한 줄로 시작하는 이야기
2026년, AI 모델의 맥락 창(context window)은 100만 토큰을 넘겼다. 책 여러 권 분량을 한 번에 넣을 수 있다는 뜻이다. 그래서 우리는 자연스럽게 믿었다. "정보를 많이 넣어줄수록 AI가 더 똑똑하게 답하겠지."
그런데 이 직관은 틀렸다. 그것도 정반대로.

AI 연구소 Chroma가 18개 주요 모델로 실험한 결과는 충격적이었다. 입력이 길어질수록, 심지어 '단어 베껴 쓰기' 같은 사소한 작업에서도 모델 성능이 무너졌다. 100번째 토큰은 잘 보던 모델이, 10,000번째 토큰은 놓친다. 이 현상에 붙은 이름이 바로 Context Rot(맥락 부패) 다.
그래서 2026년 AI 개발의 가장 중요한 기술이 새로 떠올랐다. 프롬프트를 잘 쓰는 '프롬프트 엔지니어링'을 넘어, 모델에게 무엇을·언제·어떤 순서로 보여줄지를 설계하는 '컨텍스트 엔지니어링(context engineering)' 이다. Anthropic은 이렇게 못박는다. "맥락은 한정된 자원이며, 한계효용이 체감한다(diminishing marginal returns)."
이 글은 그 통념이 어떻게 무너졌고(제1·2장), 왜 큰 창이 답이 아니며(제3장), 무엇이 새로운 기술인지(제4장), 그리고 Anthropic·Manus·Claude Code가 실전에서 쓰는 전략(제5장)과 실무 체크리스트(제6장)를 정리한다.
제1장: 통념의 붕괴 — '길수록 좋다'는 착각
↓
제2장: 증거 — Chroma의 18개 모델 실험
↓
제3장: 왜 그런가 — 어텐션 예산과 '가운데 망각'
↓
제4장: 프롬프트에서 컨텍스트 엔지니어링으로
↓
제5장: 다스리는 기술 — 압축·오프로드·격리
↓
제6장: 실무 체크리스트
제1장: 통념의 붕괴 — '길수록 좋다'는 착각
'Needle in a Haystack(건초더미에서 바늘 찾기)' 테스트를 아는가? 긴 문서 어딘가에 한 문장("정답 바늘")을 숨기고 AI가 찾아내는지 보는 시험이다. 모델들이 여기서 거의 100점을 받자, 업계는 안심했다. "100만 토큰? 문제없어. 다 기억해."

그런데 Chroma의 연구자들은 더 현실적인 질문을 던졌다. "바늘이 질문과 똑같은 단어가 아니라, '의미'로만 연결되면 어떨까? 비슷한 오답(distractor)이 섞여 있으면? 정보가 진짜 길어지면?" 결과는 통념을 무너뜨렸다.
"모델 성능은 입력 길이가 변하면 — 단순한 작업에서조차 — 크게 달라진다."
핵심은 이것이다. Needle-in-Haystack의 만점은 착시였다. 실제 업무(여러 정보를 종합하고 추론하는 일)에서 긴 맥락은 모델을 눈에 띄게 흔든다. '다 넣으면 알아서 잘하겠지'라는 가정이 가장 위험하다.
제2장: 증거 — Chroma의 18개 모델 실험
Chroma는 Claude·GPT·Gemini·Qwen 등 18개 모델(Claude Opus 4·Sonnet 4, GPT-4.1·o3, Gemini 2.5 Pro, Qwen3-235B 등)을 같은 잣대로 시험했다. 네 가지 실험이 특히 날카롭다.
Context Rot를 드러낸 핵심 실험들
① 의미 기반 바늘
질문과 단어가 겹치지 않고 '의미'로만 연결된 바늘일수록, 길이가 늘면 성능이 더 빨리 추락
② 방해자(distractor)
비슷한 오답이 단 하나만 섞여도 성능 저하. Claude는 헷갈리면 '모른다'고 기권, GPT는 자신 있게 환각
③ LongMemEval
핵심만 담은 300토큰 vs 잡음 섞인 11.3만 토큰 — 같은 질문인데 성능 격차가 크게 벌어짐
④ 단어 베껴쓰기
반복 단어를 그대로 복제하는 '초등학생도 하는' 작업조차 길어지면 틀린다
특히 ④번이 상징적이다. 그냥 베껴 쓰기만 하면 되는 작업인데도 길이가 늘자 정확도가 떨어졌다. 복제조차 못 한다면, 종합·추론은 말할 것도 없다. 실제로 바늘 찾기류 작업에서 입력이 1만 토큰에서 10만 토큰으로 늘면, 모델에 따라 정확도가 20~50%까지 하락했다. 그리고 18개 모델 중 단 하나의 예외도 없었다 — 전부 길어질수록 나빠졌다.
