TECH BLOG
기술 블로그
AI 기술 인사이트와 엔지니어링 경험을 공유합니다.
ALL POSTS
모든 포스트

금속이 녹아가는 과정을 AI로 예측한다 — Sharp-PINNs 완전 해부
결합된 편미분방정식을 동시에 학습하면 그래디언트가 충돌한다. Sharp-PINNs는 '교대 학습 + 경성 제약'이라는 우아한 해법으로 이 난제를 돌파하고, 3D 부식 시뮬레이션에서 FEM 대비 10배 빠른 속도를 달성했다.
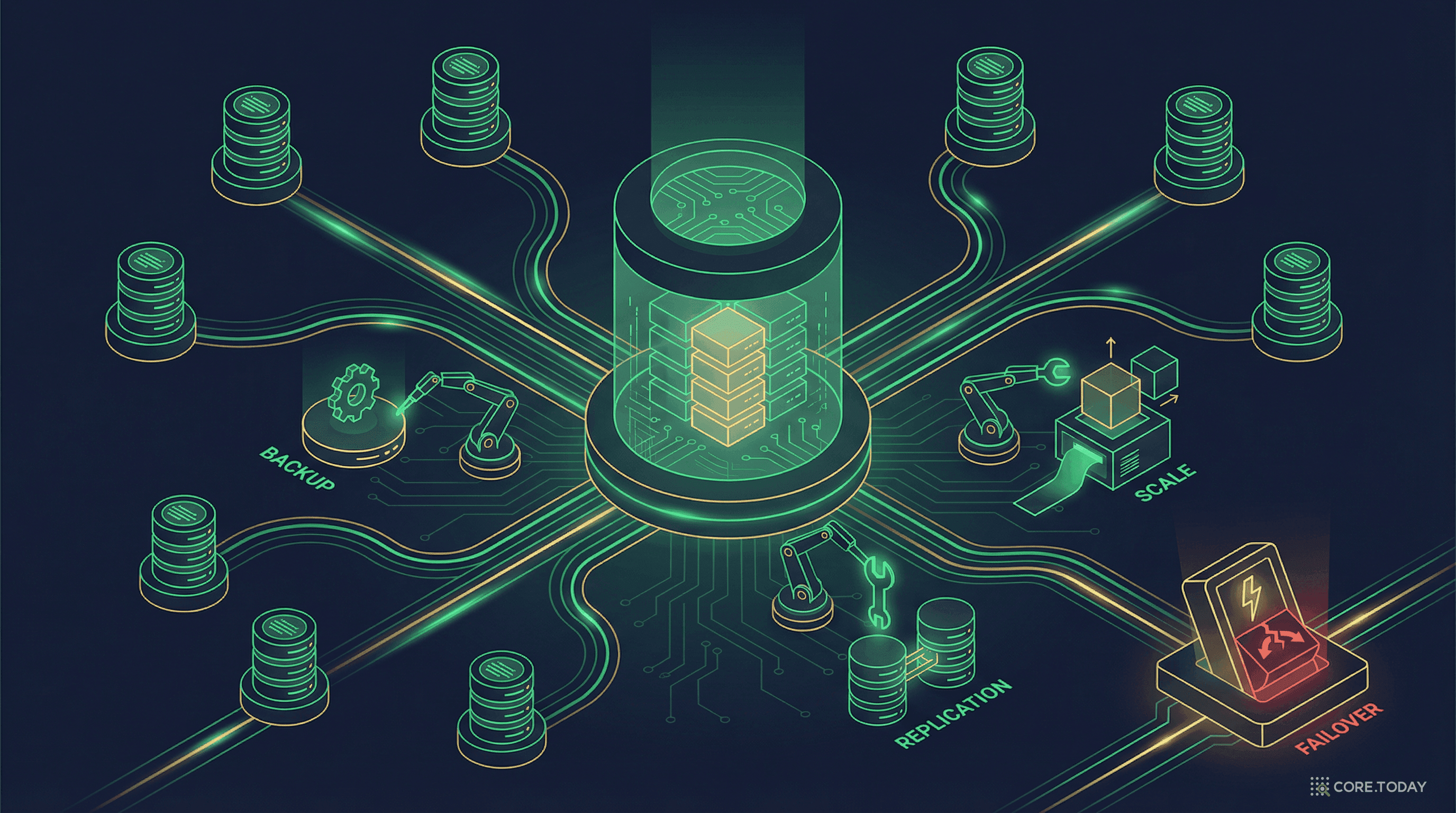
AWS RDS 완전 정복: 데이터베이스 관리라는 '야간 당직'에서 해방되는 법
새벽 3시에 DB 장애 알림을 받고 출근하던 시대에서, 백업·패치·복구·스케일링이 자동화된 시대로. RDS가 왜 탄생했고, 어떻게 DBA의 일상을 바꿨으며, Aurora는 왜 '재발명'이라 불리는지를 실전 사례와 함께 풀어본다.
