TECH BLOG
기술 블로그
AI 기술 인사이트와 엔지니어링 경험을 공유합니다.
ALL POSTS
모든 포스트

AWS Secrets Manager 완전 정복: 비밀번호를 코드에 넣지 않는 법
GitHub에 DB 비밀번호가 올라갔다. 그 순간 모든 것이 시작된다. 환경변수부터 AWS Parameter Store, Secrets Manager까지 — 비밀 관리의 단계별 진화를 코드와 함께 풀어본다. 자동 로테이션, Lambda 통합, 최소 권한 원칙까지.
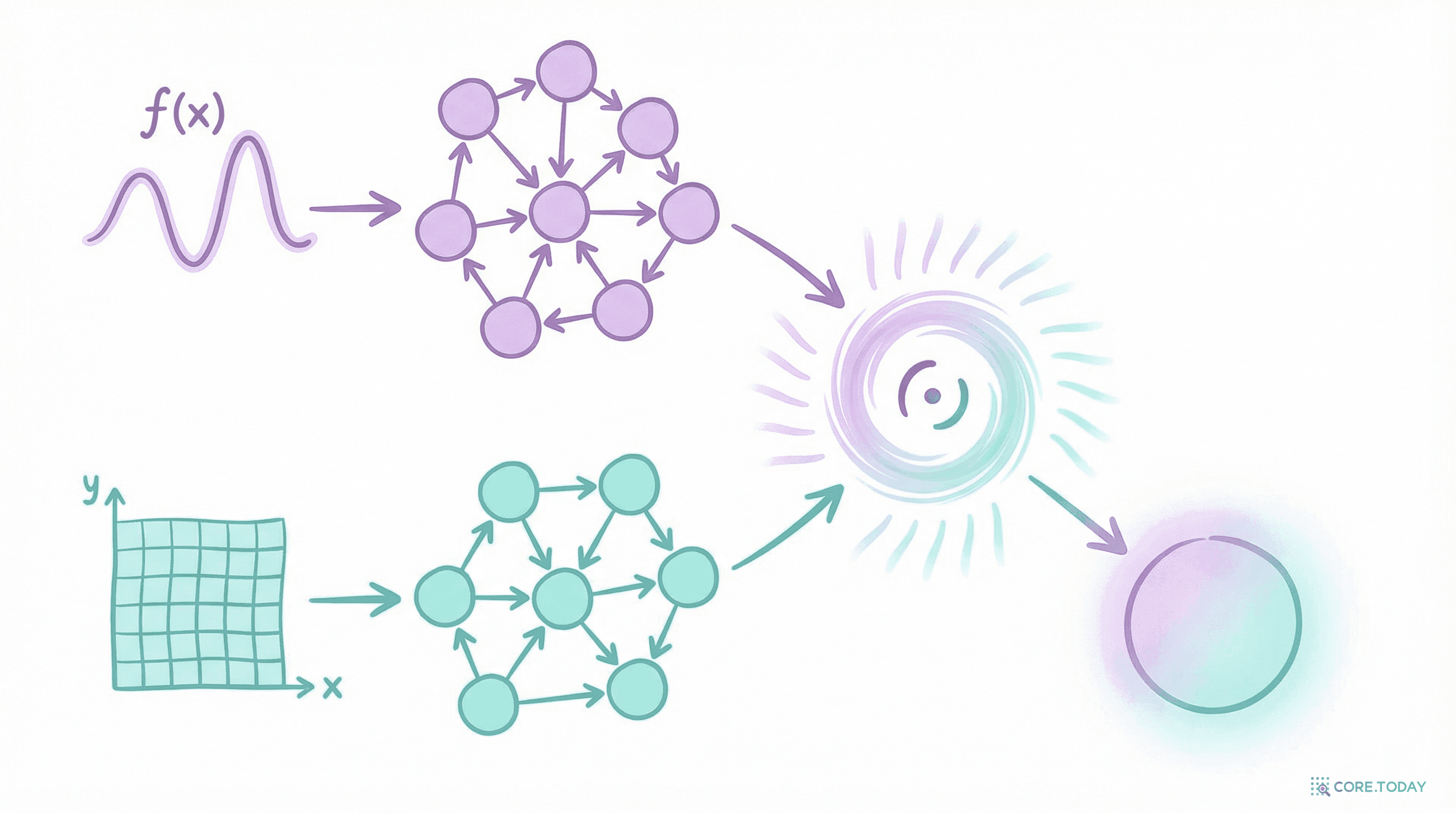
함수를 먹고 함수를 뱉는다 — DeepONet 완전 해부
1995년 증명된 '신경망으로 임의의 연산자를 근사할 수 있다'는 정리가, 25년 뒤 DeepONet으로 실현됐다. Branch Net과 Trunk Net의 우아한 이중 구조가 함수에서 함수로의 매핑을 학습하는 원리를 완전 해부한다.
