
블로그로 돌아가기
객체 검출논문 리뷰YOLO컴퓨터 비전딥러닝실시간 AI
YOLO 완전 이해: 한 번만 봐! — 실시간 객체 검출의 혁명
'느리지만 정확하게'가 아니라 '한 번에 전부' — 객체 검출을 회귀 문제로 재정의하여 실시간 처리를 가능하게 한 YOLO가 어떻게 탄생했고, 왜 10년이 지난 지금도 세상을 바꾸고 있는지를 논문과 사례로 풀어본다.
코어닷투데이2025-09-1569분
'느리지만 정확하게'가 아니라 '한 번에 전부' — 객체 검출을 회귀 문제로 재정의하여 실시간 처리를 가능하게 한 YOLO가 어떻게 탄생했고, 왜 10년이 지난 지금도 세상을 바꾸고 있는지를 논문과 사례로 풀어본다.
당신이 횡단보도 앞에 서 있다고 상상해보자.
신호가 바뀌는 순간, 당신의 눈은 동시에 수십 가지를 처리한다. 왼쪽에서 달려오는 택시, 오른쪽 인도 위의 자전거, 횡단보도를 건너는 어린이, 그 뒤를 따르는 강아지, 머리 위의 신호등. 당신은 이 모든 것을 0.1초도 안 되는 시간에 파악하고, 각각이 무엇인지, 어디에 있는지, 얼마나 빨리 움직이는지까지 판단한다. 이 판단을 바탕으로 당신은 안전하게 길을 건넌다.
이것이 인간의 시각 시스템이다. 한 번 보면, 전부 안다.
이제 같은 일을 컴퓨터에게 시켜보자.
2014년까지의 컴퓨터 비전 시스템은 이 단순한 일을 하기 위해 놀라울 정도로 복잡한 절차를 밟아야 했다. 이미지의 수천 군데를 하나하나 살펴보고, 각 영역을 잘라내어 분류기에 넣고, 중복을 제거하고, 결과를 정제하는 — 마치 돋보기로 책의 모든 글자를 하나씩 읽는 것 같은 방식이었다. 결과적으로 한 장의 이미지를 처리하는 데 수십 초가 걸렸다. 실시간? 꿈도 못 꾸는 속도였다.
2015년 6월, 한 논문이 이 모든 것을 뒤집었다.
"You Only Look Once: Unified, Real-Time Object Detection" — Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi가 발표한 이 논문의 제목부터가 도발적이었다. "한 번만 봐." 인간처럼 이미지를 한 번만 보고 모든 객체를 검출하겠다는 선언이었다. 그리고 그들은 정말로 해냈다. 초당 45프레임, Fast YOLO는 초당 155프레임. 기존 최고 시스템보다 100배 이상 빠른 속도로, 실시간 영상에서 객체를 검출하는 것이 가능해진 것이다.
이 글은 그 혁명의 이야기를 따라간다. 왜 객체 검출이 그토록 어려웠는지에서 출발해, YOLO가 어떤 발상의 전환으로 문제를 풀었는지를 거쳐, 10년 뒤인 2026년에 이 기술이 어떻게 세상을 바꾸고 있는지에 이른다. 단순히 논문을 요약하는 것이 아니라, 왜 이 아이디어가 필요했고, 어떤 직관에서 출발했으며, 그것이 어떻게 실현되었는지를 풀어보려 한다.
먼저 중요한 구분부터 하자.
이미지 분류(Image Classification)는 이미지 전체를 보고 "이것은 고양이다"라고 말하는 것이다. 입력은 이미지 하나, 출력은 라벨 하나. 2012년 AlexNet이 ImageNet 대회에서 압도적 승리를 거둔 이후, 이 문제는 급속도로 풀려나갔다. 2015년에는 ResNet이 인간보다 더 정확하게 이미지를 분류할 수 있게 되었다.
하지만 객체 검출(Object Detection)은 완전히 다른 차원의 문제다.
객체 검출은 이미지 안에서 "무엇이(what) 어디에(where) 있는가"를 동시에 답해야 한다. 이미지 안에 객체가 하나일 수도 있고, 열 개일 수도 있고, 없을 수도 있다. 각 객체의 위치(바운딩 박스 좌표), 크기, 클래스(자동차인지, 사람인지, 개인지)를 모두 예측해야 한다.
이것이 왜 어려운지 직관적으로 이해해보자. 이미지 분류가 "이 사진에 무엇이 있나요?"라는 OX 퀴즈라면, 객체 검출은 "이 사진 안의 모든 물체를 찾아서, 각각에 네모 박스를 그리고, 이름표를 붙이세요"라는 서술형 시험이다. 객체의 수가 정해져 있지 않고, 크기도 제각각이며, 서로 겹쳐 있을 수도 있다.
2015년 이전, 연구자들은 이 문제를 두 가지 접근법으로 풀고 있었다.
가장 직관적인 방법은 슬라이딩 윈도우(Sliding Window)였다. 이미지 위에 작은 창문(윈도우)을 놓고, 그 창문을 한 칸씩 옮기면서 "이 영역에 객체가 있는가?"를 판단하는 것이다.
이 방식의 대표적인 구현이 DPM(Deformable Parts Model)이다. Felzenszwalb 등이 2010년에 발표한 DPM은 HOG(Histogram of Oriented Gradients) 특징을 사용하여 객체를 부분(parts)으로 나누어 검출했다. 당시로서는 최첨단이었지만, 본질적인 한계가 있었다.
속도 문제가 치명적이었다. 이미지 한 장에 대해 윈도우를 수만 번 옮기면서, 매번 특징 추출과 분류를 수행해야 했다. 가장 빠른 DPM 구현도 초당 30프레임이 한계였고, 일반적으로는 이미지 한 장에 수 초가 걸렸다. 실시간 비디오 처리는 불가능한 수준이었다.
더 근본적인 문제는 수작업 특징(hand-crafted features)에 의존한다는 점이었다. HOG, SIFT 같은 특징은 인간이 직접 설계한 것이다. "가장자리(edge)의 방향 히스토그램이 특정 패턴이면 사람이다"라는 식의 규칙을 인간이 정의해야 했다. 이 규칙은 특정 조건에서는 잘 작동했지만, 조명이 바뀌거나, 객체가 가려지거나, 예상치 못한 자세를 취하면 쉽게 무너졌다.
