PINN은 왜 자꾸 경직되는가 — ill-conditioning, Jacobian, TSONN으로 읽는 핵심 논문
PINN은 왜 복잡한 PDE에서 자주 수렴하지 않을까? Jacobian condition number 관점에서 이 문제를 해부한 핵심 논문을 중심으로, controlled system, TSONN, 실제 유동 해석 사례, 그리고 2026년 현재 이 아이디어의 역할까지 쉽고 깊게 풀어본다.
PINN(Physics-Informed Neural Networks)은 처음 등장했을 때 매우 강한 기대를 모았다. 데이터를 많이 모으지 못해도, 손실 함수 안에 물리 법칙을 넣으면 신경망이 PDE의 해를 직접 근사할 수 있을 것처럼 보였기 때문이다. 실제로 초기의 Burgers, Poisson, inverse coefficient 문제에서는 이 접근이 상당히 설득력 있는 결과를 보여 주었다.
하지만 유체가 빨라지고, 경계층이 생기고, 형상이 복잡해지자 상황이 달라졌다. 방정식은 알고 있는데도 학습은 자주 수렴하지 않았다. 경계 조건은 맞는데 내부 residual은 줄지 않거나, 표면 압력 분포는 대체로 맞지만 leading edge에서 무너지는 사례가 반복됐다. 이후 연구는 loss weight, soft constraint, sampling, spectral bias 같은 설명을 제시했지만, 어떤 문제가 중심 원인인지에 대해서는 계속 논쟁이 남았다.
이 글에서 다룰 논문은 그 질문을 훨씬 더 오래된 언어로 다시 정리한다. 이 글의 framing을 먼저 적어 두면, 논문의 핵심 문제의식은 PINN의 학습 난제를 Jacobian conditioning의 관점에서 다시 읽어 보자는 데 있다.
이 질문이 중요한 이유는, 적어도 많은 어려운 PDE에서 풀어야 할 시스템 자체의 조건수가 PINN 수렴성에 큰 영향을 준다면 해법도 "더 큰 네트워크"보다 "더 잘-conditioned된 문제를 만드는 방법" 쪽에서 나올 가능성이 크기 때문이다.
이 글은 기본 PINN 해설, APINN 특집, NTK 실패 분석 위에 쌓는 네 번째 조각이다. 2024년 논문 An analysis and solution of ill-conditioning in physics-informed neural networks를 중심으로, 이 논문이 PINN 난제를 어떤 근거로 Jacobian conditioning의 관점에서 다시 읽는지 살펴보겠다.
제1장: 왜 PINN이 필요했는가 — 수치해석과 딥러닝 사이의 간극
수치해석의 세계는 정확하지만 느렸다. 메시를 깔고, 경계 조건을 넣고, 선형 시스템을 반복적으로 푸는 방식은 항공기나 배터리, 지하 유동 같은 문제에서 여전히 표준이다. 하지만 새로운 형상을 빠르게 스캔하거나, sparse data로 inverse problem을 풀거나, differentiable loop 안에서 반복 최적화를 돌리려 하면 너무 무겁다.
딥러닝의 세계는 반대였다. 한 번 학습하면 추론이 빠르고, 미분 가능하며, 고차원 입력도 자연스럽게 다룬다. 대신 물리 정합성이 자동으로 보장되지는 않는다. 그래서 PINN은 이 둘 사이의 간극에서 등장했다.
LPINN=Ldata+λfLphysics+λbLBC/IC
핵심 아이디어는 단순했다. 관측 데이터만 맞추는 대신, PDE residual과 경계·초기 조건을 손실에 함께 넣어 신경망이 물리 법칙을 어기지 못하게 하자는 것이다. 2019년 Raissi, Perdikaris, Karniadakis의 논문은 이 아이디어를 대중화했고, 2021년 Nature Reviews Physics의 리뷰는 이 흐름을 과학 AI 전반의 유망한 방법론으로 정리했다.
문제는 이 손실 함수가 좋은 물리 제약이면서 동시에 좋은 최적화 문제인지는 별개라는 점이다. 수치해석에서 PDE를 푼다는 것은 결국 stiff하고 규모 큰 시스템을 다루는 일이다. PINN은 그 시스템을 없앤 것이 아니라, 다른 형태로 감춘 것에 가깝다.
