
블로그로 돌아가기
CNN딥러닝컴퓨터 비전합성곱 신경망객체 검출ImageNet
CNN 완전 이해: 고양이 한 마리가 바꾼 컴퓨터 비전의 역사
고양이 뉴런 실험에서 자율주행까지 — 합성곱 신경망이 어떻게 탄생했고, 왜 작동하며, 2026년에도 여전히 중요한지를 논문과 사례로 풀어본다.
코어닷투데이2026-02-2685분
고양이 뉴런 실험에서 자율주행까지 — 합성곱 신경망이 어떻게 탄생했고, 왜 작동하며, 2026년에도 여전히 중요한지를 논문과 사례로 풀어본다.
스마트폰에 고양이 사진이 뜬다. 당신은 0.1초도 안 되어 "고양이"라고 인식한다. 뾰족한 귀, 부드러운 털, 동그란 눈. 사진이 흐릿해도, 고양이가 상자 안에 웅크리고 있어도, 심지어 검은 배경에 검은 고양이여도 — 당신은 틀리지 않는다.
이 일이 얼마나 놀라운 일인지, 컴퓨터의 관점에서 생각해보자.
28 × 28 픽셀의 작은 흑백 이미지가 있다. 인간의 눈에는 손글씨 숫자 "7"이 보인다. 하지만 컴퓨터에게 이 이미지는 784개의 숫자 배열에 불과하다. 각 픽셀은 0에서 255 사이의 밝기 값이고, 컴퓨터는 이 숫자들의 나열을 "읽을" 뿐이다. "7"이라는 형태를 "보는" 것이 아니다. 거기에 의미는 없다. 패턴도 없다. 그저 숫자 784개.
"본다"는 것과 "픽셀을 읽는다"는 것 사이에는 거대한 심연이 있다.
1960년대, 초기 인공지능 연구자들은 이 심연을 무시했다. 그들의 접근법은 단순했다. 2차원 이미지를 1차원 벡터로 쭉 펼쳐서 — 28 × 28 이미지라면 784개 숫자를 한 줄로 나열해서 — 신경망에 통째로 넣는 것이었다. "데이터를 충분히 넣으면, 기계가 알아서 패턴을 찾아낼 것이다."
결과는 참담했다.
이유는 명확하다. 이미지를 1차원으로 펼치는 순간, 공간 구조가 파괴된다. 원래 이미지에서 서로 이웃한 픽셀 — 고양이 귀의 윤곽을 이루는 픽셀들 — 은 1차원 벡터에서는 아무런 관계가 없는 먼 위치에 흩어진다. "7"의 가로획을 이루는 픽셀이 세로획을 이루는 픽셀과 어떤 공간적 관계에 있는지, 모델은 알 방법이 없다. 마치 직소 퍼즐 조각을 무작위로 섞어놓고 완성된 그림을 맞추라는 것과 같다 — 조각들의 색은 알 수 있지만, 어떤 조각이 어떤 조각 옆에 있어야 하는지는 모른다.
더 치명적인 문제도 있었다. 이미지 해상도가 조금만 올라가면 파라미터 수가 폭발적으로 증가했다. 224 × 224 컬러 이미지를 완전연결 신경망(Fully Connected Network)에 넣으면, 첫 번째 은닉층의 뉴런이 1,000개만 되어도 입력 가중치만 1억 5천만 개에 달한다. 1960년대 컴퓨터로는 꿈도 꿀 수 없는 규모였고, 사실 2020년대의 기준으로도 비효율적이다.
AI 연구자들은 근본적인 질문 앞에 서게 되었다.
"이미지의 공간 구조를 보존하면서 패턴을 학습하는 방법은 없는가?"
답은 의외의 곳에서 왔다. 컴퓨터 과학이 아니라, 신경과학 실험실에서.
1959년, 존스 홉킨스 대학교의 신경생리학자 David Hubel과 Torsten Wiesel은 놀라운 실험을 수행했다. 그들은 마취된 고양이의 시각 피질(visual cortex)에 미세 전극을 삽입하고, 고양이의 눈앞에 다양한 빛 자극을 비추면서 개별 뉴런의 반응을 기록했다.
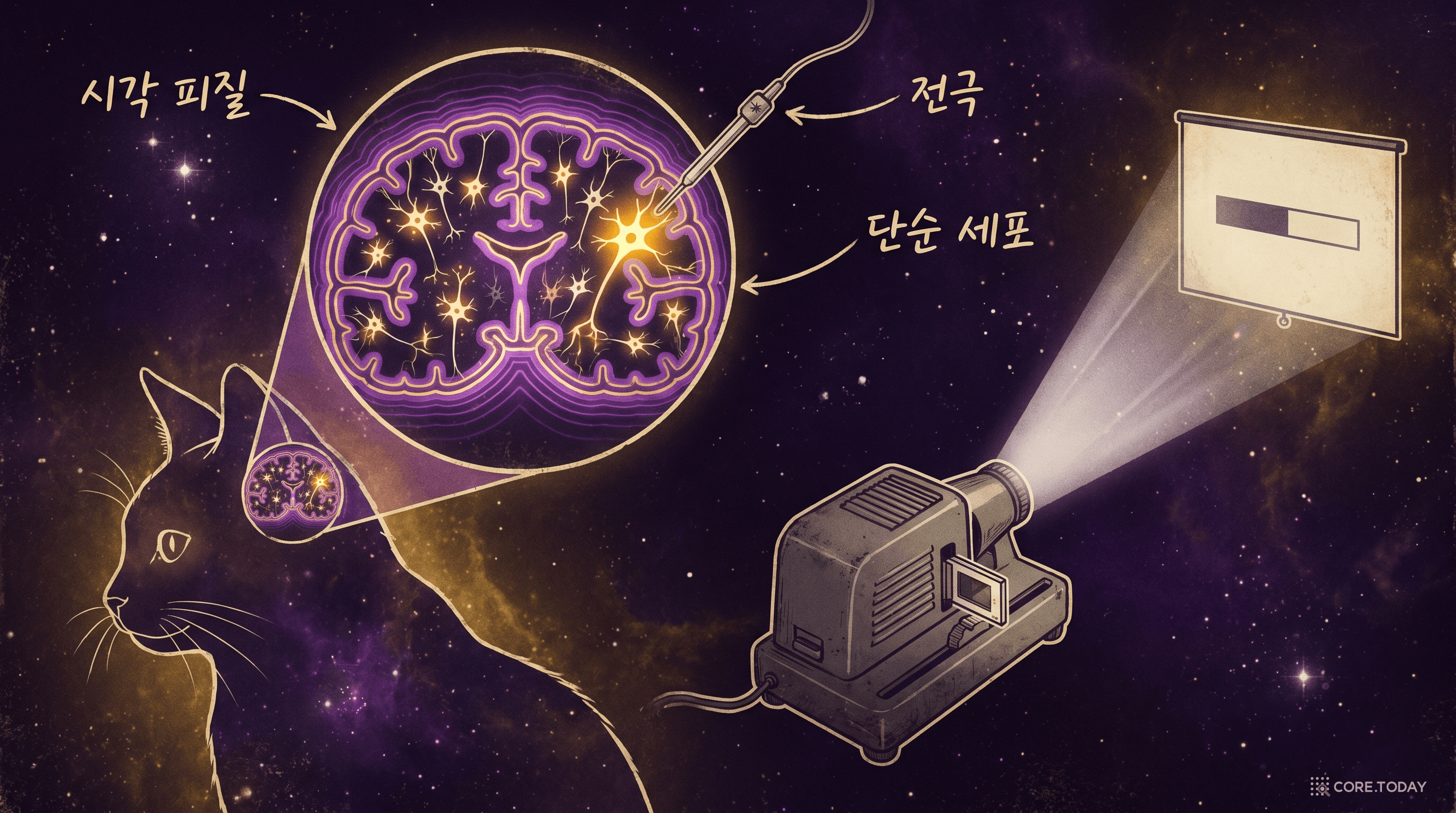
처음에는 점(dot) 형태의 빛을 사용했다. 뉴런은 거의 반응하지 않았다. 동그란 반점, 넓은 면적의 빛 — 역시 무반응이었다. 연구가 교착 상태에 빠질 무렵, 실험 장비의 우연한 오작동이 돌파구를 열었다. 슬라이드 프로젝터에 끼운 유리 슬라이드의 가장자리가 특정 각도의 직선 그림자를 만들었고, 그 순간 뉴런이 폭발적으로 반응한 것이다.
Hubel과 Wiesel은 흥분했다. 그들은 체계적으로 빛의 형태, 방향, 위치를 바꾸어가며 실험을 반복했다. 수 년간의 실험을 통해, 그들은 시각 피질에 관한 세 가지 혁명적인 발견을 이끌어냈다.
시각 피질의 뉴런은 눈에 들어오는 전체 시야에 반응하지 않았다. 각 뉴런은 시야의 특정 영역에만 반응했다. Hubel과 Wiesel은 이 영역을 수용야(receptive field)라고 불렀다.
이것은 직관과 어긋나는 발견이었다. 우리는 눈을 뜨면 세상을 "한꺼번에" 보는 것 같지만, 뇌의 개별 뉴런은 그렇지 않았다. 각 뉴런은 자기만의 작은 창문을 통해 세상의 일부만 내다보고 있었다. 마치 바둑판에서 각 기사가 자기 주변의 몇 칸만 감시하는 것처럼.
수용야 안에서 뉴런이 무엇에 반응하는지도 매우 구체적이었다. Hubel과 Wiesel이 단순 세포(simple cell)라고 명명한 뉴런들은 특정 방향의 선분(edge)에만 강하게 반응했다. 수직 선분에 반응하는 뉴런, 45도 기울어진 선분에 반응하는 뉴런, 수평 선분에 반응하는 뉴런이 각각 따로 존재했다. 같은 선분이라도 방향이 20도만 어긋나면 반응이 급격히 줄어들었다.
뇌는 이미지를 통째로 해석하는 것이 아니었다. 작은 영역에서 가장 기본적인 특징 — 선분과 엣지 — 을 먼저 감지하고 있었다.
가장 놀라운 발견은 세 번째였다. 시각 피질의 뉴런들이 계층 구조(hierarchy)를 이루고 있었던 것이다.
가장 아래 단계의 단순 세포는 특정 위치에서 특정 방향의 선분을 감지했다. 그 위 단계의 복합 세포(complex cell)는 여러 단순 세포의 출력을 조합해서, 위치가 약간 달라져도 같은 패턴을 인식할 수 있었다. 더 위의 초복합 세포(hypercomplex cell)는 복합 세포들의 출력을 조합해서 꺾인 선, 특정 길이의 선분, 움직이는 패턴 같은 더 복잡한 특징을 감지했다.
정리하면 이런 구조다. 단순한 특징이 조합되어 더 복잡한 특징이 되고, 그것이 다시 조합되어 더 높은 수준의 인식이 된다.
