#Transformer
9개의 포스트

Depth Separation 특집: 왜 '넓고 얕은' AI보다 '좁고 깊은' AI가 압도적으로 효율적인가
종이 한 장을 42번 접으면 달에 닿는다. 신경망도 마찬가지다 — 뉴런을 '옆으로 늘리는' 대신 '위로 쌓으면' 지수적으로 효율적이다. 1989년 보편 근사 정리가 약속한 '무한한 가능성'의 이면에 숨겨진 비용, 그리고 2016년 수학자들이 증명한 '깊이의 압도적 승리'까지. ResNet에서 Transformer, LoRA까지 — 현대 AI의 모든 혁신이 깊이에 빚지고 있는 이유를 파헤친다.

Transformer와 Depth Separation: 96개 층이 만드는 '생각의 깊이' — 왜 Transformer는 깊어야 똑똑한가
GPT-1은 12층, GPT-3는 96층이다. 층수가 8배 늘자, 모델은 '텍스트 생성기'에서 '범용 추론 엔진'으로 변신했다. 이 질적 도약은 왜 일어났는가? Transformer의 각 층이 어떤 역할을 하는지 — 초기 층의 문법 감지부터 깊은 층의 논리 추론까지 — 를 추적하고, 이 계층적 구조가 LoRA의 효율과 Mixture of Depths의 혁신을 어떻게 가능케 했는지를 파헤친다.
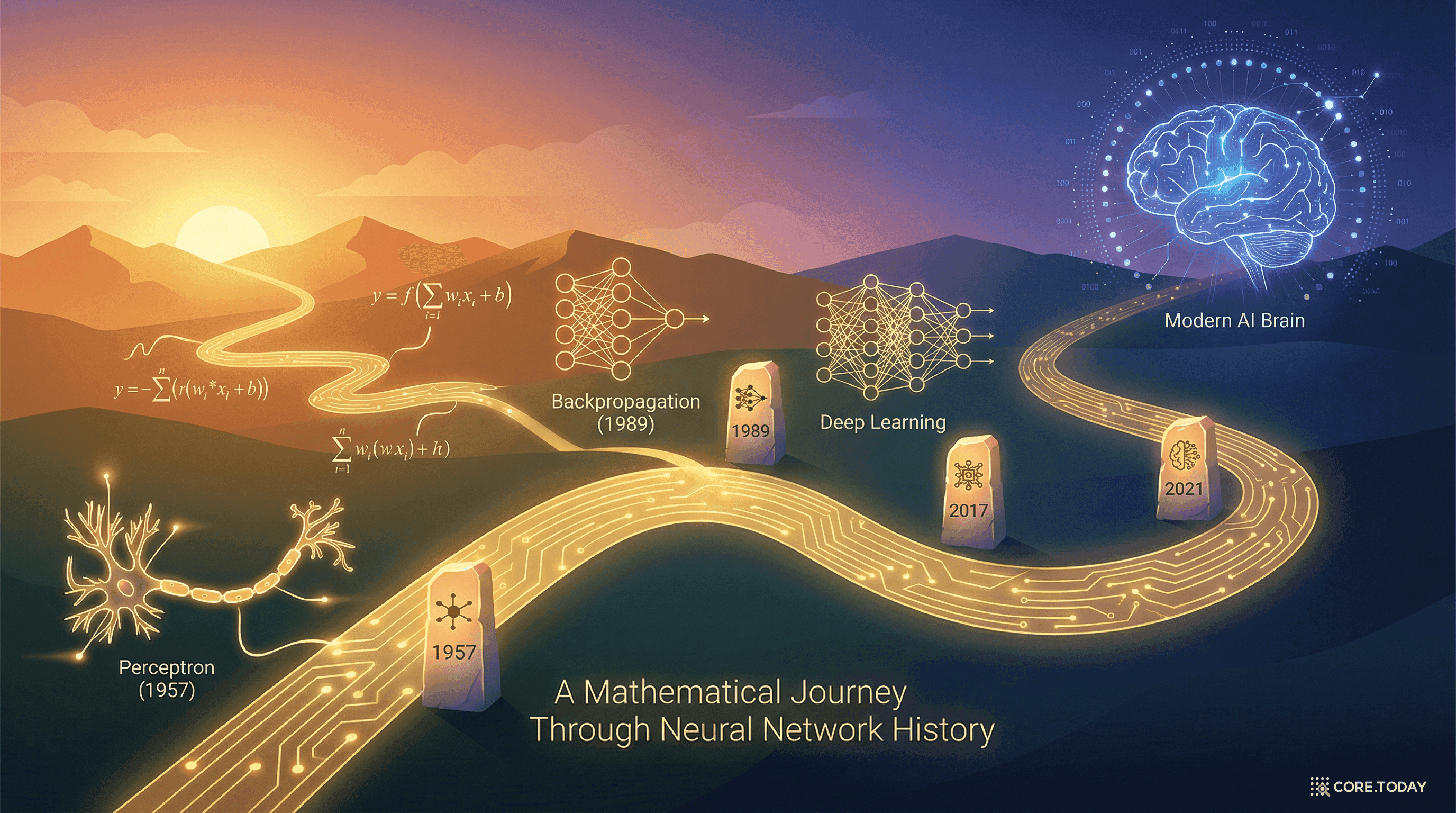
UAT에서 LoRA까지: 신경망이 세상을 배우는 수학적 여정
1989년, 한 수학 정리가 증명했다 — 뉴런이 충분하면 어떤 함수든 흉내 낼 수 있다. 이 '보편 근사 정리'에서 출발하여, 깊이의 혁명, Transformer, 스케일링 법칙을 거쳐 LoRA까지 — 신경망이 세상의 모든 것을 배우는 수학적 여정을 따라간다.

