PINN은 왜 고주파·다중 스케일 문제에서 자주 무너질까? NTK 관점으로 학습 실패의 구조를 해부한 고전 논문을 중심으로, PINN의 병목과 해결 전략, 그리고 2026년 현재 이 통찰이 어디까지 이어졌는지 깊고 쉽게 풀어본다.
코어닷투데이2026-04-1948분
들어가며 — 정답 방정식이 있는데도 왜 학습이 망가질까?
PINN, 즉 Physics-Informed Neural Network가 처음 주목받았을 때 많은 연구자들은 거의 같은 기대를 품었다. 데이터가 부족해도 괜찮고, 지배 방정식만 알고 있으면 신경망이 물리적으로 말이 되는 해를 학습해 줄 것이라는 기대였다. 이 기대는 허황되지 않았다. 실제로 부드러운 해를 가지는 몇몇 PDE에서는 PINN이 적은 관측 데이터만으로도 꽤 인상적인 결과를 보여 주었다.
그런데 조금만 어려운 문제로 가면 분위기가 바뀌었다. 경계층이 얇은 유동, 진동성이 강한 Helmholtz 방정식, 파동처럼 위상이 민감한 문제, 서로 다른 길이 스케일이 한꺼번에 섞인 문제에서는 PINN이 이상할 정도로 자주 무너졌다. 손실은 내려가는데 해는 틀리고, 경계는 잘 맞는데 내부 잔차는 남고, 전체 형상은 얼추 맞는데 고주파 구조는 사라지는 일이 반복됐다.
이 아이러니를 한 문장으로 줄이면 이렇다.
물리법칙을 알고 있는데도, 왜 신경망은 그 물리를 제대로 배우지 못하는가?
2020년에 공개된 When and Why PINNs Fail to Train: A Neural Tangent Kernel Perspective는 이 질문을 정면으로 다뤘다. 이 논문의 중요성은 "PINN이 잘 안 된다"는 불만을 다시 말한 데 있지 않다. 왜 안 되는지를 학습 동역학의 언어로 설명했다는 점에 있다. 특히 NTK, 즉 Neural Tangent Kernel 관점에서 보면, PINN의 실패는 단순한 튜닝 실수나 운 나쁜 초기화만의 문제가 아니다. 손실을 구성하는 항들이 애초에 서로 다른 속도로 학습되도록 짜여 있는 구조적 문제일 수 있다는 것이다.
이 글은 그 논문을 중심축으로 삼되, 단순 요약에 머물지 않는다. 먼저 PINN이 왜 그렇게 큰 기대를 받았는지 돌아보고, NTK라는 렌즈가 왜 필요한지 설명한 뒤, 논문이 실제로 무엇을 밝혔는지 하나씩 해부한다. 그리고 마지막에는 2026년 현재, adaptive weighting과 도메인 분해, neural operator, hybrid solver가 어떤 역할 분담 위에 서 있는지도 차분하게 짚어본다.
핵심 결론을 미리 한 줄로 말하면 이렇다.
PINN의 실패는 물리를 손실함수에 넣는 것만으로는 학습이 자동으로 정렬되지 않는다는 사실의 발견이었다.
제1장: 배경 — PINN은 왜 필요했고 왜 기대가 컸는가?
PINN은 딥러닝 유행의 부산물이 아니었다. 계산과학과 공학 현장에는 오래된 간극이 있었다. 한쪽에는 유한차분법, 유한요소법, 유한체적법처럼 물리적으로 정직하지만 계산 비용이 큰 수치해석이 있었고, 다른 한쪽에는 빠르고 유연하지만 물리를 모르는 순수 데이터 기반 학습이 있었다.
수치해석은 믿을 만하다. PDE가 맞고 경계조건이 맞으면 해도 그 체계 안에서 해석 가능하다. 하지만 도메인이 복잡하거나 반복 평가가 많아지면 계산비가 급증한다. 반대로 일반 신경망은 한 번 학습하고 나면 빠르지만, 학습 범위를 벗어나면 에너지 보존도, 경계 조건도, 연속성도 너무 쉽게 잊는다.
PINN은 이 둘 사이에 다리를 놓으려 했다. 핵심 아이디어는 단순하다. 신경망이 내놓은 함수가 데이터를 맞추는 것뿐 아니라 방정식도 만족하게 만들자. 이를 위해 손실함수에 PDE 잔차와 경계조건 위반을 같이 넣는다.
