들어가며 — 물리를 아는 AI는 왜 아직도 어려운가

2020년대 초반, PINN(Physics-Informed Neural Networks)은 꽤 그럴듯한 약속처럼 보였다.
- 유체 방정식도 풀 수 있다
- 열전달 문제도 다룰 수 있다
- 데이터가 적어도 된다
- 심지어 역문제까지 풀 수 있다
이 조합은 너무 매력적이었다. 수치해석은 정확하지만 느리고, 순수 딥러닝은 빠르지만 물리를 모른다. 그렇다면 신경망의 손실함수 안에 물리 법칙을 넣으면 두 세계의 장점을 동시에 가질 수 있지 않을까?
문제는, "아이디어가 좋다"와 "실제로 넓은 범위에서 잘 작동한다"는 완전히 다른 이야기라는 점이다.
2023년 10월 공개된 논문 PINNacle: A Comprehensive Benchmark of Physics-Informed Neural Networks for Solving PDEs 는 이 차이를 정면으로 드러냈다. 제목부터 강하다. 이 논문은 새 PINN 변형을 제안하는 글이 아니다. 오히려 지금까지 나온 대표 PINN 계열을 한자리에 세워 놓고, 진짜로 어디까지 되나 시험한 글이다. 공식 저장소 README에 따르면 이 작업은 이후 NeurIPS 2024 에 채택되었다.
이 특집의 핵심 메시지는 한 문장으로 요약할 수 있다.
PINNacle은 PINN의 승전보가 아니라, PINN이 어디서 잘 되고 어디서 무너지는지를 처음으로 체계적으로 드러낸 논문이다.
이 글에서는 다음 순서로 이야기를 풀어가겠다.
- 왜 PINN이라는 발상이 등장했는가
- PINN은 어떤 원리로 작동하는가
PINNacle은 정확히 무엇을 어떻게 시험했는가- 논문이 드러낸 가장 불편한 진실은 무엇인가
- 그런데도 왜 PINN은 여전히 중요한가
- 2026년 지금, PINN은 어디에 쓰고 어디에는 쓰지 말아야 하는가
1. 왜 이런 개념이 나오게 되었는가 — 수치해석과 딥러닝의 어긋난 장점

편미분방정식(PDE)은 현실을 기술하는 언어다. 열이 퍼지는 방식, 유체가 흐르는 방식, 진동이 전파되는 방식, 농도가 확산되는 방식, 전자기장이 형성되는 방식이 모두 PDE로 적힌다.
그런데 이 PDE를 실제로 푸는 전통적 방법은 생각보다 만만하지 않다.
전통 수치해석의 세계
FEM, FDM, FVM 같은 고전적 수치해석은 수십 년에 걸쳐 검증됐다. 이 방법들의 장점은 분명하다.
- 물리적으로 신뢰할 수 있다
- 경계조건과 보존 법칙을 정교하게 반영할 수 있다
- 산업 현장에서 검증된 워크플로가 많다
하지만 대가도 크다.
- 3D 복잡 형상은 메시 생성부터 어렵다
- 파라미터가 바뀔 때마다 다시 풀어야 한다
- 고해상도 장시간 시뮬레이션은 매우 비싸다
순수 딥러닝의 세계
반대로 데이터 기반 신경망은 한번 학습하면 예측이 매우 빠르다. 복잡한 함수 근사도 잘한다. 하지만 과학 문제에서는 치명적인 약점이 있다.
- 좋은 학습 데이터를 대량으로 모으기 어렵다
- 학습 범위를 벗어나면 물리적으로 말이 안 되는 예측을 할 수 있다
- 에너지 보존, 질량 보존 같은 제약을 자동으로 지키지 않는다
| 접근법 | 강점 | 치명적 약점 | 대표 상황 |
|---|
| 전통 수치해석 | 정확도, 신뢰성, 검증된 워크플로 | 계산 비용, 재계산 비용, 메시 복잡성 | 정확한 forward simulation |
| 순수 데이터 기반 딥러닝 | 빠른 추론, 함수 근사, 대규모 반복 예측 | 물리 위반, 외삽 취약성, 데이터 의존 | 데이터가 풍부한 surrogate |
| PINN | 물리 priors + 적은 데이터 + 역문제 친화성 | 훈련 불안정, 문제 의존성, 범용성 부족 | sparse inverse / physics-aware learning |
PINN은 바로 이 간극에서 태어났다. 목적은 단순했다.
