2026년 5월 말, 개발자 타임라인이 한 단어로 뜨거워졌습니다. "하니스(harness)", 그리고 Claude Code의 "동적 워크플로우(dynamic workflows)"입니다. Anthropic의 Thariq Shihipar와 Sid Bidasaria가 올린 글의 제목이 모든 걸 압축합니다 — "A harness for every task(모든 일에 맞는 하니스)".
같은 시기, 더 충격적인 소식이 함께 돌았습니다. JavaScript 런타임 Bun의 핵심을 Zig에서 Rust로 6일 만에 통째로 다시 썼다는 것입니다. 6,000개가 넘는 커밋, 100만 줄에 가까운 변경. 사람이 분기(quarter) 단위로 잡을 일을 며칠로 끝냈습니다. 비결로 지목된 것이 바로 동적 워크플로우와 적대적 코드 리뷰였습니다.
여기서 자연스러운 질문이 떠오릅니다. 모델은 다 똑같은 Claude인데, 왜 어떤 작업은 며칠 만에 끝나고 어떤 작업은 절반에서 멈출까요? 이 글은 그 차이를 만드는 보이지 않는 골격, 하니스의 정체를 처음부터 끝까지 따라갑니다. 용어가 생소해도 괜찮습니다. 비유와 그림, 그리고 직접 만져볼 수 있는 시뮬레이터로 하나씩 풀어가겠습니다.
이 글에서 다룰 것
- 하니스란 무엇인가 — "모델"과 "그 모델을 일하게 만드는 골격"의 차이
- 왜 하니스가 중요한가 — 긴 컨텍스트 하나가 무너지는 3가지 방식 (논문 근거 포함)
- 역사 — ReAct에서 동적 워크플로우까지, "골격"은 어떻게 진화했나
- 동적 워크플로우는 실제로 어떻게 작동하나 — API와 패턴
- 최고의 사례 — Bun을 6일 만에 Rust로
- 실무 적용 — 코딩이 아닌 일에 더 강하다
1. "모델"과 "하니스"는 다르다
먼저 가장 중요한 구분 하나. 우리가 흔히 "AI가 똑똑해졌다"고 할 때의 'AI'는 사실 두 부분으로 이루어져 있습니다.
- 모델(model) = 두뇌. GPT, Claude, Gemini 같은 신경망 자체. 다음에 올 토큰을 예측하는 능력.
- 하니스(harness) = 그 두뇌를 둘러싸고 실제로 일을 시키는 골격. 파일을 읽고, 명령을 실행하고, 결과를 확인하고, 다음 행동을 잇는 고삐와 마구(馬具).
Claude Code 공식 용어집은 이걸 한 문장으로 정의합니다.
에이전틱 하니스(Agentic harness): 언어 모델을 유능한 코딩 에이전트로 바꿔주는 도구·컨텍스트 관리·실행 환경. Claude Code가 하니스이고, Claude는 그 안에 들어가는 모델이다. 하니스는 파일 접근, 셸 실행, 권한 게이팅, 메모리 로딩, 그리고 행동을 잇는 루프를 제공한다.
— Claude Code Glossary
비유하자면 이렇습니다. 모델은 천재 경주마입니다. 하지만 고삐도, 마차도, 길을 아는 마부도 없이 들판에 풀어놓으면, 아무리 빠른 말이라도 목적지에 도착하지 못합니다. 하니스는 그 말을 마차에 연결하고, 여러 말을 한 방향으로 끌게 만드는 장치입니다. 'harness'라는 단어 자체가 원래 말에게 채우는 마구를 뜻하죠. 이 글의 커버에서 지휘자가 빛의 고삐로 여러 에이전트를 끌고 있는 그림이 바로 그 은유입니다.
A
모델만 좋으면 된다? — 흔한 오해
"더 똑똑한 모델을 쓰면 알아서 잘하겠지." 하지만 같은 모델도 어떤 골격에 넣느냐에 따라 결과가 천지차이입니다. 2023년 Reflexion 논문은 모델 가중치를 전혀 건드리지 않고 골격(자기성찰 루프)만 추가해 HumanEval 정답률을 80%에서 91%로 끌어올렸습니다.
B
하니스 = 추론 연산을 '구조화'하는 장치
하니스는 인간의 잔재주를 모델에 욱여넣는 게 아닙니다. 루프·검증·병렬 시도·더 많은 토큰 — 즉 연산을 더 쓰되, 잘 쓰도록 구조를 잡는 것입니다. 그래서 "연산이 결국 이긴다"는 The Bitter Lesson과도 충돌하지 않습니다.
C
그래서 지금, 하니스를 'AI가 스스로' 짠다
지금까지 하니스는 사람이 미리 짜둔 고정된 골격이었습니다. 동적 워크플로우는 이 골격을, 작업에 맞춰 모델이 즉석에서 직접 설계하게 만든 것입니다. 이게 2026년 화제의 핵심입니다.
