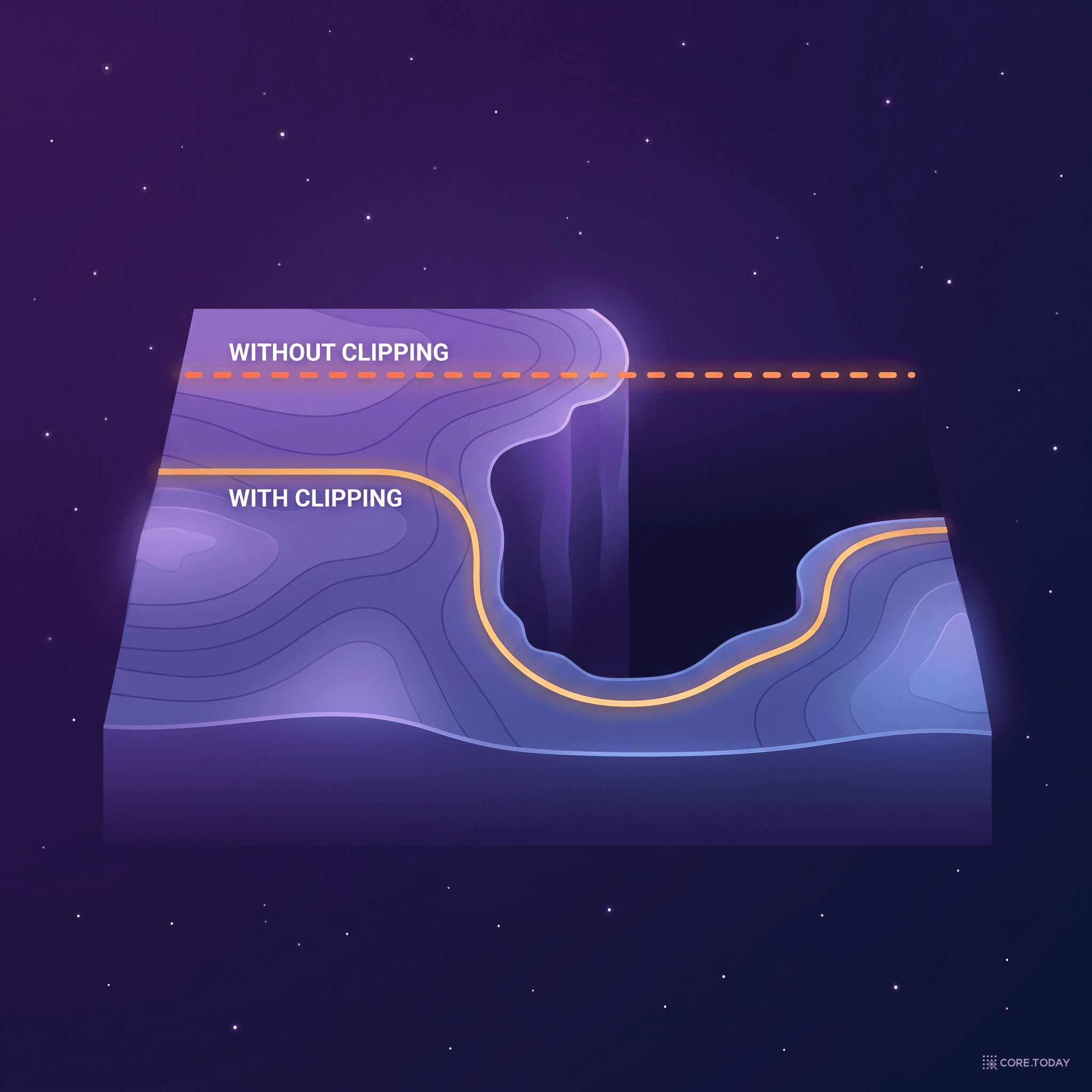
비유하자면, 손실 지형(loss landscape)에 절벽이 있다. 일반적인 경사 하강법은 이 절벽을 만나면 파라미터를 절벽 너머로 날려 보내 훈련을 망친다.
Gradient Clipping은 이 문제의 해법이다 — "기울기의 크기가 일정 한계를 넘으면 잘라낸다." 단순하지만, GPT-3, BERT, LLaMA 등 모든 대형 모델의 훈련에 쓰이는 핵심 기법이다.
이 글은 Gradient Clipping이 왜 필요하고, 어떻게 작동하며, 어떤 역사를 거쳐 오늘날의 표준이 되었는지를 처음부터 파헤친다.