데이터가 적어도, 물리 법칙을 활용해 더 그럴듯한 해를 학습하자.
역사는 생각보다 오래됐다
많은 사람이 PINN의 시작을 2019년으로 기억하지만, 씨앗은 훨씬 오래전인 1998년에 있다. Isaac Lagaris 등의 논문 Artificial Neural Networks for Solving Ordinary and Partial Differential Equations 는 신경망으로 미분방정식을 푸는 발상을 이미 제시했다.
당시 아이디어는 지금의 PINN보다 더 "수작업적"이었다. 경계조건을 만족하는 시행해(trial solution)를 설계한 뒤, 신경망이 남은 부분을 근사하게 했다. 시대를 너무 앞서간 아이디어였다. 하지만 자동미분도, 현대 GPU도, 대형 딥러닝 생태계도 없던 시절이라 주류가 되지 못했다.
전환점은 2019년이다. Maziar Raissi, Paris Perdikaris, George Em Karniadakis의 고전 논문 Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations 이 등장하면서 분위기가 달라졌다. 이 논문은 현대 딥러닝 프레임워크의 자동미분(autodiff) 을 이용해 PDE 잔차를 직접 손실함수에 넣는 방법을 체계화했다.
1998
Lagaris et al.
신경망으로 ODE/PDE 풀이의 씨앗
→
2019
Raissi et al.
현대적 PINN 정식화
↓
2020–2022
PINN variants 폭증
NTK, LRA, RAR, gPINN, XPINN, FBPINN
→
2023 / 2024
PINNacle
기대치를 냉정하게 검증
이 흐름을 이해하면 PINNacle의 역사적 의미가 보인다. 이 논문은 "새로운 약속"이 아니라, 첫 대규모 현실 점검에 가깝다.
2. PINN의 핵심 원리 — 손실함수에 물리 법칙을 넣는다는 것

PINN의 핵심은 의외로 단순하다. 일반 신경망은 데이터와의 오차만 줄인다. PINN은 여기에 물리 법칙을 얼마나 위반하는지를 추가로 벌점으로 준다.
가장 단순한 형태의 PINN 손실은 대개 이렇게 적는다.
LPINN=λdLdata+λfLphysics+λbLBC/IC
여기서
- Ldata: 관측 데이터와 예측의 차이
- Lphysics: PDE 잔차(residual)
- LBC/IC: 경계조건(boundary)과 초기조건(initial condition) 오차
를 뜻한다.
예를 들어 어떤 PDE가
N[u(x,t)]=0
형태라면, 신경망이 예측한 u^(x,t)를 이 식에 넣었을 때
f(x,t)=N[u^(x,t)]
가 0에 가까워지도록 학습한다. 즉, "정답 데이터와 비슷해야 한다" 와 "물리 법칙도 대충이 아니라 실제로 만족해야 한다" 를 동시에 요구하는 셈이다.
자동미분이 왜 중요한가
여기서 게임 체인저가 등장한다. 바로 자동미분이다.
PINN은 신경망 출력 u^를 입력 변수 x,t에 대해 미분해야 한다. 전통 수치해석처럼 격자 위 유한차분으로 근사하는 게 아니라, 딥러닝 프레임워크가 내부적으로 제공하는 미분을 그대로 활용한다. 이것이 2019년 이후 PINN이 폭발적으로 연구되기 시작한 핵심 이유다.
왜 처음엔 이렇게 유망해 보였을까
이 발상이 매력적인 이유는 너무 명확하다.
-
데이터가 적어도 된다
방정식 자체가 강한 정규화 역할을 한다.
-
역문제에 강해 보인다
내부 계수나 물성을 데이터와 PDE를 동시에 이용해 추정할 수 있다.
-
메시 프리(mesh-free)처럼 보인다
복잡한 메시 생성 부담을 줄일 수 있을 것처럼 보였다.
-
하나의 프레임워크로 forward / inverse를 모두 다룬다
연구자에게는 아주 매혹적이다.
이 때문에 2019년 이후 PINN은 "과학 AI의 공통 인터페이스"처럼 받아들여지기 시작했다.
