들어가며 — 거인의 어깨에 올라타기
아이작 뉴턴은 말했다. "내가 더 멀리 보았다면, 그것은 거인의 어깨 위에 서 있었기 때문이다."
2025년의 실시간 객체 검출에서 거인은 바로 비전 파운데이션 모델(Vision Foundation Model, VFM)이다. DINOv3, SigLIP, SAM2 — 수억 개의 파라미터와 수십억 장의 이미지로 학습된 이 거대 모델들은 놀라울 정도로 풍부한 시각 표현을 가지고 있다. 물체의 경계, 질감, 맥락, 심지어 의미론적 관계까지 — 인간 수준에 가까운 "보는 능력"을 갖추었다.
하지만 문제가 있다. 거인은 느리다.
DINOv3-ViT-B는 뛰어난 표현력을 가지고 있지만, 실시간 검출기로 직접 사용하기에는 너무 무겁다. 반대로, 실시간 검출기(RT-DETR, D-FINE 등)는 빠르지만, 경량 백본의 표현력이 제한적이어서 의미론적 병목(semantic bottleneck)에 시달린다. 빠르지만 제한된 시야를 가진 소년과, 느리지만 세상을 꿰뚫어 보는 거인. 이 둘을 연결할 수 있다면?
2025년 10월, 북경대학교(PKU)와 칭화대학교 연구팀이 그 연결고리를 만들었다.
"RT-DETRv4: Painlessly Furthering Real-Time Object Detection with Vision Foundation Models" — 핵심은 "Painlessly(고통 없이)"다. VFM의 풍부한 표현을 실시간 검출기에 학습 중에만 주입하고, 추론 시에는 VFM을 완전히 제거한다. 추론 비용 증가 제로. 배포 아키텍처 변경 제로. 그러면서 COCO에서 RT-DETRv4-X: 57.0% AP, 초당 78프레임 — D-FINE-X(55.8%)와 DEIM-X(56.5%)를 모두 넘어선, 2025년 기준 실시간 검출기의 새로운 최고 기록이다.
1장: F5 의미론적 병목 — 실시간 검출기의 아킬레스건
RT-DETR 아키텍처를 다시 보자
RT-DETR 시리즈(v1~v3, D-FINE, DEIM)의 핵심 구조를 떠올려 보자.
경량 백본 (HGNetv2)
→ S3, S4, S5 멀티스케일 특징
↓
AIFI (셀프 어텐션)
S5에만 적용 → F̃5 생성
↓
CCFF (CNN 퓨전)
F̃5 + S3, S4 → P3, P4, P5
↓
핵심은 AIFI 모듈이다. 셀프 어텐션은 가장 깊은 특징 S5에만 적용되어, 글로벌 맥락을 포착한 F~5를 생성한다. 이 F~5가 이후의 모든 것에 영향을 미친다 — CCFF의 크로스 스케일 퓨전, 쿼리 선택, 디코더 성능.
문제는 F~5의 학습 방식이다. AIFI 모듈은 간접적인 감독(indirect supervision)만으로 학습된다. 검출 손실의 기울기가 디코더 → CCFF → AIFI를 거쳐 역전파되어야 하는데, 이 긴 경로를 거치면서 기울기가 약해진다. F~5의 의미론적 품질을 충분히 최적화하기 어렵다.
이것이 F5 의미론적 병목(F5 Semantic Bottleneck)이다.
