하나의 모델, 여덟 가지 능력
문서 이해의 모든 것
3B 비전-언어 모델 하나로 레이아웃 분석, OCR, SVG 변환, 장면 인식까지 처리합니다.
문서 레이아웃
표, 수식, 그림 등 복잡한 레이아웃을 정확하게 감지하고 구조화된 JSON으로 출력합니다.
텍스트 추출
한국어, 영어, 중국어, 일본어 등 100개 이상 언어의 텍스트를 정확하게 인식합니다.
이미지 → SVG
차트, 다이어그램, 로고 등 구조화된 그래픽을 편집 가능한 SVG 벡터로 변환합니다.
장면 텍스트
간판, 포스터, 사진 속 자연 환경의 텍스트를 감지하고 인식합니다.
웹페이지 파싱
웹 스크린샷에서 UI 구성요소와 레이아웃 구조를 분석합니다.
Grounding OCR
특정 좌표 영역을 지정하여 해당 영역의 텍스트만 정밀하게 추출합니다.
레이아웃 검출
텍스트 인식 없이 문서의 구조적 요소 위치만 빠르게 감지합니다.
일반 질의응답
이미지에 대한 자유로운 질문에 AI가 답변합니다. 문서 요약, 분석 등.
Product Preview
실제 서비스 화면을 확인하세요
원본 문서와 파싱 결과를 나란히 비교하며 확인할 수 있습니다.


수식 파싱
학술 논문의 복잡한 수식을 LaTeX 코드로 정밀하게 변환합니다.
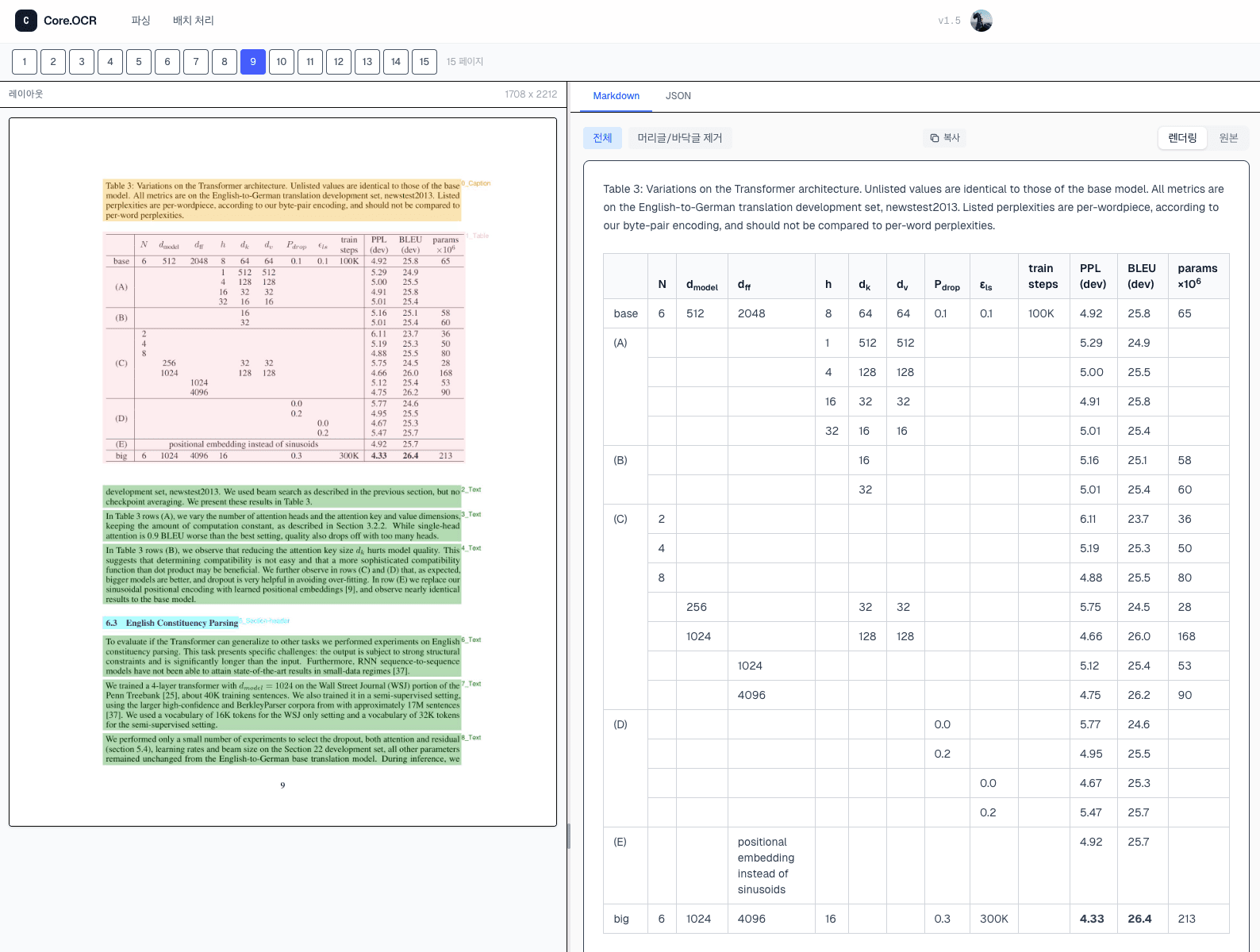
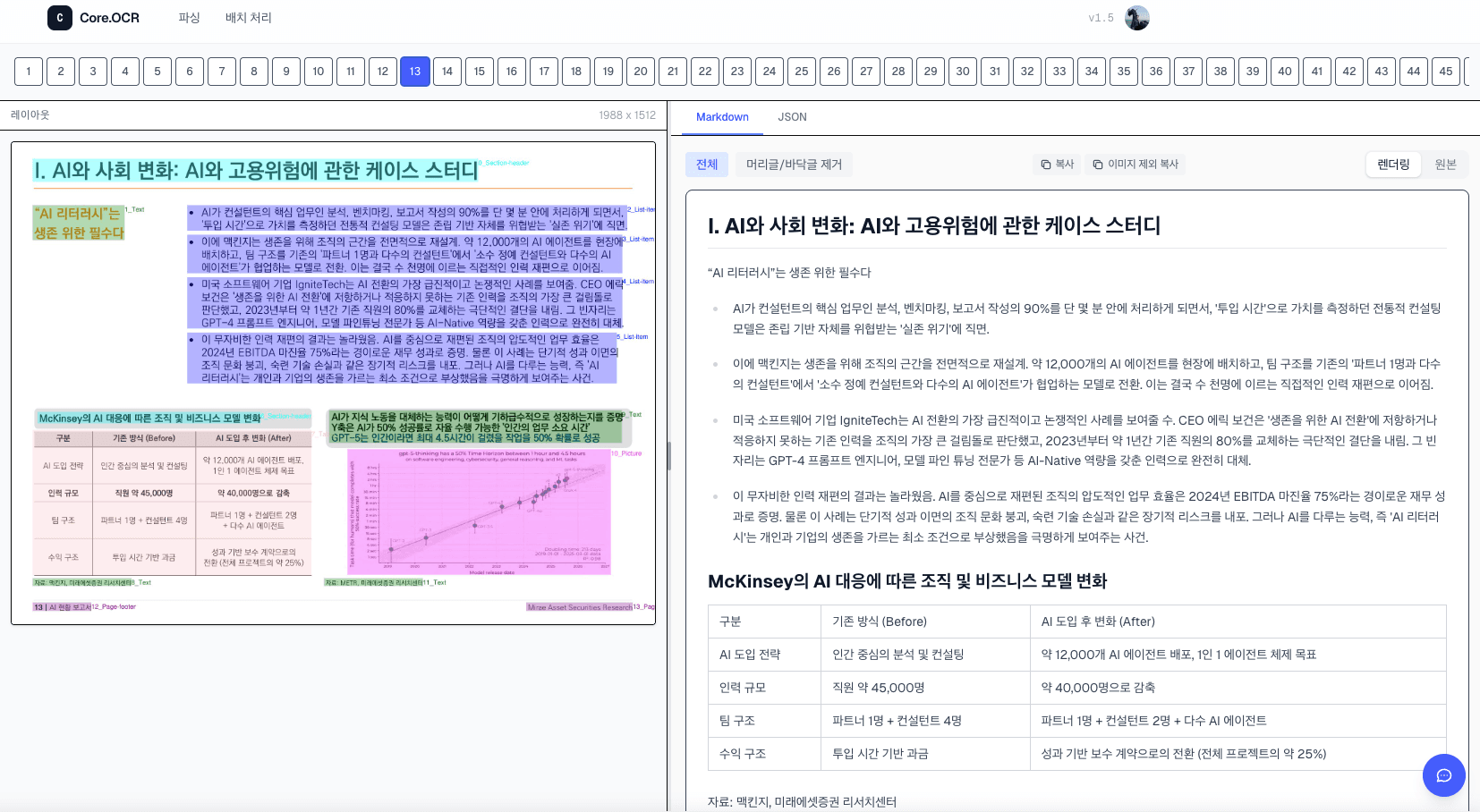
표 인식
복잡한 병합 셀, 다단 헤더가 포함된 학술 테이블을 정확하게 구조화합니다.

장면 텍스트
번호판, 간판 등 자연 환경 속 텍스트를 자동으로 감지·인식합니다.
How It Works
3단계로 완성되는 문서 파싱
업로드
