한 문장에서 시작하는 이야기
2026년 6월, LangChain의 시드니 렁클(Sydney Runkle)이 쓴 글 한 편이 개발자들 사이에서 화제가 됐다. 제목은 《The Art of Loop Engineering》(루프 엔지니어링의 기술). 핵심 주장은 놀랍도록 단순하다.
"에이전트가 강력해지는 건 모델이 똑똑해서가 아니다. 그 모델을 감싼 루프(loop)를 얼마나 잘 쌓았느냐로 결정된다."

이 문장이 낯설게 들린다면, 먼저 이렇게 바꿔 읽어보자. 우리는 지난 몇 년간 AI에게 더 좋은 질문(프롬프트) 을 던지는 법을 배웠고, 그다음엔 더 좋은 정보(컨텍스트) 를 떠먹이는 법을 배웠다. 그런데 2026년 현재, 가장 앞선 팀들은 질문도 정보도 아닌 "에이전트가 돌아가는 고리 그 자체" 를 설계하는 데 몰두하고 있다. 그 고리를 겹겹이 포개는 기술 — LangChain은 이것을 루프 엔지니어링, 그 뿌리를 만든 swyx(숀 왕)는 loopcraft(루프크래프트) 라고 부른다.
📌 이 글의 위치. 코어닷투데이는 앞서 《루프 엔지니어링 — 더 이상 에이전트에게 프롬프트하지 마라》에서 Addy Osmani의 관점으로 '루프를 이루는 다섯 가지 빌딩블록'을 다뤘다. 이번 글은 같은 주제를 LangChain이 정리한 '네 개의 루프' 프레임으로 다시 조명한다. 두 글은 겹치지 않고 이어진다 — 이쪽은 루프를 어떻게 겹쳐 쌓는가의 지도다.
이 글은 세 가지를 약속한다. 첫째, 왜 이 개념이 나왔는지를 역사와 논문에서부터 따라간다. 둘째, 네 개의 루프가 각각 무엇이고 어떻게 포개지는지를 그림과 사례로 푼다. 셋째, 2026년 지금 이 기술이 왜 중요한지 — 비용과 위험까지 솔직하게 짚는다. 용어가 생소해도 괜찮다. 하나씩, 천천히.
제1장: 왜 지금인가 — 프롬프트에서 하네스, 그리고 루프까지
↓
제2장: loopcraft — '루프를 쌓는다'는 발상
↓
제3장: 네 개의 루프 — 에이전트 · 검증 · 이벤트 · 힐 클라이밍
↓
제4장: 아키텍처의 뿌리 — ReAct와 Reflexion 논문
↓
제5장: 사례 — LangChain '문서 봇'에서 네 루프가 포개지다
↓
제6장: 2026년 — 복리, 사람, 그리고 잘못된 채점표의 위험
제1장: 왜 지금인가 — 프롬프트에서 하네스, 그리고 루프까지
루프 엔지니어링이 왜 갑자기 튀어나왔는지 이해하려면, AI를 다루는 방식이 지난 4년간 어떻게 진화했는지를 봐야 한다. 업계는 이것을 세 개의 시대(three eras) 로 나눈다.
| 시대 | 무엇을 다뤘나 | 한 줄 요약 |
|---|
프롬프트 엔지니어링
2022–2024 | 역할 지정 · 예시 제공 · 말투 제약. "질문을 어떻게 던질까" | 모델에게 무엇을 할지 말한다 |
컨텍스트 엔지니어링
2025 | 맥락 창을 관련 문서·대화 이력·도구 정의·RAG 결과로 채우기 | 모델에게 알아야 할 것을 준다 |
하네스 엔지니어링
2026 | 에이전트의 작업 흐름·제약·피드백 루프·툴체인·수명주기를 통째로 설계 | 에이전트가 안정적으로 일을 해내는 환경을 만든다 |
프롬프트는 표현을 다듬고, 컨텍스트는 정보를 큐레이션한다. 하지만 완벽한 프롬프트도, 완벽한 정보도 "이 일을 끝까지, 실수 없이, 반복해서 해내는 능력" 은 보장하지 못한다. 그 마지막 조각을 채우는 것이 하네스(harness) — 에이전트를 감싸는 '작업 환경 전체'다. (하네스 개념 자체가 궁금하다면 《오토하네스 — LLM 코드 하네스》를 참고.)