PINN이 메우려 했던 간극
전통 solverFDM / FEM / FVM정확하고 신뢰성 높음 하지만 반복 비용 큼
순수 딥러닝지도학습 surrogate빠르고 유연함 하지만 물리 위반 가능
PINNdata + PDE residual희소 데이터 환경에서 특히 매력적 다만 학습 난이도는 숨겨져 있음
이 지점이 중요하다. PINN의 출발점은 "딥러닝으로 시뮬레이터를 대체하자"라기보다, 미분 가능한 최적화 루프 안에 물리 해석기를 집어넣자는 요구에 더 가까웠다. 그래서 PINN은 지금도 inverse problem, parameter identification, sparse sensing처럼 데이터와 물리를 같이 써야 하는 문제에서 강점을 보이는 경우가 많다. 반면 복잡한 forward CFD를 단독으로 밀어붙일 때는 많은 경우 conditioning 문제가 먼저 드러난다.
제2장: 역사 — PINN의 성공 서사에서 실패 분석의 시대로
PINN의 초기 서사는 분명 성공 서사에 가까웠다. 2019년 전후의 대표 논문들은 적은 데이터로 PDE 해를 복원하고, 미지의 계수를 추정하고, mesh-free한 방식으로 복잡한 함수를 근사하는 그림을 제시했다. 당시에는 PINN이 여러 과학 문제를 폭넓게 다룰 수 있을 것이라는 기대가 컸다.
하지만 2020년 이후 연구자들의 관심은 빠르게 바뀌었다. 질문은 더 이상 "PINN이 가능한가?"가 아니라 "PINN은 왜 어려운 문제에서 자꾸 안 되는가?"가 되었다. gradient flow pathology, loss imbalance, spectral bias, hard constraint, domain decomposition, causal training, adaptive weighting이 연달아 등장한 이유가 여기에 있다.
2019 PINN 대중화 forward / inverse 문제에서 주목
→
2021 gradient pathology 손실 항 불균형 문제 부상
→
2022 NTK 관점 왜 어떤 모드가 안 배워지는지 분석
↓
2023 TSONN, domain decomposition 문제를 쪼개거나 시간화하는 흐름
→
2024 Jacobian conditioning 재해석 controlled system 제안
→
2026 하이브리드·역할 분담 관점이 더 자주 논의됨
이 2024년 논문이 특별한 이유는 실패 원인을 딥러닝 고유 현상으로만 보지 않았기 때문이다. 논문은 수치해석 쪽의 오래된 상식, 즉 반복 풀이의 난점은 종종 Jacobian conditioning과 깊게 연결된다는 관점으로 돌아간다. 이 글의 표현으로 옮기면, 문제는 "PINN도 결국 PDE solver라면 conditioning 문제를 별개로 둘 수 있는가"라는 질문에 가깝다.
이 문장은 논문의 문제의식을 잘 요약한다. PINN은 optimization problem이지만, 그 optimization이 겨루는 대상은 결국 PDE 시스템이다. 그러니 실패 분석도 Hessian만이 아니라 원래 풀어야 할 시스템의 Jacobian을 중요한 축으로 다시 읽을 필요가 있다는 것이다.
그리고 Newton 계열, Krylov 계열, preconditioned iterative solver는 모두 이 시스템의 Jacobian을 중심으로 이해된다.
J(q0)=∂q∂fq=q0
condition number는 보통 다음과 같이 쓴다.