가장 반직관적인 발견: 잘 정리된 글이 오히려 독
가장 충격적인 결과는 따로 있다. 연구진이 건초더미를 무작위로 뒤섞었더니(논리적 흐름을 깨뜨렸더니), 18개 모델 전부 성능이 오히려 좋아졌다. 잘 짜인 서사 구조가 어텐션을 분산시킨 것이다.
Claude 계열 — 불확실하면 기권(abstain). "모르겠다"고 답해 환각을 피함 (Opus 4 거부율 2.89%)
GPT 계열 — 불확실해도 자신 있게 답. 거부율 낮지만(GPT-4.1 2.55%) 길어지면 환각 증가
구형 모델 — GPT-3.5는 거부율 60%대로, 긴 맥락 신뢰성 자체가 무너짐
결론: "긴 맥락은 풀린 문제가 아니다." 창이 커진다고 부패가 사라지지 않는다. 그저 부패가 시작되는 지점이 뒤로 밀릴 뿐이다.
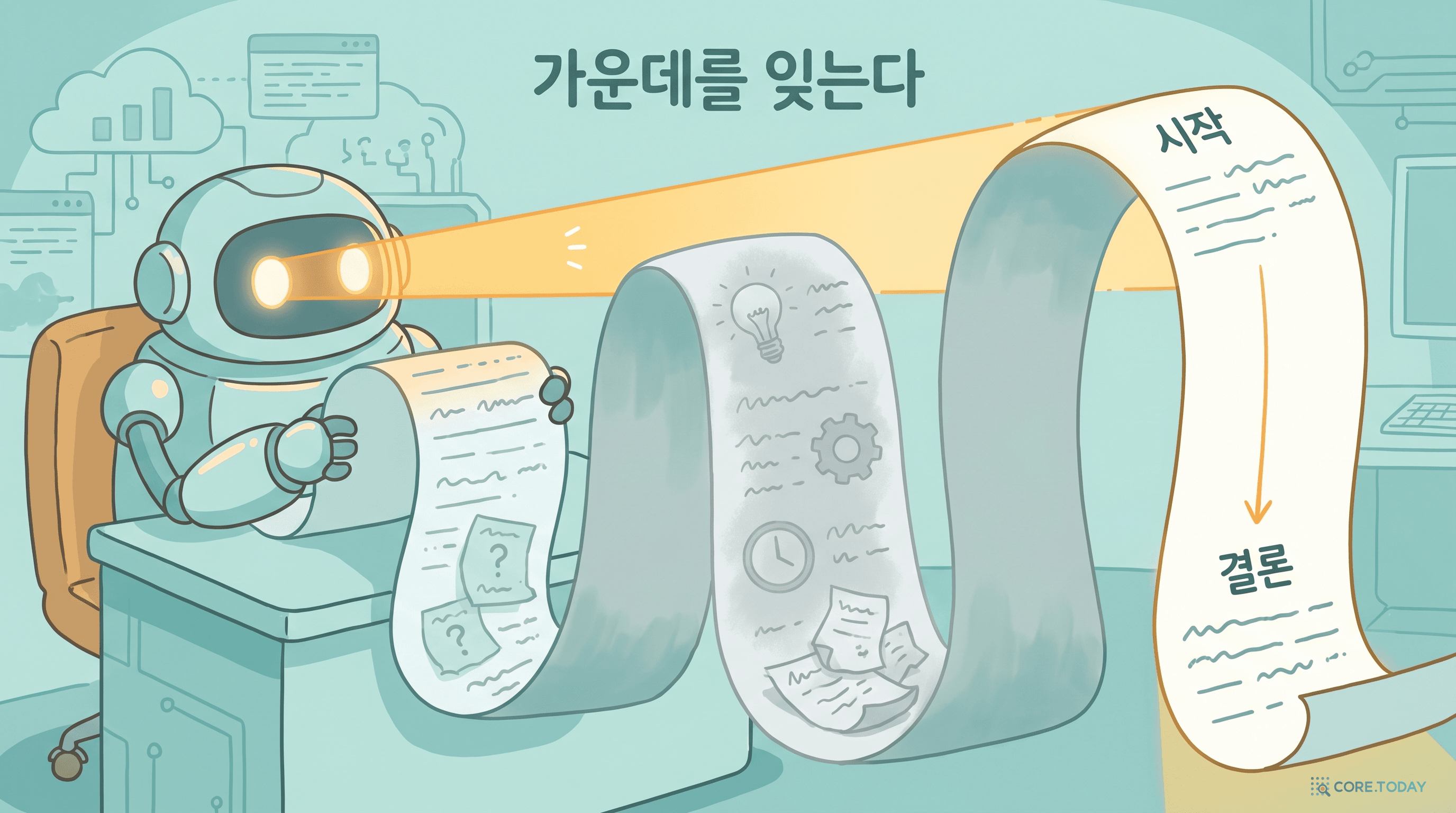
제3장: 왜 그런가 — 어텐션 예산과 '가운데 망각'
왜 이런 일이 생길까? Anthropic의 설명이 명쾌하다. LLM에게는 '어텐션 예산(attention budget)' 이라는 것이 있다.
n²
제곱으로 늘어나는 부담
트랜스포머는 모든 토큰 쌍의 관계를 계산한다. 토큰이 n개면 n² 관계 — 길어질수록 어텐션이 묽어진다
T↓
짧게 훈련된 모델
모델은 대부분 짧은 시퀀스로 학습된다. 그래서 극단적으로 긴 입력은 '훈련받지 않은 영역'이다
↕
'가운데 망각(Lost in the Middle)'
정보가 맥락의 처음·끝에 있으면 잘 찾고, 한가운데 있으면 놓친다. Chroma 실험도 '앞쪽 정보일수록 잘 회수'됨을 확인