그리고 루프 엔지니어링은 이 하네스 시대의 '운영 규율(operational discipline)' 이다. 하네스가 정적인 '환경'이라면, 루프는 그 환경 안에서 끊임없이 도는 동적인 고리다. LangChain의 표현을 빌리면:
"에이전트는 결국 모델이 도구를 부르며 작업이 끝날 때까지 도는 루프다. 이건 첫 번째 루프일 뿐이고, 가장 근본적인 루프일 뿐이다. 이 주위에 루프를 더 쌓으면 에이전트는 극적으로 더 믿음직하고, 더 확장 가능하고, 스스로 개선되는 존재가 된다."
핵심 단어는 "쌓는다(stack)" 이다. 루프는 하나가 아니다. 여러 개를 겹겹이 포갤 수 있다. 그것이 이 글의 주제다.
제2장: loopcraft — '루프를 쌓는다'는 발상
이 '쌓기'라는 발상의 원조는 AI 엔지니어 커뮤니티의 대부격인 swyx(숀 왕) 다. 그는 2026년 6월 AI Engineer World's Fair의 오프닝 강연 《Loopcraft: The Art of Stacking Loops(루프크래프트: 루프를 쌓는 기술)》 에서 지난 4년의 흐름을 이렇게 압축했다 — "채팅에서, 도구로, 목표로(from chat, to tools, to goals)." 그리고 지금의 초점은 자동화 — 크론잡과 루프 라고 못박았다.
swyx의 주장에서 가장 회자된 대목은 이른바 'Salty Lesson(짭짤한 교훈)' 이다. 이 이름은 강화학습의 대가 리처드 서튼의 유명한 'Bitter Lesson(쓰라린 교훈)' — "인간의 지식을 억지로 집어넣는 것보다, 계산량으로 확장되는 일반적 방법이 결국 이긴다" — 를 에이전트 버전으로 비튼 것이다.
🧗
Bitter Lesson (모델의 교훈)
모델을 잘 만들려면 — 인간의 규칙을 손으로 넣지 말고, 계산량으로 확장되는 학습 방법에 맡겨라.
🔁
Salty Lesson (에이전트의 교훈)
에이전트를 잘 굴리려면 — 문제를 당신 손으로 고치지 말고, 더 많은 에이전트와 함께 확장되는 시스템(목표·오케스트레이션)에 맡겨라.
📈
그래서 loopcraft
"다음 세기의 게임 전체는, 루프를 얼마나 효과적으로 쌓을 수 있느냐에 달렸다." — swyx
swyx는 여기에 실전 감각을 하나 덧붙였다. 각 국면의 초기에는 언제 아래 루프로 내려갈지(go DOWN) 를 아는 것이 중요하다는 것 — 뭔가 어긋났을 때는 더 근본적인 안쪽 루프로 내려가 신뢰성을 확보하고, 시스템이 안정되면 바깥 루프로 올라가 능력을 키운다. 즉 루프 쌓기는 위로만 올라가는 게 아니라, 안팎을 오르내리는 기술이다.
LangChain의 시드니 렁클은 바로 이 loopcraft를 이어받아, 실무자가 곧장 쓸 수 있는 네 개의 층으로 정리했다. 이제 그 네 층을 하나씩 오르자.
제3장: 네 개의 루프
LangChain의 프레임은 러시아 인형(마트료시카)을 닮았다. 가장 안쪽에 '일하는 루프'가 있고, 그것을 '채점하는 루프'가 감싸고, 다시 '스스로 깨어나는 루프'가 감싸고, 마지막으로 '자기 자신을 고쳐 쓰는 루프'가 전체를 감싼다.
4중 루프 스택 — 안에서 밖으로
① 에이전트 루프
일을 한다
모델이 도구를 부르며 작업이 끝날 때까지 반복. 실제 작업을 실행하는 심장.
② 검증 루프
채점을 한다
채점기가 결과를 기준표(rubric)에 맞춰 평가하고, 미달이면 피드백과 함께 되돌려보낸다.
③ 이벤트 루프
스스로 깨어난다
문서가 도착하거나·일정이 되거나·웹훅이 오면 에이전트가 자동으로 실행된다.
④ 힐 클라이밍 루프
자기를 고쳐 쓴다
운영 기록(trace)을 분석 에이전트가 읽고, 반복되는 문제를 찾아 하네스 자체를 다시 쓴다.