제1장: 기울기가 폭발하는 이유 — 수학으로 이해하기
역전파의 연쇄 법칙
신경망의 학습은 역전파(backpropagation)로 이루어진다. 출력의 오차를 입력 방향으로 전파하며, 각 가중치가 오차에 얼마나 기여했는지를 계산한다. 이 과정에서 연쇄 법칙(chain rule)이 사용된다.
깊이가 T인 네트워크에서, k번째 층의 기울기는:
역전파에서의 기울기 계산
기울기 = 야코비안 행렬의 곱
∂L/∂x_k = ∏(i=k+1 to T) W_rec^T · diag(σ'(x_{i-1}))
핵심은 곱셈이다. 각 층의 야코비안 행렬이 곱해진다. 이 행렬의 고유값(eigenvalue)이:
- 1보다 크면: 기울기가 층을 거칠수록 기하급수적으로 커진다 → 기울기 폭발
- 1보다 작으면: 기울기가 층을 거칠수록 기하급수적으로 작아진다 → 기울기 소실
직관적 비유
숫자 1.1을 50번 곱하면? → 117.39 (폭발)
숫자 0.9를 50번 곱하면? → 0.0052 (소멸)
기울기가 50개 층을 통과하면, 아주 작은 차이가 극적인 결과를 만든다.
제2장: 역사 — 문제의 발견에서 해법까지

1991 — Sepp Hochreiter의 독일어 석사 논문
기울기 소실/폭발 문제를 최초로 엄밀하게 증명한 것은 1991년, 뮌헨 공과대학의 석사과정 학생 Sepp Hochreiter였다. 그의 논문 "Untersuchungen zu dynamischen neuronalen Netzen"(동적 신경망 연구)에서:
"역전파 오차 신호는 급격히 줄어들거나, 한계 없이 커진다."
지도교수는 Jürgen Schmidhuber. 이 발견이 1990~2000년대의 모든 딥러닝 연구를 방향 지었다고 Schmidhuber는 술회했다.
하지만 독일어로 작성되었고 널리 배포되지 않아, 학계에서 즉각적 영향력은 제한적이었다.
1994 — Yoshua Bengio의 공식 분석
Hochreiter의 발견을 영어 학술 세계에 알린 것은 Yoshua Bengio 등의 1994년 논문이었다:
"Learning Long-Term Dependencies with Gradient Descent Is Difficult"
(IEEE Transactions on Neural Networks, 1994)
장기 의존성을 학습하려 할수록 기울기 기반 학습이 근본적으로 어려워지는 이유를 공식 분석했다. 수천 회 인용된 이 논문은 기울기 소실 문제의 표준 참고문헌이 되었다.
1997 — LSTM: 구조적 해법
Hochreiter와 Schmidhuber가 제안한 LSTM(Long Short-Term Memory)은 기울기 소실을 구조적으로 해결했다. 셀 상태(cell state)에 가중치 1의 자기 연결 경로를 만들어, 기울기가 여러 시간 단계를 통과해도 소멸하지 않게 했다.
하지만 LSTM은 기울기 소실에 대한 해답이었지, 기울기 폭발은 여전히 문제였다.
2012 — Tomas Mikolov의 첫 제안
Tomas Mikolov가 2012년 브르노 공과대학 박사 논문에서 최초로 Gradient Clipping을 제안했다. RNN 언어 모델 훈련 중 기울기 폭발을 방지하기 위해, 기울기 노름이 임계값을 넘으면 스케일링하는 기법을 도입했다.
2013 — 결정적 논문: Pascanu, Mikolov, Bengio
Gradient Clipping의 결정적 논문 (ICML 2013)
"On the Difficulty of Training Recurrent Neural Networks"
Razvan Pascanu, Tomas Mikolov, Yoshua Bengio — ICML 2013, pp. 1310-1318
이 논문이 Gradient Clipping을 정립했다. 핵심 기여:
- 기울기 노름 클리핑 알고리즘 공식화
- 기하학적 해석: 손실 지형의 "고곡률 벽(cliff)"에서 기울기가 폭발하는 메커니즘 설명
- 기울기 소실에 대한 연성 제약(soft constraint) 제안
- 실험적 검증 (다양한 임계값과 태스크)
이 논문의 Figure 6이 유명하다 — 손실 지형에 절벽이 있고, 클리핑 없이는 파라미터가 절벽 너머로 날아가지만, 클리핑을 적용하면 안전하게 절벽 옆을 따라 내려간다.