2014년, Ross Girshick 등이 발표한 R-CNN(Regions with CNN features)은 획기적인 전환점이었다. R-CNN의 핵심 아이디어는 단순했다. 이미지의 모든 곳을 보는 대신, "여기에 뭔가 있을 것 같다"는 영역만 골라서 CNN으로 분류하자.
R-CNN은 DPM보다 정확도에서 압도적이었다. Pascal VOC 2010에서 mAP(mean Average Precision) 53.7%를 달성하여, DPM의 33.4%를 크게 앞섰다. CNN이 수작업 특징보다 훨씬 강력한 표현을 학습할 수 있다는 것을 증명한 것이다.
하지만 속도는 참담했다. R-CNN은 이미지 한 장당 약 2,000개의 영역 제안을 생성하고, 각각을 독립적으로 CNN에 통과시켜야 했다. 이미지 한 장 처리에 GPU로 13초, CPU로 47초. 실시간은 고사하고, 대규모 데이터셋 처리조차 비현실적이었다.
이후 Fast R-CNN(2015)은 CNN 연산을 공유하여 속도를 크게 개선했지만, 여전히 Selective Search 단계에서 영역당 2초가 걸렸다. Faster R-CNN(2015)은 Region Proposal Network(RPN)을 도입하여 영역 제안까지 신경망으로 대체했지만, 그래도 초당 7프레임(VGG-16 기준)에 머물렀다. 실시간 처리에는 여전히 턱없이 모자란 속도였다.
여기서 한 발 물러서 문제를 바라보자. R-CNN 계열의 접근법은 객체 검출을 여러 단계의 파이프라인으로 분해한다.
각 단계는 독립적으로 학습되고 최적화된다. 영역 제안기는 검출 성능과 무관하게 학습되고, 분류기는 영역 제안의 질과 무관하게 학습된다. 전체 시스템을 하나로 묶어 최적화하는 것이 불가능했다. 마치 축구팀의 공격수, 미드필더, 수비수가 각자 따로 연습만 하고, 한 번도 함께 경기를 해보지 않은 채 실전에 나가는 것과 같았다.
YOLO의 창시자 Joseph Redmon은 이 상황을 명쾌하게 진단했다.
"기존 시스템들은 분류기를 재활용(repurpose)해서 검출에 사용하고 있다. 우리는 검출을 아예 다른 문제로 재정의한다 — 하나의 회귀 문제로."
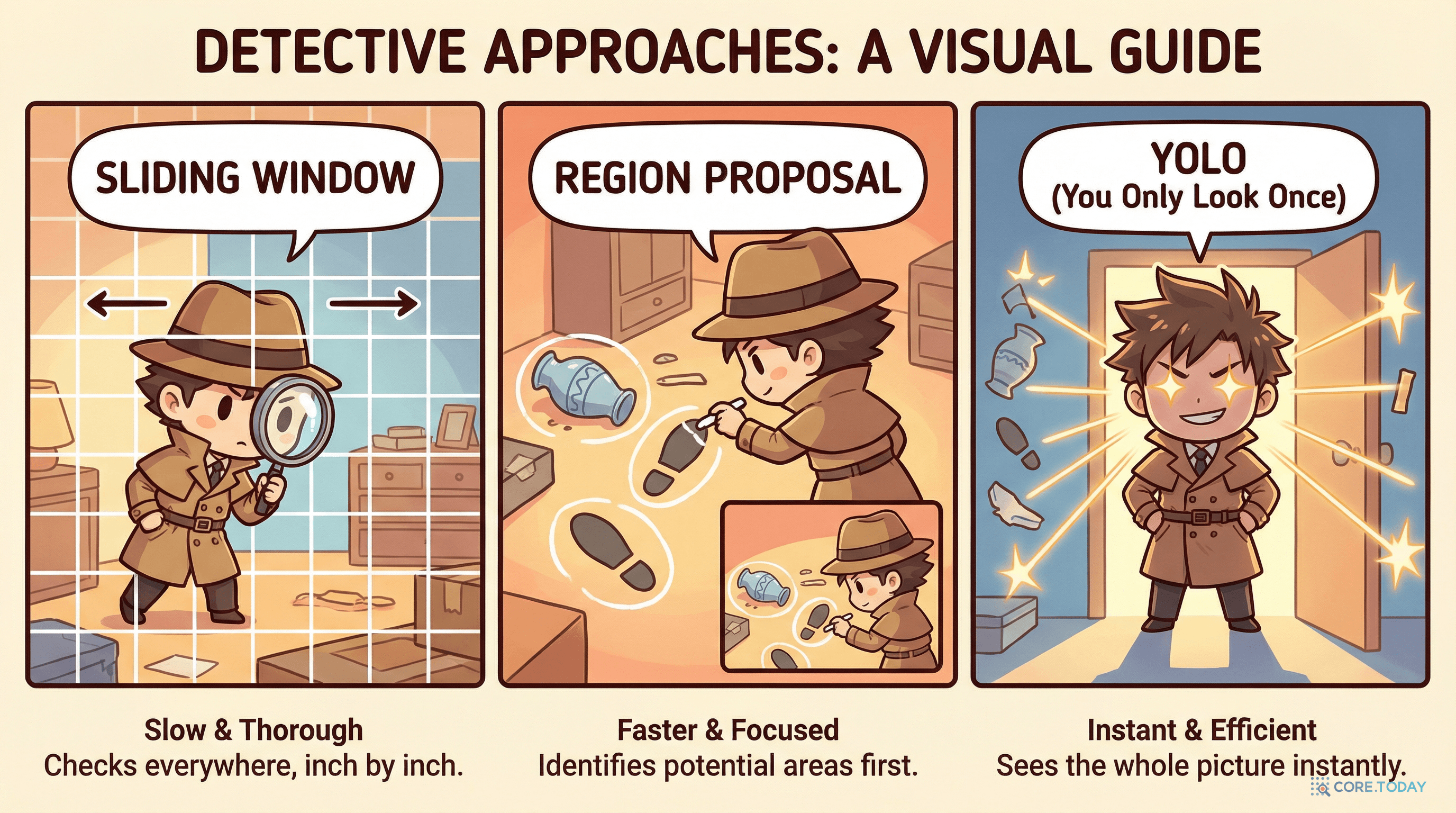
YOLO의 핵심은 놀라울 정도로 단순하다.
