종이 한 장을 42번 접으면 달에 닿는다. 신경망도 마찬가지다 — 뉴런을 '옆으로 늘리는' 대신 '위로 쌓으면' 지수적으로 효율적이다. 1989년 보편 근사 정리가 약속한 '무한한 가능성'의 이면에 숨겨진 비용, 그리고 2016년 수학자들이 증명한 '깊이의 압도적 승리'까지. ResNet에서 Transformer, LoRA까지 — 현대 AI의 모든 혁신이 깊이에 빚지고 있는 이유를 파헤친다.
한 번 접으면 0.2mm. 두 번 접으면 0.4mm. 별것 아니다. 열 번 접으면? 약 10cm — 노트북 한 권 두께다. 여전히 대단해 보이지 않는다.
하지만 스무 번 접으면 105m — 30층 건물 높이다. 서른 번 접으면 107km — 대기권을 뚫고 우주에 도달한다. 그리고 42번 접으면?
0.1mm×242=439,805km
달까지의 거리(384,400km)를 넘는다. 종이 한 장이 달에 닿는다.
이것이 지수적 성장(exponential growth) 의 힘이다. 매번 "2배"라는 단순한 연산을 반복했을 뿐인데, 결과는 상상을 초월한다. 42단계의 "접기"가 만든 두께를 접지 않고 한 번에 달성하려면? 종이를 4조 3,980억 장 쌓아야 한다.
신경망에서도 정확히 같은 일이 벌어진다.
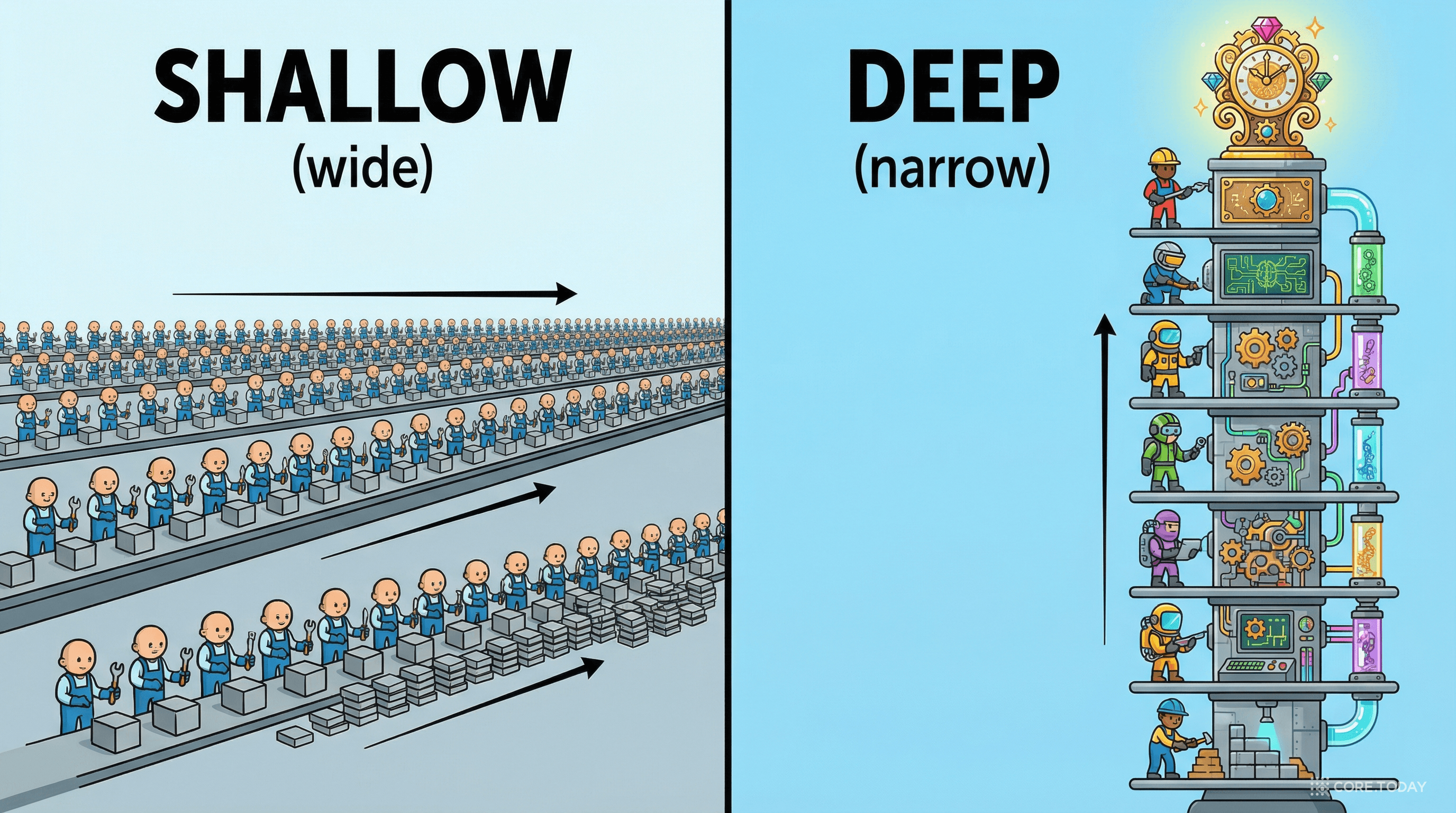
뉴런을 "옆으로 늘리는" 것은 종이를 쌓는 것이다. 뉴런을 "위로 쌓는" 것은 종이를 접는 것이다. 둘 다 같은 결과를 낼 수 있지만, 필요한 자원은 지수적으로 차이난다.
