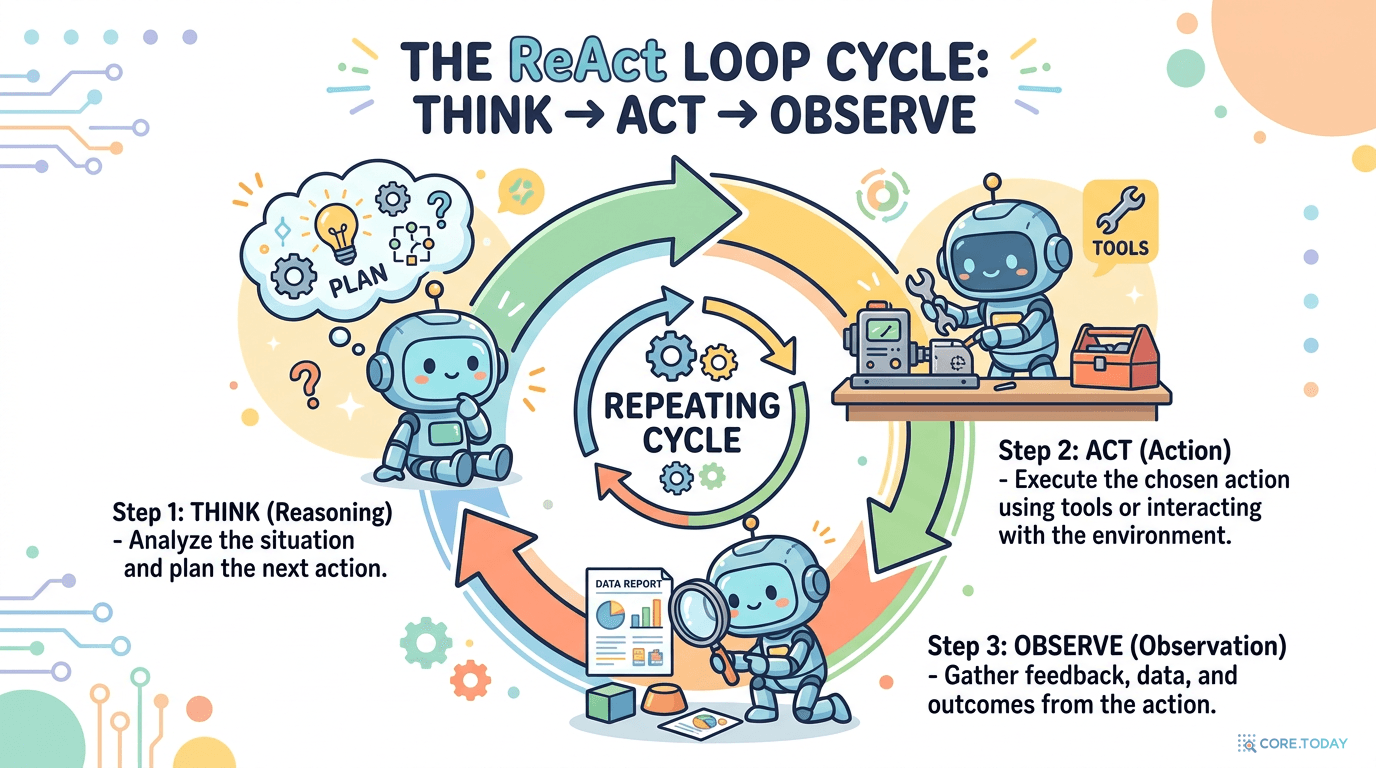
Reason (추론)목표와 현재 상태를 평가하고, 다음에 할 최선의 행동을 계획합니다. "어떤 도구를 써야 할까?"를 판단하는 단계.
↓
Act (행동)적절한 도구를 선택하고 실행합니다. API 호출, DB 조회, 웹 검색 등 실제 세상과 상호작용합니다.