기존 방법: "이미지에서 객체가 있을 만한 영역을 찾고 → 각 영역을 분류한다" (2단계)
YOLO: "이미지 전체를 한 번에 보고, 모든 바운딩 박스와 클래스를 동시에 예측한다" (1단계)
어떻게? 객체 검출을 하나의 회귀(regression) 문제로 재정의한 것이다.
분류(classification)는 "이것은 A인가 B인가?"를 묻는다. 이산적인(discrete) 답을 내놓는다. 회귀(regression)는 "이 값은 얼마인가?"를 묻는다. 연속적인(continuous) 숫자를 예측한다.
YOLO는 "이 이미지에서 객체가 어디에 있나?"를 직접 답하기 위해, 이미지 픽셀로부터 바운딩 박스 좌표와 클래스 확률을 직접 예측하는 하나의 신경망을 만들었다. 영역을 제안할 필요도, 각 영역을 따로 분류할 필요도 없다. 입력은 이미지 하나, 출력은 모든 검출 결과. 한 번의 신경망 통과(forward pass)로 끝.
이것이 논문 제목의 의미다. You Only Look Once — 한 번만 본다.
구체적으로 YOLO가 어떻게 작동하는지 살펴보자.
Step 1: 이미지를 S × S 그리드로 나눈다.
YOLO는 입력 이미지를 7 × 7 = 49개의 격자(grid cell)로 나눈다. 각 격자 셀은 이미지의 특정 영역을 "담당"한다. 어떤 객체의 중심점이 특정 셀 안에 떨어지면, 그 셀이 해당 객체를 검출할 책임을 진다.
이 아이디어가 왜 강력한지 생각해보자. 이미지 전체를 수천 개의 후보 영역으로 나누는 대신, 49개의 셀로만 나누고 각 셀에게 자기 영역의 객체를 찾으라고 위임하는 것이다. 마치 49명의 경비원이 각자 맡은 구역만 감시하는 것과 같다.
Step 2: 각 셀이 B개의 바운딩 박스를 예측한다.
각 격자 셀은 B = 2개의 바운딩 박스를 예측한다. 각 바운딩 박스는 5개의 값을 가진다.
신뢰도(confidence)는 두 가지를 동시에 반영한다. "이 박스 안에 객체가 있을 확률"과 "예측된 박스가 실제 객체와 얼마나 잘 맞는지(IOU)". 셀 안에 객체가 없으면 신뢰도는 0에 가까워야 하고, 객체가 있고 박스가 정확하면 1에 가까워야 한다.
왜 한 셀에 2개의 박스를 예측할까? 하나의 셀이 담당하는 영역에 다양한 형태의 객체가 올 수 있기 때문이다. 두 개의 예측기(predictor)가 있으면, 하나는 가로로 긴 객체(예: 자동차)에, 다른 하나는 세로로 긴 객체(예: 사람)에 특화될 수 있다. 논문에서는 이를 "예측기 간 전문화(specialization between predictors)"라고 부른다.
Step 3: 각 셀이 클래스 확률을 예측한다.
각 격자 셀은 또한 C개의 조건부 클래스 확률 을 예측한다. "이 셀에 객체가 있다고 가정할 때, 그 객체가 각 클래스일 확률"이다. Pascal VOC 데이터셋의 경우 C = 20개 클래스(사람, 자동차, 강아지 등)이므로, 20개의 확률값을 예측한다.
중요한 점은, 클래스 확률은 바운딩 박스가 아닌 셀 단위로 예측된다는 것이다. 한 셀이 2개의 바운딩 박스를 예측하지만, 클래스 확률은 하나만 예측한다.
Step 4: 최종 출력 = 7 × 7 × 30 텐서
모든 것을 합치면 YOLO의 출력은 다음과 같다.
각 셀의 30차원 벡터를 풀어보면:
테스트 시에는 바운딩 박스의 신뢰도와 클래스 확률을 곱하여 클래스별 신뢰도 점수를 구한다.
이 점수는 "이 박스 안에 클래스 i의 객체가 있을 확률"과 "그 박스가 실제 객체에 얼마나 잘 맞는지"를 동시에 반영한다.
아래의 인터랙티브 탐색기에서 YOLO의 그리드 시스템을 직접 체험해보자. 격자 셀을 클릭하면 해당 셀의 예측 결과를 확인할 수 있다.
YOLO의 전체 추론 과정을 정리하면 놀라울 정도로 단순하다.
끝이다. R-CNN의 복잡한 파이프라인과 비교해보라. 영역 제안도 없고, 수천 번의 CNN 평가도 없다. Pascal VOC에서 YOLO는 이미지당 98개의 바운딩 박스(7 × 7 × 2)만 예측하면 된다. R-CNN의 ~2,000개 영역 제안에 비하면 1/20 수준이다.
이 단순함이 속도의 비밀이다. 단일 네트워크, 단일 평가, 단일 최적화 목표. 이것이 YOLO의 철학이다.
YOLO의 네트워크 아키텍처는 이미지 분류의 명가 GoogLeNet에서 영감을 받았다. 하지만 GoogLeNet의 복잡한 Inception 모듈 대신, YOLO는 더 단순한 구조를 선택했다. 1 × 1 축소 레이어(reduction layer)를 거친 뒤 3 × 3 합성곱 레이어를 적용하는 패턴을 반복한 것이다.
전체 아키텍처는 24개의 합성곱 층과 2개의 완전연결 층으로 구성된다.
여기서 1 × 1 합성곱의 역할을 이해하는 것이 중요하다. 1 × 1 합성곱은 공간 차원(너비, 높이)은 그대로 두면서 채널 수만 줄이는 역할을 한다. 512개 채널을 256개로 줄인 뒤 3 × 3 합성곱을 적용하면, 3 × 3 합성곱의 입력 채널이 절반이 되어 연산량이 크게 줄어든다. GoogLeNet의 Inception 모듈이 이 아이디어를 처음 도입했고, YOLO는 이를 더 간결하게 활용한 것이다.
YOLO는 마지막 층을 제외한 모든 층에서 Leaky ReLU를 사용한다.
