블로그로 돌아가기
컨텍스트 엔지니어링AI 에이전트프롬프트 엔지니어링LLMRAGMCPClaude Code
컨텍스트 엔지니어링 완전 정복: 프롬프트의 시대는 끝났다
프롬프트 한 줄로 AI를 다루던 시대가 저물고 있다. 2026년, AI 에이전트 시대의 핵심 역량은 '컨텍스트 엔지니어링'이다. 역사적 배경부터 핵심 개념, 실전 사례까지 — Anthropic의 가이드를 바탕으로 완전 해부한다.
코어닷투데이2026-04-0762분
프롬프트 한 줄로 AI를 다루던 시대가 저물고 있다. 2026년, AI 에이전트 시대의 핵심 역량은 '컨텍스트 엔지니어링'이다. 역사적 배경부터 핵심 개념, 실전 사례까지 — Anthropic의 가이드를 바탕으로 완전 해부한다.
당신이 AI에게 이렇게 요청했다고 하자:
"우리 회사 4분기 매출 정리해 줘."
AI가 틀린 숫자를 뱉었다. 당신은 투덜댄다 — "AI가 왜 이렇게 멍청한 거야?"
하지만 잠깐. 그 AI에게 무엇을 보여줬는가? 4분기 재무 보고서는 넣어줬는가? 아니면 100페이지짜리 법률 자문서, 사내 식당 메뉴표, 전사 타운홀 회의록까지 전부 한꺼번에 쑤셔넣었는가?
AI가 멍청한 게 아니다. 당신이 잘못된 정보를 보여준 것이다.
이것이 바로 컨텍스트 엔지니어링이 해결하는 문제다.
2023년에는 "이 프롬프트만 쓰면 ChatGPT가 완벽하게 답변해요!"라는 말이 넘쳐났다. 마법의 문장 하나면 AI가 원하는 결과를 내놓을 것만 같았다. 그런데 2026년 현재, 진짜 AI 에이전트를 만들어 본 엔지니어들은 알고 있다 — 프롬프트는 빙산의 일각에 불과하다는 것을.
2025년 6월, 테슬라 AI 출신이자 세계에서 가장 영향력 있는 AI 엔지니어 중 한 명인 Andrej Karpathy가 트위터에 이렇게 적었다:
"+1 for 'context engineering' over 'prompt engineering'. 모든 산업 수준의 LLM 앱에서, 컨텍스트 엔지니어링은 다음 스텝에 적합한 정보로 컨텍스트 윈도우를 채우는 섬세한 예술이자 과학이다."
같은 달, Shopify CEO Tobi Lütke도 한마디 던졌다:
"나는 '프롬프트 엔지니어링'보다 '컨텍스트 엔지니어링'이라는 용어가 훨씬 좋다. 이것이 핵심 역량을 더 잘 설명한다: LLM이 과제를 그럴듯하게 풀 수 있도록 모든 맥락을 제공하는 기술."
한 달 뒤, Gartner가 공식 선언했다: "Context engineering is in, prompt engineering is out."
그리고 2025년 9월, Anthropic의 Applied AI 팀이 에이전트를 위한 컨텍스트 엔지니어링의 종합 가이드를 발표했다. 이 글은 그 가이드를 중심으로, 컨텍스트 엔지니어링이 왜 탄생했고, 무엇이며, 어떻게 활용하는지를 낱낱이 해부한다.
이 글을 읽기 전에, 하나의 비유를 기억해 두자. 이 비유가 모든 개념을 꿰뚫는다.
AI의 컨텍스트 윈도우는 냉장고다.
이 비유를 기억하면, 이후에 나오는 "주의력 예산", "컴팩션", "Just-in-Time 검색", "서브에이전트"가 모두 직관적으로 이해된다.
컨텍스트 엔지니어링은 하루아침에 탄생한 개념이 아니다. AI 연구의 핵심 이정표들이 하나씩 쌓이면서, "프롬프트를 잘 쓰는 것"만으로는 부족하다는 깨달음이 커져 왔다.
모든 것은 Google의 "Attention Is All You Need" 논문에서 시작된다. Vaswani 등이 제안한 트랜스포머 아키텍처의 핵심은 셀프 어텐션(Self-Attention) 메커니즘이다.
쉽게 말하면 이렇다: 문장 속 모든 단어가 다른 모든 단어와 "나 이거 중요해!" 하고 눈을 마주친다. "나는 은행에서 돈을 찾았다"라는 문장에서, 모델은 "은행"과 "돈"이 강하게 연결된다는 것을 학습한다. ("은행"이 "강둑"이 아니라 "금융기관"이라는 걸 "돈"이라는 단어가 알려주는 것이다.)
이 메커니즘 덕분에 LLM은 컨텍스트 윈도우 — 모델이 한 번에 볼 수 있는 토큰의 범위 — 안에서 정보를 관계적으로 이해할 수 있게 됐다. 하지만 여기에는 근본적인 제약이 숨어 있다: n개의 토큰이 있으면 n²개의 관계를 처리해야 한다. 토큰이 늘어날수록 연산량은 기하급수적으로 증가한다.