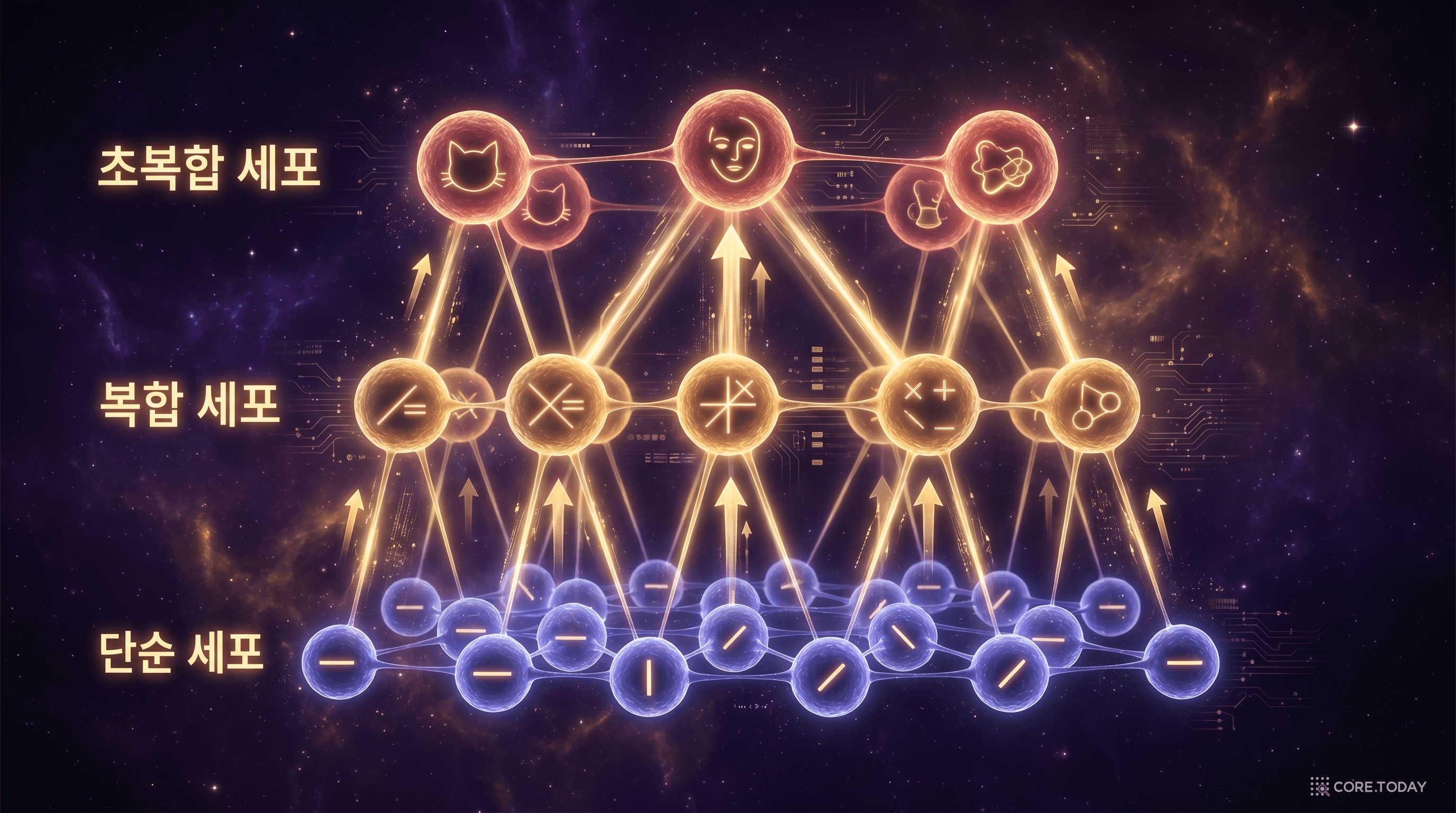
선분 → 모서리 → 윤곽 → 형태 → 물체. 고양이의 뇌는 이미지를 단계적으로, 점진적으로, 계층적으로 처리하고 있었다. 고양이의 눈앞에 "생선"이 나타나면, 뇌의 가장 낮은 층위에서는 생선의 윤곽을 이루는 선분들이 감지되고, 중간 층위에서는 그 선분들이 조합되어 생선의 형태가 구성되며, 높은 층위에서 비로소 "저것은 생선이다(먹어야 한다)"라는 인식이 완성되는 것이다.
Hubel과 Wiesel의 연구는 1960년대 초에 핵심 논문들이 발표된 이후 계속 확장되었고, 1981년 노벨 생리의학상으로 결실을 맺었다. 시각 정보 처리에 관한 이해를 근본적으로 바꿔놓은 업적이었다.
그런데 이 발견에서 공학적 통찰을 끌어낼 수 있다. Hubel과 Wiesel의 발견을 한 문장으로 압축하면 이렇다.
"전체를 한꺼번에 보려 하지 마라. 작은 영역에서 단순한 특징을 먼저 감지하고, 그것들을 조합하여 점점 복잡한 패턴을 인식하라."
이 원리가 바로, 수십 년 뒤 합성곱 신경망(Convolutional Neural Network, CNN)의 핵심 설계 철학이 된다.
전체를 한꺼번에 처리하려다 실패했던 1960년대의 접근법에 대한 답이 여기에 있었다. 이미지를 1차원으로 펼치지 말고, 2차원 공간 구조를 그대로 유지한 채, 작은 영역(수용야)을 슬라이딩하며 특징을 추출하고, 추출된 특징을 계층적으로 조합해 나가면 된다. 단순 세포가 하는 일을 첫 번째 층이, 복합 세포가 하는 일을 두 번째 층이, 초복합 세포가 하는 일을 세 번째 층이 담당하는 인공 신경망.
물론, 생물학적 발견에서 실제로 작동하는 컴퓨터 알고리즘이 나오기까지는 아직 긴 여정이 남아 있었다. 다음 장에서는 이 신경과학적 영감이 어떻게 수학적 구조로 변환되었는지 — 네오코그니트론에서 LeNet까지 — 를 살펴본다.
Hubel과 Wiesel의 발견은 신경과학 교과서에 실렸지만, 그 자체로는 컴퓨터를 "보게" 만들 수 없었다. 생물학적 원리를 수학적 모델로 번역하고, 그 모델이 실제로 학습할 수 있도록 알고리즘을 설계하는 작업이 필요했다. 이 번역 작업에 두 명의 핵심 인물이 등장한다.
첫 번째 인물은 일본 NHK 방송기술연구소의 Kunihiko Fukushima(후쿠시마 쿠니히코)다. 그는 Hubel과 Wiesel의 논문을 읽고 곧바로 공학적 질문을 던졌다. "단순 세포와 복합 세포의 계층 구조를 인공 신경망으로 구현할 수 있지 않을까?"
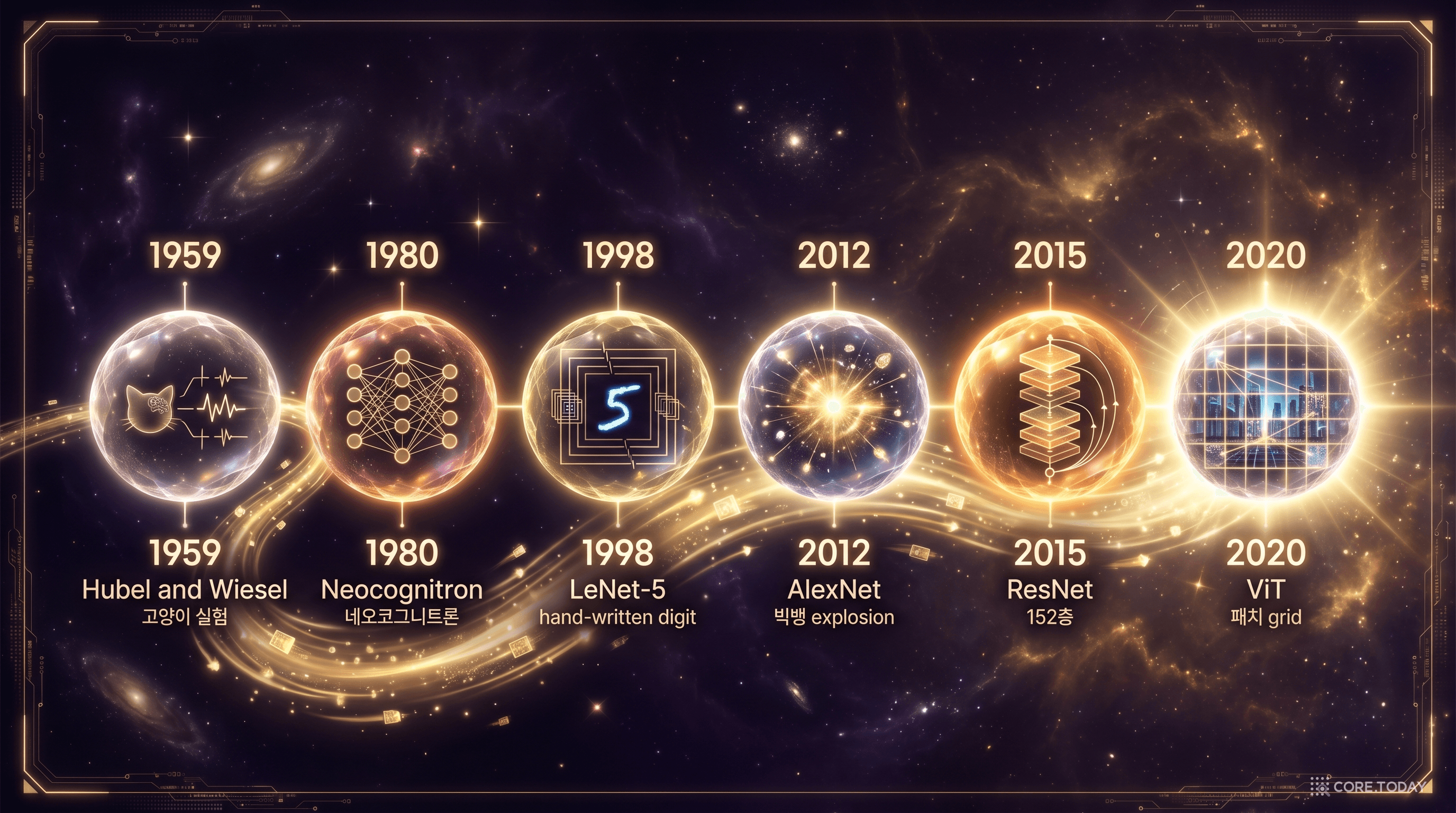
1980년, Fukushima는 네오코그니트론(Neocognitron)이라는 모델을 발표했다. 이름부터 "새로운 인지 기계"라는 야심이 묻어나는 이 모델은, 시각 피질의 구조를 놀라울 정도로 충실하게 재현했다.
네오코그니트론의 구조는 두 종류의 인공 세포가 교대로 쌓인 계층이었다. S-cell(단순 세포)은 입력의 작은 영역에서 특정 패턴을 감지했다 — Hubel과 Wiesel의 단순 세포를 그대로 모방한 것이다. C-cell(복합 세포)은 여러 S-cell의 출력을 통합하여, 패턴의 위치가 약간 변해도 동일한 특징으로 인식할 수 있게 했다. S-cell → C-cell → S-cell → C-cell로 층이 깊어질수록, 감지하는 특징은 점점 복잡해졌다. 첫 번째 S-cell 층은 선분을 감지하고, 두 번째 S-cell 층은 선분의 조합(모서리, 곡선)을 감지하며, 최종 층에서는 전체 패턴을 인식했다.
Fukushima는 이 모델로 손글씨 숫자 인식 실험을 수행했고, 일부 의미 있는 결과를 얻었다. 숫자의 크기나 위치가 약간 변해도 인식에 성공한 것이다.
하지만 네오코그니트론에는 치명적인 한계가 있었다. Fukushima는 비지도학습(unsupervised learning) 방식을 사용했다. 정답 레이블 없이, 네트워크가 스스로 특징을 발견하도록 한 것이다. 당시에는 역전파(backpropagation) 알고리즘이 아직 널리 알려지지 않았기 때문에 어쩔 수 없는 선택이었다. 결과적으로 학습이 불안정했고, 조금만 복잡한 패턴이 등장하면 성능이 급격히 떨어졌다. 실용적인 시스템으로 발전하기에는 역부족이었다.
그럼에도 네오코그니트론의 역사적 의의는 분명하다. 이 모델은 "작은 영역을 보는 필터를 계층적으로 쌓는다"는 CNN의 핵심 아이디어를 최초로 구현했다. 네오코그니트론이 설계도라면, 다음에 등장할 모델이 그 설계도로 실제 집을 짓는 역할을 하게 된다.
두 번째 인물은 프랑스 출신의 젊은 연구자 Yann LeCun(얀 르쿤)이다. 현재 Meta AI의 수석 과학자이자 2018년 튜링상 수상자인 LeCun은, 1980년대 후반 AT&T 벨 연구소에서 일하며 역사적인 돌파구를 만들었다.