이것이 Depth Separation(깊이 분리) 이다. 깊은 신경망이 얕은 신경망보다 지수적으로 효율적이라는 수학적 사실. 현대 AI의 모든 혁신 — ResNet, Transformer, GPT, LoRA — 이 이 원리에 빚지고 있다.
이 글에서는 그 이야기를 처음부터 풀어본다. 1989년 보편 근사 정리가 약속한 "무한한 가능성"의 이면에 숨겨진 함정에서 출발해, 2016년 수학자들이 증명한 깊이의 승리를 거쳐, 2026년 현재 이 원리가 어떻게 AI 산업 전체를 떠받치고 있는지까지.
1부: 보편 근사 정리의 약속과 함정
"뉴런이 충분하면 뭐든 된다"
1989년, George Cybenko는 역사적인 논문을 발표했다. "Approximation by Superpositions of a Sigmoidal Function" — 시그모이드 함수의 중첩에 의한 근사.
핵심 결론은 이렇다:
은닉층이 하나인 신경망으로, 연속 함수를 임의의 정밀도로 근사할 수 있다.
수식으로 쓰면:
f(x)≈∑i=1Nαi⋅σ(wi⋅x+bi)
여기서 σ는 활성화 함수, N은 뉴런 수다. N을 충분히 크게 잡으면 어떤 연속 함수든 원하는 만큼 가깝게 근사할 수 있다.
이것이 보편 근사 정리(Universal Approximation Theorem, UAT) 다. AI 연구자들에게 이 정리는 "희망의 등불"이었다. 1969년 민스키가 "퍼셉트론은 XOR도 못 푼다"고 저격한 이래 20년간 계속된 AI 겨울에 종지부를 찍는 이론적 근거가 된 것이다.
하지만 이 정리에는 치명적인 함정이 숨어 있었다.
"충분한 뉴런"은 실제로 몇 개인가?
UAT는 "뉴런 N을 충분히 크게 잡으면"이라고만 말한다. 얼마나 크게? 이 질문에 대한 답이 문제의 핵심이다.
간단한 예를 들어보자. 이런 "지그재그 함수"를 근사하고 싶다:
지그재그 함수: 구간 [0, 1]에서 n개의 봉우리
봉우리 4개: 뉴런 ~8개 필요 봉우리 16개: 뉴런 ~32개 필요 봉우리 256개: 뉴런 ~512개 필요 봉우리 2k개: 뉴런 ~2k+1개 필요 ← 지수적!
1차원에서도 이 정도인데, 현실의 문제는 수천~수백만 차원이다. ImageNet 이미지 분류는 224×224×3 = 150,528차원. 자연어 처리는 토큰 임베딩이 수천 차원. 이런 고차원 함수를 얕은 네트워크 하나로 근사하려면, 필요한 뉴런 수는 차원의 지수 함수로 폭발한다.
이것이 바로 차원의 저주(curse of dimensionality) 와 만나는 지점이다. UAT의 약속은 이론적으로 참이지만, 실용적으로는 종종 무의미하다.
💡
UAT의 진짜 메시지
"하나의 은닉층으로 어떤 함수든 근사할 수 있다"는 존재 정리(existence theorem)다. "효율적으로" 할 수 있다는 말이 아니다. 마치 "지구상의 모든 장소에 걸어서 갈 수 있다"는 것이 참이더라도, 실제로 서울에서 뉴욕까지 걸어가는 사람은 없는 것과 같다.
그렇다면 질문이 바뀐다. "할 수 있는가"가 아니라 "얼마나 효율적으로 할 수 있는가" — 그리고 이 질문의 답이 바로 깊이(depth) 에 있다.
2부: Depth Separation의 발견 — 깊이의 수학적 승리
서막: 선형 영역의 폭발 (Montúfar et al., 2014)
Depth separation의 서막을 연 것은 2014년 Guido Montúfar, Razvan Pascanu, Kyunghyun Cho, Yoshua Bengio의 논문 "On the Number of Linear Regions of Deep Neural Networks"다.
ReLU 활성화 함수를 사용하는 신경망은 입력 공간을 여러 개의 선형 영역(linear region) 으로 분할한다. 각 영역 안에서 네트워크는 선형 함수처럼 작동하고, 영역 경계에서 "꺾인다". 선형 영역이 많을수록 네트워크는 더 복잡한 함수를 표현할 수 있다.
