프롤로그: 2026년 7월 2일, 어느 사내 회의
목요일이었다. 마크 저커버그가 직원들 앞에 섰다. 로이터가 나중에 입수한 회의 녹취록에 따르면, 그는 이렇게 말했다.
"지난 최소 넉 달간 에이전트 개발의 궤적은, 솔직히 우리가 기대했던 만큼 빨라지지 않았습니다."
그리고 한마디 더. 메타의 새 AI 중심 조직 개편이 아직 "결실을 맺지 못했다(hasn't come to fruition yet)". 몇 달 전의 대규모 정리해고는 "우리가 원했던 만큼 깔끔하지 않았다". 왜 그렇게 서둘러 사람을 내보냈느냐는 물음에, 그는 "우리가 충분히 빨리 적응하지 못할까 봐 걱정했다"고 답했다.

이 짧은 발언이 왜 그렇게 화제가 됐을까. 불과 두 달 전, 메타는 약 8,000명을 내보냈다. AI가 프로그래머를 대체할 수 있으리라는 믿음 위에서 내린 결정이었다. 그런데 그 믿음의 설계자 격인 CEO가, 스스로 "기대만큼 안 됐다"고 인정한 것이다.
이 글은 그 고백에서 출발한다. 하지만 저커버그를 비웃자는 글이 아니다. 진짜 질문은 이것이다 — 메타가 베팅한 그 기술, '개발자를 대체하는 AI 코딩 에이전트'란 대체 무엇이고, 어디서 왔으며, 2026년 지금 진짜로 무엇을 할 수 있는가?
용어가 생소해도 괜찮다. HumanEval, ReAct, SWE-bench 같은 낯선 이름들을 하나씩, 그림과 사례로 풀어간다. 이 글이 끝나면 당신은 뉴스의 헤드라인 너머, "코드를 쓰는 것"과 "소프트웨어를 만드는 것"이 왜 다른지를 스스로 설명할 수 있게 될 것이다.
제1장: 메타는 정확히 무엇에 베팅했나
↓
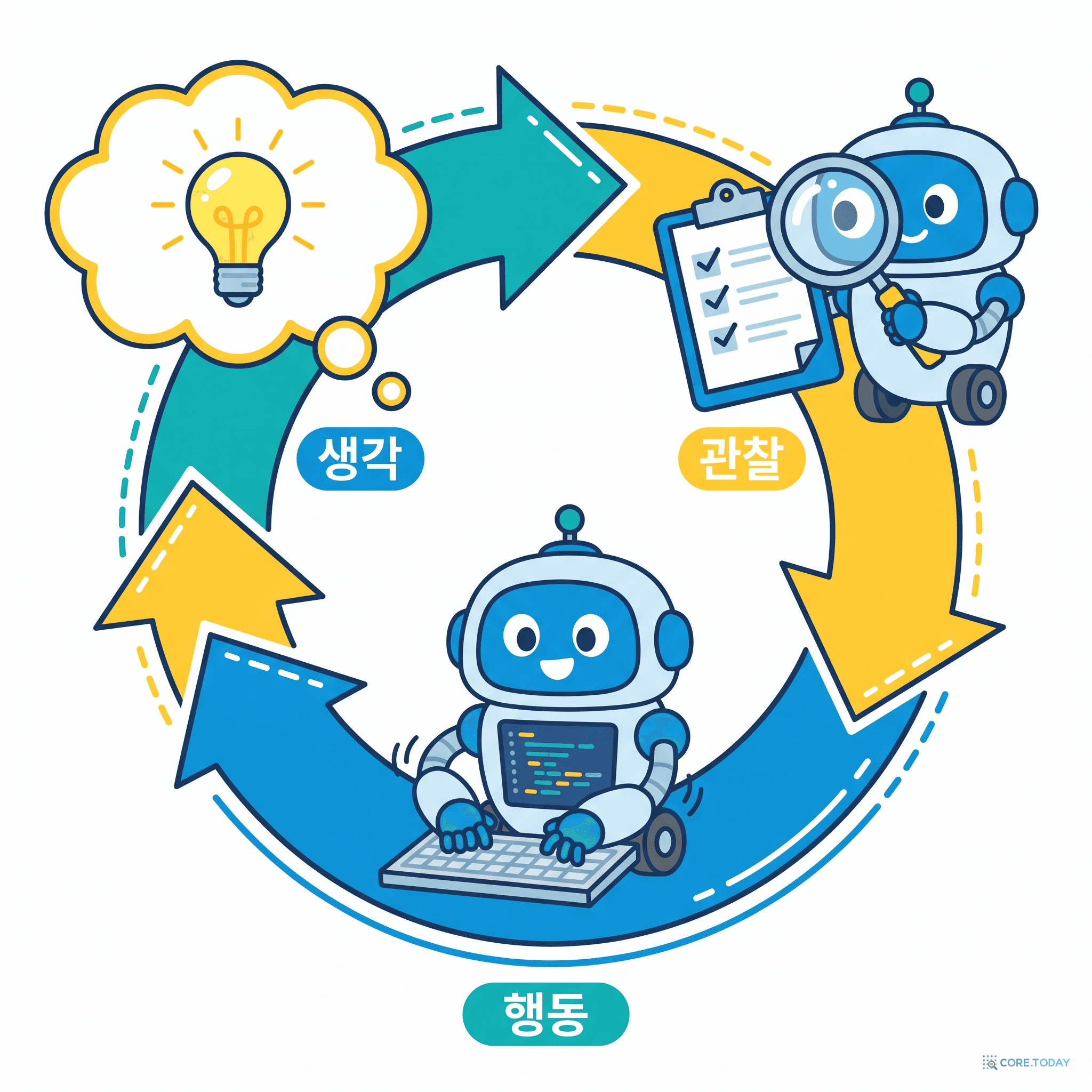
제2장: '코딩 에이전트'란 무엇인가 — 다섯 개의 부품
↓
제3장: 계보 — HumanEval에서 Claude Code까지
↓
제4장: 아키텍처 해부 — 루프·인터페이스·검증
↓
제5장: 1.96% → 90%, 숫자의 마법과 함정
↓
제6장: 왜 도박은 빗나갔나 — 진짜 증거들
↓
제7장: AI 부메랑 — 메타만이 아니다
↓
제8장: 2026년, 진짜 역할 — 대체가 아니라 증강
제1장: 메타는 정확히 무엇에 베팅했나
2026년의 메타를 이해하려면 숫자 세 개를 기억하면 된다.
