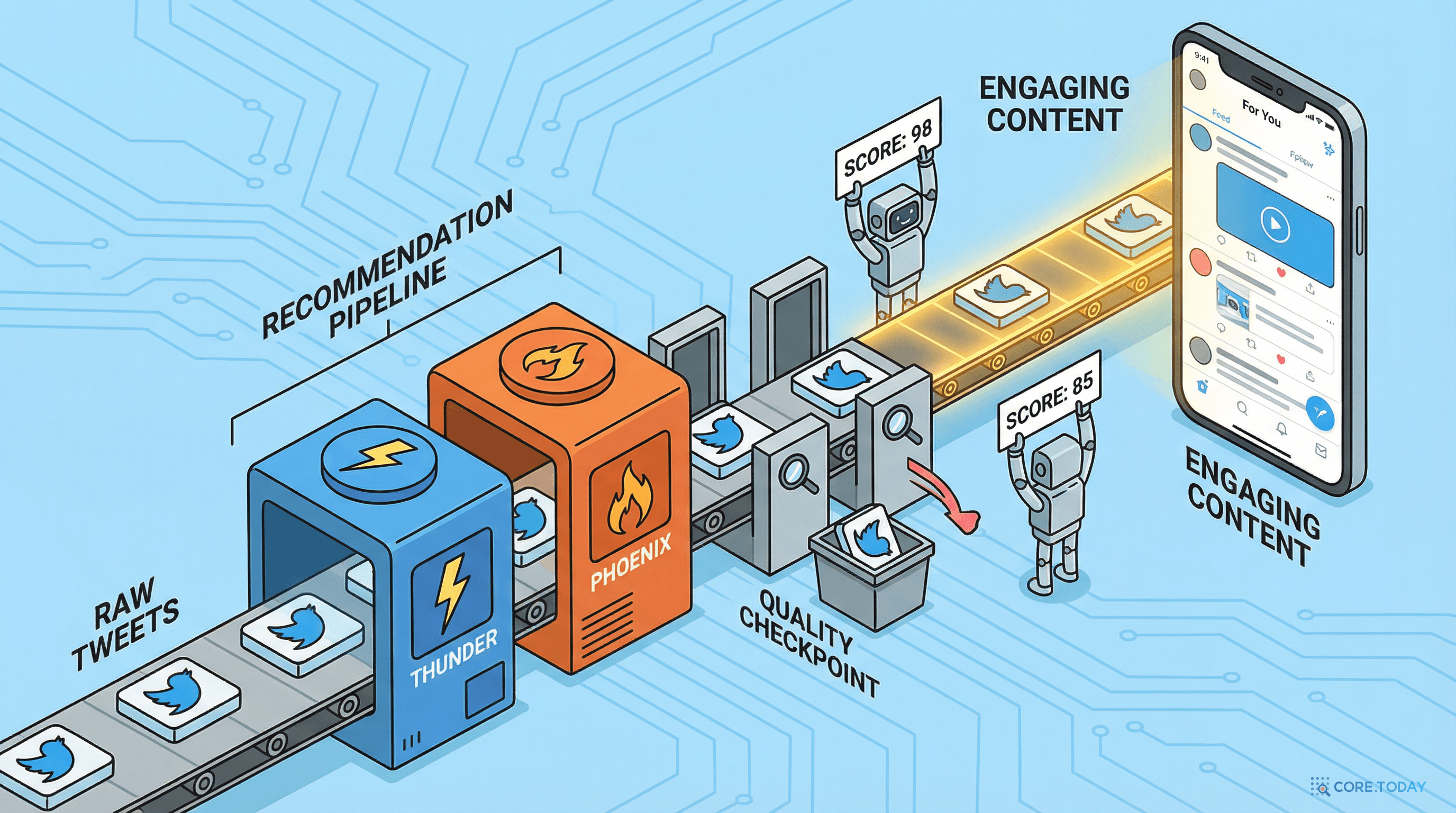
Home Mixer는 레스토랑의 총 매니저입니다. 주문(사용자 요청)을 받으면 주방에 전달하고, 요리가 나오면 품질을 확인하고, 최종적으로 손님에게 서빙합니다.
Thunder는 단골 메뉴 냉장고입니다. 자주 시키는 메뉴(팔로우 계정의 최신 글)가 미리 준비되어 있어서 즉시 꺼낼 수 있습니다.
Phoenix는 스타 셰프이자 식재료 바이어입니다. 시장에서 새로운 식재료를 찾아오고(Retrieval), 모든 재료를 시식하여 등급을 매깁니다(Ranking).
