블로그로 돌아가기
FNOFourier Neural Operator신경 연산자딥러닝시뮬레이션편미분방정식
주파수의 눈으로 물리를 본다 — Fourier Neural Operator 완전 해부
하나의 PDE를 푸는 데 수 시간이 걸리던 시뮬레이션을, 학습 한 번으로 수천 가지 조건에 대해 밀리초 만에 답하게 만든 FNO. 푸리에 변환의 직관부터 아키텍처의 핵심, 실전 사례까지 빠짐없이 풀어본다.
코어닷투데이2026-03-0242분
하나의 PDE를 푸는 데 수 시간이 걸리던 시뮬레이션을, 학습 한 번으로 수천 가지 조건에 대해 밀리초 만에 답하게 만든 FNO. 푸리에 변환의 직관부터 아키텍처의 핵심, 실전 사례까지 빠짐없이 풀어본다.
자동차를 설계한다고 생각해 보자. 공기역학 성능을 최적화하려면 차체 형상을 바꿀 때마다 나비에-스토크스 방정식을 다시 풀어야 한다. 형상 후보가 100개라면 시뮬레이션도 100번. 한 번에 6시간이 걸린다면, 전체 탐색에 600시간 — 25일이 필요하다.
PINN(Physics-Informed Neural Networks)은 이 문제를 부분적으로 해결했다. 하지만 PINN에게는 근본적 한계가 있었다.
PINN은 하나의 문제 인스턴스를 학습한다.
초기조건이 바뀌면? 경계조건이 달라지면? 형상이 바뀌면? 처음부터 다시 학습해야 한다. 마치 수학 공식을 모르고, 매번 계산기를 처음부터 두드리는 것과 같다.
만약 "방정식 자체를 푸는 방법" 을 한 번 배워서, 어떤 조건이 주어지든 즉시 답할 수 있다면? 공식을 외워두면 숫자만 바꿔 넣으면 되는 것처럼?
바로 이 발상에서 Fourier Neural Operator(FNO) 가 탄생했다. 그리고 이 아이디어의 중심에는 200년 전 프랑스 수학자가 발견한, 놀랍도록 우아한 도구가 있다.
