들어가며: 또 하나의 '딥시크 모먼트'
2025년 1월의 충격을 기억하는가. 항저우의 AI 스타트업 DeepSeek이 R1 한 편으로 NVIDIA 시가총액 5,890억 달러를 하루 만에 증발시켰던 그날. 당시의 키워드는 "오픈소스가 OpenAI o1 수준에 도달했다" 였다.
그로부터 15개월이 지난 2026년 4월 24일, 같은 회사가 다음 카드를 꺼냈다. 이름은 DeepSeek-V4 Preview — 두 가지 모델로 구성된다.
- DeepSeek-V4-Pro: 총 1.6T(1조 6천억) 파라미터, 토큰당 49B 활성, 100만 토큰 컨텍스트가 기본
- DeepSeek-V4-Flash: 284B 파라미터, 13B 활성, 똑같이 100만 토큰 기본

스펙만 보면 "또 더 큰 모델 나왔구나" 정도일지도 모른다. 그러나 V4가 들고 온 진짜 이야기는 숫자가 아니라 효율이다. 같은 100만 토큰을 처리할 때 V4-Pro는 직전 모델 V3.2 대비:
- KV 캐시는 10% — 동일한 GPU에 10배 긴 문맥을 올릴 수 있다는 뜻
- 싱글 토큰 추론 FLOPs는 27% — 토큰 한 개 만드는 데 드는 연산도 4분의 1 미만
- GQA(Grouped Query Attention) 8헤드 bfloat16 기준으로는 KV 캐시 약 2%
V4-Flash로 가면 더 무자비해진다. 같은 1M 시점에서 KV 캐시 7%, FLOPs 10%다. Hugging Face 공식 블로그가 한 줄로 정리한 표현이 인상적이다 — "a million-token context that agents can actually use" (에이전트가 진짜로 쓸 수 있는 100만 토큰 컨텍스트).
게다가 MIT 라이선스다. 가중치는 Hugging Face와 ModelScope에 그대로 풀렸고, 출시 한 달 만에 다운로드 12만 건을 돌파했다. GPT-5.4 xHigh, Claude Opus 4.6 Max, Gemini 3.1-Pro High와 같은 프론티어 폐쇄 모델과 같은 표 위에 처음으로 다시 오픈소스 모델이 올라선 순간이다.
이 글은 그 V4 Preview를 처음부터 풀어본다. (1) DeepSeek은 어디서 왔고, (2) V4의 다섯 가지 핵심 혁신은 무엇이며, (3) 벤치마크와 실제 사용 사례가 어떻게 나오는지, 그리고 (4) 2026년 봄 현재 V4를 실무에 어떻게 끼워 넣을 수 있는지.
TL;DR
- 하이브리드 어텐션 (CSA + HCA): 4배 압축한 희소 선택 어텐션과 128배 압축한 밀집 어텐션을 레이어마다 교차. 1M 컨텍스트의 KV 캐시·FLOPs 폭발을 깨뜨림
- mHC (Manifold-Constrained Hyper-Connections): 잔차 연결을 다양체 제약 하이퍼커넥션으로 교체, 깊은 신경망의 신호 전파 안정성↑
- Muon 옵티마이저: AdamW 대신 채택. 더 빠른 수렴과 더 안정적인 학습
- FP4 + FP8 혼합 정밀도: MoE 전문가 가중치는 FP4(MXFP4) QAT, 나머지는 FP8. 메모리·전력·레이턴시 모두 절감
- 두 단계 포스트-트레이닝: 도메인별 전문가를 GRPO로 따로 키운 뒤, On-Policy Distillation(OPD)으로 단일 학생 모델에 통합
- 세 가지 추론 모드: Non-think / Think High / Think Max (Max는 384K 컨텍스트 윈도우 필요)
- 벤치마크: MMLU-Pro 87.5, LiveCodeBench 93.5, Codeforces 3206, IMOAnswerBench 89.8, HMMT 2026 Feb 95.2, MRCR 1M 83.5, SWE Verified 80.6 — 일부 항목에서 Opus 4.6 Max·GPT-5.4 xHigh를 추월
제1장: 딥시크는 어떻게 여기까지 왔나 (2023 → 2026)
V4를 이해하려면 먼저 그 위에 차곡차곡 쌓인 결정들을 봐야 한다. 딥시크의 모델 계보는 단순한 버전 카운터가 아니라 각 세대마다 하나의 명확한 기술 베팅이 있었다.