Anthropic도 이 점을 명확히 짚는다:
"LLM은 트랜스포머 아키텍처에 기반하며, 모든 토큰이 전체 컨텍스트의 다른 모든 토큰에 어텐션을 기울인다. 이것은 n개 토큰에 대해 n²개의 쌍별 관계를 만든다."
더 깊은 문제도 있다. 모델의 어텐션 패턴은 학습 데이터 분포에서 형성되는데, 짧은 시퀀스가 긴 시퀀스보다 훨씬 많다. 즉, 모델은 긴 컨텍스트를 다루는 경험 자체가 적고, 그에 특화된 파라미터도 적다. Position encoding interpolation 같은 기법으로 어느 정도 보완은 가능하지만, 토큰 위치 이해의 저하는 불가피하다.
2020년, OpenAI가 GPT-3를 발표하며 인컨텍스트 러닝(In-Context Learning)이라는 현상을 대규모로 입증했다. 파인튜닝(모델을 재훈련) 없이, 프롬프트에 몇 개의 예시만 넣으면 모델이 새로운 태스크를 수행할 수 있다는 것이었다.
이것이 프롬프트 엔지니어링의 탄생이다. "프롬프트를 어떻게 쓰느냐"가 결과를 좌우한다는 인식이 퍼지면서, "마법의 프롬프트"를 찾는 여정이 시작됐다.
같은 해, Lewis 등은 RAG(Retrieval-Augmented Generation) 논문을 발표했다. 모델이 알고 있는 지식(파라미터)과 외부에서 검색한 문서를 결합하는 아이디어였다. 냉장고 비유로 하면: 모든 재료를 냉장고에 넣지 않고, 필요할 때 장을 보러 간다. 이것은 훗날 컨텍스트 엔지니어링의 "Select(선택)" 전략의 학술적 기원이 된다.
2022년부터 연구가 폭발적으로 쏟아졌다. 이 시기의 핵심 발견은: 컨텍스트에 무엇을, 어떤 순서로, 어떤 구조로 넣느냐가 모델의 행동을 결정한다는 것.
스탠포드의 Generative Agents 연구는 특히 주목할 만하다. 이들이 설계한 에이전트는 단순히 프롬프트를 잘 쓴 게 아니었다. 기억을 저장하고, 검색하고, 반성하는 전체 시스템을 만들었다. 에이전트 "Isabella Rodriguez"는 발렌타인 파티를 계획하면서, 지난 대화 기억을 검색하고, 관련된 사람들에게 초대장을 보내고, 파티 준비 상황을 메모에 기록했다. 이것이야말로 컨텍스트 엔지니어링의 초기 형태다.
2024년, Google의 Gemini 1.5 Pro가 100만 토큰 컨텍스트 윈도우를 선보이며 크기 경쟁이 시작됐다. "충분히 크면 다 들어가니까 괜찮지 않을까?" 많은 이가 그렇게 생각했다.
하지만 2025년 5월, Chroma Research의 Context Rot(컨텍스트 부패) 연구가 찬물을 끼얹었다. 18개 LLM을 테스트한 결과:
동일한 정보를 넣어도, 컨텍스트가 길어질수록 모델의 정확도가 체계적으로 하락한다. 더 충격적인 발견은 따로 있었다: 논리적으로 정리된 컨텍스트보다 무작위로 섞인 컨텍스트에서 성능이 더 높았다. 심지어 주제와 관련 있지만 틀린 정보(산만 요소) 하나만 넣어도 정확도가 떨어졌다.
냉장고 비유로 돌아가면: 냉장고를 초대형으로 업그레이드했는데, 거기에 음식을 가득 쑤셔넣자 냉기가 제대로 순환하지 않아 앞쪽 재료만 차갑고 뒤쪽은 상하기 시작한 것이다.
아래에서 이 현상을 직접 체험해 볼 수 있다:
이 연구가 증명한 것: 컨텍스트의 크기가 아니라 큐레이션의 질이 결정적이다.
Anthropic도 같은 결론을 내린다:
"더 큰 컨텍스트 윈도우를 기다리는 것이 명백한 전략처럼 보일 수 있다. 하지만 예측 가능한 미래 동안, 모든 크기의 컨텍스트 윈도우는 컨텍스트 오염과 정보 관련성 문제에 노출될 것이다 — 적어도 가장 강력한 에이전트 성능이 필요한 상황에서는."
Anthropic은 컨텍스트 엔지니어링을 이렇게 정의한다:
컨텍스트 엔지니어링이란, LLM 추론 시 최적의 토큰 집합을 큐레이션하고 유지하는 전략의 총체다. 프롬프트뿐 아니라, 그 외에 컨텍스트에 들어가는 모든 정보를 포함한다.
그리고 더 간결하게:
"어떤 컨텍스트 구성이 모델의 원하는 행동을 생성할 가능성이 가장 높은가?"