이 순서에는 의미가 있다. ①→②는 이미 널리 자리 잡은 관행이고, 진짜 판을 바꾸는 곳은 ③과 ④ — 에이전트를 당신의 생태계 안에 심고, 그것이 당신의 기준에 맞춰 스스로 계속 나아지게 만드는 층이다. 하나씩 보자.
① 에이전트 루프 — 일을 하는 심장
가장 안쪽. "모델이 도구를 부르며, 작업이 끝날 때까지 도는 것." LangChain에서는 create_agent라는 한 줄짜리 기본 원시(primitive)가 이 고리를 만들어준다. 예를 들어 문서를 관리하는 에이전트라면, 요청을 받고 → 무엇을 바꿀지 계획하고 → 저장소를 복제하고 → 파일을 읽고 → 문서를 쓰고 → 풀 리퀘스트(PR)를 여는 식으로 도구를 차례로 부른다.
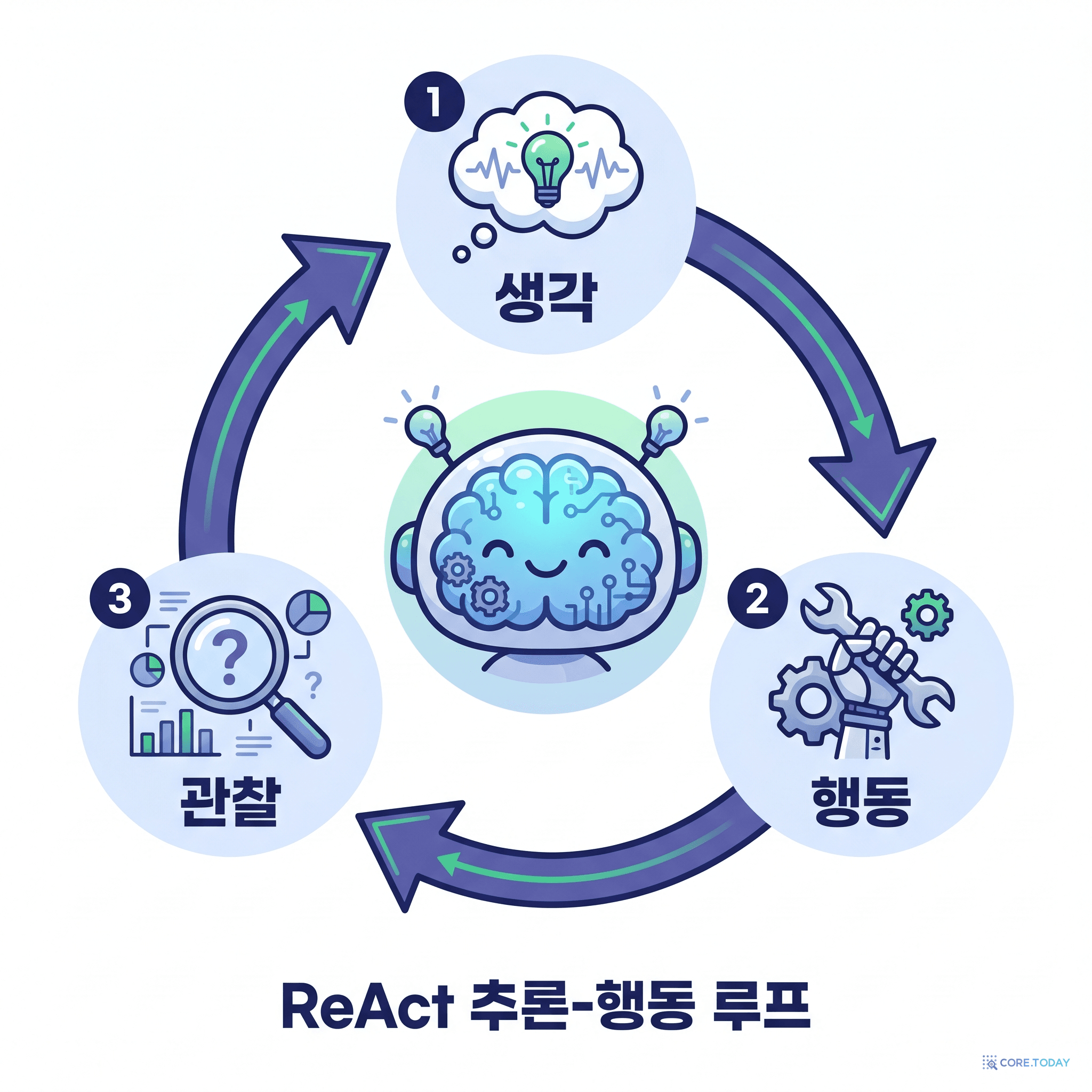
이 단순한 고리가 에이전트를 '체인(chain)'과 근본적으로 다르게 만든다. 체인은 정해진 순서를 따라가는 파이프라인이지만, 에이전트 루프에서는 매 바퀴마다 LLM이 '다음에 뭘 할지' 스스로 결정한다. 모델이 단순한 텍스트 변환기가 아니라 매 순간의 의사결정자가 되는 것 — 이 박동의 정확한 뿌리는 2022년의 ReAct 논문이고, 제4장에서 해부한다.
