
들어가며: 1억 2,500만 달러짜리 단위 오류
1999년 9월 23일, NASA의 화성 기후 탐사선(Mars Climate Orbiter)이 화성 궤도 진입에 실패해 대기권에서 소멸했다. 발사 비용만 1억 2,500만 달러(약 1,700억 원). 9개월간의 비행이 허무하게 끝난 원인은 무엇이었는가?
기술적 결함이 아니었다. 데이터 단위 불일치였다.
록히드마틴이 제공한 항법 소프트웨어는 파운드-힘·초(lbf·s) 단위로 스러스터 데이터를 전송했다. NASA의 다른 시스템은 그 데이터를 뉴턴·초(N·s, SI 단위계) 로 받아들였다. 두 시스템 사이에는 4.45배의 차이가 있다. 수천 번의 소규모 궤도 보정 계산이 누적되면서, 탐사선은 예정보다 약 80km 낮은 고도(대기권 진입 고도)로 진입해버렸다.
NASA 조사위원회가 내린 결론은 뼈아팠다:
"문제는 오류 자체가 아니었다. 시스템 엔지니어링과 프로세스 점검 체계가 그 오류를 감지하지 못한 것이 진짜 문제였다."
이것이 데이터 품질 실패의 전형이다. 데이터가 존재했다. 계산도 정확했다. 그러나 데이터의 구조와 의미(단위, 맥락)가 일치하지 않았고, 그것을 검증하는 체계가 없었다. 1억 2,500만 달러는 그 대가였다.
이 글은 DX 전문가 로드맵 10편 시리즈의 세 번째 편이다. DX의 핵심 전제 — "데이터를 못 보면 DX 못 한다" — 를 역사적 계보와 실전 수치로 증명한다.
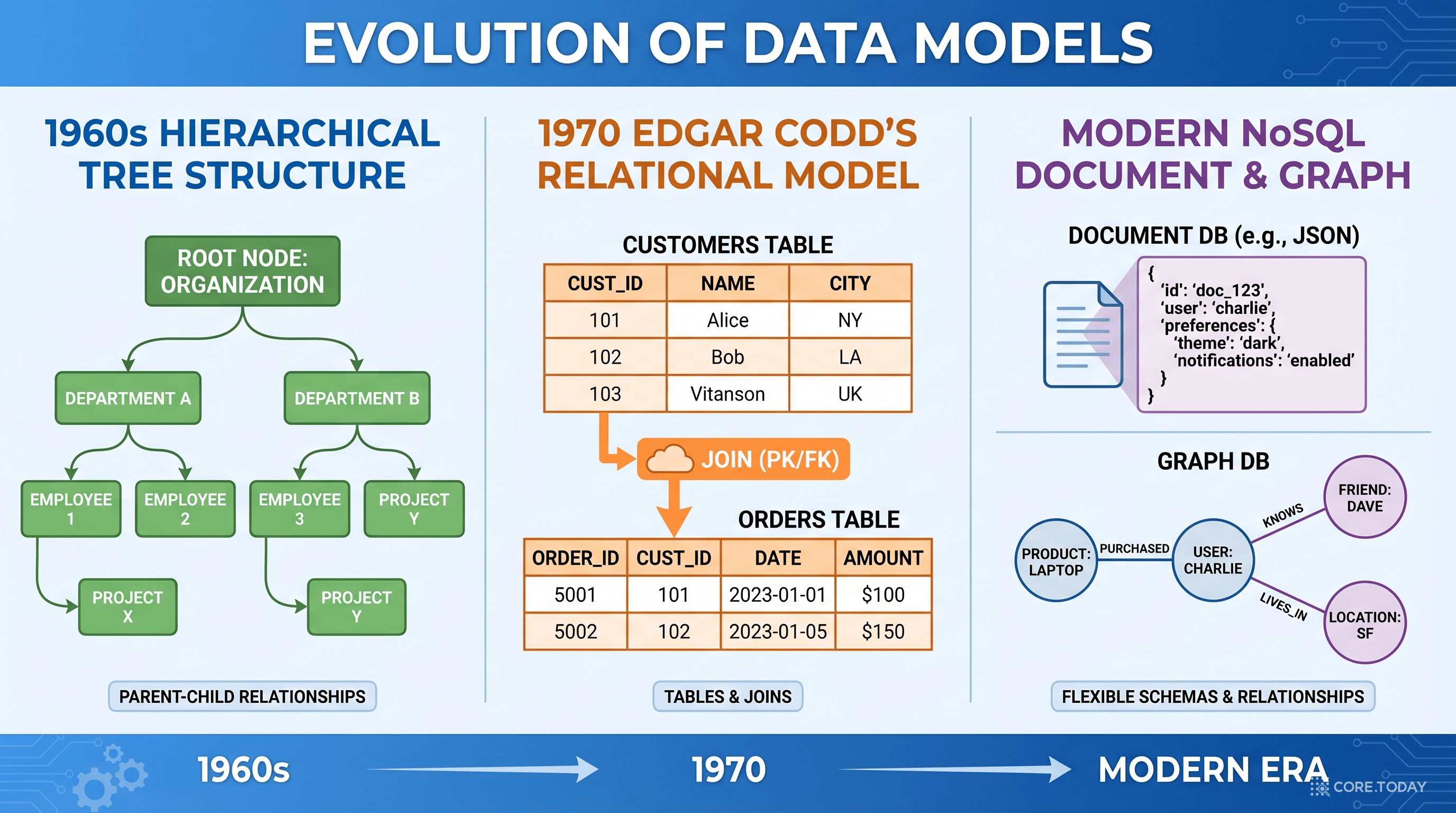
제1장: 데이터 모델링 56년의 계보 — 어떻게 "관계"를 표현하는가
1960년대: 계층형과 네트워크형 — 최초의 데이터베이스
현대 데이터베이스 이전, 1960년대 기업들이 직면한 문제는 단순했다: "대용량 데이터를 어떻게 저장하고 꺼내는가?"
당시 IBM은 IMS(Information Management System)를 개발했다. 원래 목적이 흥미롭다 — 아폴로 달 탐사 미션의 부품 구매 주문 추적이었다. 우주선 하나에 들어가는 수백만 개 부품의 계층적 구조(엔진 → 부품 → 세부 부품)를 나무(Tree) 구조로 표현했다.