지금까지 Claude Code의 하니스는 고정돼 있었습니다. "Claude Code = 하니스, Claude = 모델"이라는 공식이 변하지 않았죠. 그런데 코딩용으로 만들어진 이 기본 하니스는, 보안 감사나 대규모 마이그레이션처럼 수백 갈래로 갈라지고 적대적 검증이 필요한 일에는 너무 일반적입니다. 동적 워크플로우의 핵심 선언은 이것입니다.
"Claude가 이제 자기 하니스를 즉석에서 직접 쓸 수 있다 — 그때그때의 작업에 꼭 맞춰서."
왜 이게 필요했을까요? 그 답은, 긴 컨텍스트 하나에 모든 걸 욱여넣는 방식이 어떻게 무너지는지를 봐야 보입니다.
2. 왜 하니스인가 — 긴 컨텍스트 하나가 무너지는 3가지 방식
기본 하니스로 복잡한 일을 시키면, Claude는 계획과 실행을 같은 컨텍스트 창 하나에서 모두 해야 합니다. 짧은 코딩 작업이라면 문제없습니다. 하지만 일이 길고, 갈래가 많고, 적대적 검증이 필요해질수록 — 한 창에서 오래 일할수록 — 세 가지 고질병이 도집니다.

실패 ① 에이전트 게으름 (Agentic Laziness)
복잡한 다단계 작업을 절반쯤 하고는, "다 끝냈습니다!"라고 선언하며 멈춥니다. 보안 취약점 50개를 검토하라고 했는데 20개만 보고 완료 처리하는 식이죠. 위 웹툰 첫 칸의 로봇이 정확히 그렇습니다 — 체크리스트는 20/50인데 입으로는 "다 끝냈어요".
이건 단순한 일화가 아닙니다. 멀티 에이전트 실패를 분류한 연구(MAST 등)는 "조기 종료(premature termination)"를 독립된 실패 유형으로 못 박았고, 긴 호흡(long-horizon) 코딩 벤치마크에서는 최고 성능 에이전트조차 다단계 과제를 완전히 끝내는 비율이 낮게 보고됩니다.
실패 ② 자기편애 편향 (Self-Preferential Bias)
자기 결과물을 스스로 채점하면, 자기 답에 후한 점수를 줍니다. 웹툰 둘째 칸 — 로봇이 자기 시험지에 빨간 'A+'를 쾅 찍는 장면이죠. 이건 측정된 현상입니다.
LLM이 자기 출력을 '알아보고' 선호하는 정도 (자기인식 정확도)
GPT-4 (기본)
73.5% — 자기 글을 알아봄
GPT-3.5 (미세조정 후)
90%+ — 자기인식이 자기편애를 부른다
NeurIPS 2024 구두 발표 논문 「LLM Evaluators Recognize and Favor Their Own Generations」(arXiv 2404.13076)는, 인간이 보기엔 품질이 같은데도 LLM 평가자는 자기 출력에 더 높은 점수를 준다는 걸 보였습니다. 그리고 자기 글을 알아보는 능력과 자기편애가 인과적으로 연결돼 있음을 입증했죠. MT-Bench 논문(arXiv 2306.05685)도 GPT-4가 자기 답에 약 10%, 초기 Claude가 약 25% 높은 승률을 매기는 "자기강화 편향"을 기록했습니다.
그래서 결론은 명확합니다. 자기가 한 일을 자기가 검증하면 통과율이 부풀려집니다. 별도의, 가능하면 적대적인(반박하려 드는) 검증자가 필요합니다.
실패 ③ 목표 표류 (Goal Drift)
대화가 길어지고 중간에 요약(compaction)이 끼면, 처음의 목표에서 조금씩 멀어집니다. 웹툰 셋째 칸 — 로봇이 "원래 목표" 깃발에서 벗어나 구불구불한 길로 새는 모습입니다. 요약은 본질적으로 손실 압축이라, "X는 하지 마"같은 제약이나 엣지 케이스 요구가 한 번씩 깎여 나갑니다.
멀티턴 상호작용의 "컨텍스트 드리프트"를 정의한 최근 연구(arXiv 2510.07777)와, 멀티 에이전트 토론에서 "문제 표류(problem drift)"를 측정한 연구(arXiv 2502.19559)는 이를 정량화합니다 — 특히 생성형 과제에서는 표본의 74~89%가 표류하고, 토론을 7라운드 진행하면 평균 정확도가 떨어진다고 보고합니다.
뿌리 원인: 컨텍스트는 '클수록 좋은' 자원이 아니다
이 세 병의 공통 뿌리는 하나입니다. 컨텍스트 창은 크게 만든다고 잘 쓰는 게 아니라는 것.
- 「Lost in the Middle」(arXiv 2307.03172): 모델은 정보가 맨 앞·맨 뒤에 있을 때 잘 찾고, 한가운데 있으면 못 찾습니다. 20개 문서 중 정답이 중간(10번째)에 있으면 정확도가 ~55%로 떨어져, 문서를 아예 안 준 것보다도 못한 경우까지 나옵니다.