NOTE
중요한 오해 하나: PINN은 "수치해석이 필요 없는 마법"이 아니다. 실제로는 PDE, 경계조건, 샘플링 전략, 손실 가중치, 네트워크 구조, 옵티마이저가 모두 얽힌 매우 민감한 학습 시스템이다. PINNacle이 보여준 것은 바로 이 민감성의 규모였다.
3. 드디어 등장한 냉정한 시험장 — PINNacle은 무엇을 벤치마크했는가

PINNacle의 가장 큰 공로는 "PINN이 된다 / 안 된다"를 감으로 말하지 않고, 광범위한 PDE 세트와 여러 PINN 변형을 같은 규칙으로 비교했다는 점이다.
논문 구조는 세 덩어리로 이해하면 쉽다.
- Dataset: 22개 PDE 케이스
- Toolbox: 10여 개 대표 PINN 변형
- Evaluation: 공통 지표로 비교
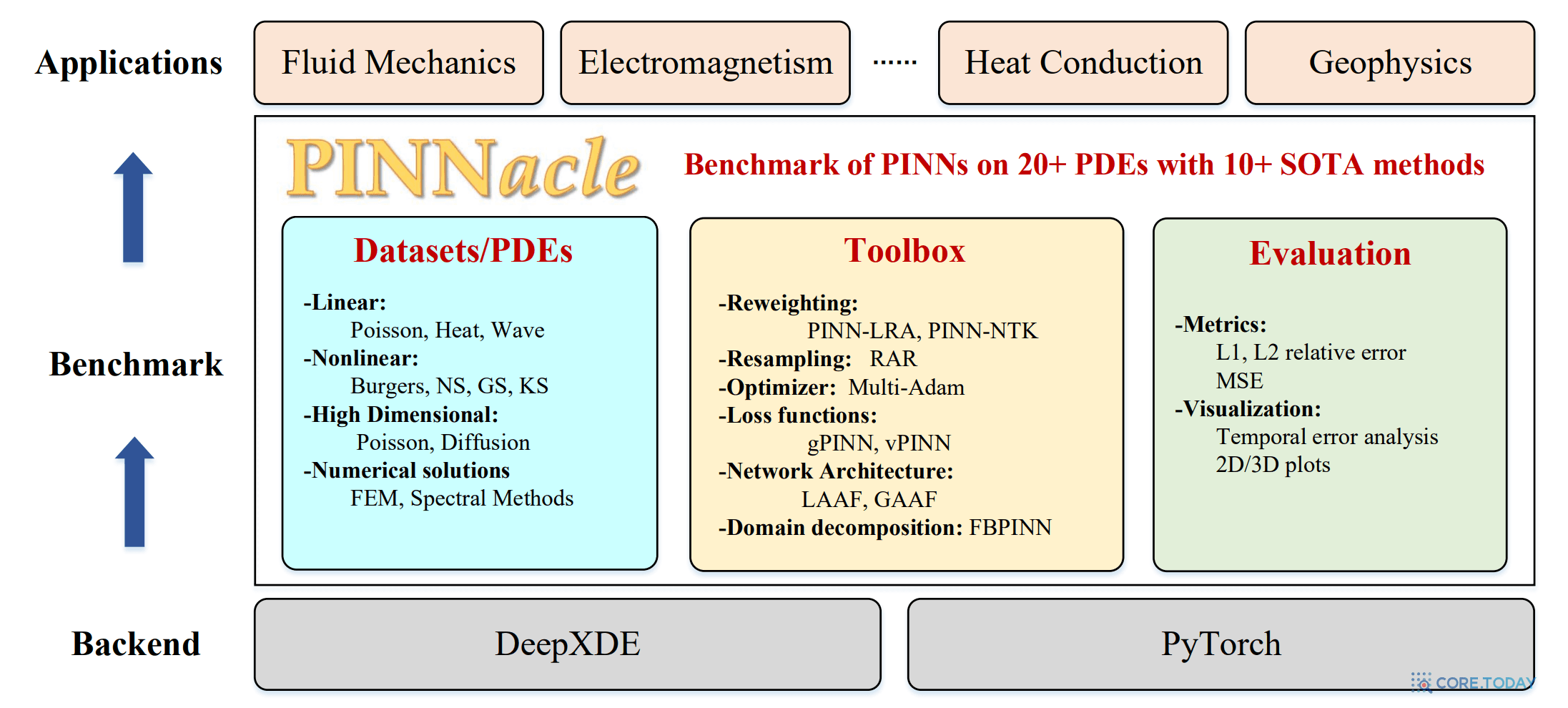
출처: PINNacle GitHub 저장소 resources/pinnacle.png (MIT License).