↓
Observe (관찰)도구의 실행 결과를 받아 컨텍스트에 통합합니다. 이 새로운 정보가 다음 Reason 단계의 입력이 됩니다.
직접 체험해보세요: ReAct 루프 시뮬레이터
아래 시뮬레이터에서 실제 에이전트가 어떻게 생각하고, 행동하고, 관찰하는지 단계별로 체험할 수 있습니다. "자동 재생"을 누르면 에이전트의 전체 추론 과정을 볼 수 있어요.
실제 사례: 환불 처리 에이전트
위 시뮬레이터의 "환불 처리" 시나리오를 코드로 보면 이렇습니다. Google의 Agent Development Kit(ADK)에서는 ReAct 루프가 LlmAgent 클래스에 내장되어 있어, 개발자가 직접 루프를 구현할 필요가 없습니다:
hljs language-python
from google.adk import LlmAgent
refund_agent = LlmAgent(
name="refund_agent",
model="gemini-2.5-flash",
instruction="""
고객의 환불 요청을 처리하는 전문 에이전트입니다.
1. 먼저 환불 정책을 검색하세요.
2. 주문 정보를 조회해 환불 조건을 확인하세요.
3. 조건이 충족되면 환불을 실행하세요.
""",
tools=[semantic_search, get_order_details, process_refund]
)
에이전트가 instruction과 tools만 받으면, 나머지 추론 과정은 LLM이 ReAct 루프를 돌면서 자율적으로 결정합니다. 이것이 규칙 기반 챗봇과의 결정적 차이입니다.
3장. 에이전트의 4대 핵심 구성 요소
모든 프로덕션급 AI 에이전트는 네 가지 핵심 구성 요소로 이루어집니다. Google의 가이드에서는 이를 모델, 도구, 오케스트레이션, 런타임으로 정리합니다.
AI 에이전트의 4대 구성 요소
모델Model에이전트의 두뇌. 추론과 의사결정을 담당
도구Tools에이전트의 손. 외부 시스템과 상호작용
오케스트레이션Orchestration에이전트의 전두엽. 계획 수립과 실행 관리
런타임Runtime에이전트의 신체. 확장성, 보안, 배포 환경
3.1 모델: 에이전트의 두뇌를 고르는 법
에이전트의 모델 선택은 "가장 강력한 모델을 고르는 것"이 아닙니다. 핵심은 능력, 속도, 비용의 최적 균형을 찾는 것입니다.
모델 선택 전략: 능력 vs 비용 트레이드오프
Gemini 3 Pro
최고 추론
Gemini 2.5 Flash
고볼륨 균형
Gemini 2.5 Flash-Lite
최저 비용
Google 가이드가 강조하는 핵심 원칙:
강력한 인지 아키텍처는 여러 전문화된 에이전트를 활용하며, 각각이 자신의 서브 태스크에 가장 효율적인 모델을 동적으로 선택합니다. 무거운 모델은 복잡한 추론에, 가벼운 모델은 일상적인 쿼리에 배정하세요.
이 원칙은 2025년 DeepSeek이 600만 달러로 OpenAI o1급 추론 모델을 만든 사건과 맥을 같이 합니다. 비싼 모델을 무조건 쓰는 시대는 끝났습니다.
3.2 도구: 에이전트에게 손을 달아주는 법
도구(Tools)는 에이전트가 추론을 넘어 실제 세계에서 행동할 수 있게 해주는 인터페이스입니다.
도구의 종류는 다양합니다:
내부 함수: 팀이 직접 작성한 비즈니스 로직
API: 내부/외부 서비스 연결 (Slack, CRM, 결제 시스템 등)
데이터 소스: DB, 벡터 스토어, 문서 저장소 조회
다른 에이전트: 멀티 에이전트 시스템에서 전문 에이전트를 도구로 활용
Google ADK에서 도구를 정의하는 방법은 놀랍도록 직관적입니다:
hljs language-python
defcheck_inventory(product_id: str) -> dict:
"""주어진 상품의 실시간 재고 수량을 반환합니다.