κ(J)=σmin(J)σmax(J)
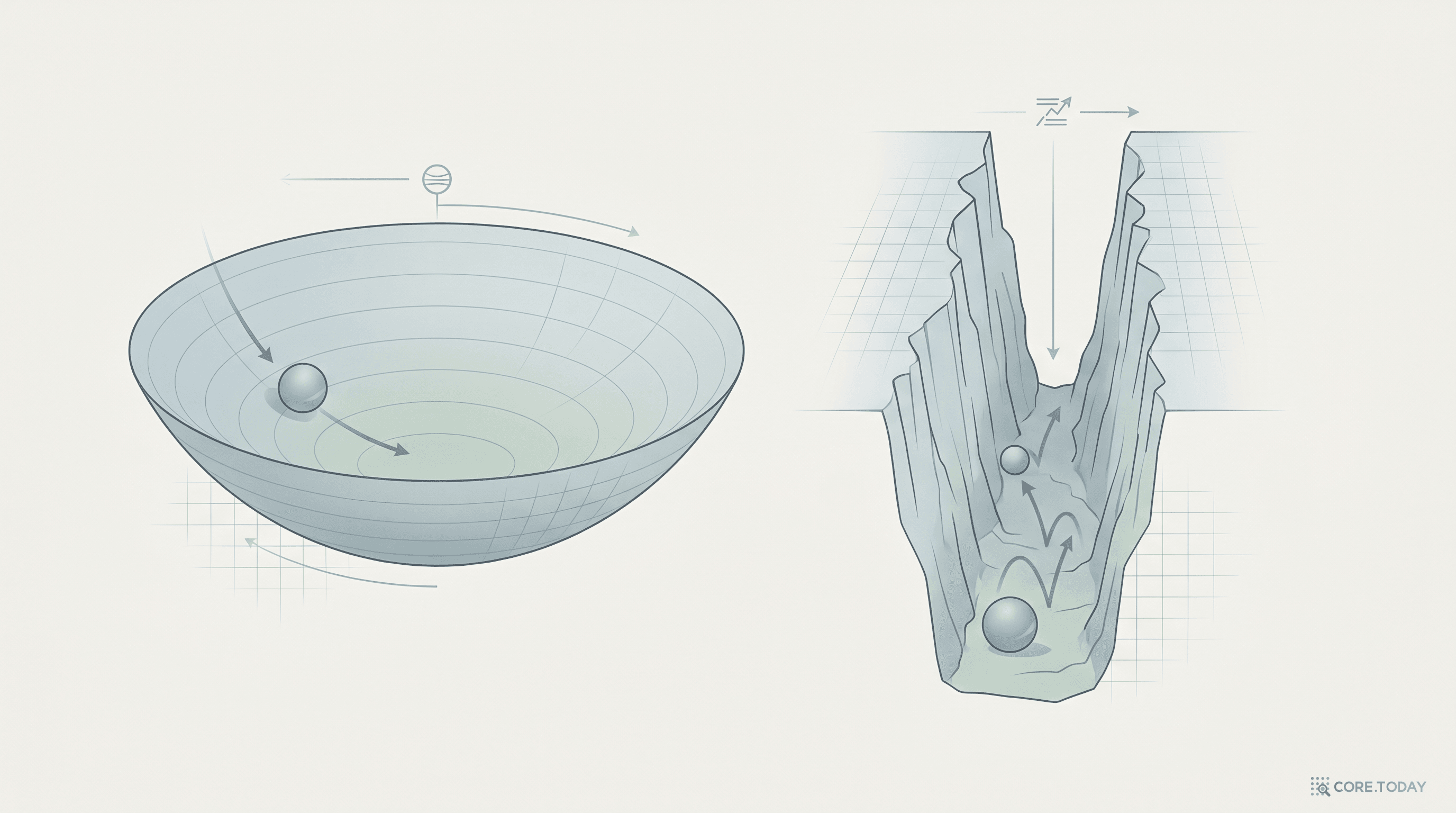
여기서 κ(J)가 크다는 것은 단순히 "숫자가 나쁘다"는 뜻이 아니다. 어떤 방향은 거의 움직이지 않고, 어떤 방향은 지나치게 민감하다는 뜻이다. 잘-conditioned된 문제는 둥근 그릇처럼 보이고, ill-conditioned된 문제는 길고 좁은 협곡처럼 보인다. 후자에서는 최적화가 한쪽 벽을 따라 지그재그로 움직이거나, 초기에 내려가다가도 바닥을 못 찾고 정체되기 쉽다.
PINN에 이 직관을 대입하면 여러 현상을 하나의 축에서 해석할 수 있다.
경계 조건은 빨리 맞는데 내부 residual이 안 줄어드는 현상
손실은 내려가는데 해는 틀린 현상
optimizer나 learning rate를 바꿔도 근본적으로 나아지지 않는 현상
Reynolds 수가 올라가거나 다중 스케일이 섞일수록 갑자기 무너지는 현상
이 논문은 특히 "PINN의 ill-conditioning은 boundary residual과 PDE residual의 weight mismatch 때문"이라는 더 좁은 설명만으로는 부족하다고 본다. 실제로 경계 조건을 엄격히 강제해도 학습이 무너지는 사례가 있기 때문이다. 문제는 손실 항의 비율이 아니라, 더 아래층의 잠재 Jacobian 구조일 수 있다는 것이다.