2023
V1 · 16B 파라미터 / 2.7B 활성. 첫 MoE 실험. "큰 모델을 작은 활성으로 굴린다"는 컨셉 검증
2024.05
V2 · 236B / 21B 활성. MLA(Multi-Head Latent Attention) 도입 — KV 캐시를 잠재 공간으로 압축. 컨텍스트 128K로 확장
2024.12
V3 · 671B / 37B 활성. FP8 학습, Auxiliary-Loss-Free 라우팅, MTP(Multi-Token Prediction). 14.8T 토큰. 5.58M 달러. GPT-4급 성능을 1/20 비용에
2025.01
R1 · 순수 RL(GRPO)로 추론 능력 발현. SFT 없이 'aha moment' 창발. AIME 71.0% Pass@1. NVIDIA 시총 5,890억 달러 증발의 주범
2025
V3.1 · 하이브리드 추론 모드(Chat ↔ Reasoning) 토글. 한 모델에 두 인격
2025
V3.2-Exp / V3.2 · DSA(DeepSeek Sparse Attention) + Lightning Indexer 도입. 어텐션 복잡도 O(L²)→O(Lk). DeepSeekMath-V2 검증기로 RL 강화
2026.04
V4 Pro / Flash · CSA + HCA 하이브리드, mHC, Muon, FP4+FP8, OPD. 100만 토큰이 "기본값"
핵심을 한 문장으로 요약하면 이렇다:
딥시크는 매 세대마다 "어텐션을 어떻게 더 싸게 만들 것인가"라는 한 가지 질문을 다른 각도에서 다시 풀어왔다.
V2에서 KV를 압축했고(MLA), V3에서 라우팅·정밀도를 다듬었고, V3.2에서 어텐션 자체를 희소하게(DSA) 만들었으며, V4에서는 그 모든 것을 두 종류의 압축 어텐션을 레이어마다 번갈아 쓰는 더 과격한 설계로 다시 묶었다. 이 집요함이 V4의 가장 중요한 컨텍스트다.
제2장: 왜 100만 토큰이 어려웠는가
V4의 혁신을 이해하려면 먼저 왜 큰 컨텍스트가 비싼지를 알아야 한다. 답은 트랜스포머의 두 가지 비용 항에 있다.

어텐션 비용의 두 가지 얼굴
FLOPs (연산)
Attention(Q, K, V) ∝ N²·d
→ 시퀀스가 2배면 연산은 4배
KV Cache (메모리)
∝ N · L · H · d
→ 토큰마다 K, V를 다 저장. 1M이면 GB 단위 폭증
GPT-4 시절 8K 컨텍스트와 비교해 보자. 시퀀스 길이가 125배 길어지면 단순 계산만으로 어텐션 연산은 약 1만 5,625배, KV 캐시는 125배가 된다. 이론상 가능해 보여도, 실제로는 한 장의 H100/H200에 수백 GB의 KV가 안 올라간다. 1M 컨텍스트가 "발표는 됐지만 비싸서 잘 안 쓰던" 이유가 여기 있다.
기존 해법들의 한계
이 문제를 해결하려는 시도는 줄곧 있어왔다. 하지만 다들 한쪽을 잡으면 다른 쪽을 놓쳤다.
| 기법 | 아이디어 | 한계 |
|---|
| Sliding Window | 최근 N개 토큰만 본다 | 긴 문서 멀리 떨어진 단서 못 잡음 |
| Sparse / Local Attention | 일부 토큰만 어텐션 | "어디를" 보느냐를 사람이 정해야 함 |
| MLA (V2) | KV를 잠재공간으로 압축 후 다시 펼침 | FLOPs는 여전히 N² |
| DSA (V3.2) | Lightning Indexer로 top-k 동적 선택 | 1M 가면 인덱싱 비용도 무거움 |
| CSA + HCA (V4) | "먼저 압축, 그 다음 희소 또는 밀집" | N과 cache를 동시에 깎음 |
V4의 답은 압축과 희소성의 순서를 바꾼 것이다. 기존엔 원본 KV를 두고 그중 일부만 골라 봤다(희소). V4는 먼저 KV를 강하게 압축해서 시퀀스 자체를 짧게 만든 다음, 거기서 희소 선택(CSA)이나 밀집 어텐션(HCA)을 한다. 이 한 끗이 1M 컨텍스트의 경제학을 바꿨다.
제3장: 핵심 혁신 ① — 하이브리드 어텐션 (CSA + HCA)
V4 아키텍처에서 가장 큰 그림은 이거다. 61개 레이어가 있는 V4-Pro의 어텐션 스택은 이렇게 생겼다.
Layer 0–1
HCA only
→
Layer 2–60
CSA ↔ HCA 교차
→
MTP Block
Sliding Window
같은 모델 안에서 두 가지 다른 성격의 어텐션이 한 칸씩 번갈아 등장하는 셈이다. 왜 이런 구조가 나왔는지, 두 메커니즘을 차근차근 본다.

CSA — Compressed Sparse Attention
CSA를 한 줄로 표현하면 "먼저 4배 압축하고, 그중 top-k만 본다" 이다.
📚
문제
1M 토큰을 그대로 키-값 캐시에 올리면 메모리도 안 되고, 매 쿼리가 1M개를 다 보면 FLOPs도 폭발한다.
