블로그로 돌아가기
APINNPINN도메인 분해딥러닝시뮬레이션편미분방정식과학 AI
어려운 문제는 쪼개서 푼다 — Augmented PINN(APINN)의 모든 것
PINN이 복잡한 문제 앞에서 좌절할 때, 수학자들은 수백 년 된 전략을 꺼내들었다 — '나눠서 정복하라.' 도메인 분해와 신경망을 결합한 APINN이 왜, 어떻게 PINN의 한계를 돌파하는지를 쉽고 깊게 풀어본다.
코어닷투데이2026-01-1849분
PINN이 복잡한 문제 앞에서 좌절할 때, 수학자들은 수백 년 된 전략을 꺼내들었다 — '나눠서 정복하라.' 도메인 분해와 신경망을 결합한 APINN이 왜, 어떻게 PINN의 한계를 돌파하는지를 쉽고 깊게 풀어본다.
PINN(Physics-Informed Neural Networks)은 혁명적 아이디어였다. 신경망의 손실함수에 물리법칙을 녹여 넣어, 데이터가 부족해도 편미분방정식(PDE)의 해를 구할 수 있게 만든 것이다.
하지만 현실 세계의 문제에 PINN을 적용하기 시작하자, 예상치 못한 벽에 부딪혔다.
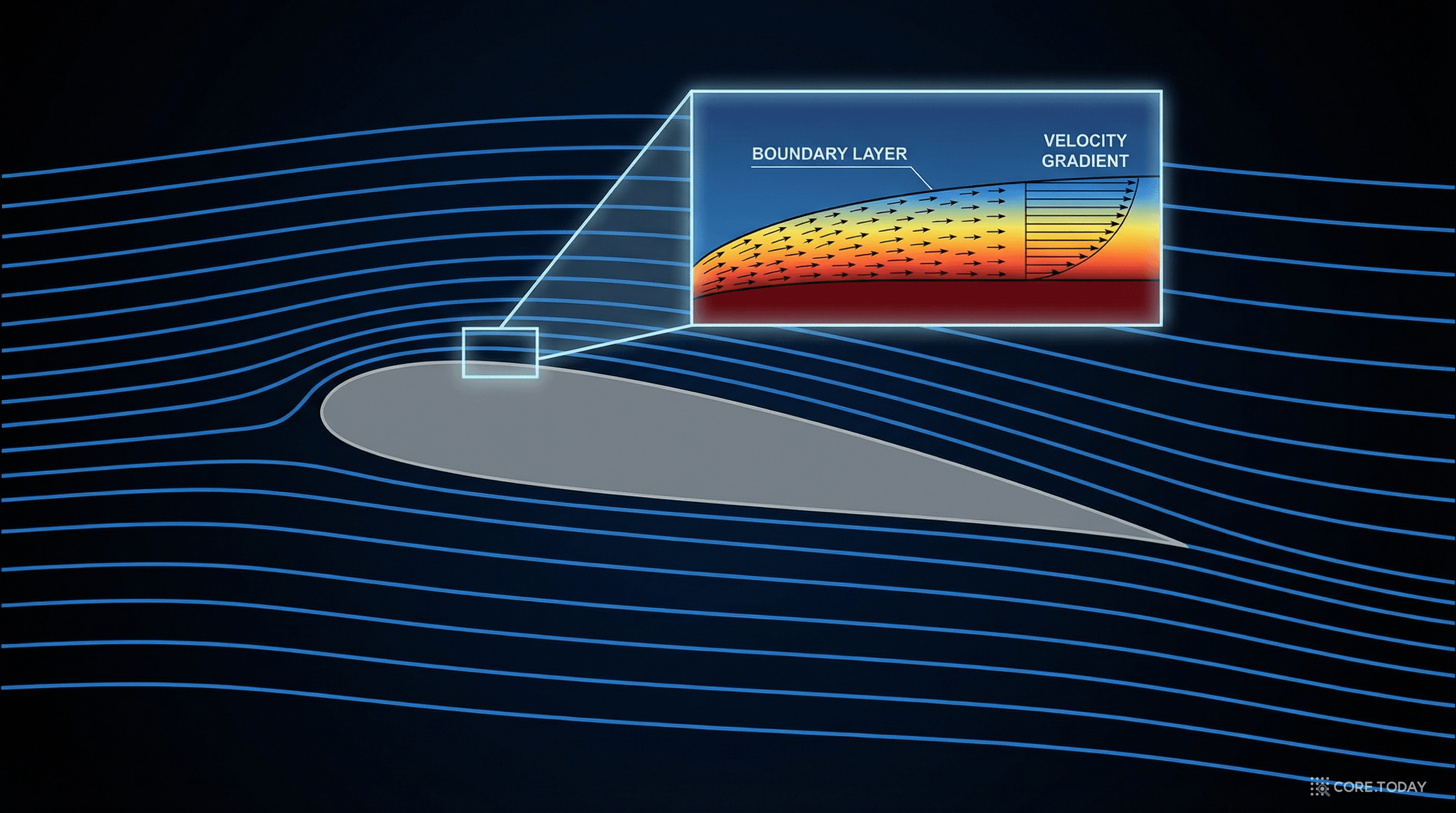
항공기 날개 주변의 유동을 생각해 보자. 날개 표면 바로 근처에는 두께 수 밀리미터의 경계층(boundary layer) 이 있다. 이 안에서 속도는 0에서 수백 m/s로 급격히 변한다. 동시에 날개로부터 수 미터 떨어진 곳에서는 유동이 매우 완만하게 변한다.