② 검증 루프 — 채점하는 감독관
에이전트 루프는 일을 해내지만, 첫 시도에 늘 올바르거나 일관된 결과를 내지는 않는다. 그래서 두 번째 루프가 등장한다. 결과를 채점기(grader) 로 감싸는 것이다.
생성
에이전트가 초안 결과를 만든다 (문서·코드·PR 등)
채점
채점기가 기준표(rubric)에 맞춰 점수를 매긴다 — 결정론적 테스트이거나, '판사 역할 LLM(LLM-as-a-judge)'
되돌림
기준 미달이면 무엇이 왜 부족한지 피드백과 함께 다시 에이전트에게 → 재시도
문서 봇의 경우 검증 루프는 이런 걸 자동으로 확인한다 — 링크가 실제로 연결되는가, CI가 통과하는가, 변경 범위(diff)가 요청한 선을 넘지 않는가. 사람이 일일이 눈으로 볼 필요 없이 기계가 먼저 거른다.
여기엔 대가가 있다. 검증 루프는 한 번 돌 때마다 지연과 비용을 더한다. 그래서 속도보다 품질이 중요한 작업일 때 값을 한다. 그리고 이 루프의 철학적 뿌리 — "코드를 쓴 모델이 자기 코드를 채점하게 두지 마라" — 는 2023년 Reflexion 논문에서 왔다. 이 역시 제4장에서 본다.
③ 이벤트 루프 — 스스로 깨어나는 상시 근무자
여기서부터 판이 바뀐다. 앞의 두 루프까지는 사람이 "실행"을 눌러야 돌아간다. 세 번째 루프는 그 방아쇠를 사람에게서 떼어낸다.

"이벤트가 발생하면 — 새 문서가 도착하고, 일정이 되고, 웹훅이 도착하면 — 에이전트가 실행된다."
이 전환의 의미를 LangChain은 이렇게 표현한다. 이벤트 루프는 "당신이 콕콕 찔러대던 도구(a tool you poke at)" 를 "더 큰 시스템 안에서 상시 돌아가는 부품(a component running continuously)" 으로 바꾼다. 크론 스케줄, 웹훅, 메시지 도착 — LangSmith Deployment와 Fleet 같은 인프라가 이 방아쇠들을 관리한다. 문서 봇의 경우, Slack 채널에 메시지가 올라오는 것이 곧 방아쇠다.
이벤트 루프에 대한 코어닷투데이의 별도 심층 해설은 《휴먼 인 더 루프》에서도 이어진다 — 상시 근무 에이전트일수록 사람이 개입하는 지점을 어디에 둘지가 더 중요해지기 때문이다.
④ 힐 클라이밍 루프 — 자기 자신을 고쳐 쓰는 루프
가장 바깥, 그리고 가장 혁신적인 층. 앞의 세 루프가 일을 개선했다면, 네 번째 루프는 개선하는 행위 자체를 자동화한다.

'힐 클라이밍(hill climbing, 언덕 오르기)'은 최적화 이론에서 온 말이다. 현재 위치에서 조금씩 더 높은 쪽으로 발을 옮겨 정상에 다가가는 방법. 여기서 '언덕'은 에이전트의 성능이고, '한 걸음'은 하네스의 작은 수정이다.
작동 방식은 이렇다. 프로덕션에서 쌓인 실행 기록(trace) 을 분석 에이전트가 읽는다. 그리고 반복되는 문제를 찾아내 — 프롬프트를 손보거나, 도구를 바꾸거나 — 하네스 자체를 다시 쓴다. LangChain은 이 메커니즘을 LangSmith Engine으로 구현했다. 이 층의 진짜 무서운 점은 되돌아오는 화살표의 방향이다.