푸리에 변환(Fourier Transform).
FNO를 이해하려면 먼저 푸리에 변환을 알아야 한다. 어렵지 않다. 음악으로 시작하자.
피아노에서 '도-미-솔' 화음을 치면, 우리 귀에는 하나의 소리로 들린다. 하지만 이 소리를 마이크로 녹음해 파형을 보면, 복잡하게 뒤얽힌 곡선이다.
그런데 이 복잡한 파형은 사실 세 개의 단순한 사인파의 합이다:
푸리에 변환은 바로 이것을 하는 수학적 도구다. 복잡한 신호를 개별 주파수 성분으로 분해한다.
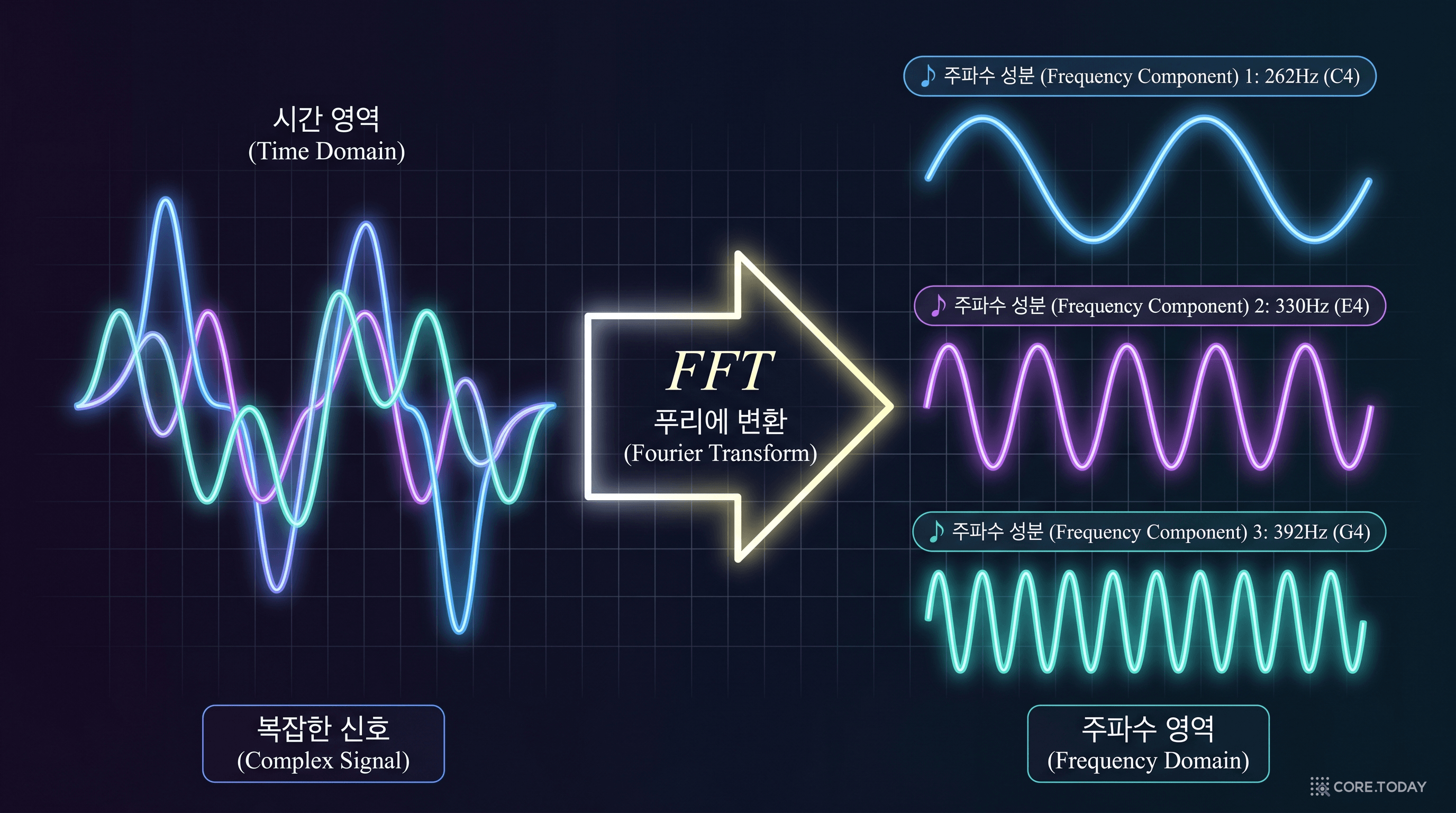
수학적으로 표현하면:
여기서 는 원래 신호, 는 주파수 에서의 성분이다. 복잡해 보이지만 본질은 단순하다: "이 신호에 주파수 짜리 파동이 얼마나 섞여 있는가?" 를 묻는 것이다.
주파수 영역에서 작업하면 놀라운 일이 벌어진다. 바로 합성곱(convolution) 정리다.
시간 영역에서의 합성곱은 주파수 영역에서의 단순 곱셈이 된다.
합성곱은 계산이 비싸다. 데이터 크기 에 대해 의 연산이 필요하다. 하지만 주파수 영역에서의 곱셈은 이면 충분하다. 거기에 고속 푸리에 변환(FFT) 이 으로 변환을 해주니, 전체 과정이 극적으로 빨라진다.
이 속도 차이는 데이터가 커질수록 압도적이다. 이것이 FNO가 푸리에 변환을 선택한 핵심 이유다.
여기에 아름다운 역사적 연결이 있다. 푸리에 변환을 발명한 조제프 푸리에(Joseph Fourier, 1768–1830) 는 애초에 열 전도 방정식(heat equation) 을 풀기 위해 이 도구를 만들었다.
1807년, 푸리에는 프랑스 학술원에 혁명적 논문을 제출했다. "임의의 함수를 사인과 코사인의 합으로 표현할 수 있다"는 주장이었다. 당시 라그랑주를 비롯한 대수학자들은 이를 믿지 않았다. 하지만 푸리에가 옳았다.