🗜️
해법
매 m개 토큰의 K·V를 학습된 softmax-gated 풀러로 한 덩어리(블록)로 묶어 4배 짧게 만든다. 그 위에서 Lightning Indexer(FP4·ReLU 점수)가 각 쿼리에 대해 top-k 블록만 고른다. 가장 최근 토큰들은 따로 슬라이딩 윈도우 가지가 처리.
⚡
결과
희소 선택의 검색 공간이 4배 짧아지므로 인덱서·어텐션이 모두 가벼워진다. 멀리 있는 단서를 정확히 짚는 능력은 보존.
HCA — Heavily Compressed Attention
HCA의 한 줄 요약은 더 단순하다. "128배로 짓눌러서 짧게 만들고, 그 위에서는 그냥 다 본다(밀집)."
🌪️
문제
CSA만으로는 정보가 군데군데 흩어진 글로벌 패턴(예: 책 첫 장과 마지막 장의 주제 연결)을 잡기 어렵다.
🧘
해법
매 m′개(m′ ≫ m) 토큰을 단 1개로 128배 압축. 압축된 시퀀스가 너무 짧아져서 모든 쿼리가 모든 블록을 본다(dense MQA). 동시에 슬라이딩 윈도우로 최근 문맥은 또 따로 본다.
🌊
결과
CSA가 "정밀 검색"이라면 HCA는 "전체 분위기 파악". 두 가지 패턴을 하나의 스택 안에서 둘 다 갖게 된다.
왜 교차 배치인가
같은 모델 안에서 CSA와 HCA를 번갈아 두는 이유는 레이어마다 어텐션이 하는 일이 다르기 때문이다. 초기 레이어는 추상적인 글로벌 구조를 잡고, 깊은 레이어는 정밀한 토큰 의존성을 다룬다는 분석이 오랫동안 있어 왔다. V4는 이를 아키텍처 차원에서 인정하고, "한 종류의 어텐션으로 모든 일을 시키지 말자"는 베팅을 했다.
결과는 분명하다. 1M 시점 기준, V3.2 대비 V4-Pro는 KV 캐시 10%, FLOPs 27%. V4-Flash는 KV 캐시 7%, FLOPs 10%까지 내려간다. 그리고 NIH(Needle-in-a-Haystack) 1M에서 약 97% 정확도, MRCR 8-needle 256K까지 ≥0.82, 1M에서 0.59 — 단순한 압축이 아니라 정확도를 거의 잃지 않는 압축이라는 것이 핵심이다.
V3.2 (1M)
KV 100% / FLOPs 100%
V4-Pro (1M)
KV 10% / FLOPs 27%
V4-Flash (1M)
KV 7% / FLOPs 10%
제4장: 핵심 혁신 ② — mHC, 잔차 연결의 후속
트랜스포머 깊은 모델의 표준 도구는 잔차 연결(residual connection) 이다. ResNet 시절부터 "출력 = 입력 + 학습한 변화"라는 단순한 구조 덕분에 100층, 200층짜리 신경망을 안정적으로 학습할 수 있었다.
V4는 그 자리에 mHC (Manifold-Constrained Hyper-Connections) 를 넣었다. 한 줄로 하면 "여러 잔차 경로를 다양체 제약 아래에서 동시에 흘려 보낸다" 정도다. 기술 보고서에는 다음과 같이 정리돼 있다.
"strengthens conventional residual connections, enhancing stability of signal propagation across layers while preserving model expressivity."
비유하면 이렇다. 기존 잔차 연결이 한 차선 고속도로라면, mHC는 제약 조건이 있는 다차선 고속도로다. 차선이 여러 개라 신호가 다양한 경로로 전파될 수 있지만, 모든 차선이 같은 다양체 위에 머물도록 강제돼 발산하지 않는다.
왜 이게 V4에서 중요했을까. 하이브리드 어텐션과 극단적 KV 압축은 신호 손실 위험을 키운다. CSA·HCA가 정보를 짓누른 만큼, 잔차 채널이 그것을 보전하고 회복할 수 있어야 한다. mHC는 그 보전·회복을 안정적으로 만드는 새 척추 역할을 한다.
제5장: 핵심 혁신 ③ — Muon 옵티마이저
거의 모든 최신 LLM이 AdamW를 쓴다. V4는 여기서도 갈라섰다. Muon 옵티마이저를 채택한 것이다. (Muon은 2024년 후반부터 일부 연구실에서 LLM 학습에 적용되며 빠른 수렴 속도가 보고되어 왔다.)
| 항목 | AdamW | Muon |
|---|
| 업데이트 규칙 | 1·2차 모멘트로 정규화한 그라디언트 | 모멘텀 행렬에 Newton-Schulz 직교화 적용 |
| 장점 | 안정·범용 | 행렬 파라미터에서 수렴 속도↑, 손실 평탄화 빠름 |
| 리스크 | 대규모에서 학습률 튜닝 까다로움 | 스칼라/임베딩에는 부적합 → 혼합 사용 |
V4 보고서가 굳이 "Muon enables faster convergence and greater training stability"라고 강조한 것은, 1.6T 모델을 32T 토큰에 학습시킬 때의 GPU 시간 = 돈이라는 현실 때문이다. 같은 품질에 도달하는 데 걸리는 step 수가 줄면 곧 학습비가 준다.