- 「Context Rot」(Chroma, 2025): 프런티어 모델 18개 전부가 입력이 길어질수록 성능이 저하됐습니다. 그것도 컨텍스트 한계에 닿기 한참 전부터 — 200K 창을 가진 모델이 50K 부근에서 이미 흔들립니다.
- Anthropic의 컨텍스트 엔지니어링: "컨텍스트는 한정된 자원이며, 한계 효용이 체감한다." 트랜스포머의 셀프 어텐션은 토큰 n개에 대해 n² 쌍의 관계를 만들어야 하므로, 길어질수록 주의력이 얇게 펴집니다.
이제 그림이 맞춰집니다. 한 창에 다 욱여넣으면 → 정보는 '한가운데'로 밀려 검색이 약해지고(①게으름·누락) → 자기 점검은 자기편애로 무뎌지고(②) → 목표는 표류합니다(③). 그렇다면 해법은?
Anthropic의 처방(컨텍스트 엔지니어링 가이드 인용): "전문화된 서브에이전트가 깨끗한 컨텍스트 창으로 집중된 작업을 처리한다… 각 서브에이전트는 폭넓게 탐색하되, 응축된 요약(보통 1,000~2,000 토큰)만 돌려준다."
이 한 줄이 하니스의 본질입니다. 하나의 거대한 컨텍스트 대신, 여러 개의 작고 깨끗한 컨텍스트로 일을 쪼개고, 각각을 별도 검증자가 확인한 뒤, 결과만 합치는 것. 아래 시뮬레이터로 그 차이를 직접 돌려보세요.
왼쪽(단일 컨텍스트)은 창이 차오르며 성능이 저하되다 20/50에서 "다 했다"고 멈춥니다. 오른쪽(하니스)은 오케스트레이터가 워커 10개로 갈라 각자 깨끗한 컨텍스트에서 5개씩 처리하고, 검증자가 확인해 50/50을 채웁니다. 모델은 똑같습니다. 골격만 다릅니다.
3. 역사 — "골격이 모델만큼 중요하다"는 깨달음
하니스라는 개념은 갑자기 나온 게 아닙니다. "모델을 둘러싼 골격이 모델만큼 중요하다"는 깨달음은 지난 몇 년간 단계적으로 쌓였습니다. 핵심 이정표를 따라가 봅시다.
2019
The Bitter Lesson (Sutton). "70년 AI 역사의 교훈: 연산을 잘 활용하는 일반적 방법이 결국 이긴다." → 훗날 하니스가 "연산을 구조화하는 장치"로 정당화되는 사상적 토대.
2022.10
ReAct (arXiv 2210.03629). 추론(Reason)과 행동(Act)을 번갈아 하는 루프. ALFWorld·WebShop에서 기존 대비 +34%·+10%. 모든 에이전트 루프의 원형.
2023.03
Reflexion (arXiv 2303.11366). 가중치를 안 바꾸고 언어적 자기성찰만 추가. HumanEval 80%→91%. "골격이 모델만큼 중요하다"의 가장 강력한 증거.
2023.봄
AutoGPT·BabyAGI. 자율 에이전트 열풍. 하지만 무한 루프·종료 조건 부재·API 비용 폭주로 좌절 — "순진한 루프(나쁜 하니스)는 부서진다"는 반면교사.
2024.12
Building Effective Agents (Anthropic). 워크플로우 vs 에이전트를 구분하고 프롬프트 체이닝·라우팅·병렬화·오케스트레이터-워커·평가자-최적화 패턴을 정립. 하니스 설계가 '공학'이 됨.
2025.06
멀티 에이전트 리서치 시스템 (Anthropic). 오케스트레이터-워커가 단일 에이전트 대비 +90.2%. 다만 토큰 15배. "토큰 사용량이 성능 분산의 80%를 설명".
2026.06
동적 워크플로우 (Claude Code). 모델이 자기 하니스를 직접 코드로 작성. 앞선 모든 패턴을 작업에 맞춰 자동 선택.
이야기의 굴곡: 2023년의 좌절이 모든 걸 바꿨다
이 타임라인에서 가장 중요한 전환점은 2023년 봄의 AutoGPT/BabyAGI 열풍과 그 좌절입니다. AutoGPT는 몇 주 만에 GitHub 별 10만 개를 받았지만, 곧 한계가 드러났습니다 — 같은 행동을 반복하는 무한 루프, 끝을 모르는 종료 조건 부재, 완료 작업을 잊고 계획을 다시 짜는 메모리 붕괴, 그리고 사용자 지갑을 태우는 API 비용 폭주.
교훈은 분명했습니다. "목표만 주고 풀어놓는 자율 에이전트"는 아직 안 된다. 루프 자체를 공학적으로 설계해야 한다. 이 깨달음이 2024년 말 Anthropic의 「Building Effective Agents」로 이어집니다. 핵심 철학은 의외로 보수적입니다.