일반 ReLU는 음수 입력에 대해 기울기가 0이 되어 뉴런이 "죽는" 문제가 있다. Leaky ReLU는 음수 영역에서도 0.1이라는 작은 기울기를 유지하여, 모든 뉴런이 학습에 참여할 수 있게 한다. 이것은 특히 바운딩 박스 좌표처럼 음수 값이 나올 수 있는 회귀 문제에서 중요하다.
마지막 층은 선형 활성화 함수(활성화 없음)를 사용한다. 출력이 좌표값과 확률값이므로, 비선형 변환 없이 직접 예측하는 것이 적절하기 때문이다.
YOLO 팀은 속도를 더 극한으로 밀어붙인 Fast YOLO도 만들었다. 아키텍처는 동일하되, 합성곱 층을 24개에서 9개로 줄이고, 각 층의 필터 수도 줄였다. 나머지 학습 파라미터와 테스트 방법은 동일하다.
결과는? 초당 155프레임이라는 경이적인 속도. mAP는 52.7%로 기본 YOLO(63.4%)보다 낮지만, 당시 다른 어떤 실시간 검출기보다 두 배 이상 정확했다.
YOLO의 훈련은 두 단계로 이루어진다.
첫 번째 단계: ImageNet 사전 학습. 처음 20개 합성곱 층에 평균 풀링 층과 완전연결 층을 붙여서, ImageNet 1000개 클래스 분류 과제로 약 1주일간 학습한다. 이 모델은 ImageNet 2012 검증 세트에서 top-5 정확도 88%를 달성했다. 이 단계에서 네트워크는 이미지의 기본적인 특징 — 가장자리, 질감, 형태 — 을 학습한다.
두 번째 단계: 검출 학습으로 전환. 사전 학습된 20개 합성곱 층에 4개의 합성곱 층과 2개의 완전연결 층을 무작위 가중치로 추가한다. 검출은 세밀한 시각 정보가 필요하므로, 입력 해상도를 224 × 224에서 448 × 448로 두 배로 올린다. 그리고 Pascal VOC 2007+2012 데이터셋으로 약 135 에폭 동안 학습한다.
YOLO의 손실 함수는 표면적으로는 단순한 합계제곱오차(sum-squared error)를 사용한다. 계산이 쉽고 최적화가 안정적이기 때문이다. 하지만 실제 손실 함수에는 여러 정교한 설계가 숨어 있다.
문제 1: 대부분의 셀에는 객체가 없다.
7 × 7 = 49개 셀 중 실제로 객체의 중심을 포함하는 셀은 소수다. 나머지 대다수의 셀은 "객체 없음"을 예측해야 한다. 이 불균형 때문에, 객체가 없는 셀의 신뢰도를 0으로 밀어붙이는 기울기가 객체를 포함하는 셀의 기울기를 압도하여 학습을 불안정하게 만들 수 있다.
해법: 두 개의 가중치 파라미터를 도입한다.
이렇게 하면 "어디에 있는가"(좌표)의 정확도에 더 큰 중요도를 부여하면서, "여기에는 없다"라는 신호가 학습을 지배하는 것을 막는다.
문제 2: 큰 박스와 작은 박스의 오차가 동일하게 취급된다.
합계제곱오차는 큰 값의 오차와 작은 값의 오차를 동일하게 취급한다. 하지만 직관적으로, 큰 바운딩 박스에서 10픽셀의 오차는 무시할 만하지만, 작은 바운딩 박스에서 10픽셀의 오차는 치명적이다.
해법: 너비와 높이를 직접 예측하는 대신, 제곱근을 예측한다. 와 를 예측하면, 같은 절대 오차라도 작은 박스에서 더 큰 손실을 발생시킨다. 이는 작은 객체의 검출 정확도를 높이는 효과가 있다.
문제 3: 한 셀에 두 개의 예측기가 있으면 누가 책임질까?
훈련 시, 각 객체에 대해 하나의 예측기만 "책임"을 진다. 어떤 예측기가 책임질지는 현재의 IOU를 기준으로 결정된다. 실제 객체와 가장 높은 IOU를 가진 예측기가 해당 객체의 손실을 담당한다. 이렇게 하면 두 예측기가 서로 다른 크기나 형태의 객체에 자연스럽게 특화된다.
이 모든 것을 합친 YOLO의 손실 함수는 다음 5개 항으로 구성된다.
여기서 는 "이 셀에 객체가 있고 이 예측기가 책임질 때만 1"인 지시 함수다. 이 함수 하나로 누가 무엇에 대해 책임지는지를 명확히 정의한다.
| 파라미터 | 값 | 설명 |
|---|---|---|
| 배치 크기 | 64 | 한 번에 64개 이미지 처리 |
| 모멘텀 | 0.9 | SGD 최적화의 관성 |
| 가중치 감쇠 | 0.0005 | 과적합 방지를 위한 L2 정규화 |
| 드롭아웃 | 0.5 | 첫 번째 FC 층 이후 적용 |
| 총 에폭 | ~135 | VOC 2007 + 2012 데이터 사용 |
| λcoord | 5 | 좌표 손실 가중치 (높임) |
| λnoobj | 0.5 | 비객체 신뢰도 손실 가중치 (낮춤) |
학습률 스케줄도 정교했다. 처음에 에서 로 서서히 올린 뒤, 75 에폭 동안 , 30 에폭 동안 , 마지막 30 에폭 동안 로 줄였다. 처음부터 높은 학습률을 사용하면 불안정한 기울기로 모델이 발산하기 때문이다.
데이터 증강(data augmentation)도 적극적으로 활용했다. 이미지를 원본 크기의 최대 20%까지 무작위로 스케일링하고 이동시키며, HSV 색공간에서 노출과 채도를 최대 1.5배까지 조정했다.
