들어가며: 다음 주 월요일, 당신의 매니저가 묻는다면
다음 주 월요일, 매니저가 회의실로 당신을 부른다. 회사가 지난 분기에 도입한 AI 코딩 도구의 ROI를 증명하라고 한다. 구독료가 만만치 않다.
당신은 어떻게 답할 것인가?
- "지난 분기 대비 개발자 1인당 코드 줄 수가 40% 증가했습니다."
- "GitHub Copilot 수락률이 33%입니다. 업계 평균보다 높죠."
- "엔지니어 설문에서 87%가 더 생산적이라고 응답했습니다."
- "엔지니어링 조직 AI 도구 도입률이 90%를 달성했습니다."
매니저가 흡족한 표정을 짓는다. 보고서가 잘 통과될 것 같다.
그런데 이 네 가지 답변은 모두 다른 방식으로 틀렸다.

2026년 5월 20일, 소프트웨어 공학 교육의 거장이자 Software Carpentry의 창립자 Greg Wilson이 The Third Bit에 짧지만 무거운 글을 올렸다. 제목은 "Twelve Ways to Be Wrong About AI-Assisted Coding" — AI 코딩 측정에서 흔히 저지르는 12가지 방법론적 오류를 정리한 일종의 체크리스트다.
이 글은 단순한 비평이 아니다. Wilson 자신이 밝히듯, "이 비판들은 작은 수정만 거치면 애자일, 테스트 주도 개발 등 지난 20년간 우리가 떠들었던 거의 모든 소프트웨어 공학 관행에 적용할 수 있다." 소프트웨어 공학이 인접 학문(심리학, 사회학, 통계학)에게 측정 방법론을 배웠더라면 우리는 지금보다 훨씬 멀리 와 있었을 것이라는 자성의 글이기도 하다.
+55%
Peng 2023: GitHub Copilot 효과
90분짜리 HTTP 서버 작성 과제 기준
−19%
Becker 2025 (METR): 같은 도구, 정반대
실제 오픈소스 프로젝트의 베테랑 개발자 기준
15%+
AI 생성 코드의 품질 결함률
Liu 2026 — 30만 개 AI 커밋 분석
807개
Cursor 도입 오픈소스 저장소 추적
He 2026 — 속도↑ 복잡도↑ 동시에 발생
이 글에서는 Wilson의 12가지 항목을 하나씩 깊이 풀어내고, 각각이 어떤 논문·역사적 배경에서 나왔는지, 그리고 2026년 현재 한국·세계 기업이 어떤 함정에 빠져 있는지를 사례와 함께 살펴본다.
제1장: 왜 지금, 이 글이 필요한가 — 측정의 위기는 새로운 일이 아니다
"측정할 수 없으면 개선할 수 없다"는 거짓말
1883년 영국 물리학자 로드 켈빈(Lord Kelvin)은 글래스고에서 한 강연에서 이렇게 말했다.
"무엇이든 측정할 수 있다면 당신은 그것에 대해 무언가를 알고 있는 것이다. 측정할 수 없다면 당신의 지식은 빈약하고 만족스럽지 못한 것이다."
이 말은 한 세기 동안 경영학과 공학의 종교가 되었다. 피터 드러커의 "측정할 수 없으면 관리할 수 없다(What gets measured gets managed)"가 그 정점이다.
그런데 드러커는 이 말을 한 적이 없다. 출처를 추적한 학자들은 모두 빈손으로 돌아왔다(이는 Beck 2023에서도 지적된다). 진짜 드러커는 "중요한 모든 것이 측정될 수 있는 것은 아니며, 측정되는 모든 것이 중요한 것도 아니다"에 가까운 사람이었다.
소프트웨어 공학은 처음부터 이 인용 오류 위에 세워졌다.
1970~2010년: 줄 수, COCOMO, 그리고 잘못된 잣대들
1976
Halstead 복잡도 지표
연산자·피연산자 수로 프로그램의 "노력"을 측정하려는 첫 시도. 곧 실무에서 무시당함
1981
COCOMO 모델 (Boehm)
코드 줄 수(LOC)를 입력으로 개발 비용을 예측. 수십 년간 IT 업계 표준이 되었지만 "LOC는 비용이지 가치가 아니다"라는 비판에 시달림
1984
Goodhart의 법칙 정식 발표
영국 경제학자 Charles Goodhart, 통화정책 논문에서: "측정이 목표가 되는 순간 그것은 더 이상 좋은 측정이 아니다"
1992
기능 점수(Function Point) 표준화
LOC의 대안으로 등장. 여전히 인간이 주관적으로 매겨야 한다는 한계
2013
DevOps Research and Assessment (DORA) 시작
Nicole Forsgren et al. — 배포 빈도, 변경 리드 타임, MTTR, 변경 실패율. "개인"이 아닌 "팀과 시스템"을 측정
2021
SPACE 프레임워크 (ACM Queue)
Forsgren·Storey·Maddila·Zimmermann·Houck·Butler — 생산성을 만족·성과·활동·소통·효율 다섯 차원으로. 하나의 지표는 결코 충분하지 않다
핵심은 이것이다. 개발 생산성을 측정하려는 시도는 50년이 넘었고, 그 50년이 가르쳐준 유일한 교훈은 "단일 지표는 거짓말한다"는 사실이다.