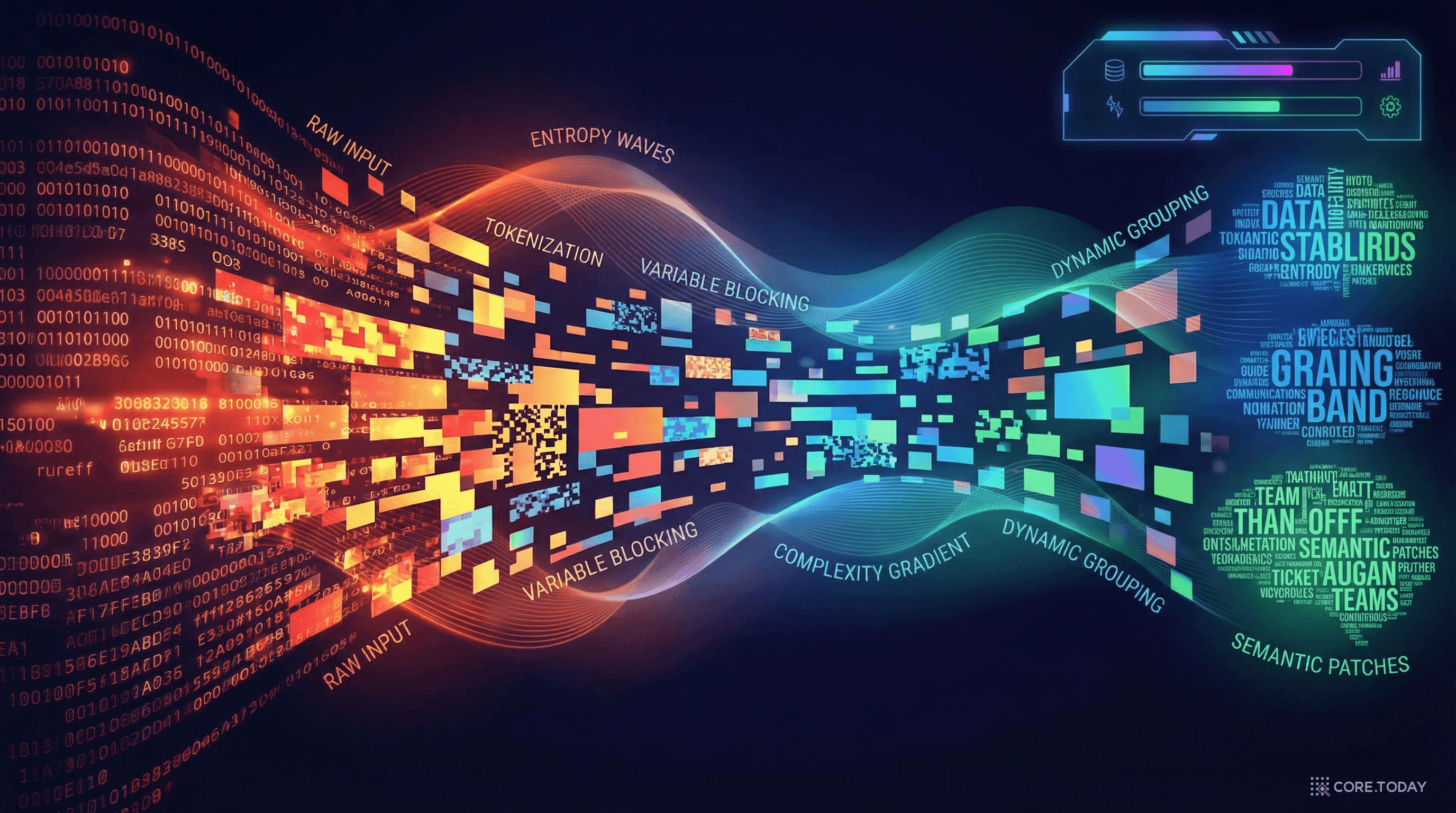
Byte Latent Transformer: 토큰을 버리고 바이트로 돌아간 AI의 반란
GPT부터 Llama까지, 모든 LLM은 '토크나이저'라는 전처리 단계에 의존한다. Meta AI의 BLT는 이 관행을 뒤집었다 — 바이트를 직접 처리하되, 엔트로피 기반으로 '어려운 곳에 더 많은 연산'을 동적 할당하여 80억 스케일에서 Llama 3에 필적하는 성능을 달성했다.

어려운 문제는 쪼개서 푼다 — Augmented PINN(APINN)의 모든 것
PINN이 복잡한 문제 앞에서 좌절할 때, 수학자들은 수백 년 된 전략을 꺼내들었다 — '나눠서 정복하라.' 도메인 분해와 신경망을 결합한 APINN이 왜, 어떻게 PINN의 한계를 돌파하는지를 쉽고 깊게 풀어본다.