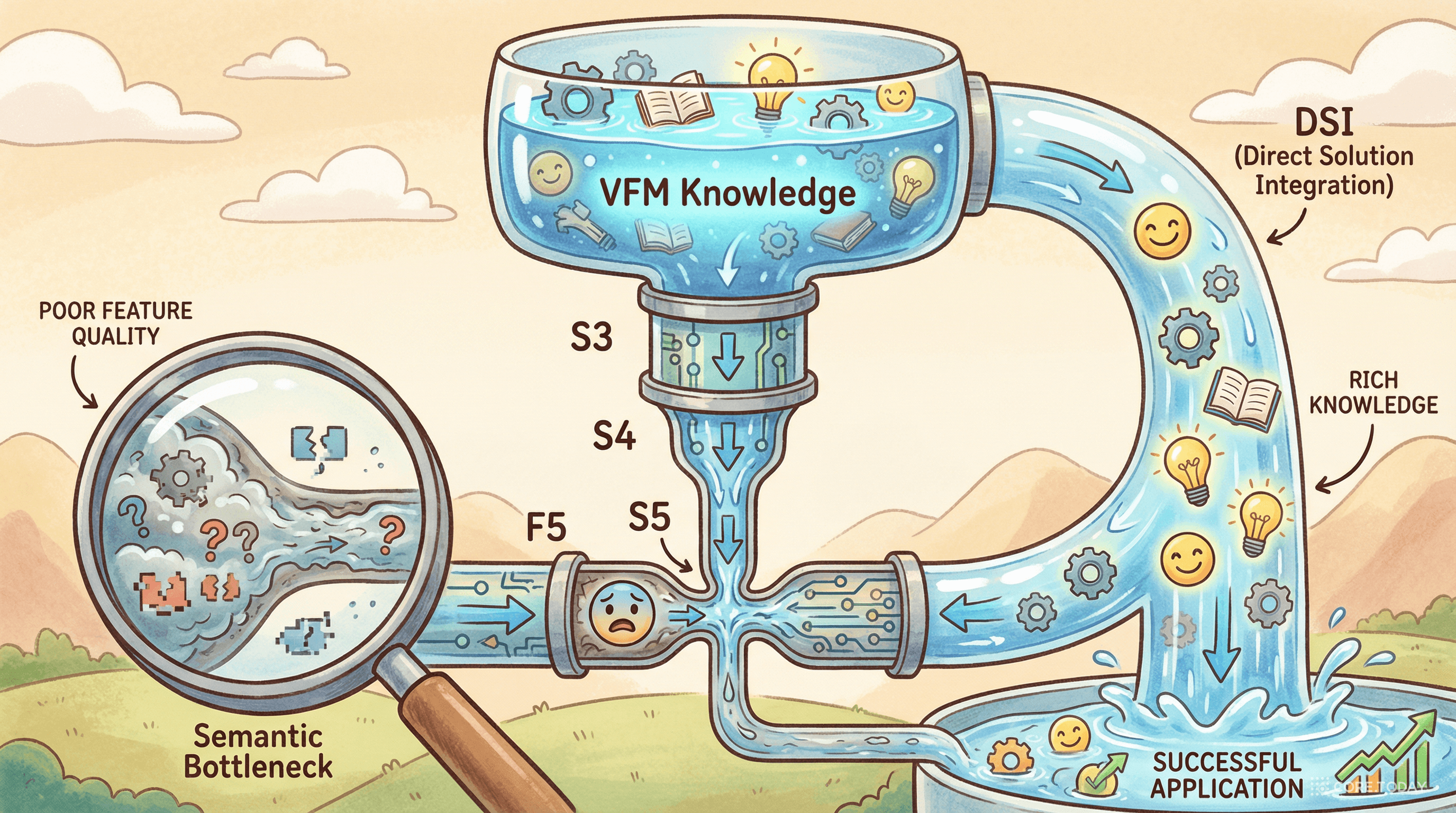
비유하면 이렇다. 회사의 CEO(디코더)가 부서장(CCFF)을 통해 현장 팀장(AIFI)에게 지시를 내린다. 하지만 중간에 전달이 왜곡되고, 팀장은 CEO의 의도를 정확히 파악하지 못한다. 만약 외부의 전문 컨설턴트(VFM)가 팀장에게 직접 코칭을 해줄 수 있다면?
이것이 RT-DETRv4의 핵심 아이디어다.
2장: DSI — 거인의 지혜를 직접 주입하다
Deep Semantic Injector: 학습 전용 모듈
DSI(Deep Semantic Injector)는 학습 중에만 존재하는 모듈이다. 핵심 동작:
- 동결된(frozen) VFM 교사(DINOv3-ViT-B)가 입력 이미지에서 고품질 특징 FT를 추출
- Feature Projector가 교사 특징의 해상도와 채널 차원을 F~5에 맞춤
- F~5와 투영된 교사 특징 사이의 코사인 유사도 손실을 계산
- 이 손실의 기울기가 AIFI와 백본으로 역전파되어, F~5의 의미론적 품질을 향상
Feature Projection:
FTsp = Reshape(Tp) → ℝHT×WT×CT
FT' = Interpolate(FTsp) → ℝH5×W5×CT
F5' = P(F̃5) → ℝH5×W5×CT
Alignment Loss (코사인 유사도):
LDSI = − (1/H5W5) Σi,j (F5'(i,j) · FT'(i,j)) / (||F5'(i,j)|| · ||FT'(i,j)||)
Total Loss:
Ltotal = Ldet + λ · LDSI
왜 F5만 정렬하는가? — 세 가지 전략 비교
논문은 세 가지 DSI 전략을 비교한다.