훈련 과정에서 네트워크는 단순히 "정답 레이블"만 외우는 것이 아니라, 도메인 내부의 콜로케이션 포인트에서 방정식을 만족하는 함수를 찾아가게 된다. 이것이 PINN의 매력이다. 실측 데이터가 희소해도 물리가 강력한 정규화로 작동할 수 있기 때문이다.
이 방식이 2019년 전후 크게 주목받은 또 하나의 이유는 자동미분이었다. PINN은 유한차분으로 미분을 근사하는 대신, 신경망 출력 uθ(x)를 입력 x에 대해 직접 미분해 PDE 잔차를 계산한다. 즉, 신경망은 단순한 근사기가 아니라 미분 가능한 함수 공간의 후보가 된다.
세 가지 문제 해결 방식
전통 수치해석FEM / FDM / FVM정확하지만 반복 계산 비용 큼
순수 데이터 기반 NN지도학습빠르지만 물리 제약 약함
PINN데이터 + PDE 잔차희소 데이터와 물리 제약을 함께 사용
이 때문에 PINN은 특히 다음 같은 문제에서 유망해 보였다.
관측 데이터가 적지만 지배 방정식은 명확한 역문제
반복 시뮬레이션이 비싼 공학 설계의 surrogate 학습
복잡한 기하나 매개변수 추정이 포함된 scientific ML 문제
하지만 여기서 놓치기 쉬운 사실이 있다. 손실에 물리를 추가했다는 것은 문제를 더 잘 정의했다는 뜻이지, 학습이 자동으로 쉬워졌다는 뜻은 아니다. 오히려 서로 다른 성격의 손실 항을 한 네트워크에 동시에 밀어 넣으면서, 최적화는 더 복잡해질 수 있다. 이 지점에서 다음 장의 이야기가 시작된다.
제2장: 역사 — 2019년 열광에서 2020년 학습 병목 인식으로
Raissi와 공동 연구자들이 2019년에 발표한 PINN 논문은 과학 AI에 강한 인상을 남겼다. 희소한 데이터만으로 Burgers 방정식 해를 복원하고, 역문제에서 미지의 계수를 추정하고, 자동미분으로 PDE 잔차를 계산하는 그림은 매우 설득력 있었다. "물리를 아는 딥러닝"이라는 말 자체가 하나의 연구 프로그램이 됐다.
초기의 성공 사례는 실제로 존재했다. 해가 비교적 매끈하고, 주파수 성분이 낮고, 문제 규모가 크지 않은 경우에는 PINN이 잘 작동했다. 특히 forward solve보다 inverse problem에서 더 매력적으로 보였다. 데이터와 물리를 동시에 쓰면서 미지의 계수나 파라미터를 추론하는 데 장점이 있었기 때문이다.
그러나 연구자들이 더 어려운 PDE에 PINN을 적용하기 시작하면서 공통된 패턴이 드러났다.
손실 항 중 하나만 빠르게 줄고 다른 항은 거의 줄지 않는다.
경계조건은 잘 맞는데 내부 residual은 남는다.
반대로 residual은 낮은데 정작 해가 틀린 경우도 생긴다.
고주파 해나 다중 스케일 구조를 거의 학습하지 못한다.
학습률을 조금만 높여도 불안정해지고, 낮추면 지나치게 느리다.
이 시기에는 "PINN이 안 된다"는 식의 회의론도 있었지만, 더 중요한 변화는 질문의 방향이었다. 문제는 더 이상 단순히 "사례에 따라 잘 되기도 하고 안 되기도 한다"가 아니었다. 왜 이런 실패가 반복되는가가 핵심이 됐다.
이 흐름에서 중요한 전환점이 바로 Wang, Yu, Perdikaris의 NTK 논문이다. 이 논문은 경험적으로 관찰되던 학습 병목을 함수공간의 동역학으로 옮겨 놓았다. "네트워크가 물리를 잘 못 배운다"는 인상을, 어떤 모드가 얼마나 빨리 수렴하는가라는 질문으로 번역한 것이다.
이 전환은 매우 중요했다. 왜냐하면 그 순간부터 PINN 연구는 손실을 하나 더 붙이는 요령의 문제가 아니라, 학습 시스템 자체의 조건수와 스펙트럼 구조를 다루는 문제가 되었기 때문이다.
