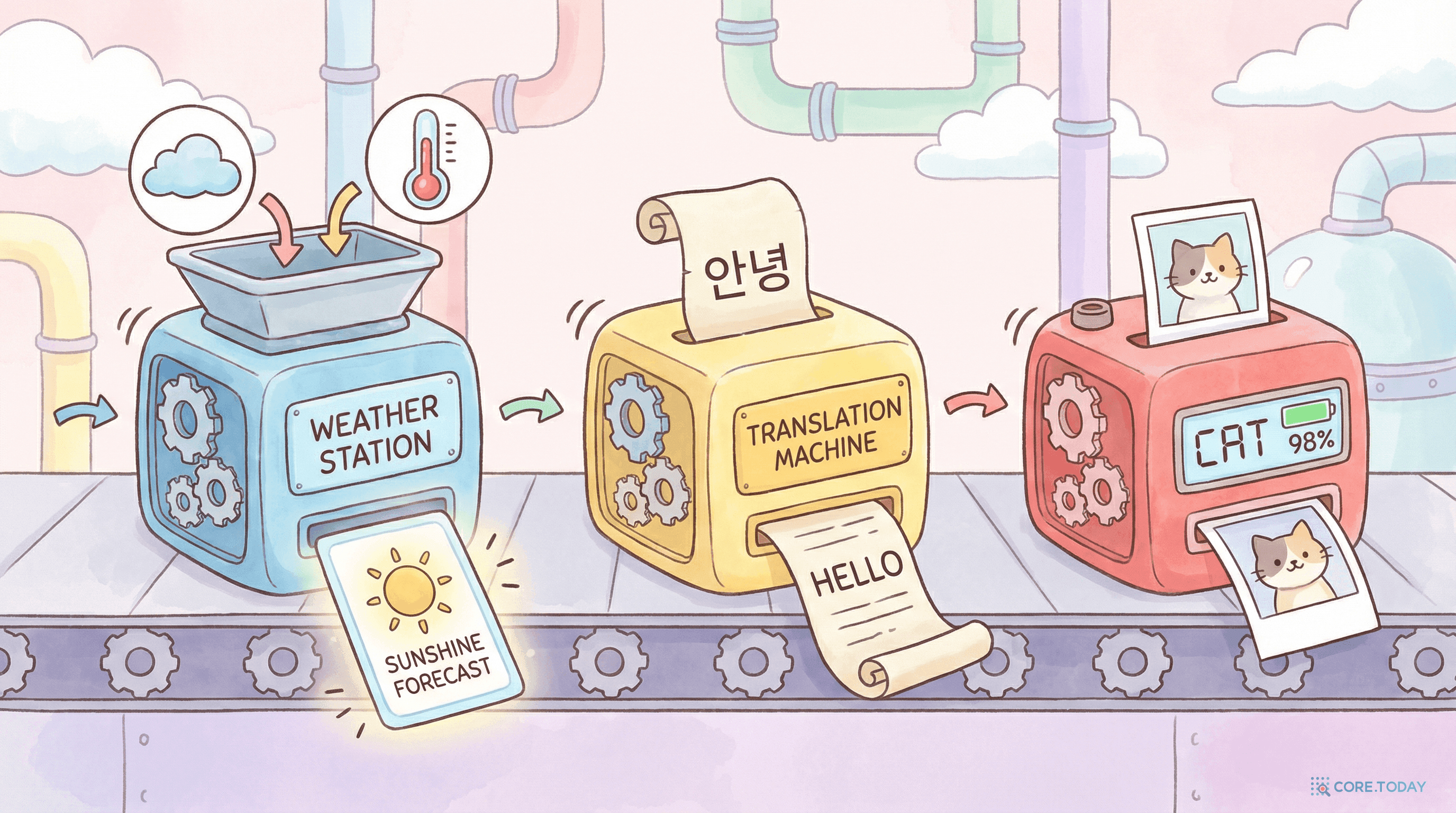
함수는 단순하다 — 입력을 받아 출력을 내놓는 규칙이다. 그런데 놀랍게도, 우리가 "지능적"이라고 부르는 거의 모든 행위가 함수다:
작업
입력
출력
함수의 복잡도
날씨 예측
기온, 습도, 기압, 풍향...
