들어가며: IBM Watson Health의 교훈
2013년, IBM은 자신만만하게 선언했다.
"Watson이 암을 정복할 것이다."
IBM은 Watson Health에 40억 달러 이상을 투자했다. MD Anderson Cancer Center와 파트너십을 맺고, 수백만 건의 의학 논문과 임상 데이터를 Watson에 학습시켰다. 목표는 원대했다 — AI가 종양학 전문의보다 더 정확한 암 진단과 치료 추천을 내놓는 것.
결과는? 2018년, MD Anderson은 Watson과의 파트너십을 6,200만 달러를 쓴 뒤 중단했다. Watson의 치료 추천은 종양학 전문의의 판단과 겨우 12.5%만 일치했다는 내부 보고도 나왔다. 2022년, IBM은 Watson Health를 사모펀드 Francisco Partners에 매각했다. 매각가는 약 10억 달러 — 투자금의 75%를 날린 셈이다.
무엇이 잘못되었는가?
AI 기술이 부족해서가 아니었다. AI를 "목적"으로 삼은 것이 문제였다.
IBM은 "AI로 암을 치료한다"는 거대한 비전으로 시작했다. 하지만 진짜 물어야 할 질문은 이것이었다 — "종양학 전문의가 치료 결정을 내릴 때 가장 시간이 오래 걸리는 단계는 무엇이며, 그 단계에서 AI가 어떤 구조화된 정보를 제공하면 의사결정이 빨라지는가?"
AI는 목적이 아니라 수단이다. 비즈니스 문제가 먼저 정의되고(1편), 프로세스가 설계되고(2편), 데이터가 구조화된 뒤(3편), 그 위에서 AI가 작동해야 한다. 순서를 뒤집으면 40억 달러짜리 실패가 된다.
이 글은 DX 전문가 로드맵 10편 시리즈의 네 번째 편이다. DX 전문가가 AI/ML을 어떻게 이해해야 하는지 — "만드는 사람"이 아닌 "활용하는 사람"의 시각에서, 1959년 머신러닝의 탄생부터 2026년 AI 에이전트까지의 계보를 추적한다.
제1장: AI/ML 60년 계보 — 체커에서 에이전트까지
기대와 환멸의 반복: AI의 역사는 "겨울"의 역사다
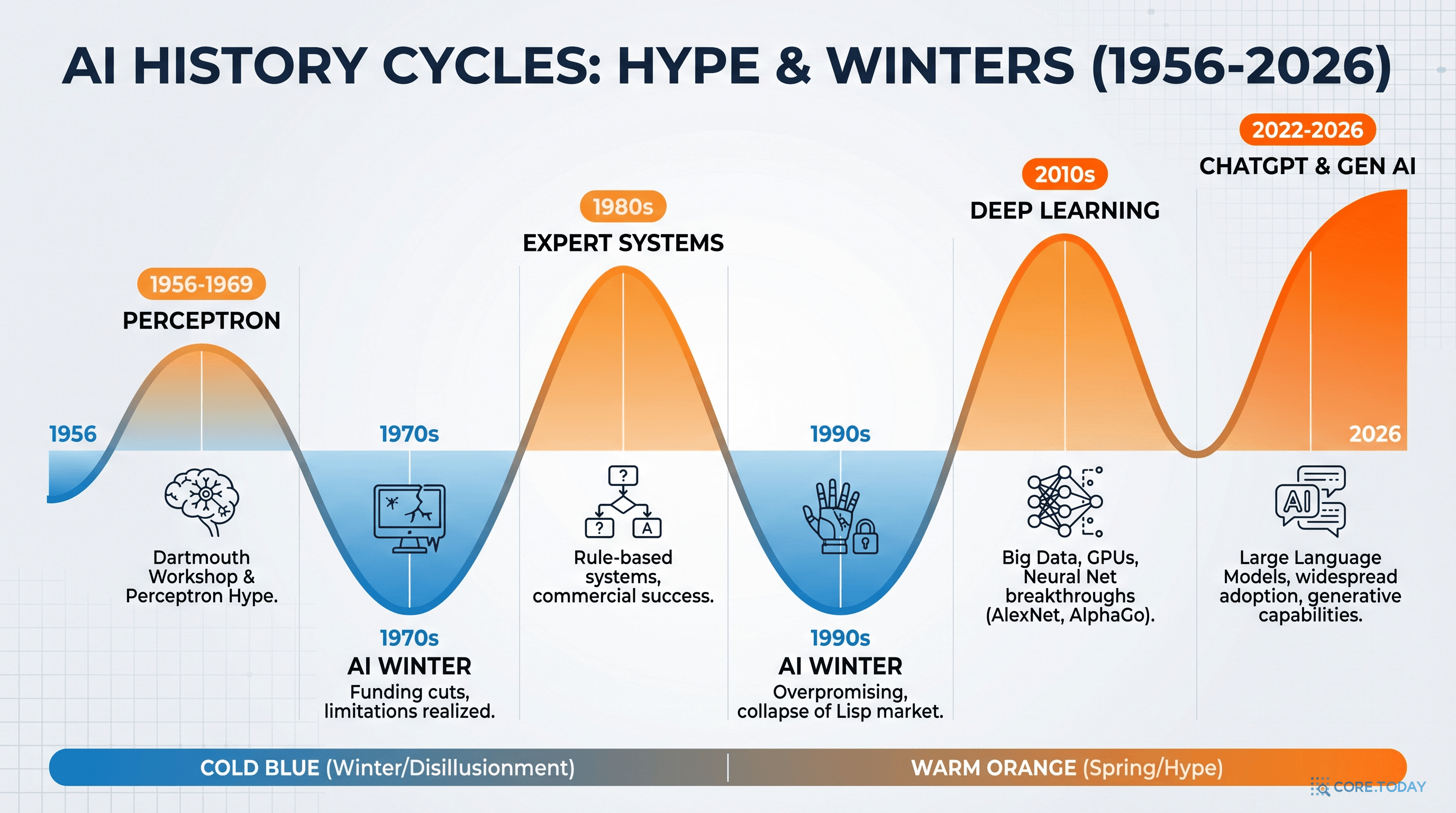
AI의 역사를 이해하는 열쇠는 "기대 → 과잉 투자 → 환멸 → 겨울 → 돌파구"의 반복 패턴이다. 이 패턴을 모르면, 2026년 현재의 AI 열풍이 영원히 지속될 것이라는 착각에 빠지거나, 반대로 "또 겨울이 올 것"이라는 회의론에 갇히게 된다.