Jacobian conditioning 한눈에 보기
좋은 조건수모든 방향의 스케일이 비슷해 반복 풀이가 안정적으로 수렴한다.
나쁜 조건수어떤 모드는 거의 안 배우고, 어떤 모드는 과민하게 반응해 학습이 경직된다.
핵심 시사점PINN도 PDE solver로 읽는다면 conditioning을 주요 변수로 함께 봐야 한다.
논문이 중요한 이유는 여기서 한 걸음 더 나가기 때문이다. PINN 내부에서 explicit Jacobian을 직접 꺼내기 어렵더라도, condition number를 의도적으로 바꾸는 controlled system을 만들면 conditioning 변화와 convergence 변화를 나란히 관찰할 수 있다는 것이다.
논문이 제시한 controlled system은 아래처럼 원래 시스템에 선형 forcing term을 더한다.
fc(q)=f(q)−γ(q−qs)=0,γ>0
여기서 qs는 원래 시스템의 steady solution이다. 이 식이 영리한 이유는 해를 바꾸지 않으면서 Jacobian의 고유값을 이동시킨다는 데 있다.
Jc(qs)=J(qs)−γI
stable system에서는 Jacobian 고유값의 실수부가 음수다. 따라서 γ를 키우면 고유값은 더 음의 방향으로 밀리고, zero 근처에 붙어 있던 troublesome mode들이 멀어진다. 직관적으로는 협곡 바닥의 비틀림을 완화해 반복 풀이가 더 곧게 내려가도록 만드는 셈이다.
원래 시스템f(q)=0이라는 본문제를 풀고 있고, PINN은 이 residual을 직접 최소화하려고 한다.
controlled system-gamma(q-q_s)를 더해 해는 그대로 두되 Jacobian 스펙트럼을 이동시킨다.
관찰 포인트gain을 키울수록 FDM condition number와 PINN convergence가 함께 좋아지면, 원인과 증거가 연결된다.
여기서 중요한 반론 하나가 있다. "steady solution을 식에 넣었으니 당연히 쉬워진 것 아닌가?" 논문은 이 반론을 negative gain 실험으로 검토한다. steady solution 정보를 넣더라도 gain의 부호가 나쁘면 condition은 오히려 악화되고, PINN과 FDM 모두 안정 수렴에 실패한다. 이 실험은 정답 힌트 자체보다 conditioning 변화가 더 중심적인 설명일 수 있음을 시사한다.
gain 부호
Jacobian 관점
PINN에서 보이는 현상
양의 gain (gamma > 0)
고유값이 더 음의 방향으로 이동, condition 개선
더 빠르고 안정적인 수렴, 같은 오차 수준에 더 빨리 도달
0
원래 시스템 그대로
복잡한 문제에서는 학습 정체 또는 잘못된 해로 수렴
음의 gain (gamma < 0)
고유값이 0에 가까워지거나 넘어가며 condition 악화
초반에는 줄어드는 것처럼 보여도 결국 stagnation, 불안정한 하강
이 controlled system은 단순한 분석 장치이면서 동시에 해법의 씨앗이기도 하다. 왜냐하면 "문제를 잘-conditioned하게 나눠 풀면 된다"는 방향을 이미 보여 주기 때문이다.
제5장: 실험으로 보기 — cavity flow와 Allen-Cahn은 무엇을 보여주나
논문은 먼저 lid-driven cavity flow와 Allen-Cahn 방정식처럼 비교적 잘 알려진 benchmark에서 메시지를 검증한다. 이 선택이 좋은 이유는 두 문제가 각각 다른 성격을 갖기 때문이다. cavity flow는 steady incompressible flow의 전형적인 난제이고, Allen-Cahn은 time-dependent nonlinear dynamics의 대표 벤치마크다.
cavity flow: gain 변화가 조건수와 수렴을 어떻게 함께 바꾸는가
논문은 Reynolds 수 2500의 2D cavity flow를 사용한다. 이 구간은 standard PINN이 잘 풀지 못하는 regime이다. 저자들은 PINN과 FDM-Newton-Krylov을 나란히 놓고 gain을 바꿔 본다. FDM에서는 explicit Jacobian을 계산할 수 있으므로, controlled system에서 gain에 따라 condition number가 어떻게 변하는지 직접 본다.
논문은 다음과 같은 경향을 보여 준다.
양의 gain이 커질수록 FDM의 Jacobian condition number는 크게 내려간다.