"내일 비 올 확률 80%"
매우 높음
번역
"오늘 날씨가 좋다"
"The weather is nice today"
매우 높음
이미지 인식
786,432개의 픽셀값
"고양이"
높음
주가 예측
과거 가격, 거래량, 뉴스...
"내일 종가 예측"
극도로 높음
ChatGPT
이전 토큰들의 시퀀스
다음 토큰의 확률 분포
상상을 초월
문제는 이 함수들이 명시적으로 쓸 수 없을 만큼 복잡하다는 것이다. "고양이를 인식하는 함수"를 수식으로 쓸 수 있는 사람은 없다. 786,432개 입력변수에 대한 조건문을 수십억 개 나열해야 할 것이다.
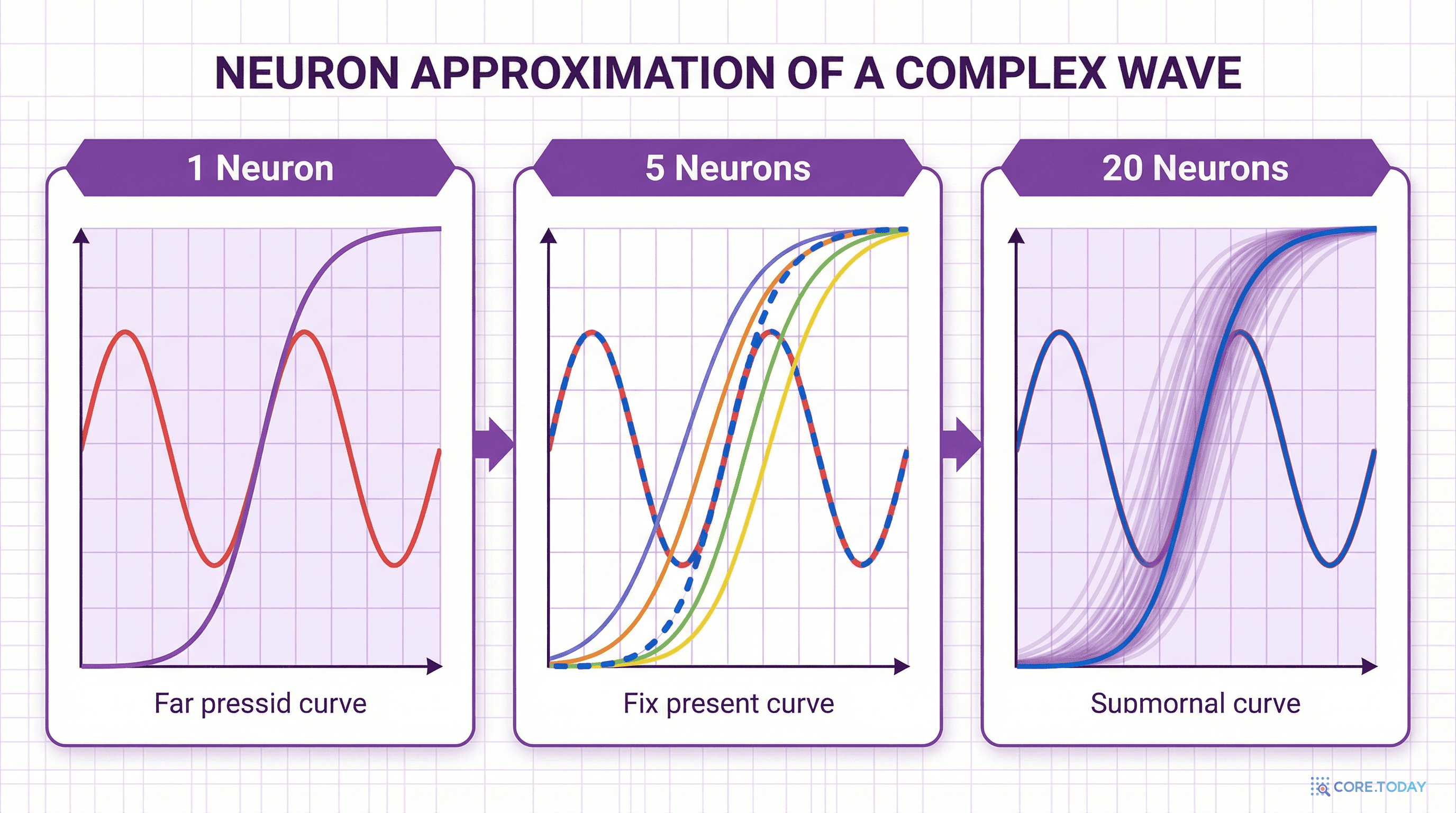
그래서 수학자들과 공학자들은 다른 전략을 택했다: 함수를 직접 쓰지 않고, 근사한다.
제2장: 함수를 근사하는 오래된 도구들
복잡한 함수를 단순한 조각들의 합으로 표현하려는 시도는 수학의 오랜 전통이다.
바이어슈트라스 근사 정리 (1885년)
독일 수학자 카를 바이어슈트라스(Karl Weierstrass) 가 1885년에 증명한 정리:
바이어슈트라스 근사 정리 (1885)
닫힌 구간 [a, b] 위의 어떤 연속 함수든, 다항식으로 균등하게(uniformly) 근사할 수 있다.
즉, 아무리 복잡한 연속 곡선이라도, 충분히 높은 차수의 다항식으로 원하는 만큼 가깝게 흉내 낼 수 있다.
이것은 "단순한 조각(다항식)을 충분히 많이 합치면 복잡한 것(임의의 연속 함수)을 만들 수 있다"는 최초의 수학적 보장이었다. UAT의 130년 선배인 셈이다.