1959
Arthur Samuel
체커 프로그램
→
1966
ELIZA
최초의 챗봇
→
1980s
전문가 시스템
붐 & 버스트
→
1997
Deep Blue
체스 세계 챔피언 격파
↓
2012
AlexNet
딥러닝 혁명
→
2017
Transformer
"Attention Is All You Need"
→
2020
GPT-3
1,750억 파라미터
→
2022.11
ChatGPT
2개월 만에 1억 명
↓
2023
GPT-4, Claude
멀티모달 AI
→
2024
오픈소스 폭발
Llama 3, Mistral
→
2025-26
AI 에이전트
자율 실행 시대
핵심 전환점 해설
1959년 — "머신러닝"의 탄생. IBM 연구원 아서 사무엘(Arthur Samuel)이 체커(checkers) 프로그램을 만들면서 "machine learning"이라는 용어를 처음 사용했다. 프로그램은 수천 번의 대국을 스스로 반복하며 점점 강해졌다. 사무엘은 이를 "명시적으로 프로그래밍하지 않고도 컴퓨터가 학습하는 능력"이라고 정의했다.
1980년대 — 전문가 시스템의 황금기와 몰락. 인간 전문가의 지식을 IF-THEN 규칙으로 코딩하는 전문가 시스템(Expert System)이 유행했다. 1985년에는 시장 규모가 10억 달러에 달했다. 하지만 유지보수가 불가능할 정도로 규칙이 복잡해지면서 제2차 AI 겨울(1987~1993)이 찾아왔다.
2012년 — 딥러닝의 빅뱅. 토론토 대학교의 제프리 힌턴(Geoffrey Hinton) 연구팀이 ImageNet 대회에서 AlexNet으로 오류율 16.4%를 기록했다 — 2위(26.2%)를 10%p 차이로 격파했다. CNN(합성곱 신경망)과 GPU의 결합이 만들어낸 혁명이었다. 이후 AI 연구는 사실상 딥러닝 중심으로 재편되었다.
2017년 — Transformer의 등장. Google의 연구팀이 "Attention Is All You Need"라는 논문을 발표했다. 셀프 어텐션(Self-Attention) 메커니즘으로 순차적 처리를 병렬화한 이 아키텍처는, 이후 GPT, BERT, Claude 등 모든 대규모 언어 모델의 기반이 되었다.
2022년 11월 — ChatGPT의 충격. OpenAI가 ChatGPT를 출시한 후 2개월 만에 1억 명이 사용했다. TikTok(9개월), Instagram(2.5년)을 압도하는 역대 최속 기록이었다. AI가 학계와 산업을 넘어 일반 소비자의 일상으로 들어온 결정적 순간이다.
| 서비스 | 1억 사용자 도달 | 출시 연도 |
|---|
| ChatGPT | 2개월 | 2022 |
| TikTok | 9개월 | 2016 |
| Instagram | 2.5년 | 2010 |
| Spotify | 4.5년 | 2008 |
| Facebook | 4.5년 | 2004 |
| 인터넷 (WWW) | 7년 | 1991 |
DX 전문가에게 이 계보가 중요한 이유: AI는 "갑자기 등장한 마법"이 아니라, 67년간 축적된 기술의 결과물이다. 그 역사를 이해해야 현재 AI의 가능성과 한계를 동시에 볼 수 있다.
제2장: 머신러닝의 3가지 패러다임 — 비즈니스 관점
AI, 머신러닝, 딥러닝 — 무엇이 다른가
이 세 개념의 관계를 먼저 정리하자. DX 현장에서 가장 흔한 혼동 중 하나다.
AI > ML > DL — 포함 관계
인공지능 (AI)
Artificial Intelligence
인간의 지능을 모방하는 모든 기술. 규칙 기반 시스템도 포함.
머신러닝 (ML)
Machine Learning
데이터에서 패턴을 학습하는 AI의 하위 집합. 명시적 프로그래밍 불필요.
딥러닝 (DL)
Deep Learning
다층 신경망을 사용하는 ML의 하위 집합. GPT, ResNet 등.
3가지 학습 패러다임
머신러닝은 학습 방법에 따라 세 가지로 나뉜다. 각각 해결하는 비즈니스 문제의 성격이 다르다.
머신러닝의 3대 패러다임
지도학습
Supervised Learning
정답이 있는 데이터로 학습 → 예측
비지도학습
Unsupervised Learning
정답 없이 패턴 발견 → 군집화
강화학습
Reinforcement Learning
시행착오로 최적 행동 탐색 → 최적화
| 구분 | 지도학습 | 비지도학습 | 강화학습 |
|---|
| 데이터 | 라벨(정답)이 있는 데이터 | 라벨 없는 데이터 | 환경과의 상호작용 |
| 핵심 목표 | 예측/분류 | 패턴 발견/군집화 | 보상 최대화 |
| 비즈니스 예시 | 스팸 필터, 신용 점수 | 고객 세분화, 이상 탐지 | 동적 가격 책정, 물류 최적화 |
| 데이터 요구량 | 높음 (라벨링 비용 큼) | 중간 | 매우 높음 (시뮬레이션 필요) |
| 대표 알고리즘 | 랜덤포레스트, XGBoost, CNN | K-Means, PCA, Autoencoder | DQN, PPO, AlphaGo |
DX 전문가가 알아야 할 판단 기준: ML이 필요한가, 규칙으로 충분한가?