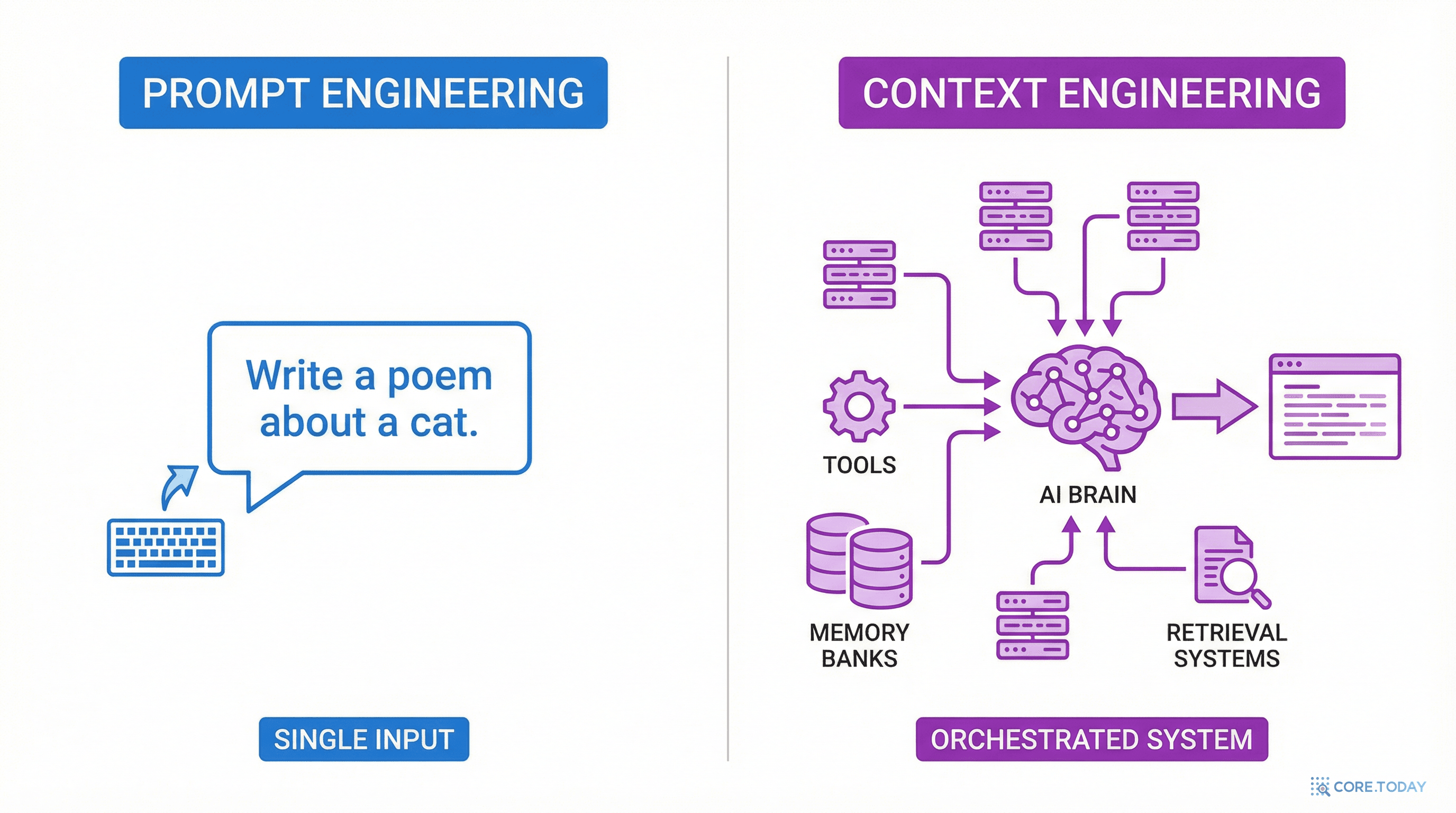
여기서 핵심 단어는 "큐레이션"과 "유지"다. 프롬프트 엔지니어링이 한 번 작성하고 끝이라면, 컨텍스트 엔지니어링은 매 추론마다 동적으로 반복되는 과정이다.
더 풍부한 비유로 풀어보자:
프롬프트 엔지니어링이 "어떤 말을 할 것인가"에 집중했다면, 컨텍스트 엔지니어링은 "이 순간 모델에게 어떤 정보의 구성이 가장 효과적인가"라는 훨씬 넓은 질문에 답한다.
Anthropic은 이 진화의 이유를 명확히 설명한다:
"LLM 엔지니어링 초기에는, 프롬프팅이 AI 엔지니어링 작업의 가장 큰 비중을 차지했다. 대부분의 사용 사례가 원샷 분류나 텍스트 생성이었기 때문이다. 하지만 여러 턴의 추론과 더 긴 시간 지평에서 작동하는 에이전트를 설계하게 되면서, 전체 컨텍스트 상태를 관리하는 전략이 필요해졌다."
| 구분 | 프롬프트 엔지니어링 | 컨텍스트 엔지니어링 |
|---|---|---|
| 초점 | 프롬프트 문구 최적화 | 전체 컨텍스트 상태 최적화 |
| 대상 | 시스템 프롬프트 | 시스템 프롬프트 + 도구 + 기록 + 검색 + 메모리 |
| 적용 시점 | 한 번 (작성 시) | 매 추론마다 동적으로 |
| 주요 과제 | "무슨 말을 할까?" | "이 순간 무엇을 보여줄까?" |
| 사용 사례 | 단일 분류, 텍스트 생성 | 멀티턴 에이전트, 장시간 태스크 |
| 비유 | 레시피 한 장 쓰기 | 주방 전체 운영 |
사실 컨텍스트 엔지니어링은 AI 전용 개념이 아니다. 우리는 매일 이것을 한다.