LeCun의 핵심 통찰은 단순하면서도 강력했다. 네오코그니트론의 계층적 구조에 역전파 알고리즘을 결합한 것이다. 1986년 David Rumelhart 등이 역전파를 널리 알린 이후, LeCun은 이 학습 알고리즘이야말로 Fukushima의 모델에 빠져 있던 마지막 퍼즐 조각임을 알아챘다. 정답과의 오차를 계산하고, 그 오차를 네트워크 전체에 역방향으로 전파하여 가중치를 조정하는 이 알고리즘은 — 네오코그니트론의 불안정한 비지도학습을 완전히 대체할 수 있었다.
1989년 첫 번째 합성곱 신경망 논문을 발표한 LeCun은 이후 약 10년간 모델을 발전시켜, 1998년에 기념비적인 논문 "Gradient-Based Learning Applied to Document Recognition"을 발표했다. 이 논문에서 소개된 모델이 바로 LeNet-5다.
LeNet-5의 구조는 현대 CNN의 원형(prototype)이라 할 수 있다.
입력 이미지에 합성곱 필터를 적용하고, 풀링으로 크기를 줄이고, 다시 합성곱과 풀링을 반복한 뒤, 완전 연결 층으로 최종 분류하는 이 구조. Conv → Pool → Conv → Pool → FC → 출력. 2026년 현재의 최신 CNN 모델들도 이 기본 골격 위에 세워져 있다.
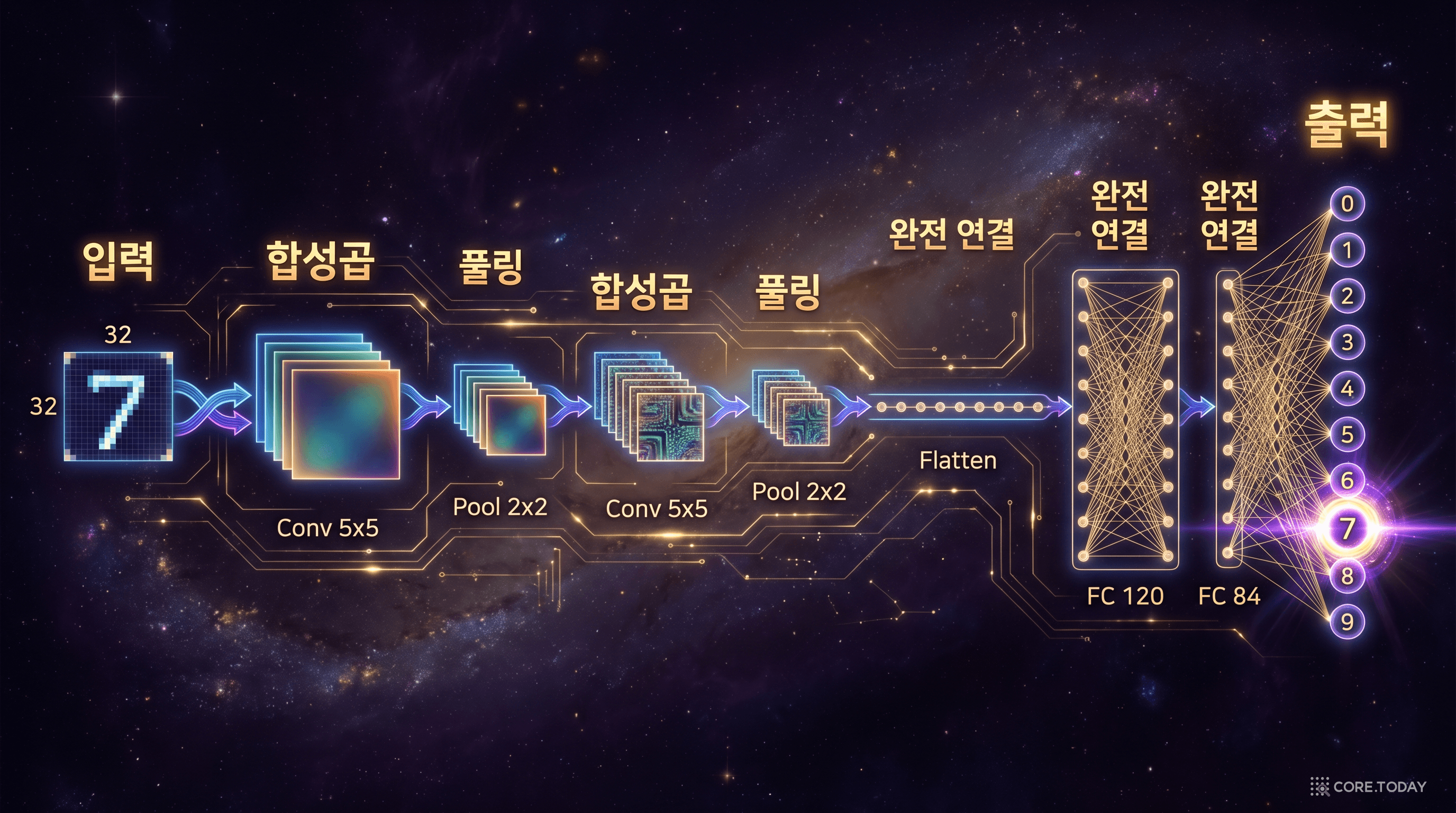
LeCun의 LeNet-5는 학계의 논문으로만 끝나지 않았다. AT&T에서 이 모델을 미국 우편 시스템의 수표 인식에 실제 적용했고, 한때 미국 전체 수표의 10% 이상을 이 시스템이 처리했다. 이론이 현실의 비즈니스 가치를 만들어낸 것이다. 네오코그니트론이 설계도였다면, LeNet-5는 사람들이 실제로 입주하여 생활하는 집이었다.
LeNet-5의 성공에도 불구하고, CNN은 주류 기술이 되지 못했다. 그 이유는 알고리즘의 문제가 아니었다. 두 가지 근본적인 자원이 부족했다.
첫째, 컴퓨팅 파워가 부족했다. LeNet-5는 32 × 32 크기의 작은 흑백 이미지를 처리했지만, 실제 세계의 이미지는 그보다 수백 배 크고 컬러였다. 1990년대 컴퓨터로 고해상도 컬러 이미지에 여러 층의 합성곱을 적용하려면, 학습에 수 주에서 수 개월이 걸렸다. GPU를 범용 연산에 활용하는 GPGPU 개념이 등장하기 전이었다.
둘째, 대규모 데이터셋이 없었다. 딥러닝 모델은 수만에서 수백만 장의 레이블링된 이미지를 필요로 하지만, 당시에는 그런 규모의 데이터셋을 구축할 인프라도, 동기도 부족했다. MNIST(6만 장의 손글씨 숫자) 정도가 가용한 최대 규모였다.
이 시기에 머신러닝 커뮤니티의 주류는 SVM(Support Vector Machine), Random Forest, Boosting 같은 전통적 방법들이었다. 이들은 사람이 설계한 특징(hand-crafted features) — 예를 들어 이미지의 색상 히스토그램이나 SIFT 기술자 — 을 먼저 추출하고, 그 특징 벡터에 대해 분류를 수행했다. 특징 추출과 분류가 분리된 파이프라인 방식이었다. 정교하게 설계한 특징은 놀라운 성능을 보였고, 학계에서는 "특징을 자동으로 학습한다"는 신경망의 접근이 불필요하게 느껴졌다.
CNN은 학계의 극히 일부 — LeCun의 연구 그룹과 몇몇 추종자들 — 에서만 명맥을 유지했다. 마치 겨울잠에 든 동물처럼, 에너지(컴퓨팅 파워)와 식량(데이터)이 충분해질 봄을 기다리며 잠들어 있었다.
그 봄은 2012년에 온다. ImageNet이라는 거대한 데이터셋과 GPU라는 강력한 연산 엔진을 만난 CNN이 폭발적으로 깨어나는 순간 — AlexNet의 등장을 다루기 전에, 먼저 CNN이 정확히 어떻게 작동하는지를 해부해 보자.
지금까지 CNN의 역사적 배경을 살펴보았다. 이제 본격적으로 기술의 내부를 들여다볼 차례다. CNN이 이미지를 "보는" 과정은 여섯 가지 핵심 연산의 조합으로 이루어진다. 각각을 하나씩 분해해 보자.
CNN의 이름에 들어있는 합성곱이란 정확히 무엇인가?
비유부터 시작하자. 당신이 범죄 현장의 대형 사진을 조사하는 탐정이라고 상상하자. 사진 전체를 한눈에 보는 대신, 작은 돋보기를 사진 위에 올려놓고 좌상단부터 우하단까지 체계적으로 슬라이딩하며 살펴본다. 돋보기의 렌즈 — 이것이 바로 필터(filter) 또는 커널(kernel)이다. 보통 3×3 또는 5×5 크기의 작은 숫자 격자다.
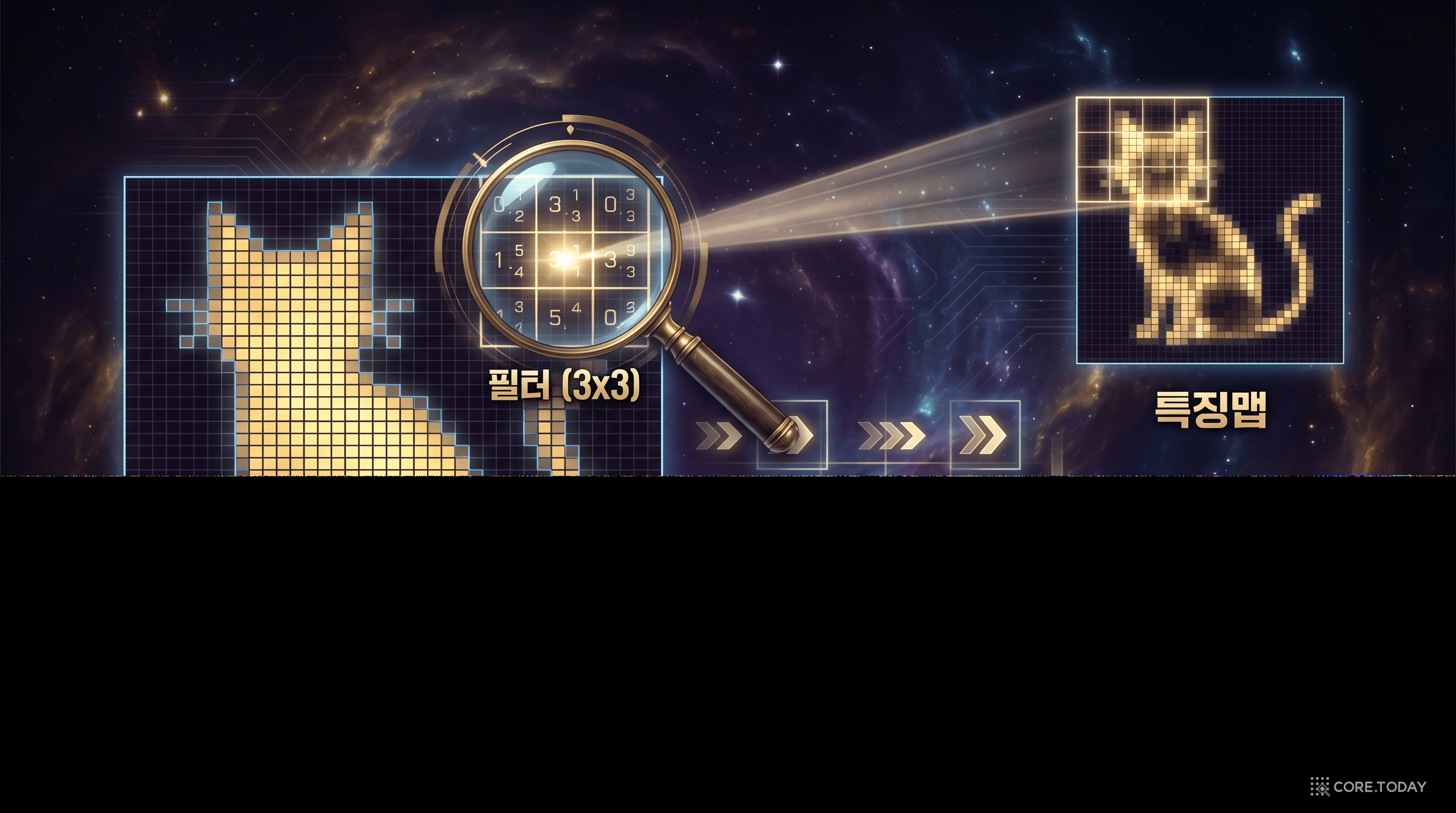
합성곱 연산은 이 필터를 이미지 위에서 한 칸씩 이동시키며, 필터와 겹치는 이미지 영역 사이의 요소별 곱의 합(element-wise multiplication + sum)을 계산하는 것이다. 수식으로 표현하면 다음과 같다.