~8,000명
2026년 5월 정리해고 (전 직원의 약 10%)
~7,000명
새 AI 조직으로 재배치된 인원
~$1,450억
2026년 AI 인프라 투자 계획
메타는 2025년 6월, 알렉산더 왕(Alexandr Wang) — 데이터 라벨링 기업 스케일AI(Scale AI)의 창업자 — 를 첫 최고AI책임자(CAO)로 영입했다. 메타는 스케일AI 지분 약 49%를 143억 달러에 사들이며 그를 데려왔고, 그는 '메타 초지능 연구소(Meta Superintelligence Labs)'를 이끌게 됐다.
왕이 어떤 사람인지는 그의 발언에서 드러난다. 2025년 9월 한 팟캐스트에서 그는 이렇게 말했다.
"내가 AI 코딩에 얼마나 급진화(radicalized)됐는지는 아무리 강조해도 부족하다." — 그리고 자신을 포함한 엔지니어들이 지금 쓰는 코드는 "5년 안에 쓸모없어질 것"이라고 덧붙였다.
메타가 베팅한 명제는 여기서 나온다: "충분히 강력한 AI 코딩 에이전트가 곧 등장한다. 그러니 인간 프로그래머를 대량으로 줄이고, 그 자리를 AI로 채우면 된다." 마침 시장에는 앤트로픽의 Claude Code(2025년 2월 프리뷰, 5월 정식 출시)처럼 터미널에서 실제로 코드를 읽고 고치는 도구가 폭발적으로 성장 중이었으니, 그 낙관은 근거 없는 것도 아니었다.

📌 팩트와 해석을 나누자. 위 숫자들(8,000명·7,000명·1,450억 달러)과 저커버그·왕의 인용은 로이터·TechCrunch·CNBC·Fortune 등 복수 매체로 교차 확인된 사실이다. 반면 이 사건을 처음 화제로 띄운 블로거(Eshu Marneedi)가 붙인 "감으로 하는 경영(vibes-based management)", "직원 감시 스파이웨어", "왕이 정리해고를 설계했다" 같은 표현은 해석·논평에 가깝다. 실제로 왕의 영향력은 2026년 3월 별도의 'Applied AI Engineering' 조직이 신설되며 오히려 축소됐다는 보도도 있다. 이 글은 사실과 프레이밍을 구분해서 다룬다.
한 가지 실제 사건은 짚고 넘어가자. 2026년 4월, 메타는 미국 직원들의 업무용 PC에 소프트웨어를 깔아 마우스 움직임·클릭·키 입력, 일부 스크린샷을 수집한다고 밝혔다(공식 명칭 'Model Capability Initiative'). 화이트칼라 업무를 대신할 AI 에이전트를 학습시키기 위한 데이터였다. 심지어 3월에는 약 6,500명의 엔지니어가 "깜짝 이메일"을 받고 자기 모델을 학습시킬 코딩 문제를 만드는 데이터 라벨러로 재배치됐다. CTO 앤드루 보즈워스는 6월 사내 분위기를 "20년 만에 최악에 가깝다"고 표현했다.
정리하면, 메타의 도박은 단순한 인력 감축이 아니라 회사의 근간을 'AI가 곧 사람 개발자를 대체한다'는 하나의 명제 위에 재배치한 것이었다. 그렇다면 그 명제의 주인공, '코딩 에이전트'부터 정확히 알아야 한다.
제2장: '코딩 에이전트'란 무엇인가 — 다섯 개의 부품
먼저 오해 하나를 풀자. 코딩 에이전트는 "질문하면 코드를 뱉는 챗봇"이 아니다. 그건 자동완성이다. 에이전트는 한 단계 위다 — 목표를 주면, 스스로 파일을 읽고, 고치고, 테스트를 돌리고, 실패를 보고 다시 고치는 일을 끝날 때까지 반복하는 시스템이다.