1991 — Hochreiter: 문제 발견 (기울기 소실/폭발)
↓
1994 — Bengio: 공식 분석
↓
1997 — LSTM: 소실 해결 (구조적 접근)
↓
2012 — Mikolov: Gradient Clipping 최초 제안
↓
2013 — Pascanu et al.: Gradient Clipping 정립 (ICML)
제3장: 어떻게 작동하는가 — 두 가지 방법
방법 1: 기울기 노름 클리핑 (Gradient Norm Clipping) — 권장
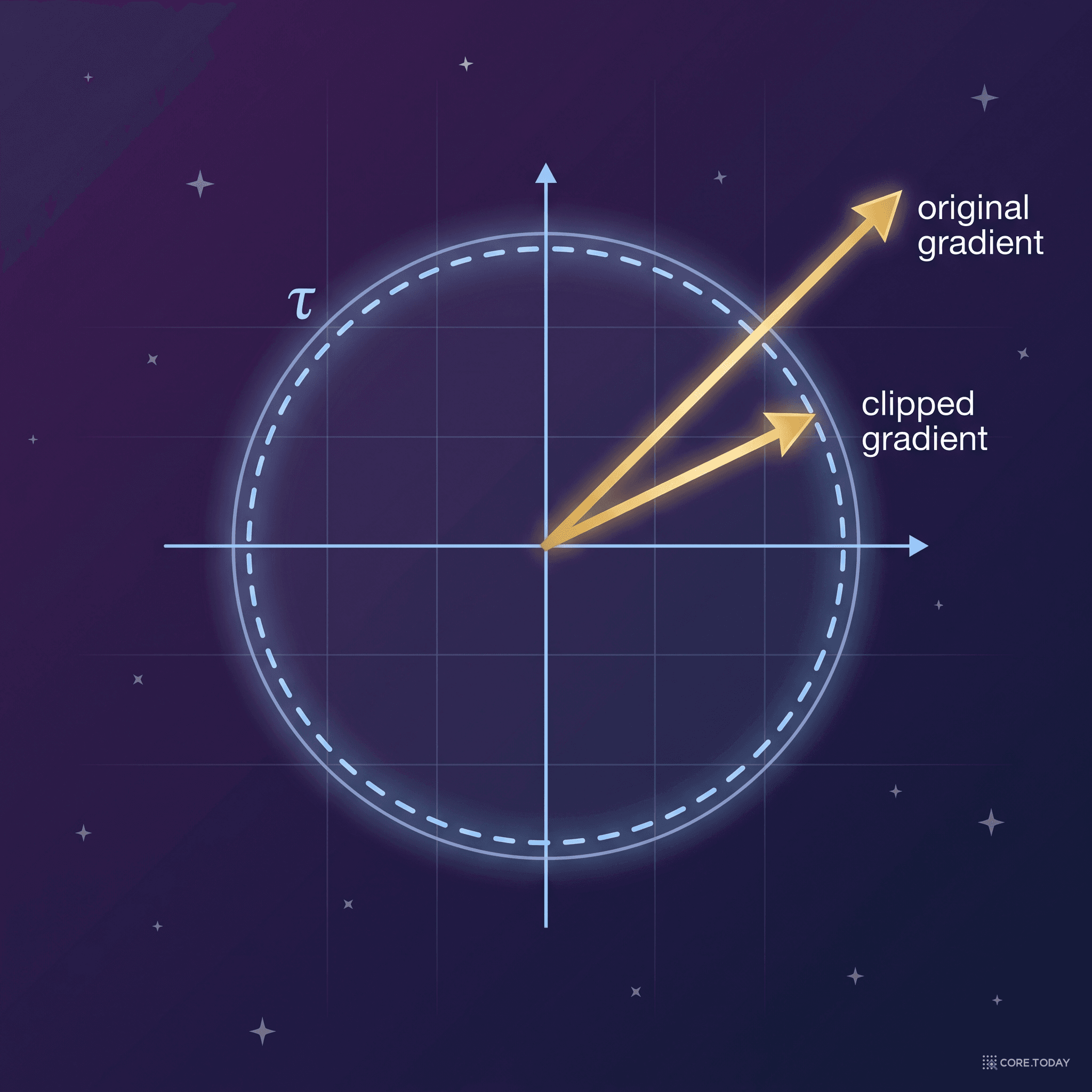
전체 기울기 벡터의 L2 노름을 계산하고, 임계값 τ를 초과하면 기울기 방향은 유지하면서 크기만 줄인다.
hljs language-python
global_norm = sqrt(sum(||g_i||^2 for all parameters))
if global_norm > tau:
for each g_i:
g_i = g_i * (tau / global_norm)
노름 클리핑의 동작
기울기 노름 ≤ τ
변경 없이 그대로 사용
기울기 노름 > τ
방향은 유지, 크기를 τ로 축소
핵심 장점: 기울기의 방향을 보존한다. 모든 파라미터의 기울기가 균일하게 스케일링되므로, 하강 방향이 왜곡되지 않는다.