| 전략 | 정렬 대상 | AP (%) | 효과 |
|---|
| (a) 백본 직접 정렬 | S3, S4, S5 각각 | 53.7~53.8 | 향상 없음 |
| (b) 하이브리드 정렬 | 백본 + F̃5 동시 | 53.8 | 향상 없음 |
| (c) AIFI 출력 정렬 | F̃5만 | 54.3 | +0.5 AP |
왜 (c)만 효과가 있을까?
F~5에 가장 풍부한 의미론적 정보가 집중되어 있기 때문이다. F~5는 AIFI(셀프 어텐션)를 거친 결과물로, 전체 모델에서 가장 높은 수준의 추상적 표현을 담고 있다. 이것을 직접 정렬하면:
- 순방향: 풍부해진 F~5가 CCFF를 통해 모든 스케일의 특징(P3, P4, P5)을 개선
- 역방향: DSI 손실의 기울기가 AIFI와 백본 모두를 업데이트
하나의 정렬 포인트로 양방향 시너지를 달성하는 것이다. 반면 백본 특징(S3, S4, S5)을 직접 정렬하면, CNN 기반 백본과 트랜스포머 기반 VFM 사이의 최적화 충돌이 발생할 수 있다.
Feature Projector: 단순한 선형 레이어가 최적
| 프로젝터 구조 | AP (%) | AP50 |
|---|
| 없음 (기준) | 53.8 | 71.4 |
| 1×1 Conv | 53.8 | 71.5 |
| MLP | 54.2 | 71.7 |
| Linear | 54.3 | 71.8 |
단순한 선형 레이어가 MLP보다 낫다. 복잡한 프로젝터는 불필요한 중간 변환을 추가하여 최적화를 방해할 수 있기 때문이다.
정렬 손실: 코사인 유사도 > MSE
| 손실 함수 | AP (%) | AP50 |
|---|
| 없음 (기준) | 52.5 | 69.9 |
| MSE Loss | 52.7 | 70.0 |
| Cosine Similarity | 53.5 | 71.1 |
코사인 유사도가 MSE보다 +0.8% AP 우수하다. 이는 VFM과 검출기의 특징이 절대적 크기보다 방향(direction)이 중요하다는 것을 시사한다. "어떤 개념을 표현하는가"의 방향을 맞추는 것이 핵심이지, 크기를 맞추는 것이 아니다.
3장: GAM — 학습의 균형을 자동으로 잡다
문제: λ는 훈련 내내 변해야 한다
DSI 손실의 가중치 λ를 어떻게 설정해야 할까?
- λ가 너무 작으면: VFM의 의미론적 감독이 부족하여, F~5 개선 효과가 미미
- λ가 너무 크면: DSI 손실이 검출 손실을 압도하여, 수렴이 불안정
더 복잡한 것은, 최적의 λ가 학습 단계에 따라 변한다는 것이다. 학습 초기에는 의미론적 감독이 강해야 하고, 후기에는 검출 태스크에 집중해야 할 수 있다. 고정된 λ로는 이 동적 요구를 충족할 수 없다.
| 고정 λ 값 | AP (%) |
|---|
| 0.1 | 54.7 |
| 0.4 | 54.8 |
| 2.0 | 55.0 |
| 20 (최적 고정) | 55.1 |
| 100 | 54.6 |
| GAM (동적) | 55.4 |
최적 고정 λ(=20)도 GAM에 0.3% AP 뒤진다. 그리고 고정 λ=20은 사전에 알 수 없다 — 모든 값을 시도해야 찾을 수 있다. GAM은 이를 자동으로 해결한다.
GAM의 동작 원리
GAM(Gradient-guided Adaptive Modulation)은 기울기 노름 비율(gradient norm ratio)에 기반하여 λ를 동적으로 조정한다.