Candidate Pipeline은 주방 시스템 자체입니다. 재료 검수, 위생 점검, 조리, 플레이팅까지의 표준 프로세스를 정의합니다.
3장. Home Mixer — 오케스트레이션의 기술
gRPC 기반 서비스
Home Mixer는 전체 파이프라인을 조율하는 오케스트레이션 계층입니다. Rust로 작성되어 있으며, ScoredPostsService라는 gRPC 서비스를 통해 사용자별 정렬된 게시물을 반환합니다.
7단계 파이프라인
사용자가 X 앱을 열고 "For You" 탭을 누르는 순간, 이 7단계가 밀리초 단위로 실행됩니다:
1단계
Query Hydration — 사용자의 최근 활동 내역, 팔로우 목록, 메타데이터를 수집합니다. "이 사용자는 누구이고, 최근 뭘 했는지"를 파악하는 단계.
2단계
후보 발굴(Candidate Sourcing) — Thunder(팔로우 계정)와 Phoenix Retrieval(비팔로우)에서 후보 게시물을 수집합니다.
3단계
Hydration — 후보 게시물에 메타데이터를 보강합니다: 텍스트, 미디어, 작성자 정보, 인증 상태, 동영상 길이, 구독 상태 등.
4단계
사전 점수 필터링 — ML 모델에 보내기 전에 불필요한 후보를 제거합니다. 중복, 오래된 글, 본인 글, 차단/음소거 계정, 이미 본 글 등.
5단계
스코어링 — Phoenix Transformer 모델이 각 후보의 참여 확률을 예측하고, 가중합으로 최종 점수를 산출합니다.
6단계
선택(Selection) — 점수 순으로 정렬하여 상위 K개를 선택합니다.
7단계
선택 후 필터링 — 삭제된 글, 스팸, 폭력/잔인한 콘텐츠 제거. 같은 대화 스레드 중복 정리.
디렉토리 구조가 말해주는 것
Home Mixer의 코드 구조를 보면 각 단계가 독립 모듈로 분리되어 있습니다:
home-mixer/
├── query_hydrators/ ← 1단계: 사용자 컨텍스트 수집
├── sources/ ← 2단계: Thunder, Phoenix에서 후보 가져오기
├── candidate_hydrators/← 3단계: 메타데이터 보강
├── filters/ ← 4단계 & 7단계: 사전/사후 필터링
├── scorers/ ← 5단계: ML 점수 계산
├── selectors/ ← 6단계: 상위 K 선택
├── side_effects/ ← 로깅, 분석 이벤트
├── candidate_pipeline/ ← 파이프라인 실행 프레임워크
├── server.rs ← gRPC 서비스 엔드포인트
└── main.rs ← 서버 시작점
이 구조의 핵심 가치는 관심사의 분리(Separation of Concerns)입니다. 필터 로직을 수정해도 스코어링에 영향을 주지 않고, 새로운 후보 소스를 추가해도 기존 파이프라인을 건드릴 필요가 없습니다.
4장. Thunder — 번개처럼 빠른 인메모리 저장소
왜 "Thunder"인가?
당신이 팔로우하는 300개 계정이 지난 24시간 동안 올린 게시물을 가져오려면, 일반적으로 데이터베이스에 쿼리를 보내야 합니다. 하지만 5억 사용자가 동시에 이 작업을 하면? 데이터베이스가 버틸 수 없습니다.
Thunder는 이 문제를 해결합니다. Kafka 이벤트 스트림을 통해 게시물이 생성되는 순간 실시간으로 수집하고, 인메모리(서버 RAM)에 사용자별로 정리해 둡니다.
⚡
초저지연 조회
외부 데이터베이스 접근 없이 서브밀리초(1ms 미만) 수준의 조회 성능. RAM에서 직접 읽기 때문에 디스크 I/O가 전혀 없습니다.
📦
게시물 유형별 분류
원본 게시물, 답글/재게시물, 동영상 게시물을 별도 저장소로 관리. 유형별로 독립적인 보존 정책과 쿼리 최적화가 가능합니다.
🔄
실시간 동기화
Kafka를 통해 게시물 생성과 삭제 이벤트를 실시간 수신. 삭제된 게시물이 피드에 남지 않도록 보장합니다.
Kafka란?
Apache Kafka는 분산 이벤트 스트리밍 플랫폼입니다. 비유하자면, 거대한 실시간 우편 시스템이죠. 누군가 트윗을 올리면, 그 이벤트가 Kafka를 통해 Thunder에게 즉시 배달됩니다. 수백만 건의 이벤트가 동시에 발생해도 순서를 보장하며 전달합니다.
