블로그로 돌아가기
쿠버네티스KubernetesK8s컨테이너오케스트레이션DevOps
쿠버네티스 완전 정복: Google이 15년간 숨겨둔 비밀 병기의 모든 것
Google이 내부에서 15년간 운영한 Borg의 경험이 어떻게 쿠버네티스로 오픈소스화되었는지, 핵심 개념은 무엇이며, 왜 전 세계 기업의 사실상 표준이 되었는지를 역사·원리·실전 사례로 풀어본다.
코어닷투데이2026-02-0734분
Google이 내부에서 15년간 운영한 Borg의 경험이 어떻게 쿠버네티스로 오픈소스화되었는지, 핵심 개념은 무엇이며, 왜 전 세계 기업의 사실상 표준이 되었는지를 역사·원리·실전 사례로 풀어본다.
쿠버네티스(Kubernetes) 는 그리스어 κυβερνήτης — "조타수, 키잡이"라는 뜻이다. 컨테이너(화물)를 실은 배를 안전하게 목적지까지 이끄는 사람. Docker의 고래 로고가 컨테이너를 운반한다면, 쿠버네티스의 조타 바퀴 로고는 그 운반을 지휘한다.
이전 글에서 ECS가 AWS 생태계 안에서 컨테이너 오케스트레이션을 해결한다고 설명했다. 쿠버네티스는 같은 문제를 클라우드에 종속되지 않는 방식으로 풀었다. AWS, GCP, Azure, 온프레미스 — 어디서든 같은 방식으로 컨테이너를 관리할 수 있다.
하지만 쿠버네티스는 하루아침에 탄생하지 않았다. 그 뿌리는 Google이 15년간 비공개로 운영한 내부 시스템에 있다.
2000년대 초반의 Google을 상상해 보자. 검색 서비스가 폭발적으로 성장하고, Gmail(2004), Maps(2005), YouTube 인수(2006)가 이어진다. 이 모든 서비스가 수십만 대의 서버에서 돌아가야 했다.
일반 기업의 서버 관리와는 차원이 달랐다:
2003~2004년, Google은 이 문제를 해결하기 위해 Borg를 개발했다. 이름은 Star Trek의 외계 종족에서 따왔다 — "저항은 무의미하다(Resistance is futile)." 일단 Borg가 클러스터를 관리하기 시작하면, 인간이 개입할 필요가 없다는 뜻이다.
Google은 10년 넘게 Borg를 비공개로 운영하다가, 2015년 EuroSys에서 "Large-scale cluster management at Google with Borg" (Abhishek Verma 등) 논문을 발표했다. 이 논문은 컨테이너 오케스트레이션의 사실상의 교과서다.
Borg의 핵심 설계 원칙:
1. 선언적 관리(Declarative Management)
관리자가 "서버 A에서 프로세스를 시작하라"(명령형)고 하는 대신, "이 작업이 항상 3개 실행되어야 한다"(선언형)고 선언한다. Borg가 현재 상태를 원하는 상태로 맞춰간다.
2. 높은 자원 활용률
Borg는 bin-packing과 자원 재활용으로 서버 활용률을 극대화했다. 논문에 따르면 Borg가 없었다면 Google은 20~30% 더 많은 서버가 필요했을 것이다. 수십만 대 규모에서 이것은 수십억 달러의 절감이다.
3. 자동 복구
서버가 고장 나면 Borg가 해당 서버의 작업을 자동으로 다른 서버로 이동시킨다. 수만 대의 서버 중 매일 수백 대가 장애를 일으켜도, 서비스는 영향을 받지 않는다.
4. 두 가지 워크로드 유형
Borg는 이 두 유형을 같은 서버에서 혼합 실행하되, 프로덕션 워크로드에 우선권을 줬다.
Google은 Borg의 한계를 개선하기 위해 2013년에 Omega 시스템에 대한 논문 "Omega: flexible, scalable schedulers for large compute clusters" (Schwarzkopf 등, EuroSys 2013)을 발표했다.