핵심 발견:
구조
뉴런 수
선형 영역 수
얕은 네트워크 (1개 은닉층, 너비 nk)
nk개
O(nk) — 선형 증가
깊은 네트워크 (k개 은닉층, 너비 n)
nk개 (동일!)
O(nk) — 지수적 증가
같은 수의 뉴런을 사용하더라도, 깊게 쌓으면 지수적으로 많은 선형 영역을 만들 수 있다. 뉴런 100개를 한 층에 100개 넣으면 O(100)개의 영역이지만, 10개씩 10층으로 쌓으면 O(1010) — 100억 개의 영역이 된다.
이것은 깊이가 표현력에 미치는 영향에 대한 첫 번째 정량적 증거였다. 하지만 "선형 영역이 많다"와 "실제로 유용한 함수를 더 효율적으로 표현한다"는 다른 문제다. 진짜 depth separation 증명은 2016년에 왔다.
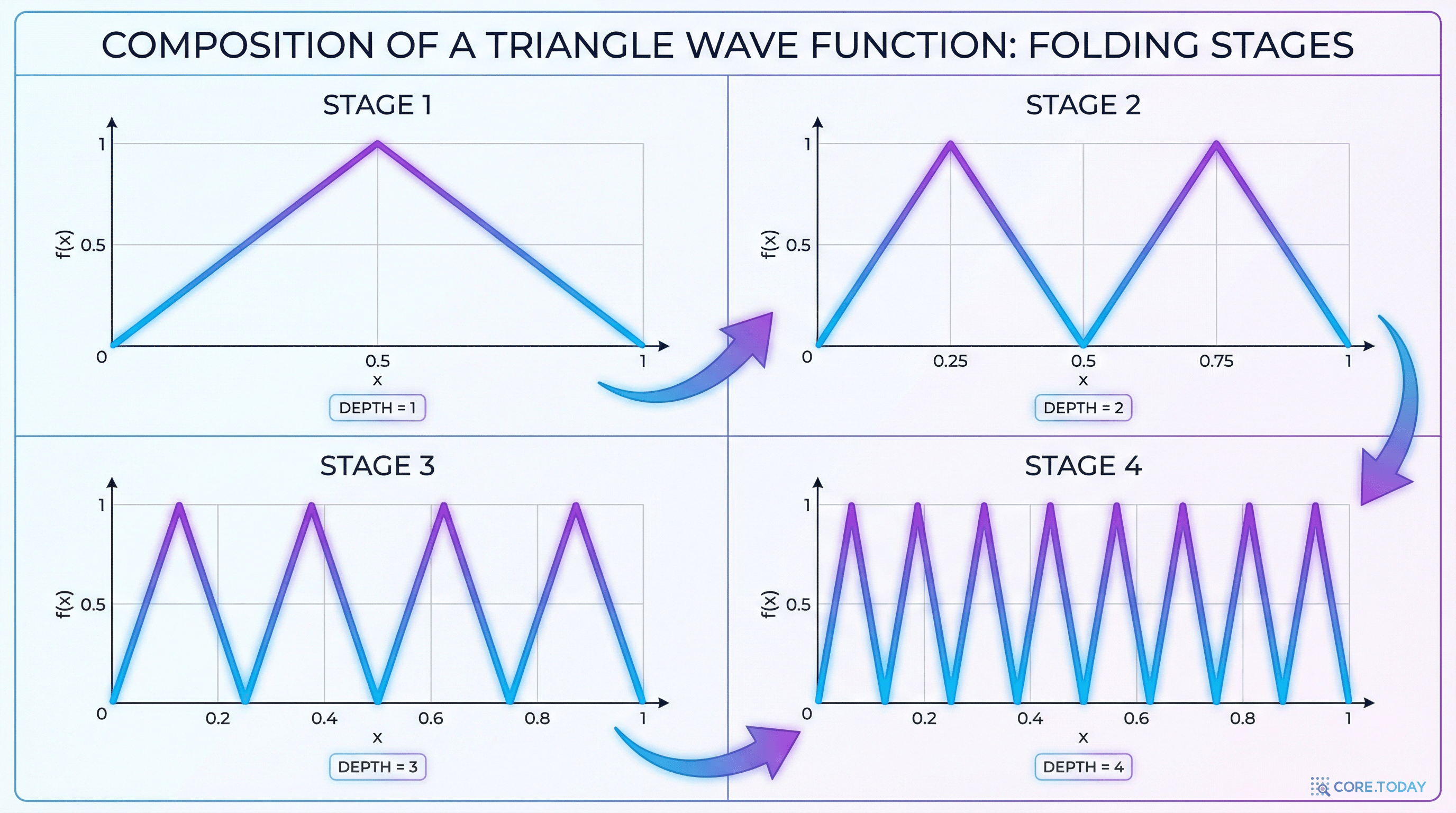
Telgarsky의 삼각파 (2016): 깊이의 압도적 우위
2016년, Matus Telgarsky는 "Benefits of Depth in Neural Networks"라는 논문으로 depth separation을 깔끔하게 증명했다. 그의 증명은 놀랍도록 직관적이다.