여기서 는 입력 이미지, 는 필터(커널), 는 출력 위치다.
글로만 보면 추상적이다. 구체적인 예시를 보자. 3×3 필터가 5×5 입력 위를 슬라이딩하는 과정이다.
이 예시에서 필터는 대각선과 십자 패턴을 감지하는 역할을 한다. 입력 영역이 필터와 비슷한 패턴이면 높은 값(5)이 나오고, 전혀 다른 패턴이면 낮은 값(0)이 나온다. 이것이 바로 합성곱이 "특징을 감지"하는 원리다.
합성곱 연산을 제어하는 두 가지 중요한 하이퍼파라미터가 있다.
스트라이드(stride)는 필터가 한 번에 몇 칸씩 이동하는지를 결정한다. 위 예시에서는 stride=1, 즉 한 칸씩 이동했다. stride=2로 설정하면 두 칸씩 건너뛰므로 출력 크기가 절반으로 줄어든다. 보폭이 넓어지는 것이다.
패딩(padding)은 입력 이미지 테두리에 0을 채워 넣는 기법이다. 패딩 없이 3×3 필터를 5×5 입력에 적용하면 출력은 3×3이 된다 — 테두리 픽셀의 정보가 손실되는 것이다. 입력과 동일한 크기의 출력을 얻고 싶다면 1픽셀의 패딩을 추가한다(same padding).
합성곱이 전통적 신경망보다 강력한 이유는 두 가지 핵심 속성에 있다.
첫째, 파라미터 공유(parameter sharing)다. 하나의 3×3 필터는 단 9개의 가중치만 가지고, 이 9개의 가중치가 이미지의 모든 위치에서 동일하게 사용된다. 224 × 224 이미지에 완전 연결 층을 사용하면 수천만 개의 가중치가 필요하지만, 합성곱은 필터 크기만큼의 가중치로 충분하다. 파라미터 수가 수천 배 줄어든다.
둘째, 희소 연결(sparse connectivity)이다. 완전 연결 층에서는 모든 입력이 모든 출력에 연결되지만, 합성곱에서는 각 출력 뉴런이 입력의 작은 영역(수용야)만 참조한다. 이것은 Hubel과 Wiesel이 발견한 생물학적 시각 시스템의 수용야를 정확히 모방한 것이다.
하나의 필터는 하나의 특징만 감지할 수 있다. 가로 엣지를 감지하는 필터는 세로 엣지를 놓치고, 세로 엣지를 감지하는 필터는 대각선을 놓친다. 그래서 CNN은 여러 개의 필터를 동시에 적용한다.
각 필터가 입력 이미지 전체를 슬라이딩하며 만들어내는 출력을 특징맵(feature map)이라 한다. 필터가 32개면 특징맵도 32개가 생성된다. 첫 번째 합성곱 층에서 입력 이미지 하나가 32개의 서로 다른 특징맵으로 변환되는 것이다.
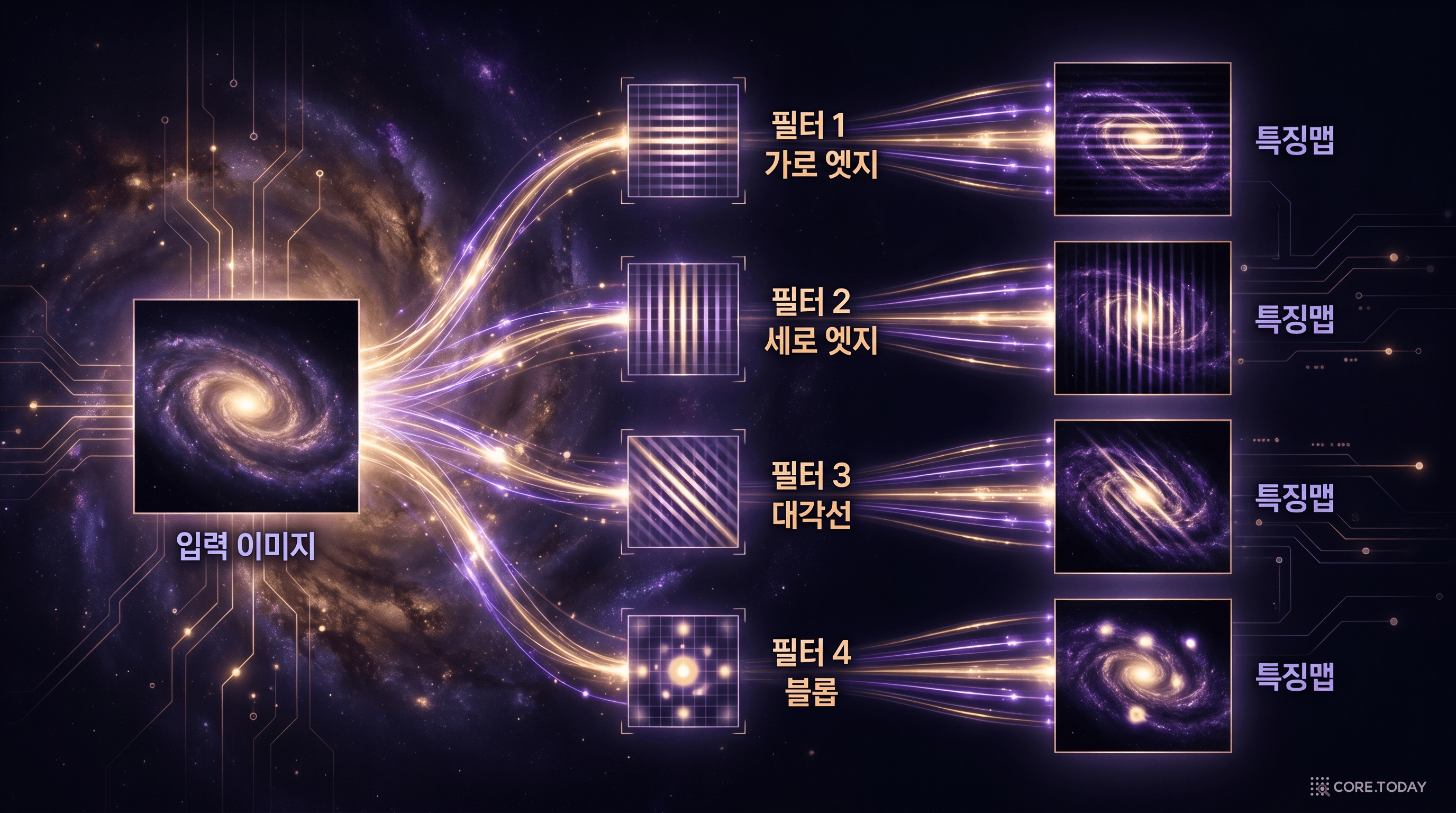
28 × 28 입력에 3×3 필터를 패딩 없이 적용하면 26 × 26 특징맵이 생성된다. 핵심은, 이 필터의 값(가중치)이 학습을 통해 자동으로 결정된다는 점이다. 사람이 "이 필터는 가로선을 감지해라"라고 지정하지 않는다. 네트워크가 역전파를 통해 수천 장의 이미지를 보면서, 분류 성능을 최대화하는 방향으로 필터 값을 스스로 조정한다. 이것이 전통적 머신러닝의 "수작업 특징 설계"와 딥러닝의 근본적 차이다.
합성곱 연산의 출력은 양수일 수도, 음수일 수도 있다. 필터와 입력 영역이 잘 매칭되면 큰 양수가 나오고, 반대 패턴이면 음수가 나온다. 여기서 활성화 함수(activation function)가 개입한다.
현대 CNN에서 가장 널리 쓰이는 활성화 함수는 놀라울 정도로 단순하다.
양수는 그대로 통과시키고, 음수는 0으로 만든다. 그것이 전부다. 비유하자면, 건물 입구의 문지기와 같다. 관련 있는 신호(양수)는 통과시키고, 관련 없는 신호(음수)는 차단한다. "이 영역에 가로선이 있다"는 양수 신호는 살아남고, "가로선이 없다"는 음수 신호는 0으로 눌린다.
왜 하필 이렇게 단순한 함수를 쓸까? 그 이전에 주로 사용되던 시그모이드(sigmoid) 함수와 비교하면 답이 명확해진다. 시그모이드는 출력을 0과 1 사이로 부드럽게 압축하는데, 문제는 입력이 극단적으로 크거나 작을 때 기울기(미분값)가 거의 0에 수렴한다는 것이다. 역전파 과정에서 기울기가 층을 지날 때마다 곱해지는데, 0에 가까운 값이 계속 곱해지면 기울기가 사실상 사라진다. 이것이 악명 높은 기울기 소실(vanishing gradient) 문제다. 네트워크가 5층, 10층으로 깊어지면 앞쪽 층의 가중치는 거의 업데이트되지 않아 학습이 멈춰버린다.
ReLU는 양수 영역에서 기울기가 항상 1이다. 아무리 깊은 네트워크에서도 기울기가 소실되지 않는다. 이 단순한 속성이 CNN의 층 수를 극적으로 늘릴 수 있게 만든 핵심 요인이다. 5층짜리 LeNet에서 152층짜리 ResNet으로 도약할 수 있었던 배경에는 ReLU가 있다.
합성곱과 ReLU를 거치면 특징맵이 생성된다. 하지만 이 특징맵은 여전히 입력과 비슷한 크기다. 여기서 풀링(pooling) 연산이 등장한다.