제6장: 핵심 혁신 ④ — FP4 + FP8 혼합 정밀도
V3가 LLM에서 FP8 학습을 본격 안착시킨 첫 모델이었다면, V4는 MoE 전문가 가중치를 FP4(MXFP4)로 양자화 인지 학습(QAT) 시킨 모델이다. 정확도 손실을 거의 없이 학습 단계에서부터 4-bit로 다루도록 익힌다는 뜻이다.
MoE Expert weights : FP4 (MXFP4 QAT)
Lightning Indexer Q/K : FP4
KV cache (대부분) : FP8
RoPE 차원 : BF16
나머지 파라미터·활성 : FP8
추론 단계에서는 시뮬레이션이 아니라 실제 FP4 가중치를 그대로 사용한다. 메모리 트래픽이 곧 절반의 절반이 된다는 의미이고, 같은 H200/B200 한 장에서 훨씬 더 많은 동시 요청을 받을 수 있다는 의미다. NVIDIA Blackwell이 FP4 텐서코어를 제대로 가속하기 시작한 시점과 정확히 맞물려 나온 설계다.
여담이지만, V4 보고서는 NVIDIA GPU와 Huawei Ascend NPU 양쪽에서 같은 정밀도 스킴을 검증했다고 명시한다. 미국·중국 칩 공급망이 분리되는 시대에 공급자 의존도를 분산하려는 의도가 분명히 보인다.
제7장: 핵심 혁신 ⑤ — 도메인 전문가 + On-Policy Distillation
V3.2까지의 포스트-트레이닝은 SFT → 혼합 RL 한 번이었다. V4는 이 파이프라인 자체를 다시 그렸다.
Pre-train
32T+ tokens
→
Domain Experts
SFT + GRPO
→
On-Policy Distillation
(reverse KL, 10+ teachers)
→
Unified V4-Pro
핵심 베팅은 "한 모델에 모든 것을 동시에 가르치지 말고, 분야별 천재를 따로 키운 뒤 한 학생에게 동시 통합 시키자" 이다.
- 1단계: 수학·코딩·에이전트·instruction-following 등 영역마다 독립적인 전문가 모델을 GRPO로 학습. 영역끼리 RL 보상이 충돌하는 문제를 회피한다.
- 2단계: 10개 이상의 교사 모델을 두고, 학생 모델이 직접 만든 응답에 대해 교사들의 분포를 따라가도록 역 KL 발산을 최소화(On-Policy Distillation, OPD). 학생이 실제로 만들 수 있는 행동 분포 안에서 가르친다는 점이 일반 distill과 다르다.
비유: 학원이 한 강사에게 모든 과목을 가르치라 시키지 않는다. 과목별 전문 강사가 각자 학생을 단련시키고, 마지막에 한 학생이 모든 모의고사를 보면서 강사들의 의견을 종합한다. 학생이 실제로 푸는 방식 위에서 피드백이 와야 일반화된다 — 이것이 OPD의 핵심이다.
제8장: Three Reasoning Modes — 같은 모델, 세 가지 사고 깊이
V4가 사용자에게 직접 노출하는 가장 큰 변화는 추론 모드가 세 단계로 늘어난 것이다.
Non-think
사고 블록 없음. 즉답형. 가벼운 챗·툴 호출에 적합. 가장 빠르고 가장 싸다
Think High
<think> 블록에 명시적 chain-of-thought. 코딩·수학·분석 기본값
Think Max
최대 추론 노력. 384K 컨텍스트 윈도우 필요. 올림피아드급 수학·연구 코드 작성·장기 에이전트용
샘플링 파라미터는 세 모드 모두 temperature=1.0, top_p=1.0로 고정돼 있다 — 사용자가 흔히 잘못 만지는 손잡이를 아예 없앤 셈이다.
또 흥미로운 디테일은 툴 콜이 있을 때와 없을 때 think 블록의 보존 정책이 다르다는 점이다. 툴이 끼면 모든 사용자 메시지 경계를 넘어서 think를 보존해 누적 추론을 유지한다. 툴이 없으면 새 사용자 메시지마다 think를 폐기해 컨텍스트를 짧게 유지한다. 장기 에이전트에서 추론 흐름이 끊기는 V3.2의 단점을 정조준한 설계다.