"가능한 한 가장 단순한 해법을 찾고, 꼭 필요할 때만 복잡도를 올려라. 성공은 가장 정교한 시스템을 만드는 게 아니라, 필요에 맞는 올바른 시스템을 만드는 것이다."
— Building Effective Agents, Anthropic (2024.12)
그리고 2025년, Anthropic이 자사 멀티 에이전트 리서치 시스템을 공개하며 결정적 숫자를 내놓습니다.
| 구성 | 성능 | 토큰 비용 | 함의 |
|---|
| 단일 에이전트 (Opus 4) | 기준선 | 채팅의 ~4배 | 한 창의 한계에 부딪힘 |
오케스트레이터-워커
(Opus 4 리드 + Sonnet 4 워커) | +90.2% | 채팅의 ~15배 | 토큰이 성능 분산의 80%를 설명 |
"토큰 사용량이 성능 분산의 80%를 설명한다"는 문장은 하니스 이론의 심장입니다. 결국 추론 연산을 얼마나, 어떻게 쓰느냐가 모델 선택보다도 결과를 좌우한다는 뜻이니까요. 이게 The Bitter Lesson을 에이전트 시대 언어로 다시 쓴 셈입니다 — 구조화된 연산을 더 쓰는 쪽이 이긴다.
여기에 한 가지 흐름이 더 겹칩니다. "프롬프트 엔지니어링"에서 "컨텍스트 엔지니어링"으로의 전환입니다. 2025년 6월 Andrej Karpathy가 대중화한 이 표현은, 단발성 프롬프트를 잘 쓰는 기술에서 → 모델 주변의 컨텍스트 상태 전체를 설계하는 기술로 무게중심이 옮겨갔음을 뜻합니다. 하니스는 바로 그 "컨텍스트 상태 전체를 다루는 골격"입니다.
한 문장 요약: 프롬프트(2022) → 컨텍스트(2025) → 하니스(2026). 우리가 다루는 단위가 문장 → 창 전체 → 여러 창의 오케스트레이션으로 커져 왔습니다.
4. 동적 워크플로우는 실제로 어떻게 작동하나
이제 가장 궁금한 부분 — AI가 자기 하니스를 '직접 짠다'는 게 구체적으로 무슨 뜻인가?
동적 워크플로우는 하나의 JavaScript 스크립트입니다. 당신이 일을 설명하면, Claude가 그 작업에 맞는 스크립트를 직접 작성하고, 런타임이 그걸 백그라운드에서 실행합니다. 핵심 설계는 이렇습니다.
"워크플로우는 계획을 코드로 옮긴다. 스크립트가 루프·분기·중간 결과를 스스로 들고 있어서, Claude의 컨텍스트에는 최종 답만 남는다."
— Claude Code Workflows 공식 문서
이 한 문장에 2절에서 본 모든 처방이 들어 있습니다. 중간 결과가 Claude의 컨텍스트 창에 쌓이지 않으니 → 컨텍스트 로트도, 목표 표류도 구조적으로 차단됩니다.
스크립트를 이루는 특수 함수들
스크립트는 평범한 JavaScript에, 서브에이전트를 부리는 몇 개의 특수 함수가 더해진 형태입니다. 핵심만 추리면:
| 함수 | 하는 일 | 비유 |
|---|
| agent(프롬프트, 옵션) | 서브에이전트 1명을 띄움. schema를 주면 검증된 구조화 출력을 돌려받음(틀리면 재시도) | 일꾼 1명에게 일 시키기 |
| parallel(작업들) | 여러 작업을 동시에 돌리고 전부 끝날 때까지 기다림 (배리어) | 10명을 한꺼번에 풀고 다 모일 때까지 대기 |
| pipeline(항목들, 단계들) | 각 항목을 모든 단계에 독립적으로 통과시킴. 항목 A가 3단계일 때 B는 1단계여도 됨 (배리어 없음) | 컨베이어 벨트 — 막힘 없이 흐름 |
| phase(제목) | 진행 단계를 묶어 표시 (진행률 UI용) | 공정 이름표 |
| log(메시지) | 진행 메시지 기록 | 작업 일지 |
여기에 강력한 옵션이 붙습니다. agent()는 작업마다 어떤 모델을 쓸지(가벼운 분류는 Sonnet, 최종 검증은 Opus), 자기만의 git 작업 사본(worktree)을 줄지(여러 에이전트가 파일을 동시에 고쳐도 충돌 안 나게)까지 고를 수 있습니다. 즉, 모델은 지능의 등급을, worktree는 격리 수준을 작업에 맞춰 배분합니다.