2022~2026년: GitHub Copilot 시대, 같은 함정의 재방문
2021년 6월 GitHub Copilot 베타가 공개되었다. 2022년 11월 ChatGPT가 세상을 흔들었고, 2023년 GitHub Copilot Chat이, 2024년 Cursor·Windsurf·Aider 같은 AI-IDE가, 그리고 2025년에는 Claude Code·Codex·Devin 같은 코딩 에이전트가 폭발적으로 등장했다.
각 회사가 자사 도구가 얼마나 대단한지 증명하려고 발표한 연구가 쏟아졌다. 그리고 거의 모두가 Wilson이 말하는 12가지 함정 중 하나에 빠져 있다.
!
2023년 봄: Copilot은 55% 빠르다는 신화
GitHub의 자체 연구
Peng et al. 2023가 발표되었다. 95명의 개발자에게 90분 안에 자바스크립트로 HTTP 서버를 짜라고 했더니, Copilot 사용자가 55% 빨랐다. 이 숫자는 곧 매니저들과 영업 자료의 단골 손님이 되었다.
→
2025년 여름: METR이 거꾸로 된 결과를 발견
비영리 평가기관 METR이
Becker et al. 2025를 발표한다. 평균 5년 이상의 경험을 가진 오픈소스 메인테이너 16명에게 자기 프로젝트에서 실제 이슈를 해결하게 했다. AI 도구를 쓰면 19% 더 느려졌다. 가장 놀라운 것은 — 참가자 자신은 24% 빨라졌다고 느꼈다는 점이다.
✓
2026년: 같은 도구, 정반대의 진실
두 연구는 모두 통계적으로 견고하다. 그렇다면 진실은? 둘 다 맞다. 단지 측정한 "생산성"이 같은 단어로 부르는 다른 것이었을 뿐이다. Wilson의 12가지 함정은 바로 이 격차를 설명하는 지도다.
제2장: 함정 1~6 — 가장 흔하고 가장 치명적인 잣대들
함정 1: 코드 줄 수를 센다 (Counting Lines of Code)

빌 게이츠가 1990년대에 했다는 말이 있다. "줄 수로 프로그래머의 생산성을 측정하는 것은 무게로 비행기 제작 진척도를 측정하는 것과 같다." 이 말도 출처는 불분명하지만, 통찰은 정확하다.
LLM은 줄 수를 늘리는 데 천재적이다. 같은 일을 더 장황하게 쓰는 것이 그들의 본성이다. 그래서 AI 도구 도입 후 1인당 줄 수가 40% 늘었다는 보고를 받으면, 그것은 생산성 향상이 아니라 말 많아짐(verbosity)이 측정된 것이다.
!
반례: 좋은 코드는 줄어든다
엉킨 로직 2000줄을 깔끔한 200줄로 줄이는 것 — 이것이 진짜 가치다. 그러나 LOC 지표에서는 −1800줄로 잡힌다. 시니어 엔지니어가 일주일 동안 한 일이 "음수 생산성"으로 기록된다.
→
참고문헌
Sadowski·Zimmermann (eds.), Rethinking Productivity in Software Engineering, Apress 2019 — Google의 내부 연구를 집대성한 책. LOC, 커밋 수, 활동 지표가 왜 모두 거짓말하는지를 30개 챕터로 분해한다.
함정 2: 인공적인 과제로 시간을 잰다 (Timing Artificial Tasks)
앞서 본 Peng 2023의 55% 숫자가 바로 이 함정의 대표 사례다.
과제 조건을 보자:
| 요소 | 연구 환경 (Peng 2023) | 실제 개발 현실 |
|---|
| 코드베이스 | 없음 — 백지에서 시작 | 수년 묵은 100만 줄짜리 레거시 |
| 요구사항 | 명확한 사양서 1쪽 | 모호한 지라 티켓, 3명의 이해관계자 |
| 시간 | 90분 단일 작업 | 회의·리뷰·코드 읽기로 잘게 쪼개진 하루 |
| 외부 의존성 | 표준 라이브러리만 | 사내 SDK, 외부 API, 인증 시스템 |
| 정답 | 명확히 동작 vs 비동작 | "잘 되는 것 같은데..." |
90분짜리 백지 HTTP 서버에서 55% 빠른 도구가 — 1만 줄짜리 결제 모듈의 미묘한 race condition을 고치는 데에는 19% 느릴 수 있다. 두 가지 모두 진실이고, 둘 다 측정 가능하지만, 어느 것도 일반화할 수 없다.
함정 3: 통제군 없는 전·후 비교 (Before/After With No Control)
1월에 Copilot을 도입하고 6월에 PR이 더 빨리 머지된다고 치자. 도구가 효과가 있는 것일까?
같은 5개월 동안 일어난 다른 일들:
- 시니어 엔지니어 12명을 추가 채용했다
- CI/CD 파이프라인을 새로 리팩토링했다
- AWS에서 GCP로 마이그레이션했다
- 새 코드 리뷰 가이드라인을 도입했다
이 모든 변화 중에서 Copilot의 효과만 따로 분리해낼 방법은 없다. 통계학에서 말하는 내적 타당성(internal validity)은 비교 가능한 통제군을 요구한다. "그게 없었더라면 어떻게 됐을까(counterfactual)"를 추정할 수 없는 비교는 인과 추론이 아니라 그저 이야기다.