사용자 A가 트윗 작성
↓
Kafka Event Stream: {type: "create", post_id: "123", author_id: "A"}
↓
Thunder: A의 팔로워 목록 확인 → 해당 팔로워들의 인메모리 저장소에 추가
↓
팔로워 B가 "For You" 요청 → Thunder에서 즉시 반환 (<1ms)
5장. Phoenix — 추천의 두뇌
Phoenix는 이 시스템의 핵심 ML 컴포넌트입니다. 이름 그대로 — 기존의 수작업 피처 엔지니어링을 완전히 태우고(burn), 순수한 머신러닝으로 다시 태어난(reborn) 시스템입니다.
Phoenix는 두 단계로 작동합니다: Retrieval(검색)과 Ranking(순위 매기기).
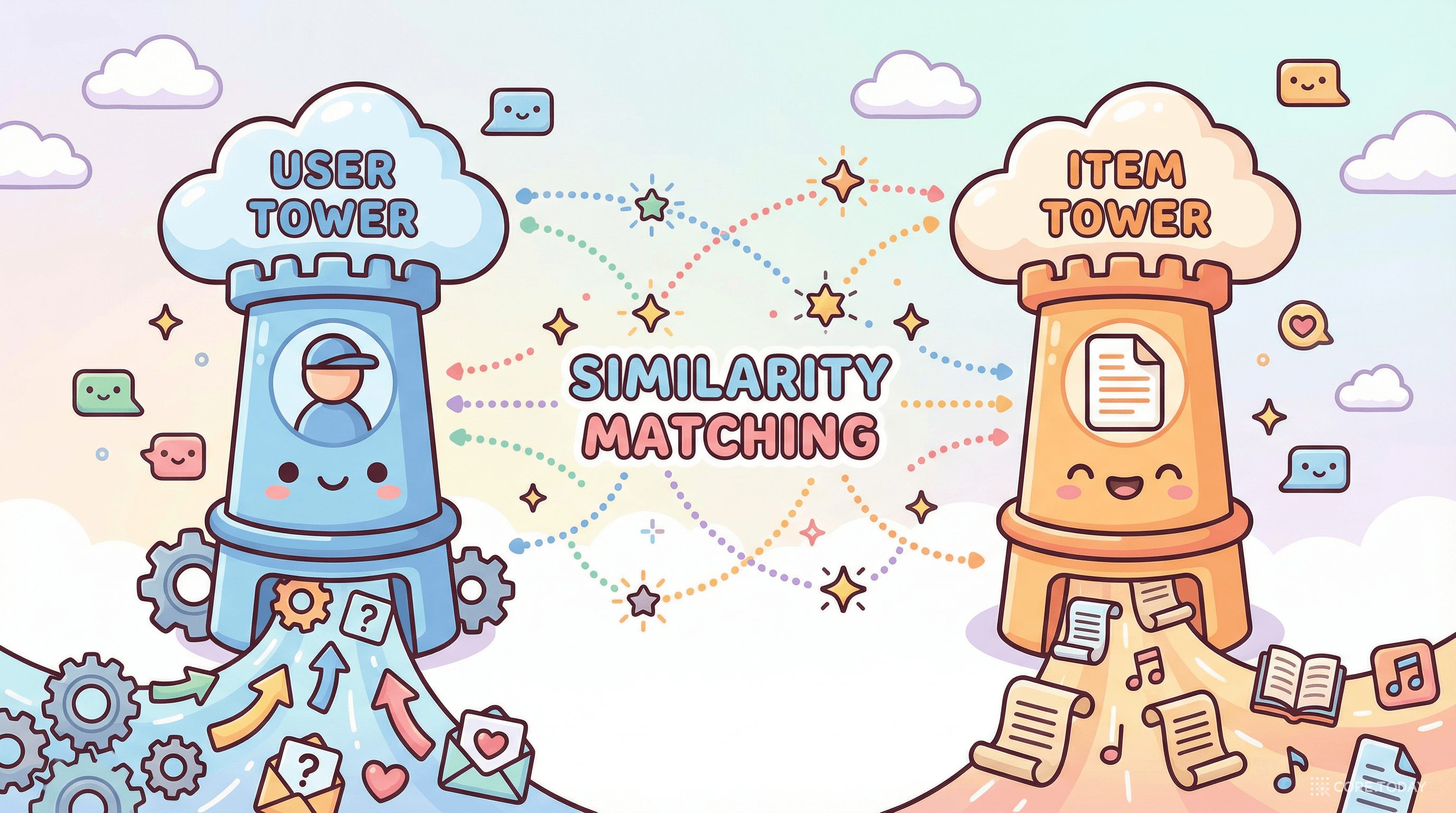
수백만 개의 게시물 중에서 당신에게 관련 있을 만한 것을 빠르게 찾아야 합니다. 모든 게시물에 대해 복잡한 모델을 돌리기엔 시간이 너무 오래 걸리죠. 이때 사용하는 것이 Two-Tower(두 탑) 모델입니다.