"되돌아오는 화살표는 그저 맨 위로 되돌아가는 게 아니다. 그것은 안으로 손을 뻗어 에이전트 루프를 직접 고친다. 바깥 루프가 한 바퀴 돌 때마다, 안쪽 루프들이 더 효과적으로 변한다."
즉 ④가 한 번 돌면 ①②③이 더 좋아진다. 그리고 더 좋아진 ①②③은 더 나은 기록을 남기고, 그 기록이 다시 ④를 돌린다. 이것이 '복리(compounding)' 다 — 시스템이 정체되지 않고 시간이 갈수록 스스로 나아진다. Reflexion(제4장)이 한 작업 안에서 보여준 '말로 복기하는 자기개선'을, 힐 클라이밍 루프는 시스템 전체 수준으로 끌어올린 셈이다.
제4장: 아키텍처의 뿌리 — ReAct와 Reflexion
네 개의 루프는 하늘에서 떨어지지 않았다. ①과 ②의 골격은 각각 2022년과 2023년의 두 논문에 이미 다 들어 있었다. 용어가 생소하겠지만, 그림과 함께 천천히 보면 어렵지 않다.
4-1. ReAct(2022) — 에이전트 루프의 조상
ReAct는 "Reasoning + acting", 즉 추론과 행동을 하나로 엮은 것이다. 야오(Yao) 등이 2022년 발표했다(arXiv:2210.03629). 이전까지 LLM 활용은 두 갈래로 갈려 있었는데, ReAct 논문의 그 유명한 Figure 1 은 같은 질문을 네 방식으로 푸는 모습을 나란히 보여준다.
| 방식 | 하는 일 | 한계 |
|---|
| (a) Standard | 그냥 답을 뱉음 | 근거도 도구도 없음 |
| (b) CoT — 추론만 | 머릿속 단계별 생각(Chain-of-Thought) | 최신 정보가 없어 그럴듯한 거짓(환각)을 지어냄 |
| (c) Act-only — 행동만 | 위키피디아 검색 같은 도구 호출 | 도구 결과를 제대로 해석·추론하지 못함 |
| (d) ReAct — 추론+행동 | 생각하고 → 도구 쓰고 → 결과 보고 → 다시 생각 | 두 세계의 장점을 모두 가짐 |
핵심은 (d)다. ReAct는 생각(Thought) → 행동(Action) → 관찰(Observation) 을 한 단위로 묶어 반복한다.
Thought · 생각
"이 인물의 출생지를 알아야겠다. 위키를 검색하자."
Action · 행동
Search["인물 이름"] — 실제 위키피디아 API를 호출
Observation · 관찰
"검색 결과: …출생지는 X…" — 도구가 돌려준 사실
이 고리가 다시 "그럼 X를 한 번 더 찾아보자"는 다음 생각으로 이어진다. 그래서 ReAct는 환각을 줄이고(매 단계 실제 도구로 사실을 확인하니까), 사람이 따라 읽기 쉬운(생각이 글로 남으니까) 풀이를 만든다. 결과도 인상적이었다 — 상호작용형 의사결정 벤치마크 ALFWorld에서 기존 모방·강화학습 방법을 절대치 34%p 앞섰고, 예시를 한두 개만 주고도 그랬다.
LangChain의 ①에이전트 루프는 바로 이 생각-행동-관찰 고리의 직계 후손이다. ReAct가 한 작업 안의 작은 루프라면, 루프 엔지니어링은 그 위에 세 개를 더 쌓은 큰 루프다.
4-2. Reflexion(2023) — 검증 루프의 조상
ReAct가 "도구를 쓰며 생각하기"였다면, Reflexion(신Shinn 등, 2023, NeurIPS)은 한 발 더 간다. "이번에 왜 틀렸지?"를 스스로 말로 적어 다음 시도에 반영하는 루프다. 놀라운 점은 모델의 가중치를 전혀 바꾸지 않는다는 것 — 오직 언어로 된 피드백만으로 성능을 끌어올린다. 그래서 '언어적 강화학습(verbal reinforcement learning)' 이라 부른다.
Reflexion의 아키텍처는 세 개의 역할로 나뉜다. 이 분업이 오늘날 검증 루프와 '서브에이전트 분리'의 조상이다.