함정 4: 개발자에게 "더 생산적이냐"고 묻는다

"개발자의 87%가 AI 도구로 더 생산적이라고 응답했습니다." — 어딘가 들어본 문장
Liang et al. 2024 (ICSE)는 이 같은 자가 보고가 왜 체계적으로 오도(誤導)되는지를 정리했다. 세 가지 편향이 동시에 작동한다.
호손 효과 (Hawthorne Effect)
1924~1932년 미국 호손 공장 실험에서 발견. 사람은 관찰되고 있다는 사실 자체로 행동이 바뀐다. 설문에 답하는 순간 평소와 다른 자신을 떠올린다.
신기함 효과 (Novelty Effect)
새 도구는 새롭다는 이유만으로 빠르게 느껴진다. 같은 도구를 6개월 쓰면 그 느낌은 사라진다. 4주짜리 설문은 4주짜리 신기함을 측정할 뿐이다.
사회적 바람직성 편향
회사가 비싸게 도입한 도구를 "별로 안 좋은데요"라고 답할 직원은 드물다. 익명이라고 안내해도 마찬가지다. 특히 관리자가 도구를 선택했다면 더욱.
METR 24% 미스매치
Becker 2025: 개발자들은 자신이 24% 빨라졌다고 느꼈지만, 실제 측정에서는 19% 느려졌다. 43%포인트의 인식-실제 간극. 자가 보고는 이 정도로 신뢰할 수 없다.
함정 5: 커밋·PR·티켓 수를 센다 (Goodhart의 법칙)

2023년 7월, McKinsey가 한 보고서를 발표했다. 제목은 "Yes, You Can Measure Software Developer Productivity". 커밋 수, PR 수, 리뷰 수 같은 활동 지표로 개인 개발자의 생산성을 매길 수 있다고 주장했다.
소프트웨어 커뮤니티가 들고일어났다. Kent Beck(TDD의 창시자, Beck 2023)과 Gergely Orosz가 즉각 반박 글을 올렸다.
이유는 단 하나의 법칙으로 요약된다.
Goodhart의 법칙 (1984):
"측정이 목표가 되는 순간, 그것은 더 이상 좋은 측정이 아니다."
개발자들이 자신의 커밋 수가 추적된다는 것을 알면 어떤 일이 벌어지는가?
1단계
커밋 쪼개기: 하나의 변경을 5개의 작은 커밋으로 분할. 커밋 메시지에 "fix typo"가 폭증한다.
2단계
티켓 잘게 나누기: 하나의 기능 작업을 8개의 서브티켓으로 분해. 지라 보드는 화려해지지만 일은 똑같다.
3단계
PR 인플레이션: 큰 PR은 부담스러우니 미세하게 쪼개서 제출. 리뷰어가 컨텍스트를 잃는다.
4단계
지표만 빛난다: 숫자는 모두 우상향, 실제 가치 전달은 오히려 느려진다. 매니저는 만족, 시스템은 망가짐.
이것이 1984년에 영국 경제학자 Charles Goodhart가 영국 통화정책을 분석하며 발견한 패턴이다. 영국 정부가 통화량 지표 M3를 목표로 삼자, 시장은 M3에 잡히지 않는 통화로 옮겨갔다. 측정 가능한 모든 것은 결국 게임화된다.
함정 6: 측정하기 쉬운 절반만 잰다
코드 생성은 빠르고 측정하기 쉽다. 그러나 그 뒤에 따라오는 일들:
- 잘못된 제안 디버깅 시간 — AI가 자신만만하게 틀린 코드를 줬을 때
- 리뷰 시간 — 사람이 봐야 할 코드가 두 배가 됐다
- 보안 취약점 — "그럴듯해 보이는" 코드 안에 숨어 있는 SQL injection
- 기술 부채 — 당장 동작하지만 다음 분기에 폭발할 결정들
Dora 2025
100% — 평가한 5개 LLM 중 업계 보안 표준을 통과한 웹 앱 코드 생성은 0개
Pearce 2022
40% — GitHub Copilot 출력 중 보안 취약점이 포함된 비율 (89개 CWE 시나리오)
Liu 2026
15%+ — AI 작성 커밋 30만 개 중 최소 하나의 품질 이슈 도입
Pearce et al. 2022 (IEEE S&P)의 "Asleep at the Keyboard?"가 가장 유명하다. CWE Top 25(가장 위험한 25가지 소프트웨어 약점)를 유도하는 시나리오에서 Copilot에게 코드를 짜게 했더니, 89개 시나리오 중 40%가 취약한 코드를 만들었다. 더 무서운 발견은 — 시간 압박 하에 있는 개발자일수록 안전하지 않은 제안을 더 쉽게 받아들인다는 것이다.
Liu et al. 2026은 GitHub 공개 저장소에서 AI 작성 표시가 있는 커밋 30만 개 이상을 분석했다. 15% 이상이 최소 하나의 품질 이슈를 도입했고, 그중 거의 1/4이 코드베이스에 장기적으로 남았다. 측정에서 빠진 비용이 결국 누적된다.