현장에서 가장 위험한 실수는 "간단한 규칙으로 해결 가능한 문제에 ML을 적용하는 것"이다. ML은 만능이 아니다. 투입 대비 효과를 냉정하게 따져야 한다.
규칙
규칙 기반으로 충분한 경우
조건이 명확하고 경우의 수가 적을 때. 예: "주문 금액 10만 원 이상이면 무료배송", "재고 100개 이하면 발주 알림". IF-THEN 로직이면 된다. ML을 쓰면 오버엔지니어링.
ML
ML이 필요한 경우
패턴이 복잡하고, 변수가 많고, 규칙을 사람이 코딩할 수 없을 때. 예: "이 고객이 다음 달에 이탈할 확률", "이 이미지에 불량이 있는가". 데이터에서 패턴을 스스로 발견해야 한다.
핵심
판단 원칙
"규칙으로 80%를 커버할 수 있는가?" — Yes이면 규칙부터 시작하고, 나머지 20%에만 ML을 적용한다. 이것이 비용 대비 최대 효과를 내는 접근법이다.
제3장: LLM과 생성형 AI — DX의 게임 체인저
대규모 언어 모델(LLM)이란 무엇인가
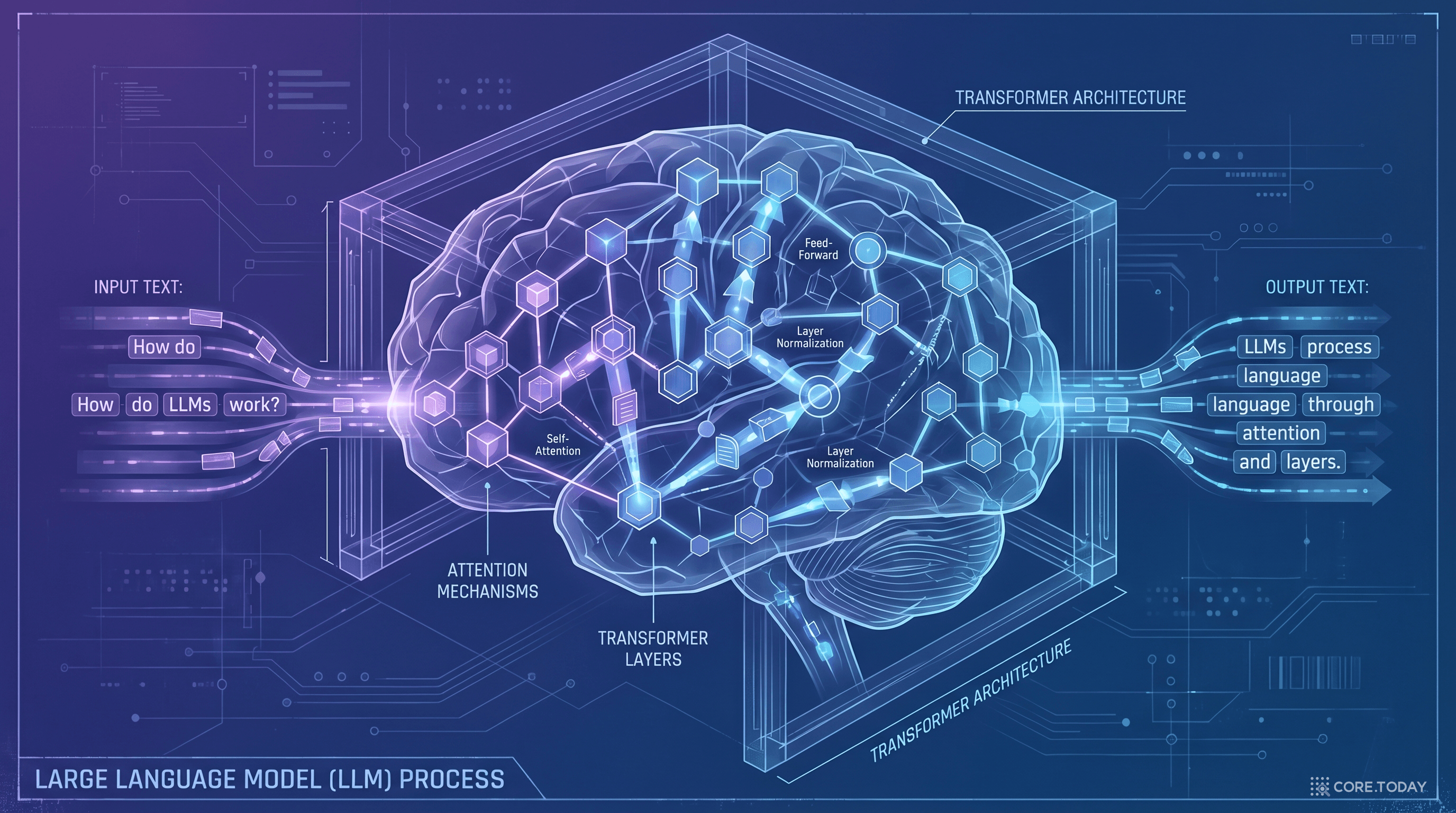
LLM(Large Language Model)은 수십억~수조 개의 파라미터를 가진 신경망이 대규모 텍스트 데이터에서 언어의 패턴을 학습한 모델이다. 핵심 메커니즘은 다음 토큰 예측(next-token prediction) — 주어진 문맥에서 다음에 올 단어를 확률적으로 예측하는 것이다.