하나의 신경망으로 이 두 영역을 동시에 학습해야 한다. 경계층의 급격한 변화를 잡으려면 네트워크가 복잡해져야 하고, 바깥 영역의 완만한 변화를 잡으려면 과적합을 피해야 한다. 상충하는 요구가 하나의 네트워크에 몰린다.
결과는? PINN이 수렴하지 않거나, 수렴하더라도 정확도가 떨어진다.
이 문제는 PINN 고유의 것이 아니었다. 사실 수치해석의 역사에서 이 문제는 수십 년 전에 이미 해결된 것이었다. 해결책의 이름은:
도메인 분해(Domain Decomposition) — 어려운 문제는 쪼개서 푼다.
그리고 이 고전적 전략을 PINN에 체계적으로 결합한 것이 바로 APINN(Augmented Physics-Informed Neural Network) 이다.
"Divide et impera(나눠서 정복하라)"는 로마 제국의 통치 원리였다. 수학에서도 이 원리는 가장 강력한 문제 해결 전략 중 하나다.
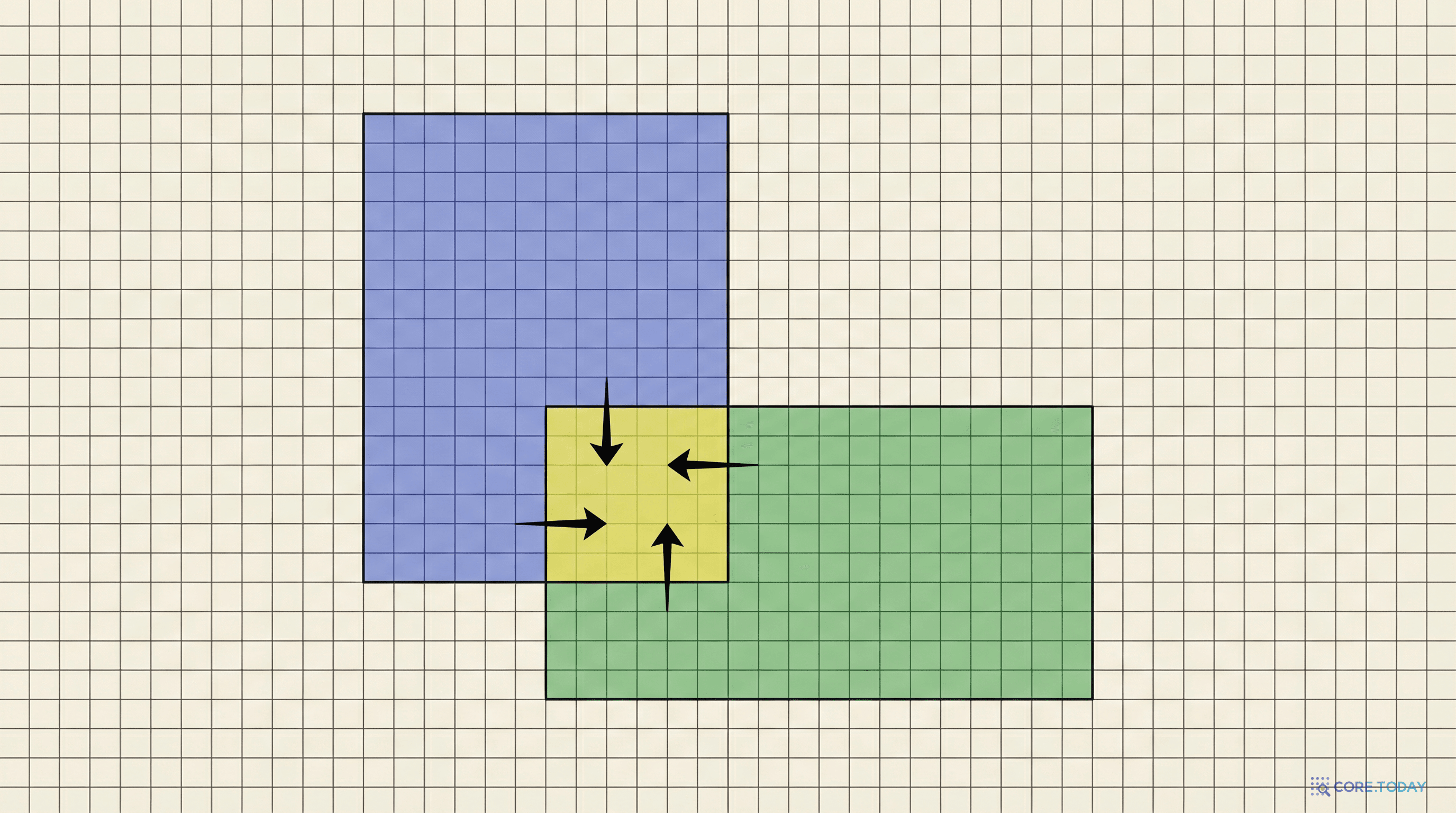
1870년, 독일의 수학자 헤르만 아마데우스 슈바르츠(Hermann Amandus Schwarz) 는 라플라스 방정식을 L자형 영역에서 풀어야 하는 문제에 직면했다. 당시의 해석 기법은 직사각형이나 원 같은 단순한 형상에서만 작동했다. L자형은 풀 수 없었다.
슈바르츠의 아이디어는 우아했다:
L자형 영역을 두 개의 겹치는 직사각형으로 나눈다. 각각을 따로 풀되, 겹치는 영역에서 서로의 해를 경계조건으로 교환하며 반복한다.
이것이 슈바르츠 교대법(Schwarz Alternating Method) 이다. 156년이 지난 지금까지도 수치해석의 핵심 알고리즘으로 사용되고 있다.
슈바르츠 이후 도메인 분해법은 크게 두 갈래로 발전했다.
겹침 방법(Overlapping Methods) — 슈바르츠 계열: 부분 영역들이 서로 겹친다. 겹치는 영역에서 해를 교환하며 반복 수렴한다. 구현이 직관적이고 수렴이 안정적이다.
비겹침 방법(Non-Overlapping Methods): 부분 영역들이 겹치지 않고 경계(인터페이스)에서만 정보를 교환한다. 대표적인 것이 FETI(Finite Element Tearing and Interconnecting) 와 BDD(Balancing Domain Decomposition) 방법이다.
이 두 전략 모두 하나의 핵심 원리를 공유한다:
큰 문제를 작은 문제들로 나누면, 각각은 쉬워지고, 전체는 병렬로 풀 수 있다.
이것이 바로 APINN이 물려받은 유산이다.
일반 PINN의 고질적 문제를 정리하면:
1. 다중 스케일 문제: 경계층처럼 급격한 변화와 완만한 변화가 공존하면, 하나의 신경망이 모든 스케일을 동시에 포착하기 어렵다.
2. 복잡한 기하학: L자형, 다공체, 분기 관로처럼 복잡한 도메인에서 하나의 네트워크로 전체를 근사하면 효율이 떨어진다.