제3장: 준비 운동 — NTK를 모르면 이 논문의 핵심이 안 보인다
NTK는 처음 들으면 다소 위협적으로 보이는 용어다. 하지만 이 논문에서 필요한 직관은 생각보다 단순하다. NTK는 현재 네트워크가 어떤 함수 방향으로 얼마나 잘 움직일 수 있는지를 보여 주는 커널이다.
정의는 다음과 같다.
K(x,x′)=⟨∂θ∂f(x,θ),∂θ∂f(x′,θ)⟩
이 식은 아주 많은 것을 말해 준다. 입력 x와 x′에서의 출력이 같은 파라미터 변화에 얼마나 같이 반응하는지를 보는 것이다. 즉, NTK는 파라미터 공간의 기울기 정보를 함수 공간으로 밀어 올린다.
좀 더 직관적으로 말하면 이렇다.
어떤 함수 모드의 NTK 고유값이 크면 그 모드는 gradient descent로 빨리 줄어든다.
어떤 함수 모드의 NTK 고유값이 작으면 그 모드는 거의 움직이지 않는다.
그래서 NTK는 "이 네트워크가 지금 무엇을 빨리 배우고 무엇을 늦게 배우는가"를 알려 준다.
PINN 맥락에서는 이 직관이 특히 중요하다. 왜냐하면 우리가 학습시키려는 것은 단순한 출력 함수 하나가 아니라, 경계에서의 값과 도메인 내부에서의 미분 잔차를 동시에 만족하는 함수이기 때문이다. 다시 말해 PINN은 단일 예측 오차를 줄이는 문제가 아니라, 서로 다른 공간에서 측정된 여러 오차를 함께 줄이는 문제다.
NTK를 보면 이 복합 문제가 어느 지점에서 꼬이는지 보인다. 고전적인 완전연결 신경망은 원래부터 spectral bias, 즉 저주파를 먼저 배우고 고주파를 늦게 배우는 경향이 있다. PINN은 이 성향 위에 PDE 미분 연산자가 얹힌다. 그러면 고주파 성분은 더 까다로워지고, 잔차 손실과 경계 손실이 서로 다른 속도로 수렴할 가능성이 커진다.
NTK를 PINN에 필요한 만큼만 요약하면
정의
출력이 파라미터 변화에 얼마나 민감한지, 그리고 서로 다른 입력점들이 그 변화를 얼마나 공유하는지를 나타내는 커널
학습 의미
고유값이 큰 모드는 빨리 수렴하고, 작은 모드는 느리게 수렴한다
PINN에서의 핵심
경계 손실과 residual 손실이 같은 속도로 줄지 않을 수 있으며, 이 불균형이 해의 왜곡이나 학습 붕괴로 이어진다
아래 막대는 논문의 측정값을 그대로 옮긴 그래프가 아니라, FCN 기반 PINN의 spectral bias와 NTK 직관을 요약한 개념도다.
모드별 전형적 학습 속도 (개념도)
저주파 모드
빠른 수렴
중간 주파수 모드
조건 의존적
고주파 모드
매우 느림
이제 논문이 왜 NTK를 꺼냈는지 이해할 수 있다. PINN의 실패는 막연한 현상이 아니라, 특정 손실 항과 특정 주파수 모드가 구조적으로 늦게 학습되는 문제일 수 있다. 다음 장이 바로 그 핵심이다.
제4장: 논문 본론 — 이 논문은 정확히 무엇을 보였는가
이 논문의 출발점은 간단하다. PINN을 경계 손실과 residual 손실의 합으로 두고, gradient flow 아래에서 네트워크 출력과 PDE residual이 어떻게 진화하는지 쓰면, 그 동역학을 NTK 블록 행렬로 표현할 수 있다는 것이다.
여기에 경계-잔차 사이의 상호작용을 나타내는 Kur, Kru까지 묶으면 PINN의 NTK가 된다.
이 식들이 왜 중요한가? 많은 설명을 걷어 내고 본질만 말하면, 논문은 네 가지를 보여 준다.
1. PINN도 NTK 관점에서 학습 동역학을 읽을 수 있다
논문은 선형 PDE와 무한 폭 근사 아래에서 PINN의 NTK가 초기화에서 결정론적 커널로 수렴하고, 학습 중 거의 상수처럼 유지된다는 점을 보인다. 이는 표준 NTK 이론을 PINN으로 가져온 것이다.