Args:
product_id: 상품 고유 ID (예: "SKU-12345")
Returns:
{"status": "success", "stock": int, "warehouse": str}
"""# 실제 재고 시스템 API 호출
result = inventory_api.get_stock(product_id)
return {"status": "success", "stock": result.quantity, "warehouse": result.location}
여기서 핵심은 docstring이 모델의 주요 정보원이라는 점입니다. 도구의 이름, 설명, 파라미터 타입 힌트가 곧 "모델과의 API 계약서"가 됩니다. 설명이 모호하면 모델이 도구를 잘못 선택하고, 에이전트가 무한 루프에 빠집니다.
3.3 오케스트레이션: 계획 수립과 실행의 기술
오케스트레이션은 에이전트의 실행 기능(executive function)입니다. 어떤 도구를, 어떤 순서로, 어떻게 조합할지를 결정합니다.
아래 탐색기에서 다양한 에이전트 타입을 클릭해보세요:
3.4 런타임: 프로토타입을 프로덕션으로
에이전트가 완성되었다면, 이제 실제 사용자에게 배포해야 합니다. 런타임은 확장성, 보안, 안정성을 제공합니다.
2024년까지 많은 기업이 "하나의 만능 AI"를 꿈꿨습니다. 하지만 현실은 달랐죠. 하나의 에이전트에 모든 도구를 넣으면:
도구가 많을수록 모델이 혼란스러워짐 (선택 오류 증가)
프롬프트가 길어져 비용과 지연 급증
실패 시 전체 시스템이 다운
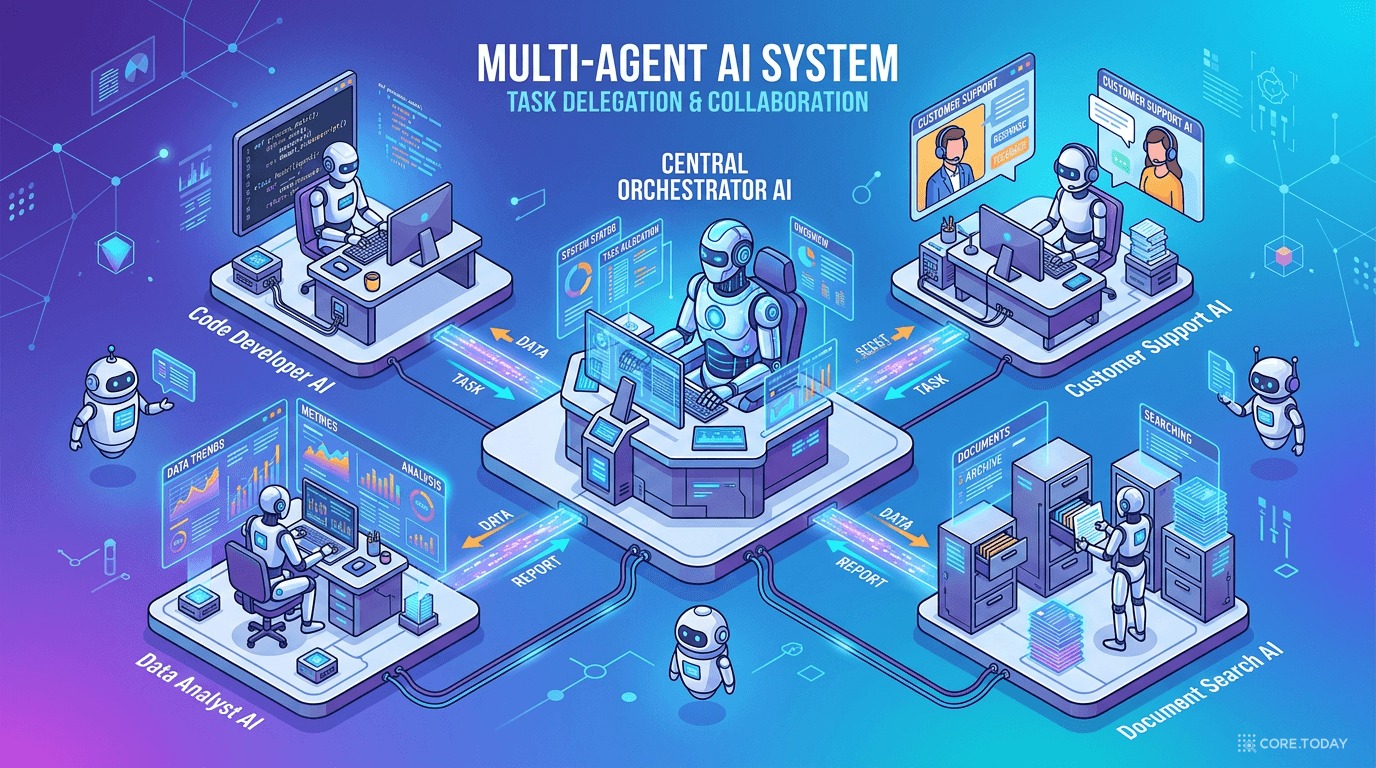
해법은 인간 조직과 동일한 구조 — 전문화된 에이전트 팀입니다.
ADK의 멀티 에이전트 패턴
Google의 Agent Development Kit(ADK)는 처음부터 멀티 에이전트 설계를 전제합니다. 앞서 에이전트 아키텍처 탐색기에서 본 것처럼, 다양한 에이전트 타입을 레고처럼 조합할 수 있습니다.
실제 예시를 봅시다. 소프트웨어 버그 분류 시스템을 만든다면:
오케스트레이터 bug_triage_agent (LlmAgent)
↓ 분석 요청
사용자 조회 get_user_details
코드 검색 search_codebase
티켓 생성 create_jira_ticket
↓ 외부 시스템 연동
CRM DB
GitHub MCP
Jira API
Agent-as-a-Tool 패턴
ADK의 강력한 패턴 중 하나가 Agent-as-a-Tool — 한 에이전트가 다른 에이전트를 도구처럼 사용하는 것입니다.
hljs language-python
# 전문가 에이전트 정의
code_analyst = LlmAgent(
name="code_analyst",
model="gemini-3-pro", # 복잡한 코드 분석엔 강력한 모델
instruction="코드를 분석하고 버그의 근본 원인을 파악하세요.",
tools=[search_codebase, read_file]
)
# 오케스트레이터가 전문가를 도구로 사용
triage_agent = LlmAgent(
name="bug_triage_agent",
model="gemini-2.5-flash", # 조율 작업엔 가벼운 모델
instruction="버그 리포트를 분석하고 우선순위를 매기세요.",
tools=[get_user_details, code_analyst, create_jira_ticket]
# ↑ 에이전트를 도구로!
)
이 구조의 장점은 모델 비용 최적화입니다. 조율 작업은 저렴한 Flash 모델이, 복잡한 코드 분석은 강력한 Pro 모델이 담당합니다.
5장. 그라운딩: 에이전트가 거짓말하지 않게 만드는 법
RAG에서 Agentic RAG까지의 진화
AI의 가장 큰 약점은 환각(Hallucination) — 그럴듯하지만 사실이 아닌 내용을 생성하는 것입니다. 에이전트가 잘못된 정보를 기반으로 행동하면 그 결과는 치명적입니다. 잘못된 환불, 틀린 의료 정보, 부정확한 투자 조언...
이 문제의 해답이 그라운딩(Grounding) — 에이전트의 응답을 검증 가능한 사실에 기반시키는 기술입니다.