Omega의 핵심 혁신은 공유 상태 스케줄링(shared-state scheduling) 이다. Borg가 단일 중앙 스케줄러를 사용한 반면, Omega는 여러 스케줄러가 클러스터 상태를 공유하며 병렬로 스케줄링 결정을 내린다. 이 아이디어는 쿠버네티스의 스케줄러 설계에 영향을 미쳤다.
2014년 중반, Google에서 놀라운 일이 일어났다. Borg와 Omega의 핵심 엔지니어들 — Joe Beda, Brendan Burns, Craig McLuckie — 이 이 기술을 오픈소스로 공개하자고 경영진을 설득했다.
그들의 논리:
2014년 6월 6일, Kubernetes v0.1이 GitHub에 공개됐다. Google은 Borg를 운영하며 겪은 교훈을 바탕으로, Borg의 좋은 점은 살리고 나쁜 점은 개선했다:
Brendan Burns 등은 2016년 ACM Queue에 "Borg, Omega, and Kubernetes" 논문을 발표하며 세 시스템의 관계와 교훈을 체계적으로 정리했다. 이 논문의 결론: 쿠버네티스는 Borg의 "세 번째 버전"이자, Google이 15년간 축적한 대규모 클러스터 관리 경험의 결정체다.
2015년 7월, Google은 쿠버네티스를 새로 설립된 CNCF(Cloud Native Computing Foundation)에 기증했다. Linux Foundation 산하의 이 재단은 쿠버네티스의 거버넌스를 맡았다.
이것이 결정적이었다. 쿠버네티스가 Google의 제품이 아니라 산업의 표준으로 인식되기 시작했다. AWS, Microsoft, Red Hat, IBM — 경쟁사들까지 기여자로 참여했다.
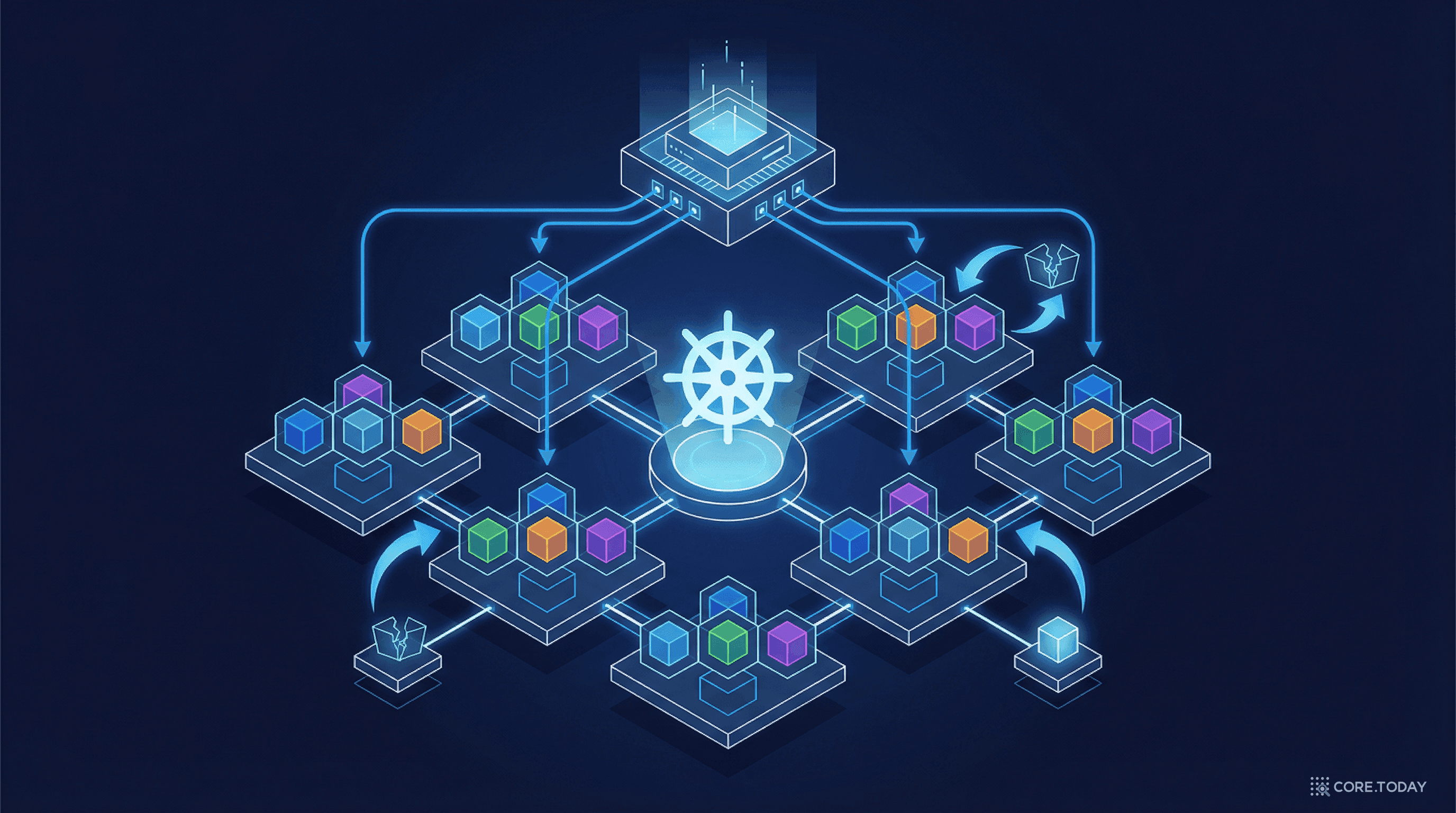
쿠버네티스를 이해하려면 몇 가지 핵심 개념을 알아야 한다. 용어가 많아 보이지만, 각각의 역할은 명확하다.

컨트롤 플레인은 클러스터의 "두뇌"다. 구성 요소:
kubectl 명령, 내부 컴포넌트, 외부 시스템 — 모두 API Server를 통해 소통워커 노드는 실제 컨테이너가 실행되는 서버다. 각 노드에는:
쿠버네티스에서 컨테이너를 직접 실행하지 않는다. Pod이라는 단위로 묶어서 실행한다.
Pod은 하나 이상의 컨테이너를 포함하는 가장 작은 배포 단위다. 같은 Pod 안의 컨테이너들은:
가장 흔한 패턴은 Pod 하나에 컨테이너 하나다. 하지만 메인 앱 + 사이드카(로그 수집기, 프록시) 패턴으로 여러 컨테이너를 묶기도 한다.
ECS의 "서비스"에 해당하는 것이 쿠버네티스의 Deployment다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: web
image: my-app:1.0
ports:
- containerPort: 8080
resources:
requests:
cpu: "250m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "512Mi"
이 YAML이 선언하는 것: "my-app:1.0 이미지를 사용하는 Pod이 항상 3개 실행되어야 한다." 쿠버네티스는 현재 상태를 이 선언에 맞춰간다. Pod이 죽으면 재시작하고, 노드가 장애를 일으키면 다른 노드에서 Pod을 다시 만든다.
Pod은 생성되고 삭제될 때마다 IP가 바뀐다. 다른 서비스가 이 Pod에 접근하려면 고정된 주소가 필요하다. 이것이 Service의 역할이다.
apiVersion: v1
kind: Service
metadata:
name: web-service
spec:
selector:
app: web # label이 app=web인 Pod들에 트래픽 전달
ports:
- port: 80
targetPort: 8080
type: ClusterIP
Service는 web-service라는 DNS 이름과 고정 IP를 제공한다. 다른 Pod은 http://web-service로 접근하면 되고, 트래픽은 label이 app: web인 Pod들에 자동으로 분배된다.