이 말은 곧, 충분히 넓은 네트워크에서는 PINN 학습을 비선형 파라미터 최적화가 아니라 커널 회귀에 가까운 선형 동역학처럼 분석할 수 있다는 뜻이다.
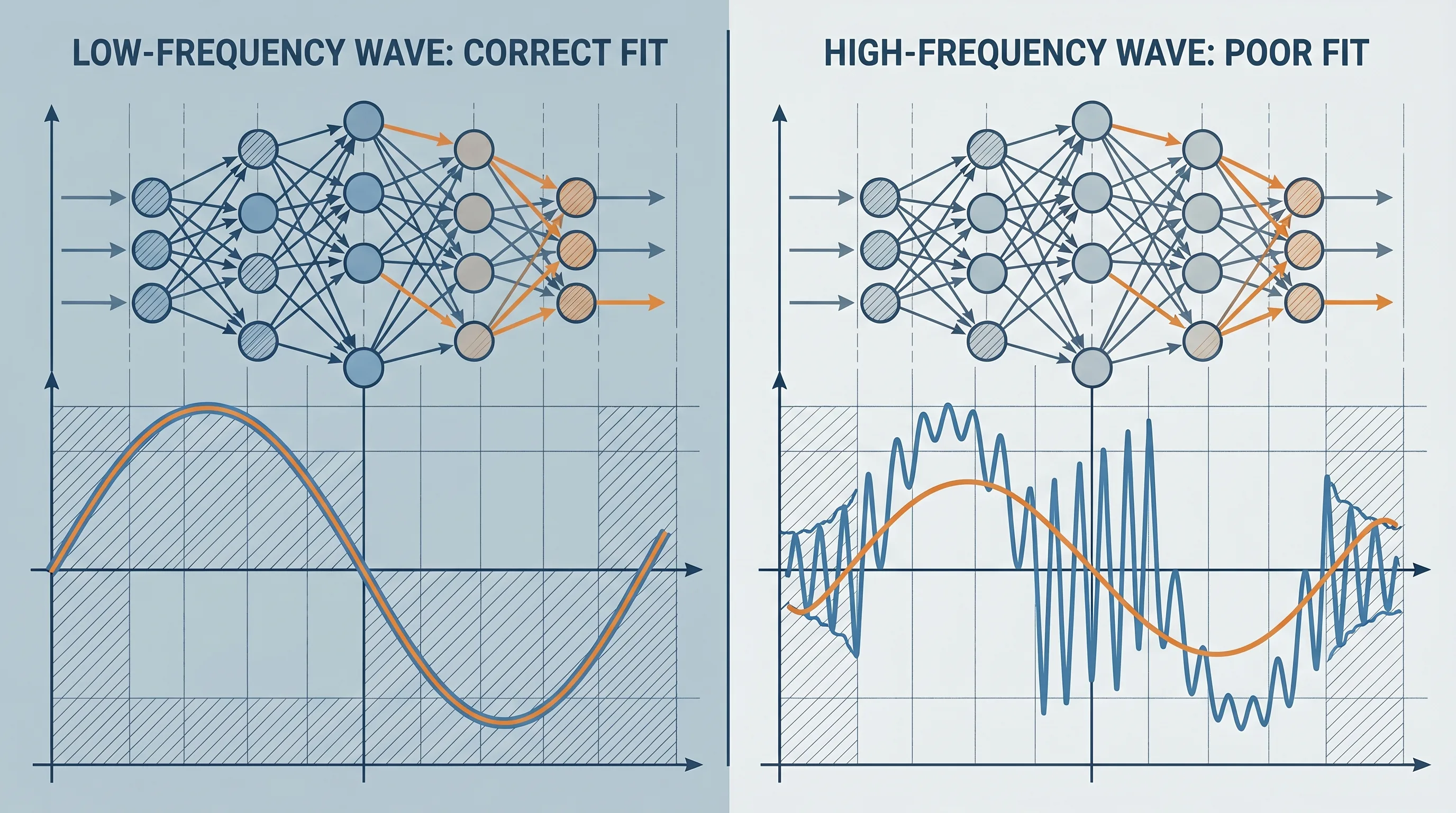
2. PINN은 일반 신경망과 마찬가지로 spectral bias를 가진다
즉, 완전연결 기반 PINN은 저주파 성분을 먼저 학습하고, 고주파 성분은 늦게 배운다. PDE를 손실에 넣는다고 해서 이 경향이 자동으로 사라지지 않는다. 오히려 Helmholtz처럼 본질적으로 진동성이 강한 문제에서는 이 약점이 더 선명해진다.