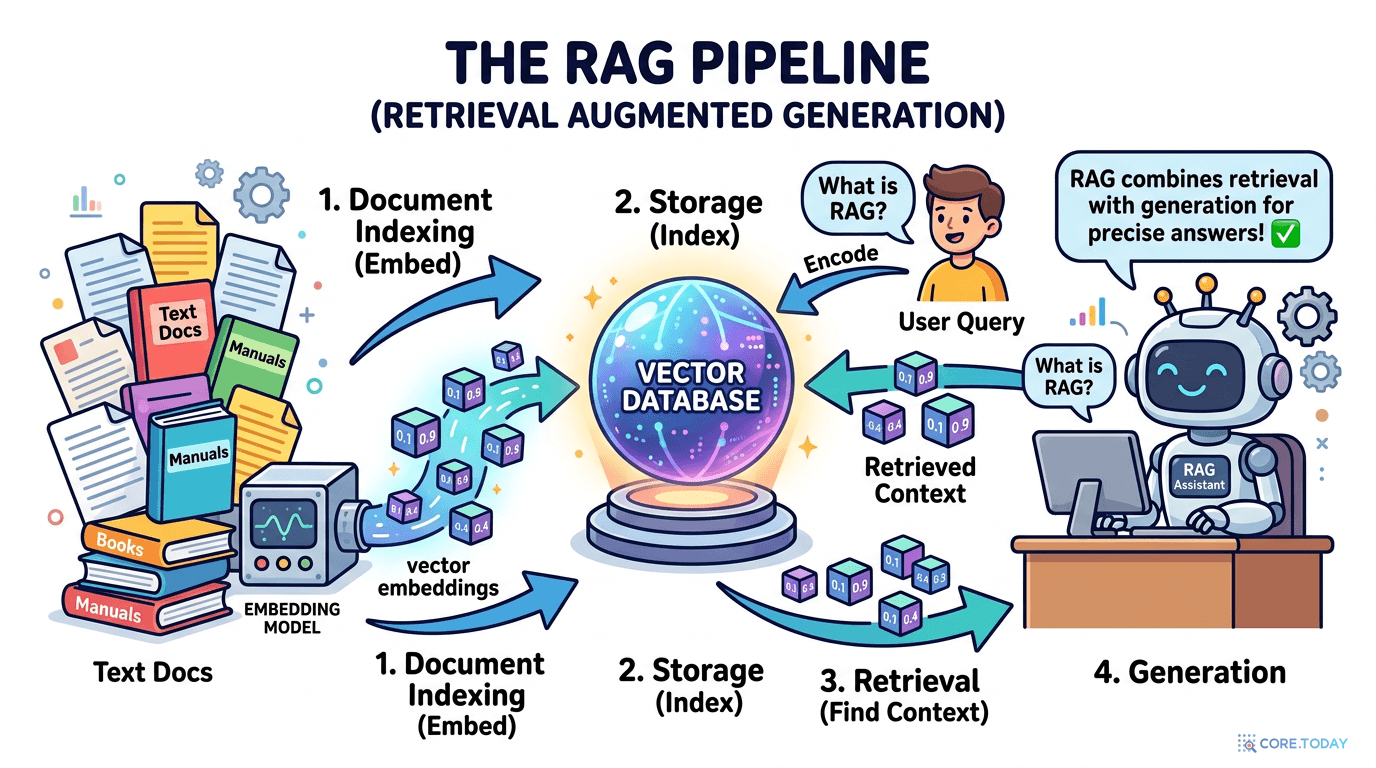
RAG (Retrieval-Augmented Generation)는 LLM이 답변하기 전에 외부 지식 베이스에서 관련 정보를 검색하는 패턴입니다.