1단계
사전 학습 (Pre-training) — 인터넷 텍스트 수조 토큰을 학습. 언어의 통계적 패턴, 세계 지식, 추론 능력을 습득한다. 수천 대 GPU로 수개월 소요.
2단계
미세 조정 (Fine-tuning) — 특정 작업이나 도메인에 맞게 추가 학습. 인간 피드백 기반 강화학습(RLHF)으로 안전하고 유용한 응답을 생성하도록 정렬(alignment)한다.
3단계
추론 (Inference) — 사용자 질문에 대해 학습된 패턴을 기반으로 응답을 생성한다. 이 단계에서 비용이 지속적으로 발생한다.
모델 스케일의 폭발적 성장
88%가 사용하지만 6%만 성과를 낸다
McKinsey의 2025년 글로벌 AI 조사에 따르면, 기업의 88%가 AI를 활용하고 있다. 그러나 EBIT(영업이익)에서 5% 이상의 성과를 내는 기업은 6%에 불과하다.
McKinsey 2025 — 기업 AI 활용 현황
이 숫자가 말해주는 것: AI를 "도입"하는 것과 AI로 "성과"를 내는 것 사이에는 거대한 간극이 있다. 88%와 6%의 차이 — 82%p의 갭 — 을 메우는 것이 DX 전문가의 역할이다.
기업에서 실제로 쓰이는 GenAI 유스케이스
기업 GenAI 활용 Top 6 (McKinsey 2025)
문서 처리
Document Processing
계약서 분석, 보고서 요약, 번역
코드 생성
Code Generation
Copilot, 코드 리뷰, 테스트 생성
고객 서비스
Customer Service
AI 챗봇, 상담원 어시스턴트
마케팅 콘텐츠
Content Creation
카피라이팅, 이미지 생성, 개인화
데이터 분석
Data Analytics
자연어 쿼리, 리포트 자동 생성
지식 관리
Knowledge Management
내부 문서 검색, FAQ, 온보딩
할루시네이션 — LLM의 아킬레스건
LLM의 가장 치명적인 한계는 할루시네이션(hallucination)이다. 모델이 사실처럼 보이지만 실제로는 틀린 정보를 자신감 있게 생성하는 현상이다.
| 항목 | 할루시네이션 실태 |
|---|
| 발생 빈도 | 일반 질의 기준 15~25% (모델/태스크에 따라 편차 큼) |
| 위험도가 높은 분야 | 의료 진단, 법률 자문, 재무 분석 — 잘못된 정보가 직접적 손해로 이어짐 |
| 근본 원인 | LLM은 "진실"을 이해하는 것이 아니라 "통계적으로 그럴듯한 다음 토큰"을 생성함 |
| 완화 방법 | RAG(검색 증강 생성), 사실 확인 체인, 인간 검증 루프 |
DX 전문가의 관점에서 할루시네이션은 "기술적 버그"가 아니라 "프로세스 설계의 문제"다. AI 출력을 그대로 최종 결과로 사용하는 프로세스를 설계하면 실패하고, AI 출력을 인간이 검증하고 보완하는 단계를 포함하는 프로세스를 설계하면 성공한다.
제4장: RAG — 기업 AI의 핵심 아키텍처
왜 기업은 GPT를 그냥 쓸 수 없는가
범용 LLM(GPT, Claude, Gemini 등)은 인터넷의 공개 데이터로 학습되었다. 그런데 기업의 비즈니스 문제를 풀려면 기업 내부 데이터(매뉴얼, 계약서, 회의록, CRM 기록 등)가 필요하다. 이 내부 데이터는 LLM의 학습 데이터에 포함되어 있지 않다.
두 가지 해법이 있다:
| 구분 | RAG (검색 증강 생성) | 파인튜닝 (Fine-tuning) |