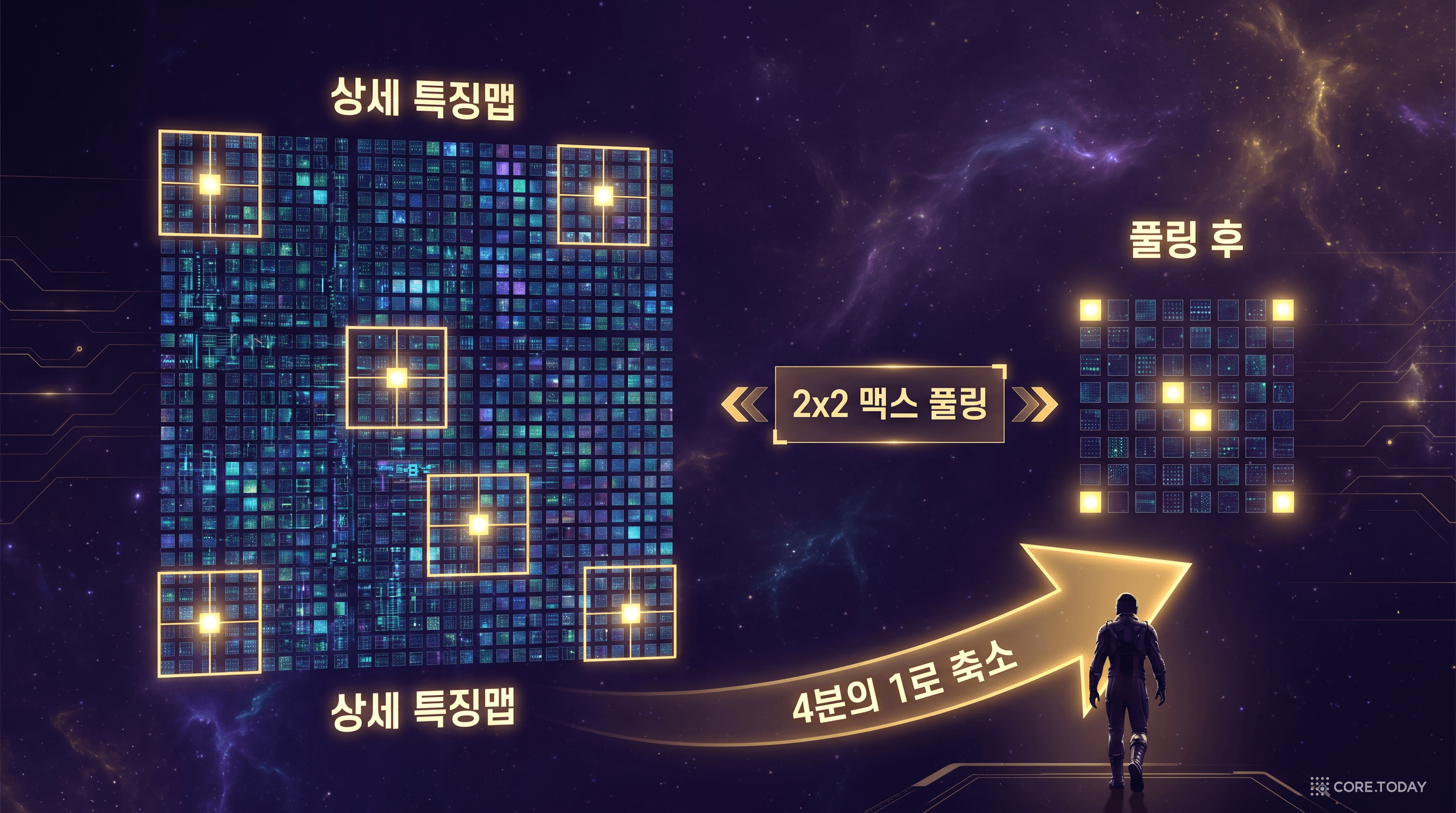
가장 널리 쓰이는 맥스 풀링(Max Pooling)은 특징맵을 작은 영역(보통 2×2)으로 나누고, 각 영역에서 가장 큰 값만 남긴다.
비유하자면, 숲을 보기 위해 한 발짝 뒤로 물러서는 것이다. 나뭇잎 하나하나의 세부 디테일은 포기하지만, 나무의 전체적인 형태와 위치는 더 잘 보이게 된다.
풀링의 효과는 두 가지다.
첫째, 위치 불변성(translation invariance)을 제공한다. 고양이가 사진의 왼쪽에 있든 오른쪽에 있든, 풀링을 거치면 "고양이의 귀가 있다"는 정보는 보존되면서 정확한 위치 정보는 약간 흐려진다. 덕분에 대상의 위치가 달라져도 동일하게 인식할 수 있다.
둘째, 차원 축소로 계산량을 줄인다. 2×2 맥스 풀링은 특징맵의 가로·세로를 각각 절반으로 줄이므로, 데이터 크기가 4분의 1로 감소한다. 다음 층의 합성곱 연산이 훨씬 가벼워진다.
Hubel과 Wiesel의 발견을 떠올려보면, 풀링은 복합 세포(complex cell)의 역할과 정확히 대응한다. 복합 세포가 여러 단순 세포의 출력을 종합하여 위치에 덜 민감한 표현을 만들었듯이, 풀링 층은 합성곱의 출력을 종합하여 위치 변화에 강건한 특징을 만든다.
합성곱, ReLU, 풀링을 여러 번 반복하면, 입력 이미지는 작지만 의미 있는 특징들의 집합으로 변환된다. 이제 이 특징들을 종합하여 최종 결론을 내릴 차례다. 이 역할을 하는 것이 완전 연결 층(Fully Connected Layer, FC)이다.
비유하자면, 합성곱 층들이 증거를 수집하는 수사관이라면, FC 층은 모든 증거를 종합하여 판결을 내리는 판사다.
FC 층에 데이터를 넣기 위해서는 먼저 Flatten(평탄화) 과정이 필요하다. 예를 들어 마지막 풀링 층의 출력이 7 × 7 × 64(7×7 크기의 특징맵 64개)라면, 이를 3,136개의 숫자가 일렬로 나열된 1D 벡터로 변환한다. 이제 이 벡터가 FC 층의 입력이 된다.
최종 FC 층의 출력에는 Softmax 함수가 적용되어 클래스별 확률을 만들어낸다.
예를 들어 10개의 숫자를 분류하는 모델이라면, Softmax는 [0.01, 0.02, 0.05, 0.80, 0.01, 0.03, 0.02, 0.03, 0.02, 0.01] 같은 확률 분포를 출력한다. 가장 높은 확률을 가진 클래스(여기서는 "3")가 모델의 예측이 된다.
현대 CNN에서 한 가지 더 빼놓을 수 없는 구성요소가 있다. 배치 정규화(Batch Normalization)다. 2015년 Ioffe와 Szegedy가 발표한 이 기법은, 각 층의 입력 분포를 정규화하여 학습을 안정화시킨다. 깊은 네트워크에서 앞쪽 층의 가중치가 바뀔 때마다 뒤쪽 층의 입력 분포가 흔들리는 문제(내부 공변량 이동, internal covariate shift)를 해결한 것이다. 배치 정규화 덕분에 학습률을 더 크게 설정할 수 있고, 학습 속도가 대폭 빨라진다. 오늘날 거의 모든 CNN 아키텍처에 배치 정규화가 포함되어 있다.
이제 모든 조각을 맞춰보자. CNN의 전체 처리 흐름은 다음과 같다.
입력 이미지가 합성곱-ReLU-풀링 블록을 여러 번 통과하며, 각 단계에서 점점 더 추상적인 특징이 추출된다. 마지막으로 FC 층이 추출된 특징을 종합하고, Softmax가 최종 확률을 출력한다.
이 파이프라인에서 가장 흥미로운 현상은, 층이 깊어질수록 특징의 추상화 수준이 체계적으로 올라간다는 것이다.

숲에 비유하면 이렇다. 첫 번째 층은 나뭇잎 하나하나의 윤곽을 본다. 중간 층은 나뭇잎들이 모여 이루는 나뭇가지의 패턴을 본다. 깊은 층은 나뭇가지들이 모여 이루는 나무 한 그루의 형태를 인식한다. 그리고 최종 층은 나무들이 모인 숲 전체를 파악한다.
이 계층적 특징 추출이야말로 CNN의 진정한 힘이다. 그리고 이것은 — 돌이켜보면 — Hubel과 Wiesel이 고양이의 시각 피질에서 발견한 "단순 세포 → 복합 세포 → 초복합 세포"의 계층 구조를 인공 신경망으로 재현한 것이다. 1959년의 생물학적 발견이 반세기 후에 디지털 세계에서 결실을 맺은 셈이다.
CNN의 내부 작동 원리를 이해했으니, 다음 장에서는 이 원리가 어떻게 세상을 뒤흔들었는지 — 2012년 AlexNet의 등장과 그로부터 시작된 딥러닝 혁명을 살펴본다.
CNN의 잠복기를 끝낸 것은 하나의 대회였다. ILSVRC(ImageNet Large Scale Visual Recognition Challenge) — 컴퓨터 비전의 올림픽이라 불리는 이 대회는 Stanford의 Fei-Fei Li 교수팀이 구축한 ImageNet 데이터셋을 기반으로 2010년부터 시작되었다.
규모부터 압도적이었다. 1,000개 카테고리, 120만 장의 학습 이미지, 5만 장의 검증 이미지, 10만 장의 테스트 이미지. 개와 고양이 수준의 단순 분류가 아니었다. "시베리안 허스키"와 "알래스칸 말라뮤트"를 구분해야 했고, "앵무새"와 "큰부리새"를 구별해야 했다. 인간에게도 쉽지 않은 과제였다.
평가 지표는 Top-5 에러율이었다. 모델이 한 이미지에 대해 확률이 높은 상위 5개 클래스를 예측하고, 그 5개 안에 정답이 없을 확률을 측정한다. "이 사진은 시베리안 허스키(35%), 알래스칸 말라뮤트(25%), 에스키모 도그(15%), 사모예드(12%), 허스키(8%)입니다"라고 예측했을 때, 정답이 이 5개 안에 있으면 맞힌 것으로 인정하는 관대한 기준이다. 그런데도 2010년과 2011년, 전통적 머신러닝 방법론이 달성한 최고 성적은 28%대 에러율에 머물렀다. 이미지 4장 중 1장 이상에서 상위 5개 예측 안에도 정답을 넣지 못한 것이다.
SVM 기반 파이프라인, 수작업으로 설계한 SIFT와 HOG 특징 기술자, 복잡한 앙상블 기법. 연구자들은 매년 1~2%포인트의 성능 향상을 위해 치열하게 경쟁했다. 그리고 2012년, 모든 것이 바뀌었다.
2012년 ILSVRC의 우승자는 토론토 대학교의 Alex Krizhevsky, Ilya Sutskever, 그리고 그들의 지도교수 Geoffrey Hinton이었다. 그들의 논문 "ImageNet Classification with Deep Convolutional Neural Networks"에서 소개된 모델은 제1저자의 이름을 따 AlexNet으로 불리게 된다.
결과부터 말하자. AlexNet의 Top-5 에러율은 15.3%였다. 2위는 전통적 방법론을 사용한 팀으로 26.2%였다. 10.8%포인트 차이. 이 격차가 얼마나 충격적이었는지, 비유를 하나 들어보자. 올림픽 마라톤에서 1등과 2등의 차이는 보통 몇 초에서 몇 분이다. 그런데 어느 날 1등이 2등보다 42분 앞서 결승선을 통과했다고 상상해보라. "저 선수는 뭔가 다른 것을 하고 있다"는 것이 즉시 명백해진다. AlexNet의 등장이 그랬다.
AlexNet의 혁신은 네 가지로 압축된다.
첫째, GPU 학습이다. AlexNet은 NVIDIA GTX 580 GPU 2개를 병렬로 사용하여 학습했다. 당시 GPU를 신경망 학습에 본격적으로 활용한 최초의 대규모 사례였다. CPU로는 몇 주가 걸릴 학습을 GPU로 며칠 만에 완료할 수 있었다. 이것은 단순한 속도 향상이 아니라, 더 큰 모델을 더 많은 데이터로 학습할 수 있다는 가능성의 문을 열어젖힌 것이다.
둘째, ReLU 활성화 함수다. 제4장에서 설명한 바로 그 함수다. AlexNet 이전에는 시그모이드나 tanh가 주류였는데, Krizhevsky 등은 ReLU를 사용함으로써 학습 속도를 6배 가량 높였다. 기울기 소실 문제 없이 8개 층의 깊은 네트워크를 효과적으로 학습시킬 수 있었다.
셋째, Dropout 정규화다. 학습 과정에서 무작위로 뉴런의 50%를 비활성화시키는 이 기법은, 네트워크가 특정 뉴런에 과도하게 의존하지 않도록 강제한다. 마치 축구팀이 연습 경기마다 주전 선수 절반을 무작위로 빼고 훈련하는 것과 같다. 모든 선수가 어떤 조합에서든 역할을 수행할 수 있게 되므로, 실전에서 팀 전체의 안정성이 올라간다. 이 단순한 트릭이 과적합(overfitting)을 효과적으로 방지했다.
넷째, 데이터 증강(data augmentation)이다. 원본 이미지를 좌우 반전, 무작위 자르기, 색상 변형 등으로 변형하여 학습 데이터를 인위적으로 늘렸다. 한 장의 고양이 사진에서 수십 가지 변형을 만들어내니, 실질적인 학습 데이터가 몇 배로 불어나는 효과가 있었다.
이 논문 하나가 AI의 방향을 바꿨다. 전통적 머신러닝의 "수작업 특징 설계 → 분류기" 파이프라인은 하룻밤 사이에 시대에 뒤처진 방법론이 되었고, 연구자들은 앞다투어 CNN으로 전환했다. 학계에서는 이 시점을 "딥러닝 빅뱅"이라 부른다.