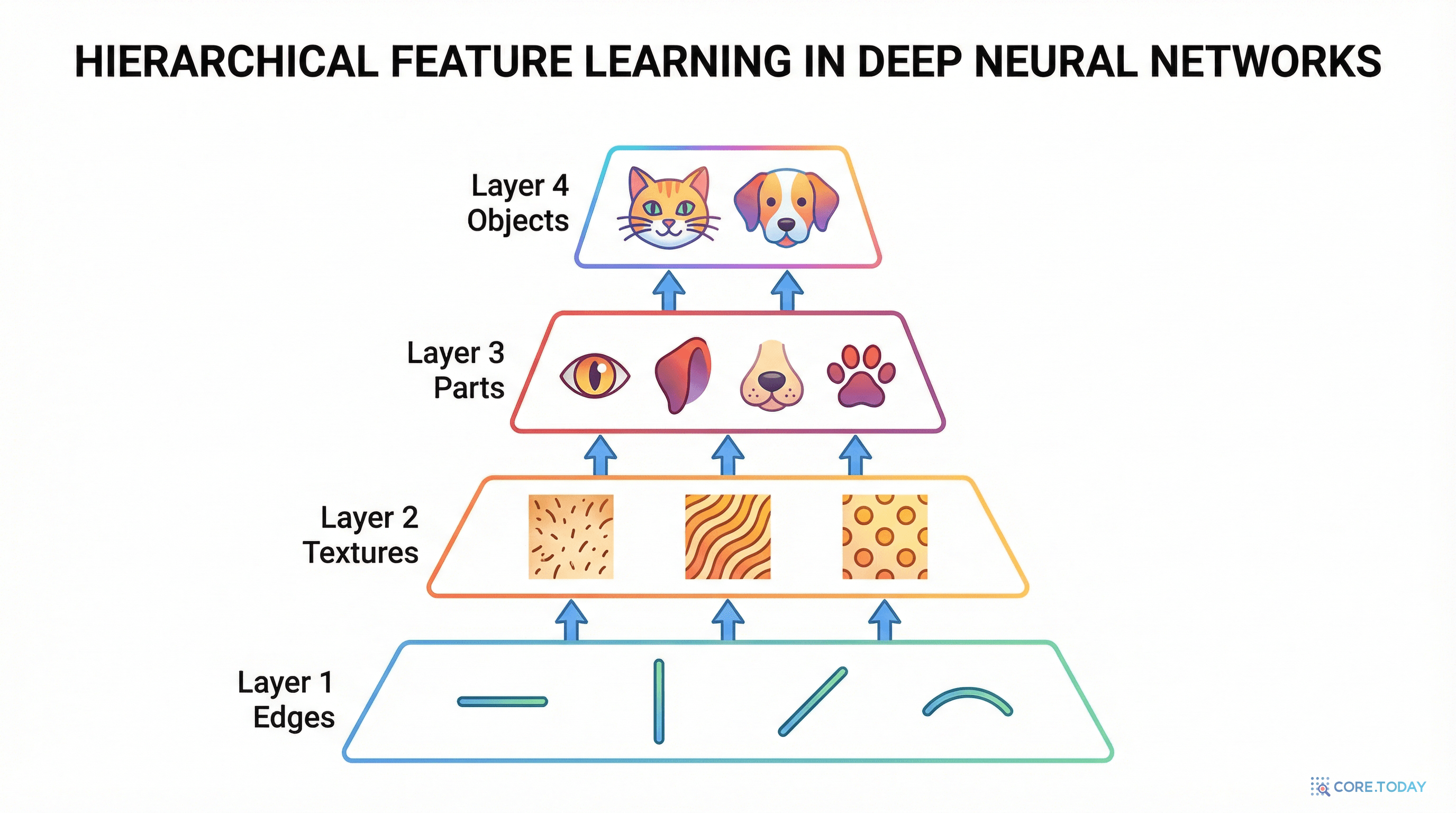
눈의 망막은 빛의 강도 변화 — 즉 엣지(edge) — 를 감지한다. 시각 피질의 V1 영역은 이 엣지들을 조합하여 방향성 있는 선분을 인식한다. V2 영역은 선분들을 조합하여 곡선과 모서리를 파악한다. V4는 이것들을 모아 형태와 질감을 인식하고, IT 피질에 이르러서야 "이것은 고양이다"라는 객체 인식이 완성된다.
Layer 1 엣지 감지 —, |, /, \
→
Layer 2 텍스처 줄무늬, 점, 격자
→
Layer 3 부분 눈, 귀, 코
→
Layer 4 객체 고양이 🐱
이 과정의 핵심은 계층적 합성(hierarchical composition) 이다. 각 단계는 이전 단계의 출력을 조합하여 더 추상적인 개념을 만든다. 엣지 몇 개로 텍스처를 만들고, 텍스처 몇 개로 부분을 만들고, 부분 몇 개로 전체 객체를 만든다.