22개 케이스는 어떤 문제들인가
논문은 Appendix B에서 22개 케이스를 구체적으로 정의한다. 큰 묶음으로 보면 다음과 같다.
| 문제군 | 개수 | 대표 예시 | 왜 중요한가 |
|---|
| Burgers | 2 | Burgers1d-C, Burgers2d-C | 비선형 transport와 shock 성격 |
| Poisson | 4 | Poisson2d-C, Poisson2d-CG, Poisson3d-CG, Poisson2d-MS | 복잡 형상, 이질 계수, 3D 구조 |
| Heat / Diffusion | 4 | Heat2d-VC, Heat2d-MS, Heat2d-CG, Heat2d-LT | 시간축, 멀티스케일, 장시간 적분 |
| Navier-Stokes | 3 | NS2d-C, NS2d-CG, NS2d-LT | 유체역학의 대표 난제 |
| Wave | 3 | Wave1d-C, Wave2d-CG, Wave2d-MS | 2차 시간 미분, 진동, 보존 특성 |
| Chaotic PDE | 2 | Gray-Scott (GS), Kuramoto-Sivashinsky (KS) | 민감도와 chaotic dynamics |
| High-dimensional | 2 | PNd, HNd | 차원의 저주와 mesh-free의 가능성 |
| Inverse | 2 | PInv, HInv | coefficient reconstruction |
여기서 중요한 건 개수보다도 난제 축이다. 논문은 네 가지를 핵심 challenge로 꼽는다.
- complex geometry
- multi-scale phenomena
- nonlinear / chaotic behavior
- high dimensionality
이 네 가지는 실제 산업과 과학 문제의 핵심이기도 하다. 깔끔한 1D toy problem만으로는 절대 드러나지 않는 부분들이다.
어떤 방법들이 비교 대상이었나
PINNacle은 대표적인 PINN 변형을 계열별로 묶어 비교했다.
PINNacle이 비교한 방법 계열
Loss Reweighting
PINN-LRA, PINN-NTK
손실항 간 수렴 속도 불균형 완화
Resampling
RAR
어려운 지점에 collocation 재배치
Optimizer
MultiAdam, Adam+LBFGS
multi-objective scale mismatch 완화
Loss Formulation
gPINN, hp-VPINN / vPINN
gradient loss 또는 variational form 추가
Architecture
LAAF, GAAF
adaptive activation으로 표현력 보강
Domain Decomposition
FBPINN
복잡 형상·국소 구조를 쪼개서 해결
이 논문이 좋은 이유는, "A가 B보다 좋다"는 광고가 아니라 어떤 계열의 아이디어가 어떤 종류의 난제에서 의미를 갖는지를 읽게 해 준다는 점이다.
4. 논문이 드러낸 가장 중요한 결과 — vanilla PINN은 생각보다 자주 실패한다
드디어 핵심 결과다. 논문은 L2 relative error 10% 이하를 성공 기준으로 봤을 때, vanilla PINN이 22개 중 10개만 해결한다고 정리한다.
PINNacle의 핵심 충격: vanilla PINN 성공 비율
이 수치가 왜 중요한가? 이유는 간단하다. PINN은 종종 몇몇 대표 예시에서 매우 인상적인 그림을 보여 줬다. 그런데 PINNacle은 그 그림을 22개 현실형 문제 세트로 확장했을 때 성적이 얼마나 흔들리는지 보여줬다.
논문 본문 discussion과 Table 3에서 읽을 수 있는 메시지를 정리하면 이렇다.