3. 더 치명적인 문제는 손실 항 간 수렴 속도 불일치다
논문의 핵심은 여기 있다. 전체 오차는 하나처럼 보이지만, 실제로는 경계 손실과 residual 손실이 전혀 다른 고유값 스펙트럼 위에서 움직인다. 그래서 어떤 항은 빠르게 줄고, 어떤 항은 거의 멈춘다.
실제로 논문은 선형 PDE, 무한 폭, gradient flow에 가까운 가정 아래에서 PINN NTK의 여러 블록이 서로 다른 고유값 스펙트럼과 수렴률을 가질 수 있음을 분석한다. 실무 설명에서는 이를 종종 "Krr 쪽이 더 빠르다" 혹은 "Kuu 쪽이 더 느리다"처럼 축약해 말하지만, 논문의 핵심은 단순한 스칼라 크기 비교보다 어떤 고유모드가 얼마나 빨리 줄어드는지에 있다. 즉, Kuu와 Krr의 상대적 규모는 직관을 주는 휴리스틱일 수 있지만, 그것만으로 학습 성공과 실패를 판정하는 충분조건은 아니다.
4. 바로 그 불일치가 "물리를 알고도 실패하는" 이유다
PINN은 물리식을 알고 있다. 하지만 gradient descent는 손실을 해석적으로 이해하지 않는다. 그저 더 빨리 줄어드는 방향으로 움직일 뿐이다. 만약 residual 공간의 어떤 모드는 빠르게 줄고 경계 공간의 중요한 모드는 느리게 남는다면, 네트워크는 물리를 아는 척하면서도 정답 해에 도달하지 못할 수 있다.
이것이 논문의 가장 중요한 통찰이다. 문제는 물리 정보의 부재가 아니라, 물리 정보가 최적화 안에서 균형 있게 전달되지 않는다는 것이다.
항목
무엇을 측정하나
실무에서 보이는 현상
Kuu
경계/데이터 값이 파라미터 변화에 얼마나 잘 반응하는가
값 맞춤은 되는데 내부 구조가 느리게 따라오는지 판단하는 단서
Krr
미분 연산이 걸린 residual이 얼마나 빨리 줄어드는가
residual 수치가 빨리 줄어도 해 자체는 틀릴 수 있음을 보여 줌
Kur,Kru
경계와 내부 잔차가 서로의 업데이트에 얼마나 얽혀 있는가
한쪽을 개선하는 업데이트가 다른 쪽을 거의 못 돕거나 방해할 수 있음
전체 NTK
PINN 전체 훈련의 함수공간 동역학
총손실 하나만 보면 놓치는 불균형을 드러냄
왜 Kuu와 Krr 구분이 실무적으로 중요한지는 아주 현실적인 예로 설명할 수 있다. 다만 아래 설명은 논문의 블록 스펙트럼 분석을 이해하기 위한 직관적 요약이지, 단일 수치 비교만으로 상태를 진단하는 규칙은 아니다.
Krr 쪽 모드가 더 빠르게 수렴하는 상황: residual 관련 오차는 빠르게 줄지만 경계 적합이 느려서, 해가 물리식 일부만 맞는 어정쩡한 상태로 남을 수 있다.
Kuu 쪽 모드가 상대적으로 더 빠른 상황: 경계나 데이터는 잘 맞지만 내부 PDE를 풀어야 하는 핵심 모드는 거의 업데이트되지 않는다.
전자는 "식은 맞는데 답이 틀린" 상태를 만들고, 후자는 "겉모습은 맞는데 물리적으로 틀린" 상태를 만든다. 둘 다 PINN 사용자에게는 익숙한 실패 패턴이다.
1. 초기화
네트워크는 특정 NTK 스펙트럼을 가진 상태에서 출발한다.
2. 분리
경계 블록과 residual 블록의 고유값 규모가 서로 다르게 형성된다.
3. 불균형
빠른 항은 계속 줄고 느린 항은 사실상 정지해 total loss 내부의 속도 차가 벌어진다.
4. 실패
물리를 알고 있어도 정답 해의 중요한 모드에 도달하지 못한다.
이제 질문은 자연스럽게 다음으로 넘어간다. 그렇다면 실제 PDE에서 이 차이는 어떻게 나타나는가?