제3장: 함정 7~12 — 보이지 않게 더 교묘한 잣대들
함정 7: 도입률(adoption rate)을 성공 지표로 본다
"엔지니어링 전사에서 AI 도구 도입률 90%를 달성했습니다."
이것은 조달(procurement) 성과지 생산성 성과가 아니다. 도구를 설치하고 켰다는 것과, 그 제안이 유용하다는 것은 완전히 다른 명제다.
Weisz et al. 2025 (CHI'25)는 IBM의 사내 AI 코딩 어시스턴트를 1년간 추적했다. 결론은 "평균적으로는 생산성 향상이 있지만, 그 효과는 사용자 그룹마다 균일하지 않다"였다. 어떤 그룹에는 큰 도움, 어떤 그룹에는 효과 없음, 또 어떤 그룹에는 부담만 늘었다. 도입률 90%라는 단일 숫자는 이 분포를 완전히 가린다.
함정 8: 자원자와 비자원자를 비교한다 (Selection Bias)
"Copilot을 자발적으로 쓰는 개발자들이 안 쓰는 개발자들보다 30% 생산성이 높다." — 산업계에서 가장 흔한 보고다.
문제는 두 집단이 처음부터 달랐다는 것이다. 신기술을 자발적으로 받아들이는 사람들은:
- 학습 의욕이 더 강하고
- 새 도구에 익숙하며
- 이미 평균보다 더 활발하게 일하던 사람일 가능성이 높다
Stray et al. 2026 (HICSS-59)은 한 대형 IT 조직에서 Copilot 도입 전과 후 2년을 추적했다. "Copilot을 쓴 사람들은 도구가 도입되기 전부터 이미 다른 동료보다 활발했다." 이들이 Copilot 도입 후에도 활발한 것은 — 그들이 활발한 사람이었기 때문이지, Copilot 덕분이 아닐 수 있다.
이런 함정을 피하려면 무작위 통제 실험(RCT)이 필요하다. 이는 비싸고 어렵다. 그래서 산업 보고서는 거의 항상 자기 선택 편향을 피하지 못한다.
함정 9: 개인 대신 시스템을 봐야 한다

개인의 코딩 속도는 측정하기 가장 쉽다. 그래서 측정된다. 그런데 티켓에서 프로덕션까지의 시간(cycle time)이 변하지 않는다면, 개인 속도가 아니라 다른 곳이 병목이었다는 뜻이다.
코드 생성이 30% 빨라졌는데 코드 리뷰가 30% 더 걸리게 됐다면, 시스템 전체의 처리량은 그대로다. 오히려 분량이 많아진 PR을 리뷰해야 하는 시니어가 새로운 병목이 된다.
Xu et al. 2025는 이 효과를 정량화했다. 제목 자체가 강렬하다 — "AI-Assisted Programming Decreases the Productivity of Experienced Developers by Increasing the Technical Debt and Maintenance Burden."
AI 도구는 경험이 적은 기여자의 산출량을 늘렸지만, 시니어 개발자의 생산성을 19% 감소시켰다. 이들이 AI 생성 코드로 인한 6.5% 증가한 코드 리뷰 부담을 흡수해야 했기 때문이다.
이것을 시스템 사고(systems thinking)의 실패라고 부른다. Theory of Constraints(엘리야후 골드랫, 1984)가 30년 넘게 가르쳐온 교훈 — 병목 외 어디를 최적화하든 처리량은 늘지 않는다 — 이 AI 도구 평가에서도 그대로다.