Ingest
문서 수집 — PDF, 이미지, 동영상 등 원본 데이터를 수집
Chunk
분할 — 문서를 의미 단위 조각(chunk)으로 나눔
Embed
벡터화 — 각 조각을 벡터 임베딩으로 변환 (의미를 숫자로)
Store
저장 — 벡터 데이터베이스에 인덱싱하여 저장
Retrieve
검색 — 사용자 질문을 벡터로 변환 → 유사도 검색 → 관련 정보 추출
벡터 데이터베이스: 의미로 검색하는 기술
전통적 데이터베이스와 벡터 DB의 차이를 실감할 수 있는 예시입니다:
❌
기존 SQL 검색SELECT * FROM shoes WHERE description LIKE '%발이 넓은 사람에게 좋은%' → 결과 없음! 정확한 문자열이 DB에 없기 때문
✅
벡터 검색 (시맨틱)"발이 넓은 사람에게 좋은 신발" 검색 → "와이드 핏", "넓은 발폭 추천", "편안한 착화감" 등 의미적으로 관련된 상품 모두 반환!
💡
핵심 원리벡터 임베딩은 텍스트의 "의미"를 다차원 공간의 좌표로 변환합니다. 비슷한 의미의 텍스트는 가까운 좌표에 위치합니다.
GraphRAG: 관계를 이해하는 검색
기본 RAG는 "비슷한 문장 찾기"에 강하지만, 개념 간의 관계는 이해하지 못합니다. 예를 들어 "이 약의 부작용과 관련된 다른 약물은?" 같은 질문은 단순 유사도 검색으로 풀 수 없습니다.
GraphRAG는 데이터를 지식 그래프로 구축해, 개념 간의 관계를 명시적으로 표현합니다.
GraphRAG — 의료 AI 에이전트 예시
일반 RAG: "두통약 A" 검색 → "두통약 A의 성분" 반환 (관련 문장) GraphRAG: "두통약 A" 검색 → 증상 ← 두통 → 원인 → 혈압 → 치료 → 혈압약 B "두통약 A를 복용 중인 환자에게 혈압약 B를 함께 처방할 때의 상호작용"까지 파악 가능
실제 사례로, BioCorteX는 440억 개 연결의 지식 그래프를 구축하고, Gemini 기반 에이전트와 A2A 프로토콜로 신약 개발 과정을 수년에서 수일로 단축했습니다.
Agentic RAG: 에이전트가 검색 전략을 스스로 수립
가장 진보된 형태인 Agentic RAG에서는, 에이전트가 수동적으로 검색 결과를 받는 게 아니라 능동적으로 검색 전략을 수립합니다.
ReAct 프레임워크와 결합하면 에이전트는:
복잡한 질문을 여러 하위 질문으로 분해
각 질문에 최적의 검색 방법 결정 (웹 검색? DB 조회? API 호출?)
결과를 평가하고 추가 검색 필요 여부 판단
모든 정보를 종합해 근거 있는 최종 답변 생성
사용자: "SolarFlare 러닝화 재고 있어?"
에이전트 추론 과정:
1. 먼저 product_lookup으로 정확한 상품 특정 (시맨틱 검색)
2. check_inventory로 실시간 재고 확인 (API 호출)
3. "네! SolarFlare 러닝화 재고가 82켤레 있습니다." (근거 기반 답변)
6장. 프로토콜의 표준화: MCP와 A2A
왜 표준이 필요한가?
웹이 HTTP 없이는 불가능했듯, 에이전트 생태계도 통신 표준 없이는 확장할 수 없습니다.
웹의 역사
AI 에이전트
역할
HTTP
A2A (Agent-to-Agent)
에이전트 간 통신
REST API
MCP (Model Context Protocol)
도구 연결
브라우저
에이전트 런타임
실행 환경
DNS
에이전트 디스커버리
서비스 발견
MCP: 에이전트의 USB-C
Model Context Protocol (MCP)은 Anthropic이 제안한 오픈 표준으로, AI 에이전트가 외부 데이터 소스와 도구에 연결하는 방식을 표준화합니다.
MCP 이전에는 각 도구마다 커스텀 통합을 만들어야 했습니다. MCP 이후에는 — USB-C처럼 — 하나의 표준 인터페이스로 모든 도구에 연결됩니다.