테일러 급수와 푸리에 변환
테일러 급수(Taylor Series): 매끄러운 함수를 다항식의 무한 합으로 표현한다.
ex=1+x+2!x2+3!x3+⋯
푸리에 변환(Fourier Transform): 주기 함수를 사인/코사인의 합으로 분해한다.
f(x)=a0+∑n=1∞[ancos(nx)+bnsin(nx)]
둘 다 강력하지만 한계가 있다:
테일러: 함수가 무한 번 미분 가능해야 한다
푸리에: 주기 함수에 가장 적합하다
두 방법 모두: 근사의 "기본 도구"(다항식, 삼각함수)를 미리 정해놓고 계수만 조정한다
콜모고로프-아르놀드 표현 정리 (1957년)
소련 수학자 안드레이 콜모고로프(Andrey Kolmogorov) 가 1957년에 증명한 놀라운 결과:
어떤 연속 다변수 함수든, 유한 개의 연속 1변수 함수의 합성과 덧셈만으로 정확히 표현할 수 있다.
수학적으로 우아했지만, 내부 함수가 극도로 병적(pathological)이어서 실용적 계산에는 쓸 수 없었다. 그러나 이 정리는 "기본 함수를 조합하면 어떤 함수든 만들 수 있다"는 철학적 씨앗을 뿌렸다 — 67년 뒤인 2024년에 KAN(Kolmogorov-Arnold Networks)으로 부활하게 된다.
핵심 한계: "형태를 알아야 한다"
테일러, 푸리에, 다항식 — 이 모든 전통적 근사법에는 공통된 한계가 있다:
근사의 기본 형태를 사람이 미리 결정해야 한다. 다항식? 삼각함수? 어떤 기저 함수를 쓸 것인가? 이 선택이 잘못되면 아무리 계수를 조정해도 좋은 근사를 얻을 수 없다.