[사례 1: 의사에게 증상 설명하기]
병원에 갔을 때 당신은 의사에게 태어나서 지금까지의 전체 병력을 읊지 않는다. "3일 전부터 왼쪽 무릎이 아프고, 계단 내려갈 때 심해지고, 부종은 없습니다"처럼 관련된 정보만 선별해서 전달한다. 만약 출생부터 현재까지 모든 건강 기록을 한 번에 읊었다면, 의사는 핵심을 놓칠 것이다.
[사례 2: 신입사원에게 업무 인수인계하기]
새로 온 팀원에게 프로젝트를 넘길 때, 지난 2년치 Slack 기록을 전부 보여주지 않는다. 핵심 결정 사항, 현재 상태, 주의할 점을 정리한 인수인계서를 만든다. 그리고 "자세한 건 이 폴더에 있으니 필요할 때 찾아봐"라고 알려준다. 이것이 바로 컨텍스트 엔지니어링의 "Write + Select + Compress" 전략이다.
[사례 3: 변호사에게 상담받기]
법률 상담을 받을 때, 좋은 의뢰인은 관련 계약서와 쟁점을 정리해서 가져간다. 나쁜 의뢰인은 이메일 100통, 카톡 스크린샷 50장을 한꺼번에 쏟아놓는다. 변호사도 사람이라 주의력에 한계가 있다 — LLM도 마찬가지다.
Anthropic이 제시한 컨텍스트 엔지니어링의 핵심 원칙은 놀라울 정도로 단순하다:
"원하는 결과의 가능성을 극대화하는 가장 작은 고신호 토큰 집합을 찾아라."
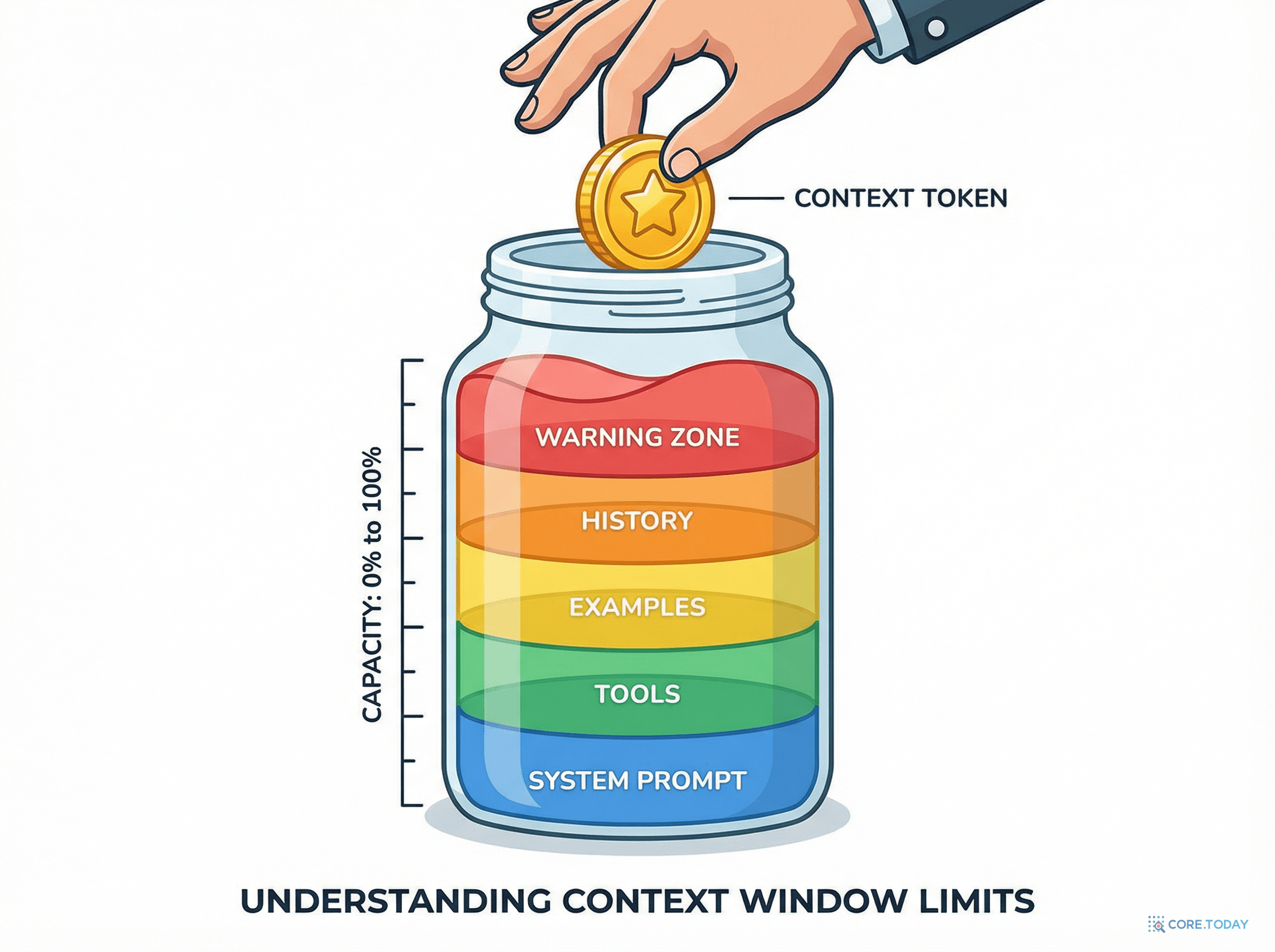
이걸 이해하려면 주의력 예산(Attention Budget)이라는 개념을 알아야 한다.