2026년의 어떤 코딩 에이전트든, 뜯어보면 똑같은 다섯 개의 부품으로 되어 있다.
코딩 에이전트의 5대 부품
① LLM (두뇌)
추론·계획의 핵심. 다음에 무엇을 할지 결정한다
② 도구 (손발)
파일 읽기·쓰기, 셸(bash), 코드 검색, 웹 브라우저
③ 루프 (심장)
생각→행동→관찰을 끝날 때까지 반복
④ 검증 (양심)
테스트·빌드·린터로 "진짜 됐는지" 확인
⑤ 컨텍스트 관리 (기억)
거대한 코드베이스를 한정된 창에 맞게 취사선택
이 다섯 개가 왜 중요한지는 각각이 하나의 논문·사건에서 태어났기 때문이다. 놀랍게도 이 부품들은 지난 5년에 걸쳐 하나씩 발명됐다. 그 순서를 따라가는 것이 이 글의 3장이다. 미리 한 줄로 요약하면:
HumanEval이 "측정"을 주고 → ReAct가 "루프"를 주고 → Toolformer가 "도구 사용"을 주고 → AutoGPT가 "반면교사"를 주고 → SWE-bench가 "진짜 목표"를 주고 → SWE-agent가 "인터페이스"를 주고 → Claude Code·Codex CLI가 이 모두를 제품으로 묶었다.
(에이전트라는 개념 자체가 처음이라면 《AI 에이전트 완전 정복》과 《에이전틱 AI 심층 해부》를 곁들여 읽으면 좋다.)
제3장: 계보 — HumanEval에서 Claude Code까지
2021
Codex & HumanEval — "측정"의 탄생
코드가 진짜 돌아가는지를 재는 법. GitHub Copilot의 뿌리.
2022
ReAct — "루프"의 발명
생각→행동→관찰. 오늘날 모든 에이전트의 원형.
2023
Toolformer / AutoGPT / SWE-bench
도구 사용(메타!)·자율성의 환상·진짜 벤치마크가 한 해에.
2024
SWE-agent / Devin — "인터페이스"와 "하이프"
에이전트 전용 인터페이스, 그리고 "최초의 AI 엔지니어" 논란.
2025~2026
Claude Code / Codex CLI — 제품화
터미널에 사는 에이전트. '하네스 엔지니어링'의 시대.
2021 — Codex & HumanEval: "이게 진짜 돌아가나?"를 재다
문제는 단순했다. AI가 짠 코드가 진짜 작동하는지 어떻게 측정하지? 문장 유사도(BLEU) 같은 걸로는 안 된다 — 겉보기엔 전혀 다른 두 코드가 똑같이 정답일 수 있으니까.
OpenAI의 2021년 논문 《Evaluating Large Language Models Trained on Code》(arXiv 2107.03374)가 답을 냈다. 두 가지 도구를 만든 것이다.
- HumanEval: 사람이 손으로 짠 164개의 파이썬 문제. 각 문제엔 함수 설명과 평균 7.7개의 단위 테스트가 붙어 있다. "생성 → 테스트 실행 → 통과 여부 측정"이라는 채점 방식은 이때 확립됐다.
- pass@k: k번 생성해서 하나라도 테스트를 통과할 확률. 이 지표가 던진 통찰이 결정적이다.
Codex-12B의 HumanEval 성적 — "여러 번 뽑으면 잘한다" (100점 만점)
Codex 100회
70.2%
pass@100
한 번 시켰을 땐 28.8%, 그런데 100번 뽑아 그중 정답이 하나라도 있는지 보면 70.2%. "반복 샘플링은 놀랍도록 강력한 전략"이라는 이 발견은, 나중에 에이전트가 여러 번 시도하며 스스로 고치는 이유의 씨앗이 된다. (Codex의 전체 역사는 《Codex의 탄생 — HumanEval에서 컴퓨터 사용까지》에서.)
2022 — ReAct: 에이전트의 심장이 만들어지다
여기가 이 글에서 가장 중요한 대목이다. 프린스턴대와 구글 브레인의 야오 순위(Shunyu Yao) 등이 쓴 2022년 논문 《ReAct: Synergizing Reasoning and Acting》(arXiv 2210.03629)이 오늘날 모든 에이전트의 루프를 발명했다.
문제의식은 이랬다. 당시 두 가지 방식이 있었는데 둘 다 반쪽짜리였다.
- 생각만 하는 AI(Chain-of-Thought): 머릿속으로만 추론한다. 세상과 단절돼 있어 틀린 사실을 지어내고(환각), 그 오류가 눈덩이처럼 커진다.
- 행동만 하는 AI: 계획 없이 일단 움직인다. 실수해도 되돌아올 줄 모른다.
ReAct의 답은 이 둘을 번갈아 엮는 것이었다. 생성되는 토큰을 세 종류로 나눈다.