3. 손실 함수 경쟁: 도메인이 넓으면 콜로케이션 포인트가 분산되고, 물리 손실·경계 손실·데이터 손실 간의 균형이 깨진다.
4. 확장성: 문제의 크기가 커지면 단일 PINN의 학습이 기하급수적으로 어려워진다. GPU 메모리에도 한계가 있다.
도메인 분해는 이 모든 문제에 대한 자연스러운 처방이다.
PINN에 도메인 분해를 적용한 첫 번째 체계적 시도는 2020년, Brown University의 Ameya Jagtap과 George Em Karniadakis가 발표한 XPINN(Extended PINN) 이다.
"Extended Physics-Informed Neural Networks (XPINNs): A Generalized Space-Time Domain Decomposition Based Deep Learning Framework for Nonlinear Partial Differential Equations" — Jagtap & Karniadakis (2020), Communications in Computational Physics
XPINN의 아이디어는 직관적이다:
XPINN은 PINN의 확장성 문제를 해결하는 데 중요한 첫걸음이었다. 하지만 이론적 한계가 있었다:
바로 이 지점에서 APINN이 등장한다.
"Augmented Physics-Informed Neural Networks (APINNs): A Naïve Least-Squares Solver for Elliptic PDEs" — Shang et al. (2023), 그리고 관련 후속 연구들
APINN의 핵심 차별점은 "증강(Augmented)" 이라는 이름에 담겨 있다. 단순히 도메인을 나누고 패널티를 주는 것이 아니라, 증강 라그랑지안(Augmented Lagrangian) 이라는 최적화 프레임워크를 통해 도메인 분해를 수학적으로 엄밀하게 수행한다.
쉽게 말하면:
이 차이가 왜 중요한지를 이해하려면, 증강 라그랑지안의 핵심 아이디어를 알아야 한다.
어떤 함수 를 최소화하되, 제약조건 을 만족해야 하는 문제를 생각하자.
전략 1: 패널티 방법 (Penalty Method)
제약 위반에 벌점을 준다. 단순하지만, 를 충분히 크게 해야 제약이 만족된다. 가 커지면 최적화가 나빠진다 (조건수 악화). 딜레마가 존재한다.
비유: 교통 위반에 벌금을 매기는 것. 벌금이 낮으면 무시하고, 높이면 사람들이 과잉 반응한다.
전략 2: 라그랑주 승수법 (Lagrange Multiplier)
라그랑주 승수 가 제약을 "가격"으로 반영한다. 이론적으로 깔끔하지만, 안장점 문제(saddle point problem) 가 되어 최적화가 불안정할 수 있다.
전략 3: 증강 라그랑지안 (Augmented Lagrangian)
라그랑주 승수법과 패널티 방법의 장점만 결합한다. 가 제약을 정확히 강제하므로 를 극단적으로 키울 필요가 없고, 패널티 항이 수렴 속도를 높여준다.
비유: 교통 위반에 벌금(패널티)도 매기면서 동시에 신호 시스템(승수)도 운영한다. 두 메커니즘이 협력하므로 벌금을 과도하게 높이지 않아도 교통이 원활해진다.
APINN은 이 증강 라그랑지안을 도메인 분해의 인터페이스 조건 강제에 적용한다.
전체 도메인 를 부분 영역 로 나누면, 인접한 영역 와 의 경계면 에서 다음을 만족해야 한다:
APINN의 전체 손실함수는:
여기서:
APINN의 학습은 ADMM(Alternating Direction Method of Multipliers) 패턴을 따른다. ADMM은 증강 라그랑지안 문제를 풀기 위한 표준 알고리즘이다.
핵심 통찰: STEP 1에서 각 부분 영역의 PINN은 독립적으로, 병렬로 학습할 수 있다. 통신은 STEP 2–3의 인터페이스 교환에서만 발생한다. 이것이 APINN의 병렬 확장성의 원천이다.
라그랑주 승수 의 갱신이 특히 중요하다. 는 이전 반복에서의 인터페이스 불일치를 누적 기억한다. 패널티 방법이 "현재의 위반"만 보는 것과 달리, 증강 라그랑지안은 과거의 위반 이력까지 반영해 점점 더 강하게 제약을 강제한다. 이것이 를 극단적으로 키우지 않아도 수렴하는 이유다.