YOLO의 실험 결과는 당시 연구 커뮤니티에 충격을 안겼다. Pascal VOC 2007 데이터셋에서의 결과를 살펴보자.
| 실시간 검출기 | mAP | FPS | 학습 데이터 |
|---|---|---|---|
| 100Hz DPM | 16.0 | 100 | VOC 2007 |
| 30Hz DPM | 26.1 | 30 | VOC 2007 |
| Fast YOLO | 52.7 | 155 | VOC 2007+2012 |
| YOLO | 63.4 | 45 | VOC 2007+2012 |
| 비실시간 검출기 | mAP | FPS | 학습 데이터 |
|---|---|---|---|
| Fastest DPM | 30.4 | 15 | VOC 2007 |
| R-CNN Minus R | 53.5 | 6 | VOC 2007 |
| Fast R-CNN | 70.0 | 0.5 | VOC 2007+2012 |
| Faster R-CNN VGG-16 | 73.2 | 7 | VOC 2007+2012 |
| Faster R-CNN ZF | 62.1 | 18 | VOC 2007+2012 |
| YOLO VGG-16 | 66.4 | 21 | VOC 2007+2012 |
핵심 관찰:
Fast YOLO는 가장 빠른 범용 객체 검출기다. 155 FPS로, mAP 52.7%는 당시 다른 어떤 실시간 검출기보다 두 배 이상 정확했다.
YOLO는 실시간이면서 높은 정확도를 달성한다. 45 FPS에 mAP 63.4%. Faster R-CNN VGG-16의 73.2%보다는 낮지만, 속도는 6배 이상 빠르다.
속도-정확도 트레이드오프가 완전히 바뀌었다. Fast R-CNN은 70.0% mAP를 달성하지만 0.5 FPS, 즉 이미지 한 장에 2초가 걸린다. YOLO는 약간 낮은 정확도로 90배 빠르다.
이 결과를 직관적으로 비교해보자.
YOLO와 Fast R-CNN의 에러 패턴을 비교한 결과는 매우 흥미롭다.
두 모델의 에러 패턴은 극명하게 다르다.
Fast R-CNN의 가장 큰 약점은 배경 오류(13.6%)다. 객체가 없는 배경을 객체로 잘못 검출하는 "거짓 양성(false positive)" 비율이 높다. R-CNN은 영역 제안을 먼저 하기 때문에, 배경을 포함하는 영역이 제안되면 이를 걸러내기 어렵다. 전체 맥락을 보지 못하기 때문이다.
YOLO의 가장 큰 약점은 위치 오류(19.0%)다. 객체를 올바르게 인식하지만, 바운딩 박스의 위치가 부정확한 경우가 많다. 이것은 7 × 7이라는 비교적 조밀하지 않은(coarse) 그리드로부터 위치를 예측하기 때문에 자연스러운 결과다.
반면 YOLO의 배경 오류는 4.75%에 불과하다. Fast R-CNN의 13.6%에 비해 약 1/3 수준. Fast R-CNN이 배경을 잘못 검출할 확률이 YOLO의 거의 3배라는 의미다. 왜 그럴까? YOLO는 이미지 전체를 한 번에 보기 때문에, 배경과 객체의 맥락적 관계를 자연스럽게 학습한다. 반면 R-CNN은 작은 패치만 보기 때문에 배경 맥락을 놓치기 쉽다.
이 상호보완적인 에러 패턴은 흥미로운 가능성을 열었다. 두 모델을 결합하면 어떨까?
Fast R-CNN이 예측한 각 바운딩 박스에 대해, YOLO가 같은 영역에서 비슷한 박스를 예측했는지 확인한다. YOLO가 동의하면(비슷한 박스를 예측했으면) 신뢰도를 높이고, 동의하지 않으면 낮추는 것이다. 직관적으로, YOLO의 낮은 배경 오류를 활용하여 Fast R-CNN의 거짓 양성을 제거하는 전략이다.
| 모델 | 단독 mAP | 결합 mAP | 향상 |
|---|---|---|---|
| Fast R-CNN (최고 성능) | 71.8 | — | 기준 |
| + Fast R-CNN (2007 data) | 66.9 | 72.4 | +0.6 |
| + Fast R-CNN (VGG-M) | 59.2 | 72.4 | +0.6 |
| + Fast R-CNN (CaffeNet) | 57.1 | 72.1 | +0.3 |
| + YOLO | 63.4 | 75.0 | +3.2 |
결과가 명확하다. Fast R-CNN의 다른 변형들을 추가해도 mAP가 0.3~0.6%밖에 올라가지 않지만, YOLO를 추가하면 3.2%나 상승한다. 이것은 단순한 앙상블 효과가 아니라, YOLO가 Fast R-CNN과 근본적으로 다른 종류의 에러를 만들기 때문이다. 논문 원문의 표현을 빌리면:
"YOLO로 인한 향상은 단순한 모델 앙상블의 부산물이 아니다. 다른 버전의 Fast R-CNN을 결합해도 거의 효과가 없다는 사실이 이를 증명한다. YOLO가 테스트 시 다른 종류의 실수를 하기 때문에, Fast R-CNN의 성능을 끌어올리는 데 매우 효과적인 것이다."
Pascal VOC 2012 테스트 세트에서 YOLO는 57.9% mAP를 기록했다. 최고 성능은 아니지만, Fast R-CNN + YOLO 결합 모델은 70.7% mAP로 리더보드 4위에 올랐다. 주목할 점은, YOLO가 유일한 실시간 검출기라는 것이다.
YOLO는 bottle, sheep, tv/monitor 같은 작은 객체 카테고리에서 R-CNN 대비 8~10% 낮은 성능을 보였다. 하지만 cat, train 같은 카테고리에서는 더 높은 성능을 달성했다.
가장 놀라운 결과는 일반화 실험에서 나왔다. 자연 이미지(사진)로 학습한 모델을 예술 작품에 적용하면 어떻게 될까?
연구진은 Picasso Dataset과 People-Art Dataset이라는 두 예술 작품 데이터셋에서 "사람 검출" 성능을 테스트했다.
| 모델 | VOC 2007 AP | Picasso AP | People-Art AP |
|---|---|---|---|
| YOLO | 59.2 | 53.3 | 45 |
| R-CNN | 54.2 | 10.4 | 26 |
| DPM | 43.2 | 37.8 | 32 |
| Poselets | 36.5 | 17.8 | — |
R-CNN은 VOC 2007에서 54.2%의 높은 AP를 보이지만, Picasso 데이터셋에서는 10.4%로 급락한다. AP가 5분의 1로 줄어든 것이다. R-CNN은 Selective Search가 자연 이미지에 최적화되어 있어, 예술 작품의 비현실적인 색상과 형태에서 좋은 영역 제안을 만들지 못하기 때문이다.