신경망은 이 한계를 넘어선다. 기저 함수 자체를 데이터로부터 학습한다. 이것이 혁명적인 차이다.
QLoRADettmers et al., 2023. 4비트 양자화 + LoRA. A100 1개로 65B 모델 파인튜닝
DoRALiu et al., 2024. 가중치를 방향과 크기로 분해. LoRA 대비 일관된 성능 향상
AdaLoRAZhang et al., 2023. 각 레이어의 랭크를 자동 조절. 파라미터 예산 최적 배분
LoRA+Hayou et al., 2024. A와 B 행렬에 다른 학습률 적용. 2배 빠른 수렴
실전 임팩트: AI 민주화
LoRA가 바꾼 현실:
비용: GPU 1대로 70B 모델 파인튜닝 (QLoRA)
속도: 수일 → 수시간
저장: 모델당 350GB → 35MB 어댑터
배포: 하나의 기본 모델 + 용도별 어댑터 교체
Hugging Face에 등록된 LoRA 어댑터만 10만 개 이상. 개인 개발자와 소규모 팀도 자신만의 맞춤 AI를 만들 수 있는 시대가 열렸다.
제9장: UAT 너머의 지평
KAN: 콜모고로프를 다시 생각하다 (2024)
67년 전 콜모고로프의 정리가 부활했다. Liu et al. (2024) 의 KAN(Kolmogorov-Arnold Networks)은 전통 MLP(Multi-Layer Perceptron)의 대안이다.
특성
MLP (전통)
KAN (2024)
학습 가능 요소
가중치 (숫자)
활성화 함수 자체 (스플라인)
이론적 기반
UAT (Cybenko, 1989)
Kolmogorov-Arnold (1957)
해석 가능성
블랙박스
함수 형태를 직접 관찰 가능
적합 분야
범용 (언어, 이미지)
과학 계산, 물리 시뮬레이션
KAN은 "뉴런의 가중치가 아니라 엣지의 활성화 함수를 학습한다"는 아이디어로, 특히 과학 분야에서 해석 가능한 모델을 만드는 데 주목받고 있다.
Mixture of Experts: 전체가 아닌 부분을 활성화
UAT는 "모든 뉴런이 항상 작동하는" 밀집 네트워크에 대한 정리다. Mixture of Experts(MoE)는 다른 접근을 취한다: 입력에 따라 전문가(expert)의 일부만 활성화한다.
Mixtral 8×7B는 총 46.7B 파라미터를 가지지만, 추론 시에는 12.9B만 사용한다. "필요한 부분만 쓴다"는 효율성이 핵심이다. MoE에 대한 이론적 근사 보장은 아직 활발한 연구 주제다.
Test-Time Compute: 추론 시간에 더 생각하기
최근의 새로운 트렌드: 모델 크기를 키우는 대신, 추론 시간에 더 많이 계산한다. OpenAI의 o1 시리즈, Anthropic의 Claude의 확장된 사고(extended thinking)가 이 접근이다.
이것은 UAT의 관점에서 흥미로운 전환이다:
기존: 더 큰 네트워크(더 많은 뉴런) = 더 나은 근사
새로운: 같은 네트워크 + 더 긴 추론 체인 = 더 나은 답변
"뉴런을 늘리는 대신 생각의 깊이를 늘린다"는 것은 UAT가 직접 다루지 않는 새로운 차원이다.