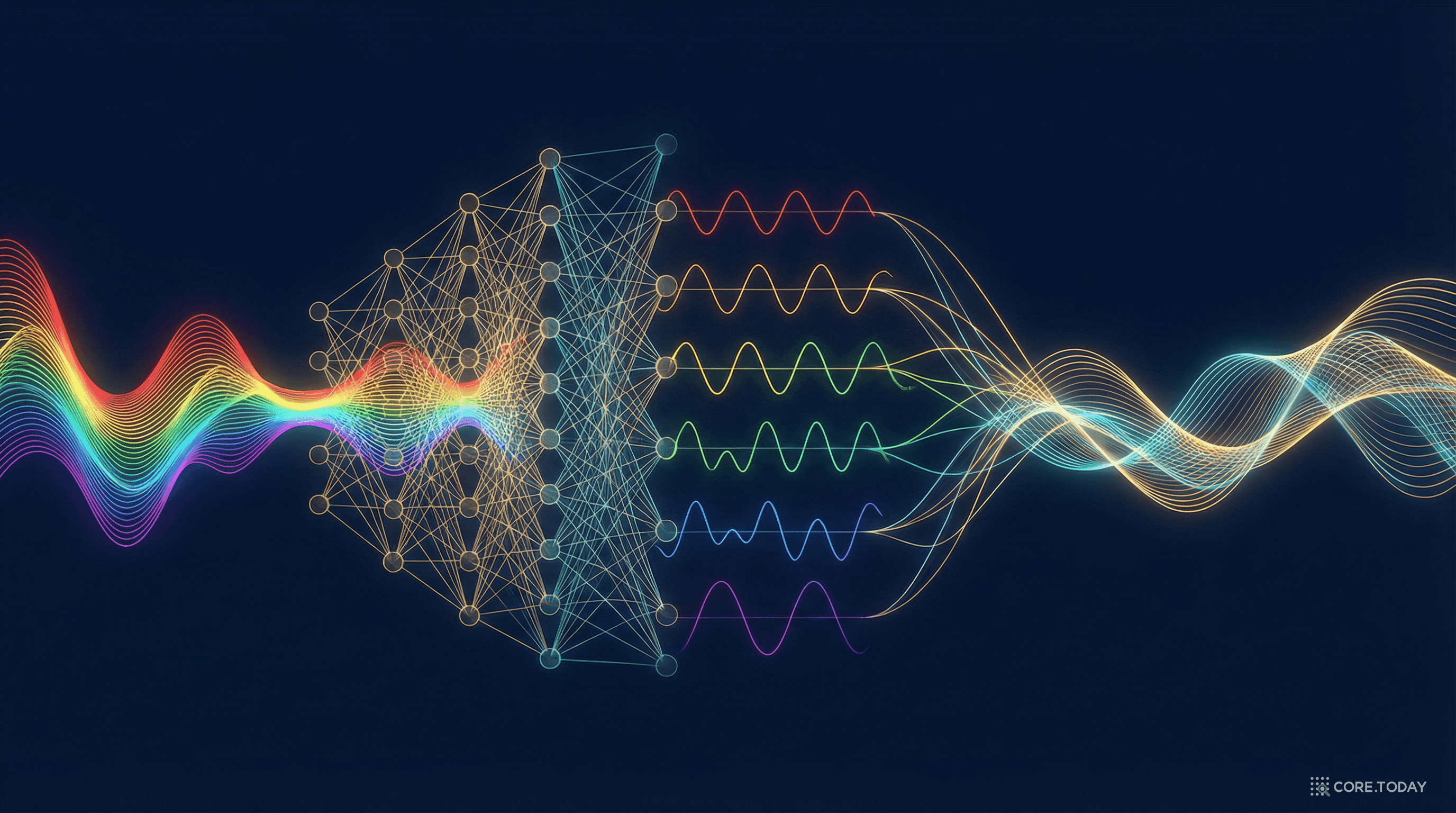
주파수의 눈으로 물리를 본다 — Fourier Neural Operator 완전 해부
하나의 PDE를 푸는 데 수 시간이 걸리던 시뮬레이션을, 학습 한 번으로 수천 가지 조건에 대해 밀리초 만에 답하게 만든 FNO. 푸리에 변환의 직관부터 아키텍처의 핵심, 실전 사례까지 빠짐없이 풀어본다.
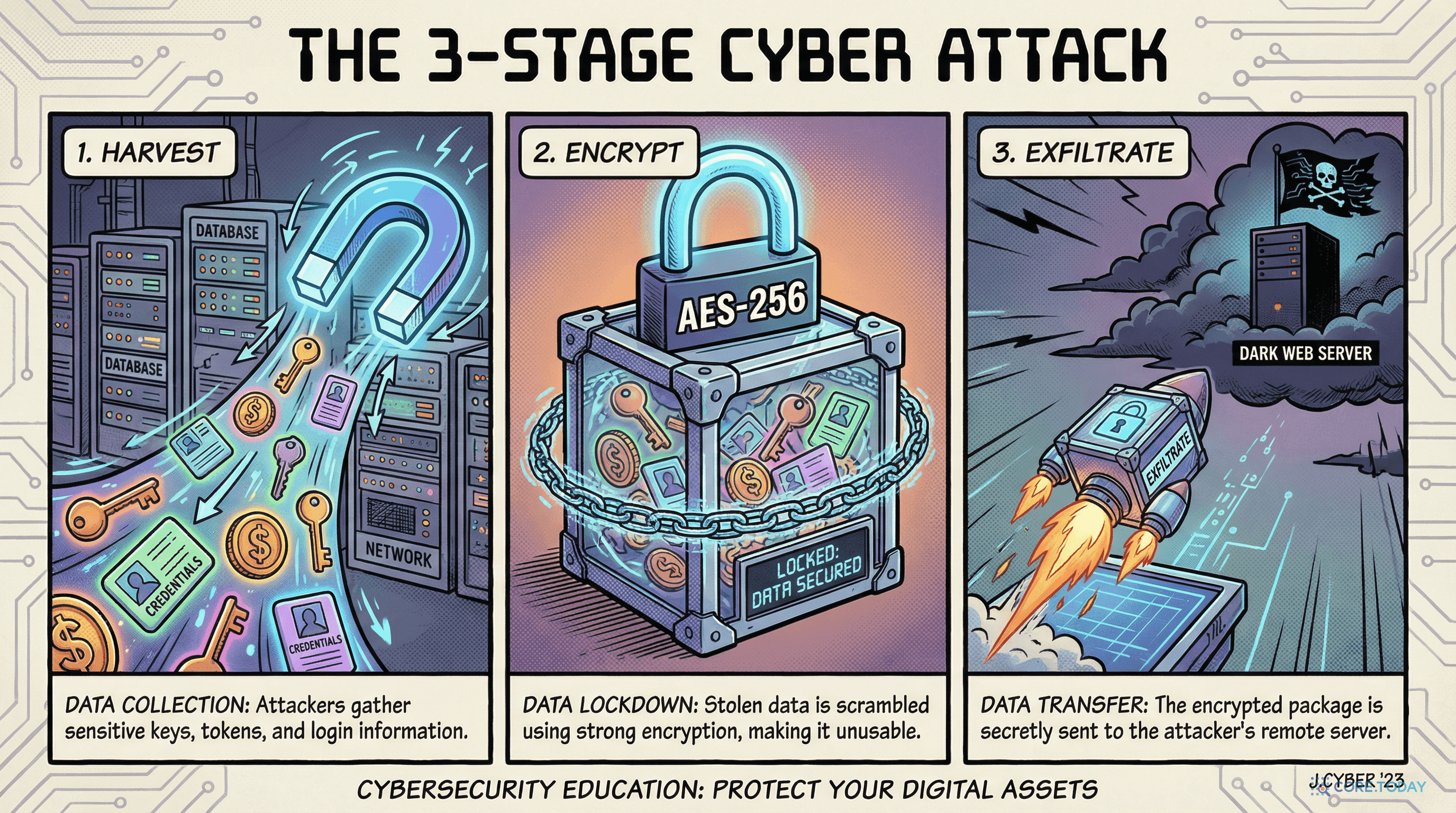
당신의 AI 게이트웨이가 백도어였다 — LiteLLM 공급망 공격의 모든 것