👤
User Tower (사용자 타워)
사용자의 특징과 참여 기록을 Transformer로 처리하여 512차원 벡터(임베딩)로 변환합니다. "이 사용자의 취향"을 하나의 숫자 배열로 압축하는 것이죠.
📄
Candidate Tower (후보 타워)
모든 게시물도 마찬가지로 512차원 벡터로 변환합니다. 게시물의 내용, 작성자 정보, 미디어 타입 등이 하나의 벡터로 압축됩니다.
🎯
Dot Product (유사도 계산)
두 벡터의 내적(dot product)을 계산하면 유사도가 나옵니다. 이 연산은 매우 빠르기 때문에 수백만 개의 후보를 밀리초 단위로 필터링할 수 있습니다.
역사적 맥락: YouTube에서 시작된 Two-Tower
Two-Tower 모델의 기원은 2016년 Google의 YouTube 추천 논문으로 거슬러 올라갑니다. YouTube는 매일 수십억 개의 동영상 중에서 사용자에게 추천할 것을 골라야 했고, 모든 동영상에 복잡한 모델을 적용하는 것은 불가능했습니다.
해결책은 단순했습니다: 사용자와 아이템을 각각 독립적으로 벡터화한 뒤, 벡터 간 거리로 관련성을 판단하는 것. 이 접근법은 이후 Google, Spotify, Pinterest, LinkedIn 등 거의 모든 대규모 추천 시스템에 채택되었습니다.
X의 Two-Tower가 특별한 점은, 사용자 타워의 Transformer 구조가 랭킹 모델과 동일한 아키텍처를 공유한다는 것입니다. 검색과 순위 매기기에서 일관된 표현(representation)을 사용하므로, 검색 단계에서 높은 점수를 받은 게시물이 순위 매기기에서도 높은 점수를 받을 가능성이 높습니다.
검색 단계에서 수백 개의 후보를 골랐다면, 이제 정밀하게 순위를 매겨야 합니다. 여기서 등장하는 것이 Phoenix Ranking 모델 — xAI의 Grok-1에서 가져온 Transformer 아키텍처입니다.
Grok-1에서 추천 시스템으로
Grok-1은 원래 314B 파라미터의 대규모 언어모델입니다. Mixture-of-Experts(MoE) 구조로, 64개 레이어, 48개 쿼리 헤드, RoPE(Rotary Position Embeddings) 등을 사용하죠.