생산성을 제대로 보려면 DORA 4대 지표 같은 시스템 지표를 봐야 한다:
| DORA 지표 | 의미 | AI 도입 후 변화? |
|---|
| 배포 빈도 (Deployment Frequency) | 얼마나 자주 배포되는가 | 코드 생성 속도와 별개로 측정해야 |
| 변경 리드 타임 (Lead Time for Changes) | 커밋부터 프로덕션까지 시간 | 리뷰 병목으로 오히려 증가 가능 |
| MTTR (Mean Time to Restore) | 장애 복구 시간 | AI 생성 코드의 복잡도 증가가 영향 |
| 변경 실패율 (Change Failure Rate) | 배포 후 장애 발생률 | He 2026: Cursor 도입 후 증가 사례 보고 |
함정 10: 신기함 기간(novelty period) 동안 측정한다
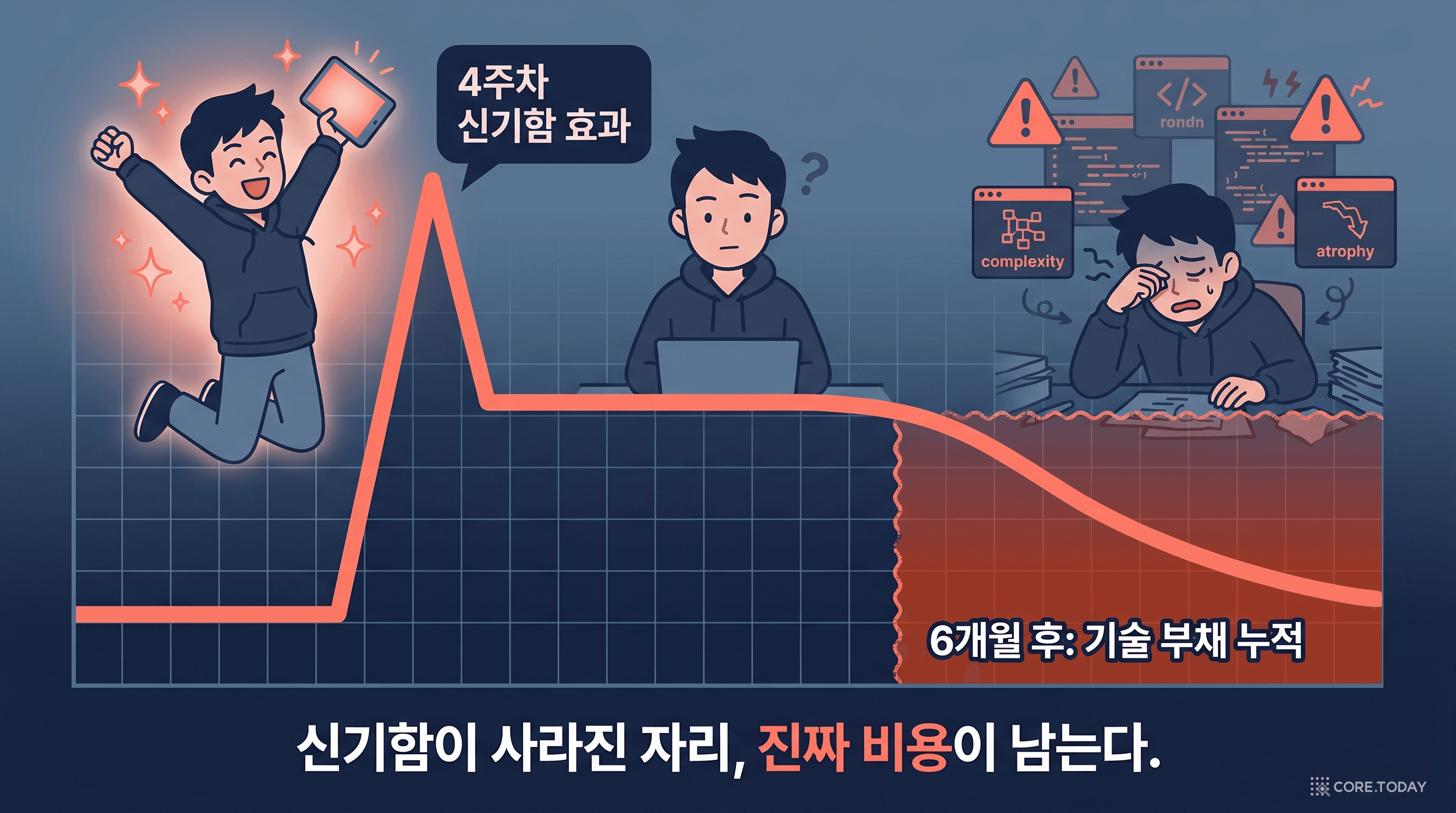
4주짜리 연구가 발견한 생산성 향상은 — 4주짜리 생산성 향상이다.
He et al. 2026 (MSR'26)이 Cursor AI IDE를 도입한 807개 오픈소스 저장소를 분석했다. 제목이 모든 것을 말해준다 — "Speed at the Cost of Quality: How Cursor AI Increases Short-Term Velocity and Long-Term Complexity."
관찰
도입 직후 4~8주: 커밋 빈도와 변경 라인 수가 큰 폭으로 증가. "AI가 효과 있다"는 보고서가 나가는 시점
변화
3~6개월: 정적 분석 경고 수, 순환 복잡도, 함수 길이가 통계적으로 유의하게 증가. 코드베이스 전체의 인지 부하 누적
결과
속도 향상은 일시적이지만, 복잡도 증가는 영속적이다. 신기함 기간에 측정을 끝내면 비용 절반을 빼놓고 영수증을 발행하는 셈
신기함 기간이 지나야 보이는 효과들:
- 기술 부채 누적 — 당장 동작하는 빠른 해결책이 6개월 뒤 폭발
- 숙련도 위축 — AI에게 위임한 작업의 인간 능력 저하 (cf. 코어닷투데이 — '인지적 외주화' 위기)
- 협업 패턴 변화 — 페어 프로그래밍 감소, 사일로화
- 온보딩 패턴 변화 — 신입 개발자가 AI에 의존해 코드베이스를 깊이 이해 못 함
함정 11: 수락률(acceptance rate)을 품질 신호로 본다

GitHub Copilot은 자랑스럽게 발표한다: "개발자들이 우리 제안의 35%를 받아들입니다." 더 많이 받아들일수록 좋은 도구라는 인상을 준다.
그런데 수락은 "그럴듯해 보임"을 측정하는 것이지, "맞음"을 측정하지 않는다. 개발자가 Tab을 한 번 누른다는 것은:
- ✅ 코드가 컴파일될 것 같다
- ✅ 변수명이 합리적이다
- ✅ 함수 구조가 익숙하다
- ❌ ...그러나 실제로 맞는지, 안전한지, 유지보수 가능한지는 검증되지 않았다
Pearce 2022가 발견한 충격적인 부속 결과: 시간 압박 상태의 개발자는 보안에 취약한 제안조차 더 많이 받아들였다. 즉, 마감이 임박할수록 수락률이 올라가는데, 그 올라간 수락률은 그 도구가 더 좋아져서가 아니라 그저 덜 까다로워졌기 때문이다.