| 모델 | 구조 | 대표 시스템 | 한계 |
|---|
| 계층형 (1966) | 트리(부모-자식) | IBM IMS | 1:N 관계만, 유연성 없음 |
| 네트워크형 (1969) | 그래프(다대다) | CODASYL 표준 | 복잡한 포인터 탐색, 물리 구조 노출 |
| 관계형 (1970) | 테이블(집합론) | IBM System R, Ingres | 데이터 독립성 확보 → 혁명 |
네트워크 모델은 찰스 바크만(Charles Bachman)이 설계하고 CODASYL(데이터 시스템 언어 컨퍼런스) 컨소시엄이 1969년 표준화했다. 계층형보다 유연했지만, 프로그래머가 데이터의 물리적 주소를 직접 탐색해야 했다 — 마치 미로에서 실타래를 잡고 길을 찾는 것처럼.
1970년 6월: Edgar Codd의 혁명 — "관계"를 집합론으로
IBM 연구소 소속의 수학자 에드거 F. 코드(Edgar F. Codd)는 CODASYL 방식에 근본적 불만을 품고 있었다. 왜 프로그래머가 데이터의 물리적 위치를 알아야 하는가? 데이터의 논리적 구조와 물리적 저장 방식을 분리할 수 없는가?
1970년 6월, 코드는 Communications of the ACM 13권 6호에 8페이지짜리 논문을 발표했다:
"A Relational Model of Data for Large Shared Data Banks"
이 논문이 현대 데이터베이스의 시작점이다. 핵심 아이디어는 세 가지였다:
아이디어 1
데이터 독립성(Data Independence) — 물리적 저장 구조를 몰라도 논리적으로 데이터에 접근 가능
아이디어 2
관계(Relation) = 테이블 — 집합론에 기반한 2차원 테이블로 모든 데이터 표현
아이디어 3
비절차적 질의(Non-procedural Query) — "어떻게"가 아니라 "무엇을"만 기술하면 됨 → SQL의 탄생
코드는 1981년 ACM 튜링상을 수상했다. 그러나 아이러니하게도, 그를 고용한 IBM은 기존 IMS 시스템을 지키려는 내부 정치로 인해 관계형 데이터베이스 개발에 소극적이었다. 상업적 성공은 오라클(래리 엘리슨이 코드의 논문을 읽고 창업)이 먼저 거뒀다.