인간이 작업 기억(Working Memory)의 한계 때문에 한 번에 7±2개의 정보 덩어리만 처리할 수 있듯이, LLM에도 비슷한 제약이 있다. 컨텍스트에 새로운 토큰이 추가될 때마다 주의력 예산의 일부가 소모된다. 이미 중요한 정보에 쏟고 있던 주의력이 희석되는 것이다.
Anthropic의 원문이 이것을 아름답게 표현한다:
"인간이 제한된 작업 기억 용량을 가진 것처럼, LLM도 대량의 컨텍스트를 처리할 때 사용하는 '주의력 예산'이 있다. 새로운 토큰이 도입될 때마다 이 예산의 일부가 소모되어, LLM에게 제공되는 토큰을 신중하게 큐레이션해야 할 필요성이 커진다."
냉장고 비유로 돌아가면: 냉장고의 냉기가 주의력 예산이다. 재료가 적으면 전부 시원하지만, 꽉 채우면 냉기가 고루 퍼지지 않아 어떤 건 차갑고 어떤 건 미지근해진다.
Anthropic은 컨텍스트의 각 구성 요소에 대해 구체적인 가이드라인을 제시한다. 하나씩 뜯어보자.
시스템 프롬프트는 에이전트의 정체성과 행동 규칙을 정의하는 출발점이다. Anthropic은 "적정 고도(Right Altitude)"라는 비유를 사용해 두 가지 극단적 실패 모드를 경고한다.
냉장고 비유: 너무 낮은 고도는 "월요일에는 김치찌개만 만들어, 화요일에는 된장찌개만 만들어"처럼 매일의 메뉴를 하드코딩하는 것이다. 너무 높은 고도는 "뭐든 맛있는 거 해줘"다. 적정 고도는 "한식 위주로, 채소 많이, 너무 맵지 않게, 손님이 알레르기 있으면 물어봐"처럼 원칙과 판단 기준을 주는 것이다.
Anthropic의 핵심 권장 사항:
"가장 좋은 모델로 최소한의 프롬프트부터 테스트하고, 초기 테스트에서 발견된 실패 모드를 기반으로 명확한 지시와 예시를 추가하라."
그리고 중요한 단서:
"최소한(minimal)이 짧은(short)과 같은 말은 아니다. 원하는 행동을 준수하도록 에이전트에게 충분한 정보를 사전에 제공해야 한다."
구조적으로는 <background_information>, <instructions>, ## Tool guidance, ## Output description 같은 XML 태그나 Markdown 헤더로 섹션을 구분하기를 권장한다.
에이전트가 환경과 상호작용하는 수단인 도구는 컨텍스트의 핵심 구성 요소다. Anthropic은 강조한다:
"도구는 에이전트와 그 정보/행동 공간 사이의 계약을 정의하기 때문에, 도구가 효율성을 촉진하는 것이 극도로 중요하다."
그리고 가장 자주 목격하는 실패 모드를 명확히 경고한다:
"가장 흔한 실패 모드는 너무 많은 기능을 커버하거나 어떤 도구를 써야 할지 모호한 결정 포인트를 만드는 비대한 도구 세트다."
핵심 테스트: "인간 엔지니어가 이 상황에서 어떤 도구를 써야 하는지 확정적으로 말할 수 없다면, AI 에이전트도 그보다 나을 수 없다."
Manus(AI 에이전트 플랫폼)의 실전 데이터에 따르면, 프로덕션 에이전트는 생성하는 토큰 1개당 입력 토큰 100개를 처리한다 (100:1 비율). 도구 결과의 토큰 효율성이 곧 전체 시스템의 비용과 성능을 결정짓는 것이다.
Anthropic은 few-shot 예시를 여전히 가장 효과적인 기법 중 하나로 꼽는다. 하지만 흔한 실수가 있다: 프롬프트에 가능한 모든 엣지 케이스를 나열하려는 것.
"세탁 목록처럼 엣지 케이스를 나열하지 마라. 대신, 에이전트의 기대 행동을 효과적으로 보여주는 다양하고 대표적인 예시 세트를 큐레이션하라."
그리고 아름다운 한 줄:
"LLM에게 예시는 천 마디 말의 가치가 있는 '그림'이다."
냉장고 비유: 요리 초보에게 "소금은 간이 싱거울 때, 설탕은 단맛이 필요할 때, 간장은..." 하고 100가지 조건을 나열하는 것보다, 잘 만든 요리 3접시를 맛보게 하는 게 훨씬 효과적이다.
Anthropic이 모든 컨텍스트 구성요소(시스템 프롬프트, 도구, 예시, 메시지 기록 등)에 대해 제시하는 종합 가이드:
"사려 깊게, 컨텍스트를 정보는 풍부하되 간결하게 유지하라 (be thoughtful and keep your context informative, yet tight)."