즉 맥락 창은 '무한한 메모장'이 아니라 점점 흐려지는 주의력의 무대다. 정보를 더 넣을수록 정작 중요한 신호가 잡음에 묻힌다. Anthropic의 표현으로 "맥락은 오염(context pollution)과 관련성(relevance) 문제에서 자유로울 수 없다 — 창의 크기와 무관하게."
제4장: 프롬프트에서 컨텍스트 엔지니어링으로
여기서 패러다임이 바뀐다. 좋은 프롬프트 한 줄을 쓰는 기술(프롬프트 엔지니어링)에서, 매 추론 순간 모델의 맥락에 들어갈 토큰 전체를 큐레이팅하는 기술(컨텍스트 엔지니어링) 로.
| 구분 | 프롬프트 엔지니어링 | 컨텍스트 엔지니어링 |
|---|
| 대상 | 잘 쓴 지시문(프롬프트) 하나 | 시스템 지시·도구·메모리·이력 등 맥락 전체 |
| 시점 | 한 번의 요청 | 여러 추론 턴에 걸친 지속적 큐레이션 |
| 질문 | "어떻게 물어볼까?" | "무엇을·언제·얼마나 보여줄까?" |
Anthropic이 제시하는 북극성은 단 하나다. "원하는 결과를 낼 가능성을 극대화하는, 가장 작은 고신호(high-signal) 토큰 집합을 찾아라." 많이 넣는 게 아니라, 적게·정확하게 넣는 것이 이긴다.
학계는 이를 성숙도 모델로 정리한다 — 프롬프트 엔지니어링(PE) → 컨텍스트 엔지니어링(CE) → 의도 엔지니어링(IE) → 명세 엔지니어링(SE). 좋은 컨텍스트의 5대 기준은 관련성·충분성·격리·경제성·출처(provenance) 다. 그리고 한 문장이 본질을 찌른다 — "에이전트의 컨텍스트를 지배하는 자가 그 행동을 지배한다."
제5장: 다스리는 기술 — 압축·오프로드·격리
그래서 실전에서는 무엇을 할까? AI 에이전트 회사 Manus의 프로덕션 원칙이 가장 깔끔하다. 세 단어로 요약된다 — Reduce(줄이고) · Offload(밖으로 빼고) · Isolate(격리하라).

