TransformerDepth Separation깊이Self-AttentionLoRAResidual StreamMixture of Depths
Transformer와 Depth Separation: 96개 층이 만드는 '생각의 깊이' — 왜 Transformer는 깊어야 똑똑한가
GPT-1은 12층, GPT-3는 96층이다. 층수가 8배 늘자, 모델은 '텍스트 생성기'에서 '범용 추론 엔진'으로 변신했다. 이 질적 도약은 왜 일어났는가? Transformer의 각 층이 어떤 역할을 하는지 — 초기 층의 문법 감지부터 깊은 층의 논리 추론까지 — 를 추적하고, 이 계층적 구조가 LoRA의 효율과 Mixture of Depths의 혁신을 어떻게 가능케 했는지를 파헤친다.
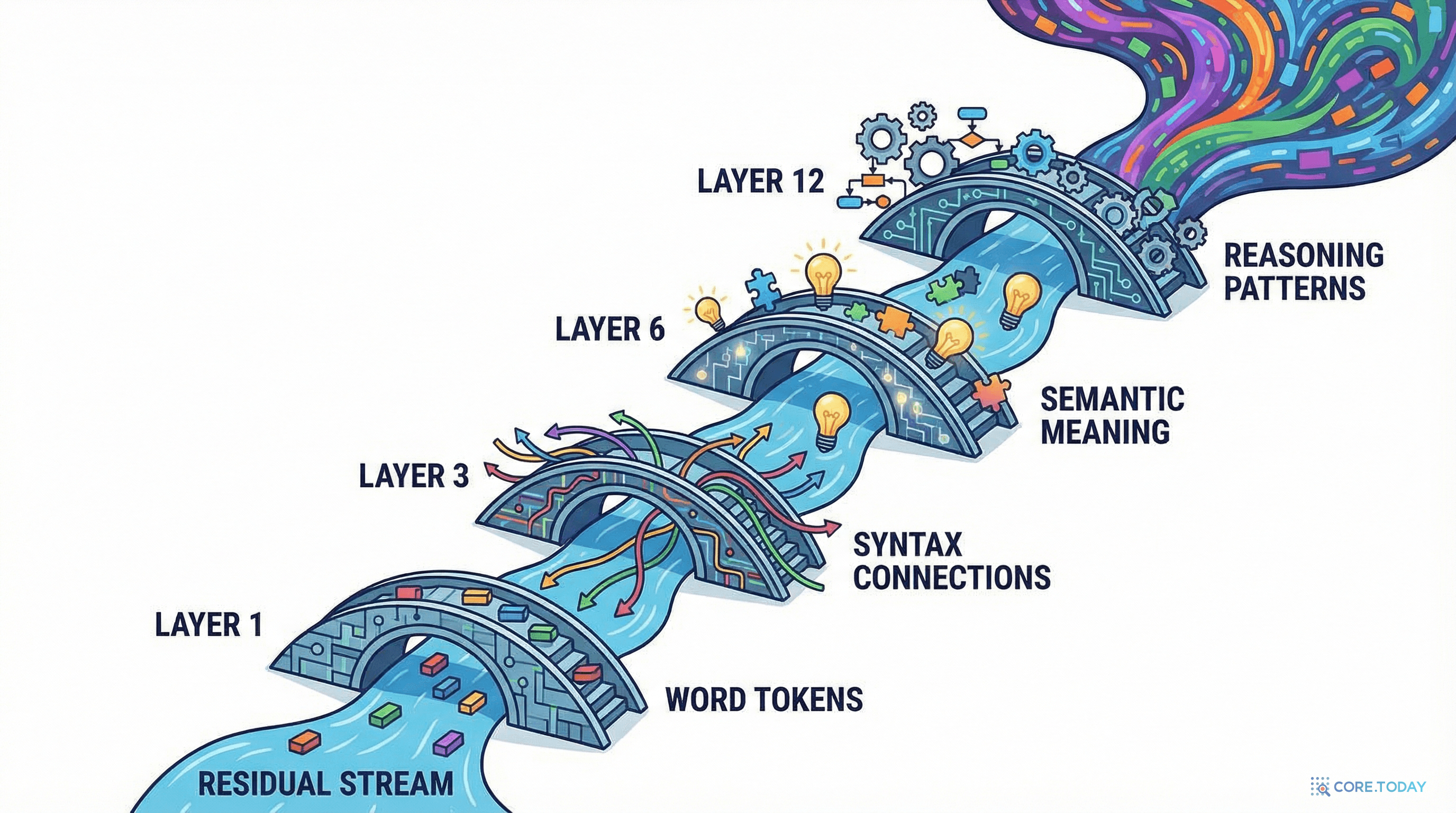
GPT-3는 입력 텍스트를 96번 다시 읽는다. 매번 같은 텍스트를 보지만, 매번 다른 수준의 이해를 추출한다. 1번째 층은 "이 토큰은 명사다"를 파악하고, 30번째 층은 "이 문장의 주어와 동사가 누구인지"를 추론하며, 90번째 층은 "이 질문에 대한 답은 무엇인지"를 결정한다.
이것이 Transformer에서의 depth separation이다. 단순히 "층이 많다"가 아니라, 각 층이 질적으로 다른 역할을 수행하면서 — 문법에서 의미로, 의미에서 추론으로 — 점진적으로 더 깊은 이해에 도달하는 구조.
GPT-1은 12층이었다. 텍스트를 생성할 수 있었지만, "이해한다"고 보기 어려웠다. GPT-3는 96층이 되면서 few-shot learning — 예시 몇 개만 보고 새로운 과제를 수행하는 능력 — 을 획득했다. 층수가 8배 늘어난 것만으로, 모델은 "텍스트 생성기"에서 "범용 추론 엔진"으로 질적 변신을 했다.
이 글에서는 이 질적 도약의 비밀을 해부한다. Transformer의 각 층이 구체적으로 무엇을 하는지, 왜 깊이가 추론 능력과 직결되는지, 그리고 이 이해가 LoRA부터 Mixture of Depths까지 현대 AI의 핵심 혁신들을 어떻게 가능케 했는지를.
1부: Attention 이전 — 왜 "깊이"가 불가능했는가
RNN의 근본적 한계: 순차적 병목
Transformer 이전의 세계를 잠깐 돌아보자.
2014년까지, 시퀀스 처리의 지배적 패러다임은 RNN(Recurrent Neural Network) 과 그 변형인 LSTM, GRU였다. 이들의 작동 방식은 본질적으로 순차적이었다.
t=1
"나는" 처리 → 은닉 상태 h₁
t=2
"오늘" 처리 → h₁을 참고해 h₂ 생성
t=3
"학교에" 처리 → h₂를 참고해 h₃ 생성
t=4
"갔다" 처리 → h₃를 참고해 h₄ 생성
각 시점의 은닉 상태 ht는 이전 시점의 ht−1에만 의존한다. 마치 전화 게임과 같다 — 첫 번째 사람의 메시지가 마지막 사람에게 도달할 때쯤이면 원래 의미가 희석되거나 왜곡된다.
이것이 장거리 의존성(long-range dependency) 문제다. "나는 파리에서 태어나서 프랑스어를 유창하게 ___"라는 문장에서, 빈칸을 채우려면 멀리 떨어진 "파리에서 태어나서"를 기억해야 한다. 하지만 RNN에서 이 정보는 수십 개의 ht를 거치면서 점점 희미해진다.
LSTM과 GRU가 이 문제를 완화했지만, 근본적 한계가 있었다. 깊이를 쌓기 어려웠다. RNN을 2~3층으로 쌓는 것은 가능했지만, 10층, 20층, 100층으로 깊게 쌓으면 학습이 극도로 불안정해졌다. 순차적 구조 자체가 기울기 흐름을 방해했기 때문이다.
⚠️
RNN의 이중 병목
시간 축 병목: 먼 과거의 정보가 은닉 상태 전달 중 희석 깊이 축 병목: 층을 쌓으면 기울기 소실이 더 심해져 학습 불가
결과: RNN 기반 모델은 대부분 2~4층에 머물렀다
depth separation 이론이 말해주는 것은 명확하다: 깊이가 지수적 효율을 제공한다. 하지만 RNN은 그 깊이를 물리적으로 확보할 수 없었다. 이것이 Transformer 이전 시대의 근본적 딜레마였다.
Bahdanau Attention (2014): 첫 번째 돌파구
Dzmitry Bahdanau 등(2014)이 제안한 attention 메커니즘은 시간 축 병목을 해결했다. 디코더가 매 시점 인코더의 모든 은닉 상태를 직접 참조할 수 있게 한 것이다. 전화 게임 대신, 모든 참가자가 원본 메시지를 직접 볼 수 있게 된 셈이다.
하지만 attention을 추가해도 RNN의 순차적 구조는 그대로였다. 깊이 축 병목은 해결되지 않았다. 진정한 혁명은 순차적 구조 자체를 버리는 것에서 시작되었다.
2부: "Attention Is All You Need" — 깊이의 고속도로를 열다
2017년, 구조적 혁명
2017년 6월, Ashish Vaswani 등 8명의 Google 연구자가 "Attention Is All You Need"를 발표했다. 이 논문의 핵심 메시지는 제목 그대로다: Attention만으로 충분하다. RNN은 필요 없다.
Transformer의 핵심 구조:
Self-Attention
모든 토큰이 다른 모든 토큰을 직접 참조 — "누구와 관련 있지?"
Feed-Forward Network
각 토큰의 표현을 비선형 변환 — "이 정보로 무엇을 계산하지?"
Residual Connection + LayerNorm
입력을 출력에 직접 더하고 정규화 — "기존 정보를 유지하면서 새 정보 추가"
이 세 요소의 조합이 하나의 Transformer 블록이다. 이 블록을 N번 쌓으면 N-층 Transformer가 된다.
왜 Transformer는 "깊이의 고속도로"인가?
Transformer가 RNN과 근본적으로 다른 점은 깊이를 쌓는 것이 자연스럽다는 것이다. 세 가지 구조적 특성이 이를 가능하게 한다.
1. 잔차 연결(Residual Connection)
ResNet에서 영감받은 이 구조는 각 블록의 입력을 출력에 직접 더한다:
output=Block(x)+x
기울기가 잔차 연결을 통해 "지름길"로 흐를 수 있으므로, 96층을 쌓아도 학습이 안정적이다. RNN에서는 이것이 불가능했다 — 시간 축의 순차 의존성이 잔차 연결의 효과를 상쇄했기 때문이다.
2. Self-Attention의 병렬성
RNN은 t 시점을 처리하려면 t−1 시점의 결과가 필요하다. Transformer의 self-attention은 모든 토큰을 동시에 처리한다. 이 병렬성 덕분에 GPU를 최대한 활용하여 깊은 모델을 효율적으로 학습할 수 있다.
3. LayerNorm의 안정화
각 층의 출력을 정규화하여 활성화 값의 크기를 일정하게 유지한다. 이것이 없으면 깊은 네트워크에서 활성화 값이 폭발하거나 소실된다.
특성
RNN/LSTM
Transformer
일반적 깊이
2~4층
12~96층+
깊이 스케일링
극히 어려움
자연스러움
기울기 흐름
시간축+깊이축 이중 소실
잔차 연결로 안정적
병렬 학습
불가 (순차적)
완전 병렬
Depth separation 활용
제한적
최대한 활용
Transformer는 depth separation의 이론적 이점을 실제로 구현할 수 있는 최초의 시퀀스 아키텍처였다. RNN 시대에는 "깊이가 좋다"는 것을 알아도 쓸 수 없었다. Transformer가 그 벽을 무너뜨렸다.
3부: Residual Stream 가설 — Transformer 내부의 "정보 고속도로"
2021년, Chris Olah 등 Anthropic 연구자들은 Transformer의 내부 작동을 이해하기 위한 강력한 프레임워크를 제안했다. Residual Stream(잔차 스트림) 가설이다.
핵심 아이디어: Transformer를 "96개의 독립적인 층"으로 보는 대신, 하나의 연속적인 정보 스트림으로 보자. 이 스트림은 입력 임베딩에서 시작하여 모든 층을 관통하며 흐른다. 각 층은 이 스트림에서 정보를 읽고(read), 계산을 수행한 뒤, 결과를 스트림에 쓴다(write).
입력 임베딩 초기 스트림
→
Layer 1 읽기 → 계산 → 쓰기
→
Layer 2 읽기 → 계산 → 쓰기
→
… Layer N 최종 출력
수식으로 표현하면:
xl+1=xl+Attnl(xl)+FFNl(xl+Attnl(xl))
xl이 잔차 스트림이다. 각 층은 이 스트림에 덧셈으로 정보를 추가한다. 이것은 근본적으로 중요한 관점의 전환이다.
왜 이 관점이 depth separation에 중요한가?
잔차 스트림 관점에서 보면, Transformer의 깊이는 정보를 점진적으로 정제하는 과정이다. 강물이 여러 정수 시설을 거치면서 점점 깨끗해지는 것처럼, 토큰의 표현이 여러 층을 거치면서 점점 풍부하고 정확해진다.
얕은 Transformer는 이 정제 과정이 짧다. "물을 한 번만 거르는" 것과 같다. 깊은 Transformer는 96단계의 정제를 거친다. 그리고 depth separation 이론이 말해주듯, 이 반복적 정제의 효과는 지수적이다.
잔차 스트림의 비유: 와인 제조
포도(입력 임베딩)에서 출발
→ Layer 1~10: 세척, 파쇄, 압착 — 원재료를 분리하고 기본 성분을 추출
→ Layer 11~40: 1차 발효, 정제 — 복잡한 풍미가 형성되기 시작
→ Layer 41~80: 숙성, 블렌딩 — 깊은 풍미와 균형이 발달
→ Layer 81~96: 최종 결정, 병입 — 최종 품질 결정
각 단계를 건너뛸 수는 없다. 포도에서 바로 숙성 와인을 만들 수 없듯, 초기 층 없이 깊은 층의 추론도 불가능하다.
Transformer의 각 층이 실제로 무엇을 학습하는지는 어떻게 알 수 있을까? 프로빙(probing) 이라는 기법이 있다. 각 층의 은닉 상태 위에 간단한 분류기를 올려놓고, "이 층은 품사를 구분할 수 있는가?", "이 층은 주어-동사 관계를 알고 있는가?"를 테스트하는 것이다.
수많은 프로빙 연구들이 일관되게 보여주는 패턴이 있다.
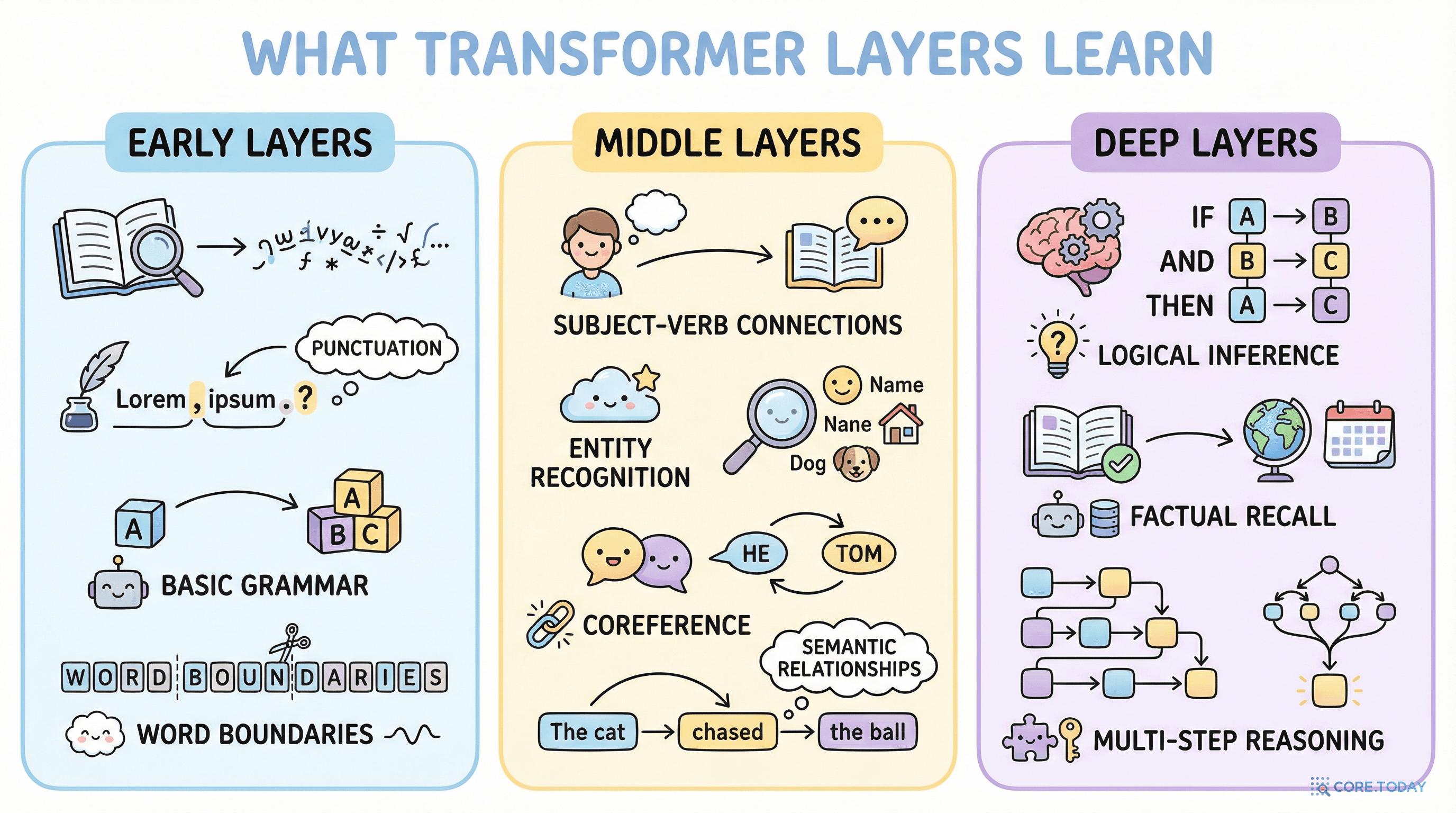
초기 층 (Layer 1~3): 토큰과 문법의 세계
Tenney et al. (2019), "BERT Rediscovers the Classical NLP Pipeline"은 BERT의 12개 층을 체계적으로 분석한 획기적 연구다.
발견: 초기 층은 전통적인 NLP의 초기 단계를 재발견한다.
Layer 1: 토큰의 정체(identity) — "이 토큰이 무엇인지"를 표현. 비슷한 토큰끼리 가까운 벡터를 가짐
Layer 2: 품사 태깅(POS tagging) — 명사, 동사, 형용사 등의 문법적 역할 구분
Layer 3: 구문 구조(constituency parsing) — 어떤 단어들이 하나의 구(phrase)를 이루는지
BERT 각 층의 품사 태깅 정확도 (Tenney et al., 2019)
Layer 0 (임베딩)
85%
Layer 1
94%
Layer 2
96%최고
Layer 6
94%
Layer 12
91%
흥미로운 점: 품사 정보는 Layer 2에서 최고에 달하고, 이후 층에서는 오히려 약간 감소한다. 이는 깊은 층이 품사 같은 "저수준 정보"를 버리고 더 추상적인 정보에 집중하기 때문이다. 각 층이 자신의 역할을 가지고 있다는 depth separation의 실증이다.
중간 층 (Layer 4~8): 의미와 관계의 세계
중간 층에서 일어나는 일은 훨씬 더 흥미롭다.
Jawahar et al. (2019), "What Does BERT Look At?"에 따르면:
Layer 5~7: 의미역 표지(semantic role labeling) — "누가 무엇을 누구에게 했는가?"
Layer 6~8: 상호참조 해결(coreference resolution) — "이 '그'는 앞의 '철수'를 가리킨다"
Layer 1~3 문법 "이건 명사야"
→
Layer 4~5 구조 "주어-동사 관계"
→
Layer 6~8 의미 "'그'는 '철수'다"
→
Layer 9~12 추론 "답은 B다"
이것은 CNN의 계층적 특징 학습과 정확히 평행하다. CNN에서 초기 층이 엣지를, 중간 층이 텍스처를, 깊은 층이 객체를 학습하는 것처럼, Transformer에서 초기 층은 문법을, 중간 층은 의미를, 깊은 층은 추론을 학습한다.
깊은 층 (Layer 9~12+): 추론과 과제 수행의 세계
깊은 층에서 벌어지는 일은 가장 신비롭고, 가장 중요하다.
Geva et al. (2021), "Transformer Feed-Forward Layers Are Key-Value Memories"는 혁명적인 발견을 했다. Transformer의 FFN(Feed-Forward Network) 층이 키-값 메모리처럼 작동한다는 것이다.
구체적으로: FFN의 첫 번째 행렬(W1)이 "키(key)"로 작동하여 특정 패턴을 감지하고, 두 번째 행렬(W2)이 "값(value)"으로 작동하여 해당 패턴에 대한 정보를 출력한다. 깊은 층의 FFN은 다음과 같은 것들을 저장하고 검색한다:
사실 지식: "파리는 프랑스의 수도다"
의미 관계: "의사-병원" 같은 연관
추론 패턴: "A이면 B이고, B이면 C이므로, A이면 C다"
🧠
깊은 층 = 세계 지식 + 추론 엔진
초기 층이 "문장을 이해하는 능력"을 제공한다면, 깊은 층은 "세계에 대한 지식"과 "그 지식을 사용한 추론"을 제공한다. 층을 제거하는 실험(layer ablation)에서 초기 층을 제거하면 문법이 무너지고, 깊은 층을 제거하면 사실 관계와 추론 능력이 사라진다.
12층 vs 96층: 질적 차이의 비밀
왜 12층 모델(GPT-1, BERT)은 "이해"에 그치고, 96층 모델(GPT-3)은 "추론"까지 가능한가?
12층 모델에서는 문법(1~3층) + 의미(4~8층) + 과제 수행(9~12층)이 각각 3~4층씩만 할당된다. 각 영역에 주어진 "연산 예산"이 빠듯하다.
96층 모델에서는 이 구조가 8배로 확장된다. 문법 영역에 8~12층, 의미 영역에 20~30층, 그리고 추론 영역에 50층 이상이 할당된다. depth separation 이론에 따르면, 이 추가 층들의 효과는 선형이 아니라 지수적이다.
능력
12층 (GPT-1)
96층 (GPT-3)
문법 이해
우수
우수
의미 이해
양호
탁월
사실 기반 질의응답
제한적
강력
논리 추론
불가능에 가까움
가능
Few-shot Learning
불가
가능 (질적 도약!)
In-context Learning
불가
강력
Few-shot learning과 in-context learning은 "충분한 깊이"가 있을 때만 나타나는 창발적 능력(emergent ability)이다. 이것이 Transformer에서의 depth separation의 가장 극적인 실증이다.
5부: 수학적 근거 — Transformer의 Depth Separation 이론
표현력의 형식적 한계
Transformer의 깊이와 표현력의 관계는 2020년대 들어 활발하게 연구되고 있다. 핵심 결과들을 살펴보자.
Hahn (2020), "Theoretical Limitations of Self-Attention in Neural Network Models":
고정 깊이의 Transformer는 PARITY 함수(입력의 짝홀 판별)를 계산할 수 없다.
이것은 강력한 부정적 결과다. 아무리 너비(은닉 차원)를 키워도, 깊이가 고정되면 특정 함수를 표현할 수 없다. depth separation의 직접적 증거다.
Merrill & Sabharwal (2023), "The Parallelism Tradeoff: Limitations of Log-Precision Transformers":
정밀도 O(logn)의 O(1)-depth Transformer는 TC⁰ 회로(threshold circuits)와 동일한 표현력을 가진다. 깊이를 늘리면 표현력이 더 강한 회로 클래스에 대응한다.
쉽게 말하면: 얕은 Transformer는 카운팅조차 정확히 할 수 없지만, 깊은 Transformer는 훨씬 복잡한 연산이 가능하다.
합성 과제에서의 깊이 효과
Anil et al. (2022), "Exploring Length Generalization in Large Language Models"는 실험적으로 깊이의 효과를 보였다:
4자리 덧셈: 6~12층이면 충분
8자리 덧셈: 24층+ 필요
16자리 덧셈: 48층+ 필요
자릿수가 2배 늘어날 때마다 필요한 깊이도 대략 2배 늘어난다. 이는 Transformer가 각 "추론 단계"를 1~2개 층에서 처리하고, 더 복잡한 문제는 더 많은 추론 단계 = 더 많은 층을 요구한다는 것을 의미한다.
산술 과제 해결에 필요한 최소 Transformer 깊이
2자리 덧셈
~6층
4자리 덧셈
~12층
8자리 덧셈
~24층
16자리 덧셈
~48층
"생각의 깊이" = 층의 깊이
이 결과들이 시사하는 바는 명확하다:
💡
Transformer 깊이의 본질
Transformer의 각 층은 하나의 "추론 단계"에 대응한다. 문제의 복잡도가 k 단계의 추론을 요구하면, 최소 O(k) 층이 필요하다. 너비(은닉 차원)를 아무리 키워도 이 깊이 요구량을 대체할 수 없다 — 이것이 Transformer에서의 depth separation이다.
LoRA(Low-Rank Adaptation)의 핵심은 파인튜닝 시 각 층의 가중치 변화 ΔW가 저랭크(low-rank) 라는 가정이다. 즉, ΔW≈BA로 분해할 수 있고, B와 A의 랭크 r은 원래 차원 d보다 훨씬 작다.
이 가정이 Transformer에서 특히 잘 맞는 이유는 depth separation과 직접 연결된다:
계층적 분업 → 각 층이 하나의 추상화 수준만 담당 → 가중치가 구조적 → 변화도 구조적(저랭크)
잔차 스트림 → 각 층의 기여가 "덧셈"이므로, 개별 층의 변화가 작아도 전체에 영향 → 작은 ΔW로 충분
깊이가 충분 → 96개 층에 LoRA를 적용하면, 각 층의 미세한 변화가 합쳐져 큰 행동 변화를 만듦
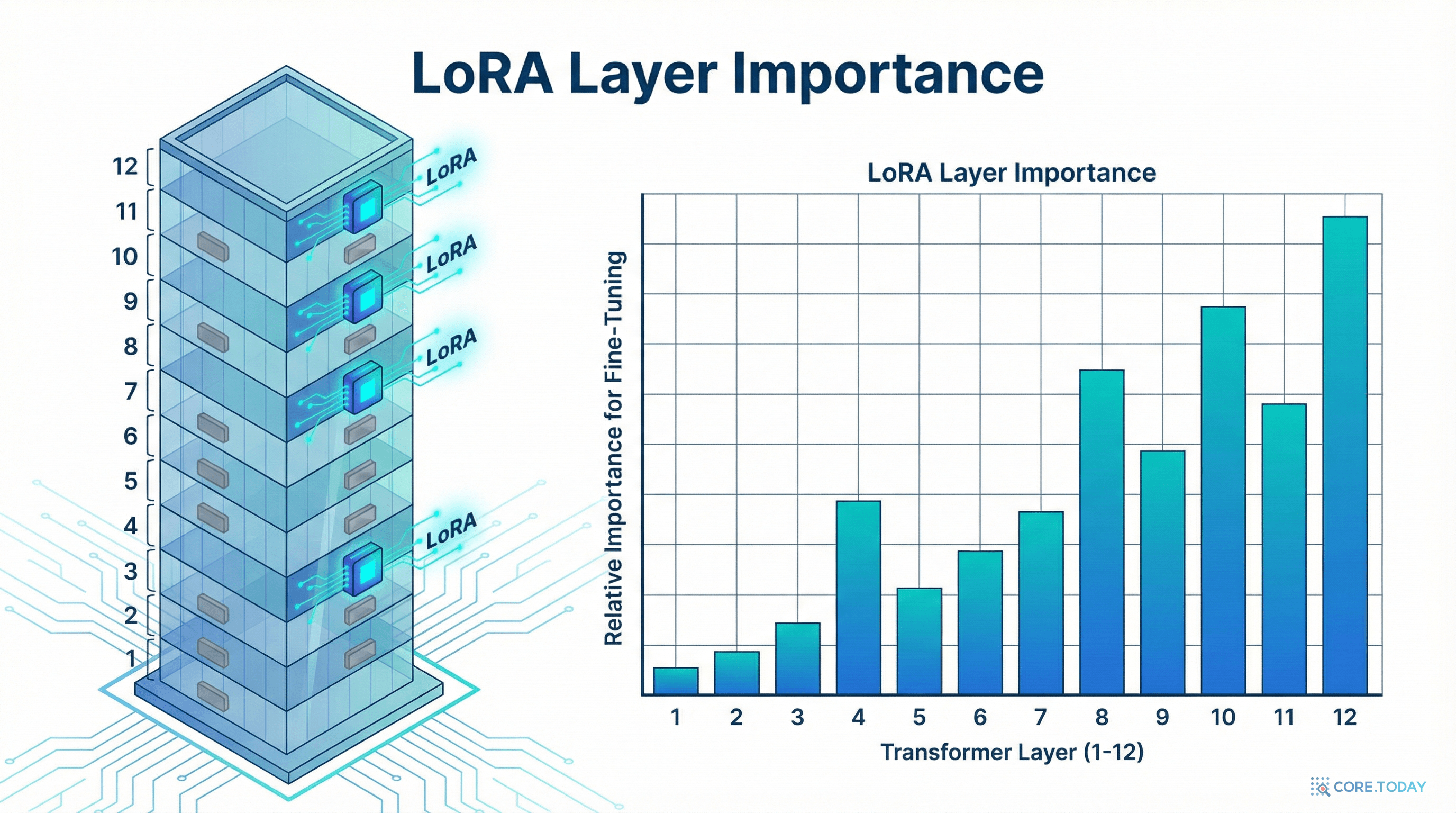
어떤 층이 가장 중요한가?
모든 층이 동등하게 중요하지는 않다. Hu et al. (2022)의 원 LoRA 논문과 후속 연구들이 밝힌 패턴:
LoRA 적용 시 층별 중요도 (GPT-3 기준, 상대적)
Layer 1~24 (초기)
낮음문법 층
Layer 25~48 (중간 전반)
중간의미 층
Layer 49~72 (중간 후반)
높음지식 층
Layer 73~96 (깊은)
매우 높음추론/과제 층
깊은 층이 LoRA에서 가장 중요하다. 왜? 과제 적응(task adaptation)은 주로 "어떤 추론을 수행할 것인가"의 문제이고, 이것은 깊은 층이 담당하기 때문이다. 문법이나 기본 의미 이해는 과제가 바뀌어도 거의 변하지 않지만, 추론 패턴은 과제마다 크게 달라진다.
Layer-wise Rank Allocation: 깊이 이해의 실용적 응용
이 통찰에서 나온 것이 Layer-wise Rank Allocation 기법이다.
균일 LoRA vs 적응적 LoRA
균일 LoRA: 모든 96개 층에 동일한 r=8 적용
→ 총 파라미터: 96 × 2 × d × 8 = 1,536 × d
적응적 LoRA: 초기 층 r=2, 중간 층 r=4, 깊은 층 r=16
→ 총 파라미터: (24×2×d×2) + (48×2×d×4) + (24×2×d×16) = 1,152 × d
→ 파라미터 25% 절감, 성능 동등 또는 향상
depth separation의 이해 없이는 이런 최적화가 불가능하다. "모든 층이 같은 역할을 한다"고 가정하면, 균일 배분이 최선이다. 하지만 "각 층이 다른 수준의 추상화를 담당한다"는 것을 알면, 중요한 층에 더 많은 용량을 할당하는 전략이 가능해진다.
매개변수 효율적 파인튜닝(PEFT)의 미래
LoRA의 성공 이후, depth separation에 기반한 다양한 PEFT 기법이 등장했다:
AdaLoRA (Zhang et al., 2023): 각 층의 중요도를 자동으로 학습하여 랭크를 적응적으로 할당
QLoRA (Dettmers et al., 2023): 4비트 양자화 + LoRA로 메모리를 극단적으로 절약하되, 깊은 층의 정밀도를 더 높게 유지
DoRA (Liu et al., 2024): 가중치를 크기와 방향으로 분해하여 LoRA의 표현력을 향상 — 깊은 층에서 특히 효과적
이 모든 기법의 공통점: Transformer의 층마다 역할이 다르다는 depth separation의 통찰을 활용한다.
2024년, Google DeepMind의 David Raposo 등이 발표한 "Mixture-of-Depths: Dynamically allocating compute in transformer-based language models"는 도발적인 질문을 던졌다.
"the"나 "is" 같은 기능어(function word)도 96개 층을 모두 통과해야 하는가?
답은 아니오였다.
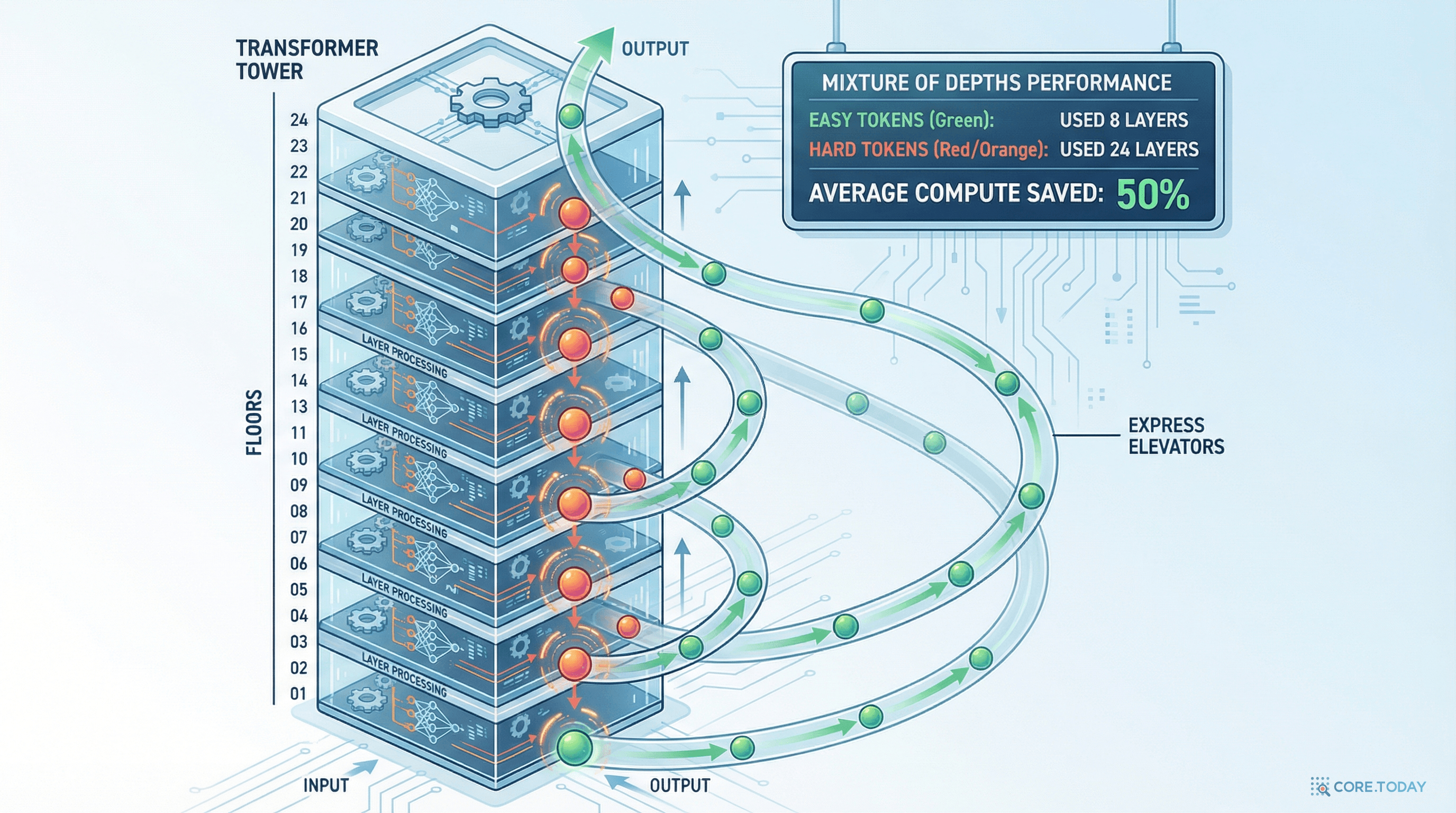
Mixture of Depths (MoD)의 핵심 아이디어
각 층에 라우터(router) 를 추가하여, 토큰이 해당 층을 통과할지 건너뛸지를 결정한다.
1단계
라우터 결정 각 토큰에 대해 "이 층이 필요한가?" 점수 계산
2단계
상위 K개 선택 점수 상위 K개 토큰만 해당 층의 Self-Attention + FFN 통과
3단계
잔차 연결 건너뛴 토큰은 잔차 스트림을 그대로 다음 층으로 전달
결과는 놀라웠다:
모델
FLOPs 사용량
성능 (perplexity)
기본 Transformer (모든 토큰 96층)
100%
기준
MoD (상위 50%만 통과)
~50%
동등
단순히 48층으로 줄임
50%
성능 저하
FLOPs를 절반으로 줄이면서 성능은 유지. 같은 연산량으로 단순히 층을 줄이는 것보다 훨씬 낫다.
MoD가 depth separation을 증명하는 방법
MoD의 성공은 depth separation의 두 가지 핵심 통찰을 동시에 증명한다:
첫째, 깊이는 대체 불가능하다. 48층 모델은 96층 MoD 모델보다 성능이 떨어진다. 단순히 층을 줄이면 안 된다 — 깊이는 필요한 곳에 반드시 존재해야 한다.
둘째, 깊이의 필요량은 입력마다 다르다. "the cat sat on the mat"에서 "the"는 2~3개 층이면 충분하지만, "mat"은 맥락을 고려해야 하므로 더 많은 층이 필요하다. 핵심 토큰에 깊이를 집중 배분하는 것이 균일 배분보다 효율적이다.
MoD: 깊이의 경제학
기존: 모든 학생에게 96시간 수업 (성실한 학생도, 이미 아는 학생도) MoD: 이미 아는 학생은 40시간, 어려워하는 학생은 96시간
→ 총 수업 시간 50% 절감, 학습 성과 동일
핵심: 깊이를 줄이는 게 아니라, 깊이를 필요한 곳에 집중하는 것
8부: Test-Time Compute Scaling — 물리적 깊이를 넘어
추론 시에도 깊이가 중요하다
2024~2025년, AI 연구의 가장 뜨거운 트렌드 중 하나는 테스트 시간 연산 스케일링(test-time compute scaling) 이다. OpenAI의 o1, o3, 그리고 DeepSeek의 R1이 대표적이다.
핵심 아이디어: 모델의 물리적 깊이(층 수)는 고정하되, 추론 시 "사고의 사슬(chain of thought)"을 통해 논리적 깊이를 무한히 늘린다.
생각 1
"이 문제는 삼각형의 넓이를 구하는 거야. 밑변은…"
생각 2
"높이를 구하려면 피타고라스 정리를 써야 해. 빗변이 5, 밑변이 3이니까…"
생각 3
"높이는 4야. 넓이 = 1/2 × 3 × 4 = 6"
각 "생각"은 모델의 96개 층을 한 번 더 통과하는 것이다. 3번의 사고 단계 = 96 × 3 = 288개 층의 유효 깊이. 10번의 사고 단계 = 960개 층의 유효 깊이.
물리적 깊이 vs 논리적 깊이
개념
물리적 깊이
논리적 깊이 (CoT)
무엇인가
모델의 층 수
추론 단계 × 층 수
결정 시점
학습 전 (아키텍처 설계)
추론 시 (문제 난이도에 따라)
상한
고정 (예: 96층)
가변 (이론적으로 무한)
비용
학습 비용에 영향
추론 비용에 영향
depth separation 적용
레이어 간 계층적 분업
추론 단계 간 계층적 분업
이것은 depth separation의 가장 최근, 그리고 가장 흥미로운 확장이다. 기존에는 "더 깊은 모델 = 더 똑똑한 모델"이었다면, 이제는 "더 깊게 생각하는 모델 = 더 똑똑한 모델"이 된 것이다.
그리고 이 논리적 깊이도 depth separation의 원리를 따른다. 수학 올림피아드 문제에서 o3가 사고 단계를 2배로 늘리면, 정답률이 20~30%p 올라가는 것이 관찰된다. 깊이의 지수적 효과가 물리적 층 수를 넘어 추론 단계에서도 작동하는 것이다.
9부: 2026년, Transformer 깊이의 최전선
Transformer 깊이 혁신의 전체 지도
2017
Transformer 탄생 6층 인코더 + 6층 디코더. 잔차 연결로 깊이 스케일링의 문을 열다
2018~19
GPT-1/2, BERT 12~48층. "깊이 = 언어 이해"의 첫 번째 실증
2020
GPT-3 96층. Few-shot learning 출현 — 깊이의 질적 도약
2021~22
LoRA & 프로빙 연구 층별 역할 차이 규명 → 효율적 적응 기법 탄생
2024
MoD & o1 동적 깊이 할당 + 논리적 깊이 확장 — 깊이의 경제학
2026
적응적 깊이, Layer Pruning, Speculative Decoding 깊이의 효율적 활용이 산업의 핵심 경쟁력으로
지금 주목해야 할 세 가지 방향
1. Layer Pruning (층 가지치기)
학습된 Transformer에서 중요하지 않은 층을 제거하여 추론 속도를 높이는 기법. Men et al. (2024) 의 연구에 따르면, LLaMA-2 70B에서 중간 층의 상당수(최대 25%)를 제거해도 성능 저하가 미미했다.
왜 가능한가? depth separation에 의해 각 층의 기여가 균등하지 않기 때문이다. 일부 층은 "이미 해결된 문제를 다시 확인하는" 중복 연산을 수행하며, 이런 층은 안전하게 제거할 수 있다.
2. Speculative Decoding (추측 디코딩)
작은 모델(draft model)이 먼저 빠르게 토큰을 생성하고, 큰 모델(verifier)이 이를 검증하는 기법. 깊이가 다른 두 모델의 협업이다.
이것은 depth separation의 실용적 응용이다. "쉬운 토큰"은 얕은 모델로 충분하고, "어려운 토큰"만 깊은 모델이 처리한다. MoD와 같은 원리의 시스템 수준 구현이라 할 수 있다.
3. Adaptive Depth at Training Time
최신 연구들은 학습 과정 자체에서 깊이를 적응적으로 조절한다. 학습 초기에는 적은 층으로 시작하여 점진적으로 층을 추가하는 progressive growing 기법이나, 학습 중 확률적으로 층을 건너뛰는 stochastic depth 등이 있다.
이런 기법들은 학습 비용을 20~40% 줄이면서 최종 성능은 유지하거나 오히려 향상시킨다. 깊이의 이점을 최대한 활용하면서 비용은 최소화하는, depth separation 이론의 가장 실용적인 귀결이다.
마무리: Transformer는 왜 "깊게 생각하는 기계"인가
이 글에서 추적한 Transformer 깊이의 여정을 정리해보자.
📖
핵심 메시지 5가지
1. Transformer는 깊이의 고속도로를 열었다. 잔차 연결 + self-attention + LayerNorm의 조합이 RNN에서 불가능했던 수십~수백 층의 깊이를 가능케 했다.
2. 각 층은 질적으로 다른 역할을 한다. 초기 층은 문법, 중간 층은 의미, 깊은 층은 추론. 이것이 Transformer에서의 depth separation이다.
3. 깊이가 창발적 능력을 만든다. 12층에서 96층으로의 도약이 few-shot learning과 in-context learning이라는 질적 변화를 가져왔다.
4. LoRA는 depth separation의 부산물이다. 층별 역할 분화가 저랭크 구조를 만들고, 이것이 효율적 적응을 가능케 한다.
5. 깊이의 개념은 확장되고 있다. 물리적 층 수를 넘어 MoD(동적 깊이), CoT(논리적 깊이)로 진화 중이다.
처음의 비유로 돌아가자. 소설을 한 번 읽으면 줄거리를 알고, 96번 읽으면 작가의 숨겨진 의도까지 파악한다.
GPT-3는 매 입력을 96번 "다시 읽는다." 하지만 이것은 같은 읽기를 96번 반복하는 것이 아니다. 매 층이 다른 수준의 이해를 추출한다 — 문법에서 의미로, 의미에서 논리로, 논리에서 통찰로.
이것이 "딥러닝"의 "딥"이 진정으로 의미하는 바다. 단순히 층이 많다는 것이 아니라, 깊이를 통해 질적으로 다른 수준의 이해에 도달한다는 것.
그리고 2026년의 AI는 이 깊이를 더 똑똑하게, 더 효율적으로, 더 유연하게 활용하는 방향으로 진화하고 있다. 필요한 곳에 깊이를 집중하고(MoD), 적응이 필요한 층만 수정하고(LoRA), 어려운 문제에는 더 깊이 생각하는(CoT) — 깊이의 경제학이 AI 산업의 새로운 경쟁 축이 되고 있다.
참고 문헌
Vaswani, A. et al. (2017). "Attention Is All You Need." Advances in Neural Information Processing Systems (NeurIPS), 30.
Bahdanau, D., Cho, K., & Bengio, Y. (2014). "Neural Machine Translation by Jointly Learning to Align and Translate." International Conference on Learning Representations (ICLR).
Tenney, I. et al. (2019). "BERT Rediscovers the Classical NLP Pipeline." Annual Meeting of the Association for Computational Linguistics (ACL).
Jawahar, G. et al. (2019). "What Does BERT Look At? An Analysis of BERT's Attention." Workshop on BlackboxNLP at ACL.
Geva, M. et al. (2021). "Transformer Feed-Forward Layers Are Key-Value Memories." Conference on Empirical Methods in Natural Language Processing (EMNLP).
Elhage, N. et al. (2021). "A Mathematical Framework for Transformer Circuits." Anthropic Research.
Hahn, M. (2020). "Theoretical Limitations of Self-Attention in Neural Network Models." Transactions of the Association for Computational Linguistics (TACL).
Merrill, W. & Sabharwal, A. (2023). "The Parallelism Tradeoff: Limitations of Log-Precision Transformers." Transactions of the Association for Computational Linguistics (TACL).
Brown, T. et al. (2020). "Language Models are Few-Shot Learners." Advances in Neural Information Processing Systems (NeurIPS), 33.
Hu, E. J. et al. (2022). "LoRA: Low-Rank Adaptation of Large Language Models." International Conference on Learning Representations (ICLR).
Zhang, Q. et al. (2023). "AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning." International Conference on Learning Representations (ICLR).
Raposo, D. et al. (2024). "Mixture-of-Depths: Dynamically allocating compute in transformer-based language models." arXiv preprint.
Men, X. et al. (2024). "ShortGPT: Layers in Large Language Models are More Redundant Than You Expect." arXiv preprint.
Anil, C. et al. (2022). "Exploring Length Generalization in Large Language Models." arXiv preprint.
Liu, S. et al. (2024). "DoRA: Weight-Decomposed Low-Rank Adaptation." International Conference on Machine Learning (ICML).