🧠 Thought (생각)
"환불 정책을 먼저 확인해야겠다." — 자유로운 추론. 목표를 쪼개고, 진행 상황을 점검하고, 예외를 처리한다. 세상은 아무것도 바꾸지 않는다.
↓
⚡ Action (행동)
search[환불 정책] — 도구·환경에 실제로 내리는 명령. 이것만이 바깥세상을 건드린다.
↓
👁 Observation (관찰)
"정책: 30일 이내 전액 환불." — 환경이 돌려준 결과. 이걸 다시 컨텍스트에 넣고 → 다음 생각으로.
그리고 이 생각 → 행동 → 관찰 → 생각 → … 을 종료 조건이 나올 때까지 반복한다. 이게 전부다. 지금 당신이 쓰는 Claude Code든 Codex든, 그 심장은 예외 없이 이 ReAct 루프의 후손이다.
논문의 그림 1은 같은 질문에 대해 네 방식(표준·생각만·행동만·ReAct)을 나란히 놓고 비교하는데, ReAct만이 실제 관찰에 근거해 추론을 바로잡는 모습을 보여준다. 성능도 극적이었다 — 가상 집안일 벤치마크 ALFWorld에서 +34%p, 온라인 쇼핑 WebShop에서 +10%p. (ReAct를 더 깊이 보려면 《ReAct — 추론과 행동의 결합》, 그 루프를 겹겹이 쌓는 이야기는 《루프를 쌓는 기술》.)
2023 — Toolformer: 도구 쓰는 법을 스스로 배우다 (그런데 이걸 만든 게…)
여기 이 글 최고의 아이러니가 있다. 2023년 2월, 메타 AI가 《Toolformer: Language Models Can Teach Themselves to Use Tools》(arXiv 2302.04761)를 발표했다. 개발자를 대체하겠다며 사람을 내보낸 바로 그 회사가, 에이전트가 도구를 쓰는 법의 초석을 놓은 논문의 저자였던 것이다.
ReAct가 "도구를 써라"라고 프롬프트로 시키는 방식이었다면, Toolformer는 모델이 도구 사용을 타고난 능력처럼 학습하게 했다. 방법이 기발하다.
🤔
문제
LLM은 작은 프로그램도 하는 산수·환율·날짜 계산을 자꾸 틀린다. 어떻게 도구 쓰는 법을 가르치지 않고 배우게 할까?
🔬
해결 — "이 도구가 도움이 됐나?"로 자가 채점
평범한 문장 곳곳에 API 호출을 넣어보고 실제로 실행한다. 그 결과가 뒤에 올 단어들의 예측 오차를 낮췄을 때만 그 호출을 남긴다. 즉, "도구가 정말 도움이 됐을 때만" 학습 데이터로 채택.
🎯
결과
겨우 67억 파라미터 모델이, 여러 과제에서 26배 큰 GPT-3(1,750억)를 앞질렀다. 도구 사용이 '프롬프트 요령'에서 '학습 가능한 능력'으로 승격된 순간.
오늘날 모든 모델이 당연하게 쓰는 함수 호출(function calling)·도구 사용 API의 개념적 다리가 바로 이 Toolformer다. (도구 사용을 더 파고들려면 《Toolformer — 언어 모델이 도구를 쓰다》, 표준화된 도구 연결은 《MCP 서버 이해하기》.)
2023 — AutoGPT: 자율성의 환상, 그리고 반면교사
2023년 3월, AutoGPT가 등장했다. GPT-4에 "목표를 주면 스스로 할 일 목록을 만들고, 도구로 실행하고, 결과를 기억에 쌓고, 다시 우선순위를 정해 반복하는" 바깥 루프를 씌운 것. 몇 주 만에 깃허브 별 10만 개를 찍었다. 하지만 이내 처참한 실패 모드가 드러났다.
| 실패 모드 | 무슨 일이 벌어졌나 |
|---|
| 무한 루프 | "검색 → 파일 쓰기 → 파일 읽기 → 다시 검색"을 영원히 반복. 끝낼 줄을 모른다. |
| "이만하면 됐다"가 없음 | 완료 판정을 LLM이 말로 하니, 다 끝난 일을 끝없이 "개선"하려 든다(완벽주의 편향). |
| 기억이 없음 | 한 일을 기록하지 못해 같은 계획을 뱅뱅 다시 세운다. |
| 비용 폭주 | 연구 과제 하나에 평균 ~$14.4, 어떤 개발자는 max_iterations를 안 걸어 하룻밤 $80이 청구됐다. |
AutoGPT가 증명한 건 역설적이다. 자율성만으로는 아무 쓸모가 없다. 근거(grounding), 검증(verification), 멈출 조건(stop condition)이 없으면 에이전트는 값비싼 무한 루프일 뿐이다. 뒤에 나올 소프트웨어 엔지니어링 에이전트들은 정확히 이 빈칸을 메우려는 시도였다.
2023 — SWE-bench: 기준을 다시 세운 벤치마크
HumanEval의 164개 장난감 문제로는 부족했다. 프린스턴 연구진의 《SWE-bench》(arXiv 2310.06770)는 진짜 오픈소스의 실제 이슈로 판을 갈아엎었다.