세 방법의 차이를 명확히 정리하자.
구체적으로:
XPINN:
, 는 사용자가 미리 설정하는 하이퍼파라미터다. 값이 작으면 경계면이 불연속이 되고, 크면 최적화가 나빠진다. 문제마다 튜닝이 필요하다.
APINN:
는 학습 중에 자동으로 갱신된다. 도 필요하지만 그 값에 대한 민감도가 훨씬 낮다. 라그랑주 승수가 "자동 조절 나사" 역할을 하기 때문이다.
Wang et al. (2022)의 NTK(Neural Tangent Kernel) 분석에 따르면, PINN의 다중 손실 항은 학습 속도가 다른 경쟁하는 그래디언트를 만든다. 패널티 방법은 이 경쟁을 악화시킬 수 있다.
증강 라그랑지안은 이 문제를 구조적으로 완화한다. 라그랑주 승수가 그래디언트의 방향을 조정해, 물리 손실과 인터페이스 손실이 협력하는 방향으로 학습을 유도한다.
16세기 이탈리아의 프레스코 화가들은 거대한 천장화를 그릴 때, 전체를 한꺼번에 그리지 않았다. 벽을 작은 구역으로 나누고, 각 구역에 젖은 회반죽을 바른 뒤 마르기 전에 그림을 완성했다(프레스코는 "신선한"이라는 뜻이다).
핵심은 구역 경계에서 그림이 자연스럽게 이어지도록 하는 것이었다. 색조, 원근법, 인물의 포즈가 경계에서 끊기면 안 된다.
APINN은 정확히 같은 일을 한다:
10명이 하나의 보고서를 동시에 쓰면 혼란스럽다. 하지만 보고서를 10개 장(chapter)으로 나누고, 각자 한 장씩 쓰되, 장과 장의 연결 부분에서 내용이 일관되도록 편집장이 조율하면 훨씬 효율적이다.
2D 평판의 정상 상태 열전도를 생각하자. 왼쪽은 100°C, 오른쪽은 0°C.
PINN 접근: 하나의 신경망이 전체 영역의 온도 분포를 학습한다.
APINN 접근: 영역을 4등분한다.
각 PINN은 자신의 영역에만 집중하면 되므로 네트워크 크기가 작아도 충분하다. 전체 파라미터 수가 같다면, 큰 네트워크 하나보다 작은 네트워크 여럿이 각 영역의 특성에 더 잘 적응한다.
문제: 대류-확산 방정식에서 확산 계수가 매우 작으면(), 해에 날카로운 경계층이 형성된다. 경계 근처에서 해가 급격히 변하고, 내부에서는 완만하다. 일반 PINN은 이 급격한 전이를 포착하지 못해 진동하거나 수렴에 실패한다.
APINN 적용: 도메인을 경계층 영역과 내부 영역으로 분리한다. 경계층 영역의 PINN은 작지만 깊은 네트워크로 급격한 변화에 특화시키고, 내부 영역의 PINN은 얕지만 넓은 네트워크로 완만한 패턴을 학습한다.
결과: PINN 대비 경계층 영역의 오차가 10배 이상 감소하면서, 전체 학습 시간도 단축됐다. 각 네트워크가 자신의 스케일에만 집중할 수 있기 때문이다.
문제: L자형 도메인에서 라플라스 방정식을 풀면, 내부 모서리(re-entrant corner)에서 특이점(singularity) 이 발생한다. 해의 기울기가 무한대로 발산하는 지점이다. 단일 PINN으로는 이 특이점을 정확히 포착하면서 나머지 영역도 잘 근사하기가 극히 어렵다.
APINN 적용: 특이점 주변을 별도의 부분 영역으로 분리하고, 해당 영역의 PINN에 특이점의 수학적 형태( 같은)를 사전 지식으로 내장한다. 나머지 영역의 PINN은 매끄러운 해만 학습하면 된다.
이것은 슈바르츠가 156년 전에 풀려고 했던 바로 그 문제다. APINN은 슈바르츠의 전략을 신경망 시대에 되살린 것이다.