제5장: 사례로 이해하기 — Poisson은 되고 Helmholtz는 왜 더 어렵나
PINN을 처음 접할 때 많은 사람이 혼란스러워하는 이유는, 어떤 문제에서는 꽤 잘 되고 어떤 문제에서는 거의 무력해 보이기 때문이다. NTK 관점은 이 차이를 "문제의 난이도"가 아니라 학습 가능한 모드의 스펙트럼 구조로 설명하게 해 준다.
Poisson 문제는 왜 비교적 잘 되는가
1차원 Poisson 방정식은 이 논문에서도 핵심 예제로 등장한다. 부드러운 forcing과 매끈한 해를 가지는 Poisson 문제에서는, 네트워크가 배워야 할 주요 모드가 상대적으로 저주파 쪽에 몰려 있는 경우가 많다. 완전연결 네트워크의 spectral bias와 크게 충돌하지 않는 셈이다.
쉽게 말해 Poisson 문제의 해가 "완만한 언덕" 같은 모양이면, FCN 기반 PINN은 그 큰 지형을 비교적 빨리 따라간다. 이때는 residual과 경계가 동시에 어느 정도 줄면서 그럴듯한 해를 얻을 수 있다.
Helmholtz와 wave는 왜 더 가혹한가
반면 Helmholtz 방정식이나 파동 방정식은 본질적으로 진동성이 강하다. 해 자체가 빠르게 오르내리고, 위상 오차도 치명적이다. 이 경우 네트워크는 고주파 모드와 미세한 간섭 패턴을 잡아야 한다. 하지만 완전연결 네트워크는 원래 이런 모드를 늦게 배운다.
즉, 문제는 "물리식을 몰라서"가 아니다. 물리식이 요구하는 함수 모드가 네트워크가 가장 늦게 배우는 모드라는 데 있다.
다중 스케일과 경계층은 또 다른 함정이다
경계층 문제를 생각해 보자. 도메인 대부분은 완만하지만, 아주 얇은 영역에서 해가 급격히 변한다. PINN은 큰 구조와 얇은 급변 구조를 동시에 표현해야 한다. 그런데 gradient descent는 먼저 넓고 부드러운 구조를 설명하는 방향으로 움직인다. 그 결과 경계층은 끝까지 흐릿하게 남거나, 내부 residual이 특정 좁은 영역에서만 크게 남는다.
이런 실패는 종종 다음처럼 관찰된다.
전체 곡선은 맞는 것처럼 보이는데 경계 근처가 틀린다.
경계는 맞는데 도메인 내부의 진동 위상이 어긋난다.
저주파 외피(envelope)는 맞는데 고주파 리플이 사라진다.
아래 막대 역시 논문의 정량 벤치마크를 재현한 결과가 아니라, 대표 PDE 계열에서 자주 관찰되는 병목을 질적으로 묶어 놓은 개념도다.
PDE 유형별 전형적 PINN 난이도 (질적 개념도)
부드러운 Poisson
낮음
중간 주파수 wave
중간
고주파 Helmholtz
높음
경계층·다중 스케일
매우 높음
문제 구조에 따라 달라지는 병목
Poisson매끈한 저주파 해spectral bias와 비교적 덜 충돌
Helmholtz / Wave진동성과 위상 민감성고주파 모드 학습 지연이 치명적
Boundary Layer얇은 급변 영역 + 넓은 완만 영역다중 스케일 충돌과 샘플링 불균형
여기서 중요한 교훈은 간단하다. PINN 실패를 "데이터가 적어서"라고만 보면 절반만 본 것이다. 더 정확히는, 학습 동역학이 어떤 모드를 거의 무시하도록 되어 있어서 실패하는 경우가 많다. NTK는 바로 그 보이지 않던 차이를 드러낸다.
제6장: 해결 — adaptive weighting은 무엇을 바꾸려 했는가
논문이 제안하는 처방은 놀랍도록 상식적이면서도 중요하다. 만약 손실 항들이 서로 다른 속도로 수렴하는 것이 문제라면, 가중치를 조절해 그 수렴 속도를 맞춰 보자는 것이다.
겉으로 보면 이것은 흔한 loss reweighting처럼 보인다. 하지만 논문의 포인트는 단순한 손실 크기 균형이 아니다. 중요한 것은 현재 손실 값이 아니라, NTK 스펙트럼이 암시하는 평균 수렴 속도다. 다시 말해 "누가 더 크냐"보다 "누가 더 빨리 줄어드느냐"를 맞추려는 시도다.