|---|
| 방식 | 질의 시 관련 문서를 실시간 검색하여 프롬프트에 삽입 | 내부 데이터로 모델 자체를 추가 학습 |
| 데이터 최신성 | 실시간 반영 가능 | 재학습 필요 (수시간~수일) |
| 비용 | 벡터 DB + 검색 인프라 비용 | GPU 학습 비용 (수백~수천만 원) |
| 할루시네이션 | 출처 명시 가능 → 검증 용이 | 출처 추적 어려움 |
| 적합한 경우 | 최신 정보 반영이 중요할 때, 지식 베이스가 자주 변경될 때 | 특수 도메인 언어/스타일이 필요할 때, 응답 품질이 최우선일 때 |
| 대표 사례 | 사내 문서 검색 챗봇, 고객 상담 어시스턴트 | 의료 LLM(Med-PaLM), 법률 LLM(Harvey) |
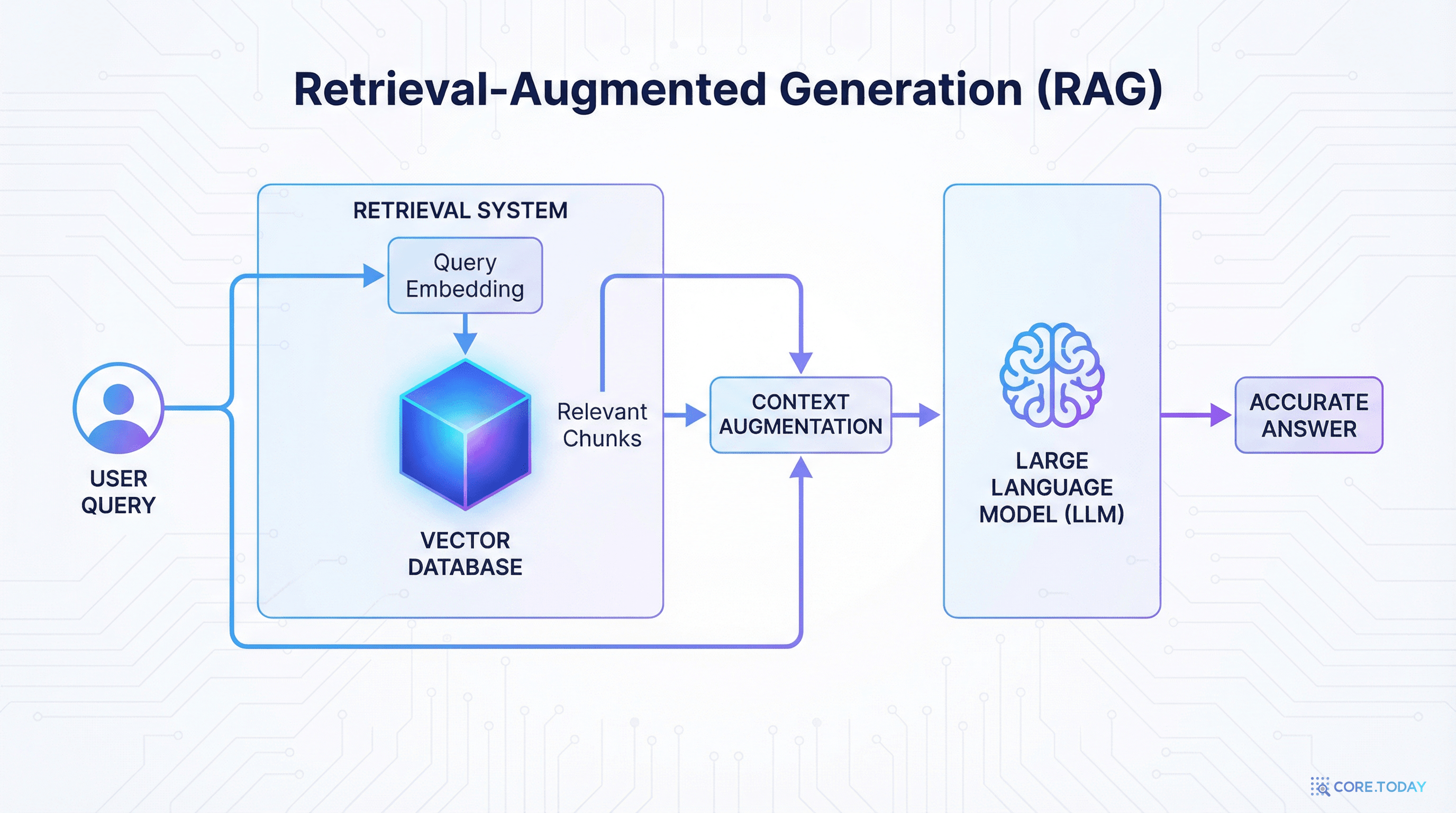
RAG 아키텍처: 4단계 파이프라인
RAG는 "검색(Retrieval)"과 "생성(Generation)"을 결합한 아키텍처다. DX 전문가가 반드시 이해해야 할 파이프라인이다.
1. 질의
Query — 사용자가 자연어로 질문한다. "지난 분기 매출 하락의 주요 원인은?" 이 질문이 벡터로 변환(임베딩)된다.
2. 검색
Retrieve — 벡터 데이터베이스에서 질문과 의미적으로 유사한 문서 청크(chunk)를 검색한다. 키워드 매칭이 아닌 의미 기반 검색이 핵심.
3. 증강
Augment — 검색된 문서를 LLM의 프롬프트에 컨텍스트로 삽입한다. "다음 자료를 참고하여 답변하세요: [검색된 문서]"
4. 생성
Generate — LLM이 검색된 문서를 근거로 답변을 생성한다. 출처를 함께 표시하여 검증 가능성을 확보한다.
사용자 질의
→
임베딩 모델
→
벡터 검색
→
관련 문서 Top-K
↓
프롬프트 조합
→
LLM 생성
→
답변 + 출처
RAG가 실패하는 3가지 원인
RAG가 만능은 아니다. DX 현장에서 RAG 프로젝트가 실패하는 패턴은 크게 세 가지다.
1
데이터 품질 문제
원본 문서가 정리되지 않았거나, 중복이나 모순이나 오류가 있으면 검색 결과의 품질도 떨어진다. "Garbage In, Garbage Out"은 RAG에서도 철칙이다. 3편(데이터 구조 이해)에서 다룬 데이터 품질이 RAG의 성패를 결정한다.
2
청킹(Chunking) 전략 실패
문서를 너무 작게 자르면 맥락이 사라지고, 너무 크게 자르면 관련 없는 내용이 포함된다. 최적의 청크 크기와 오버랩 비율을 실험적으로 찾아야 한다. 이것은 엔지니어링이 아니라 도메인 이해의 문제다.
3
검색-생성 간극
올바른 문서를 검색했는데 LLM이 무시하거나, 검색 결과가 질문과 미묘하게 어긋나는 경우. 리랭킹(Reranking)과 프롬프트 엔지니어링으로 보완하지만, 근본적으로는 질문 설계와 데이터 구조화가 해답이다.
제5장: Prompt Engineering에서 Context Engineering으로
"프롬프트 엔지니어링"의 한계
2023년부터 "프롬프트 엔지니어링"이 유행했다. 더 좋은 답을 얻기 위해 질문을 잘 작성하는 기술이다. "역할을 부여하라", "예시를 넣어라", "단계적으로 생각하라(Chain-of-Thought)" 등의 테크닉이 확산되었다.
하지만 이것은 전체 그림의 일부에 불과했다.