같은 변화가 PINN의 convergence history에서도 거의 같은 방향으로 나타난다.
원래 시스템(γ=0)에서는 PINN이 의미 있는 해를 거의 얻지 못한다.
논문 본문에서 제시한 coarse-grid FDM 값만 봐도 흐름이 분명하다. cavity의 경우 condition number는 대략 γ=0에서 12542, γ=2에서 502 수준까지 내려간다. 반대로 negative gain에서는 값이 폭증해 γ=−2에서 약 $5 \times 10^8$에 이른다. 숫자는 FDM 쪽에서 계산한 것이지만, PINN의 수렴 양상과 같은 방향을 가리킨다는 점이 핵심이다.
Allen-Cahn: 시간 의존 문제에서도 conditioning이 중요한 축임을 보여준다
Allen-Cahn 방정식에서는 1D time-dependent setting을 쓴다. 여기서도 패턴은 거의 같다. 양의 gain을 올릴수록 PINN은 더 빠르게 수렴하고, negative gain에서는 초기에 급격히 내려가는 것처럼 보여도 결국 원래 시스템보다 나은 안정성을 주지 못한다.
Allen-Cahn에서 제시된 FDM proxy 수치 역시 같은 흐름을 보여 준다. γ=0일 때 약 3448이던 condition number가 γ=2에서는 약 716으로 줄어든다. 이 결과는 논문의 해석이 steady CFD에만 국한되지 않고, 시간 의존 문제가 들어와도 conditioning이 중요한 설명 축이 될 수 있음을 보여 준다.
논문이 보여 준 핵심 패턴
cavity: gamma=0
조건수 매우 큼
cavity: gamma=2
약 502
Allen-Cahn: gamma=0
약 3448
Allen-Cahn: gamma=2
약 716
이 실험들이 말하는 바는 "양의 gain을 넣으면 PINN이 더 잘 된다"는 요령에 머물지 않는다. 논문은 PINN의 수렴 실패가 Jacobian ill-conditioning과 체계적으로 연결되어 있을 가능성을 정성·정량 양쪽에서 보여 주려 한다.
제6장: 해결 — controlled system이 TSONN으로 이어지는 이유
controlled system은 분석 장치로는 훌륭하지만, 실제 계산에서는 qs를 모른다. 모르면 원래 문제를 이미 푼 셈이기 때문이다. 논문은 여기서 한 번 더 영리한 전환을 한다. steady solution 대신 현재 네트워크 출력을 넣는다.
f(q)−γ(q−qn)=0
여기서 qn은 현재 outer step에서의 네트워크 추정값이다. 이 식은 곧바로 pseudo-time stepping으로 읽을 수 있다.
Δτq−qn=f(q),Δτ=1/γ
이것이 TSONN(Time-Stepping-Oriented Neural Network)이다. 직관적으로 보면 standard PINN은 최종 steady solution으로 한 번에 점프하려 하고, TSONN은 pseudo time을 따라 여러 개의 더 잘-conditioned된 subproblem을 푼다. 즉 큰 협곡 하나를 뛰어넘으려는 대신, 경사가 완만한 계단을 여러 번 오른다고 보면 된다.
논문이 강조하는 TSONN의 핵심은 다음 세 가지다.
TSONN을 solver처럼 읽는 법
outer iteration현재 추정 q_n을 기준 상태로 고정하고, 다음 pseudo-time step의 subproblem을 정의한다.
inner iteration그 subproblem을 충분히 풀어 다음 상태 q_next에 해당하는 네트워크 출력을 근사한다.
step size trade-offgain이 커질수록 각 subproblem은 쉬워지지만, steady state까지 더 많은 outer step이 필요하다.
이 논문은 2023년 TSONN 논문을 사실상 설명하고 정교화한 작업으로 읽을 수 있다. 특히 이번 논문은 왜 pseudo-time이 conditioning을 완화하는지, 왜 negative gain이 "reversed-time"처럼 ill-posed한지, 그리고 왜 pseudo-time 항이 PDE operator뿐 아니라 boundary/initial operator 바깥층까지 함께 들어가야 하는지를 더 명확히 설명한다.