Anthropic은 에이전트에 대해 놀라울 정도로 단순한 정의로 수렴했다:
"에이전트란 LLM이 루프에서 자율적으로 도구를 사용하는 것이다."
이 단순한 정의 안에 컨텍스트 엔지니어링의 핵심 도전이 숨어있다: 에이전트가 루프를 돌 때마다 새로운 데이터가 생성되고, 이 데이터는 주기적으로 정제되어야 한다.
초기 AI 앱들은 추론 전에 관련 데이터를 모두 검색해서 컨텍스트에 넣어놓는 방식(사전 검색)을 썼다. 하지만 에이전트 시대가 열리면서, 새로운 패러다임이 등장했다: "딱 필요한 순간에(Just-in-Time)" 가져오기.
이 접근법의 핵심 아이디어:
Anthropic의 코딩 에이전트 Claude Code가 이 방식의 대표 사례다:
"Claude Code는 이 접근법을 사용하여 대용량 데이터베이스에 대한 복잡한 데이터 분석을 수행한다. 모델은 타겟 쿼리를 작성하고, 결과를 저장하고,
head와tail같은 Bash 명령어로 대량의 데이터를 분석한다 — 전체 데이터 객체를 컨텍스트에 로딩하지 않으면서."
Anthropic은 이것을 인간의 인지 방식에 비유한다:
"이 접근법은 인간의 인지를 반영한다: 우리는 일반적으로 정보의 전체 코퍼스를 암기하지 않고, 파일 시스템, 받은편지함, 북마크 같은 외부 정리 및 인덱싱 시스템을 도입하여 필요할 때 관련 정보를 검색한다."
Just-in-Time 전략의 부가적 장점은 점진적 발견을 가능하게 한다는 것이다. 에이전트가 데이터를 자율적으로 탐색할 때, 각 상호작용에서 다음 결정을 위한 단서를 얻는다:
Anthropic의 아름다운 표현:
"에이전트는 레이어 바이 레이어로 이해를 조립하며, 작업 기억에는 필요한 것만 유지하고 추가적인 영속성을 위해 노트테이킹 전략을 활용한다."
test_utils.py라는 파일이 tests 폴더에 있을 때와 src/core_logic/에 있을 때, 에이전트는 그 목적이 다르다는 것을 자연스럽게 추론한다. 마치 경험 많은 개발자가 폴더 구조를 보고 프로젝트 아키텍처를 파악하듯이.
물론 런타임 탐색에는 트레이드오프가 있다 — 사전에 계산된 데이터를 가져오는 것보다 느리다. 그리고 적절한 가이드 없이는 에이전트가 삽질(도구 오용, 막다른 길 추적, 핵심 정보 놓침)을 할 수 있다.
Anthropic은 가장 효과적인 에이전트가 하이브리드 전략을 쓴다고 밝힌다:
| 전략 | 장점 | 단점 | 적합한 상황 |
|---|---|---|---|
| 사전 검색 (Pre-fetch) | 빠른 속도 | 스테일 인덱스, 관련 없는 데이터 혼입 | 안정적인 콘텐츠 (법률, 금융) |
| JIT 검색 | 항상 최신, 최소 컨텍스트 | 탐색 시간, 삽질 가능 | 동적 콘텐츠 (코드, 실시간 데이터) |
| 하이브리드 | 속도 + 정확성 | 설계 복잡도 증가 | 대부분의 프로덕션 에이전트 |
Claude Code가 이 하이브리드 모델의 대표 사례다:
"Claude Code는 하이브리드 모델을 사용한다: CLAUDE.md 파일은 컨텍스트에 사전 로딩되고,
glob과grep같은 프리미티브로 환경을 탐색하여 파일을 Just-in-Time으로 가져온다 — 스테일 인덱싱과 복잡한 구문 트리 문제를 효과적으로 우회한다."
냉장고 비유: 매일 쓰는 기본 재료(계란, 우유, 밥)는 냉장고에 항상 두고, 특별한 재료는 그날 요리에 맞춰 장을 보러 간다. 모든 것을 미리 사놓으면 상하고, 매번 마트에 가면 너무 느리다.
Anthropic의 미래 방향에 대한 조언:
"모델 능력이 향상됨에 따라, 에이전트 설계는 지능적인 모델이 지능적으로 행동하도록 허용하는 방향으로 트렌드가 갈 것이며, 점진적으로 인간의 큐레이션이 줄어들 것이다."
그리고 실용적인 한마디:
"가장 단순한 것부터 시작하라 (Do the simplest thing that works)."
에이전트가 수십 분, 수 시간에 걸쳐 작업해야 할 때, 토큰 수는 컨텍스트 윈도우의 한계를 넘어간다. Anthropic은 이를 위한 세 가지 핵심 기법을 제시한다.
Anthropic의 설명:
"컴팩션은 컨텍스트 윈도우의 내용을 높은 충실도로 증류하여, 에이전트가 최소한의 성능 저하로 계속 작업할 수 있게 한다."
Claude Code는 컨텍스트 사용률이 95%에 도달하면 자동으로 컴팩션을 수행한다:
냉장고 비유: 냉장고가 꽉 찼을 때, 식재료를 전부 버리는 게 아니라 밑반찬으로 만들어서 더 작은 용기에 정리하는 것이다. 핵심 맛은 보존하면서 부피를 줄인다.