1
각 학습 스텝에서, 모든 컴포넌트(백본, AIFI, CCFF, 디코더)의 기울기 L1 노름을 계산
2
AIFI의 기울기 비율 r_t = G_t^(AIFI) / G_t^(total)을 계산
5
범위 밖이면 λ를 경계 방향으로 조정, 범위 안이면 유지
r̄e > ρ + δ (AIFI 기울기 과다):
λe+1 = λe · (ρ - δ) / r̄e ← λ 감소
r̄e < ρ - δ (AIFI 기울기 부족):
λe+1 = λe · (ρ + δ) / r̄e ← λ 증가
ρ - δ ≤ r̄e ≤ ρ + δ (적정 범위):
λe+1 = λe ← 유지
핵심 설계: λ를 중점이 아닌 경계 방향으로 조정한다. DSI 손실의 기울기는 AIFI 전체 기울기의 일부이므로, 경계 기반 조정이 더 안정적인 수렴을 유도한다.
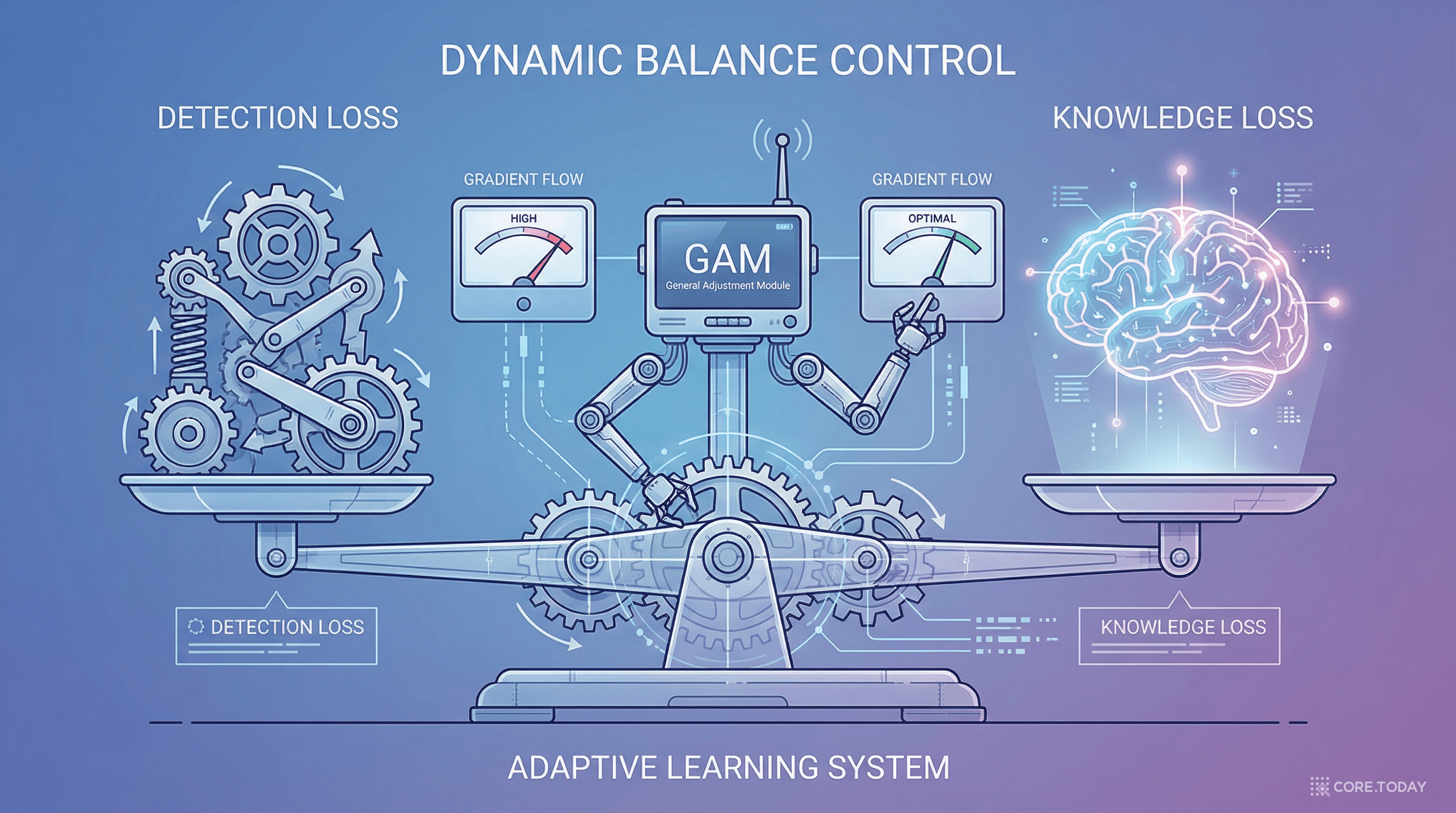
4장: 추론 비용 제로 — "고통 없는" 증류
학습과 추론의 완전한 분리
RT-DETRv4의 가장 강력한 특성은 추론 시 아무것도 변하지 않는다는 것이다.