논문은 Kuu, Krr, 그리고 전체 커널의 trace를 이용해 각 항의 평균 수렴률을 추정하고, 느린 항의 가중치를 상대적으로 키우는 적응형 규칙을 제안한다. 직관은 이렇다.
이미 빨리 줄고 있는 항은 더 세게 밀 필요가 없다.
너무 느리게 줄어드는 항은 더 큰 비중을 받아야 한다.
목표는 모든 손실 항을 같은 값으로 만드는 것이 아니라, 학습 속도를 덜 어긋나게 만드는 것이다.
이 접근은 실전에서 꽤 합리적이다. 왜냐하면 많은 PINN 실패가 "한 항이 너무 작다"가 아니라, 한 항의 업데이트가 거의 진행되지 않는다는 형태로 나타나기 때문이다.
전략
무엇을 맞추려 하나
기대 효과
고정 가중치
사용자가 정한 비율을 끝까지 유지
문제마다 다른 스펙트럼 불균형을 반영하지 못함
gradient 크기 균형
역전파된 기울기 규모를 맞춤
불안정성 완화에 도움되지만 모드별 수렴 속도까지 직접 설명하진 못함
NTK 기반 adaptive weighting
각 손실 성분의 평균 수렴률을 정렬
느린 항을 살려 총학습의 불균형을 줄이는 데 초점
adaptive weighting의 직관적 루프
진단Kuu와 Krr의 trace 혹은 스펙트럼 규모를 본다.
판정어느 손실 항이 지나치게 빠르거나 느린지, 어느 모드가 방치되는지 확인한다.
재가중느린 항의 가중치를 상대적으로 올려 convergence mismatch를 줄인다.
재평가다음 구간에서 다시 스펙트럼을 보고 필요하면 조정한다.
하지만 여기서 과장하면 안 된다. adaptive weighting은 중요한 처방이지만 만능약은 아니다.
첫째, 이 방법은 표현력 문제 자체를 해결하지 않는다. 네트워크가 고주파 모드를 본질적으로 잘 표현하지 못하면, 가중치를 조절해도 한계가 남는다.
둘째, 논문이 가장 강한 형태로 성립하는 이론은 선형 PDE, 무한 폭, 극소 학습률 같은 조건에 기대고 있다. 실제 비선형 PDE와 유한 폭 네트워크에서는 NTK가 완전히 고정돼 있지 않다.
셋째, 재가중은 어디까지나 불균형 완화이지, 고차원 복잡 기하나 극단적 다중 스케일 문제를 단일 FCN PINN으로 해결하는 만능 스위치는 아니다.
그래서 이후 연구는 adaptive weighting만으로 멈추지 않았다. gradient pathologies를 겨냥한 annealing, 샘플링을 다시 설계하는 residual-based adaptive sampling, 고주파 표현을 돕는 Fourier feature와 SIREN 계열, 시간 순서를 이용하는 causal training, 그리고 아예 문제를 쪼개는 domain decomposition으로 흐름이 이어졌다.
제7장: 2026년 관점 — 이 논문의 역할은 끝났는가
2026년 현재 돌아보면, 이 NTK 논문은 PINN 열풍의 찬물을 끼얹은 반대 논문이라기보다, PINN을 진지하게 다룰 때 자주 출발점이 되는 진단 프레임을 제공한 논문에 가깝다.
지금도 이 논문이 중요한 이유는 세 가지다.
PINN 실패를 감각적 경험담이 아니라 학습 이론의 언어로 번역했다.
후속 기법들이 무엇을 해결하려는지 공통 기준을 제공했다.
"물리를 손실에 넣었다"는 선언만으로는 충분하지 않다는 점을 분명히 했다.
다만 이 대목에서는 톤을 조금 낮출 필요가 있다. 아래 정리는 어떤 보편 법칙이라기보다, PINN 원논문, NTK 해석 논문, cPINN/XPINN 계열, APINN, FNO, 그리고 최근의 solver-coupled 예시인 NewPINNs 같은 대표 문헌과 현장 적용 경향을 함께 읽으며 정리한 필자의 요약이다. 실제 선택은 PDE 종류, 데이터 가용성, 반복 추론 수요, 기존 solver 자산에 따라 달라진다.