2026년 3월, AI 개발자 필수 도구 LiteLLM이 공급망 공격으로 백도어에 감염됐습니다. Python 인터프리터가 시작되는 순간 모든 인증정보가 탈취되는 3단계 악성코드의 전모를 해부합니다.

Amazon Bedrock 완전 정복: AI 모델을 '골라 쓰는' 시대의 시작
GPU를 사서 모델을 학습시키던 시대에서, API 한 줄로 세계 최고의 AI 모델을 바로 쓰는 시대로. Bedrock이 왜 탄생했고, 어떤 모델을 제공하며, 직접 호스팅·OpenAI API·Azure OpenAI와 무엇이 다른지를 실전 관점에서 풀어본다.
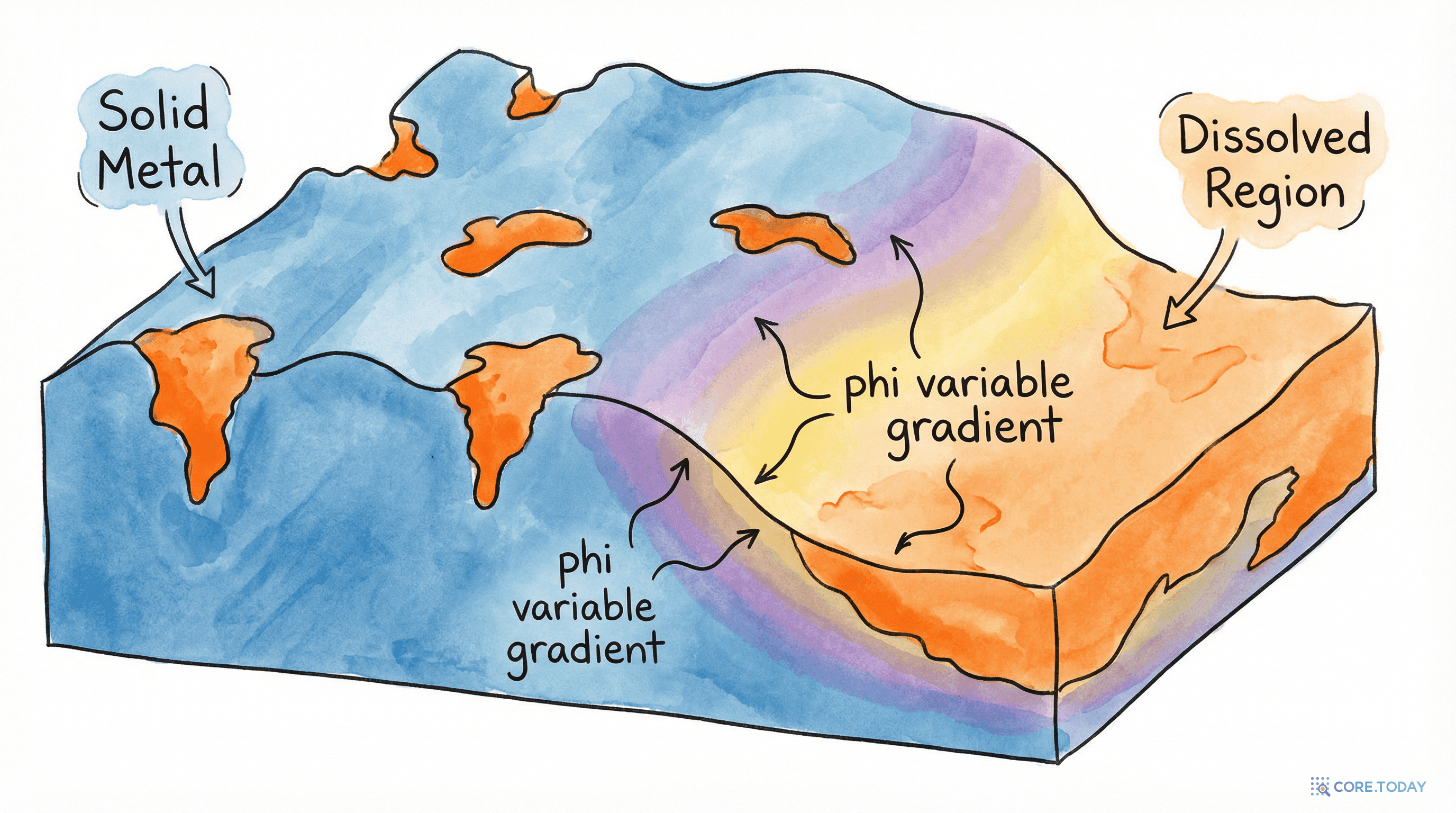
얼음이 녹고, 금속이 부식되고, 균열이 자라는 수학 — 상장 방법의 모든 것