얕은 네트워크가 이것을 하려면? "엣지 → 고양이"를 한 번에 매핑해야 한다. 이를 위해서는 가능한 모든 엣지 조합과 그에 대응하는 객체를 독립적으로 기억해야 한다. 고양이의 눈 모양, 귀 모양, 몸통 패턴, 다리 자세, 꼬리 곡률 — 이것들의 모든 조합을 하나하나 외워야 한다. 조합 폭발(combinatorial explosion) 이 일어난다.
깊은 네트워크는 이 문제를 우아하게 피한다. 각 층이 중간 추상화를 담당하면서, 전체 조합을 외울 필요 없이 로컬한 패턴의 조합만으로 글로벌한 인식에 도달한다.
이것은 비유가 아니라 실제로 관찰되는 현상이다. Zeiler & Fergus (2014) 는 학습된 CNN의 각 층을 시각화하여 초기 층이 엣지를, 중간 층이 텍스처를, 깊은 층이 객체 부분을 학습한다는 것을 직접 확인했다.
직관 3: 재사용 — 한 번 배운 것을 여러 곳에 써먹는다
회로 설계에서 잘 알려진 사실이 있다. 깊은 회로(deep circuit)는 얕은 회로(shallow circuit)보다 효율적이다. 이유는 중간 결과의 재사용 때문이다.
예를 들어, 32비트 숫자 두 개의 패리티(parity, 짝홀성) 를 계산한다고 하자.
접근
깊이
필요 게이트 수
깊은 회로 (트리 구조)
O(log n)
O(n) — 선형
얕은 회로 (깊이 2)
O(1)
O(2n) — 지수적
깊은 회로는 32개의 입력을 16쌍으로 묶어 XOR을 계산하고, 그 16개의 결과를 8쌍으로 묶어 다시 XOR하고… 이런 식으로 5단계만에 답을 낸다. 각 단계의 중간 결과가 다음 단계에서 재사용된다.
얕은 회로는 중간 결과를 저장할 "층"이 없으므로, 모든 가능한 입력 조합에 대한 답을 개별적으로 처리해야 한다.
신경망에서도 마찬가지다. 깊은 네트워크의 중간 층은 재사용 가능한 중간 표현(intermediate representation) 을 학습한다. "고양이의 눈" 패턴은 "페르시안 고양이"와 "러시안 블루"를 인식할 때 모두 재사용된다. "수평 엣지" 패턴은 "고양이의 눈"과 "자동차의 범퍼"를 만들 때 모두 재사용된다.
얕은 네트워크에는 이런 재사용이 없다. 각 뉴런이 독립적으로 입력에서 출력까지의 전체 매핑을 담당해야 한다.
📐
세 가지 직관 정리
합성: 층을 추가할 때마다 표현력이 곱셈적으로 증가한다. 계층: 단순한 특징 → 복잡한 개념으로의 자연스러운 빌드업이 가능하다. 재사용: 중간 표현을 여러 상위 개념이 공유하여 효율이 극대화된다.
4부: 역사가 증명한 깊이의 힘
수학적 증명이 2014~2016년에 나왔지만, 사실 실험적 증거는 훨씬 전부터 있었다. 컴퓨터 비전의 역사는 그 자체로 depth separation의 실증이다.
깊이의 연대기
모델 깊이의 역사: 층 수의 변화 (1998–2015)
LeNet-5 '98
5층
AlexNet '12
8층
VGG-19 '14
19층
GoogLeNet '14
22층
ResNet '15
152층
LeNet-5 → AlexNet: 깊이의 시작 (5층 → 8층)
Yann LeCun의 LeNet-5(1998)은 겨우 5개 층으로 손글씨 숫자를 인식했다. 14년 후, AlexNet(2012)은 8개 층으로 ImageNet을 정복했다. 층수는 단 3개 늘었지만, 과제의 복잡도는 10개 클래스(숫자)에서 1,000개 클래스(ImageNet)로 100배 뛰었다. 깊이 60% 증가로 복잡도 100배의 문제를 풀 수 있게 된 것이다.
VGG: 깊이의 체계적 실험 (11층 → 19층)
Simonyan & Zisserman(2014)은 깊이를 체계적으로 변화시킨 최초의 연구였다. VGG-11, VGG-13, VGG-16, VGG-19를 만들어 "깊이만 늘리면 어떻게 되는가"를 정면으로 실험했다.
깊이를 늘리면 좋다는 것을 알았지만, 기울기 소실(vanishing gradient) 문제가 벽이었다. 층이 깊어질수록 역전파 과정에서 기울기가 0에 가까워져 학습이 멈추는 현상이다. VGG-19를 VGG-50으로 만들면 오히려 성능이 떨어졌다.
Kaiming He 등(2015)이 이 벽을 무너뜨렸다. 잔차 연결(residual connection) — 각 블록의 입력을 출력에 직접 더해주는 "지름길" — 하나로.
출력=F(x)+x
이 간단한 덧셈이 기울기의 고속도로를 만들어, 152층까지 학습이 가능해졌다. 그리고 152층 ResNet은 인간 전문가(5.1% 에러)를 넘어서는 3.57%의 top-5 에러율을 달성했다.