열린 질문들
아직 풀리지 않은 질문들
왜 일반화하는가?과파라미터화된 모델이 과적합하지 않는 이유에 대한 완전한 이론이 없다
창발은 예측 가능한가?스케일을 키우면 어떤 새 능력이 나타날지 사전에 알 수 없다
최적 아키텍처는?Transformer가 최선인지, 더 나은 구조가 있는지 불명확
표현의 기하학신경망이 학습한 표현의 내부 구조를 완전히 이해하지 못한다
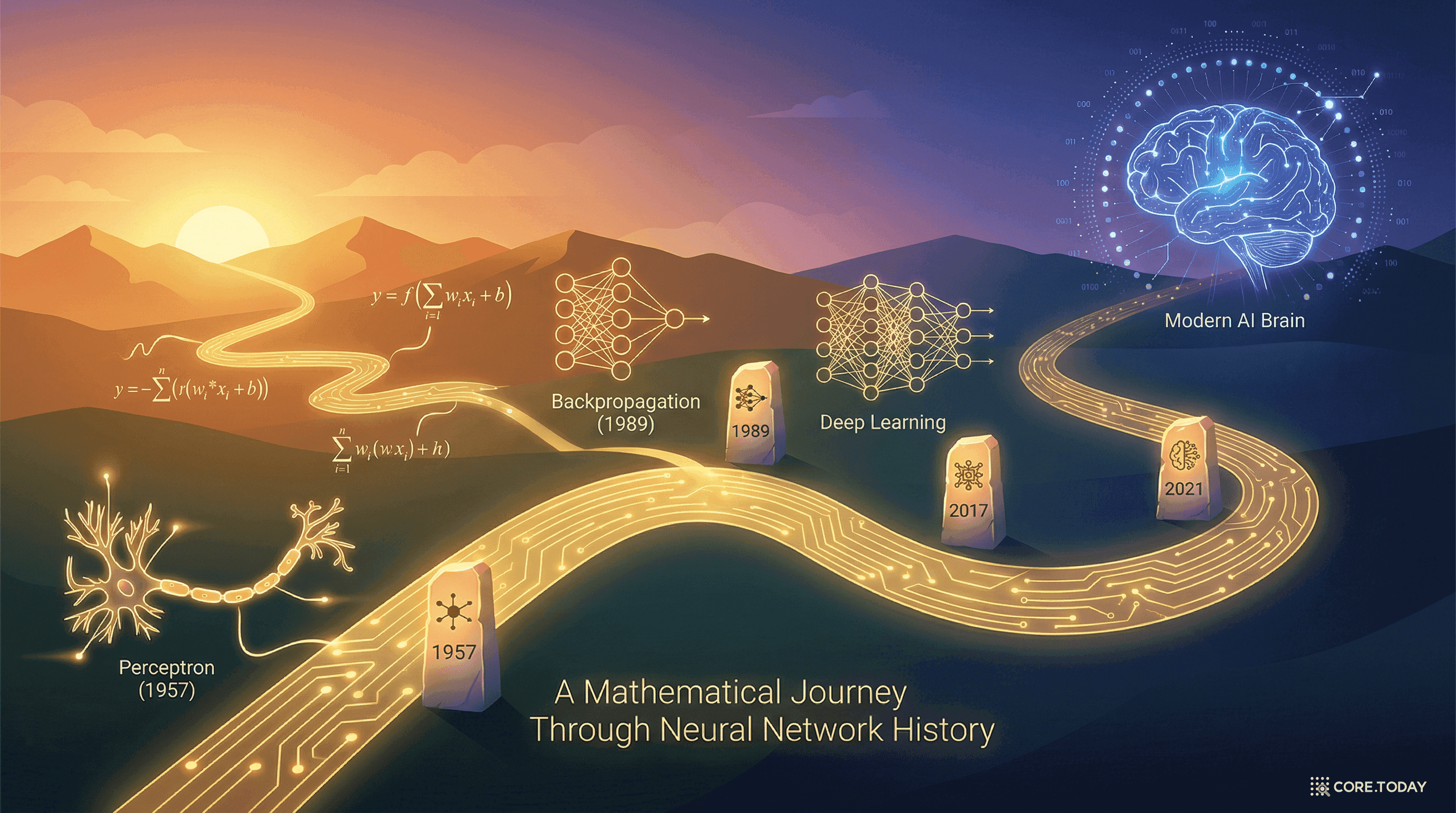
마무리: 수학이 연 문, 공학이 넓힌 길
이 글의 여정을 되돌아보자.