Bakal et al. 2025는 Zoominfo에서 400명의 개발자를 추적했다. 평균 수락률 33%, 만족도 높음. 그러나 — 받아들여진 코드의 정확성·보안성은 추적되지 않았다.
"좋아 보이도록 보상하는 지표는, 좋도록 보상하는 지표가 아니다."
함정 12: AI를 "아무것도 없음"과 비교한다
마지막 함정은 가장 미묘하다. "AI 사용 vs 아무 도구도 안 씀"의 비교는 실제로는 존재하지 않는 시나리오를 측정한다.
AI 도구 없이 일하는 개발자도 다음을 쓴다:
- 공식 문서 (MDN, Python docs, RFC들)
- Stack Overflow, GitHub Issues
- 동료에게 질문하기, 페어 프로그래밍
- 스스로 설계 시간 (이것이 가장 가치 있다)
진짜 비교 대상은 "AI 도구 vs 기존의 모든 보조 수단들의 합"이다. 그러나 이 비교가 거의 이루어지지 않는 이유는 — 그렇게 측정하면 AI의 추가 효과가 매우 작아지기 때문이다.
약한 베이스라인은 어떤 도구도 좋아 보이게 만든다.
제4장: 사례 연구 — 같은 도구, 정반대 결론
이제 우리가 가진 도구상자를 들고, 산업계에서 가장 화제가 된 두 연구를 다시 보자.
사례 A: Peng et al. 2023 — "55% 빠른 GitHub Copilot"
| 항목 | 내용 | 어떤 함정과 닿는가 |
|---|
| 참가자 | 모집된 95명, 대부분 1~5년차 | 함정 8 (자기 선택 편향) |
| 과제 | JavaScript HTTP 서버, 90분 | 함정 2 (인공적 과제) |
| 비교군 | Copilot 사용 vs 미사용 | 함정 12 (약한 베이스라인) |
| 측정 지표 | 완료 시간 | 함정 6 (쉬운 절반만) |
| 결과 | 55.8% 시간 단축 | 함정 10 (단기 측정) |
이 연구가 잘못된 것은 아니다. 다만 측정한 것이 무엇인지를 정확히 이해해야 한다. "초보~중급 개발자가 익숙한 언어로 명확한 사양의 백지 과제를 90분 내에 끝낼 때, AI 자동완성이 도움이 된다." 이 명제는 참이다. 이것을 "AI는 개발자를 55% 더 생산적으로 만든다"로 일반화하는 순간, 진실은 영업 자료가 된다.
사례 B: Becker et al. 2025 (METR) — "19% 느려진 베테랑들"
| 항목 | 내용 | 어떻게 함정을 피했나 |
|---|
| 참가자 | 평균 5년+ 경력 OSS 메인테이너 16명 | 진짜 시니어를 대상으로 함 |
| 과제 | 자기 자신의 프로젝트의 실제 이슈 246개 | 함정 2를 정면 해결 (실제 코드베이스) |
| 비교군 | 무작위로 issue별 AI 허용/금지 배정 | 같은 개발자, 같은 프로젝트, 다른 조건 |
| 측정 | 시간, AI 사용 시간, 자체 평가 | 인식과 실제를 동시에 측정 |
| 결과 | AI 사용 시 19% 더 느림. 그러나 본인은 24% 빨라졌다고 느낌 | 함정 4를 직접 폭로 |
METR 연구는 거의 모든 함정을 의식적으로 피한 설계다. 그래서 결과는 "AI는 도움이 안 된다"가 아니라 — "베테랑 개발자가 자기 코드베이스에서 일할 때, 현재 세대 AI 도구는 도움보다 부담이 더 크다"이다.
두 연구는 모두 진실이다. 다른 모집단, 다른 과제, 다른 컨텍스트.
한국 기업에 주는 함의
2026년 현재 한국의 많은 IT 조직이 AI 코딩 도구 도입 ROI를 보고해야 하는 상황에 있다. 이 보고서들에서 가장 흔히 발견되는 패턴:
!
전형적인 한국 기업 보고서 패턴
"도입 후 3개월간 1인당 커밋 수 22% 증가, 개발자 설문 만족도 4.2/5.0, 라이선스 도입률 88%, 추정 시간 절감 1인당 월 18시간" — 이 보고서는 함정 4, 5, 7, 10번에 동시에 빠져 있다.
→
대안: SPACE 프레임워크와 DORA
단일 지표 대신 다섯 차원(Satisfaction, Performance, Activity, Communication, Efficiency)을 동시에 본다. 시스템 지표(DORA 4대)와 함께 6~12개월의 종단 추적이 필요하다.
✓
결국 던져야 할 질문
"우리 팀의 어떤 사람들이, 어떤 종류의 작업에서, 어떤 베이스라인 대비, 얼마나 더 나은 결과를 얻는가?" — 이 네 가지를 따로 답해야 한다. 단 하나의 ROI 숫자는 거의 항상 거짓말이다.