여기서 중요한 사실 하나를 더 짚자. 논문은 PINN을 TSONN의 반대편에 있는 다른 방법이 아니라, Δτ→∞ 또는 γ→0인 특수한 경우로 본다. 즉 표준 PINN은 사실상 "pseudo-time step을 무한히 크게 잡은 implicit time-stepping"에 해당한다. 이 관점이 좋은 이유는, PINN을 버리는 대신 더 일반적인 solver family 안에 재배치하기 때문이다.
제7장: 사례 확장 — airfoil과 M6 wing이 왜 중요한가
논문이 NACA0012 airfoil과 3D M6 wing까지 가는 이유도 여기에 있다. toy PDE에서는 많은 아이디어가 좋아 보일 수 있지만, 고 Reynolds, 복잡 형상, sharp transition, 3차원 압력 분포처럼 공학적으로 난이도 높은 문제에서야 방법의 한계와 장점이 더 분명하게 드러난다.
NACA0012: "mesh-free"만으로는 부족하고, conditioning이 붙어야 한다
저자들은 먼저 Re=5000의 NACA0012 airfoil을 다룬다. 흥미로운 부분은, TSONN이 PINN의 mesh-free 특성을 유지하면서도 실제 계산에서는 여전히 background grid의 점들을 collocation points로 쓴다는 점이다. 즉 "mesh-free"는 메시 생성의 엄밀한 부재를 뜻한다기보다, solver 구조가 grid-based linear algebra에 직접 묶여 있지 않다는 뜻에 가깝다.
이 실험에서 standard PINN은 의미 있는 결과를 거의 내지 못한다. 반면 TSONN은 pseudo-time step을 줄여 가며 더 안정적인 수렴을 얻고, 최종적으로 약 2% 수준의 relative error를 달성한다. 특히 압력 contour와 wall pressure coefficient 분포가 reference와 상당히 가깝게 맞는다.
M6 wing: 논문의 상징적 장면
M6 wing은 CFD에서 널리 쓰이는 benchmark geometry다. 이 논문은 Re=5000의 incompressible laminar setting에서 3D M6 wing 주위를 계산한다. 저자 표현대로 이는 이 형상에서 다룰 수 있는 거의 최대 수준의 laminar Reynolds 수에 가깝다. 다시 말해, 아직 turbulence model까지 간 것은 아니지만 "PINN이 공학적으로 만만한 장난감만 푸는가?"라는 질문에는 매우 강한 답이 된다.
논문 결과에서 TSONN은 wall pressure distribution 기준 약 6%의 relative error를 보인다. 가장 큰 오차는 wing root leading edge 부근, 즉 압력과 유동장이 더 급하게 변하는 구간에 집중된다. 이 또한 중요한 메시지다. conditioning을 개선해도 어려운 영역이 사라지는 것은 아니다. 다만 이제는 문제가 어디서 남는지 설명 가능한 수준까지 도달한다.
왜 NACA0012와 M6 wing이 중요할까
NACA0012
2D airfoil은 경계층, 압력분포, 형상 민감도를 동시에 가진다. PINN이 toy PDE에서 실제 CFD로 넘어가는 첫 관문이다.
M6 wing
3D geometry와 spanwise pressure variation까지 포함한다. 여기서 성능이 나오면 "conditioning을 다루는 PINN"이 공학 문제에 닿는다는 신호가 된다.
핵심 해석
이 논문은 PINN이 모든 난제를 해결했다고 주장하지 않는다. 다만 ill-conditioning을 정면으로 다루면 난이도 높은 형상까지 밀어 올릴 수 있음을 보여 준다.
이 장면은 2026년 시점에서도 여전히 참고할 만하다. 고차원 operator learning이 강해졌다고 해도, geometry-specific하고 data-scarce한 유동 문제에서는 여전히 conditioning을 통제하는 optimization-based solver가 유효한 선택지로 남아 있기 때문이다.
2026년 시점에서 보면, 이 논문이 남긴 유산은 "PINN을 포기하자"보다 "PINN을 어디에, 어떤 형태로 써야 하는지 다시 배치하자"는 쪽에 더 가깝다. 이 글의 해석으로는, PINN은 단독 만능 해법이라기보다 conditioning을 얼마나 잘 다루느냐, 그리고 어떤 문제 클래스에 적용하느냐에 따라 성격이 크게 달라지는 도구로 읽힌다.
이 글의 해석으로는, 2026년의 역할 지도를 아래처럼 조심스럽게 정리해 볼 수 있다.