🏗️
ResNet이 증명한 depth separation
ResNet-18 (11.7M 파라미터, top-1 69.8%) vs ResNet-152 (60M 파라미터, top-1 78.3%). 파라미터를 5배 늘려 정확도를 8.5%p 올렸다. 만약 같은 파라미터를 깊이 대신 너비에 투자했다면? Wide ResNet-18-10 (11.7M, top-1 69.5%)은 깊이가 같은 ResNet-18과 비슷한 수준에 그쳤다. 너비보다 깊이가 파라미터 효율이 압도적으로 높다.
깊이 vs 너비: 숫자로 보는 비교
ImageNet Top-1 정확도: 깊이 vs 너비 스케일링 (파라미터 수 유사)
ResNet-18 (기본)
69.8%11.7M
Wide ResNet-18×2
71.2%45M
ResNet-50
76.1%25.6M
ResNet-152
78.3%60M
ResNet-50은 Wide ResNet-18×2의 절반의 파라미터로 5%p 더 높은 정확도를 달성한다. 깊이의 효율성이 숫자로 선명하게 드러나는 대목이다.
CNN에서 깊이가 "특징의 추상화 수준"을 의미했다면, Transformer에서 깊이는 "추론의 단계 수" 를 의미한다.
GPT 시리즈의 깊이 변화를 보자:
GPT 시리즈: 층 수(깊이)의 변화
GPT-1 '18
12층
GPT-2 '19
48층
GPT-3 '20
96층
GPT-1에서 GPT-3로 가면서 층 수는 8배 증가했고, 동시에 모델의 능력은 질적으로 변화했다. GPT-1은 단순한 텍스트 생성만 가능했지만, GPT-3는 few-shot learning — 예시 몇 개만 보여주면 새로운 과제를 수행하는 능력 — 을 보여주었다.
이 질적 변화의 상당 부분이 깊이에서 온다. Transformer의 각 층은 다음과 같은 연산을 수행한다:
Self-Attention
"어떤 정보에 주목해야 하지?" — 토큰 간 관계 파악
Feed-Forward
"이 정보로 무엇을 계산할까?" — 비선형 변환, 지식 조회
Residual + Norm
"기존 정보를 유지하면서 새 정보 추가" — 안정적 학습
96층이라는 것은 이 "주목 → 계산 → 통합" 사이클을 96번 반복한다는 뜻이다. 이것은 마치 96단계의 추론 과정과 같다. 1단계에서 단어의 의미를 파악하고, 10단계에서 문장 구조를 이해하고, 50단계에서 맥락을 파악하고, 90단계에서 최종 답을 추론한다.
Janis Goldzycher & Gerhard Jäger (2024) 의 연구 "What Formal Languages Can Transformers Express?"는 이것을 형식적으로 분석했다. 고정 깊이의 Transformer는 특정 형식 언어(예: 카운팅이 필요한 언어)를 인식할 수 없지만, 깊이를 입력 길이에 비례하게 늘리면 훨씬 넓은 범위의 언어를 처리할 수 있다.
즉, Transformer에서도 depth separation이 작동한다. 깊이가 곧 추론 능력이다.
EfficientNet: 깊이의 최적 배합을 찾다
EfficientNet(Tan & Le, 2019)은 depth separation의 실용적 귀결이다. 모델을 스케일업할 때 깊이, 너비, 해상도를 균형 있게 키우면 어떻게 되는가를 체계적으로 실험한 것이다.
Compound Scaling 공식:
depth:d=αϕ,width:w=βϕ,resolution:r=γϕ
α⋅β2⋅γ2≈2,α≥1,β≥1,γ≥1
최적의 계수를 찾은 결과: α=1.2, β=1.1, γ=1.15. 깊이 스케일링 계수(α=1.2)가 너비(β=1.1)보다 크다. 같은 연산 예산이 주어졌을 때, 깊이에 더 많이 투자하는 것이 최적이라는 실험적 확인이다.
결과는 극적이었다:
모델
파라미터
Top-1 정확도
FLOPs
GPipe (당시 SOTA)
557M
84.3%
~300B
EfficientNet-B7
66M
84.3%
37B
8.4배 작고, 8.1배 빠르면서 같은 정확도. 깊이, 너비, 해상도의 균형 잡힌 스케일링이 만든 효율의 혁명이었다.
2021년, Microsoft Research의 Edward Hu 등이 LoRA(Low-Rank Adaptation)를 발표했다. 핵심 아이디어: 파인튜닝 시 원래 가중치 행렬 W0을 고정하고, 저랭크(low-rank) 행렬ΔW=BA만 학습한다. B∈Rd×r, A∈Rr×d, r≪d.
GPT-3(175B)에서 r=8로 설정하면, 학습해야 할 파라미터가 175B에서 4.7M으로 줄어든다. 전체의 0.003%. 그런데 성능은 풀 파인튜닝과 동등하거나 더 낫다.
이것이 가능한 이유는 깊이와 깊은 관련이 있다.