| 난제 유형 | 대표 케이스 | 논문 메시지 | 상대적으로 눈에 띈 방법 |
|---|
| 복잡 형상 | Poisson2d-CG, Heat2d-CG | loss reweighting, resampling, adaptive activation이 일부 개선 | PINN-NTK / PINN-LRA / LAAF |
| 멀티스케일 | Poisson2d-MS, Heat2d-MS, Wave2d-MS | 큰 구조와 미세 구조를 동시에 맞추는 데 지속적으로 고전 | PINN-NTK, 일부 domain decomposition |
| 비선형·chaotic | Burgers2d-C, GS, KS, NS 계열 | few methods can adequately address nonlinear problems | FBPINN on GS, MultiAdam in 일부 단순 케이스 |
| inverse | PInv, HInv | variational formulation이 특히 강함 | vPINN / hp-VPINN |
| 장시간·고차원 | Heat2d-LT, Poisson3d-CG, HNd | Heat2d-LT, Poisson3d-CG에서는 전 방법 실패. HNd는 LBFGS가 힌트 | PINN + LBFGS on HNd |
몇 개의 숫자는 꼭 기억할 만하다
- vanilla PINN: 22개 중 10개만 성공
- Poisson2d-CG: loss reweighting / resampling 계열이 1.43% 수준의 좋은 결과를 보인 예시
- HInv: vPINN이 1.19% 로 inverse setting에서 강점
- GS: FBPINN이 7.99% 로 chaotic 케이스에서 눈에 띄는 성과
- Heat2d-CG: LAAF가 2.39% 로 가장 좋은 fitting result
- Poisson3d-CG, Heat2d-LT: 논문 discussion 기준으로 모든 방법 실패
이 숫자들이 말하는 바는 단순하다.
PINN은 "좋은 아이디어"이지만, 그 자체로는 범용 PDE 솔버가 아니다.
왜 이렇게 되는가
이 질문은 이후의 NTK, loss landscape, spectral bias 계열 연구와 이어진다. 지금 이 글에서 직관만 요약하면 이렇다.
1
PDE 잔차, 경계조건, 데이터 항은 서로 다른 난이도와 스케일을 가진다.
2
하나의 네트워크가 복잡 형상, 고주파, 긴 시간축, 비선형성을 동시에 표현해야 한다.
3
학습은 특정 손실이나 특정 모드에 치우치고, 어려운 부분은 오래 남는다.
4
결국 toy problem에선 그럴듯해도, 실제 난제에서는 안정성과 재현성이 급격히 흔들린다.
즉, PINNacle은 PINN이 틀렸다고 말하는 논문이 아니라, PINN의 난점이 어디서 시작되는지 좌표를 찍어 준 논문이다.
WARN
PINNacle을 "PINN은 끝났다"로 읽으면 오독이다. 이 논문이 진짜로 말하는 것은 "문제 난이도와 방법 계열의 궁합을 보지 않고 vanilla PINN 하나로 다 하려는 사고가 위험하다"는 쪽에 가깝다.
5. 그런데도 왜 PINN은 여전히 중요한가 — 사례로 보면 이유가 보인다
논문 결과만 보면 "그럼 PINN은 별로 아닌가?"라는 반응이 나올 수 있다. 하지만 이 결론은 절반만 맞다.
PINN은 모든 PDE를 빠르고 안정적으로 푸는 일반 해법으로는 실망스러울 수 있다. 하지만 데이터가 적고, 물리 priors가 강하며, 숨은 파라미터를 찾아야 하는 문제에서는 여전히 매우 매력적이다.
사례 1. 배터리와 열관리
배터리 팩, 전력반도체, 열교환기 같은 시스템은 PDE 없이는 설명이 안 된다. 그런데 실제 센서는 적고, 내부 상태는 직접 보기 어렵다. 이때 중요한 것은 단순히 온도를 예측하는 것보다, 열전도 계수, 경계 조건, 내부 열원 같은 숨은 파라미터를 추정하는 것이다.
이런 문제는 전형적인 inverse problem이다. PINNacle이 inverse 케이스에서 variational 계열이 강했다고 보고한 이유도 여기에 있다. PINN은 데이터가 희소할수록 오히려 "물리 priors"를 leverage하는 구조가 된다.
사례 2. 유체와 공력 설계
항공, 자동차, 터보머신, 혈류 해석에서는 유체 PDE가 핵심이다. 이 영역에서 PINN이 곧바로 classical CFD를 대체할 것이라는 기대는 지나쳤다. PINNacle은 NS 계열과 wave 계열, 장시간 문제에서 이런 기대가 얼마나 낙관적이었는지 보여준다.
하지만 유체 문제에서도 PINN의 위치가 완전히 사라지는 것은 아니다.