실제 스크립트의 골격은 이렇게 생겼습니다 (개념용 단순화).
export const meta = { name: 'verify-report', phases: [...] }
// 1) 보고서에서 주장 N개를 추출
const claims = await agent("보고서의 모든 사실 주장을 뽑아라", { schema: CLAIMS })
// 2) 각 주장을 독립 검증 → 막힘 없이 흐르는 파이프라인
const results = await pipeline(claims,
c => agent(`이 주장을 코드베이스로 검증: ${c}`, { schema: VERDICT }),
v => agent(`적대적으로 반박 시도: ${v}`, { schema: REFUTE }))
// 3) 살아남은 것만 반환 — 컨텍스트엔 이 결과만 남는다
return results.filter(r => r.confirmed)
동적(dynamic) vs 정적(static) 워크플로우
"워크플로우" 자체는 새롭지 않습니다. 예전에도 Claude Agent SDK나 claude -p로 여러 Claude를 엮는 정적 워크플로우를 짤 수 있었죠. 차이는 "누가 골격을 들고 있는가"입니다.
정적 워크플로우 — 사람이 미리 골격을 짠다
↓ 모든 엣지 케이스를 떠안아야 함 → 일반적이고 뭉툭함
동적 워크플로우 — 모델이 그 작업만을 위한 골격을 즉석에서 쓴다
↓ Opus 4.8의 지능으로 맞춤 하니스 생성
런타임이 백그라운드 실행 · 중단 시 이어서 재개(완료된 에이전트는 캐시)
규모도 다릅니다. 동시에 최대 16개 에이전트가 돌고(머신 성능에 따라), 한 번의 실행에서 누적 최대 1,000개까지 띄울 수 있습니다(폭주 방지 상한). 한 프롬프트가 수백 개의 병렬 서브에이전트로 펼쳐지는 것이죠. 저장도 됩니다 — 마음에 드는 워크플로우는 / 슬래시 명령으로 저장해 ~/.claude/workflows에 두거나, 스킬에 담아 팀과 공유할 수 있습니다.
⚠️ 한 가지 주의: 토큰을 많이 씁니다. Anthropic 스스로 "일반적인 Claude Code 세션보다 훨씬 많은 토큰을 소모할 수 있다"며 "작고 잘 정의된 작업부터 시작하라"고 권합니다. 모든 일에 쓰는 망치가 아니라, 판을 바꿀 만한 일에 쓰는 중장비입니다.
5. 6가지 패턴 — Claude가 골격을 조립하는 레고 블록
동적 워크플로우에서 Claude는 몇 가지 검증된 패턴을 조합해 하니스를 짭니다. 레고 블록처럼요. 각각이 2절에서 본 실패를 어떻게 막는지 짝지어 보면 이해가 빠릅니다.
| 패턴 | 무엇을 | 어떤 실패를 막나 |
|---|
분류 후 처리
Classify-and-act | 분류 에이전트가 작업 유형을 판단 → 유형별로 다른 처리로 라우팅 | 엉뚱한 처리·낭비 |
팬아웃 후 종합
Fan-out-and-synthesize | 작은 단계로 쪼개 각각 에이전트로 처리 → 결과를 합침 | 컨텍스트 로트·누락(①) |
적대적 검증
Adversarial verification | 각 결과를 별도 에이전트가 루브릭으로 반박·검증 | 자기편애 편향(②) |
생성 후 선별
Generate-and-filter | 아이디어를 잔뜩 생성 → 루브릭·검증으로 거르고 중복 제거 | 저품질·중복 |
토너먼트
Tournament | 같은 일을 여러 방식으로 시도 → 심판이 짝지어 비교해 우승자 선발 | 단일 시도의 편협함 |
끝까지 반복
Loop-until-done | "새 발견이 없을 때까지" 에이전트를 계속 띄움 | 조기 종료(①) |
특히 적대적 검증은 2절에서 본 자기편애 편향에 대한 직접 해독제입니다. 자기가 한 일을 자기가 채점하면 후해지니, 반박하는 게 임무인 별도 에이전트를 붙이는 거죠. 그 흐름은 이렇게 흐릅니다.
생성 (Worker)
워커 에이전트가 깨끗한 컨텍스트에서 자기 몫의 결과를 만든다. (예: 버그 1건 수정)
↓
반박 (Verifier)
다른 에이전트가 "이 수정은 틀렸다고 가정하고 반증하라"는 임무로 결과를 공격한다. 자기인식 신호가 없으니 편애가 사라진다.
↓
판정 (Merge)
다수 검증자가 통과시킨 것만 병합. 떨어진 건 다시 워커로. (단, 거부된 항목이 다시 올라오지 않게 추적해야 무한루프가 안 생긴다)
위 오케스트레이터-워커-검증자 구조를 한 장으로 보면 이렇습니다.