200년 전 편미분방정식을 풀기 위해 탄생한 푸리에 변환이, 200년 후 다시 편미분방정식을 푸는 신경망의 핵심이 된 것이다.
수학의 역사에서 이보다 완벽한 원(circle)을 그리는 이야기를 찾기 어렵다.
FNO를 이해하려면 먼저 연산자(operator) 라는 개념을 알아야 한다.
일반적인 신경망은 벡터에서 벡터로의 매핑을 학습한다. 입력 이미지(픽셀 벡터) → 출력 클래스(확률 벡터). 유한 차원에서 유한 차원으로의 함수다.
하지만 물리 시뮬레이션에서 우리가 정말 원하는 것은 함수에서 함수로의 매핑이다.
이 매핑 를 연산자(operator) 라고 부른다. 연산자는 숫자가 아니라 함수를 먹고 함수를 뱉는다.
PINN은 하나의 좌표를 받아 해당 점에서의 물리량 를 출력한다. 하나의 문제 인스턴스에 특화된다.
FNO는 입력 함수 전체를 받아 출력 함수 전체를 한꺼번에 매핑한다. 한 번 학습하면, 어떤 초기조건이든 즉시 해를 예측할 수 있다.
이런 접근이 수학적으로 가능한 걸까? 1995년, Tianping Chen과 Hong Chen은 IEEE Transactions on Neural Networks에서 핵심적인 이론적 기반을 제시했다.
단일 은닉층 신경망으로 임의의 연속 연산자를 근사할 수 있다.
이것은 유한 차원의 보편 근사 정리(Universal Approximation Theorem)를 무한 차원(함수 공간) 으로 확장한 결과다. 이 이론이 25년 뒤 DeepONet과 FNO의 수학적 정당성을 뒷받침하게 된다.
2020년 10월(프리프린트), 2021년 ICLR에서 공식 발표된 이 논문이 FNO의 시작이다:
"Fourier Neural Operator for Parametric Partial Differential Equations" — Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, Anima Anandkumar (Caltech & NVIDIA)
Caltech과 NVIDIA의 공동 연구였으며, 특히 Anima Anandkumar 교수(당시 NVIDIA 겸직)의 리더십 아래 진행됐다.
FNO의 핵심 통찰은 간결하다.
기존 신경망에서 합성곱 연산은 로컬(지역적) 이다. 3×3이든 5×5이든, 커널이 주변 이웃만 본다. 하지만 PDE의 해는 글로벌(전역적) 상호작용을 포함한다. 한쪽 끝에서 발생한 변화가 전체 도메인에 영향을 미친다.
전역적 상호작용을 효율적으로 포착하려면? 푸리에 변환이다.
FNO의 핵심 연산인 푸리에 레이어(Fourier Layer) 는 이렇게 작동한다:
수식으로 정리하면, 푸리에 레이어의 출력은:
여기서:
직관적으로 말하면: FNO는 매 층마다 데이터를 주파수 세계로 보내고, 그곳에서 "어떤 주파수를 강조하고 어떤 주파수를 약화할지" 학습한 뒤, 다시 물리 세계로 돌려보낸다.

모드 절단(Mode Truncation): 실제 구현에서는 모든 주파수를 다 쓰지 않는다. 상위 개의 저주파 모드만 유지하고 나머지 고주파는 버린다. 이것은 파라미터 수를 크게 줄이면서도 물리적으로 중요한 대규모 구조를 잘 포착한다. 많은 물리 현상에서 에너지는 저주파에 집중되어 있기 때문이다.
FNO의 가장 놀라운 특성이다. 낮은 해상도에서 학습하고, 높은 해상도에서 바로 사용할 수 있다.
일반적인 CNN은 64×64 격자로 학습하면 64×64에서만 쓸 수 있다. 해상도가 바뀌면 모델을 다시 학습해야 한다.
FNO는 함수 공간에서 연산자를 학습하기 때문에, 이산화(discretization)에 묶이지 않는다. 64×64로 학습한 FNO를 256×256에서 평가할 수 있다 — 제로샷 초해상도(zero-shot super-resolution).
해상도가 4배로 올라가도 오차 증가가 미미하다. 학습 데이터를 저해상도로 준비할 수 있으므로 데이터 생성 비용이 극적으로 줄어든다.