Reduce · 압축(Compaction)
맥락이 차오르면 대화 이력을 고밀도 요약으로 압축. 핵심: 가역적(reversible) — 파일시스템에서 복원 가능한 정보만 덜어낸다(요약과 다름)
Offload · 오프로드
긴 데이터는 맥락이 아니라 파일시스템에 저장. 가벼운 식별자(파일명·경로)만 들고 다니다 필요할 때 꺼내 본다(just-in-time retrieval)
Isolate · 격리
무거운 하위 작업은 서브에이전트에게. 깨끗한 맥락에서 일을 끝내고 요약(1,000~2,000토큰)만 돌려준다 — 메인 맥락을 더럽히지 않음
압축(Compaction) vs 요약(Summarization) — 결정적 차이
Manus가 강조하는 미묘하지만 중요한 구분이 있다. 압축은 가역적, 요약은 비가역적이다. 모든 도구 호출 결과는 '전체(full)'와 '압축(compact)' 두 형태를 갖는다. 압축 형태는 파일시스템이나 외부 상태에서 언제든 복원 가능한 정보만 떼어낸다. 반면 요약은 정보를 영구히 버린다. 그래서 똑똑한 에이전트는 먼저 '압축'으로 버티고, 정말 한계일 때만 '요약'한다.
그 밖의 실전 기법
- 구조적 노트(Structured Note-Taking): 에이전트가 맥락 밖 파일에 메모를 남기고 나중에 다시 불러온다. Claude가 포켓몬을 플레이할 때 "지난 1,234 스텝" 의 진행을 정확히 추적한 비결이 이것.
- 점진적 공개(Just-in-Time): 모든 데이터를 미리 욱여넣지 않고, 탐색하며 필요한 만큼만 끌어온다. (Claude Code가
head·tail로 거대 파일을 부분만 읽는 방식)
- 선제 압축: 맥락이 가득 차길 기다리지 말고 60%쯤에서 미리 압축하는 것이 권장된다(Claude Code 운영 사례) — 부패가 드러나기 전에.
제6장: 실무 체크리스트 — 그리고 시리즈와의 연결
컨텍스트 엔지니어링은 추상적 이론이 아니라 내일 바로 쓰는 기술이다. 코어닷이 정리한 체크리스트는 다음과 같다.
컨텍스트 엔지니어링 실무 6원칙
① 더 적게, 더 정확히
'다 넣기'를 의심하라. 결과를 낼 최소한의 고신호 토큰만. 관련 없는 맥락은 적극 제거
② 위치를 설계하라
중요한 정보는 맥락의 처음과 끝에. '가운데 망각'을 피하도록 배치
③ 파일시스템으로 오프로드
긴 데이터는 외부에 두고 식별자만. 필요할 때 just-in-time으로 회수
④ 선제적으로 압축
맥락 60%쯤에서 미리 압축. 가역적 compaction 우선, 비가역적 요약은 최후에
⑤ 무거운 일은 격리
서브에이전트에 위임하고 요약만 회수. 메인 맥락을 깨끗하게 유지
⑥ 가장 단순한 것부터
"되는 것 중 가장 단순한 것을 하라"(Anthropic). 과도한 RAG·파이프라인보다 명료함이 이긴다
마치며: 모든 것은 컨텍스트다
이 글은 사실 우리 시리즈 전체를 관통한다. 우리가 다룬 스킬도, 메모리도 — 결국 '매 순간 모델의 맥락에 무엇을 넣을 것인가' 라는 하나의 질문으로 모인다. 메모리는 '과거를 맥락에 어떻게 되살릴까', 스킬은 '절차를 맥락에 어떻게 끼울까'의 문제다. 그 위에서 컨텍스트 엔지니어링은 이 모든 것을 한정된 어텐션 예산 안에서 조율하는 상위 기술이다.
2026년, 가장 강력한 AI 엔지니어는 더 큰 모델을 쓰는 사람이 아니다. 모델에게 보여줄 것과 감출 것을 아는 사람 — 컨텍스트의 설계자다. 맥락은 많을수록 좋은 게 아니라, 정확할수록 좋다.
참고 자료 / 출처