1976년: Peter Chen의 ER 다이어그램 — "현실"을 데이터로 번역하기
관계형 모델이 "저장 방식"을 혁신했다면, 피터 첸(Peter Pin-Shan Chen)은 "설계 방식"을 혁신했다.
1976년, MIT 조교수이던 첸은 ACM Transactions on Database Systems에 논문 한 편을 발표했다:
"The Entity-Relationship Model — Toward a Unified View of Data"
ER 모델의 핵심 통찰: 현실 세계는 "개체(Entity)"와 "관계(Relationship)"로 이루어져 있다. 고객(개체)이 주문(관계)을 통해 상품(개체)을 구매한다. 이 직관적인 표현 방식은 오늘날까지 데이터베이스 설계의 공통 언어다.
이 논문은 컴퓨터 과학 역사상 가장 많이 인용된 논문 중 하나가 되었다. UML(통합 모델링 언어)도 ER 모델의 직계 후손이다.
1992년 vs 1996년: Inmon vs. Kimball — 데이터 웨어하우스 전쟁
관계형 DB가 트랜잭션 처리(OLTP)를 장악하자, 다음 문제가 등장했다: "분석(OLAP)을 위한 데이터는 어떻게 구조화할 것인가?"
이것이 데이터 웨어하우스(Data Warehouse)의 탄생 배경이다. 그리고 30년간 지속된 설계 철학 대논쟁이 시작되었다.
| 구분 | 빌 인먼 (Bill Inmon, 1992) | 랄프 킴볼 (Ralph Kimball, 1996) |
|---|
| 접근법 | Top-Down (전사적 통합 먼저) | Bottom-Up (부서별 데이터 마트 먼저) |
| 구조 | 3NF 정규화된 중앙 창고 | 스타/스노우플레이크 스키마 |
| 장점 | 단일 진실 공급원, 데이터 일관성 | 빠른 구축, 비즈니스 친화적 |
| 단점 | 구축 기간 수년, 고비용 | 마트 간 불일치 발생 가능 |
| 명언 | "고기잡이 배를 쌓아봐야 고래가 되지 않는다" | "DW는 모든 데이터 마트의 합이다" |
누가 이겼는가? 둘 다 이겼고, 둘 다 졌다. 현대의 클라우드 데이터 웨어하우스(Snowflake, BigQuery, Redshift)는 양쪽의 철학을 흡수했다 — 중앙집중식 저장(인먼)에 분석 친화적 레이어(킴볼)를 얹는 방식으로.
2010년 10월: 데이터 레이크의 탄생 — "일단 다 담아라"
2010년 10월, Pentaho의 CTO 제임스 딕슨(James Dixon)은 자신의 블로그에 포스팅 하나를 올렸다. 제목: "Pentaho, Hadoop, and Data Lakes."
딕슨의 비유는 직관적이었다: 데이터 마트(Data Mart)가 "생수 가게의 병입 생수"라면, 데이터 레이크(Data Lake)는 "자연 상태의 호수"다. 정수되지 않은 원시 상태 그대로, 다양한 원천에서 흘러들어온 물(데이터)을 담아둔다.
데이터 레이크의 핵심 가치:
- 스키마를 미리 정의하지 않는다 (Schema-on-Write → Schema-on-Read)
- 구조화/비구조화 데이터를 모두 수용
- Hadoop/HDFS로 저비용 대용량 저장 가능
그러나 2010년대 중반 기업들이 발견한 것은 "데이터 레이크"가 너무나 쉽게 "데이터 늪(Data Swamp)"이 된다는 사실이었다. 메타데이터가 없고, 품질이 검증되지 않고, 누가 어떤 데이터를 왜 넣었는지 아무도 모르는 상태. 데이터 거버넌스의 부재가 데이터 레이크를 오염시켰다.