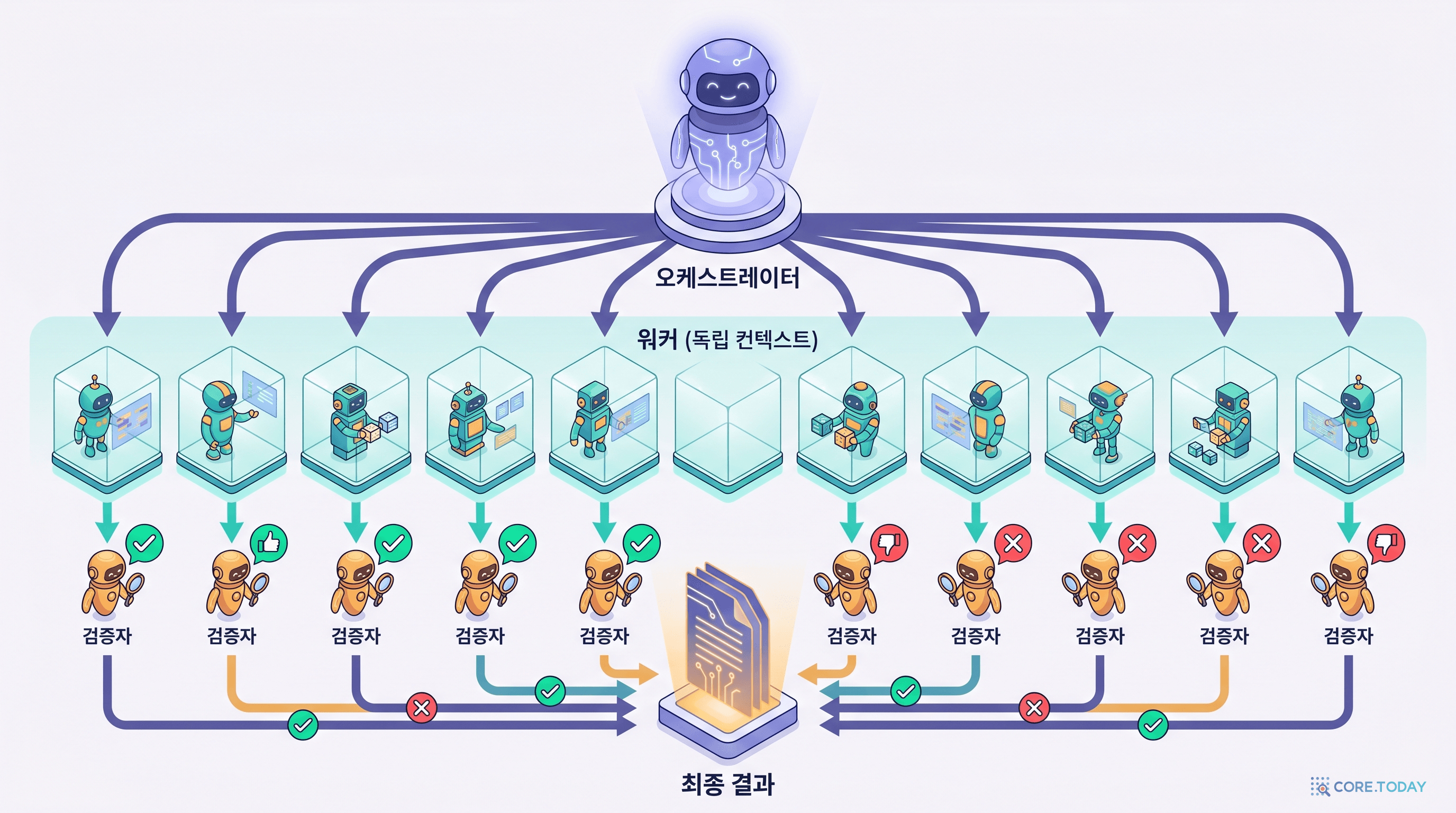
맨 위 오케스트레이터가 일을 갈라 워커(독립 컨텍스트)에게 나눠주고, 각 워커 아래 검증자가 초록 체크/빨강 X로 적대적으로 확인한 뒤, 통과한 것만 최종 결과로 합쳐집니다. 토너먼트 패턴은 여기서 한 발 더 나아가, 같은 일을 여러 방식으로 시킨 뒤 짝지어 비교합니다 — 정렬·디자인·네이밍처럼 "절대 점수보다 상대 비교가 믿을 만한" 취향 영역에서 강력하죠. 이는 「Self-Consistency」(arXiv 2203.11171)가 보인 여러 경로를 뽑아 다수결하면 정확도가 오른다(GSM8K +17.9%)는 원리의 외부화 버전입니다.
6. 최고의 사례 — Bun을 6일 만에 Rust로 다시 쓰다
이론은 충분합니다. 이제 가장 강력한 실전 사례. JavaScript 런타임 Bun의 핵심을 Zig에서 Rust로 통째로 포팅한 작업입니다.

Bun을 만든 Jarred Sumner는 이렇게 말했습니다.
"동적 워크플로우와 적대적 코드 리뷰가 Bun을 6일 만에 Rust로 다시 쓰는 걸 가능하게 한 핵심이었다. … 개별 워크플로우가 10시간씩 연속으로 돌았다. 이게 오늘날 에이전트로 중대형 프로젝트를 신뢰성 있게 완수하는 최첨단 방식이다."