방법 2: 기울기 값 클리핑 (Gradient Value Clipping)
각 기울기 원소를 독립적으로 [-τ, τ] 범위로 제한한다.
hljs language-python
for each element g in gradient:
g = max(-tau, min(tau, g))
단점: 각 차원이 독립적으로 잘리므로 기울기 방향이 왜곡될 수 있다. 실무에서는 노름 클리핑이 거의 항상 선호된다.
비교
| 항목 | 노름 클리핑 | 값 클리핑 |
|---|
| 기울기 방향 | 보존됨 | 왜곡될 수 있음 |
| 제약 형태 | 원형 (L2 ball) | 정사각형 (L∞ box) |
| 실무 추천 | 거의 항상 사용 | 특수한 경우에만 |
| 구현 | clip_grad_norm_ | clip_grad_value_ |

제4장: 실전 — 어떤 값을 쓰는가
대형 모델의 설정
주요 모델의 Gradient Clipping 임계값
패턴이 보이는가? 1.0이 사실상 표준이다. GPT-2, GPT-3, BERT, LLaMA 모두 글로벌 노름 클리핑 임계값 1.0을 사용한다.
GPT-3 논문(Brown et al., 2020)은 이를 "나쁜 배치에 대한 헤지(hedge against bad batches)"라고 표현했다. 간혹 나타나는 이상 배치가 훈련을 망치는 것을 방지한다.
임계값 가이드
| 임계값 | 용도 |
|---|
| 0.5 | 공격적. 깊은/순환 구조에 사용 |
| 1.0 | 표준값. 대부분의 Transformer/LLM 훈련 |
| 5.0~10.0 | 관대한 설정. 기울기가 자연스럽게 큰 구조 |
실전 팁
- 훈련 중 기울기 노름을 모니터링하라. TensorBoard, W&B에서 실시간 추적 가능.
- 기울기가 지속적으로 임계값에 도달하면, 학습률이 너무 높거나 모델 구조에 문제가 있을 수 있다.
- 기울기가 거의 클리핑되지 않으면, 임계값을 약간 낮춰도 된다 (더 안정적 훈련).
제5장: 코드로 보는 구현
PyTorch
hljs language-python
import torch
import torch.nn as nn
model = MyModel()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
for batch in dataloader:
loss = model(batch)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
optimizer.zero_grad()
순서가 중요하다: loss.backward() → clip_grad_norm_ → optimizer.step(). 기울기를 계산한 후, 파라미터를 업데이트하기 전에 클리핑한다.
TensorFlow
hljs language-python
import tensorflow as tf
optimizer = tf.keras.optimizers.Adam(
learning_rate=1e-4,
clipnorm=1.0
)
TensorFlow에서는 옵티마이저 생성 시 clipnorm 파라미터로 간단히 설정할 수 있다.
제6장: 대안과 보완 기법
Gradient Clipping은 기울기 문제를 해결하는 유일한 방법이 아니다. 다른 기법들과 함께 사용된다:
기울기 안정화 기법 계보
가중치 초기화
Xavier (2010) / He (2015)
초기화 시점에 기울기 분산을 유지. 예방적 접근.
정규화
BatchNorm (2015) / LayerNorm (2016)
활성화 분포를 정규화. 기울기 안정화 부수 효과.
잔차 연결
ResNet (2015)
기울기가 직접 흐르는 지름길. 152층+ 네트워크 가능하게 함.
Gradient Clipping
Pascanu et al. (2013)
훈련 중 기울기 크기를 직접 제한. 최후의 안전장치.
관계 정리
| 기법 | 시점 | 작동 방식 | Gradient Clipping과의 관계 |
|---|
| Xavier/He 초기화 | 훈련 전 | 가중치 분산 조절 | 예방 vs 치료 |
| BatchNorm/LayerNorm | 순전파 중 | 활성화 정규화 | 보완적 |
| 잔차 연결 | 순전파/역전파 중 | 기울기 직통 경로 | 보완적 |
| Gradient Clipping | 역전파 후 | 기울기 크기 직접 제한 | 최후의 안전벨트 |
현대 LLM 훈련에서는 이 모든 기법이 동시에 사용된다: He 초기화 + LayerNorm + 잔차 연결 + Gradient Clipping(1.0).