Andrej Karpathy의 선언 (2025년 6월)
전 Tesla AI 디렉터이자 OpenAI 공동창업자인 안드레이 카파시(Andrej Karpathy)가 2025년 6월 X(구 Twitter)에 올린 글이 기술 업계에 파장을 일으켰다:
"I think the role of 'Prompt Engineer' is going to change into the role of 'Context Engineer.' It's really about filling in the context window of an LLM with just the right information needed for the next generation step."
핵심 전환: 프롬프트(질문)를 잘 쓰는 것이 아니라, LLM에게 제공하는 전체 맥락(context)을 설계하는 것이 핵심이라는 선언이다.
| 구분 | Prompt Engineering | Context Engineering |
|---|
| 초점 | 질문(prompt)을 잘 쓰는 것 | 전체 맥락(context window)을 설계하는 것 |
| 범위 | 프롬프트 텍스트 | 시스템 프롬프트 + 검색 결과 + 도구 출력 + 대화 기록 + 메모리 |
| 핵심 역량 | 언어 감각, 테크닉 | 정보 아키텍처, 데이터 큐레이션, 시스템 설계 |
| 비유 | 좋은 질문을 던지는 기자 | 브리핑 자료 전체를 준비하는 참모 |
Cognizant의 1,000명 Context Engineer 채용
글로벌 IT 서비스 기업 Cognizant는 2025년 하반기에 1,000명의 Context Engineer를 채용한다고 발표했다. 이들의 역할은 "프롬프트를 쓰는 것"이 아니라, 기업의 비즈니스 프로세스와 데이터와 도메인 지식을 AI 시스템의 컨텍스트로 구조화하는 것이다.
이것은 1편(문제 정의)에서 다룬 "올바른 질문을 던지는 힘"의 AI 시대 확장판이다. DX 전문가에게 Context Engineering은 새로운 별개의 기술이 아니라, 비즈니스 이해 + 데이터 구조화 + AI 활용이 통합된 핵심 역량이다.
1. 시스템 프롬프트 — AI의 역할, 제약 조건, 출력 형식을 정의
2. 검색된 지식 (RAG) — 벡터 DB에서 가져온 관련 문서
3. 도구 출력 (Tool Use) — API 호출, DB 쿼리, 계산 결과
4. 대화 기록 (Conversation History) — 이전 대화의 맥락
5. 메모리 (Memory) — 장기적으로 축적된 사용자/조직 컨텍스트
이 5가지를 어떤 순서로, 얼마나, 어떤 형식으로 컨텍스트 윈도우에 채우느냐가 AI 시스템의 품질을 결정한다.
제6장: 성공과 실패 사례 — 숫자가 말하는 현실
성공 사례: AI를 "수단"으로 사용한 기업들
1
JPMorgan — COIN (Contract Intelligence)
상업 대출 계약서 검토에 연간 360,000시간의 변호사 인력이 투입되었다. COIN 시스템은 같은 작업을 초 단위로 처리한다. 핵심: AI가 변호사를 대체한 것이 아니라, 변호사가 고부가가치 업무에 집중할 수 있게 된 것이다.
2
UPS — ORION (On-Road Integrated Optimization and Navigation)
배송 경로 최적화 AI로 연간 1억 마일 주행 거리를 줄이고, 4억 달러(약 5,400억 원)를 절감했다. 10만 명의 드라이버가 매일 최적 경로를 자동으로 받는다.
3
Starbucks — Deep Brew
AI 기반 개인화 추천 엔진으로 앱 사용자에게 맞춤형 음료와 푸드를 추천한다. 결과: 연간 4억 1,000만 달러(약 5,500억 원)의 추가 매출을 창출했다.
4
포스코 — AI 품질 검사
철강 제조 공정에서 AI 비전 검사 시스템을 도입하여 표면 결함 검출 정확도를 99% 이상으로 끌어올렸다. 연간 2,500억 원 규모의 품질 비용을 절감한 것으로 추산된다. 핵심 성공 요인: AI 도입 전에 품질 데이터를 체계적으로 구조화한 것.
성공 사례의 공통 패턴
실패 사례: AI를 "목적"으로 삼은 기업들
실패
IBM Watson Health — 40억 달러의 교훈
40억 달러 이상 투자, 2022년 약 10억 달러에 매각. "AI로 암을 정복한다"는 거대한 목적이 실패 원인. 의사의 실제 워크플로우를 이해하지 못한 채, AI를 의사결정 전체에 적용하려 했다. 의사들은 "왜 이 추천을 했는지" 설명할 수 없는 블랙박스를 신뢰하지 않았다.
실패
Amazon 채용 AI — 성별 차별 (2018)
Amazon은 이력서를 AI로 자동 평가하는 시스템을 개발했다. 문제: 학습 데이터가 과거 10년간의 채용 기록이었는데, 기존 채용자 대부분이 남성이었다. AI는 이 편향을 학습하여 여성 지원자를 체계적으로 불이익 처리했다. "여성 체스 동아리"라는 키워드가 있으면 감점. Amazon은 이 시스템을 폐기했다.