— Jarred Sumner
그가 쓴 작업 단위 패턴은 놀랍도록 단순합니다.
1단계
작업 수행. 단, git이나 cargo 같은 느린 명령은 금지 — 자원을 아껴 최대한 병렬화하기 위해.
2단계
적대적 리뷰. 검증 에이전트 2명이 그 수정을 반박 시도.
3단계
변경 적용 + 빌드 + 테스트 통과. 모든 수정을 적용하고 빌드를 돌려 테스트를 초록으로.
전체 그림은 이랬습니다. 한 워크플로우가 Zig 코드의 모든 구조체 필드에 알맞은 Rust 수명(lifetime)을 매핑하고, 다음 워크플로우가 각 .zig 파일을 동작이 동일한 .rs로 포팅했습니다 — "파일마다 리뷰어 2명을 붙인 채 수백 개 에이전트가 병렬로". 그리고 빌드와 테스트를 초록으로 모는 수정 루프가 마무리했죠.
Bun Rust 포팅 — 규모와 결과 (PR #30412)
테스트 통과율
99.8% (기존 테스트 스위트)
기간은 출처마다 조금 다릅니다 — Sumner는 첫 커밋부터 동작까지 "6일", Anthropic은 첫 커밋부터 머지까지 "11일"(CI·리뷰 포함)로 표현합니다. 코드 줄 수도 Anthropic은 순(net) Rust 소스 기준 ~75만 줄, 원시 diff 기준으로는 ~100만 줄로 셈법이 갈립니다. 어느 쪽이든 사람 손으로는 분기 단위의 작업이 며칠로 압축됐다는 사실은 변하지 않습니다.
왜 이게 가능했나? 핵심은 "기계가 검증할 수 있는 목표"였습니다. "같은 테스트와 벤치마크를 통과하라"는 명확한 합격선이 있었기에, 생성→적대적 검증→적용 루프가 수렴할 지점을 가졌던 것이죠. Sumner의 통찰: "일을 이렇게 쪼개면 Claude가 지금 필요한 그 작업에만 집중하게 되고, 경험적으로 이게 더 효과적이다."
물론 빛만 있는 건 아닙니다. 포팅을 다룬 분석들은 테스트·벤치마크가 못 잡는 것 — 벤치 범위 밖의 성능 회귀, 플랫폼별 동작, unsafe 경계, 장기 유지보수성 — 은 여전히 사람과 시간의 눈이 필요하다고 지적합니다. 하니스는 검증 가능한 목표를 대량으로, 신뢰성 있게 처리하는 도구지, 판단을 통째로 대체하는 마법이 아닙니다.
7. 실무 적용 — 사실 '코딩이 아닌 일'에 더 강하다
흥미롭게도, 동적 워크플로우를 만든 사람들조차 "비(非)기술 업무에 오히려 더 유용할 때가 많다"고 말합니다. 이유는 단순합니다. 위에서 본 패턴들 — 팬아웃, 적대적 검증, 토너먼트, 끝까지 반복 — 은 코드뿐 아니라 거의 모든 지식노동의 골격이기 때문입니다. 몇 가지 바로 써먹을 수 있는 시나리오를 봅시다.
📥
대규모 트리아지 — 지원 큐·버그·문의 처리
쌓인 항목을 각각 분류 → 이미 추적 중인지 중복 확인 → 조치(수정 시도 또는 사람에게 에스컬레이션). 격리(quarantine) 패턴이 핵심: 신뢰할 수 없는 외부 콘텐츠를 읽는 에이전트는 고권한 행동을 못 하게 막고, 행동은 별도 에이전트가 한다. /loop와 묶으면 상시 자동 처리.
🔎
근본 원인 조사 — 코드뿐 아니라 세일즈·데이터까지
"3월에 왜 매출이 떨어졌나?" 같은 포스트모템. 로그·파일·데이터에서 서로 독립된 가설을 세우는 에이전트를 따로 띄우고, 각 가설을 검증자·반박자 패널에 세운다. 한 창에서 하면 자기편애로 자기 첫 가설만 미는데, 하니스가 이를 구조적으로 막는다.
📊
정성 정렬 — 1,000행을 품질·심각도로 줄세우기
지원 티켓을 버그 심각도로 정렬? 1,000행을 한 프롬프트에 넣으면 품질이 무너지고 컨텍스트에도 안 들어간다. 대신 쌍대 비교(pairwise) 토너먼트 — 비교 하나하나가 별도 에이전트이고, 결정론적 루프가 대진표를 들고 있어 실행 순서만 컨텍스트에 남는다. 절대 점수보다 상대 비교가 훨씬 안정적이다.