내재적 차원성: 깊이가 만든 구조
Aghajanyan et al. (2020) 의 "Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning"은 핵심적인 발견을 했다:
사전학습된 언어 모델의 파인튜닝에 필요한 내재적 차원(intrinsic dimensionality) 은 모델의 전체 파라미터 수보다 수천 배 작다.
무슨 뜻인가? 175B 파라미터가 있는 공간에서, 파인튜닝으로 움직여야 하는 "유효한 방향"은 수천~수만 개에 불과하다는 것이다. 나머지 차원은 이미 사전학습에서 "자리를 잡아" 움직일 필요가 없다.
이 저차원 구조는 깊이에서 온다. 그 메커니즘은 다음과 같다:
1단계
깊이 → 계층적 표현 깊은 네트워크는 저수준 특징(음소, 문자)에서 고수준 개념(의미, 맥락)까지 계층적으로 학습한다
2단계
계층적 표현 → 구조화된 가중치 각 층의 가중치는 특정 수준의 추상화만 담당하므로, 랜덤이 아니라 강한 구조를 갖는다
3단계
구조화된 가중치 → 저랭크 특성 구조화된 행렬은 유효 랭크가 낮다 — 소수의 특이값이 전체 행동을 지배한다
4단계
저랭크 특성 → LoRA의 효과 파인튜닝에 필요한 변화(ΔW)도 저랭크이므로, r≪d인 BA 분해로 충분히 포착된다
얕은 네트워크에서 LoRA가 효과적이지 않은 이유
얕은 네트워크의 가중치는 입력과 출력 사이의 모든 매핑을 한 층에 압축해야 한다. 이렇게 되면 가중치 행렬은 구조가 없고 랭크가 높다 — 많은 독립적인 "역할"을 동시에 수행하기 때문이다.
깊은 네트워크는 각 층이 하나의 추상화 수준만 담당하므로, 가중치가 더 구조적이고, 따라서 더 압축 가능하다.
깊이와 LoRA 효율의 관계 (직관적 비유)
얕은 네트워크: 만능 직원 1,000명 — 각자 100가지 일을 동시에 한다
→ "마케팅 전략을 바꿔라" → 1,000명 모두를 재교육해야 한다 (풀 파인튜닝)
깊은 네트워크: 전문가 10명이 10단계 분업
→ "마케팅 전략을 바꿔라" → 마케팅 담당 1명만 재교육 (LoRA)
이것이 depth separation이 LoRA를 가능하게 만든 메커니즘이다. 깊이가 없었다면, 저랭크 적응이라는 아이디어 자체가 작동하지 않았을 것이다. 현대 AI 민주화의 핵심인 LoRA는 사실상 깊이의 부산물인 셈이다.
7부: 2026년, 깊이의 새로운 차원들
Depth separation은 "깊으면 좋다"는 단순한 메시지가 아니다. 현대 AI는 깊이의 개념을 다양한 방향으로 확장하고 있다.
Mixture of Experts: 조건부 깊이
Mixture of Experts(MoE) 모델(예: Mixtral, DeepSeek-V3)은 모든 입력이 모든 층을 통과하는 것이 아니라, 입력에 따라 다른 전문가(expert)를 선택적으로 활성화한다.
입력 토큰
→
라우터 어떤 전문가?
→
Expert 3 수학 전문
→
출력
이것은 "깊이"의 새로운 해석이다. 전체 모델의 깊이는 동일하지만, 각 토큰이 경험하는 유효 깊이(effective depth) 는 다르다. 수학 문제에는 수학 전문가가, 코드에는 코딩 전문가가 활성화된다.
MoE는 depth separation의 효율성을 더 극대화한다. 전체 파라미터는 수조 개에 달하지만, 실제 활성화되는 파라미터는 그 일부다. 깊이의 이점을 유지하면서 연산량은 줄이는 절묘한 균형이다.
동적 깊이: Early Exit
Early Exit 기법은 입력의 난이도에 따라 네트워크의 깊이를 동적으로 조절한다.
Early Exit: 쉬운 문제는 빨리 끝내고, 어려운 문제만 깊이 생각한다
"고양이" 분류 (쉬움): 10층에서 이미 확신 99% → 여기서 출력! "시베리안 허스키 vs 알래스칸 말라뮤트" (어려움): 152층 전부 필요
→ 평균 연산량 40~60% 감소, 정확도 유지
이것은 depth separation의 역설적 활용이다. 깊이가 효율적이라는 것을 알기에, 필요한 만큼만 깊이를 사용하는 전략이 가능해진다.
Test-Time Compute Scaling: 추론 시의 깊이
2024~2025년 가장 주목받는 트렌드 중 하나는 테스트 시간 연산 스케일링(test-time compute scaling) 이다. OpenAI의 o1, o3 시리즈가 대표적이다.
핵심 아이디어: 학습 시의 깊이(모델의 층 수)는 고정하되, 추론 시에 "사고의 깊이"를 늘린다. Chain-of-thought reasoning을 통해 모델이 답을 내기 전에 여러 단계의 추론을 수행하는 것이다.