Actor · 행동가
실제 행동과 답을 생성하는 LLM. 내부적으로 CoT·ReAct를 쓴다 (정책 역할)
Evaluator · 평가자
생성된 궤적(trajectory)을 받아 성공/실패의 보상 점수를 매긴다
Self-Reflection · 성찰가
실패를 "무엇이·왜 잘못됐고 다음엔 어떻게"라는 말로 변환
↓ 성찰 메모를 일화 기억(episodic memory)에 저장 → 다음 시도의 입력으로 ↓
돌아가는 방식은 하나의 고리다 — 과업 정의 → 궤적 생성 → 평가 → 성찰 → 다음 궤적 생성. 짧은 기억(현재 궤적)과 긴 기억(누적된 성찰)을 함께 굴리며, 파인튜닝 없이 시행마다 나아진다. 이 세 역할이 만든 핵심 원칙이 바로 검증 루프의 심장이다.
답을 쓴 모델이 자기 답을 채점하게 두지 마라. 코드를 작성한 모델은 자기 숙제에 너무 후한 점수를 준다. Reflexion은 평가를 분리해 이 편향을 깼다.
성과도 확실했다. ALFWorld에서 134개 과제 중 130개를 완수해 ReAct 단독을 크게 앞섰고, 코드 생성 벤치마크 HumanEval에서 약 91% 로 당시 최고 수준에 올랐다.
Reflexion — ALFWorld (130/134 과제)
Reflexion — HumanEval 코딩 정확도
▲ 두 논문의 대표 수치. ReAct는 '향상 폭(%p)', 나머지 둘은 '달성률(%)' 기준이라 절대 비교는 아님
두 논문이 루프 엔지니어링에 남긴 유산
- ReAct → 생각-행동-관찰 고리 = ①에이전트 루프의 기본 박동
- Reflexion → 메이커·체커 분리 + 외부 기억 = ②검증 루프와 ④힐 클라이밍의 씨앗
여기서 한 가지가 또렷해진다. Reflexion의 '일화 기억'은 오늘날 에이전트 메모리의 직접 조상이다. 기억이 어떻게 루프를 시간 너머로 이어주는지는 《AI는 어떻게 기억하는가》에서 깊게 다뤘다.
제5장: 사례 — '문서 봇'에서 네 루프가 포개지다
이론은 충분하다. 이제 네 개의 루프가 하나의 살아 있는 시스템으로 포개지는 순간을 보자. LangChain이 든 대표 사례는 자사의 문서 관리 에이전트('docs agent') 다. 개발자가 코드를 바꾸면 문서도 따라 바뀌어야 하는데, 그 지겨운 일을 봇이 대신한다.

③ 이벤트 루프
Slack의 #docs-plz 채널에 "이 기능 문서 좀"이라는 메시지가 올라온다. 이 메시지 도착이 곧 방아쇠 — 사람이 봇을 켜지 않아도 봇이 스스로 깨어난다.
① 에이전트 루프
봇이 저장소를 복제하고, 관련 파일을 읽고, 무엇을 바꿀지 계획하고, 문서를 고쳐 쓴 뒤 PR을 연다. 도구를 부르며 작업이 끝날 때까지 도는 심장.
② 검증 루프
자동 채점기가 확인한다 — 링크가 다 연결되는가, CI가 통과하는가, 변경 범위가 요청한 선을 넘지 않는가. 미달이면 피드백과 함께 ①로 되돌린다.
④ 힐 클라이밍 루프
쌓인 실행 기록을 분석 에이전트가 읽고, "이 봇이 자꾸 특정 유형 링크를 깨뜨린다"를 발견하면 봇의 프롬프트·도구를 스스로 손본다. 다음부터 ①②가 더 잘 돈다.
여기서 중요한 통찰 하나. 자동 채점기가 링크가 연결되는지는 확인할 수 있지만, '이 문서의 어조·프레이밍이 틀렸다'는 건 여전히 사람이 알아챈다. LangChain이 강조하는 대목이다.
"자동 채점기는 링크가 연결되는지 확인할 수 있다. 하지만 프레이밍이 잘못됐다는 걸 알아채는 건 사람의 몫이다."
그래서 네 루프 모두에 사람이 개입하는 체크포인트(human-in-the-loop) 가 자연스럽게 존재한다. 특히 돈이나 데이터베이스를 건드리는 되돌릴 수 없는 작업 앞에서는 반드시. loopcraft는 사람을 없애는 기술이 아니라, 사람이 '실행'이 아니라 '조종(steer)'에 집중하도록 자리를 옮기는 기술이다.