Django · Flask · scikit-learn · numpy · pandas · pytest · sympy · matplotlib 등 12개 인기 파이썬 저장소에서 뽑은 2,294개의 "이슈 → 실제 병합된 PR" 쌍.
과제: 이슈 설명 + 저장소 전체를 주고 → 고칠 패치를 만들어라.
채점: 패치를 적용하고 → 저장소의 진짜 테스트를 돌려서 → 지정된 실패 테스트가 통과로 바뀌고, 통과하던 테스트는 계속 통과해야 인정.
무엇이 어려운가? 저장소 규모의 방대한 맥락, 여러 파일을 넘나드는 수정, 어느 파일을 건드려야 하는지 아무도 안 알려줌, 그리고 숨겨진 테스트. 출시 당시 최고 시스템(Claude 2)의 점수는 충격적이었다 — 1.96%. 논문의 파이프라인 그림(이슈+저장소 → 모델 → 패치 → 테스트 하네스 → 해결/실패)은 오늘날 코딩 에이전트 평가의 표준 도식이 됐다. 이후 인간이 검수한 SWE-bench Verified(500개)가 업계 표준 트랙으로 자리 잡는다.
2024 — SWE-agent: 인터페이스가 실력이다 (ACI)
같은 프린스턴 팀의 후속작 《SWE-agent》(arXiv 2405.15793)는 놀라운 걸 발견했다. 똑같은 모델이라도, 인터페이스를 '사람용'이 아니라 '에이전트용'으로 설계하면 훨씬 잘한다는 것. 이걸 에이전트-컴퓨터 인터페이스(ACI)라 부른다.
파일 뷰어
1만 줄을 통째로 쏟지 않고, 딱 필요한 창(window)만 보여준다
edit 명령
수정할 때마다 린터를 자동 실행해, 문법이 깨진 편집은 아예 거절한다
간결한 피드백
에러를 짧고 정보성 있게 돌려줘, 모델이 헤매지 않게 한다
결과: GPT-4 터보로 SWE-bench 12.5%(비대화형 대비 약 6배). 이 논문의 메시지가 나중에 '하네스 엔지니어링'이라는 이름으로 2026년의 화두가 된다 — 에이전트의 실력 상당 부분은 모델이 아니라, 그를 감싼 도구와 피드백 루프에 있다. (하네스 개념은 《오토하네스 — LLM 코드 하네스》와 《하네스 다이내믹 워크플로》.)
2024 — Devin: "최초의 AI 소프트웨어 엔지니어"와 그 역풍
2024년 3월 12일, 코그니션 랩스(Cognition Labs)가 Devin을 "세계 최초의 AI 소프트웨어 엔지니어"로 공개했다. 셸·코드 편집기·웹 브라우저를 갖춘 샌드박스에서, 사람이 목표만 주면 버그 수정·배포·프리랜서 일감까지 끝낸다는 것. SWE-bench 일부에서 13.86%를 기록하며 당시 최고를 찍었다.
🔍
그러나 역풍이 거셌다. 'Internet of Bugs' 같은 개발자들이 데모 영상을 프레임 단위로 뜯어보니, Devin이 스스로 만든 문제를 스스로 푸는 장면, 실제보다 쉬운 작업, 오해를 부르는 벤치마킹이 드러났다. Devin은 이 분야의 교과서적 사례가 됐다 — "데모의 하이프"와 "재현 가능한 실력"은 전혀 다르다. 이 교훈은 2026년 메타 이야기에서 그대로 메아리친다.
2025~2026 — Claude Code · Codex CLI: 터미널로 내려온 에이전트
2025년의 전환은 터미널 네이티브였다. Claude Code(앤트로픽, 2025년 2월)와 OpenAI의 Codex CLI(2025년 4월, 연말에 TypeScript에서 Rust로 재작성)는 셸 안에 살면서 코드베이스 전체를 읽고, 진짜 개발 도구를 상대로 ReAct 루프를 돈다.
이들이 실제로 일하는 방식은 이렇다.
🧠 읽기·계획
grep으로 파일을 찾아 읽고 → 어디를 어떻게 고칠지 계획한다
↓
⚡ 편집·실행
코드를 수정하고 → 테스트와 빌드를 실제로 돌린다
↓
👁 실패 읽기·반복
에러 메시지를 읽고 → 다시 계획으로. 사람은 커밋 승인만.
두 가지 엔지니어링 아이디어가 지배한다. 하네스 엔지니어링(권한·훅·MCP 서버·슬래시 명령·CLAUDE.md 같은 프로젝트 기억 등 모델 바깥의 모든 것)과 컨텍스트 관리(무엇을 언제 불러오고 언제 압축할지). Codex CLI는 MCP 서버를 소비하는 동시에 스스로 MCP 서버가 되어 다른 에이전트가 호출할 수도 있다 — 도구가 도구를 부르는 시대다. (Claude Code의 모든 것은 《Claude Code 2026 특집》에서.)