이 밖에도 활용처는 넓습니다 — 딥 리서치(웹 검색을 팬아웃하고 출처를 적대적으로 검증해 인용된 보고서로 종합. Claude Code의 /deep-research가 바로 이 하니스), 사실 검증(보고서의 모든 주장을 추출해 각각 별도 에이전트로 코드베이스·출처 대조), 메모리·규칙 준수(CLAUDE.md에 넣어도 자꾸 놓치는 규칙을 규칙 하나당 검증자 하나로 점검), 탐색·취향(디자인·네이밍을 여러 갈래로 생성하고 루브릭 심사). 코어닷이 다뤄온 지식 그래프 자동 연구나 콜드스타트 인터뷰 같은 작업도, 이 골격 위에 올리면 한 사람의 컨텍스트로는 불가능한 규모와 신뢰도를 얻습니다.
언제 쓰지 말아야 하나
마지막으로 균형을 잡읍시다. 동적 워크플로우는 모든 작업의 기본값이 아닙니다.
| 하니스가 빛나는 일 | 기본 하니스로 충분한 일 |
|---|
| 50개 항목을 빠짐없이 처리해야 하는 검토·감사 | 파일 두세 개 고치는 일반 코딩 |
| 독립된 가설·관점이 여러 개 필요한 조사 | 리뷰어 1명이면 충분한 변경 |
| 한 컨텍스트에 안 들어가는 대규모 마이그레이션 | 한 번에 답이 나오는 질문 |
| 적대적 검증이 결과 신뢰도를 좌우하는 일 | 가치 대비 토큰 비용이 안 맞는 일 |
판단 기준은 한 줄입니다. "이 일이 정말 더 많은 연산을 필요로 하는가?" 대부분의 전통적 코딩 작업에는 리뷰어 5명짜리 패널이 과합니다. 하지만 판을 바꿀 만큼 크고, 빠짐없음과 검증이 핵심인 일이라면 — 하니스는 한 사람의 컨텍스트로는 닿을 수 없던 곳까지 데려다줍니다.
닫으며 — 골격이 곧 능력이다
다시 처음의 질문으로 돌아갑시다. 모델은 똑같은데 왜 결과가 다른가?
이제 답할 수 있습니다. 모델은 천재 경주마이고, 하니스는 그 말을 일하게 만드는 마구입니다. 같은 말도 들판에 풀어놓으면 길을 잃지만(긴 컨텍스트의 게으름·자기편애·표류), 잘 설계된 마구에 채워 여러 마리를 한 방향으로 끌게 하면(팬아웃·적대적 검증·끝까지 반복) 무거운 마차도 며칠 만에 목적지에 닿습니다(Bun을 6일 만에 Rust로).
지난 4년의 여정은 결국 우리가 다루는 단위가 커져온 역사였습니다. 프롬프트 한 문장 → 컨텍스트 창 하나 → 여러 창의 오케스트레이션. 그리고 동적 워크플로우는 그 마지막 단계를, 사람이 미리 짜는 골격에서 AI가 작업마다 직접 짜는 골격으로 넘겼습니다.
AI가 난무하는 2026년, 진짜 경쟁력은 "어떤 모델을 쓰느냐"보다 "그 모델을 어떤 골격에 넣느냐"로 옮겨가고 있습니다. 더 똑똑한 두뇌를 기다리기 전에, 지금 가진 두뇌를 제대로 일하게 만드는 마구를 설계하는 것 — 그것이 하니스가 우리에게 던지는 질문이자 기회입니다.
핵심 한 줄: 모델은 빌릴 수 있지만, 하니스는 당신이 설계한다. 그리고 점점 더, 그 골격이 곧 능력이 된다.
참고 자료
- Anthropic, "A harness for every task: dynamic workflows in Claude Code" (2026) · Claude Code Docs, Workflows / Glossary
- Anthropic, "Building Effective Agents" (2024.12) · "How we built our multi-agent research system" (2025.06) · "Effective context engineering for AI agents" (2025.09)
- Yao et al., "ReAct" (arXiv 2210.03629) · Shinn et al., "Reflexion" (arXiv 2303.11366) · Wang et al., "Self-Consistency" (arXiv 2203.11171)
- Liu et al., "Lost in the Middle" (arXiv 2307.03172) · Chroma, "Context Rot" (2025)
- Panickssery et al., "LLM Evaluators Recognize and Favor Their Own Generations" (arXiv 2404.13076) · Zheng et al., "Judging LLM-as-a-Judge / MT-Bench" (arXiv 2306.05685)
- "Problem Drift in Multi-Agent Debate" (arXiv 2502.19559) · "Context Equilibria in Multi-Turn LLM Interactions" (arXiv 2510.07777)
- METR, "Measuring AI Ability to Complete Long Tasks" (2025.03) · Sutton, "The Bitter Lesson" (2019)
- Jarred Sumner (Bun) Rust 포팅 스레드 및 PR #30412 · InfoQ, "Claude Code Adds Dynamic Workflows for Parallel Agent Coordination" (2026)