제9장: 1.6T 파라미터, 49B만 활성 — MoE 도시의 비유
숫자가 크니 한 번 시각화하자. 1.6조 개의 파라미터는 거의 모든 사람이 직관할 수 없는 규모다.

총 전문가 풀
1.6T 파라미터
≈ 1,600,000,000,000
토큰당 활성
49B 파라미터
전체의 약 3.0%
비교: V3
671B 총, 37B 활성
전체의 약 5.5%
V3 → V4로 가면서 총 파라미터는 2.4배 늘었지만 활성 비율은 더 낮아졌다. 즉 "전체 지식 풀은 더 넓히되, 한 토큰을 만들 때 부르는 인력은 더 절제한다"는 방향이다. 비싼 프론티어 모델이 모두 가는 길과 같다 (GPT-4 시리즈, Gemini 1.5 Pro, Claude 4도 같은 패턴이라는 분석이 다수다 — 다만 폐쇄 모델이라 정확한 숫자는 비공개).
제10장: 벤치마크 — 실제로 얼마나 강한가
이제 숫자다. V4-Pro-Max(Think Max 모드)를 동시대 프론티어 모델과 같은 표 위에 올려보자.
| 분야 | 벤치마크 | V4-Pro-Max | 참고 (best 폐쇄 모델) |
|---|
| 지식 | MMLU-Pro | 87.5 | Gemini 3.1-Pro 선두권 |
| SimpleQA-Verified | 57.9 | Opus 4.6 Max 46.2 |
| 코딩 | LiveCodeBench | 93.5 | — |
| Codeforces Rating | 3206 | GPT-5.4 xHigh 3168 |
| 수학 | IMOAnswerBench | 89.8 | — |
| HMMT 2026 Feb | 95.2 | — |
| 장문맥 | MRCR 1M | 83.5 | Gemini 3.1-Pro High 76.3 |
| 에이전트 | SWE Verified | 80.6 | Opus 4.6 Max 80.8 |
| Terminal Bench 2.0 | 67.9 | GPT-5.4 xHigh 75.1 |
| Toolathlon | 51.8 | K2.6 50.0, Gemini 3.1-Pro 48.8 |
읽는 법은 이렇다.
- 수학·과학·지식 도메인: 사실상 폐쇄 SOTA와 동급 또는 추월. 특히 SimpleQA에서 11.7점 차이는 사실 검증·QA 분야에선 큰 격차다.
- 코딩 경쟁: Codeforces 3206은 실제 인간 대회에서 그랜드마스터 상단권. 알고리즘적 사고에서 GPT-5.4 xHigh를 살짝 추월.
- 에이전트 / 툴 사용: SWE Verified·MCPAtlas·Toolathlon에서 Opus 4.6 Max와 호각. 자동화 코딩 에이전트의 백본 후보로 진지하게 고려할 수 있는 첫 번째 오픈소스 모델.
- 장문맥: MRCR 1M에서 Gemini 3.1-Pro High를 7.2점 추월. "100만 토큰 컨텍스트가 진짜로 작동한다"는 주장의 가장 강한 증거.
DeepSeek 자체 R&D 팀이 PyTorch·CUDA·Rust·C++ 30개 과제로 평가한 사내 벤치마크에서는, V4-Pro-Max가 67% 통과, Sonnet 4.5는 47%, Opus 4.5는 70%. 그리고 같은 팀의 85명 개발자 설문에서 52%가 V4-Pro로 주력 코딩 모델을 교체할 준비가 됐다고 답했다.
제11장: 실무 적용 사례 — 1M 컨텍스트가 뭘 바꾸는가
스펙 다음은 그래서 뭘 할 수 있는가다. 1M 컨텍스트와 효율 모두 받쳐주는 모델이 등장하면 비로소 새로 가능해지는 워크플로우들이 있다.