반면 YOLO는 VOC 2007에서 59.2%, Picasso에서 53.3%로, 성능 하락이 상대적으로 적다. YOLO는 객체의 크기와 형태, 그리고 객체 간의 관계를 학습하기 때문이다. 예술 작품과 사진은 픽셀 수준에서는 매우 다르지만, 크기와 형태, 배치에서는 비슷하다. YOLO는 바로 이 고수준(high-level) 특징을 포착하는 것이다.
논문은 YOLO의 한계를 솔직하게 인정한다. 이 정직함이 오히려 이 논문의 신뢰성을 높인다.
각 그리드 셀은 2개의 바운딩 박스만 예측하고, 1개의 클래스만 가질 수 있다. 이 제약은 작은 객체들이 모여 있는 경우 치명적이다. 예를 들어, 하늘을 나는 새 떼(flock of birds)가 있다면, 한 셀 안에 여러 마리의 새가 들어올 수 있다. 하지만 그 셀은 최대 2개의 박스만 예측할 수 있으므로, 나머지 새들은 검출하지 못한다.
모델이 학습 데이터에서 본 적 없는 비정상적인 종횡비(aspect ratio)의 객체에 대해 일반화하기 어렵다. 예를 들어, 매우 길고 얇은 객체나 매우 넓은 객체를 처음 보면 바운딩 박스 예측이 부정확해질 수 있다.
YOLO는 여러 번의 다운샘플링을 거쳐 최종적으로 7 × 7 크기의 특징 맵을 생성한다. 이 조밀하지 않은(coarse) 특징 맵으로부터 바운딩 박스를 예측하기 때문에, 세밀한 위치 정보가 손실된다. 이것이 YOLO의 높은 위치 오류의 근본 원인이다.
, 예측으로 부분적으로 해결했지만, 여전히 손실 함수는 큰 박스와 작은 박스의 오차를 동등하게 취급하는 경향이 있다. 큰 박스에서의 작은 오차는 일반적으로 무해하지만, 작은 박스에서의 같은 크기의 오차는 IOU에 훨씬 큰 영향을 미친다.
이러한 한계들은 이후 YOLO의 진화 과정에서 하나씩 해결되어 나간다.
우리가 지금까지 살펴본 원조 YOLO다. Joseph Redmon이 워싱턴 대학교 박사과정 중 만들었으며, 객체 검출을 회귀 문제로 재정의하여 실시간 처리를 가능하게 했다. CVPR 2016에서 발표되었다.
Joseph Redmon과 Ali Farhadi가 발표한 후속작. 논문 제목이 "YOLO9000: Better, Faster, Stronger"다. 핵심 개선사항:
YOLOv3는 Redmon과 Farhadi의 마지막 공동 작업이다. 논문 제목이 "YOLOv3: An Incremental Improvement"라는 겸손한 이름이었지만, 기여는 컸다.
YOLOv3-608은 57.9% mAP@0.5로 당시 Focal Loss(RetinaNet)과 동등한 정확도를 4배 빠르게 달성했다.
2020년 2월, YOLO의 창시자 Joseph Redmon은 트위터에 이런 글을 남겼다.
"나는 컴퓨터 비전 연구를 중단했다. 내 연구가 사회에 미치는 부정적인 영향 — 특히 군사적 활용과 프라이버시 침해 — 을 무시할 수 없게 되었다."
그가 만든 YOLO가 드론의 표적 인식, 대규모 감시 시스템, 군사 무기의 자동 조준 등에 활용되는 것을 보면서, 자신의 연구가 세상을 더 좋은 곳으로 만들고 있는지 의문을 품게 된 것이다. 이 결정은 AI 연구 커뮤니티에 큰 반향을 일으켰다. 기술의 발전이 윤리적 책임과 함께 가야 한다는 중요한 메시지였다.
하지만 YOLO의 이야기는 여기서 끝나지 않았다. 오픈소스의 힘으로 다른 연구자들이 그 뒤를 이었다.