- 일부 경계나 파라미터를 역추정할 때
- sparse sensor에서 내부 유동장을 추정할 때
- 설계 loop 안에서 일부 제약을 학습 모델에 넣고 싶을 때
즉, 정면승부형 full CFD replacement 보다는 inverse / constrained surrogate / hybrid loop 쪽이 더 현실적이다.
사례 3. 재료·지구과학·의료
이 세 분야는 공통점이 있다.
- 전체 내부장을 완전히 관측할 수 없다
- 실험 데이터는 비싸고 적다
- 물리 법칙은 꽤 잘 알려져 있다
예를 들어
- 재료 내부 확산 계수 추정
- 지하 매질의 물성 역추정
- 생체 내부 유동이나 전달 현상 추정
같은 문제는 PINN의 개성이 잘 살아나는 영역이다. 이때 중요한 것은 "정답장을 많이 맞히는 것"보다 적은 데이터로 물리적으로 말이 되는 파라미터를 식별하는 것이다.
사례 4. 디지털 트윈과 simulator-in-the-loop
2026년의 과학 ML에서 PINN이 여전히 살아남는 또 하나의 이유는 hybrid workflow 때문이다.
실무에서는 대개 이렇게 간다.
- classical solver가 기준 해를 준다
- 실측 데이터가 일부 들어온다
- 학습 모델이 일부 unknown parameter를 맞춘다
- operator model 또는 surrogate가 반복 추론 속도를 높인다
여기서 PINN은 "전체 파이프라인의 왕"이 아니라, 물리 제약을 학습 안으로 끌어오는 연결부로 쓰인다.
6. PINNacle이 조용히 알려주는 실전 팁 — 하이퍼파라미터도 생각보다 중요하다
이 논문의 흥미로운 부분은 메인 테이블만이 아니다. ablation도 꽤 중요하다.
논문은 기본적으로 대부분의 실험을 20,000 epochs, learning rate 0.001 에서 수행하고, 별도의 분석에서 batch size, epoch 수, learning rate schedule 영향을 살펴본다.
핵심 메시지는 다음과 같다.
- batch size가 커질수록 대체로 성능이 좋아지는 경향이 있다
- epoch를 늘리면 좋아지지만 어느 지점 이후 포화된다
- learning rate는 문제마다 최적점이 다르며, 너무 크면 불안정하고 너무 작으면 매우 느리다
- 10−3 또는 10−4, 혹은 step decay 가 상대적으로 안정적이었다
이건 실무적으로 꽤 중요하다. PINN 논문을 읽을 때 종종 "모델 구조"에만 눈이 가지만, 실제로는 학습 레시피가 결과를 크게 좌우한다.
TIP
실전에서 가장 위험한 착각: PINN이 안 되는 이유를 곧바로 "아이디어가 틀려서"라고 단정하는 것이다. 반대로, 한두 개 설정으로 잘 되었다고 "이제 다 된다"고 결론내리는 것도 똑같이 위험하다. PINNacle은 바로 이 양극단을 동시에 경계하게 만든다.
7. 2026년의 현실 — PINN, Neural Operator, 전통 솔버는 어떻게 역할을 나누는가

2026년 현재, 과학 ML의 풍경은 훨씬 분화됐다. 이제 질문은 "PINN이 좋으냐 나쁘냐"가 아니다. 더 정확한 질문은 이것이다.
이 문제에서 PINN이 맞는 도구인가, 아니면 Neural Operator나 전통 솔버가 더 자연스러운가?
1. PINN이 좋은 자리
- sparse observations가 있는 inverse problem
- 물성, 계수, source term 같은 parameter identification
- geometry가 복잡하지만 데이터는 적고 물리는 강한 문제
- 실측 데이터와 PDE를 함께 묶어야 하는 문제
- simulator-in-the-loop optimization
이 자리는 PINN의 정체성과 맞닿아 있다.
2. Neural Operator가 좋은 자리
이 저장소에는 이미 DeepONet 해설, FNO 해설, PINN vs Neural Operator 비교 글 이 있다. 이 글들과 PINNacle을 함께 읽으면 차이가 선명해진다.
Neural Operator 계열은 보통 이런 데 더 잘 맞는다.
- 같은 PDE family에 대해 여러 조건을 반복 추론해야 할 때
- 충분한 학습 데이터가 있을 때
- 하나의 해가 아니라 연산자 전체를 배우고 싶을 때
- surrogate inference throughput이 중요할 때
즉, "한 번 학습해 두고 계속 써먹을 문제"라면 PINN보다 operator learning 쪽이 더 자연스러운 경우가 많다.