Anthropic의 컴팩션 설계 조언은 정밀하다:
"리콜(recall)을 극대화하는 것부터 시작하라 — 컴팩션 프롬프트가 트레이스에서 관련 정보를 모두 캡처하는지 확인한 뒤, 정밀도(precision)를 개선하여 불필요한 내용을 제거하라."
가장 안전하고 가벼운 형태의 컴팩션은 도구 호출 결과 정리다:
"가장 안전한 경량 컴팩션 형태 중 하나는 도구 결과 정리다 — 메시지 기록 깊숙한 곳에서 한참 전에 호출된 도구의 원시 결과를 에이전트가 다시 볼 이유가 있을까?"
Claude Code가 할일 목록을 만들거나, 커스텀 에이전트가 NOTES.md 파일을 유지하는 것이 이 패턴이다.
그런데 이것의 가장 극적인 사례는 코딩이 아니라 게임에서 나왔다.
Claude가 포켓몬을 플레이한 사례:
Anthropic의 에이전트는 수천 게임 스텝에 걸쳐 정밀한 기록을 유지했다 — "지난 1,234스텝 동안 1번 도로에서 포켓몬을 훈련시키는 중, 피카츄가 목표 10레벨 중 8레벨을 올림."
놀라운 것은 다음이다:
"어떤 메모리 구조에 대한 프롬프팅도 없이, 에이전트는 스스로 탐사한 지역의 지도를 개발하고, 어떤 핵심 성취를 달성했는지 기억하고, 어떤 공격이 어떤 상대에게 효과적인지 전략 메모를 유지했다."
컨텍스트 리셋 이후에도 에이전트는 자기 자신의 메모를 읽고 다시간 훈련 시퀀스나 던전 탐험을 이어나갔다. 이것은 모든 정보를 컨텍스트 윈도우 안에 유지하는 것만으로는 불가능한 장시간 전략이다.
냉장고 비유: 냉장고 문에 메모를 붙이는 것이다. "토마토 소스 만든 날짜: 4/5", "닭가슴살 해동 시작: 4/6 저녁", "이번 주 식단: 월-한식, 화-양식". 냉장고 안의 재료(컨텍스트)가 바뀌어도, 메모(노트)는 남아서 일관성을 유지한다.
Anthropic의 설명:
"메인 에이전트는 상위 수준의 계획으로 조율하고, 서브에이전트는 깊은 기술 작업을 수행하거나 도구를 사용하여 관련 정보를 찾는다. 각 서브에이전트는 수만 토큰 이상을 광범위하게 탐색할 수 있지만, 압축된 요약(보통 1,000-2,000 토큰)만 반환한다."
이 구조의 핵심 장점은 관심사의 분리다:
Anthropic의 멀티에이전트 리서치 시스템은 이 패턴으로 단일 에이전트 대비 상당한 성능 향상을 달성했다.
냉장고 비유: 큰 레스토랑에서는 한 명의 셰프가 모든 걸 하지 않는다. 수셰프(souce), 그릴 담당, 디저트 담당이 각자의 깨끗한 작업대에서 자기 요리를 완성하고, 헤드 셰프는 전체 코스를 조율한다. 각 담당자의 복잡한 작업 과정은 격리되고, 결과물(완성된 접시)만 헤드 셰프에게 전달된다.
Anthropic은 태스크 특성에 따른 선택 가이드를 제시한다:
| 기법 | 최적 상황 | 핵심 특성 |
|---|---|---|
| 컴팩션 | 광범위한 대화가 필요한 태스크 | 대화 흐름 유지에 강점 |
| 구조화된 노트 | 명확한 마일스톤이 있는 반복 개발 | 진행 상황 추적에 탁월 |
| 서브에이전트 | 병렬 탐색이 가치 있는 복잡한 리서치/분석 | 관심사 분리, 높은 토큰 효율 |
AI 에이전트 플랫폼 Manus는 프레임워크를 4번이나 재구축하면서 컨텍스트 엔지니어링의 교훈을 얻었다.
KV-캐시 최적화가 가장 중요한 성능 레버다. Claude Sonnet 기준, 캐시된 입력 토큰은 $0.30/MTok이고 캐시되지 않은 토큰은 $3.00/MTok이다 — 10배 차이.
Manus가 발견한 3가지 핵심 원칙:
원칙 1: 에러를 남겨라. 실패한 행동과 스택 트레이스를 컨텍스트에 유지하면, 모델이 암묵적으로 신념을 업데이트하고 같은 실수를 반복하지 않는다. 냉장고에 "이 재료 유통기한 지남!" 스티커를 붙이는 것과 같다.
원칙 2: 주의력 조작 (Attention Manipulation).
todo.md 파일을 만들고 매 턴 업데이트하면 목표가 모델의 최근 주의 영역에 들어간다. 50번의 도구 호출에 걸친 "미들에서 잃어버림(lost-in-the-middle)" 현상을 방지한다.
원칙 3: 컨텍스트 다양성. 직렬화 템플릿과 문구에 작은 구조적 변화를 두면 반복 작업에서 패턴 모방과 환각을 방지한다.