학습
학습 시 (VFM 사용)
동결된 VFM 교사 + Feature Projector + DSI 손실 + GAM. 추가 학습 시간 미미.
추론
추론 시 (VFM 제거)
VFM, Feature Projector, DSI 모듈 모두 제거. 검출기 아키텍처 100% 동일. 지연 시간 0ms 추가.
이것이 "Painlessly(고통 없이)"의 진정한 의미다. 배포 환경을 전혀 바꿀 필요가 없다. 기존에 D-FINE-L을 배포하고 있었다면, RT-DETRv4-L로 교체해도 동일한 하드웨어, 동일한 지연 시간, 동일한 배포 파이프라인으로 운영할 수 있다. 달라지는 것은 가중치(weight)뿐이다.
다른 증류 방법과의 근본적 차이
기존 증류 방법(Logit Mimicking, Feature Imitation 등)은 대부분 학생 모델의 아키텍처를 수정하거나, 별도의 교사 모델을 학습해야 했다. RT-DETRv4는 둘 다 필요 없다.
- 교사 모델 학습 불필요: VFM은 이미 학습된 모델을 그대로 사용 (동결)
- 학생 아키텍처 수정 불필요: 기존 검출기 그대로 사용
- VFM 종류에 무관: DINOv3, SigLIP, SAM2, CLIP 등 어떤 VFM이든 사용 가능
- 검출기 종류에 무관: RT-DETRv2, D-FINE, DEIM 등 모두에 적용 가능
5장: 실험 결과 — 모든 스케일에서 새로운 SOTA
아래 탐색기에서 RT-DETRv4와 다른 실시간 검출기들을 직접 비교해보자.
COCO val2017 전체 비교
| S 모델 | 에폭 | 파라미터 | 지연 (ms) | AP (%) |
|---|
| YOLOv10-S | 500 | 7M | 2.52 | 46.3 |
| YOLO11-S | 500 | 9M | 2.60 | 47.0 |
| YOLOv12-S | 600 | 9M | 2.78 | 48.0 |
| YOLOv13-S | 600 | 9M | 2.98 | 48.0 |
| D-FINE-S | 120 | 10M | 3.66 | 48.5 |
| DEIM-S | 120 | 10M | 3.66 | 49.0 |
| RT-DETRv4-S | 90 | 10M | 3.66 | 49.7 |
| L 모델 | 에폭 | 파라미터 | 지연 (ms) | AP (%) |
|---|
| YOLOv10-L | 500 | 24M | 7.38 | 53.2 |
| YOLO11-L | 500 | 25M | 6.33 | 53.4 |
| YOLOv12-L | 600 | 27M | 6.85 | 53.7 |
| YOLOv13-L | 600 | 88M | 8.63 | 53.4 |
| D-FINE-L | 72 | 31M | 8.07 | 54.0 |
| DEIM-L | 50 | 31M | 8.07 | 54.7 |
| RT-DETRv4-L | 50 | 31M | 8.07 | 55.4 |
| X 모델 | 에폭 | 파라미터 | 지연 (ms) | AP (%) |
|---|
| YOLOv10-X | 500 | 30M | 10.45 | 54.4 |
| YOLO11-X | 500 | 57M | 11.50 | 54.7 |
| YOLOv12-X | 600 | 59M | 11.80 | 55.2 |
| D-FINE-X | 72 | 62M | 12.90 | 55.8 |
| DEIM-X | 50 | 62M | 12.90 | 56.5 |
| RT-DETRv4-X | 50 | 62M | 12.90 | 57.0 |
핵심 관찰:
1. 모든 스케일에서 SOTA. S(49.7%), M(53.5%), L(55.4%), X(57.0%) — 네 가지 모든 스케일에서 기존 최고를 갱신.