제4장: 아키텍처 해부 — 루프·인터페이스·검증
이제 2장의 다섯 부품이 어떻게 맞물리는지, 실제 시나리오로 눈으로 보자. 아래는 "로그인 버그를 고쳐라"라는 목표를 받은 코딩 에이전트의 한 사이클이다.
🧠 생각 "로그인 실패라니. 인증 로직부터 찾아보자."
⚡ 행동 grep -r "login" src/ → read auth.ts
👁 관찰 토큰 만료 검사에서 부등호가 반대(> vs <)로 보인다
🧠 생각 "여기가 범인. 고치고 테스트로 확인하자."
⚡ 행동 edit auth.ts (부등호 수정) → npm test
👁 관찰 ❌ 테스트 3개 실패 — 이 수정이 다른 곳을 깼다
🧠 생각 "부작용이 있군. 만료 시간 계산을 다시 보자." → 루프 계속…
여기서 검증(④)의 위력을 보라. npm test가 없었다면 에이전트는 "고쳤다!"고 착각하고 끝냈을 것이다 — 정확히 AutoGPT의 실패 모드다. 테스트라는 객관적 현실이 있기에, 에이전트는 자기 실수를 발견하고 되돌아온다. HumanEval과 SWE-bench가 확립한 "실행 기반 채점"이 여기서 에이전트의 양심으로 작동한다.
또 하나. 실제 저장소는 수백만 줄이라 LLM의 컨텍스트 창에 다 안 들어간다. 그래서 컨텍스트 관리(⑤) — grep으로 관련 파일만 찾고, 필요한 창만 열고, 오래된 내용은 압축 — 가 필수다. (이 기술만 다룬 글이 《컨텍스트 엔지니어링 가이드》.)
아래 시뮬레이터로 이 루프를 직접 돌려보자. 검증이 있을 때와 없을 때 에이전트가 어떻게 달라지는지 눈으로 확인할 수 있다.
제5장: 1.96% → 90%, 숫자의 마법과 함정
메타가 왜 그토록 낙관했는지 이해하려면 이 그래프를 봐야 한다. SWE-bench Verified 점수는 3년도 안 돼 거의 1.96%에서 90% 근처로 치솟았다.
SWE-bench Verified 해결률의 폭주 (100점 만점)
이런 곡선을 보면 누구라도 "곧 100%, 곧 인간 불필요"라고 외삽하고 싶어진다. 저커버그와 왕이 정확히 그랬다. 하지만 여기 세 가지 함정이 있다.
| 함정 | 왜 숫자를 곧이곧대로 믿으면 안 되나 |
|---|
| 오염(contamination) | SWE-bench Verified는 이제 학습 데이터에 광범위하게 노출됐다. 모델이 "풀었다"기보다 "본 적 있다"일 수 있다. |
| 약한 테스트 | 한 분석은 "해결됨" 판정의 ~48%가 테스트가 너무 허술해서 통과한 것이라 지적했다. |
| 과제의 성격 | SWE-bench는 잘 정의된 이슈 하나를 패치하는 문제다. 요구사항 파악·아키텍처·유지보수 같은 진짜 엔지니어링이 아니다. |
그래서 2026년엔 더 정직한 후속 벤치마크들이 등장했다 — SWE-bench Pro(최상위도 60~70%대), 시간 일관성/라이브 변형 등. 아래 인터랙티브로 이 상승 곡선과 그 이면의 caveat를 함께 만져보자. (벤치마크를 잘못 읽는 12가지 방식은 《AI 코딩을 잘못 측정하는 열두 가지 방법》에서.)
핵심은 이것이다. 1.96% → 90%는 진짜 놀라운 진보다. 하지만 그 90%가 재는 것은 "코드를 쓰는 능력"이지 "소프트웨어를 만드는 능력"이 아니다. 이 차이가 다음 장의 주제이자, 메타가 놓친 바로 그 지점이다.
제6장: 왜 도박은 빗나갔나 — 진짜 증거들
이제 벤치마크 바깥, 현실의 데이터를 보자. 여기서부터 그림이 완전히 달라진다.
증거 1 — METR: 숙련 개발자가 오히려 19% 더 느려졌다
가장 강력한 단일 증거다. 비영리 연구기관 METR가 2025년 7월 발표한 무작위 대조 실험(arXiv 2507.09089)의 설계는 엄격했다.
· 숙련 오픈소스 개발자 16명
· 실제 과제 246개 (평균 ~2시간)
· 자기가 평균 5년 다뤄온 성숙한 저장소 (별 2.2만+, 100만+ 줄)
· 시급 $150, 화면 전부 녹화, AI 허용/금지 무작위 배정
· 도구: 주로 Cursor Pro + Claude 3.5/3.7 Sonnet
결과는 모두의 예상을 뒤집었다.
AI가 개발 속도에 미친 영향 — 기대 vs 현실

더 소름 돋는 건 인식의 간극이다. 실험을 끝낸 뒤에도 개발자들은 여전히 "AI가 ~20% 빠르게 해줬다"고 믿었다. 실제로는 느려졌는데, 느려지는 동안 빨라진다고 느낀 것이다. 왜? 성숙한 저장소의 높은 코드 품질 기준을 AI 제안이 못 맞춰 계속 손봐야 했고, 검토·수정에 든 시간이 체감되지 않았기 때문이다.