제5장: 그럼 어떻게 측정해야 하는가 — SPACE, DORA, 그리고 인간 과학에서 빌려와야 할 것들
Wilson이 글의 머리말에서 던진 핵심 메시지는 이것이다.
"소프트웨어 공학이 인접 인간 과학(심리학, 사회학, 통계학)에게 이런 종류의 것들을 어떻게 연구하는지 배웠더라면, 우리는 지금보다 훨씬 멀리 와 있을 것이다."
다음은 그가 명시적으로 추천하지는 않았지만, 그의 12가지 함정을 피하기 위해 필요한 진짜 방법론들이다.
SPACE 프레임워크 (Forsgren et al. 2021)
S — Satisfaction
개발자가 자신의 일·도구·환경에 만족하는가. 단순한 "더 빠르나요?"가 아닌, 번아웃·웰빙까지 포함
P — Performance
실제 산출물의 품질과 영향력. 코드가 의도한 결과를 달성했는가, 안정적인가
A — Activity
커밋·PR 같은 활동 지표. 오직 이것만 보지 않을 것을 명시함
C — Communication
팀 협업, 코드 리뷰, 지식 공유의 건강함
E — Efficiency
흐름 상태(flow), 중단의 빈도, 컨텍스트 스위칭 비용
SPACE의 핵심 원칙: 한 차원만 보지 말 것. 활동(A)이 늘었는데 만족(S)이 떨어지고 효율(E)이 나빠졌다면, 그것은 좋은 변화가 아니다.
DORA 4대 지표 + 시스템 사고
개인이 아닌 전달 파이프라인을 본다.
- 배포 빈도 — 실제 가치가 사용자에게 닿는 속도
- 변경 리드 타임 — 커밋부터 프로덕션까지
- MTTR — 장애 복구 시간
- 변경 실패율 — 배포의 품질
AI 도입 전후가 아니라 — AI 도입 그룹 vs 동일 시점의 비도입 그룹을 동시에 본다.
인간 과학에서 빌려와야 할 것들
| 함정 | 빌려와야 할 방법 | 인접 학문 |
|---|
| 자가 보고 편향 | 행동 데이터와 자기 보고의 동시 측정 | 심리학, 행동경제학 |
| 자기 선택 편향 | 무작위 통제 실험 (RCT) | 의학, 농학 |
| 호손 효과 | 블라인드 설계, 자연 실험 | 사회심리학 |
| Goodhart 효과 | 다중 지표, 메타 측정 | 통화경제학 |
| 신기함 효과 | 종단(longitudinal) 연구, 6~12개월 추적 | 발달심리학 |
| 컨텍스트 의존성 | 표본의 다양성, 외적 타당성 사전 검증 | 통계학, 역학 |
이것이 Wilson이 글 말미에 "원하면 1일짜리 연구 방법론 교육 워크숍을 연결해주겠다"고 적은 이유다. 소프트웨어 공학 커뮤니티는 이런 방법론을 거의 가르치지 않는다.
제6장: 2026년의 현실 — 거울 앞에 선 우리
AI 코딩의 이중성
2026년 5월 현재의 풍경:
93%
미국 개발자의 AI 도구 사용률
Stack Overflow Developer Survey 2024 기준 (한국은 약 80%)
40%
신뢰도 — 작년 대비 하락
사용은 늘지만 신뢰는 감소. "잘 모르겠는데 다들 쓰니까"
$13B
2026년 AI 코딩 도구 시장
2022년 대비 7배 성장. 누구도 멈출 수 없는 흐름
16편
Wilson이 인용한 학술 연구
5년 사이 학계가 따라잡으려 발버둥치는 중
우리가 진짜로 측정해야 할 것
Wilson의 글이 던지는 가장 깊은 질문은 — "우리는 무엇을 좋은 소프트웨어 개발이라고 부를 것인가?"다.
만약 좋은 개발이 "빠르게 더 많은 코드를 짜는 것"이라면, AI 도구는 명백한 승리다. 만약 좋은 개발이 "적절한 시기에 적절한 문제를 정의하고, 미래 6년 동안 유지보수할 수 있는 시스템을 만드는 것"이라면, 답은 훨씬 복잡하다.
!
2026년의 함정
AI 도구를 도입한 모든 조직이 "성공" 보고서를 써야 한다. 그래서 그들은 12가지 함정 중 가장 우호적인 것을 골라 측정한다. 보고서는 통과되지만, 그 측정이 다음 분기 결정을 좌우한다. 잘못된 측정은 잘못된 투자로 이어진다.
→
2026년의 기회
반대로, 측정을 제대로 하는 조직은 다른 결정을 내리게 된다. 어떤 팀에 어떤 도구가 맞는지, 어떤 작업에 AI가 도움이 되고 어떤 작업에 안 되는지, 어떤 시니어를 보호해야 하는지를 안다. 이것이 다음 10년의 경쟁 우위다.
✓
코어닷투데이의 권장
AI 코딩 도구의 효과를 평가하려는 한국 조직에게 — (1) 단일 지표를 보지 말 것. SPACE 다섯 차원을 동시에 본다. (2) 통제군 없는 전·후 비교를 ROI로 보고하지 말 것. (3) 최소 6개월 종단 추적 후 결론 내릴 것. (4) 시니어 개발자의 리뷰 부담을 별도로 측정할 것. (5) "수락률"과 "도입률"을 성과 지표에서 제외할 것.