Li et al.의 원 논문에서 나비에-스토크스 방정식 벤치마크 결과:
약 200,000배 빠르다. 물론 FNO에는 사전 학습 비용이 있지만, 동일한 방정식을 수십~수만 번 풀어야 하는 설계 최적화, 불확실성 정량화, 실시간 제어 같은 시나리오에서는 압도적인 이점이다.
CNN의 3×3 커널은 지역적 패턴만 본다. 전역 정보를 얻으려면 층을 깊게 쌓아야 한다. 반면 FNO의 푸리에 레이어는 한 번의 FFT로 전체 도메인의 상호작용을 포착한다. 이것은 PDE의 해가 전역적 의존성을 가진다는 물리적 특성과 자연스럽게 맞아떨어진다.
유한요소법(FEM)은 복잡한 형상에 대해 메시 생성에만 수 주가 걸릴 수 있다. FNO는 균일 격자 위에서 FFT를 수행하므로 메시 생성이 불필요하다. (비균일 격자에 대한 확장은 후속 연구에서 다뤄진다.)
FNO 이전에도 신경 연산자 연구는 있었다. 왜 하필 푸리에 변환이 승리했을까?
Graph Neural Operator (GNO): Li et al.이 FNO 이전에 제안한 접근법. 입력 함수를 그래프로 표현하고, 그래프 신경망으로 연산자를 학습한다. 비정규 격자를 처리할 수 있지만, 이웃 탐색과 메시지 전달 비용이 격자 크기에 따라 급증한다.
Low-Rank Neural Operator: 커널을 저차원으로 분해해 효율성을 높인 접근법. 하지만 표현력에 한계가 있었다.
FNO가 이긴 이유:
FFT의 복잡도가 속도와 표현력의 균형점을 정확히 잡았다. 또한 FFT는 GPU에서 고도로 최적화된 라이브러리(cuFFT)가 이미 존재했기 때문에, 구현 즉시 하드웨어 가속의 이점을 누릴 수 있었다.
문제: 전통적 수치 기상 예측(NWP)은 전 세계 대기를 격자로 나누고 유체역학 방정식을 직접 푼다. ECMWF의 IFS 모델은 한 번의 10일 예측에 슈퍼컴퓨터 수천 코어로 1시간 이상이 소요된다.
FNO 적용: NVIDIA와 UC Berkeley가 개발한 FourCastNet(2022)은 FNO 기반의 글로벌 기상 예측 모델이다. ERA5 재분석 데이터로 학습한 후, 10일 예측을 단 2초에 수행한다.
Pathak et al. (2022)이 발표한 이 모델은:
비유: 전통 NWP가 "체스를 한 수씩 두는 것"이라면, FourCastNet은 "전체 게임의 패턴을 읽는 것"이다.
문제: CO₂를 지하 암반에 주입·저장하는 CCS(Carbon Capture and Storage) 프로젝트에서는, CO₂ 플룸(plume)이 수십 년에 걸쳐 어떻게 이동하는지 예측해야 한다. 다공성 매질 유동 시뮬레이션은 한 시나리오에 수 시간에서 수 일이 걸린다.
FNO 적용: Wen et al. (2022)은 FNO를 사용해 다공성 매질에서의 CO₂ 이동을 예측했다. 지질학적 불확실성을 고려해 수천 개의 투과율(permeability) 시나리오에 대한 빠른 예측이 가능해졌다.
이는 CCS 프로젝트의 위험 평가와 주입 전략 최적화에 직접 활용된다. 기존에 1,000개 시나리오를 탐색하는 데 수 개월이 걸리던 작업이 수 시간으로 단축됐다.
문제: 자동차의 공력 계수(drag coefficient)를 최적화하려면, 차체 형상을 바꿀 때마다 CFD(전산유체역학) 시뮬레이션을 반복해야 한다. 형상 하나당 6–24시간.
FNO 적용: NVIDIA의 Modulus 플랫폼에 통합된 FNO 기반 서로게이트 모델(surrogate model)은 학습 후 밀리초 단위의 공력 예측을 제공한다. 설계 공간 탐색이 기존 대비 1,000배 이상 가속된다.