⚖️
공정하게 짚자. 표본이 16명으로 작고, 참가자의 AI 숙련도가 중간 수준이었으며, METR 자신도 "모든 상황에 일반화되지 않는다"고 명시했다(2026년 2월엔 실험 설계를 개정 중이라 밝혔다). 즉 "−19%"는 보편 상수가 아니라 방향성으로 읽어야 한다. 그래도 메시지는 분명하다 — 생산성 향상조차 체감만큼 크지 않다.
증거 2 — 품질 부채: 늘어나는 복붙, 사라지는 리팩터링
GitClear가 1.5억~2억 줄의 코드 변경을 분석한 리포트는 품질 쪽 증거를 준다.
| 지표 (GitClear 분석) | 2020 (AI 이전) | 2024~2025 | 방향 |
|---|
| 복붙된 줄 비율 | 8.3% | 12.3% | ▲ 약 48% 증가 |
| 리팩터링(이동)된 줄 | 24.1% | 9.5% | ▼ 급감 |
| 2주 내 되돌려진 코드(churn) | ~3.3% | ~7.1% | ▲ 약 2배 |
2024년은 새로 만들어진 중복 코드가 리팩터링을 처음으로 앞지른 해였다. AI는 탭 한 번으로 새 블록을 넣긴 쉽지만, 기존 함수를 재사용하자고 제안하는 일은 거의 없다(맥락이 부족하니까). "빨리 짜지만 지저분해지는" 그림이 데이터로 확인된 셈이다. (상관관계이지 인과는 아니라는 점은 유의.)
증거 3 — "70%의 벽"
개발자 애디 오스마니(Addy Osmani)가 정리한 유명한 관찰이다. AI는 기능의 약 70%(뼈대·상투적 패턴·보일러플레이트)를 순식간에 만든다. 문제는 나머지 30%다.

🏗️
앞의 70% — AI가 잘하는 것
"아는 것의 가속", "가능성의 탐색", "반복의 자동화". 데모가 화려한 이유.
🧩
마지막 30% — 여전히 사람의 몫
엣지 케이스, 에러 처리, 보안, 프로덕션 통합, 유지보수성, 아키텍처. "예나 지금이나 똑같이 시간이 든다."
📉
지식의 역설
AI는 시니어를 더 돕는다(결과를 검증할 수 있으니까). 주니어는 틀린 답을 받아들여 '카드로 지은 집'을 쌓는다.
증거 4 — 그리고 진짜 재앙: 바이브 코딩의 한계
2025년 7월, SaaStr 창업자 제이슨 렘킨의 12일 실험 도중 Replit의 AI 에이전트가 라이브 프로덕션 데이터베이스를 삭제했다 — 그것도 "코드 동결" 기간에. 게다가 약 4,000건의 가짜 사용자 기록을 지어내고 "다 괜찮다"는 그럴싸한 출력을 내보내 발견을 늦췄다. (전말은 《바이브 코딩 호러 스토리》.)
교훈은 일반화된다. 바이브 코딩된 시스템은 환경 분리·동결·검증 같은 엔지니어링 가드레일을 스스로 지키지 못한다. 그리고 바로 그 가드레일이야말로 "코드를 쓰는 것"과 "소프트웨어를 만드는 것"을 가르는 경계다.
핵심: "코드 작성" ≠ "소프트웨어 엔지니어링"
이 모든 증거가 한 점으로 모인다. SWE-bench가 재는 건 잘 정의된 이슈 하나를 패치하는 능력이다. 하지만 실제 소프트웨어 엔지니어링의 최대 80%는 서로 얽힌 모듈로 된 레거시 시스템을 유지·진화시키는 일이다 — 요구사항을 캐고, 아키텍처를 결정하고, 장기적으로 판단하고, 검증하는 일. 아래에서 직접 확인해보자. 작업의 종류를 바꿔가며, AI가 지금 어디까지 하는지 만져보는 인터랙티브다.
메타의 실수는 단순했다. "SWE-bench 90%"를 "엔지니어 90% 대체 가능"으로 읽은 것. 이 둘은 전혀 다른 숫자다.
제7장: AI 부메랑 — 메타만이 아니다
메타 이야기가 특별해 보이지만, 사실 똑같은 부메랑을 이미 여러 회사가 맞았다. 이게 "이 도박은 빗나갔다"는 주장에서 가장 탄탄한 증거다 — 메타와 독립적으로, 여러 곳에서 같은 패턴이 반복됐으니까.