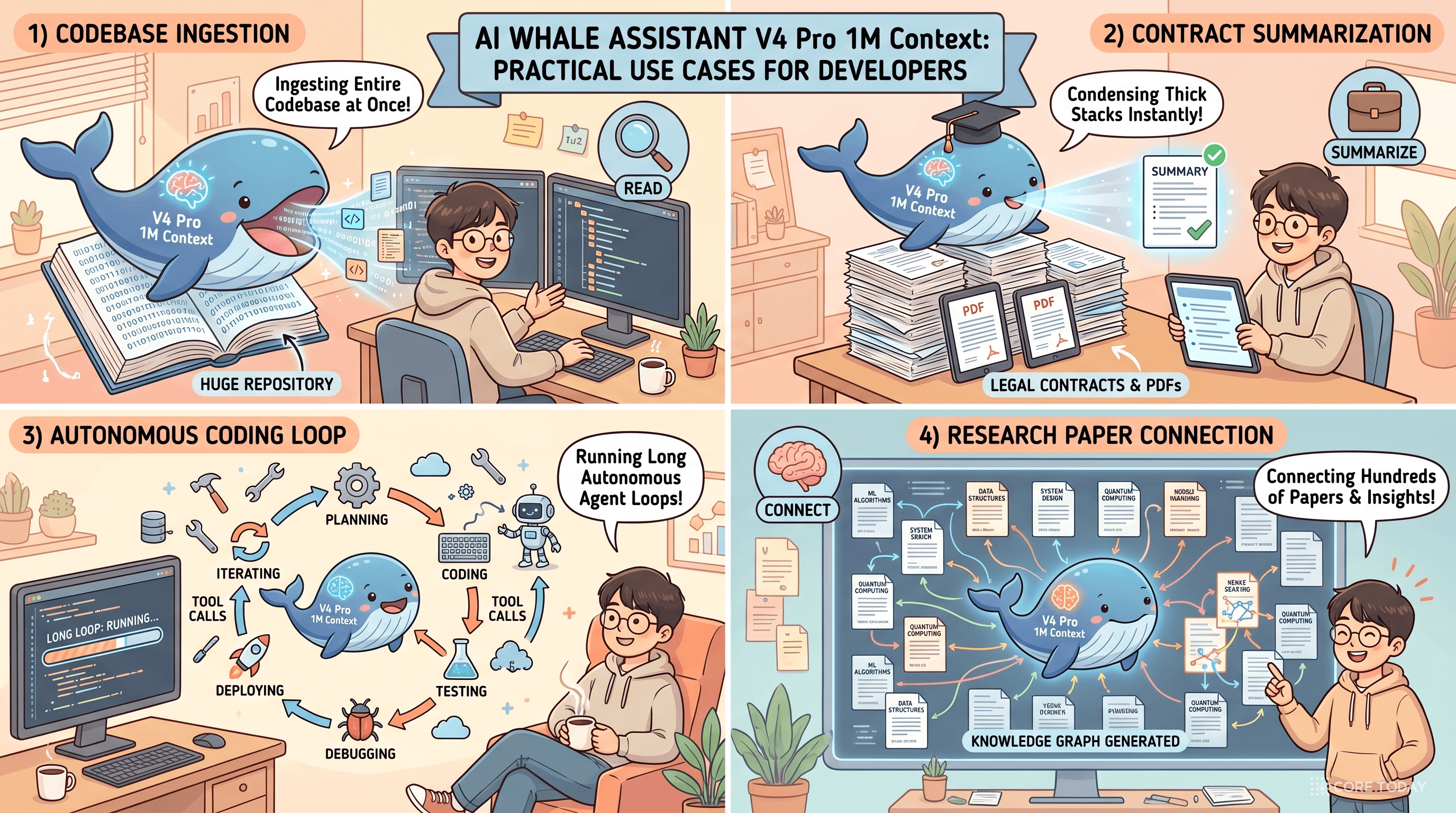
사례 ① — 전체 코드베이스를 한 번에
중규모 모노레포(예: 50만~80만 줄, 약 60~80만 토큰)는 자르지 않고 한 번에 모델 컨텍스트에 올라간다. 가능해지는 일들:
- 새 기능 추가 시, "이 변경이 깨뜨릴 수 있는 모든 호출자"를 컨텍스트 안에서 직접 찾아 PR 설명에 적어준다
- 보안 리뷰: "모든 라우트에서 인증·인가 누락이 있는지 전수 점검" — RAG로는 지문이 흩어져 놓치는 것
- 마이그레이션 보조: 한 패키지 버전업이 영향 주는 모든 위치를 한 번에 매핑
hljs language-bash
git ls-files | xargs cat | \
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-H "Content-Type: application/json" \
-d @- <<EOF
{
"model": "deepseek-v4-pro",
"messages": [
{"role":"system","content":"You are a senior security auditor."},
{"role":"user","content":"다음 전체 코드베이스에서 인증/인가 누락, SSRF, 안전하지 않은 deserialize, 시크릿 노출 의심 라인을 file:line 형식으로 찾아라.\n\n$(cat)"}
]
}
EOF
사례 ② — 두꺼운 PDF·계약서·논문 묶음
50~100쪽짜리 계약서 10건을 한꺼번에 올리고 "우리 회사 표준 계약 대비 위험 조항 30개를 표로 뽑아라" — V3.2에서는 RAG가 빠지면 위험 신호를 놓치기 일쑤였다. V4는 MRCR 1M 83.5가 보장하듯 깊이 묻힌 단서까지 잡는다.
연구자에게 더 큰 사용처는 여러 논문 동시 비교다. PINN·KAN·NeRF 등 분야 핵심 논문 30편을 한 번에 올려 두고, "이 분야의 핵심 가정이 시간순으로 어떻게 진화했는지 표로 만들어라"가 한 번의 호출로 가능해진다.