문제: 버거스 방정식처럼 시간에 따라 해가 급격히 변하는 문제에서, 긴 시간 구간을 한꺼번에 학습하면 PINN이 초기 시간대는 잘 맞추지만 후기 시간대에서 정확도가 떨어진다.
APINN 적용: 시간축을 여러 구간으로 나눈다. 각 시간 구간에 별도의 PINN을 배치하고, 구간 경계에서 해의 연속성을 증강 라그랑지안으로 강제한다.
각 PINN이 짧은 시간 구간에만 집중하므로, 장기 시간 적분의 오차 누적 문제가 크게 완화된다. 이는 수치해석에서 시간 분할(time-splitting) 기법의 신경망 버전이다.
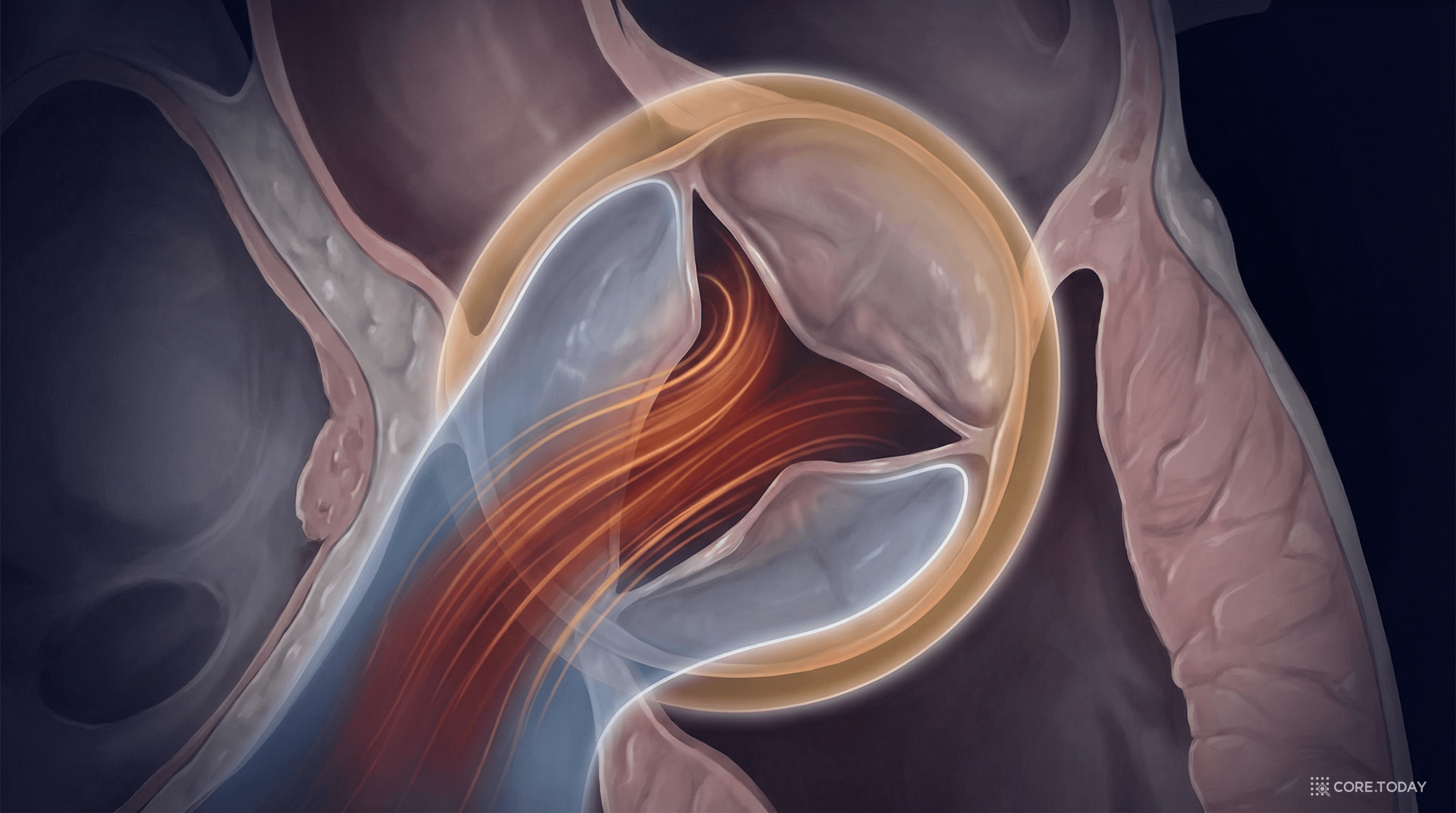
문제: 심장 판막 주변의 혈류를 모델링하려면, 유체(혈액)의 나비에-스토크스 방정식과 고체(판막)의 탄성 방정식을 동시에 풀어야 한다. 두 물리 시스템은 서로 다른 지배 방정식을 따르면서, 경계면에서 상호작용한다.