성공과 실패를 가르는 핵심 차이
| 요소 | 성공 기업 (6%) | 실패 기업 (나머지) |
|---|
| 출발점 | 비즈니스 문제에서 시작 | AI 기술에서 시작 |
| 범위 | 좁은 문제 → 단계적 확장 | 처음부터 대규모 변혁 |
| 데이터 | 데이터 품질에 먼저 투자 | 모델 성능에만 집중 |
| 프로세스 | AI에 맞게 워크플로우 재설계 | 기존 프로세스에 AI를 끼워넣기 |
| 인간의 역할 | AI를 보조 도구로, 인간이 최종 판단 | AI에 의사결정을 위임 |
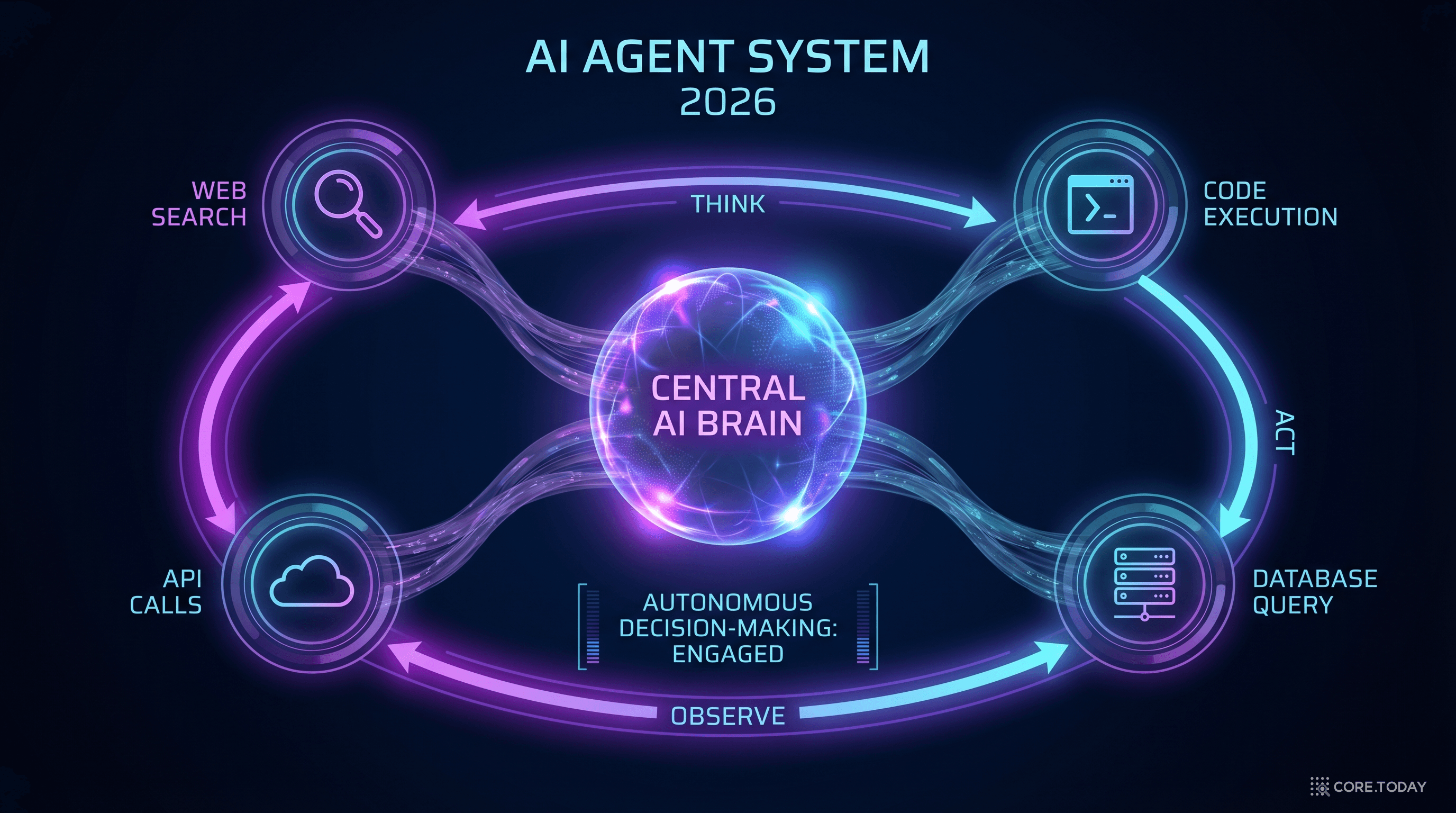
제7장: 2026년 AI 트렌드 — DX 전문가가 주시해야 할 4가지
1. AI 에이전트 (Agentic AI)
2025~2026년 AI의 가장 큰 변화는 에이전트(Agent)의 부상이다. 기존 AI는 "질문하면 답하는" 수동적 도구였다면, AI 에이전트는 목표를 부여받으면 스스로 계획을 세우고, 도구를 사용하고, 중간 결과를 평가하며, 작업을 완수하는 자율적 시스템이다.
목표 설정
→
계획 수립
→
도구 실행
→
결과 평가
↓
완료 판단
→
미완료 시 재계획
→
반복 실행
→
최종 산출물
기존 AI (Chatbot): "Q3 매출 보고서를 요약해줘" → 요약 텍스트 출력 → 끝
AI 에이전트: "Q3 매출 하락 원인을 분석하고, 개선 방안을 포함한 보고서를 작성하라" → CRM 데이터 조회 → 매출 트렌드 분석 → 경쟁사 보고서 검색 → 원인 분석 → 개선안 도출 → 보고서 초안 작성 → 인간 검토 요청
2. SLM (Small Language Models) — 작지만 강한 모델
모든 작업에 GPT-4 급의 초대형 모델이 필요한 것은 아니다. SLM(Small Language Model)은 수십억 파라미터 수준의 경량 모델로, 특정 도메인에서 대형 모델에 준하는 성능을 보이면서도 비용과 지연 시간을 극적으로 줄인다.
| 구분 | LLM (대형 모델) | SLM (소형 모델) |
|---|
| 파라미터 | 70B~1.8T | 1B~8B |
| 추론 비용 | 높음 (클라우드 GPU 필요) | 낮음 (온디바이스 실행 가능) |
| 지연 시간 | 수백 ms ~ 수 초 | 수십 ms |
| 데이터 보안 | 클라우드 전송 필요 | 로컬 처리 → 데이터 유출 없음 |
| 적합한 작업 | 복잡한 추론, 창의적 생성, 다국어 | 분류, 요약, 엔티티 추출, 임베딩 |
| 대표 모델 | GPT-4, Claude Opus, Gemini Ultra | Phi-3, Gemma, Llama 3.2 (1-3B) |
DX 관점에서 SLM의 의미: "클라우드에 데이터를 보낼 수 없는" 환경(의료, 금융, 국방, 제조 현장)에서 AI를 적용할 수 있는 유일한 선택지다. 엣지 AI와 결합하면 공장 현장, 병원, 매장 등에서 실시간 AI 추론이 가능해진다.