AI 에이전트 (ADK)
↕ MCP (표준 프로토콜)
BigQuery
PostgreSQL
Slack
GitHub
Notion
hljs language-python
# ADK에서 MCP 서버의 도구를 바로 사용from google.adk.tools import MCPToolset
github_tools = MCPToolset(
server_url="https://github-mcp-server.example.com"
)
agent = LlmAgent(
name="dev_agent",
model="gemini-2.5-flash",
tools=[github_tools] # GitHub의 모든 MCP 도구를 자동으로 사용 가능
)
A2A: 에이전트끼리 대화하는 프로토콜
Agent2Agent (A2A)는 Google이 2025년 4월 발표하고 Linux Foundation에 기부한 오픈 프로토콜입니다. 에이전트 간의 발견, 통신, 협업을 표준화합니다.
A2A의 핵심 개념:
Agent Card: 에이전트의 "디지털 명함" — 능력, 엔드포인트 URL, 인증 요구사항을 JSON으로 광고
Task 기반 아키텍처: 클라이언트 에이전트가 서버 에이전트에게 "태스크"를 요청하는 구조
모달리티 무관: 텍스트, 오디오, 비디오 모두 지원
Box 사례가 인상적입니다. A2A 프로토콜과 ADK, Gemini를 결합해 자연어로 문서를 검색하고 인사이트를 추출하는 에이전트를 구축했습니다. 컨텐츠 중심 워크플로우의 의사결정 속도를 극적으로 향상시켰습니다.
프로토타입 단계에서는 에이전트를 직접 테스트해보고 "잘 되는 것 같은데?"로 넘어가곤 합니다. Google은 이를 "vibe testing"이라 부르며, 프로덕션에서는 절대 충분하지 않다고 경고합니다.
LLM 기반 시스템은 비결정적(non-deterministic)입니다. 같은 입력에 다른 출력이 나올 수 있습니다. 전통적인 단위 테스트만으로는 이 복잡성을 다룰 수 없습니다.
Harrison Chase (LangChain CEO):
"에이전트는 새로운 수준의 생산성을 가져다주지만, 그 성공은 우리의 안내(guidance)에 달려 있습니다."