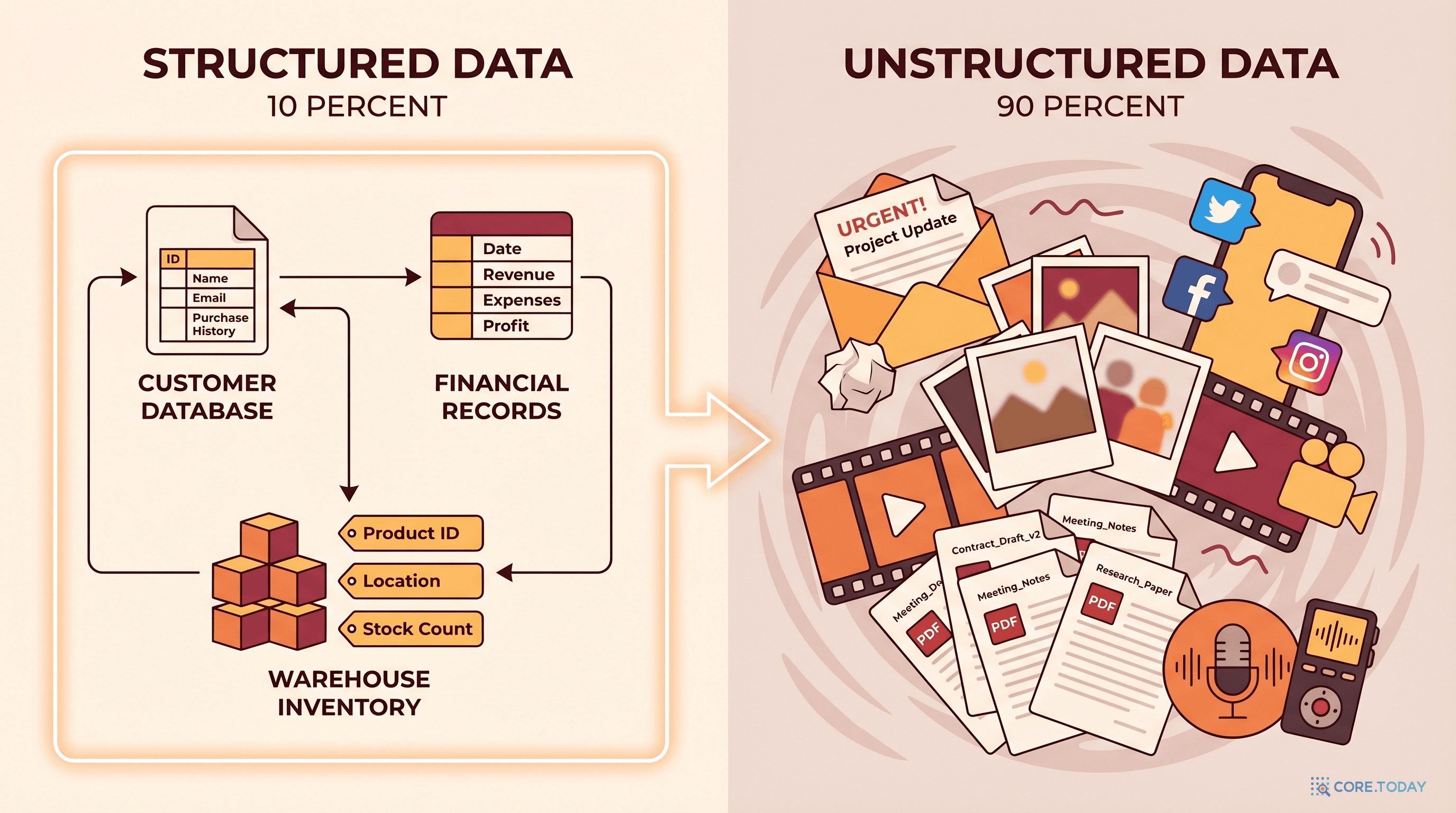
제2장: 정형 vs. 비정형 데이터 — 기업 데이터의 진짜 모습
90%가 비정형이다
Gartner의 분석에 따르면, 기업 데이터의 80~90%가 비정형(Unstructured) 데이터다. 2025년 현재 이 비율은 90%를 넘어섰다.
비정형 데이터 (이메일, 문서, 이미지, 영상, 로그)
90%
반정형 데이터 (JSON, XML, 로그 파일)
7%
그런데 아이러니가 있다. 전통적 기업의 IT 시스템은 정형 데이터 3%를 관리하는 데 최적화되어 있다. ERP, CRM, SCM — 모두 정형 데이터 기반이다. 나머지 97%는 이메일 서버에, 파일 서버에, 영업사원의 노트북에, 고객 통화 녹취 파일에 흩어져 있다.