문제 유형
자주 거론되는 선택지
이 글의 해석
희소 데이터 inverse problem
PINN / adaptive PINN
데이터와 물리 제약을 동시에 써야 하는 경우가 많고, geometry별 fine-tuning을 감수할 수 있다.
복잡 형상 laminar CFD
TSONN, XPINN/APINN, hybrid PINN-solver
실무에서는 종종 conditioning과 domain decomposition을 함께 다뤄야 안정성이 나온다.
대규모 반복 추론, operator family 학습
Neural operator(FNO 등)
많은 경우 문제 하나를 푸는 것보다 문제 family 전체의 연산자를 학습하는 편이 더 효율적이다.
고정밀 산업 해석 파이프라인
Hybrid solver
실무에서는 종종 클래식 CFD / FEM을 주해석기로 두고, PINN 계열은 보정·역문제·warm start에 붙이는 편이 더 안전하다.
이 그림 역시 정답표라기보다, 현재 문헌과 실무 감각을 함께 놓고 읽은 editorial summary에 가깝다. 그 전제 위에서 각 방법의 역할을 적어 보면 이렇다.
PINN은 여전히 inverse problem과 sparse sensing에서 강점을 보이는 경우가 많다. 다만 forward solve를 직접 맡길 때는 loss balancing, hard constraint, adaptive sampling 같은 안정화 기법이 함께 논의되는 경우가 많다.
APINN / XPINN 계열은 "문제가 너무 크거나 한 네트워크로 학습하기 어렵다"는 상황에서 종종 거론된다. conditioning 문제를 공간 분해로 완화한다는 점에서, 이 논문의 Jacobian 관점과 잘 맞물린다.
Neural operator는 반복 추론이 핵심일 때 대체로 유리하다. 충분한 학습 데이터와 parameterized family가 있다면, FNO류는 "한 문제를 매번 풀기"보다 "연산자 자체를 학습하기"에 적합한 경우가 많다.
Hybrid solver는 실제 산업 현장에서 종종 가장 실용적인 절충안 가운데 하나로 읽힌다. 예를 들어 classical solver가 coarse solution이나 supervision을 제공하고, PINN/TSONN이 inverse correction이나 differentiable optimization을 맡는 구성이 그렇다.
정리하면, 이 논문은 2026년 scientific ML landscape에서 PINN을 밀어냈다기보다 PINN이 설 자리를 더 정교하게 규정하는 데 기여했다. 물리를 손실에 넣는 것만으로는 충분하지 않을 수 있지만, conditioning을 함께 다루면 solver family의 한 축으로 읽을 여지가 커진다는 것이 이 글의 해석이다.
마치며
이 글에서 남는 요지는 비교적 단순하다. 좋은 함수 근사기와 좋은 반복 풀이기는 다른 문제다. 이 논문은 PINN의 어려움을 Jacobian, condition number, gain, pseudo-time stepping이라는 언어로 더 구체적으로 설명하려고 시도한다.
그래서 이 글의 결론은 PINN 찬양도, PINN 회의론도 아니다. 오히려 다음에 가깝다.
PINN을 쓰고 싶다면 conditioning을 함께 물어볼 필요가 있다.
conditioning을 개선하려면 문제를 time stepping이나 domain decomposition, preconditioning 관점에서 다시 쓰는 접근이 유력한 후보가 된다.
2026년의 실무에서는 PINN, APINN, neural operator, classical solver를 경쟁 관계보다 역할 분담 관계로 보는 편이 대체로 더 생산적이다.
그래서 PINN을 볼 때는 "이 모델이 물리를 알고 있는가?"와 함께, "이 모델이 풀고 있는 문제는 얼마나 잘-conditioned한가?"를 같이 물어볼 필요가 있다.
Maziar Raissi, Paris Perdikaris, George Em Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics 2019
Sifan Wang, Yujun Teng, Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing 2021
Sifan Wang, Xinling Yu, Paris Perdikaris. When and why PINNs fail to train: A neural tangent kernel perspective.Journal of Computational Physics 2022
Ameya D. Jagtap, George Em Karniadakis. Extended Physics-Informed Neural Networks (XPINNs): A Generalized Space-Time Domain Decomposition Based Deep Learning Framework for Nonlinear Partial Differential Equations.Communications in Computational Physics 2020
Zongyi Li et al. Fourier Neural Operator for Parametric Partial Differential Equations.ICLR 2021 / arXiv:2010.08895