RAG vs Long Context 2026 — 10M 토큰 시대, 검색이 여전히 필요한가?
GPT-2의 1,024 토큰에서 Llama 4 Scout의 1,000만 토큰까지 — 컨텍스트 윈도우가 10,000배 커졌다. 이제 RAG는 필요 없는가? 2026년의 답은 '둘 다'이면서 '상황에 따라 다르다'이다.
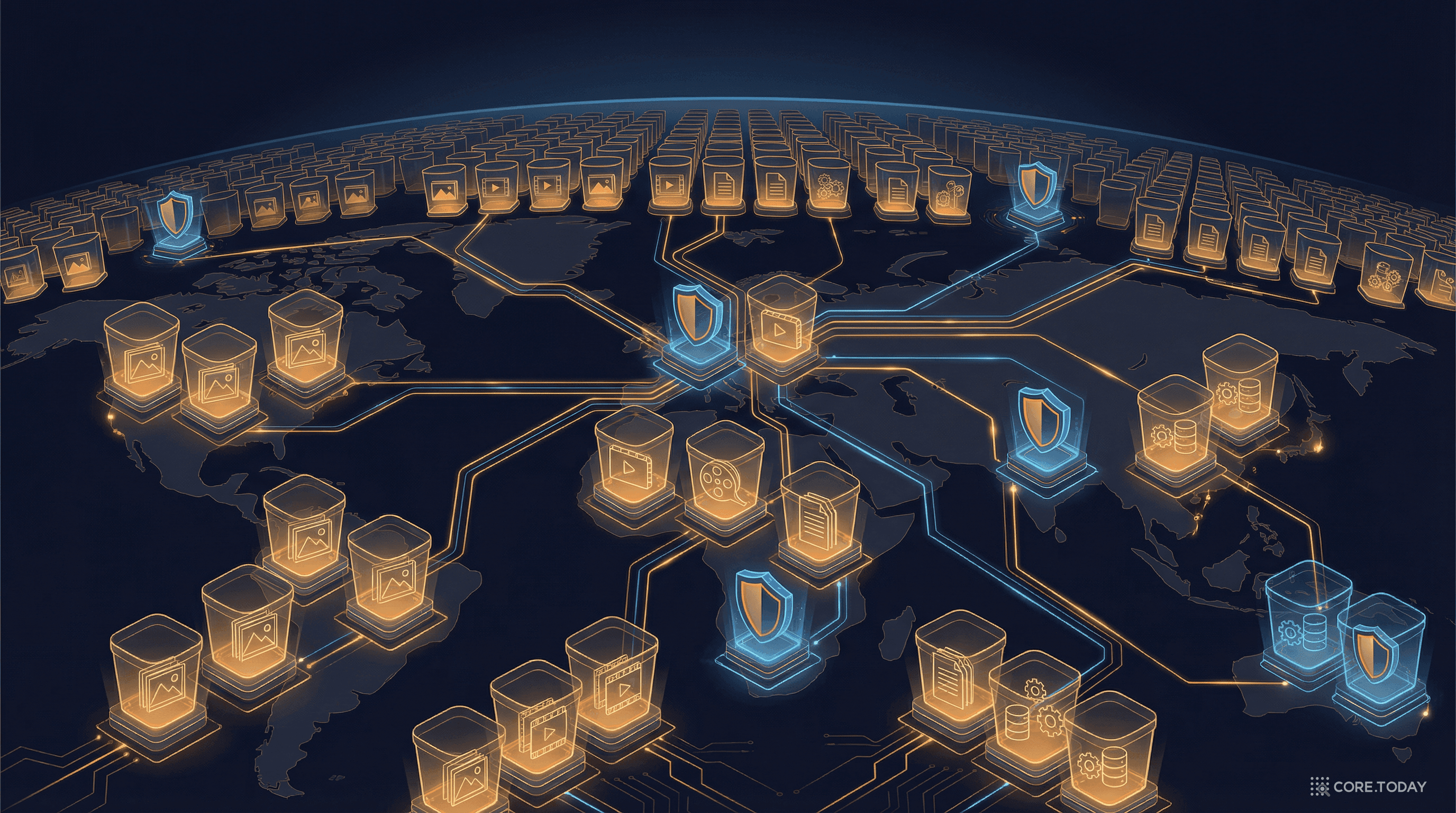
AWS S3 완전 정복: 인터넷의 하드디스크가 된 서비스의 모든 것
AWS의 첫 번째 서비스이자, 인터넷 인프라의 보이지 않는 기둥. S3가 왜 탄생했고, 어떻게 99.999999999%의 내구성을 달성하며, 전 세계 기업이 어떤 사고를 겪었고, 실무에서 어떻게 활용해야 하는지를 풀어본다.
교육 AI 특집: 블룸의 꿈에서 AI 튜터까지, 모든 학생에게 최고의 선생님을
1984년 벤자민 블룸이 던진 질문 — '1:1 과외만큼 효과적인 교육을 모두에게 줄 수 있는가' — 에 40년 만에 AI가 답하고 있다. 교육 기술 100년의 역사부터 2026년 AI 튜터의 현재까지.

에이전트 AI 특집: 민스키의 상상에서 AAIF까지, 70년의 여정
1950년대 튜링의 사고하는 기계에서 2026년 에이전트 간 프로토콜 표준화까지. AI 에이전트 70년의 궤적을 추적하고, 지금 일어나고 있는 구조적 전환의 본질을 파악한다.
AWS Well-Architected Framework: 클라우드를 '제대로' 설계하는 6가지 기둥
EC2 하나 띄우는 건 쉽다. 하지만 '잘' 띄우는 건 다른 문제다. AWS가 10년간 수만 고객의 아키텍처를 리뷰하며 정리한 공식 설계 원칙 — Well-Architected Framework의 6가지 기둥을 20대 눈높이에서 풀어본다.