사례 ③ — 장기 에이전트 루프
V4 보고서가 가장 강조한 응용 영역이다. 툴 콜 사이에 think를 보존하기 때문에, 30~50번의 도구 호출이 이어지는 자동화 코딩 에이전트가 처음으로 "중간에 자기 추론을 잊지 않는" 기반을 갖게 된다.
DeepSeek은 RL 학습에 쓴 자체 인프라 DSec(DeepSeek Elastic Compute) 도 같이 공개했다. Function call → container → microVM(Firecracker) → full VM(QEMU)까지 동일한 Python SDK로 다루며, 수십만 개 동시 샌드박스를 굴린다. 에이전트 학습용 인프라까지 묶어 공개한 것은 V4에서 처음이다.
사례 ④ — 멀티 모드 콜라보
Non-think로 받은 사용자 메시지를 분류·라우팅 → 복잡한 코딩은 Think Max로 돌리는 듀얼 모드 라우터 패턴이 자연스럽게 만들어진다.
def route(user_message):
cls = call_v4(user_message, mode="non-think", system="분류만 해라: trivial/code/math/agent")
if cls == "trivial":
return call_v4(user_message, mode="non-think")
if cls in ("code", "math"):
return call_v4(user_message, mode="think-high")
if cls == "agent":
return call_v4(user_message, mode="think-max", tools=AGENT_TOOLS)
이렇게 하면 비용은 최소화하면서, 정말 어려운 질문에만 Think Max의 추론 비용을 지불하게 된다.
제12장: 다른 프론티어 모델과 비교 — V4의 자리
2026년 4월 현재 프론티어 LLM 지형을 한눈에 보면 이렇다.
| 모델 | 제공자 | 아키텍처 | 컨텍스트 | 라이선스 |
|---|
| Claude Opus 4.6 Max | Anthropic | 비공개 | 비공개(추정 1M+) | 폐쇄 |
| GPT-5.4 xHigh | OpenAI | 비공개 | 비공개 | 폐쇄 |
| Gemini 3.1-Pro High | Google | 비공개 MoE 추정 | 1M+ (실험적 2M) | 폐쇄 |
| DeepSeek V4-Pro | DeepSeek | CSA+HCA MoE 1.6T/49B | 1M 기본, 384K think | MIT (오픈) |
| Kimi K2.6 | Moonshot | MoE | 1M+ | 일부 오픈 |
| GLM-5.1 | Zhipu | MoE | 200K+ | 일부 오픈 |
위치를 한 줄로 요약하면:
V4 Pro는 "Opus / GPT-5.4 / Gemini 3.1-Pro와 같은 표 위에 다시 올라온 첫 오픈 가중치 모델"이다.
특히 폐쇄 모델 한 곳에 종속되기 어려운 사용처 — 금융·의료·국방·정부, 그리고 데이터를 자국 클라우드에 묶어둬야 하는 한국 대기업 R&D — 에서 V4는 직전까지 비어 있던 자리를 채운다. 자체 GPU에 가중치를 올려 데이터가 회사 밖으로 나가지 않도록 하면서도 프론티어급 추론을 받을 수 있는 최초의 옵션이다.
제13장: V4 시작하기 — 실전 셋업
1) HuggingFace로 직접 받기
hljs language-bash
huggingface-cli download deepseek-ai/DeepSeek-V4-Pro \
--local-dir ./DeepSeek-V4-Pro
huggingface-cli download deepseek-ai/DeepSeek-V4-Flash \
--local-dir ./DeepSeek-V4-Flash
2) DeepSeek API로 호출 (OpenAI 호환)
hljs language-python
from openai import OpenAI
client = OpenAI(
api_key=os.environ["DEEPSEEK_API_KEY"],
base_url="https://api.deepseek.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a precise senior engineer."},
{"role": "user", "content": "이 1M 토큰짜리 모노레포에서 N+1 쿼리를 모두 찾아줘."},
],
temperature=1.0,
top_p=1.0,
extra_body={"reasoning_effort": "high"},
)
print(resp.choices[0].message.content)
3) Anthropic 호환 엔드포인트
V4는 Claude Code, OpenClaw, OpenCode 등 Anthropic 메시지 포맷을 쓰는 에이전트와 그대로 호환된다. base_url만 DeepSeek로, 모델명만 deepseek-v4-pro로 바꾸면 된다.
4) NVIDIA NIM 엔드포인트
NVIDIA가 Blackwell GPU 기반 NIM(Inference Microservice)으로 V4-Pro를 서빙한다. 자체 GPU 클러스터가 없는 팀이 FP4 가속을 그대로 받으며 100만 토큰 추론을 시도해 볼 수 있는 가장 빠른 길이다.