X의 'For You' 피드는 어떻게 당신의 마음을 읽을까 — 오픈소스로 공개된 추천 알고리즘 완전 해부
X(구 트위터)가 오픈소스로 공개한 'For You' 피드 추천 알고리즘을 완전 해부합니다. Grok 기반 Transformer, Two-Tower 검색, Candidate Isolation까지 — 5억 개 트윗에서 당신의 피드를 만드는 기술의 모든 것.

Mamba SSM 완전 정복: Transformer의 왕좌를 위협하는 '선택적 기억'의 혁명
Transformer가 AI의 전부인 줄 알았다. 그런데 '모든 토큰을 다 기억하는 것'이 정말 최선일까? 제어 이론에서 출발한 상태 공간 모델이 '선택적 기억'이라는 무기로 AI의 판도를 바꾸고 있다.

Transformer 특집: 순서를 기억하는 기계에서 모든 것을 한눈에 보는 기계로
RNN의 순차 처리 한계에서 Attention의 탄생, 그리고 'Attention Is All You Need' 한 편의 논문이 GPT, BERT, 오늘의 LLM 시대 전부를 만들어낸 이야기를 수식과 사례로 풀어본다.

금융 시계열의 데이터 부족을 GAN으로 해결한다 — Transformer 기반 합성 데이터 증강의 모든 것
금융 시장 데이터는 본질적으로 부족하고 변동이 크다. 바르샤바 공대 연구팀이 Transformer 기반 GAN으로 합성 금융 데이터를 생성해 LSTM 예측 정확도를 유의미하게 향상시킨 논문을 완전 해부한다.

FlashAttention 해부: 박사과정 학생이 만든 커널이 AI 산업 전체를 바꿨다
GPT-3의 컨텍스트가 2K에 머물렀던 이유? 어텐션이 O(N²) 메모리를 잡아먹었기 때문이다. 한 박사과정 학생이 GPU 메모리 계층을 이해하고, 수학은 그대로 두되 메모리 접근만 바꿔서 2~4배 빠르고 10~20배 적은 메모리를 달성했다. 정확도 손실 0%.

Gradient Clipping 완전 해부: 딥러닝의 안전벨트는 어떻게 탄생했는가
1991년, 독일어로 쓴 석사 논문 하나가 딥러닝의 근본 문제를 발견했다. 기울기가 폭발하거나 소멸한다. 22년 뒤, 세 명의 연구자가 해법을 제시했다 — Gradient Clipping. GPT-3부터 LLaMA까지, 모든 대형 모델의 훈련에 쓰이는 이 기법의 역사와 원리를 처음부터 파헤친다.