실제로 여러 자동차 OEM이 초기 설계 단계에서 FNO 기반 서로게이트를 사용해 후보군을 빠르게 줄인 뒤, 최종 후보에 대해서만 정밀 CFD를 수행하는 하이브리드 워크플로우를 채택하고 있다.

문제: 석유 저류층 시뮬레이션은 다상 유동(multiphase flow) + 복잡한 지질 구조를 다루는 극도로 비싼 계산이다. 역사 매칭(history matching) — 관측 데이터에 맞도록 저류층 모델을 보정하는 과정 — 에는 수백~수천 회의 시뮬레이션이 필요하다.
FNO 적용: Yan et al. (2022)은 FNO를 2상 유동 시뮬레이션의 서로게이트 모델로 학습시켜, 포화도(saturation)와 압력 분포를 예측했다. 역사 매칭 루프에 FNO를 넣으면 최적화 시간이 수 주에서 수 시간으로 단축된다.
문제: 건축물이나 기계 부품의 구조 안전성을 평가하려면 FEM으로 응력 분포를 계산한다. 설계 변수가 많으면 반복 계산 비용이 막대하다.
FNO 적용: Li et al. (2023)은 FNO를 탄성 방정식의 연산자 학습에 적용해, 다양한 하중 조건과 형상에 대한 응력·변형 분포를 즉시 예측하는 모델을 구축했다. 위상 최적화(topology optimization) 루프에서 FEM을 대체하면 설계 반복 속도가 100배 이상 향상된다.
문제: 전력망에 갑작스러운 사고(발전기 탈락, 송전선 사고 등)가 발생했을 때, 시스템이 안정한지를 빠르게 판단해야 한다. 전통적 과도 안정성 분석은 미분-대수 방정식 시스템을 수치적으로 풀어야 한다.
FNO 적용: 전력 시스템의 초기 상태(발전기 출력, 부하 분포 등)에서 사고 후 동적 응답까지의 매핑을 FNO로 학습하면, 실시간(수 밀리초) 안정성 판단이 가능해진다. 이는 스마트 그리드의 자동 보호 시스템에 직접 활용될 수 있다.
원조 FNO 이후, 한계를 극복하고 적용 범위를 넓히는 연구가 활발하다.
Guibas et al. (2022)이 제안. 주파수 도메인에서 토큰 믹싱(token mixing) 을 수행하는 비전 트랜스포머 스타일의 아키텍처. FourCastNet의 기반이 된 구조로, 이미지 분류에서도 경쟁력 있는 성능을 보였다.
Li et al. (2023)이 제안. 원래 FNO는 균일한 직교 격자에서만 작동한다는 한계가 있었다. Geo-FNO는 비정규 기하학(불규칙한 도메인 형상)을 변형(deformation)을 통해 직교 격자로 매핑한 뒤 FNO를 적용한다. 이를 통해 비행기 날개, 심장 혈관 같은 복잡한 형상에도 FNO를 사용할 수 있게 됐다.
Wen et al. (2022)이 제안. U-Net의 다중 스케일 구조와 FNO를 결합했다. 인코더-디코더 경로를 통해 다양한 공간 스케일의 특징을 포착하며, 특히 지하 유동 같은 다중 스케일 문제에서 원조 FNO 대비 정확도가 크게 향상됐다.
Tran et al. (2023)이 제안. 3D 문제에서 FFT의 계산 비용이 급증하는 문제를 해결하기 위해, 주파수 영역 가중치 텐서를 차원별로 분해(factorize) 한다. 파라미터 수를 에서 로 줄이면서도 정확도를 유지한다.
FNO와 PINN을 결합한 접근법도 등장했다. Li et al. (2024)은 FNO의 학습에 PDE 잔차를 추가 손실 항으로 부과해, 데이터가 적은 상황에서도 물리적으로 일관된 예측을 하는 모델을 만들었다.
혁명적이지만, FNO에도 분명한 한계가 있다.
원조 FNO는 FFT를 사용하므로 직교 균일 격자(regular grid) 에서만 작동한다. 실제 공학 문제의 복잡한 형상에 바로 적용하기 어렵다. Geo-FNO 같은 확장이 이를 완화하지만, 형상 매핑 자체가 추가 비용과 오차를 발생시킨다.