전통적 배포:
# 명령형: 단계별로 "어떻게" 하라고 지시
ssh server1 "docker pull my-app:1.0 && docker run -d -p 8080:8080 my-app:1.0"
ssh server2 "docker pull my-app:1.0 && docker run -d -p 8080:8080 my-app:1.0"
ssh server3 "docker pull my-app:1.0 && docker run -d -p 8080:8080 my-app:1.0"
쿠버네티스:
# 선언형: "무엇을" 원하는지만 말한다
kubectl apply -f deployment.yaml
# "my-app:1.0을 3개 실행하라" → K8s가 알아서 어디에, 어떻게 실행할지 결정
선언적 관리의 장점:
kubectl apply를 여러 번 실행해도 결과가 동일쿠버네티스는 세 가지 레벨의 오토스케일링을 제공한다:
| 레벨 | 이름 | 설명 |
|---|---|---|
| Pod 수평 | HPA(Horizontal Pod Autoscaler) | CPU/메모리/커스텀 메트릭에 따라 Pod 수 조절 |
| Pod 수직 | VPA(Vertical Pod Autoscaler) | Pod의 CPU/메모리 요청량을 자동 조정 |
| 클러스터 | Cluster Autoscaler | Pod이 스케줄링될 공간이 부족하면 노드 자동 추가 |
HPA 예시:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: web-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-server
minReplicas: 2
maxReplicas: 50
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
"CPU 사용률 60%를 유지하도록 Pod을 2~50개 범위에서 조절하라."
# 이미지 업데이트 → 자동 롤링 배포
kubectl set image deployment/web-server web=my-app:1.1
# 문제 발견 시 즉시 롤백
kubectl rollout undo deployment/web-server
# 배포 상태 확인
kubectl rollout status deployment/web-server
Deployment는 기본적으로 롤링 업데이트 전략을 사용한다. 새 Pod을 하나씩 추가하고 기존 Pod을 하나씩 제거하여 무중단 배포를 보장한다. 이전 ReplicaSet이 보존되므로 undo 한 줄로 즉시 이전 버전으로 돌아갈 수 있다.
쿠버네티스 자체도 강력하지만, 진짜 힘은 생태계에 있다. CNCF Landscape에 등록된 프로젝트만 수천 개다.
| 카테고리 | 도구 | 역할 |
|---|---|---|
| 패키지 매니저 | Helm | K8s 앱을 차트로 패키징·배포·관리 |
| CI/CD | Argo CD, Flux | GitOps 기반 자동 배포 |
| 서비스 메시 | Istio, Linkerd | 서비스 간 트래픽 관리, mTLS, 관측성 |
| 모니터링 | Prometheus + Grafana | 메트릭 수집 + 시각화 |
| 로깅 | EFK 스택, Loki | 중앙화된 로그 수집·검색 |
| 인그레스 | NGINX Ingress, Traefik | 외부 트래픽을 서비스로 라우팅 |
| 보안 | OPA/Gatekeeper, Falco | 정책 적용, 런타임 보안 |
| 스토리지 | Rook/Ceph, Longhorn | 분산 스토리지 오케스트레이션 |
직접 쿠버네티스를 설치·운영하는 것은 매우 복잡하다. 대부분의 기업은 클라우드의 관리형 서비스를 사용한다:
| 서비스 | 클라우드 | 특징 |
|---|---|---|
| EKS | AWS | 가장 큰 시장 점유율, Fargate 연동 |
| GKE | Google Cloud | K8s 원조, Autopilot 모드 |
| AKS | Azure | Azure AD 통합, Windows 컨테이너 지원 |
| NKS | NHN Cloud | 국내 클라우드, 한국 리전 특화 |
관리형 서비스가 해주는 것: 컨트롤 플레인(API Server, etcd, Scheduler) 운영·업그레이드·백업. 사용자는 워커 노드와 워크로드만 관리하면 된다.