1885
바이어슈트라스가 증명: 다항식으로 연속 함수를 근사할 수 있다
1957
콜모고로프가 증명: 다변수 함수도 1변수 함수의 합성으로 표현 가능
1989
사이벤코, 호르닉이 증명: 신경망은 보편 근사기다 — 수학적 면허증 발급
2012
AlexNet이 입증: 깊은 네트워크 + GPU = 실전에서 작동한다
2017
Transformer 등장: Attention이라는 새로운 근사 도구
2020
스케일링 법칙: 더 크면 더 좋다 — 그리고 예측 가능하다
2021
LoRA: 거대 모델을 0.003%만 조정해서 맞춤화 — 효율적 근사의 혁명
바이어슈트라스에서 LoRA까지, 140년에 걸친 이 여정의 본질은 하나다:
복잡한 함수를 단순한 조각들의 조합으로 표현하되, 그 조합을 점점 더 효율적으로 찾아가는 것.
바이어슈트라스는 "다항식으로 할 수 있다"고 했고, 사이벤코는 "뉴런으로 할 수 있다"고 했고, 현대 딥러닝은 "깊이와 어텐션으로 효율적으로 할 수 있다"고 했고, LoRA는 "이미 좋은 근사를 찾았으면 약간만 고치면 된다"고 했다.
UAT는 이 여정의 출발점이자 나침반이다. "원리적으로 가능하다"는 보장이 있었기에 연구자들은 "어떻게 효율적으로 할 것인가"에 집중할 수 있었다.
그리고 그 여정은 아직 끝나지 않았다. KAN, MoE, Test-Time Compute — 새로운 도구와 패러다임이 계속 등장하고 있다. 하지만 그 모든 것의 수학적 기반에는, 1989년의 그 정리가 여전히 놓여 있다.
뉴런이 충분하면, 어떤 함수든 근사할 수 있다. 그리고 세상의 모든 것은 함수다.
참고 문헌
Weierstrass, K. (1885). "Über die analytische Darstellbarkeit sogenannter willkürlicher Functionen einer reellen Veränderlichen."
Kolmogorov, A. N. (1957). "On the representation of continuous functions of several variables by superpositions of continuous functions of fewer variables." Doklady Akademii Nauk.
Cybenko, G. (1989). "Approximation by Superpositions of a Sigmoidal Function." Mathematics of Control, Signals, and Systems.
Hornik, K., Stinchcombe, M., White, H. (1989). "Multilayer feedforward networks are universal approximators." Neural Networks.
Hornik, K. (1991). "Approximation capabilities of multilayer feedforward networks." Neural Networks.
Telgarsky, M. (2016). "Benefits of Depth in Neural Networks." COLT 2016.
Lu, Z., et al. (2017). "The Expressive Power of Neural Networks: A View from the Width." NeurIPS 2017.
Vaswani, A., et al. (2017). "Attention Is All You Need." NeurIPS 2017.
Belkin, M., et al. (2019). "Reconciling modern machine learning practice and the bias-variance trade-off." PNAS.
Kaplan, J., et al. (2020). "Scaling Laws for Neural Language Models." arXiv preprint.
Aghajanyan, A., Gupta, S., Zettlemoyer, L. (2020). "Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning." ACL 2021.
Hu, E. J., et al. (2021). "LoRA: Low-Rank Adaptation of Large Language Models." ICLR 2022.
Yun, C., et al. (2020). "Are Transformers universal approximators of sequence-to-sequence functions?" ICLR 2020.
Liu, Z., et al. (2024). "KAN: Kolmogorov-Arnold Networks." arXiv preprint.