IDC 전망에 따르면 비정형 데이터는 연간 55~65% 성장률로 증가 중이며, 2023년~2026년 사이 총량이 3배 증가할 것으로 예측된다.
데이터 유형 분류
| 유형 | 특징 | 예시 | AI 활용 |
|---|
| 정형 (Structured) | 사전 정의 스키마, 관계형 DB 저장 | 매출 테이블, 고객 마스터, 재고 현황 | 전통 ML, 통계 분석 |
| 반정형 (Semi-structured) | 태그/키로 구분, 유연한 스키마 | JSON API 응답, XML 문서, 서버 로그 | 파싱 후 분석 |
| 비정형 (Unstructured) | 스키마 없음, 자유 형식 | 이메일, 계약서, 콜센터 녹취, 제품 이미지 | LLM, 컴퓨터 비전 필요 |
비정형 데이터가 만드는 DX의 기회
비정형 데이터가 어렵다는 것은 가치가 더 크다는 의미이기도 하다. 콜센터 통화 5,000시간의 녹취를 분석하면 고객 불만의 패턴이 보인다. 10년치 계약서 PDF를 파싱하면 리스크 조항의 분포가 보인다. 공장 카메라 영상을 분석하면 불량 패턴이 보인다.
이것이 바로 LLM이 DX를 가속화하는 이유다 — LLM은 비정형 데이터를 구조화하는 비용을 극적으로 낮추기 때문이다.
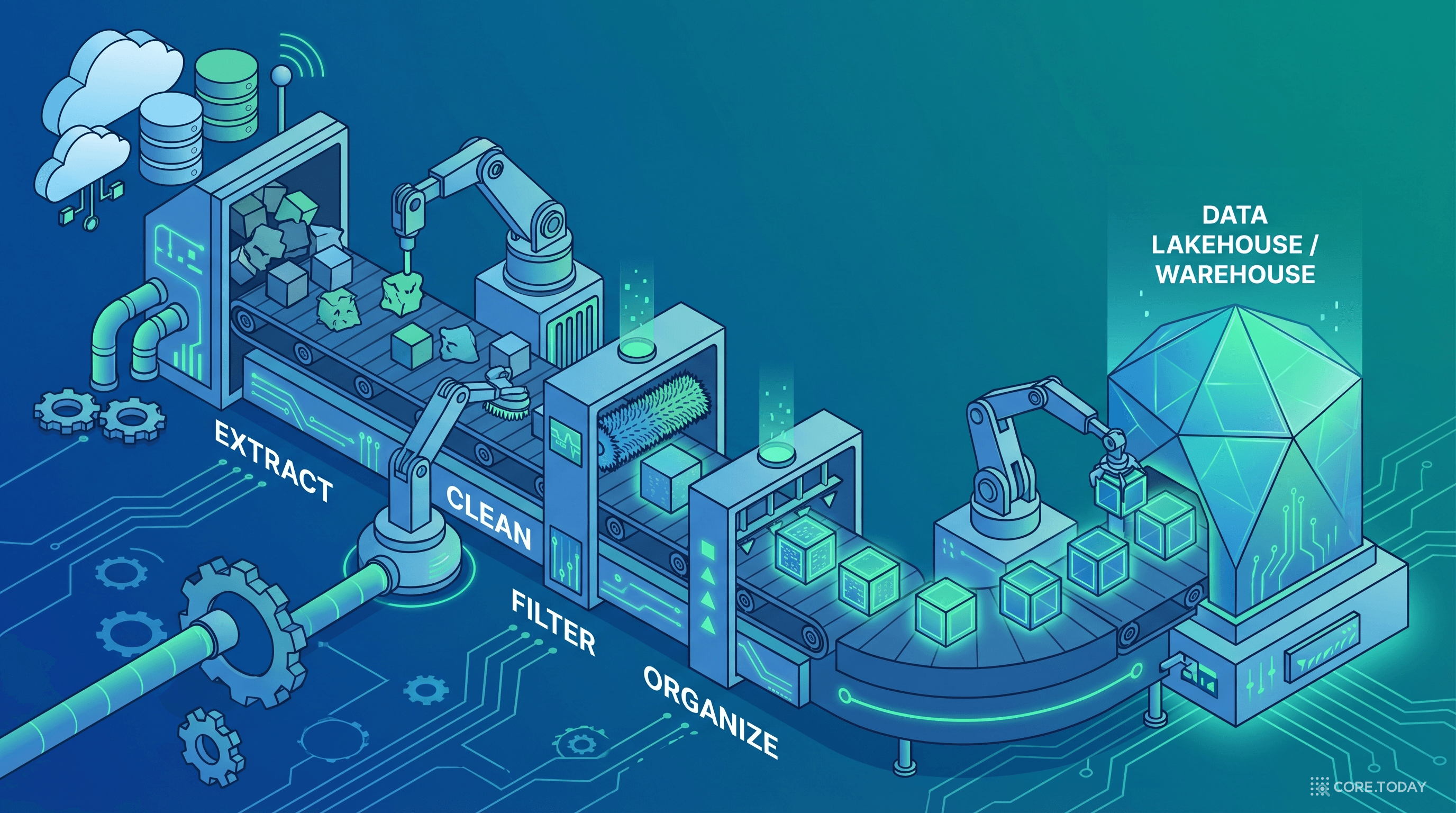
제3장: 데이터 파이프라인 — 원석을 보석으로
ETL의 역사: 1970년대 배치 처리에서 실시간 스트림까지
ETL(Extract-Transform-Load)은 1970년대 저장 공간과 처리 비용이 극히 비쌌던 시절에 탄생했다. 논리는 단순했다 — 데이터를 적재하기 전에 변환(Transform)해서 용량과 처리 부담을 줄이자.
소스 시스템
(ERP, CRM, IoT)
→
Extract
(추출)
→
Transform
(정제·변환)
→
Load
(적재)
→
분석 시스템
(DW, BI)
클라우드 데이터 웨어하우스(Snowflake, BigQuery, Redshift)의 등장은 패러다임을 바꿨다. 스토리지 비용이 1/100로 떨어지고, 컴퓨팅 파워를 탄력적으로 확장할 수 있게 되자 — "일단 다 적재하고, 나중에 필요할 때 변환하자" 는 ELT가 주류가 됐다.