3. 전통 솔버가 여전히 기본인 자리
PINNacle이 가장 강하게 밀어주는 현실 인식은 여기다.
- 고정밀 forward solve가 정말 중요할 때
- 장시간 안정성이 필수일 때
- 강한 비선형·멀티스케일·복잡 형상이 한꺼번에 올 때
- 이미 검증된 solver stack이 있을 때
이때 classical solver는 여전히 기본축이다. PINN이 있다고 해서 이 자리가 사라지지 않는다.
4. 그래서 2026년의 답은 "하이브리드"
실제로는 세 가지를 함께 쓴다.
| 도구 | 가장 잘 맞는 역할 | 약점 | 2026년의 현실적 위치 |
|---|
| PINN | inverse, sparse-data, physics-constrained fitting | 훈련 불안정, 문제 의존성, 범용 forward solver 아님 | 전문가용 specialist |
| Neural Operator | many-query surrogate, operator learning | 데이터 준비 비용, geometry 제약 | 반복 추론용 accelerator |
| Classical Solver | 정확한 baseline, 고신뢰 forward simulation | 느림, 재계산 비용, 워크플로 복잡 | 여전히 기준축 |
| Hybrid | solver + PINN + operator 조합 | 파이프라인 설계 난도 | 가장 현실적인 운영 모드 |
8. 그래서 PINNacle은 왜 중요한가 — 기대를 깨뜨렸기 때문에
어떤 논문은 새 성능 기록을 세워서 중요해진다. PINNacle은 조금 다른 이유로 중요하다. 이 논문은 환상을 정리했기 때문에 중요하다.
PINN이 처음 등장했을 때 많은 사람이 기대했던 것은 사실상 이것이었다.
- 적은 데이터로도 PDE를 잘 푼다
- 메시 없이도 된다
- forward와 inverse를 모두 포괄한다
- 복잡한 과학 문제를 하나의 신경망 패러다임으로 다룬다
PINNacle은 이 기대를 아주 구체적인 문장으로 고쳐 준다.
- 어떤 문제는 정말 된다
- 하지만 어떤 문제는 잘 안 된다
- 잘 안 되는 이유는 우연이 아니라 구조적이다
- 그래서 방법 계열을 문제 특성에 맞게 고르지 않으면 안 된다
이건 실망스러운 결론이면서 동시에 건강한 결론이다. 왜냐하면 과학과 공학은 원래 그런 분야이기 때문이다. 좋은 아이디어 하나가 모든 PDE를 정복하는 경우는 거의 없다.
오히려 PINNacle 이후의 풍경이 더 성숙하다.
- loss reweighting은 어디에 필요한가
- domain decomposition은 왜 geometry와 multiscale에 먹히는가
- variational form은 inverse problem에서 왜 강한가
- operator learning은 언제 PINN보다 더 자연스러운가
이런 질문이 가능해졌기 때문이다.
맺으며 — PINN의 실패는 아이디어의 실패가 아니다
이 글의 마지막 문장은 이렇게 남겨 두고 싶다.
PINN의 실패는 아이디어의 실패가 아니라, 물리를 손실에 넣는 것만으로는 충분하지 않다는 사실의 발견이었다.
PINNacle은 PINN을 끝장낸 논문이 아니다. 오히려 PINN을 어디에 써야 하고 어디에서는 기대를 낮춰야 하는지 처음으로 제대로 알려 준 논문이다.
그래서 2026년의 관점에서 보면, PINN은 더 이상 "모든 PDE를 대체할 차세대 솔버"가 아니다. 대신 물리 제약을 학습에 주입하는 매우 강력하지만, 문제 특성에 민감한 전문 도구가 되었다.
이건 후퇴가 아니다. 오히려 기술이 성숙했다는 신호에 가깝다.
함께 읽으면 좋은 글
참고 문헌과 원출처
- Zhongkai Hao et al., PINNacle: A Comprehensive Benchmark of Physics-Informed Neural Networks for Solving PDEs
- 공식 저장소: PINNacle GitHub
- Isaac E. Lagaris et al., Artificial Neural Networks for Solving Ordinary and Partial Differential Equations
- Maziar Raissi et al., Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations