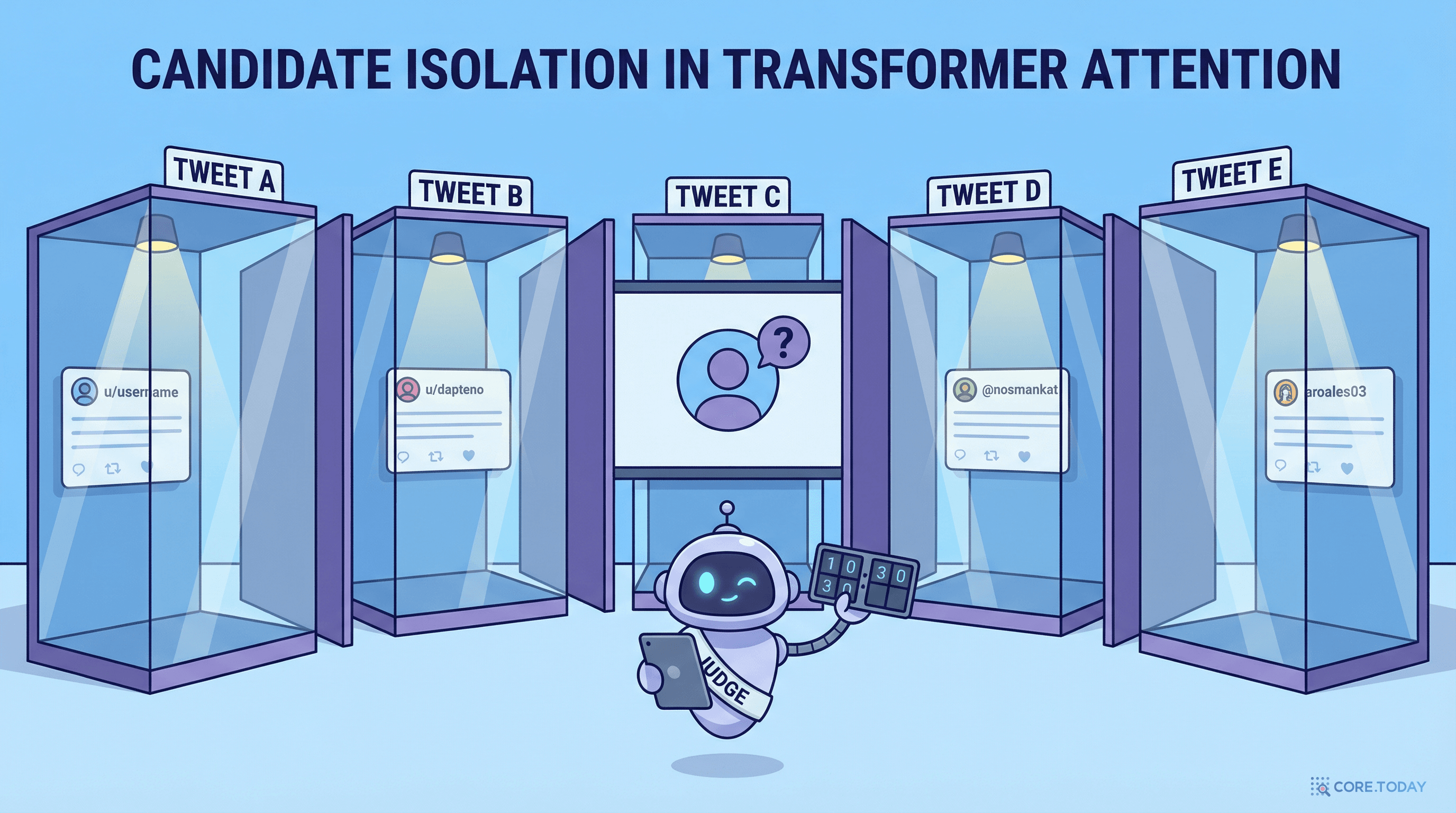
X의 엔지니어들은 이 Transformer 아키텍처를 추천 시스템에 맞게 축소하고 재설계했습니다. 핵심 변경은 바로 Candidate Isolation(후보 독립 평가)입니다.
Candidate Isolation이 왜 중요한가?
일반적인 Transformer에서는 입력 토큰들이 서로 어텐션(attention)을 주고받습니다. 즉, 하나의 토큰이 다른 모든 토큰의 정보를 참조할 수 있죠.
하지만 추천 시스템에서 이것은 큰 문제를 일으킵니다:
❌
문제: 배치 의존성
게시물 A의 점수가 같은 배치에 있는 게시물 B, C에 따라 달라집니다. 같은 게시물인데 어떤 배치에 속하느냐에 따라 점수가 변하면 일관성이 깨집니다.
✅
해결: Candidate Isolation
후보 게시물들이 서로의 정보를 참조하지 못하도록 어텐션 마스크를 적용합니다. 각 후보는 사용자 컨텍스트만 참조할 수 있습니다.
🚀
효과: 캐싱과 병렬 처리
점수가 배치에 무관하므로 결과를 캐싱할 수 있고, 후보들을 병렬로 독립 평가할 수 있습니다. 속도와 일관성 모두 확보.
어텐션 마스크의 구조
Transformer의 어텐션 마스크가 어떻게 Candidate Isolation을 구현하는지 시각화해 보겠습니다:
Attention Mask 패턴 (Candidate Isolation)
사용자 + 히스토리 토큰
✅ 모든 토큰에 양방향 어텐션 가능 (Full Bidirectional)
후보 → 사용자/히스토리
✅ 후보가 사용자 컨텍스트를 참조 가능 (Allowed)
후보 → 다른 후보
❌ 차단됨. 자기 자신만 참조 가능 (Diagonal Only)
비유하자면 이렇습니다: 면접관(사용자 컨텍스트)이 10명의 지원자(후보 게시물)를 평가할 때, 각 지원자는 개별 면접실에서 독립적으로 면접을 봅니다. 지원자들은 면접관의 질문(사용자 취향)에는 답할 수 있지만, 다른 지원자가 뭐라고 답했는지는 모릅니다.
입력 구조: 3가지 임베딩 스트림
Phoenix Ranking 모델은 세 가지 종류의 입력을 받습니다:
임베딩 스트림
포함 정보
역할
사용자 임베딩
Hash 기반 사용자 ID 임베딩
사용자의 기본 특성 표현
히스토리 임베딩
과거 참여한 게시물, 작성자, 행동 유형, 플랫폼
사용자의 취향 패턴 학습
후보 임베딩
게시물 내용, 작성자 정보, 플랫폼 정보
평가 대상 게시물의 특성
특이한 점은 Hash 기반 임베딩을 사용한다는 것입니다. 일반적인 추천 시스템은 사용자 ID마다 고유한 임베딩 벡터를 학습하지만, 수억 명의 사용자와 수십억 개의 게시물에 대해 이렇게 하면 메모리가 폭발합니다. 대신 여러 개의 해시 함수를 사용하여 ID를 해시 테이블 인덱스로 변환하고, 해당 인덱스의 임베딩을 조합합니다.
6장. 15개 행동 예측: 단순한 "좋아요"를 넘어서
다중 행동 예측(Multi-Action Prediction)
기존 추천 시스템 대부분은 하나의 관련성 점수를 예측했습니다. "이 사용자가 이 게시물을 좋아할 확률은 몇 %인가?" 정도였죠.
Phoenix는 완전히 다릅니다. 15가지 서로 다른 행동에 대한 확률을 동시에 예측합니다:
긍정적 행동
가중치
부정적 행동
가중치
좋아요 (Favorite)
+0.5
관심없음 (Not Interested)
감점
답글 (Reply)
+0.3
차단 (Block Author)
-3.0
리포스트 (Repost)
+1.0
음소거 (Mute Author)
감점
인용 (Quote)
긍정
신고 (Report)
-5.0
클릭 (Click)
긍정
프로필 클릭
긍정
동영상 시청
긍정
사진 확대
긍정
공유 (Share)
긍정
체류 (Dwell)
긍정
작성자 팔로우
+4.0
가중치가 말해주는 것
이 가중치 체계에는 X의 제품 철학이 녹아 있습니다:
행동별 가중치 (공개된 예시 기준)
작성자 팔로우
+4.0
리포스트
+1.0
좋아요
+0.5
답글
+0.3
차단
-3.0
신고
-5.0
몇 가지 흥미로운 관찰:
팔로우 가중치가 가장 높다(+4.0) — "이 게시물이 너무 좋아서 작성자를 팔로우했다"는 가장 강한 긍정 신호입니다. 좋아요(+0.5)보다 8배 높습니다.
부정 신호가 긍정보다 강하다 — 차단(-3.0)은 좋아요(+0.5)의 6배, 신고(-5.0)는 10배의 영향력을 가집니다. 이것은 사용자 이탈 방지(retention)가 단기적 참여(engagement)보다 중요하다는 철학을 반영합니다.
Candidate Pipeline은 추천 파이프라인의 재사용 가능한 프레임워크입니다. Rust의 Trait 시스템을 활용하여 각 단계를 독립적인 모듈로 정의합니다:
Trait
역할
예시
Source
후보 게시물 공급
Thunder, Phoenix Retrieval
Hydrator
메타데이터 보강
작성자 정보, 미디어 타입
Filter
불필요한 후보 제거
중복, 차단 계정, 오래된 글
Scorer
점수 계산
Phoenix ML, 가중합, 다양성
Selector
최종 선택
Top-K 선택
SideEffect
부수 효과 처리
로깅, 분석 이벤트
4개의 스코어러가 순차적으로 작동
스코어링 단계에서는 4개의 스코어러가 순서대로 적용됩니다:
Phoenix Scorer
→
Weighted Scorer
→
Author Diversity
→
OON Scorer
Phoenix Scorer — Transformer 모델의 15가지 행동 예측값을 가져옵니다
Weighted Scorer — 예측값을 가중합하여 최종 관련성 점수를 산출합니다
Author Diversity Scorer — 같은 작성자의 게시물이 피드를 독점하지 않도록 중복 작성자의 점수를 감쇄합니다
OON (Out-of-Network) Scorer — 팔로우하지 않는 계정의 콘텐츠 점수를 조정합니다
Author Diversity Scorer는 특히 중요합니다. 이것이 없으면, 게시물을 많이 올리는 파워유저의 콘텐츠가 피드를 장악할 수 있습니다. 이 스코어러는 대량 게시 전략(volume-based strategy)의 효과를 의도적으로 제한합니다.