Claude Code는 Anthropic이 직접 만든 코딩 에이전트로, 컨텍스트 엔지니어링의 모범 사례가 집약되어 있다:
컨텍스트 엔지니어링의 실전 효과를 보여주는 데이터:
LangChain은 컨텍스트 엔지니어링을 4가지 전략으로 체계화했다. 컨텍스트 윈도우를 컴퓨터의 RAM에, 컨텍스트 엔지니어를 운영 체제에 비유한 프레임워크다.
에이전트가 중요한 정보를 컨텍스트 윈도우 밖에 저장하는 전략. 세 가지 층위가 있다:
필요한 순간에 적합한 정보를 컨텍스트에 가져오는 전략. RAG가 가장 대표적이지만, 최신 트렌드는 도구 정의에도 RAG를 적용하는 것이다 — 모든 도구를 사전 로딩하지 않고, 현재 태스크에 관련된 도구만 검색하여 로딩.
Claude Code의 ToolSearch가 바로 이 전략의 구현이다. 수십 개의 도구 정의를 전부 컨텍스트에 넣지 않고, 필요할 때 관련 도구만 검색해서 로딩한다.
컨텍스트에서 불필요한 토큰을 제거하는 전략. 세 가지 방법:
컨텍스트를 독립적인 처리 단위로 분리하는 전략. 서브에이전트 아키텍처가 대표적이며, 각 서브에이전트는 자기만의 깨끗한 컨텍스트를 가진다.
냉장고 비유로 4가지 전략을 한 번에 정리하면:
2024년 11월 Anthropic이 공개한 Model Context Protocol(MCP)은 이제 사실상의 산업 표준이 됐다. 2026년 3월 기준 월간 SDK 다운로드 9,700만 회를 돌파했고, OpenAI, Google, Microsoft 모두 지원한다.
MCP가 해결한 문제는 간단하다: AI가 외부 도구·데이터와 연결되는 방식의 표준화. 각 AI 회사가 각 도구 회사와 개별 통합을 하는 N×M 문제를 N+M으로 줄인 것이다.
이것은 USB-C가 충전 케이블을 통일한 것과 같다. MCP는 컨텍스트 엔지니어링에서 "외부 정보를 어떻게 가져올 것인가"에 대한 표준 답안이다.
2026년 4월 현재, 컨텍스트 엔지니어링은 더 이상 첨단 연구 주제가 아니다. 이미 모든 주요 AI 제품에 내장되어 있다:
| 제품/프레임워크 | 컨텍스트 엔지니어링 적용 방식 |
|---|---|
| Claude Code | CLAUDE.md 사전 로딩 + JIT 탐색 + 자동 컴팩션 + 서브에이전트 + 메모리 도구 |
| Cursor / Windsurf | 코드베이스 인덱싱 + 관련 파일 자동 선택 + 대화 컴팩션 |
| ChatGPT Memory | 대화 간 장기 메모리 + 사용자 선호 Write 전략 |
| Vercel AI SDK | 도구 기반 JIT 데이터 로딩 + 스트리밍 컨텍스트 관리 |
| LangChain / LangGraph | 4가지 전략(Write/Select/Compress/Isolate) 프레임워크화 |
Anthropic의 결론은 명확하다:
"모델이 개선됨에 따라 더 적은 규범적(prescriptive) 엔지니어링이 필요해지겠지만, 컨텍스트를 소중하고 유한한 자원으로 다루는 것은 신뢰할 수 있는 에이전트 구축의 핵심으로 남을 것이다."
이것은 웹 개발의 역사와 닮았다. 인터넷 속도가 빨라지고 브라우저가 강력해져도, 프론트엔드 성능 최적화는 여전히 중요하다. 네트워크 대역폭이 아무리 커져도 불필요한 리소스를 전부 보내는 것은 비효율적이다. 마찬가지로, 컨텍스트 윈도우가 아무리 커져도 주의력 예산의 물리적 제약은 사라지지 않는다.
Anthropic은 팀들에게 간결하면서도 실용적인 로드맵을 제시한다:
프롬프트 엔지니어링이 "한 줄의 마법"을 찾는 기술이었다면, 컨텍스트 엔지니어링은 "AI가 주연인 영화의 시나리오 전체를 쓰는 기술"이다.
무대 세트를 어떻게 배치할 것인가. 어떤 소품이 필요한가. 배우에게 어떤 사전 지식을 줄 것인가. 즉흥연기는 어디까지 허용할 것인가. 대본이 너무 길어지면 어떻게 요약할 것인가.
Anthropic의 마지막 메시지가 모든 것을 요약한다:
"컨텍스트 엔지니어링은 우리가 LLM으로 구축하는 방식의 근본적인 전환을 나타낸다. 모델이 더 유능해질수록, 도전은 단지 완벽한 프롬프트를 만드는 것이 아니라 — 각 단계에서 모델의 제한된 주의력 예산에 어떤 정보가 들어갈지를 사려 깊게 큐레이션하는 것이다."
2026년, AI 에이전트의 시대를 이끄는 핵심 역량은 더 이상 "어떤 프롬프트를 쓰느냐"가 아니다.
"이 순간, 이 모델에게, 어떤 정보의 구성을 보여줄 것인가."
이것이 컨텍스트 엔지니어링이다.