Spotify는 2019년 자체 오케스트레이션 시스템 Helios에서 쿠버네티스로 마이그레이션했다. 이전 글에서 다룬 1,800개의 마이크로서비스가 모두 쿠버네티스 위에서 돌아간다.
마이그레이션 동기: 자체 시스템 유지보수에 전담 팀이 필요했는데, 쿠버네티스로 전환하면 커뮤니티의 혁신을 무료로 활용할 수 있었다.
Airbnb는 2019~2021년에 걸쳐 EC2 기반 인프라를 쿠버네티스로 전환했다. 핵심 동기는 개발자 생산성이었다.
전환 전: 새 서비스 배포에 엔지니어가 다양한 인프라 설정을 직접 해야 함 전환 후: 표준화된 K8s 매니페스트로 수 분 내에 새 서비스 배포 가능
유럽 입자물리학 연구소(CERN)는 대형 강입자 충돌기(LHC) 실험 데이터를 처리하기 위해 쿠버네티스를 사용한다. 초당 페타바이트 규모의 데이터가 수천 개의 컨테이너화된 분석 작업으로 처리된다.
이전 ECS 글에서도 다뤘지만, 쿠버네티스 관점에서 다시 정리하면:
| 기준 | ECS | EKS (K8s) |
|---|---|---|
| 학습 곡선 | 낮음 (AWS 경험만 있으면) | 높음 (K8s 개념 학습 필요) |
| 유연성 | AWS 생태계 내 | 모든 환경 (클라우드, 온프레미스, 엣지) |
| 생태계 | AWS 서비스 통합 | CNCF 전체 생태계 |
| 이식성 | AWS 종속 | 클라우드 중립 |
| 컨트롤 플레인 비용 | 무료 | ~$73/월 (EKS) |
| 운영 복잡도 | 낮음 | 높음 |
| 팀 규모 | 소규모팀에 적합 | 중대규모팀에 적합 |
| GitOps | 제한적 | Argo CD, Flux 등 풍부 |
2025~2026년 가장 큰 트렌드는 AI 워크로드의 쿠버네티스 관리다:
AI 모델 학습에 GPU 100개가 필요하다 → 학습이 끝나면 0개로 → 쿠버네티스가 이 탄력적 자원 관리를 자동화한다.
쿠버네티스가 클라우드를 넘어 엣지(Edge) 로 내려오고 있다:
공장의 AI 키오스크, 매장의 추론 서버 — 이런 엣지 디바이스를 클라우드와 동일한 K8s API로 관리하는 것이 가능해지고 있다.
2026년의 키워드는 Platform Engineering — 개발자가 인프라를 직접 다루지 않고, 내부 플랫폼팀이 K8s 위에 구축한 셀프서비스 플랫폼을 통해 배포하는 패턴이다. Backstage(Spotify 오픈소스), Kratix, Crossplane 같은 도구가 이 트렌드를 주도한다.
리눅스가 운영체제의 사실상 표준이 되었듯, 쿠버네티스는 컨테이너 인프라의 사실상 표준이 됐다. Google이 15년간 축적한 대규모 시스템 운영의 지혜가, 오픈소스를 통해 모든 기업에 공개된 것이다.
쿠버네티스는 만능이 아니다. 작은 팀에게는 과할 수 있고(ECS가 더 나을 수 있다), 학습 곡선이 가파르며, 운영 복잡도가 높다. 하지만 대규모 서비스, 멀티클라우드 전략, 풍부한 생태계가 필요한 상황에서는 대안이 없다.
이 시리즈를 통해 살펴본 인프라의 진화:
코어닷투데이의 AI 제품들이 다양한 환경(클라우드, 엣지, 온프레미스)에서 동일하게 배포되고 관리될 수 있는 것은, 이 컨테이너 인프라의 진화 위에 서 있기 때문이다.