물이 어는 경계, 금속이 녹스는 전선, 합금이 분리되는 면 — 자연은 '경계'로 가득하다. 경계를 명시적으로 추적하는 대신 연속 필드로 표현하는 상장 방법이, 재료과학에서 부식 예측까지 어떻게 혁신을 만들고 있는지를 풀어본다.
AWS Route 53 완전 정복: 도메인 이름 하나로 전 세계를 연결하는 법
브라우저에 'google.com'을 치면 무슨 일이 벌어질까? DNS는 인터넷의 전화번호부다. AWS Route 53은 이 전화번호부를 글로벌 규모로 관리하면서, 트래픽 라우팅과 장애 감지까지 한다. 도메인 등록부터 실전 아키텍처까지, Route 53의 모든 것을 풀어본다.
AI에게 물리법칙을 가르치다 — Physics-Informed Neural Networks의 모든 것
데이터만으로는 부족하고, 시뮬레이션만으로는 느리다. 물리법칙을 손실함수에 녹인 PINN이 과학과 공학의 난제를 어떻게 풀어가는지, 탄생 배경부터 최신 사례까지 쉽고 깊게 살펴본다.

AutoHarness 논문 해설 — AI가 스스로 '규칙 위반 방지 코드'를 만든다
Gemini-2.5-Flash 체스 대회 패배의 78%가 '반칙'이었다. Google DeepMind의 AutoHarness 논문은 LLM이 스스로 규칙 검증 코드를 작성해 이 문제를 해결한다. 작은 모델이 큰 모델을 이기는 역전극의 비밀.