제7장: 적응형 Gradient Clipping — 2021년 이후의 진화
AGC (Adaptive Gradient Clipping, 2021)
DeepMind의 Andrew Brock 등이 NFNet 논문에서 제안한 적응형 기울기 클리핑:
기존: 전체 기울기에 고정된 임계값 적용
AGC: 각 층의 기울기를 해당 층의 가중치 크기에 비례하여 클리핑
기울기/가중치 비율이 λ를 초과하면 클리핑:
||G||/||W|| > λ → G를 스케일 다운
핵심 통찰: 기울기 한 스텝이 원래 가중치를 얼마나 변화시키는가를 기준으로 삼는다. 큰 가중치는 큰 기울기를 허용하고, 작은 가중치는 작은 기울기만 허용한다.
AGC 덕분에 Batch Normalization 없이도 깊은 네트워크를 훈련할 수 있게 되었다. ImageNet에서 86.5% top-1 정확도 달성.
AdaGC (2025) — LLM 시대의 적응형 클리핑
2025년 발표된 AdaGC는 텐서별 적응형 클리핑을 도입했다. 각 파라미터 텐서의 기울기 노름 이동 평균(EMA)을 추적하고, 개별적으로 임계값을 조정한다.
LLaMA-2 7B에서 손실 스파이크를 완전히 제거하고, 다운스트림 정확도 1.32% 향상, WikiText 퍼플렉시티 3.5% 감소를 달성했다.
제8장: 왜 Gradient Clipping은 수학적으로 빠른가
2020년 ICLR에서 Zhang 등이 발표한 논문 "Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity"는 직관을 넘어선 이론적 증명을 제공했다.
핵심 발견:
신경망의 기울기 매끄러움(smoothness)은 상수가 아니다 — 기울기 노름에 비례해 커질 수 있다.
이 완화된 매끄러움 가정 하에서, Gradient Clipping은 고정 학습률의 일반 경사 하강법보다 임의로 빠르게 수렴할 수 있다.
Gradient Clipping은 암묵적 적응 방법(implicit adaptive method)이다 — 지역 곡률에 따라 유효 학습률을 자동 조정한다. 곡률이 높은 곳(절벽)에서는 작은 스텝을, 평탄한 곳에서는 정상 스텝을 밟는다.
맺으며: 딥러닝의 안전벨트
Gradient Clipping의 역사는 딥러닝의 핵심 과제를 반영한다:
1991년, Hochreiter가 기울기 소실/폭발을 발견했다. 1997년, LSTM이 소실을 해결했다. 2013년, Pascanu 등이 폭발에 대한 우아한 해법을 정립했다. 2021년, AGC가 적응형으로 진화했다.
그리고 2025년 현재, 모든 대형 모델의 훈련 코드에 max_norm=1.0이 들어 있다. 이것은 우연이 아니다 — 30년간의 연구가 만든 결론이다.
Gradient Clipping은 자동차의 안전벨트와 같다. 평소에는 느껴지지 않지만, 위기 순간에 모든 것을 구한다.

hljs language-python
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
참고 자료
- Hochreiter, "Untersuchungen zu dynamischen neuronalen Netzen" (Diploma thesis, TU Munich, 1991)
- Bengio, Simard, Frasconi, "Learning Long-Term Dependencies with Gradient Descent Is Difficult" (IEEE TNN, 1994)
- Hochreiter & Schmidhuber, "Long Short-Term Memory" (Neural Computation, 1997)
- Mikolov, "Statistical Language Models Based on Neural Networks" (PhD thesis, Brno UT, 2012)
- Pascanu, Mikolov, Bengio, "On the Difficulty of Training Recurrent Neural Networks" (ICML 2013)
- Brock et al., "High-Performance Large-Scale Image Recognition Without Normalization" (ICML 2021)
- Zhang et al., "Why Gradient Clipping Accelerates Training" (ICLR 2020)
- AdaGC: Improving Training Stability for LLM Pretraining (arXiv 2502.11034, 2025)
- Brown et al., "Language Models are Few-Shot Learners" (GPT-3, NeurIPS 2020)
- Touvron et al., "LLaMA: Open and Efficient Foundation Language Models" (2023)