AlexNet의 충격이 가시기도 전에, 옥스포드 대학교의 Karen Simonyan과 Andrew Zisserman이 2014년 "Very Deep Convolutional Networks for Large-Scale Image Recognition"을 발표했다. VGGNet이라 불리는 이 모델은 하나의 질문에서 출발했다. "네트워크를 더 깊게 만들면 어떻게 될까?"
VGGNet의 핵심 인사이트는 우아할 정도로 단순하다. 큰 필터 하나를 쓰는 대신, 3×3이라는 가장 작은 필터를 깊게 쌓는다. 3×3 필터 2개를 연속으로 적용하면 5×5 필터 하나와 같은 수용야를 갖고, 3개를 쌓으면 7×7 수용야와 동일해진다. 그런데 파라미터 수는 훨씬 적다.
왜 그럴까? 7×7 필터 하나의 파라미터 수는 $7 \times 7 = 49개다. 반면 3×3 필터 3개의 파라미터 수는 \3 \times 3 \times 3 = 27$개로, 거의 절반이다. 게다가 층이 3개이므로 비선형 활성화(ReLU)도 3번 적용되어 표현력이 더 풍부해진다. 적은 비용으로 더 강력한 모델을 만드는 셈이다.
VGG-16(16개의 가중치 층)과 VGG-19(19개 층)가 발표되었고, ILSVRC 2014에서 준우승을 차지했다. VGGNet은 "깊이(depth)가 곧 성능"이라는 명제를 강력하게 증명했다. 구조의 균일성과 직관성 덕분에, VGGNet은 오늘날까지 컴퓨터 비전 입문 교육에서 가장 먼저 소개되는 아키텍처 중 하나로 남아 있다.
같은 해, Google의 Christian Szegedy 등이 "Going Deeper with Convolutions"을 발표하며 완전히 다른 방향의 혁신을 제시했다. ILSVRC 2014 우승 모델인 GoogLeNet(Inception v1)이다.
VGGNet이 "더 깊게"를 추구했다면, GoogLeNet은 "더 넓게"를 추구했다. 핵심은 Inception 모듈이다. 하나의 입력에 대해 1×1, 3×3, 5×5 크기의 필터를 동시에 병렬로 적용하고, 그 결과를 합치는 구조다. 어떤 크기의 패턴이 중요할지 네트워크가 모르기 때문에, 여러 크기를 한꺼번에 보게 하자는 발상이었다.
여기에 한 가지 영리한 트릭이 추가된다. 3×3과 5×5 합성곱 앞에 1×1 합성곱을 배치하여 채널 수를 미리 줄이는 것이다. 1×1 합성곱이라고 하면 직관적이지 않지만, 이것은 본질적으로 채널 방향의 차원 축소다. 256개 채널을 64개로 압축한 뒤 3×3 합성곱을 적용하면, 계산량이 극적으로 감소한다.
결과는 인상적이었다. GoogLeNet은 22개 층으로 VGGNet보다 깊지만, 파라미터 수는 AlexNet의 1/12 수준에 불과했다. 적은 자원으로 더 높은 성능을 달성한, 효율의 승리였다.
네트워크를 깊게 쌓으면 성능이 좋아진다는 것은 VGGNet이 증명했다. 그렇다면 100층, 200층으로 쌓으면 어떨까? 직관적으로는 더 좋아져야 하지만, 현실은 그 반대였다.
Microsoft Research의 Kaiming He 등은 56층 네트워크가 20층 네트워크보다 오히려 성능이 떨어지는 현상을 관찰했다. 과적합이 아니었다. 학습 데이터에서도 성능이 떨어졌다. 이것이 바로 열화 문제(degradation problem)다. 층이 너무 깊어지면 최적화 자체가 어려워지는 것이다. 기울기가 소실되거나 폭발하면서 학습이 방향을 잃어버린다.
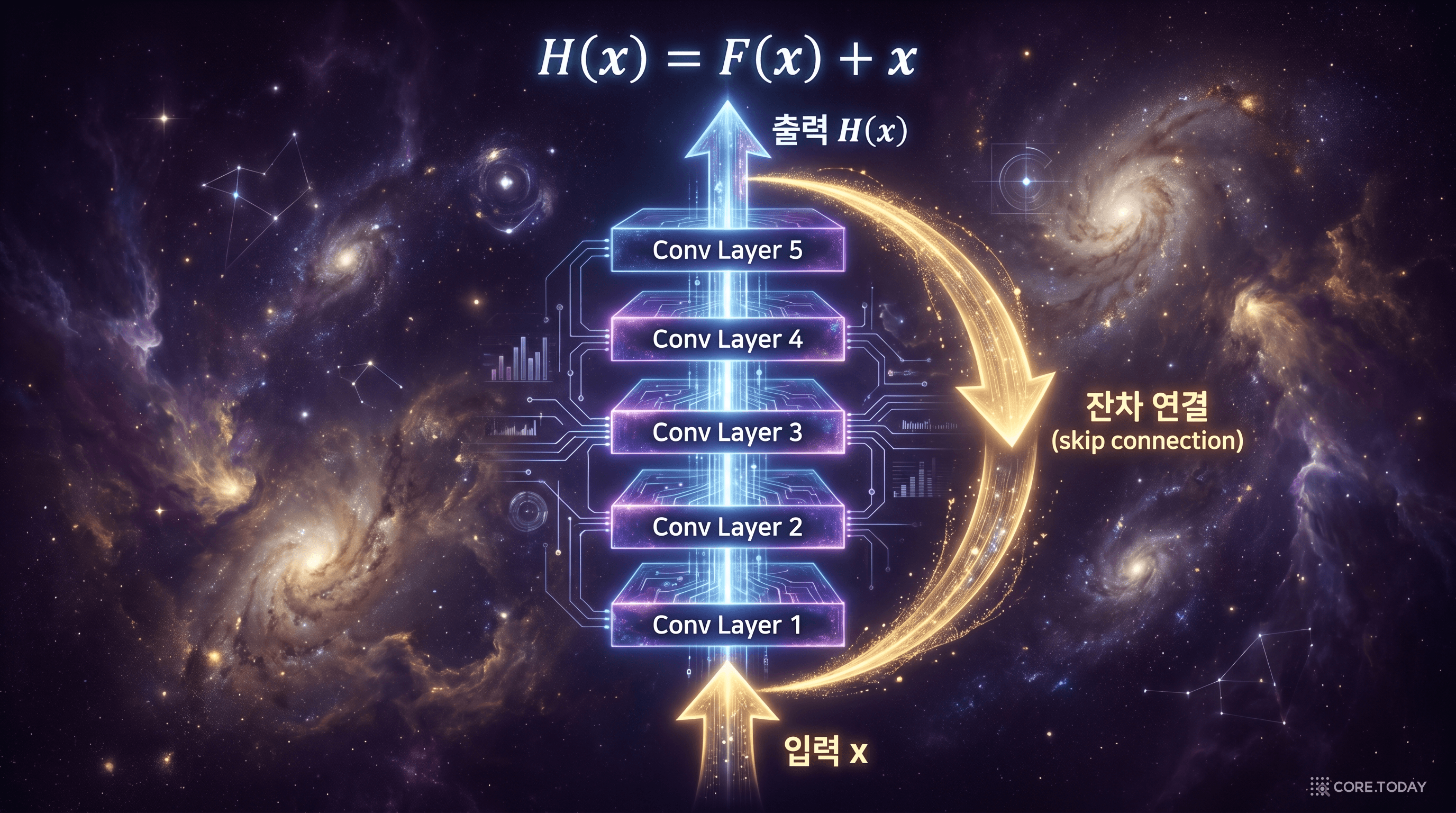
2015년, He 등은 "Deep Residual Learning for Image Recognition"에서 이 문제에 대한 우아한 해결책을 제시했다. 잔차 연결(skip connection, residual connection)이다. 아이디어는 놀라울 정도로 단순하다. 입력 가 몇 개의 합성곱 층을 통과하여 라는 출력을 만들면, 여기에 원래 입력 를 직접 더한다.
이것이 무엇을 의미하는지 비유로 설명해보자. 수학 시험에서 "이 미분방정식의 해를 구하시오"라는 문제가 나왔다고 하자. 답안을 처음부터 끝까지 쓰는 것은 매우 어렵다. 하지만 만약 모범 답안이 미리 적혀 있고, 당신이 할 일은 "모범 답안과의 차이점만 빨간 펜으로 수정하는 것"이라면? 문제가 훨씬 쉬워진다. 모범 답안이 완벽하면 아무것도 수정하지 않으면 되고(잔차 = 0), 약간의 수정이 필요하면 조금만 고치면 된다.
ResNet의 잔차 연결이 바로 이 원리다. 네트워크가 정답 를 직접 학습하는 대신, 정답과 입력의 차이(잔차) 만 학습한다. 대부분의 경우 잔차는 0에 가까우므로, 학습이 훨씬 안정적이고 효율적이다. 무엇보다, 잔차 연결은 기울기가 층을 "건너뛰어" 직접 전달되는 고속도로 역할을 한다. 152개 층을 쌓아도 기울기가 소실되지 않는다.
ResNet의 결과는 역사적이었다. 152층 네트워크가 ILSVRC 2015에서 Top-5 에러율 3.57%를 달성했다. 같은 테스트에서 인간의 Top-5 에러율은 약 5.1%로 알려져 있다. 기계가 인간의 시각 인식 능력을 처음으로 넘어선 순간이었다.
ResNet은 가장 많이 인용된 딥러닝 논문 중 하나가 되었고, 잔차 연결은 CNN을 넘어 Transformer, 음성 인식, 자연어 처리 등 거의 모든 딥러닝 아키텍처에 기본 구성요소로 자리 잡았다.
2011년부터 2015년까지, 불과 4년 만에 일어난 변화를 한눈에 보자.
2015년, 기계가 이미지 분류에서 인간의 성능을 처음으로 넘어섰다. 25.8%에서 3.57%로 — 에러율이 7분의 1로 줄어드는 데 걸린 시간은 고작 4년이었다. 이것은 AI 역사에서 전환점이 된 순간이다. "딥러닝이 진짜 작동한다"는 것이 누구도 부정할 수 없는 사실로 확립되었고, 학계와 산업계 모두에서 딥러닝에 대한 투자와 연구가 폭발적으로 증가했다. CNN이 겨울잠에서 깨어나 봄을 맞이한 정도가 아니었다. 한여름의 태양 아래 만개한 것이다.
그렇다면 이 기술이 연구실을 벗어나 실제 세상에서는 어떻게 활용되고 있을까?
학술 대회의 벤치마크 숫자는 인상적이지만, 기술의 진정한 가치는 그것이 사람들의 삶을 어떻게 바꾸는가에 있다. CNN은 이미 연구실을 넘어 병원, 도로, 공장, 그리고 당신의 주머니 속 스마트폰에 들어와 있다.
2017년, Stanford 대학의 Andre Esteva 등은 Nature에 획기적인 논문을 발표했다. CNN 모델에 13만 장의 피부 병변 이미지를 학습시킨 결과, 피부과 전문의 21명과 동등한 수준으로 피부암을 진단할 수 있었다는 내용이었다. 피부과 전문의가 되려면 의대 6년, 인턴 1년, 레지던트 4년 이상의 훈련이 필요하다. CNN은 수만 장의 이미지를 학습하는 것만으로 그에 필적하는 진단 능력을 갖추게 된 것이다.
유방촬영술(mammography) 분야에서도 CNN의 활약은 눈부시다. 2020년 Google Health 팀이 Nature에 발표한 연구에 따르면, AI 시스템이 유방암 조기 발견에서 방사선 전문의보다 11.5% 높은 정확도를 보였다. 유방암은 조기 발견 여부가 생존율을 결정적으로 가르는 질환이다. 1%의 정확도 향상이 수천 명의 생명을 구할 수 있다.