제6장: 2026년 — 복리, 사람, 그리고 잘못된 채점표의 위험
왜 지금 이것이 중요한가 — 복리 효과
2026년, 앞선 팀들이 loopcraft에 몰두하는 이유는 하나로 요약된다. 복리(compounding). 프롬프트나 컨텍스트를 아무리 잘 다듬어도 그것은 한 번의 개선이다. 하지만 힐 클라이밍 루프를 심으면, 시스템은 프로덕션 데이터를 먹으며 시간이 갈수록 스스로 나아진다. 정체(plateau)하지 않고 복리로 쌓인다.
마이크로소프트 CEO 사티아 나델라의 말을 빌려, LangChain은 이렇게 정리한다.
"학습 루프를 일찍 구축한 회사는 — 복제하기 어려운 우위를 쌓게 된다."
이것이 loopcraft가 단순한 개발 기법을 넘어 경영 전략이 되는 지점이다. 경쟁사가 더 좋은 모델을 사 오는 사이, 당신의 시스템은 당신의 데이터로만 만들어지는 개선의 언덕을 스스로 오른다.
하지만 — 잘못된 채점표라는 함정
루프를 쌓는 데는 대가와 위험이 따른다. LangChain과 해설자들이 입을 모아 경고하는 지점을 솔직하게 짚는다.
| 얻는 것 | 치르는 것 / 위험 |
|---|
| 층마다 신뢰성·자율성·자기개선이 올라간다 | 층마다 지연(latency)과 비용이 붙는다 |
| 상시 백그라운드 운영 | 상당한 인프라 투자가 필요하다 |
| 복리로 쌓이는 개선 | 기준표(rubric)가 잘못되면 — 시스템은 신나게 엉뚱한 목표로 최적화된다 |
마지막 줄이 핵심이다. 힐 클라이밍 루프는 '언덕을 오르는' 기술인데, 당신이 잘못된 언덕을 가리키면 시스템은 그 잘못된 정상까지 아주 효율적으로 올라가 버린다. 채점표가 '링크가 깨지지 않는 것'만 본다면, 봇은 어조가 엉망이어도 링크만 멀쩡한 문서를 양산하도록 진화한다. 자동화가 강력할수록, 무엇을 채점하는가가 무엇보다 중요해진다.
비용 폭주·보안(자율 루프 + 외부 연결의 '치명적 삼각편대')·주니어 파이프라인의 소멸 같은 더 어두운 논쟁은 코어닷투데이의 후속편 《루프 엔지니어링의 위험과 논쟁》에서 따로 깊게 다뤘다.
정리 — 루프를 쌓는다는 것
🧩
과거: 에이전트를 프롬프트했다
사람이 매번 지시하고, 결과를 검토하고, 다음 일을 시켰다. 사람이 곧 루프였다.
🔁
현재: 루프를 쌓는다
일하는 루프를 검증 루프가 감싸고, 이벤트 루프가 깨우고, 힐 클라이밍 루프가 전체를 스스로 고쳐 쓴다.
📈
그래서: 사람은 조종석으로
사람의 일은 '실행'에서 '조종'으로 옮겨간다 — 어느 언덕을 오를지 가리키고, 되돌릴 수 없는 순간에 손을 얹는 것.
swyx의 말로 이 글을 닫는다. "다음 세기의 게임 전체는, 루프를 얼마나 효과적으로 쌓을 수 있느냐에 달렸다." 2026년, 그 게임은 이미 시작됐다. 그리고 다행히도, 그 규칙은 프롬프트 한 줄보다 배우기에 훨씬 흥미롭다 — 왜냐하면 그것은 한 번의 답이 아니라 스스로 나아지는 시스템을 짓는 일이기 때문이다.
함께 읽으면 좋은 코어닷투데이 시리즈
참고 자료
- Sydney Runkle, The Art of Loop Engineering, LangChain Blog, 2026
- swyx, Loopcraft: The Art of Stacking Loops (AI Engineer World's Fair 2026) · Latent.Space 데일리 디스패치
- Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models, 2022
- Shinn et al., Reflexion: Language Agents with Verbal Reinforcement Learning, NeurIPS 2023
- What the heck is loop engineering?, Softmax Data, 2026