8장. 두 겹의 필터링: 왜 두 번 걸러야 할까?
사전 점수 필터 (Pre-Scoring)
ML 모델에 보내기 전에 명백히 불필요한 후보를 제거합니다. ML 추론은 비용이 크기 때문에, 여기서 최대한 걸러내는 것이 효율적입니다.
필터 유형
제거 대상
이유
중복 제거
같은 게시물의 중복 후보
여러 소스에서 같은 글이 올 수 있음
시간 기반
너무 오래된 게시물
신선도가 중요
자기 자신
본인이 쓴 글
자기 글은 추천 불필요
차단/음소거
차단하거나 음소거한 계정
사용자 의사 존중
음소거 키워드
뮤트한 키워드 포함
사용자 설정 존중
이미 본 콘텐츠
이전에 봤거나 서빙된 글
반복 노출 방지
구독 불가
유료 콘텐츠 (비구독자)
접근 권한 확인
선택 후 필터 (Post-Selection)
ML 모델이 점수를 매기고 상위 K개를 선택한 후에 한 번 더 걸러냅니다:
삭제된 게시물 — 스코어링과 선택 사이에 삭제된 경우
스팸 콘텐츠 — 정교한 스팸 탐지 모델 적용
폭력/잔인한 콘텐츠 — 안전성 필터
대화 스레드 중복 — 같은 대화의 여러 분기가 선택된 경우 정리
왜 두 번 걸러야 할까요? 사전 필터는 비용 절약(ML 추론 횟수 감소)이 목적이고, 사후 필터는 안전성 보장(사용자에게 절대 보여선 안 되는 콘텐츠 차단)이 목적입니다. 서로 다른 이유로 존재하는 겁니다.
9장. 기술 스택: 왜 Rust와 Python인가?
x-algorithm 코드 구성 비율
Rust
62.9%
Python
37.1%
Rust — 프로덕션 서빙
Thunder(인메모리 저장소), Home Mixer(오케스트레이션), Candidate Pipeline(파이프라인 프레임워크)은 모두 Rust로 작성되어 있습니다.
왜 Rust일까요? 200ms 미만의 응답 시간이 목표이기 때문입니다. 사용자가 앱을 열고 피드가 로드되는 데 200ms 이상 걸리면 체감 속도가 느려집니다. Rust는 가비지 컬렉션(GC) 없이 메모리 안전성을 보장하므로, 예측 가능한 저지연(predictable low latency)을 달성할 수 있습니다.
Python + JAX — ML 모델
Phoenix의 Transformer 모델은 Python과 JAX로 구현되어 있습니다. JAX는 Google이 개발한 수치 연산 라이브러리로, 자동 미분과 GPU/TPU 가속을 지원합니다. Grok-1도 JAX로 구현되었기 때문에, 아키텍처를 가져오기에 최적의 선택이었죠.
10장. 핵심 설계 원칙 — 5가지 철학
원칙 1: 수작업 피처 엔지니어링 제거
"시스템에서 수작업으로 설계된 모든 기능 및 대부분의 휴리스틱 알고리듬은 제거되었다."
전통적인 추천 시스템은 도메인 전문가가 "이 피처가 중요할 것이다"라고 판단하여 수작업으로 설계합니다. 예: "게시물의 해시태그 수", "작성자의 팔로워 수", "게시 후 경과 시간" 등.
X는 이것을 전부 제거했습니다. Transformer가 사용자의 행동 시퀀스에서 직접 패턴을 학습합니다. 사람이 "이것이 중요하다"고 알려주는 대신, 모델이 데이터에서 스스로 무엇이 중요한지를 발견합니다.
원칙 2: Candidate Isolation
어텐션 마스크를 통해 후보 게시물 간 상호 참조를 차단합니다. 이것은 일관된 점수 산출, 결과 캐싱 가능, 병렬 처리 용이라는 세 가지 실용적 이점을 제공합니다.
원칙 3: Hash 기반 임베딩
전통적인 임베딩 테이블 대신 여러 해시 함수를 사용한 임베딩 조회를 채택했습니다. 수억 명의 사용자와 수십억 개의 게시물에 대한 메모리 효율성을 확보하면서도, 해시 충돌의 영향을 여러 해시 함수로 분산합니다.
원칙 4: 다중 행동 예측
단일 "관련성" 점수가 아닌 15가지 행동에 대한 확률을 동시에 예측합니다. 이것은 멀티태스크 러닝(Multi-Task Learning)의 핵심 이점을 활용합니다 — 여러 관련된 태스크를 동시에 학습하면, 각 태스크의 성능이 개별 학습보다 높아집니다.