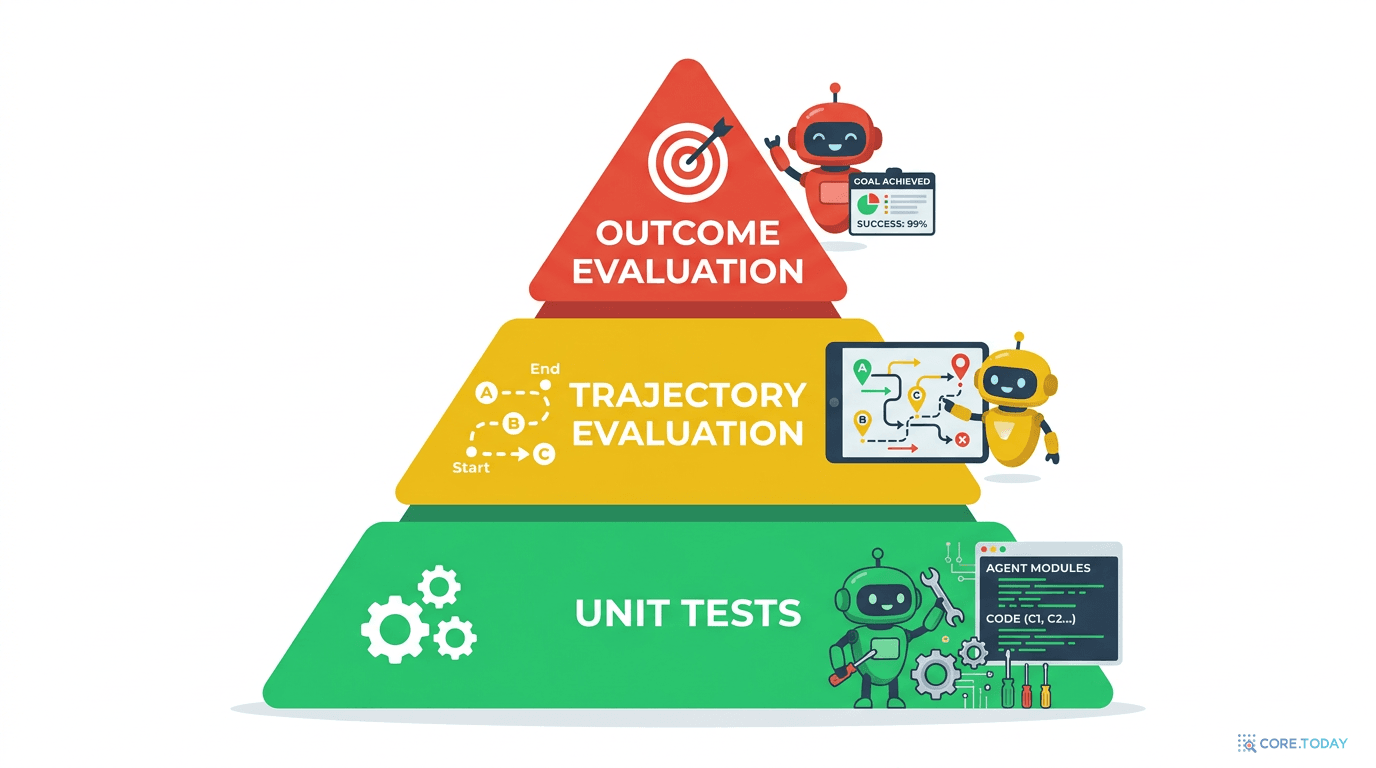
3계층 평가 프레임워크
Google이 제시하는 AgentOps의 핵심은 3계층 평가 체계입니다:
🔧
Layer 1: 컴포넌트 평가 (결정적 단위 테스트)무엇을? 도구 함수, 데이터 파싱, API 통합의 정상/에러/엣지 케이스 테스트 왜? 에이전트 실패가 단순한 도구 버그에서 기인하지 않도록 보장 방법: ADK에서 도구를 Python 함수로 정의 → 표준 pytest로 테스트
🧭
Layer 2: 궤적 평가 (추론 과정의 정확성)무엇을? ReAct 루프의 전체 궤적(trajectory) — Reason, Act, Observe 각 단계를 검증 왜? 최종 답이 맞아도 과정이 잘못되면 다음엔 실패할 수 있음 방법: ADK + Cloud Trace로 각 단계를 시각화, "골든 셋" 프롬프트로 회귀 테스트
🎯
Layer 3: 결과 평가 (의미적 정확성)무엇을? 최종 사용자 응답의 사실 정확성, 유용성, 완전성, 톤 검증 왜? 그라운딩된 정보에 기반한 응답인지, 환각은 없는지 확인 방법: ADK 도구로 팩트 체크 자동화, Agent Starter Pack으로 CI/CD 파이프라인에 통합
Agent Starter Pack: 원커맨드 프로덕션 셋업
Google의 Agent Starter Pack은 위의 모든 AgentOps 원칙을 한 줄의 명령어로 구현합니다:
Agent Starter Pack — 프로덕션 환경 일괄 구성
$ uvx agent-starter-pack create my-agent -a adk@gemini-fullstack
자동으로 생성되는 것들:
• Terraform — 클라우드 인프라 코드 (Cloud Run, IAM, 네트워크)
• Cloud Build CI/CD — 빌드, 테스트, 평가, 배포 자동화 파이프라인
• Cloud Trace + OpenTelemetry — 에이전트 실행 추적 및 디버깅
• Cloud Logging — 중앙 집중식 로그 관리
• BigQuery — 장기 감사 로그 저장 및 분석
• 평가 데이터셋 — tests/integration/ 골든 셋 프롬프트 스켈레톤