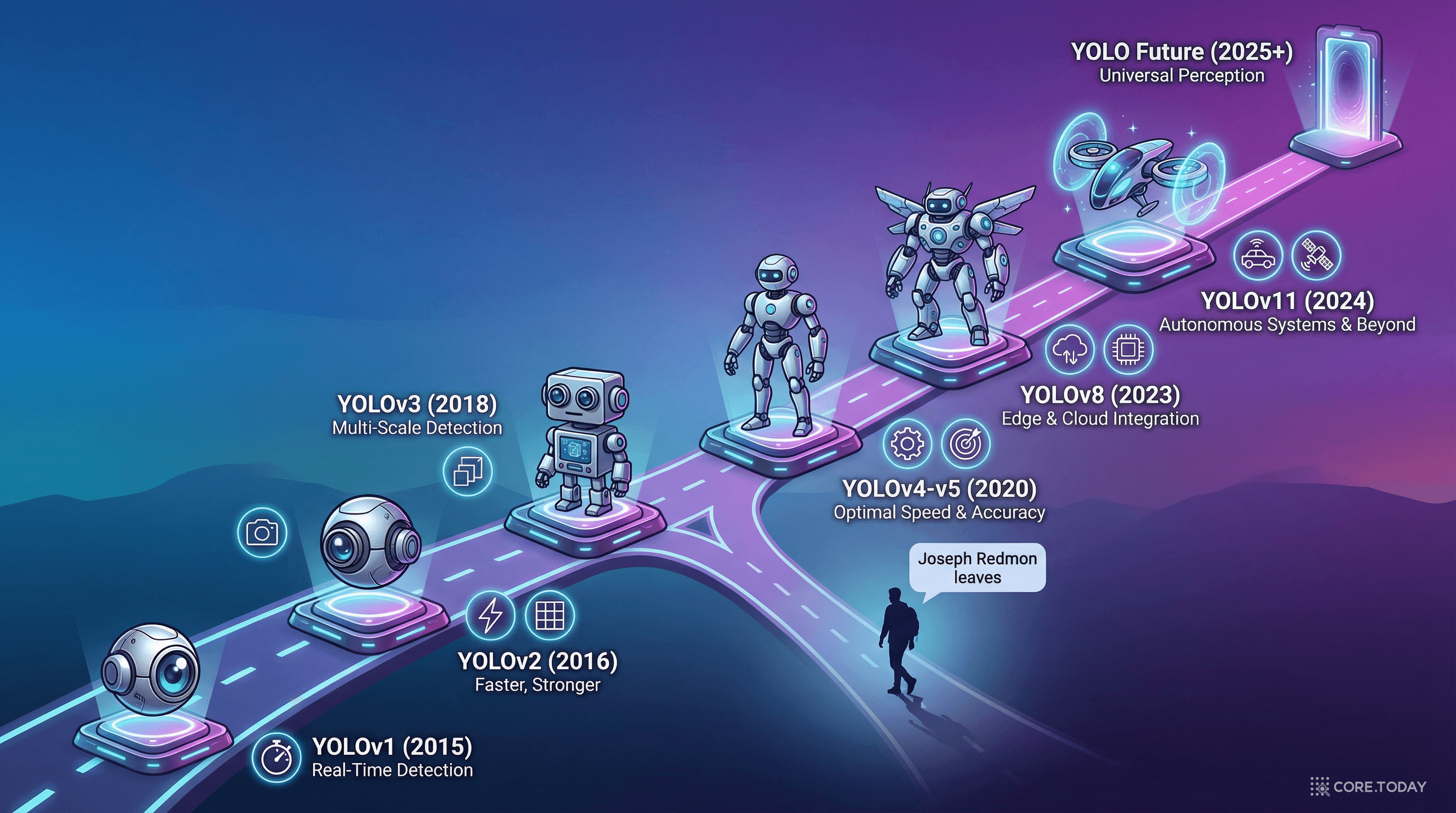
| 버전 | 연도 | 주요 기여자 | 핵심 혁신 |
|---|---|---|---|
| YOLOv4 | 2020 | Alexey Bochkovskiy | CSPDarknet53, Mish 활성화, Mosaic 증강 |
| YOLOv5 | 2020 | Ultralytics (Glenn Jocher) | PyTorch 기반 구현, 자동 앵커, Focus 구조 |
| YOLOX | 2021 | Megvii (旷视) | 앵커 프리(Anchor-free) 설계 |
| YOLOv6 | 2022 | Meituan (美团) | EfficientRep 백본, Task-aligned Head |
| YOLOv7 | 2022 | WongKinYiu | E-ELAN, 모델 스케일링 전략 |
| YOLOv8 | 2023 | Ultralytics | 앵커 프리, C2f 모듈, 통합 프레임워크 |
| YOLOv9 | 2024 | WongKinYiu | PGI, GELAN 아키텍처 |
| YOLOv10 | 2024 | Tsinghua Univ. | NMS-free 학습, 이중 헤드 |
| YOLOv11 | 2024 | Ultralytics | C3k2 블록, 경량 헤드 설계 |
| YOLO-World | 2024 | Tencent | 오픈 보캐뷸러리 검출 (텍스트 프롬프트) |
원래 YOLO는 C로 작성된 Darknet 프레임워크 위에서 동작했다. YOLOv5부터 PyTorch 기반으로 전환되면서 접근성이 폭발적으로 높아졌고, 산업계에서의 채택도 가속화되었다.
특히 주목할 진화 방향은 다음과 같다.
앵커에서 앵커 프리로. YOLOv1은 앵커 박스 없이 직접 예측했다. YOLOv2~v4는 앵커를 도입했다. YOLOX와 YOLOv8부터 다시 앵커 프리로 회귀했다. 역사가 한 바퀴 돈 셈이다.
NMS에서 NMS-free로. 원래 YOLO의 후처리에 필수적이었던 NMS(Non-Maximum Suppression)를 YOLOv10에서 학습 가능한 방식으로 대체했다. 추론 파이프라인이 더 단순해졌다.
오픈 보캐뷸러리로. YOLO-World는 텍스트 프롬프트를 사용하여 학습 데이터에 없는 새로운 카테고리의 객체도 검출할 수 있다. CLIP과 유사한 비전-언어 연결을 YOLO에 통합한 것이다.
2015년의 논문 한 편이 시작한 혁명은 10년이 지난 지금, 놀라울 정도로 광범위한 영역에 침투해 있다.
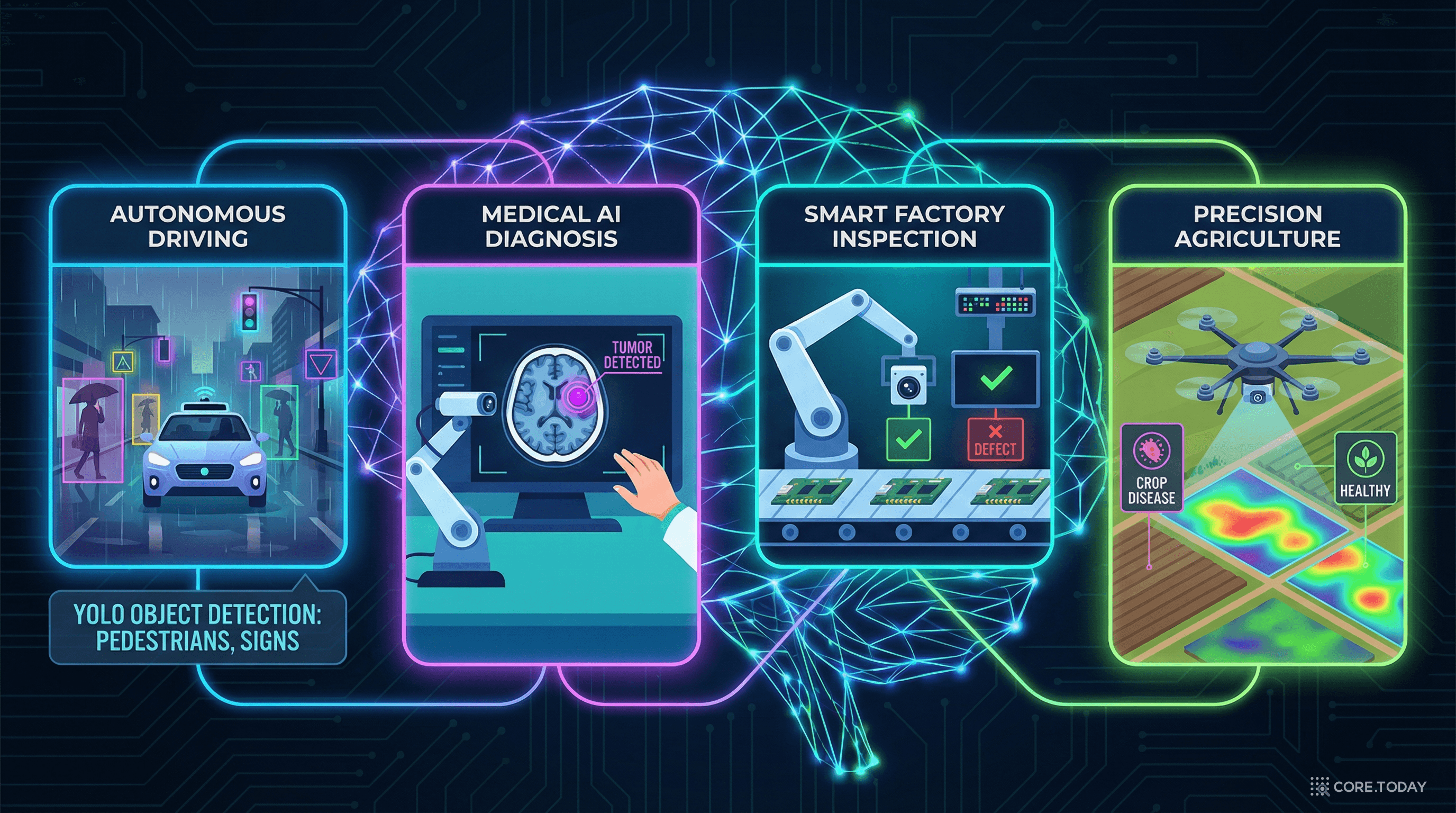
자율주행은 YOLO의 가장 대표적인 응용 분야다. 테슬라, 현대, 웨이모 등의 자율주행 시스템에서 YOLO 계열 모델은 보행자, 차량, 신호등, 표지판을 실시간으로 검출한다. 자율주행에서는 정확도도 중요하지만, 지연 시간(latency)이 더 중요하다. 시속 60km로 달리는 차량은 1초에 약 17미터를 이동한다. 검출이 0.1초만 늦어져도 1.7미터를 더 가는 것이다. YOLO의 실시간 성능은 이 맥락에서 결정적인 이점이 된다.
의료 분야에서 YOLO 계열 모델은 X-ray, CT, MRI 영상에서 종양, 골절, 이상 소견을 검출하는 데 사용된다. 특히 대장내시경 영상에서 용종(polyp)을 실시간으로 검출하는 시스템은 이미 여러 병원에서 운영 중이다. 의사가 놓칠 수 있는 작은 병변을 AI가 실시간으로 표시해주는 것이다.