5) 운영 체크리스트
| 항목 | 권장 |
|---|
| 온도/탑P | temperature=1.0, top_p=1.0 고정 (변경 비권장) |
| Think 모드 | 일반 라우팅 = Non-think, 코딩/수학 = Think High, 올림피아드/장기 에이전트 = Think Max |
| 컨텍스트 윈도우 | Think Max 사용 시 384K 이상 보장 |
| 도구 콜 | |DSML| XML 포맷 사용. JSON-in-string 회피 |
| 샌드박스 | 장기 에이전트는 DSec 패턴(Firecracker microVM) 참고 |
| 레이트 리미트 / 비용 | API 가격은 V3.2 대비 토큰당 더 낮게 책정. 단, Think Max는 토큰 수가 늘어 총비용은 증가 가능 |
주의: deepseek-chat, deepseek-reasoner 모델 별칭은 2026-07-24 15:59 UTC에 폐기 예정. 운영 코드는 deepseek-v4-pro / deepseek-v4-flash로 미리 갱신해 두자.
제14장: 한계와 비판 — 무엇이 아직 부족한가
V4 Preview가 모든 면에서 SOTA는 아니다. 솔직하게 정리해 둔다.
- Terminal Bench 2.0 67.9 — GPT-5.4 xHigh의 75.1에 약 7점 뒤짐. 아주 긴 셸 세션·OS 제어 분야에서는 아직 갈 길이 있다
- Toolathlon·MCPAtlas는 호각이지만 Opus 4.6 Max와 비교 시 일관된 우위는 아님 — 도메인에 따라 갈린다
- 하드웨어 진입 장벽 — 1.6T 가중치는 8×B200 (또는 동급 Ascend) 풀 노드급에서 실질 운영 가능. 개인이 노트북에서 띄우는 모델이 아니다. 그런 사용처에는 V4-Flash(284B)가 더 현실적
- Long-context 1M 정확도 0.59 (MRCR 8-needle) — 256K 이내 0.82와 비교하면 극단까지 가면 분명히 떨어진다. 마케팅 카피와 실제 한계는 구분해서 봐야 한다
- Preview 표기 — DeepSeek 자체가 "Preview"로 부른다. 정식 GA 사이클에서 안정성·안전 가드레일이 더 다듬어질 가능성이 크다. Preview를 프로덕션 크리티컬 패스에 바로 올리는 결정은 신중하게.
제15장: 그래서, 2026년 봄 V4의 의미는?
세 가지로 정리한다.
1) "오픈 가중치가 다시 프론티어를 따라잡았다"
R1이 추론 능력에서 오픈소스의 도약을 보여줬다면, V4는 효율과 컨텍스트에서 같은 일을 했다. 동시대 폐쇄 모델 3종(Opus 4.6, GPT-5.4, Gemini 3.1)과 같은 표에 오픈 가중치 모델이 다시 올라온 것은 R1 이후 처음이다.
2) "1M 컨텍스트가 마케팅에서 기본값으로"
이전까지 1M 컨텍스트는 "지원은 한다"는 자랑이었지만 실제 비용·정확도·레이턴시 트라이앵글이 안 맞아 잘 안 썼다. V4는 셋 다 어느 정도 풀어내며 100만 토큰을 기본값으로 끌어내렸다. 이는 RAG 설계, 에이전트 메모리 정책, 코드 어시스턴트 UX 모두에 영향을 주는 변곡점이다.
3) "주권 AI(Sovereign AI)의 현실적 옵션"
폐쇄 API 한 곳에 데이터를 넘기지 못하는 곳 — 공공기관·국방·금융·의료·국가 R&D — 에 V4는 첫 번째 프론티어급 자체 호스팅 옵션을 준다. NVIDIA·Huawei 양쪽 가속기에서 검증됐다는 점도, 칩 공급망이 갈라지는 시대에 의미 있는 신호다.
마치며: 더 단단해진 베이스라인
DeepSeek V4 Pro가 모든 문제의 답은 아니다. 그러나 이번 릴리스가 분명히 한 것은 새로운 베이스라인의 위치다. 이제 "우리도 LLM을 자체 호스팅한다"고 말할 때, 비교 대상은 GPT-3.5나 LLaMA 2가 아니다. Opus 4.6 Max·GPT-5.4 xHigh·Gemini 3.1-Pro와 한 표에 올라간 1.6T MoE다.
"AI는 더 이상 폐쇄된 거대 기업의 전유물이 아니다. 지금 이 순간, 한 장의 GPU와 한 줄의 huggingface-cli만 있으면 누구나 그 최전선의 무게를 직접 다룰 수 있다."
코어닷투데이는 V4를 우리 사내 파이프라인 — 블로그 자동화, PDF 생성, 한국어 컨설팅 RAG — 에 단계적으로 통합하면서 실측 결과를 별도 글로 후속 발행할 예정이다. 가장 먼저 보고 싶은 시나리오가 있다면 contact 페이지로 알려주시기 바란다. 다음 특집은 "V4-Pro로 한국어 100만 토큰 RAG를 24시간 안에 띄우기" 가 될 가능성이 크다.
참고 자료 (주요 출처)