2. 동일한 지연 시간. D-FINE과 DEIM과 정확히 같은 지연 시간(3.66/5.91/8.07/12.90ms). 추론 비용 증가 제로.
3. 더 적은 학습 에폭. YOLO 시리즈가 500~600 에폭을 필요로 하는 반면, RT-DETRv4는 50~90 에폭이면 충분. 학습 효율도 압도적이다.
COCO AP (%) — 2025년 실시간 검출기 비교 (X 스케일)
DSI + GAM의 범용성
RT-DETRv4 프레임워크는 특정 검출기에 종속되지 않는다. RT-DETRv2, D-FINE, DEIM 모두에 적용하여 일관된 성능 향상을 달성한다.
| 베이스 모델 | 원래 AP | + DSI | + DSI + GAM | 최종 향상 |
|---|
| RT-DETRv2-L | 52.1 | 52.3 | 52.6 | +0.5 |
| D-FINE-L | 53.1 | 53.2 | 53.4 | +0.3 |
| DEIM-L | 53.8 | 53.9 | 54.3 | +0.5 |
모든 베이스 모델에서 추론 비용 제로로 +0.3~0.5% AP 향상. "고통 없는 향상"이라는 논문 제목이 과장이 아님을 증명한다.
6장: 왜 VFM인가 — 파운데이션 모델 시대의 검출
아키텍처 최적화의 포화
RT-DETRv4 논문이 관찰한 중요한 트렌드가 있다.
"아키텍처 효율성이 포화되면서, 학습 감독과 의미론적 표현이 추가적 발전의 핵심 레버가 되고 있다."
YOLO 시리즈는 v10, v11, v12, v13으로 진화하며 백본, 넥, 헤드의 아키텍처를 지속적으로 개선해왔다. DETR 시리즈는 RT-DETR → RT-DETRv2 → RT-DETRv3 → D-FINE → DEIM으로 인코더, 디코더, 손실 함수를 개선했다.
하지만 아키텍처 개선의 한계 수확이 명확해지고 있다. YOLOv12-X(55.2%)와 YOLOv13-X(54.8%) 사이의 차이는 이미 미미하고, 오히려 감소하기도 한다. 아키텍처만으로는 더 이상 큰 폭의 향상이 어렵다.
RT-DETRv4는 이 한계를 외부 지식의 주입으로 돌파한다. VFM이라는 "거인의 어깨"를 빌리는 것이다. 그리고 VFM 자체도 빠르게 진화하고 있다 — DINOv2(2023) → DINOv3(2025). VFM이 더 강력해질수록, RT-DETRv4도 자동으로 더 강력해진다.
VFM의 유연한 선택
RT-DETRv4 프레임워크는 특정 VFM에 종속되지 않는다. DINOv3, SigLIP, SAM2, EVA02, CLIP 등 어떤 VFM이든 교사로 사용할 수 있다. 이것은 다음을 의미한다:
- 최신 VFM이 나올 때마다 RT-DETRv4를 업데이트할 수 있다 (재학습만 하면 됨)
- 도메인 특화 VFM이 있다면 (의료, 위성 등) 해당 VFM을 교사로 사용하여 도메인 성능을 극대화할 수 있다
- 멀티 VFM 통합의 가능성도 열려 있다 — 여러 VFM의 지식을 동시에 증류하는 것
7장: 시각화 — 보이는 차이
논문의 Figure 4는 DEIM-L과 RT-DETRv4-L의 특징 맵을 PCA로 시각화하여 비교한다. 결과는 명확하다.
RT-DETRv4의 특징 맵에서:
- F~5 (AIFI 출력): 객체 윤곽이 훨씬 더 선명하고, 배경과의 구분이 뚜렷하다
- P3, P4, P5 (CCFF 출력): 모든 스케일에서 더 정밀한 객체 반응을 보인다
- 특히 P5: 객체 영역에 대한 반응이 강하고 집중적이다
이것은 DSI가 F~5의 의미론적 품질을 향상시키고, 그 효과가 CCFF를 통해 모든 스케일로 전파된다는 것을 시각적으로 확인해준다.