FNO를 학습시키려면 수백~수천 쌍의 (입력 함수, 출력 함수) 데이터가 필요하다. 이 데이터는 대부분 전통적 수치 시뮬레이션으로 생성한다. 즉, 학습 데이터를 만드는 데 이미 비싼 시뮬레이션이 필요하다. 초기 투자 비용이 높다는 뜻이다.
푸리에 변환은 본질적으로 매끄러운 함수에 최적화되어 있다. 충격파(shock wave)나 접촉 불연속면(contact discontinuity)처럼 급격한 변화가 있는 해에서는 기브스 현상(Gibbs phenomenon) — 불연속점 근처에서 진동이 발생하는 현상 — 이 나타날 수 있다.
FNO로 시간 의존 문제를 풀 때, 한 타임스텝의 출력을 다음 타임스텝의 입력으로 사용하는 자기회귀(autoregressive) 방식을 쓰면 오차가 누적된다. 장기 예측에서 불안정성이 발생할 수 있다.
LLM이 자연어의 기초 모델이라면, FNO는 물리 시뮬레이션의 기초 모델을 향한 핵심 빌딩 블록이다.
NVIDIA의 Earth-2 프로젝트는 FourCastNet(FNO 기반)을 포함한 여러 AI 모델을 결합해, 지구 전체의 기후·기상 디지털 트윈을 구축하고 있다. 목표는 "하나의 모델로 기상, 해양, 빙하, 대기화학을 통합 예측"하는 것이다.
Microsoft의 ClimaX (2023)도 트랜스포머와 FNO 아이디어를 결합해 다양한 기후 관련 다운스트림 태스크에 전이 학습이 가능한 기초 모델을 제안했다.
확산 모델(diffusion model)과 FNO의 결합도 주목할 만하다. Yang & Perdikaris (2023)은 조건부 확산 모델의 스코어 함수를 FNO로 파라미터화해, PDE 해의 확률 분포를 학습하는 방법을 제안했다. 이를 통해 단일 점 추정이 아닌 불확실성을 포함한 앙상블 예측이 가능해진다.
디지털 트윈에서 FNO의 역할이 확대되고 있다. 센서 데이터가 실시간으로 들어올 때, FNO가 밀리초 단위로 전체 시스템의 상태를 예측하고, 이를 기반으로 제어 결정을 내리는 아키텍처다.
실제로 에너지, 제조, 항공 분야에서 FNO 기반 서로게이트 모델이 실시간 공정 최적화에 투입되고 있다. 전통적 시뮬레이션은 "사후 분석"에만 쓰였지만, FNO의 속도는 "실시간 의사결정" 을 가능하게 한다.
이 글의 마무리로, PINN과 FNO의 관계를 정리하자.
둘은 경쟁이 아니라 스펙트럼의 양 끝이다:
그리고 이 모든 것의 목표는 동일하다: 물리 시뮬레이션을 민주화하는 것. 슈퍼컴퓨터와 전문 인력 없이도, 누구나 물리 세계를 정확하고 빠르게 예측할 수 있는 미래.
조제프 푸리에는 열 방정식을 풀기 위해 함수를 주파수로 분해하는 방법을 발명했다. 200년이 지난 지금, 그의 도구는 신경망의 심장에 들어가 편미분방정식을 푸는 방법 자체를 학습하고 있다.
FNO의 본질은 이것이다: 주파수의 눈으로 물리 세계를 보면, 복잡한 것이 단순해진다.
복잡한 유체 유동도, 대기의 혼돈적 움직임도, 지하 수천 미터의 CO₂ 이동도 — 주파수 공간에서 바라보면 학습 가능한 패턴이 된다. 그리고 이 패턴을 한 번 배우면, 수만 가지 시나리오에 즉시 답할 수 있다.
이것이 FNO가 AI for Science의 핵심 인프라로 자리잡고 있는 이유이며, 200년 전 프랑스 수학자의 통찰이 왜 지금도 유효한지를 보여주는 가장 극적인 증거다.