안저 검사에서의 활용도 주목할 만하다. 당뇨병 환자의 망막 혈관 사진을 CNN이 분석하여 당뇨성 망막 질환을 조기에 발견한다. 전문 안과의가 부족한 개발도상국에서, 스마트폰에 부착한 간단한 렌즈로 안저 사진을 찍고 AI가 원격으로 진단하는 시스템이 이미 배포되고 있다.
여기서 강조할 것이 있다. CNN 기반 의료 AI의 목표는 의사를 대체하는 것이 아니라, 의사에게 "제2의 눈"을 제공하는 것이다. 방사선 전문의가 하루에 수백 장의 영상을 판독하며 피로가 누적될 때, AI가 "이 영상에서 의심스러운 부분이 있습니다"라고 먼저 표시해주면 — 놓칠 수 있었던 미세한 병변을 발견할 확률이 높아진다. 인간의 전문성과 기계의 일관성이 결합된, 최선의 조합이다.
자율주행차의 "눈"은 카메라이고, 그 카메라 영상을 해석하는 "뇌"가 CNN이다. Tesla, Waymo 등의 자율주행 시스템은 카메라 1대의 영상을 초당 30~60프레임으로 처리하며, 각 프레임에서 보행자, 차선, 신호등, 다른 차량, 도로 표지판을 동시에 인식한다.
이 분야에서 특히 중요한 CNN 아키텍처가 YOLO(You Only Look Once) 계열이다. 기존의 객체 감지 모델이 "영역 제안 → 분류"의 두 단계를 거쳤다면, YOLO는 이미지 전체를 한 번만 보고(look once) 모든 객체의 위치와 클래스를 동시에 예측한다. 이 단일 패스 구조 덕분에 실시간 추론이 가능해졌다. 도로 위에서 0.1초의 지연은 사고로 이어질 수 있기에, 속도와 정확도를 동시에 달성하는 것이 자율주행 CNN의 핵심 과제다.
자율주행은 단순한 이미지 분류가 아니다. "저 물체가 무엇인가"뿐 아니라, "어디에 있는가", "어느 방향으로 움직이는가", "다음 순간 어디에 있을 것인가"까지 예측해야 한다. CNN은 이 모든 과제의 출발점이다.
반도체 웨이퍼에서 나노미터 수준의 결함을 찾아내는 일, 식품 생산 라인에서 이물질을 감지하는 일, 자동차 도장 면의 미세한 흠집을 발견하는 일 — 이 모든 분야에서 CNN이 인간 검사원을 보조하거나 대체하고 있다.
반도체 품질 검사에서 CNN의 정확도는 99.5%를 넘는다. 하지만 진정한 강점은 정확도가 아니라 일관성이다. 인간 검사원은 8시간 근무의 마지막 시간에 집중력이 떨어지고, 개인마다 판단 기준에 미세한 차이가 있다. CNN은 첫 번째 이미지와 백만 번째 이미지를 동일한 기준으로 판단한다. 24시간 무중단, 피로도 없고 감정의 영향도 없다. 공장 운영자에게 이것은 불량률 감소와 직결되며, 곧 비용 절감이자 경쟁력이다.
위에서 내려다보는 시선에도 CNN이 있다. Global Forest Watch 프로젝트는 위성 이미지에 CNN을 적용하여 전 세계의 산림 벌채를 실시간으로 모니터링한다. 아마존 열대우림의 불법 벌목이 일어나면, 위성이 촬영하고 CNN이 감지하여 수일 내에 경보를 발송한다.
농업에서는 드론과 위성이 촬영한 항공 이미지를 CNN이 분석하여 작물의 건강 상태를 평가한다. 병해충이 발생한 구역, 수분이 부족한 구역, 비료가 과다 투입된 구역을 자동으로 식별하여, 농부가 정밀 농업(precision agriculture)을 실현할 수 있게 돕는다.
재난 대응에서의 활용도 중요하다. 지진이나 태풍이 지나간 후, 피해 지역의 위성 이미지를 CNN이 분석하여 건물 손상도를 자동으로 분류한다. "완파", "반파", "경미한 손상", "무피해" — 인간이 현장을 돌아다니며 조사하려면 수일에서 수주가 걸리지만, CNN은 위성 이미지만으로 수시간 내에 피해 규모를 추정할 수 있다. 구조 인력의 배치와 구호물자의 배분에 결정적인 정보를 제공하는 것이다.
거창한 사례만 있는 것이 아니다. CNN은 이미 우리의 일상 깊숙이 들어와 있다.
스마트폰 얼굴 인식. iPhone의 Face ID가 당신의 얼굴을 인식하고 잠금을 해제할 때, CNN이 작동하고 있다. 안경을 쓰거나, 모자를 쓰거나, 어두운 곳에서도 — CNN은 수만 개의 얼굴 특징점을 추출하여 본인 여부를 판단한다.
사진 자동 분류. Google Photos에 사진을 올리면 "해변", "생일파티", "강아지"로 자동 분류되는 것, 특정 인물의 얼굴을 자동으로 그룹핑하는 것 — 모두 CNN이다.
OCR(광학 문자 인식). 영수증을 카메라로 찍으면 금액이 자동으로 인식되고, 명함을 촬영하면 연락처로 저장되는 기능. 문서의 글자를 인식하는 현대 OCR 시스템의 핵심에도 CNN이 있다.
실시간 카메라 번역. Google Translate 앱에서 카메라를 외국어 간판에 비추면, 실시간으로 한국어가 오버레이되는 마법 같은 기능. CNN이 문자를 감지하고, 인식하고, 그 위치에 번역 결과를 합성한다.
이처럼 CNN은 학술 논문의 벤치마크 숫자가 아니라, 우리 삶 곳곳에서 매일 수십억 번 작동하는 실용 기술이 되었다. 1959년 Hubel과 Wiesel이 고양이의 뇌에서 발견한 원리가, 반세기를 지나 인류의 일상을 바꾸고 있는 것이다.
CNN의 황금기를 이야기했다. ImageNet을 정복했고, 의료·자율주행·제조 현장에 깊이 뿌리내렸다. 그런데 2020년대에 접어들면서 컴퓨터 비전 분야에 거대한 지각변동이 일어났다. 자연어 처리(NLP) 세계를 평정한 Transformer가 비전 영역에도 발을 들인 것이다. CNN은 이제 과거의 유물이 된 걸까? 아니면 여전히 살아있는 기술인가? 2026년 현재의 풍경을 정직하게 그려본다.
2020년, Google Brain 팀의 Alexey Dosovitskiy 등이 한 편의 논문을 발표했다. 제목부터 도발적이었다 — "An Image is Worth 16×16 Words." 이미지 한 장이 16×16 단어들의 집합이라니, 무슨 뜻일까?
핵심 아이디어는 이렇다. 이미지를 16×16 픽셀 크기의 패치(patch)로 잘게 나눈다. 224×224 이미지라면 196개의 패치가 만들어진다. 각 패치를 하나의 "토큰"으로 취급하여, NLP에서 문장의 단어들을 처리하듯 Transformer 아키텍처에 입력한다. 문장에서 단어 간의 관계를 자기 주의(self-attention) 메커니즘으로 포착하듯, 이미지에서 패치 간의 관계를 동일한 메커니즘으로 포착하겠다는 것이다.
결과는 놀라웠다. 충분히 큰 데이터셋 — Google 내부의 JFT-300M (3억 장의 이미지) — 으로 사전학습한 ViT는 ImageNet에서 당시 최고 수준의 CNN을 능가하는 성능을 보였다. NLP에서 BERT와 GPT가 보여준 "스케일링의 마법"이 비전에서도 통한 것이다.
학계는 술렁였다. "합성곱 없이도 이미지를 이해할 수 있다"는 사실 자체가 패러다임의 전환이었다. CNN의 핵심 설계 원리 — 지역적 필터, 계층적 구조, 파라미터 공유 — 를 하나도 사용하지 않고, 오직 주의 메커니즘만으로 동등하거나 더 나은 성능을 달성한 것이니까. 일각에서는 "CNN의 시대가 끝났다"는 선언마저 나왔다.
하지만 현실은 그렇게 단순하지 않았다.
ViT의 논문을 자세히 읽으면, 저자들 스스로도 중요한 단서를 남겨놓았다. "중간 규모의 데이터셋(ImageNet 단독)으로 학습하면 ViT는 비슷한 크기의 ResNet에 미치지 못한다." 3억 장의 데이터가 있어야 비로소 CNN을 넘어선다는 것이다. 왜 그럴까?
답은 귀납적 편향(inductive bias)에 있다. CNN에는 두 가지 강력한 편향이 아키텍처 자체에 내장되어 있다. 첫째, 지역성(locality) — 필터가 인접한 픽셀만 함께 처리하므로, "가까운 픽셀은 관련이 있다"는 가정이 구조적으로 보장된다. 둘째, 이동 등변성(translation equivariance) — 동일한 필터가 이미지의 모든 위치에 적용되므로, "고양이 귀가 왼쪽에 있든 오른쪽에 있든 같은 방식으로 감지한다"는 속성이 자동으로 성립한다.
이 편향들은 사전 지식과 같다. 시험에 들어가기 전에 "이 과목에서 중요한 건 이런 것들이야"라는 귀띔을 받은 셈이다. 덕분에 적은 데이터로도 효율적으로 학습할 수 있다.
반면 ViT에는 이러한 편향이 거의 없다. 모든 패치가 첫 번째 층부터 다른 모든 패치와 관계를 맺을 수 있다 — 자유도가 훨씬 높지만, 그만큼 "무엇이 중요한지"를 데이터에서 처음부터 배워야 한다. 백지 상태에서 시작하는 것이다. 데이터가 충분하면 더 유연하고 강력한 표현을 학습할 수 있지만, 데이터가 부족하면 CNN보다 못한 결과가 나온다.
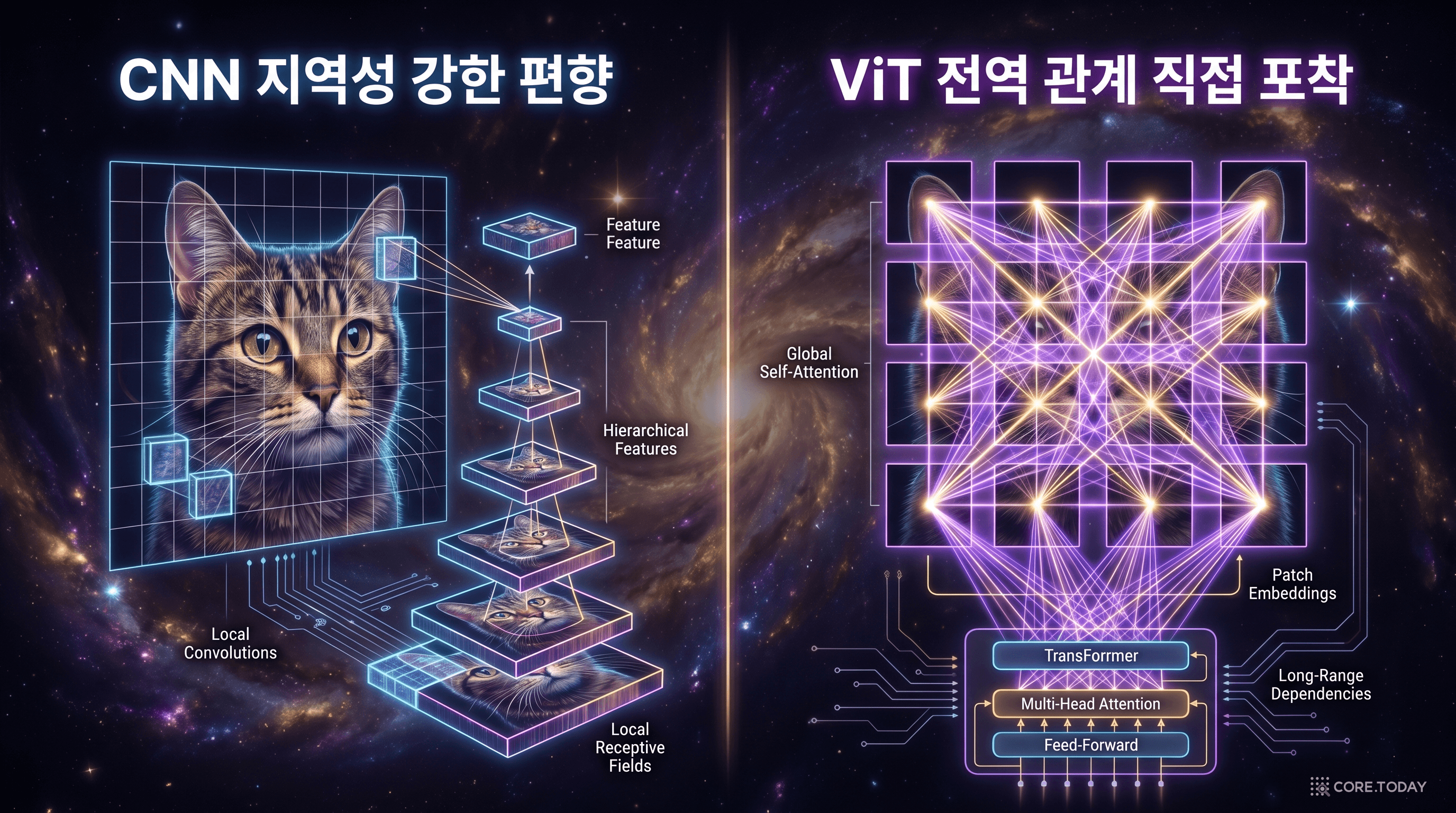
두 아키텍처의 특성을 비교하면 다음과 같다.