8장: 2026년의 RT-DETRv4 — 패러다임의 완성
객체 검출 10년의 흐름
2015년 YOLO에서 시작된 실시간 객체 검출의 10년을 돌아보자.
2015
YOLO — 검출을 회귀로 재정의. 실시간의 시작.
2020
DETR — 트랜스포머로 앵커와 NMS 제거. 엔드투엔드의 시작.
2024
RT-DETR — 트랜스포머 검출기를 실시간으로. YOLO를 처음으로 능가.
2024
D-FINE — 좌표 대신 분포를 정제. 회귀의 재정의.
2025
RT-DETRv4 — VFM의 지혜를 주입. 표현의 한계를 돌파.
각 단계는 다른 차원의 혁신이었다:
- YOLO: 파이프라인의 혁신 (다단계 → 단일 패스)
- DETR: 구성요소의 혁신 (앵커/NMS 제거)
- RT-DETR: 효율성의 혁신 (하이브리드 인코더)
- D-FINE: 회귀 방식의 혁신 (좌표 → 분포)
- RT-DETRv4: 학습 감독의 혁신 (자체 학습 → 외부 지식 증류)
아키텍처가 포화된 시대에, 어떤 지식으로 학습하느냐가 새로운 프론티어가 된 것이다.
실무 시사점
1. 배포 무비용 업그레이드. 기존 D-FINE/DEIM 배포 환경을 그대로 유지하면서, 가중치만 교체하여 +0.5~1.0% AP 향상 가능. 하드웨어 투자 없이 소프트웨어 업데이트만으로 성능 향상.
2. VFM 생태계와의 연동. DINOv3가 더 강력한 DINOv4로 진화하면, RT-DETRv4도 자동으로 혜택을 받는다. 파운데이션 모델 생태계의 발전이 실시간 검출의 발전으로 직결된다.
3. 학습 비용 효율. 50~90 에폭으로 YOLO의 500~600 에폭보다 10배 적은 학습으로 더 높은 성능. 학습 예산이 제한된 환경에서 특히 유리하다.
마치며 — 거인은 떠나지만, 지혜는 남는다
RT-DETRv4의 가장 아름다운 설계는 이것이다.
학습할 때는 거인(VFM)이 곁에서 가르치고, 추론할 때는 거인 없이 혼자 달린다.
마치 좋은 스승에게 배운 학생이, 졸업 후 스승 없이도 배운 지혜를 발휘하는 것과 같다. 스승의 지식은 학생의 내면에 내재화되어, 별도의 도구나 자원 없이도 작동한다.
이 "고통 없는" 증류 패러다임은 단순히 객체 검출을 넘어선 함의를 가진다. AI 연구의 핵심 트렌드 — 거대 파운데이션 모델의 지식을 경량 모델에 효율적으로 전달하는 것 — 의 구체적이고 성공적인 사례다.
57.0% AP. 이 숫자는 인상적이지만, 더 중요한 것은 이 숫자를 달성하는 방식이다. 아키텍처를 키우지 않고, 추론을 느리게 하지 않고, 배포를 복잡하게 하지 않고 — 오직 학습 감독을 강화하는 것만으로. 이것이 "Painlessly"의 철학이며, 2026년 실시간 AI의 지향점이다.
거인은 학습이 끝나면 떠난다. 하지만 그가 전수한 지혜는, 작은 검출기 안에 영원히 남는다.
참고 자료
- Liao, Z., Zhao, Y., Shan, X., Yan, Y., Liu, C., Lu, L., Ji, X., & Chen, J. (2025). "RT-DETRv4: Painlessly Furthering Real-Time Object Detection with Vision Foundation Models." arXiv:2510.25257
- Zhao, Y. et al. (2024). "DETRs Beat YOLOs on Real-time Object Detection." CVPR 2024.
- Peng, Y. et al. (2024). "D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement." ICLR 2024.
- Oquab, M. et al. (2023). "DINOv2: Learning Robust Visual Features without Supervision."
- Siméoni, O. et al. (2025). "DINOv3." arXiv:2025.
- Carion, N. et al. (2020). "End-to-End Object Detection with Transformers." ECCV 2020.
- 프로젝트: https://github.com/RT-DETRs/RT-DETRv4