이미지 또는 PDF 파일을 드래그 앤 드롭하거나 선택합니다. 최대 50MB, 멀티페이지 PDF도 지원합니다.
파싱 모드 선택
레이아웃 분석, 텍스트 추출, SVG 변환 등 목적에 맞는 8가지 모드 중 하나를 선택합니다.
결과 확인
Markdown, JSON, 레이아웃 시각화, SVG — 4가지 탭에서 결과를 나란히 비교하며 확인합니다.
Benchmark
검증된 파싱 정확도
영어, 중국어, 한국어 벤치마크에서 검증된 Core.OCR의 문서 파싱 정확도입니다.
Output Formats
다양한 출력 형식, 하나의 파이프라인
Markdown부터 SVG까지 — 용도에 맞는 출력 형식을 선택하세요.
Markdown
문서를 사람이 읽기 좋은 마크다운 형식으로 변환합니다. 제목, 본문, 리스트 구조를 자동 보존합니다.
# 제 1장 서론 본 연구는 딥러닝 기반의 문서 이해 모델을...
JSON
레이아웃 요소의 유형, 좌표, 내용을 구조화된 JSON으로 출력합니다. 다운스트림 파이프라인 연동에 최적.
{
"type": "table",
"bbox": [120, 340, 800, 600],
"content": "<table>...</table>"
}LaTeX / HTML
수식은 LaTeX로, 표는 HTML로 자동 변환합니다. 학술 문서와 비즈니스 리포트 모두 정확하게 처리합니다.
$$E = mc^2$$ <table> <tr><td>항목</td><td>값</td></tr> </table>
SVG
차트, 다이어그램, 로고를 편집 가능한 벡터 형식으로 재구성합니다. 확대해도 깨지지 않는 고품질 출력.
<svg viewBox="0 0 200 100"> <rect fill="#3b82f6" .../> <text>Chart</text> </svg>