| 특성 | CNN | ViT |
|---|---|---|
| 귀납적 편향 | 강함 (지역성, 이동 불변성 내장) | 약함 (데이터에서 학습해야 함) |
| 데이터 효율 | 적은 데이터로도 학습 | 대규모 데이터 필요 |
| 전역 관계 | 깊은 층에서 간접적으로 포착 | 첫 층부터 직접 포착 |
| 추론 속도 | 빠름 (특히 모바일) | 상대적으로 느림 |
| 확장성 | 한계가 있음 | 데이터/모델 크기에 비례하여 향상 |
이 표가 말해주는 것은 명확하다. CNN과 ViT는 서로 다른 트레이드오프를 가진 상호보완적 기술이라는 것이다. 무한한 데이터와 연산이 있는 세계에서는 ViT가 유리하고, 제한된 자원으로 효율적인 결과를 내야 하는 세계에서는 CNN이 유리하다. 현실 세계는 이 두 극단 사이 어딘가에 있다.
두 아키텍처의 장점을 결합하려는 움직임은 자연스러웠다. 2022년, Meta AI의 Zhuang Liu 등이 "A ConvNet for the 2020s"라는 논문을 발표했다. ConvNeXt라 명명된 이 모델은 질문 하나에서 출발했다. "Transformer의 설계 원칙(큰 커널, 더 적은 활성화, Layer Normalization 등)을 순수 CNN에 적용하면 어떻게 될까?"
결과는 놀라웠다. 합성곱만으로 구성된 ConvNeXt가 같은 규모의 ViT와 동등하거나 오히려 우수한 성능을 보인 것이다. CNN 커뮤니티는 환호했다. "CNN은 죽지 않았다. 단지 현대화가 필요했을 뿐이다." ConvNeXt는 이 메시지를 데이터로 증명했다.
동시에 EfficientViT 같은 모델은 반대 방향에서 접근했다. Transformer의 전역 모델링 능력은 유지하되, CNN의 효율적인 연산 구조를 차용하여 추론 속도를 극적으로 개선한 것이다.
2026년의 트렌드는 명확하다. 순수 CNN도 아니고, 순수 Transformer도 아니다. 두 세계의 장점을 교차 수분(cross-pollination)한 하이브리드 아키텍처가 프로덕션의 주류를 이루고 있다.
그런데 모든 AI가 클라우드에서 실행되는 것은 아니다. 스마트폰, IoT 센서, 드론, 자동차의 임베디드 프로세서 — 이른바 엣지 디바이스에서는 연산 자원과 전력이 극도로 제한된다. 이 세계에서 CNN은 여전히 1순위 선택지다.
Howard 등이 2017년에 발표한 MobileNet은 깊이별 분리 합성곱(depthwise separable convolution)이라는 기법으로 합성곱의 계산량을 8~9배 줄였다. 일반 합성곱이 모든 입력 채널을 한꺼번에 처리한다면, 깊이별 분리 합성곱은 각 채널을 독립적으로 처리한 뒤 1×1 합성곱으로 채널 간 정보를 결합한다. 결과적으로 성능 손실은 최소화하면서 모델 크기와 연산량은 극적으로 감소했다.
2019년에는 Google Brain의 Mingxing Tan과 Quoc V. Le가 EfficientNet을 발표했다. 이 모델의 핵심 아이디어는 복합 스케일링(compound scaling)이다. 네트워크의 너비(채널 수), 깊이(층 수), 입력 해상도를 하나의 계수로 동시에 균형 있게 확장하는 방법이다. 기존에는 이 세 가지를 각각 독립적으로 조정했는데, EfficientNet은 세 요소의 균형이 성능의 핵심임을 보였다. 결과적으로 기존 CNN 대비 8.4배 작은 모델로 동등한 정확도를 달성했다.
ViT가 이 엣지 환경에서 CNN을 대체하기에는 아직 멀었다. 자기 주의 메커니즘의 계산 복잡도는 패치 수의 제곱에 비례하므로(), 고해상도 이미지를 처리할 때 연산량이 급격히 증가한다. 클라우드의 A100 GPU에서는 문제 없지만, 스마트폰의 작은 NPU에서는 치명적이다. 2026년 현재, 당신의 스마트폰에서 실시간으로 작동하는 비전 AI의 대부분은 여전히 CNN 기반이다.
현재의 상황을 조감도로 정리하면 다음과 같다.
왼쪽의 순수 CNN은 리소스 제약이 엄격한 엣지 환경에서 여전히 독보적이다. 오른쪽의 순수 Transformer는 무한에 가까운 데이터와 연산을 투입할 수 있는 연구 및 대규모 사전학습 영역에서 강세다. 그리고 가운데의 하이브리드가 두 세계의 교차점에서 실전 배포의 주류를 이루고 있다.
여기서 한 걸음 더 깊이 들어가보자. ViT가 CNN을 "대체"했다고 말하는 것은 정확하지 않다. 오히려 ViT는 CNN의 핵심 인사이트를 흡수했다.
ViT의 첫 번째 연산인 패치 임베딩(patch embedding)을 자세히 보면, 이것은 본질적으로 16×16 크기, stride 16의 합성곱 연산과 수학적으로 동일하다. 이미지를 패치로 나누어 벡터로 변환하는 작업이 곧 합성곱인 것이다. 또한 Swin Transformer (Liu et al., 2021) 같은 후속 모델은 전역 자기 주의 대신 윈도우 기반 지역 주의(windowed local attention)를 사용하는데, 이것은 CNN의 수용야(receptive field) 개념의 변형이다.
CNN이 증명한 세 가지 원리를 생각해보자.
첫째, 지역적 패턴 감지. 이미지에서 의미 있는 정보는 인접한 픽셀들의 관계에서 나온다. 이 원리는 ViT의 패치 임베딩에, Swin Transformer의 지역 윈도우에 그대로 살아 있다.
둘째, 계층적 특징 추출. 단순한 특징에서 복잡한 특징으로 단계적으로 올라가는 구조. Swin Transformer의 계층적 구조, DINOv2의 다중 스케일 특징 추출이 이 원리를 계승한다.
셋째, 파라미터 공유를 통한 효율성. 같은 필터를 모든 위치에 적용하는 CNN의 설계는, Transformer에서 같은 주의 헤드가 모든 위치의 토큰에 적용되는 것과 구조적으로 유사하다.
비유하자면 이렇다. CNN이라는 건물 자체는 리모델링되고 있다. 외벽이 바뀌고, 인테리어가 달라지고, 최신 설비가 들어온다. 하지만 그 건물을 지탱하는 건축 원리 — 기초를 튼튼히 하고, 하중을 분산시키고, 층층이 쌓아 올리는 원리 — 는 새로운 건물에도 그대로 적용되고 있다. CNN의 유산은 특정 아키텍처가 아니라, 그 아키텍처가 증명한 원리에 있다. 그리고 원리는 아키텍처보다 오래 살아남는다.
1959년, 존스 홉킨스 대학교의 어두운 실험실. David Hubel과 Torsten Wiesel은 마취된 고양이의 시각 피질에 전극을 꽂고, 뉴런 하나의 신호에 귀를 기울이고 있었다. 슬라이드 프로젝터의 우연한 오작동이 만든 직선 그림자에, 뉴런이 폭발적으로 반응했다. 그 순간, 시각 인식의 비밀을 향한 여정이 시작되었다.
2026년, 서울의 한 교차로. 자율주행차의 카메라가 횡단보도를 건너는 고양이를 포착한다. 차량의 CNN이 초당 30프레임으로 영상을 분석하고, 0.03초 만에 "고양이 — 정지 필요"라는 판단을 내린다. 차는 부드럽게 멈춘다. 고양이는 유유히 길을 건넌다.
67년의 시간이 두 장면 사이에 놓여 있다. 고양이의 뇌에서 뉴런의 반응을 관찰하던 과학자들의 호기심에서 출발하여, 수학적 모델로 번역되고(Fukushima, 1980), 역전파라는 학습 엔진을 얻고(LeCun, 1989), 데이터와 GPU 부족이라는 겨울을 견디며 잠복하고, ImageNet과 GPU라는 봄을 만나 폭발적으로 성장하고(AlexNet, 2012; ResNet, 2015), 병원과 도로와 공장에 스며들고, 마침내 Transformer라는 새로운 동료와 공존하며 진화를 계속하고 있다.
이 여정에서 CNN이 증명한 것은 하나의 명제다. "자연을 관찰하고, 그 원리를 모방하되, 기계의 강점으로 확장하라." Hubel과 Wiesel이 고양이의 뇌에서 발견한 원리를, 공학자들이 실리콘 위에 재현하고, GPU의 병렬 연산으로 확장한 것이다.
이 긴 여정에서 세 가지 교훈을 기억하고 싶다.
"생물학적 영감의 힘 — 최고의 알고리즘은 종종 자연에서 온다. 수용야, 계층적 처리, 지역적 패턴 감지. 이 모든 것을 최초로 '발명'한 것은 인간이 아니라 수억 년의 진화였다."
"단순한 원리의 반복 — 합성곱이라는 단순한 연산 하나가, 수백 층 쌓이고, 수백만 번 반복되어, 기적 같은 인식 능력을 만들어낸다. 복잡함은 단순함의 축적에서 태어난다."
"아이디어의 시간 — 좋은 아이디어는 환경이 갖춰질 때까지 기다릴 줄 안다. Fukushima의 네오코그니트론(1980)에서 AlexNet(2012)까지 32년. 원리는 이미 거기 있었지만, GPU와 데이터라는 연료가 채워질 때까지 조용히 기다렸다."
지금 이 순간에도 CNN은 당신의 스마트폰에서 얼굴을 인식하고, 병원에서 X-ray를 분석하고, 도로 위에서 보행자를 감지하고, 공장에서 불량품을 걸러내고, 하늘에서 지구를 관찰하고 있다. 고양이 한 마리의 뉴런에서 시작된 이 이야기는, 아직 끝나지 않았다.
만약 이 글을 읽고 CNN에 대한 호기심이 생겼다면, 직접 경험해볼 것을 권한다. PyTorch 한 줄이면 합성곱 층을 만들 수 있고, MNIST 데이터셋과 30분이면 당신만의 첫 번째 CNN을 학습시킬 수 있다. 67년 전 Hubel과 Wiesel이 고양이의 뇌에서 발견한 그 원리가 — 당신의 노트북 위에서, 당신의 손으로 — 작동하는 순간을 목격하게 될 것이다.