2026년 scientific ML에서 자주 보이는 역할 분담 (필자 요약)
단일 PINN + weighting희소 데이터, 역문제작고 구조가 분명한 문제에서 여전히 선택되는 편
XPINN / APINN도메인 분해다중 스케일, 복잡 기하, 경계층에서 자주 검토됨
Neural Operator / Hybrid Solver대규모 반복 추론반복 추론과 solver 결합이 중요할 때 유력한 대안이 됨
계열
잘 맞는 문제
한계
기본 PINN
희소 관측, 파라미터 식별, 작은 규모 forward/inverse 문제에서 자주 먼저 시도됨
고주파, 다중 스케일, 큰 도메인에서는 빠르게 한계가 드러나는 편
adaptive weighting PINN
loss mismatch가 주된 병목으로 의심되는 문제
표현력과 아키텍처 한계를 직접 바꾸지는 못함
XPINN / APINN
복잡 형상, 경계층, 지역별 다른 스케일이 있는 문제에서 자주 강점을 보임
분할 설계와 인터페이스 처리 비용이 추가됨
Neural Operator
많은 인스턴스에 대한 빠른 반복 추론, operator-level generalization
충분한 데이터와 분포 정의가 필요하며, 특정 inverse setting에서는 PINN보다 불리할 수 있음
Hybrid Solver
수치해석과 학습을 결합한 산업 워크플로
구축 비용이 높지만, 기존 solver 자산이 클수록 실무적으로 매력적일 수 있음
특히 APINN이나 XPINN 같은 도메인 분해 계열은 이 논문의 메시지를 다른 방식으로 계승한다고 볼 수 있다. NTK 기반 adaptive weighting이 "한 네트워크 안에서 속도를 맞추자"라면, 도메인 분해는 "애초에 한 네트워크가 감당하기 어려운 스케일 충돌을 쪼개자"는 방향에 가깝다. 또 neural operator 계열은 문제를 샘플별 PDE 해석이 아니라 연산자 학습으로 재정의한다. 즉, 같은 scientific ML 안에서도 질문 자체가 달라지고 있다.
그렇다면 이 논문은 무엇을 아직 해결하지 못했는가? 이것도 분명히 말해야 한다.
spectral bias의 근본 원인을 제거하지는 못한다.
완전연결 PINN 외의 아키텍처에서 동일한 병목이 어떻게 달라지는지 완전히 정리하지 못한다.
극단적 고주파, shock, 복잡한 비선형 다중물리 문제에 대한 보편 처방을 주지 못한다.
실제 산업 문제에서의 샘플링 전략, 도메인 분해, solver coupling까지 포함한 end-to-end 설계를 제공하지는 못한다.
하지만 바로 그 한계 때문에 이 논문은 여전히 유효하다. 모든 문제를 풀어서가 아니라, 어떤 문제가 왜 안 풀리는지 보는 기준을 만들었기 때문이다. 2026년의 더 세련된 방법들 역시 상당수가 이 기준과의 관계 속에서 자신의 장단점을 설명한다.
Makki et al. (2026), NewPINNs: solver-coupled hybrid 방향을 보여 주는 최근 예시 하나. 이 흐름 전체를 대표한다고 보기는 어렵지만, 2026년의 한 경향을 읽는 데는 유용하다.
마치며
PINN이 던진 약속은 여전히 매력적이다. 데이터가 부족한 곳에서 물리와 학습을 묶고, 수치해석과 딥러닝 사이를 연결하려는 시도는 scientific ML의 핵심 축 가운데 하나로 남아 있다. 다만 지금은 모두가 안다. 물리식을 손실함수에 더하는 것만으로 학습이 저절로 정렬되지는 않는다.
NTK 관점에서 본 PINN 실패는 그래서 중요한 전환점이었다. 이 논문은 "PINN은 왜 안 되는가"를 냉소적으로 선언한 것이 아니라, 언제, 왜, 어떤 방식으로 안 되는가를 더 정밀하게 묻도록 만들었다. 그 질문 덕분에 adaptive weighting이 나왔고, gradient pathology 연구가 이어졌고, Fourier feature와 causal training이 등장했고, XPINN과 APINN, neural operator, hybrid solver 같은 더 현실적인 대안들이 자리를 잡았다.
결국 우리가 얻은 교훈은 단순하다.
PINN의 실패는 아이디어의 실패가 아니라, 물리를 손실에 넣는 것만으로는 충분하지 않다는 사실의 발견이었다.