12가지 함정 — 한 장 요약
스스로의 AI 도구 평가 보고서를 체크리스트로 점검해보자.
| # | 함정 | 핵심 문제 | 해독제 |
|---|
| 1 | 코드 줄 수 | 장황함 ≠ 생산성 | 가치 전달 지표 |
| 2 | 인공적 과제 타이밍 | 백지 과제 ≠ 현실 | 실제 코드베이스 RCT |
| 3 | 통제군 없는 전·후 | 다른 변수와 혼동 | 동시 통제군 |
| 4 | "더 생산적이냐" 설문 | 호손·신기함·바람직성 편향 | 행동+자가보고 병행 |
| 5 | 커밋·PR·티켓 수 | Goodhart의 법칙 | 다중 지표, 메타 측정 |
| 6 | 쉬운 절반만 측정 | 리뷰·보안·부채 누락 | 전체 수명주기 비용 |
| 7 | 도입률을 성과로 | 설치 ≠ 유용 | 실제 이익 분포 |
| 8 | 자원자 vs 비자원자 | 자기 선택 편향 | 무작위 배정 |
| 9 | 개인만 측정 | 시스템 병목 무시 | DORA, 파이프라인 |
| 10 | 신기함 기간 측정 | 4주 효과의 환상 | 6~12개월 종단 |
| 11 | 수락률 = 품질 | 그럴듯함 ≠ 옳음 | 정확성·보안 사후 추적 |
| 12 | 아무것도 안 함과 비교 | 약한 베이스라인 | 현실적 대안과 비교 |
마치며: 측정의 윤리, 그리고 더 나은 질문
이 글은 AI 코딩 도구를 비난하는 글이 아니다. Wilson 자신도 머리말에 명시한다 — "이 글은 AI에 관한 것이 아니라, 사람들이 AI를 어떻게 평가하는지에 관한 것이다."
AI 코딩 도구는 진짜로 어떤 일에는 강력하다. 어떤 사람에게는 인생을 바꿀 만큼. 그러나 어떤 일, 어떤 사람, 어떤 조건에서 그러한지를 정확히 알기 위해서는 — 잘못된 잣대 12개를 먼저 내려놓아야 한다.
피터 드러커가 진짜로 한 말은 — "가장 위험한 것은 잘못된 답을 가진 채 일하는 것이 아니라, 잘못된 질문을 가진 채 일하는 것이다."
2026년 우리가 던져야 할 질문은 "AI는 우리를 X% 더 빠르게 만들었는가?"가 아니다. "AI는 우리가 만드는 시스템과, 그 시스템을 만드는 사람들을 어떻게 바꾸고 있는가?"다.
이 글의 모든 인용은 원문 "Twelve Ways to Be Wrong About AI-Assisted Coding" (Greg Wilson, The Third Bit, 2026-05-20)의 참고문헌에서 가져왔다. Greg Wilson은 Software Carpentry의 창립자이자 Beautiful Code, Teaching Tech Together 등의 저자로, 소프트웨어 공학 교육과 연구 방법론에 평생을 바쳐온 학자다.
함께 읽으면 좋은 글
핵심 참고문헌
- Becker, J., Rush, N., Barnes, E., Rein, D. (2025) "Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity." arXiv:2507.09089
- Peng, S., Kalliamvakou, E., Cihon, P., Demirer, M. (2023) "The Impact of AI on Developer Productivity: Evidence from GitHub Copilot." arXiv:2302.06590
- Xu, F., Medappa, P.K., Tunc, M.M., Vroegindeweij, M., Fransoo, J.C. (2025) "AI-Assisted Programming Decreases the Productivity of Experienced Developers by Increasing the Technical Debt and Maintenance Burden." arXiv:2510.10165
- He, H., Miller, C., Agarwal, S., Kästner, C., Vasilescu, B. (2026) "Speed at the Cost of Quality: How Cursor AI Increases Short-Term Velocity and Long-Term Complexity in Open-Source Projects." Proc. MSR '26.
- Pearce, H., Ahmad, B., Tan, B., Dolan-Gavitt, B., Karri, R. (2022) "Asleep at the Keyboard? Assessing the Security of GitHub Copilot's Code Contributions." IEEE S&P 2022.
- Liu, Y., Widyasari, R., Zhao, Y., Irsan, I.C., Chen, J., Lo, D. (2026) "Debt Behind the AI Boom: A Large-Scale Empirical Study of AI-Generated Code in the Wild." arXiv:2603.28592.
- Forsgren, N., Storey, M.-A., Maddila, C., Zimmermann, T., Houck, B., Butler, J. (2021) "The SPACE of Developer Productivity." ACM Queue, 19(1).
- Goodhart, C. (1984) "Problems of Monetary Management: The U.K. Experience." In Inflation, Depression, and Economic Policy in the West, Rowman and Littlefield.
- Stray, V., Brandtzæg, E.G., Wivestad, V.T., Barbala, A., Moe, N.B. (2026) "Developer Productivity With and Without GitHub Copilot: A Longitudinal Mixed-Methods Case Study." HICSS-59.
- Sadowski, C., Zimmermann, T. (eds.) (2019) Rethinking Productivity in Software Engineering. Apress.