공장의 생산 라인에서 YOLO는 제품 외관 검사에 널리 사용된다. 초당 수십 개의 제품이 지나가는 컨베이어 벨트에서, 카메라가 촬영한 이미지를 YOLO가 실시간으로 분석하여 스크래치, 변형, 이물질 등의 불량을 검출한다. 기존에 사람이 눈으로 하던 품질 검사를 AI가 더 빠르고 정확하게 수행하는 것이다.
농업 분야에서는 드론에 탑재된 카메라와 YOLO를 결합하여 병충해 감지, 잡초 식별, 작물 생육 모니터링을 수행한다. 넓은 농경지를 드론이 비행하면서 실시간으로 문제를 발견하고, 해당 위치만 정밀 농약을 살포하는 "정밀 농업"이 가능해진 것이다.
2026년, YOLO의 가장 중요한 트렌드는 엣지(Edge) 배포다. YOLOv8-nano 같은 경량 모델은 스마트폰, IoT 디바이스, 라즈베리 파이 위에서도 실시간으로 동작한다. 클라우드 서버에 이미지를 보내지 않고도 기기 자체에서 검출이 가능하기 때문에, 개인정보 보호와 네트워크 독립성 측면에서 큰 장점이 있다.
NPU(Neural Processing Unit)를 탑재한 최신 모바일 칩(Qualcomm Snapdragon, Apple Neural Engine, 삼성 Exynos)은 YOLO 추론을 하드웨어 수준에서 가속한다. 우리가 매일 사용하는 스마트폰 카메라의 실시간 얼굴 인식, 문서 스캔, AR 필터 등의 이면에 YOLO의 DNA가 흐르고 있다.
Joseph Redmon이 던진 질문은 10년이 지난 지금 더 무거워졌다. YOLO 기술은 범죄 예방과 공공 안전을 위한 감시 시스템에도 사용되지만, 대규모 프라이버시 침해의 도구가 될 수도 있다. 군사 드론의 자동 표적 인식에도 사용된다. 기술 자체는 중립적이지만, 그것을 어떻게 사용하느냐는 우리 사회가 답해야 할 질문이다.
YOLO 논문을 관통하는 키워드는 단순함(simplicity)이다.
기존 시스템이 영역 제안, 특징 추출, 분류, 후처리라는 복잡한 파이프라인을 쌓아올리는 동안, YOLO는 "한 번에 전부 보자"라는 놀라울 정도로 단순한 아이디어를 제시했다. 이미지 전체를 하나의 신경망에 넣고, 하나의 텐서로 모든 검출 결과를 출력한다.
이 단순함은 세 가지 혁신적 결과를 가져왔다.
첫째, 속도. 단일 네트워크 평가로 초당 45~155프레임. 실시간 비디오 처리가 가능해졌다.
둘째, 전역 추론. 이미지 전체를 보기 때문에 맥락을 이해하고, 배경 오류를 현저히 줄였다.
셋째, 일반화. 객체의 형태와 관계를 학습하기 때문에, 자연 이미지에서 학습한 모델이 예술 작품에서도 작동한다.
물론 YOLO는 완벽하지 않았다. 작은 객체 검출, 위치 정확도, 그리드 제약 등의 한계가 있었다. 하지만 그 한계들은 이후 10년간의 연구를 통해 하나씩 극복되었고, YOLO는 v1에서 v11까지 진화하며 컴퓨터 비전의 산업 표준이 되었다.
2026년 오늘, 당신이 횡단보도를 건널 때 옆을 지나가는 자율주행차, 병원에서 CT를 촬영할 때 이상 소견을 표시하는 AI, 공장에서 불량품을 걸러내는 로봇, 드론이 농경지를 모니터링하는 장면 — 이 모든 곳에 YOLO의 DNA가 흐르고 있다.
한 번만 봤을 뿐인데, 세상이 바뀌었다.