APINN 적용: 유체 영역과 고체 영역을 각각 별도의 PINN으로 모델링하고, 유체-구조 경계면에서의 결합 조건(속도 연속, 응력 균형)을 증강 라그랑지안으로 강제한다. 각 PINN은 자신의 물리에만 특화된다.
이것이 도메인 분해의 근본적 장점이다: 서로 다른 물리가 지배하는 영역을 자연스럽게 분리할 수 있다.
문제: 다자산(multi-asset) 옵션의 가격은 고차원 블랙-숄즈 PDE로 결정된다. 자산 수가 10개면 10차원 PDE다. 차원의 저주(curse of dimensionality)로 전통적 격자 기반 방법은 불가능하다.
APINN 적용: 고차원 도메인을 가격 영역별로 분할하고, 각 영역에 특화된 PINN을 배치한다. 특히 행사가(strike price) 근처처럼 해의 변화가 급격한 ATM(at-the-money) 영역과 변화가 완만한 ITM/OTM 영역을 분리하면, 각 네트워크의 부담이 크게 줄어든다.
문제: 방사성 폐기물 처분장의 안전성 평가를 위해, 지하 수십 킬로미터 규모의 지하수 유동을 수만 년 시간 스케일로 시뮬레이션해야 한다. 단일 시뮬레이션의 규모가 막대하다.
APINN 적용: 공간을 지질학적 층(layer)별로 분해하고, 각 층의 물리적 특성(투과율, 공극률)에 맞는 전문 PINN을 배치한다. 층 경계면에서의 압력·유량 연속성을 증강 라그랑지안으로 강제한다. 각 층을 다른 GPU에서 병렬로 학습할 수 있어 확장성이 좋다.
1. 수학적 수렴 보장: 증강 라그랑지안 + ADMM 조합은 볼록(convex) 최적화에서 수렴이 증명되어 있다. PDE 문제는 일반적으로 비볼록이지만, 실험적으로 패널티 방법 대비 훨씬 안정적인 수렴을 보인다.
2. 하이퍼파라미터 민감도 감소: 라그랑주 승수가 자동 조절되므로, 패널티 가중치를 수동으로 세밀하게 튜닝할 필요가 줄어든다.
3. 완전 병렬화: 각 부분 영역의 PINN을 독립 GPU에서 학습할 수 있다. 통신은 인터페이스 교환 단계에서만 발생한다.
4. 이질적 네트워크 아키텍처: 각 부분 영역에 다른 크기, 깊이, 활성화 함수의 네트워크를 배치할 수 있다. 경계층에는 깊은 네트워크, 매끄러운 영역에는 얕은 네트워크를 두는 것이 가능하다.
5. 다중 물리 자연 지원: 서로 다른 지배 방정식이 적용되는 영역을 자연스럽게 분리한다. 유체-구조, 열-구조, 전자기-열 결합 문제에 적합하다.
1. 외부 루프의 비용: ADMM 외부 루프가 수렴하려면 여러 번의 반복이 필요하다. 반복마다 각 부분 영역의 PINN을 (부분적으로) 재학습해야 하므로, 단순한 문제에서는 PINN 대비 오히려 비효율적일 수 있다.
2. 분해 전략의 선택: 도메인을 어떻게 나눌지(부분 영역의 수, 형상, 겹침 여부)가 성능에 큰 영향을 미친다. 이 선택은 아직 대부분 사용자의 물리적 직관에 의존한다.