이것은 depth separation의 가장 최신 확장이다. 모델 아키텍처의 물리적 깊이를 넘어서, 추론 과정의 논리적 깊이까지 확장하는 것. 그리고 이 논리적 깊이도 지수적 이점을 제공한다 — 복잡한 수학 문제나 코딩 과제에서, 추론 단계를 2배로 늘리면 정확도가 수십 퍼센트포인트 올라가는 현상이 관찰된다.
깊이의 미래: Layer-wise LoRA와 Depth-Adaptive Training
최신 연구들은 깊이의 이점을 더 정밀하게 활용하는 방향으로 나아가고 있다:
Layer-wise LoRA Rank Allocation: 모든 층에 동일한 랭크 r을 적용하는 대신, 중요한 층에는 높은 랭크, 덜 중요한 층에는 낮은 랭크를 할당한다. 이를 통해 LoRA의 효율을 10~30% 더 높일 수 있다.
Progressive Layer Dropping: 학습 중에 랜덤으로 층을 건너뛰는 기법. depth separation 이론에 따르면 모든 층이 동등하게 중요한 것은 아니므로, 이 기법은 학습 속도를 높이면서 성능을 유지한다.
Depth-Adaptive Inference: 입력마다 다른 수의 층을 사용하는 추론 기법. 쉬운 입력은 적은 층으로, 어려운 입력은 많은 층으로 처리하여 평균 연산량을 줄인다.
마무리: 깊이의 교훈
이 글에서 우리가 따라간 여정을 정리해보자.
1989
보편 근사 정리 — "1층이면 충분하다"는 약속. 하지만 비용이 지수적일 수 있다는 함정
2012–15
깊이 전쟁 — AlexNet(8) → VGG(19) → ResNet(152). 깊이를 늘릴 때마다 비약적 성능 향상
GPT-3 & LoRA — 96층의 깊이가 few-shot learning을 가능케 하고, 깊이가 만든 저차원 구조가 LoRA를 가능케 함
2026
MoE, Early Exit, Test-time Scaling — 깊이의 개념이 물리적 층 수를 넘어 동적·논리적 깊이로 확장
종이 접기 비유로 돌아가자. 종이를 42번 접으면 달에 닿고, 4조 장을 쌓아도 같은 높이가 된다. 둘 다 "달에 닿는다"는 결과는 같다. 하지만 42번의 접기와 4조 장의 종이 — 어느 쪽이 현실적인가?
현대 AI의 모든 혁신은 "접기"를 선택했다. ResNet은 잔차 연결로 깊이의 한계를 돌파했고, Transformer는 96층의 깊이로 언어 이해를 달성했고, EfficientNet은 깊이 중심 스케일링으로 효율 혁명을 일으켰고, LoRA는 깊이가 만든 저차원 구조 덕분에 AI 민주화를 가능케 했다.
Depth separation은 단순한 이론이 아니다. 현대 AI의 설계 원리이자, 효율성의 근본적 원천이다.
다음에 누군가 "왜 딥러닝을 '딥'러닝이라고 부르는가?"라고 물으면, 이렇게 답해주자.
"깊이가 지수적으로 효율적이기 때문이다. 종이를 쌓는 대신 접는 것과 같은 이유다."
참고 문헌
Cybenko, G. (1989). "Approximation by Superpositions of a Sigmoidal Function." Mathematics of Control, Signals and Systems, 2(4), 303–314.
Hornik, K. (1991). "Approximation Capabilities of Multilayer Feedforward Networks." Neural Networks, 4(2), 251–257.
Montúfar, G., Pascanu, R., Cho, K., & Bengio, Y. (2014). "On the Number of Linear Regions of Deep Neural Networks." Advances in Neural Information Processing Systems (NeurIPS), 27.
Telgarsky, M. (2016). "Benefits of Depth in Neural Networks." Conference on Learning Theory (COLT).
Eldan, R. & Shamir, O. (2016). "The Power of Depth for Feedforward Neural Networks." Conference on Learning Theory (COLT).
He, K., Zhang, X., Ren, S., & Sun, J. (2016). "Deep Residual Learning for Image Recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Simonyan, K. & Zisserman, A. (2015). "Very Deep Convolutional Networks for Large-Scale Image Recognition." International Conference on Learning Representations (ICLR).
Tan, M. & Le, Q. V. (2019). "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." International Conference on Machine Learning (ICML).
Hu, E. J. et al. (2022). "LoRA: Low-Rank Adaptation of Large Language Models." International Conference on Learning Representations (ICLR).
Aghajanyan, A. et al. (2020). "Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning." Annual Meeting of the Association for Computational Linguistics (ACL).
Zeiler, M. D. & Fergus, R. (2014). "Visualizing and Understanding Convolutional Networks." European Conference on Computer Vision (ECCV).
Zagoruyko, S. & Komodakis, N. (2016). "Wide Residual Networks." British Machine Vision Conference (BMVC).
Brown, T. et al. (2020). "Language Models are Few-Shot Learners." Advances in Neural Information Processing Systems (NeurIPS), 33.