3. AI 거버넌스 — 규제가 현실이 된다
EU
EU AI Act (2025년 8월 시행) — 세계 최초의 포괄적 AI 규제법. AI를 위험도에 따라 4등급으로 분류(금지/고위험/제한/최소). 고위험 AI(채용, 대출, 의료 등)에는 적합성 평가, 투명성, 인간 감독 의무. 위반 시 전 세계 매출의 최대 7% 과징금.
한국
AI 기본법 (2026년 1월 시행) — 고위험 AI에 대한 영향평가 및 사전 고지 의무. AI 개발자와 이용자의 책임 구분. AI 윤리 가이드라인과 AI 안전 연구 지원을 포함.
미국
행정명령 + 주(州)법 — 연방 차원의 포괄적 법률 없이, 바이든 행정명령(2023)과 각 주의 개별 입법으로 대응. 콜로라도 AI 차별 방지법(2024), 캘리포니아 AI 투명성법 등이 시행 중.
4. 글로벌 AI 투자: $300B+ 시대
그러나 McKinsey의 2025년 조사에서 기업의 21%만이 GenAI에 맞게 워크플로우를 재설계했다는 점을 주목해야 한다. $300B+의 투자가 쏟아지고 있지만, "AI를 조직에 녹이는 구조적 변환"은 여전히 소수만 하고 있다. 나머지 79%의 기업에게 이것이 거대한 기회이자, DX 전문가의 핵심 가치가 발휘되는 영역이다.
마무리: "AI로 뭘 할까?"가 아니라 "이 문제를 AI가 어떻게 도울 수 있는가?"
이 글에서 추적한 67년의 AI 역사가 말해주는 단 하나의 교훈이 있다.
AI는 입구이고, 구조화된 데이터가 출구이다.
IBM Watson Health가 40억 달러를 날린 것은 AI 기술이 부족해서가 아니다. "AI로 암을 정복한다"는 잘못된 질문으로 시작했기 때문이다. JPMorgan COIN이 성공한 것은 AI가 뛰어나서가 아니다. "계약서 검토에 360,000시간이 걸린다"는 명확한 비즈니스 문제에서 시작했기 때문이다.
DX 전문가의 AI 활용 공식
비즈니스 문제
1편: 문제 정의
무엇을 해결할 것인가?
프로세스 설계
2편: 시스템 설계
어떤 흐름으로 해결하는가?
데이터 구조화
3편: 데이터 이해
어떤 데이터가 필요한가?
AI/ML 적용
4편: 현재 글
AI가 어떻게 도울 수 있는가?
-
"AI로 뭘 할까?" ❌
-
"이 비즈니스 문제를 AI가 어떻게 도울 수 있는가?" ✅
-
"ChatGPT를 도입하자" ❌
-
"고객 문의 응답 시간 24시간을 2시간으로 줄이는 데 LLM+RAG가 어떻게 기여할 수 있는가?" ✅
-
"AI 에이전트를 만들자" ❌
-
"반복적인 보고서 작성에 월 200시간이 소요되는데, 에이전트가 데이터 수집부터 초안 작성까지 자동화하면 어떤 비용 절감이 가능한가?" ✅
88%의 기업이 AI를 사용하지만, 실제 성과를 내는 기업은 6%에 불과하다. 이 82%p의 간극을 메우는 사람이 DX 전문가다. AI를 "만드는 사람"이 아니라, AI를 "올바른 비즈니스 문제에 올바른 방식으로 적용하는 사람" — 이것이 DX 전문가의 AI 역량이다.
다음 편에서는 AI와 데이터가 작동하는 기반 — DX의 다섯 번째 축, "시스템 아키텍처"를 다룬다.
참고 자료
- Arthur Samuel, "Some Studies in Machine Learning Using the Game of Checkers," IBM Journal of Research and Development 3(3), 1959
- Vaswani et al., "Attention Is All You Need," NeurIPS (2017)
- Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, "ImageNet Classification with Deep Convolutional Neural Networks," NeurIPS (2012)
- Tom Brown et al., "Language Models are Few-Shot Learners" (GPT-3), NeurIPS (2020)
- Patrick Lewis et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," NeurIPS (2020)
- McKinsey, "The State of AI in 2025: How organizations are rewiring to capture value" (2025)
- Andrej Karpathy, Context Engineering 개념, X/Twitter (June 2025)
- Cognizant, "1,000 Context Engineers Hiring Announcement" (2025)
- European Commission, "EU Artificial Intelligence Act" (2024, 시행 2025)
- IBM Annual Report, Watson Health 관련 재무 공시 (2013~2022)
- Reuters, "Amazon scraps secret AI recruiting tool that showed bias against women" (October 2018)
- JPMorgan Chase, "COIN: Contract Intelligence" 내부 기술 발표 (2017)
- UPS, "ORION: On-Road Integrated Optimization and Navigation" 공식 발표 (2016)
- Starbucks, "Deep Brew: AI and Machine Learning at Starbucks" 기술 블로그 (2020)