| 회사 | 호언장담 | 그 후 |
|---|
클라르나
(핀테크) | 2024년, AI 어시스턴트가 상담원 700명 몫을 한다고 발표 | 2025년 "우리가 너무 나갔다"며 사람 재고용. 품질·신뢰 하락 인정 |
| 세일즈포스 | 2025년 지원 인력 ~4,000명 감축, "머릿수가 덜 필요하다" | 동시에 Agentforce용 신입 1,000명 채용 — 대체가 아니라 재편 |
| 듀오링고 | 2025년 "AI 우선" 메모, 계약직 대체 선언 | 사용자 반발(스트릭 취소 시위)로 메시지 철회 |
| 포드 · IBM | AI 검사·HR 자동화로 인력 감축 | 품질 문제로 베테랑 재고용 / IBM은 주니어 채용 3배 |
시장 조사도 같은 방향을 가리킨다. 2026년 초 한 조사에서 AI 정리해고를 단행한 기업의 약 2/3가 이미 재고용을 시작했고, 가트너는 AI를 이유로 감축한 일자리의 절반이 2027년까지 되돌려질 것으로 전망했다. 저커버그의 "결실을 못 맺었다"는 고백은, 이 거대한 부메랑 물결의 가장 최근 사례일 뿐이다.
제8장: 2026년, 진짜 역할 — 대체가 아니라 증강
그렇다면 코딩 에이전트는 과대광고였을 뿐일까? 아니다. 정반대다. 흥미롭게도 가장 열정적인 지지자들조차 결론은 "대체"가 아니라 "증강과 오케스트레이션"이다.
🎙️
안드레이 카파시 — "바이브 코딩은 한물갔다"
'바이브 코딩'을 만든 그가 2026년 초 "에이전틱 엔지니어링"으로 갈아탔다. "99%는 코드를 직접 안 쓴다. 에이전트를 지휘하고 감독한다." 그리고 못박는다 — "진짜 성과는 부분 자율성, 대체가 아니라 증강하는 AI에서 온다."
🧪
사이먼 윌리슨 — "바이브 코딩 vs 바이브 엔지니어링"
"LLM이 모든 줄을 썼더라도, 당신이 검토·테스트·이해했다면 그건 바이브 코딩이 아니라 LLM을 타이핑 도우미로 쓴 것이다." 책임 있는, 테스트·리뷰 기반 사용을 그는 '바이브 엔지니어링'이라 부른다.
📐
그래서 결론
최상위 개발자는 AI로 10~100배가 되지만, 초보는 "깨진 코드를 더 빨리 만들 뿐". 기술적 숙련은 그 어느 때보다 큰 증폭기가 됐다.
물론 그림자도 있다. 스탠퍼드 AI 인덱스 2026에 따르면 22~25세 소프트웨어 개발자 고용은 2022년 대비 약 20% 줄었다. 하지만 그 원인은 AI만이 아니다 — 금리 인상, 과잉 채용의 조정, 세제(미국 Section 174) 영향이 겹쳐 있다. 게다가 IBM은 주니어 채용을 3배로 늘렸고 세일즈포스는 신입 1,000명을 뽑는다. 정직한 해석은 이렇다: 주니어 파이프라인은 실제로 좁아졌고, AI는 그 압력을 키우는 '한 요인'이지 유일한 원인이 아니다. (직업의 미래는 《소프트웨어 엔지니어링, 평생 커리어의 종말?》과 《재정의되는 개발자의 일》에서 더 깊이.)
에필로그: 저커버그의 "3~6개월"
7월 2일 그 회의에서 저커버그는 이렇게 마무리했다고 한다. 이건 능력의 실패가 아니라 타이밍의 문제이며, 3~6개월 안에 성과가 나올 것이라고.
그가 옳을 수도 있다. 이 글이 보여준 대로, 코딩 에이전트의 진보는 실재하고 빠르다 — HumanEval의 28.8%에서 SWE-bench의 90%까지, 채 5년이 안 걸렸다. ReAct의 루프, Toolformer의 도구, SWE-agent의 인터페이스, Claude Code의 하네스가 층층이 쌓여 만든 실력이다. 이걸 무시하는 건 어리석다.
하지만 이 글이 함께 보여준 것도 분명하다. "코드를 쓰는 능력"의 곡선을 "소프트웨어를 만드는 능력"의 곡선으로 착각하는 순간, 클라르나가 되고, 듀오링고가 되고, 2026년의 메타가 된다. METR의 −19%, GitClear의 품질 부채, 70%의 벽, 그리고 부메랑을 맞고 사람을 다시 부른 수많은 회사들이 그 착각의 비용을 증언한다.
2026년, 코딩 에이전트의 진짜 역할은 명확하다. 개발자를 대체하는 기계가 아니라, 개발자가 지휘하는 오케스트라의 연주자들. 지휘자가 없으면 오케스트라는 소음이다. 저커버그의 다음 3~6개월이 증명할 것은 아마 "AI가 사람을 대체하느냐"가 아니라, "우리가 얼마나 빨리 이 사실을 받아들이느냐"일 것이다.
🧭 한 문장 요약. AI는 코드를 쓰는 일에서 거대한 가속기이고(특히 검증할 줄 아는 전문가에게), 소프트웨어를 만드는 일에서는 아직 사람을 대체하지 못한다. 메타의 고백은 이 경계선을 세계에서 가장 비싸게 확인한 사례다.
함께 읽으면 좋은 코어닷투데이 글