3. 비정상(transient) 문제의 복잡성: 시공간 분해는 시간 방향의 인터페이스 조건이 추가되어 구현이 복잡해진다.
4. 비볼록 문제에서의 이론적 갭: 증강 라그랑지안의 수렴 이론은 볼록 문제에 대해 엄밀하지만, 신경망 학습은 비볼록이다. 실질적으로는 잘 작동하지만, 이론적 보장에는 아직 간극이 있다.
APINN은 "도메인 분해 + 신경망"이라는 큰 흐름의 일부다. 관련 기법들을 함께 조망하자.
Jagtap et al. (2020)이 제안. 보존 법칙의 적분형(integral form)을 활용해, 인접 영역 간의 보존적 플럭스 교환을 강제한다. XPINN이 해의 값 연속성에 초점을 맞췄다면, cPINN은 물리적 보존량의 일관성에 초점을 맞춘다.
Moseley et al. (2023)이 제안. 각 부분 영역의 PINN 출력에 파티션 오브 유니티(Partition of Unity) 가중 함수를 곱해 전체 해를 조합한다. 인터페이스에서의 연속성이 구조적으로 보장되므로 별도의 인터페이스 손실이 불필요하다.
시간 방향의 도메인 분해를 특화한 접근법. 파라리얼(Parareal) 알고리즘의 PINN 버전으로, 긴 시간 구간을 병렬로 처리한다. APINN의 시간 분할이 이 아이디어와 직접 연결된다.
현재 도메인 분해 전략은 대부분 수동이다. 앞으로는 강화학습(RL) 이나 메타 학습(meta-learning) 으로 최적의 분해 전략을 자동으로 탐색하는 연구가 진행되고 있다. "이 PDE에는 어떻게 나누는 것이 최적인가?"를 AI가 결정하는 것이다.
FNO의 빠른 추론 속도와 APINN의 다중 스케일 처리 능력을 결합하는 시도가 있다. 각 부분 영역에 FNO를 배치하고, 인터페이스를 APINN의 증강 라그랑지안으로 연결하는 구조다. 이를 통해 대규모 문제를 빠르게, 그리고 정확하게 풀 수 있다.
대규모 디지털 트윈(발전소, 항공기, 도시 인프라)에서, 전체 시스템을 하나의 모델로 다루기는 불가능하다. APINN의 도메인 분해는 디지털 트윈의 자연스러운 모듈화 전략이 된다. 엔진, 날개, 동체를 각각의 PINN 모듈로 모델링하고, 결합 조건을 증강 라그랑지안으로 관리하는 것이다.
APINN의 병렬 구조는 다중 GPU 환경에 자연스럽게 매핑된다. 부분 영역 수 = GPU 수로 설정하면, 각 GPU가 하나의 부분 영역을 전담한다. 인터페이스 통신은 GPU 간 텐서 교환으로 구현된다. 이는 전통적 도메인 분해의 MPI 병렬 패턴을 딥러닝 프레임워크에서 재현하는 것이다.
이 글을 마무리하기 전에, 지금까지 다룬 PINN 계열 기법들의 전체 지도를 그려보자.
각 기법은 하나의 질문에 답한다:
도메인 분해의 본질은 역설적이다. 문제를 쪼개면 각 조각이 더 쉬워지고, 쉬워진 조각들을 올바르게 연결하면 전체가 더 정확해진다.
슈바르츠가 1870년에 L자형 영역을 두 직사각형으로 나눴을 때, 그는 "나누는 것이 곧 정복하는 것"임을 수학적으로 증명했다. 156년 뒤, APINN은 같은 원리를 신경망 시대에 되살리며, PINN이 혼자서는 넘지 못했던 벽을 넘고 있다.
APINN이 전하는 메시지는 과학을 넘어선다:
어려운 문제는 쪼개서 풀고, 쪼갠 것은 엄밀하게 연결하라.
이것은 로마 제국의 통치 원리이자, 소프트웨어 공학의 모듈화 원칙이자, 팀워크의 기본이기도 하다. 그리고 이제, AI가 물리 세계를 이해하는 방식이기도 하다.