원칙 5: 모듈형 파이프라인
파이프라인 실행 및 모니터링 로직을 비즈니스 로직과 완전히 분리합니다. 새로운 소스, 필터, 스코어러를 추가할 때 기존 코드를 수정할 필요가 없습니다.
🔧
독립 단계 병렬 실행
서로 의존하지 않는 단계는 동시에 실행됩니다. Thunder와 Phoenix Retrieval은 병렬로 후보를 수집합니다.
🛡️
적절한 오류 처리
하나의 단계가 실패해도 전체 파이프라인이 죽지 않습니다. 오류에 대한 폴백(fallback) 전략이 각 단계에 내장되어 있습니다.
📊
단계별 모니터링
각 단계의 지연 시간, 성공률, 후보 수를 독립적으로 추적합니다. 병목이 어디인지 즉시 파악할 수 있습니다.
11장. 2026년, 이것이 의미하는 것
LLM이 추천 시스템을 먹어치우고 있다
X의 알고리즘은 더 큰 트렌드의 일부입니다: 대규모 언어모델(LLM) 기술이 추천 시스템의 핵심 인프라가 되고 있다는 것.
과거
추천 시스템과 NLP는 별개의 분야. 각각 다른 모델, 다른 팀, 다른 인프라.
전환기
Transformer 아키텍처가 NLP를 넘어 추천, 비전, 오디오에 확산. "Attention Is All You Need"의 실현.
현재
xAI는 Grok(대화형 AI)과 X 추천 시스템이 같은 Transformer를 공유. LLM 인프라 = 추천 인프라.
이것은 단순한 기술 공유가 아니라 조직적 효율성의 혁명입니다. LLM 팀이 개선한 Transformer 아키텍처가 곧바로 추천 시스템의 성능 향상으로 이어지고, 추천 시스템에서 발견한 패턴이 LLM의 학습에 피드백됩니다.
오픈소스의 의미: 투명성인가, 마케팅인가?
X는 이 코드를 Apache License 2.0으로 공개하고, 4주마다 업데이트하겠다고 약속했습니다. 하지만 몇 가지 빠진 것들이 있습니다:
공개된 것 ✅
공개되지 않은 것 ❌
전체 서빙 아키텍처
학습된 모델 가중치
파이프라인 코드
학습 데이터셋
모델 아키텍처 (JAX)
정확한 가중치 계수
필터링 로직
광고 추천 시스템
Trait 기반 프레임워크
A/B 테스트 프레임워크
코드를 읽을 수는 있지만, 실제로 재현하거나 검증하는 것은 불가능합니다. 학습된 가중치와 데이터 없이는 같은 결과를 낼 수 없으니까요. 그래도 이 수준의 공개는 주요 소셜 플랫폼 중 전례가 없는 것이며, 추천 시스템 연구자와 엔지니어에게 귀중한 학습 자료입니다.
당신의 피드를 바꾸고 싶다면
이 알고리즘을 이해하면, 당신의 For You 피드를 의도적으로 조절할 수 있습니다:
"좋아요"보다 "팔로우"가 8배 강하다 — 좋아하는 분야의 계정을 적극적으로 팔로우하세요
"차단"이 "좋아요"보다 6배 강하다 — 관심 없는 계정을 차단하면 유사한 콘텐츠가 빠르게 줄어듭니다
다양성 스코어러가 존재한다 — 한 계정의 글을 아무리 좋아해도, 피드의 일정 비율 이상은 차지할 수 없습니다
히스토리가 곧 프로필이다 — Transformer는 당신의 최근 행동 시퀀스에서 취향을 학습합니다. 의도적인 참여가 피드를 바꿉니다
마치며: 알고리즘은 거울이다
X의 "For You" 피드는 당신의 행동 패턴을 거울처럼 비추는 시스템입니다. 좋아요를 누른 것, 오래 머문 것, 공유한 것, 차단한 것 — 이 모든 행동이 Transformer에 입력되어, "이 사람은 다음에 무엇을 좋아할까?"를 예측합니다.
xAI가 Grok의 Transformer를 추천 시스템에 적용한 것은 단순한 기술 선택이 아니라, "AI의 핵심 인프라를 통합하겠다"는 전략적 결정입니다. 대화형 AI, 추천 시스템, 검색 — 모두 같은 Transformer 위에서 돌아가는 세계. 그것이 xAI가 그리는 미래입니다.