ETL vs. ELT: 언제 무엇을?
| 구분 | ETL | ELT |
|---|
| 변환 시점 | 적재 전 (중간 서버) | 적재 후 (DW 내부) |
| 적합한 환경 | 온프레미스, 레거시 시스템 | 클라우드 DW (Snowflake, BigQuery) |
| 원시 데이터 보존 | 어렵다 (변환 후 저장) | 가능 (원본 그대로 적재) |
| 대표 도구 | Informatica, IBM DataStage, SSIS | dbt + Fivetran, dbt + Airbyte |
현대 데이터 스택의 구성 요소
2020년대의 Modern Data Stack은 이렇게 구성된다:
현대 데이터 스택 (Modern Data Stack)
데이터 수집
Fivetran / Airbyte
300+ 커넥터, 완전 관리형 EL
변환 레이어
dbt (data build tool)
SQL 기반 변환, 버전 관리, 테스트
저장 & 쿼리
Snowflake / BigQuery
클라우드 DW, 페타바이트 규모
오케스트레이션
Apache Airflow
77,000+ 조직 사용 (2024년 기준)
대규모 처리
Apache Spark
Fortune 500의 60% 이상 사용
BI & 시각화
Looker / Tableau / Superset
셀프서비스 분석
Apache Airflow는 2014년 10월 Airbnb에서 맥심 보쉬맹(Maxime Beauchemin)이 만들었다. 에어비앤비의 급성장과 함께 데이터 파이프라인이 수백 개로 늘어나면서 "이것들을 어떻게 스케줄링하고 모니터링할 것인가"에 대한 답이었다. 2019년 Apache 최상위 프로젝트가 됐고, 현재 7만 7,000개 이상의 조직에서 사용 중이다.
Apache Spark는 Databricks가 지원하는 오픈소스 빅데이터 처리 엔진이다. 1,000개 이상의 기여자, 250개 이상의 기여 조직 — Databricks의 기업 고객은 2024년 기준 1만 5,000개 이상, Fortune 500의 60% 이상이 고객이다.
데이터 메시: 분산 데이터 아키텍처의 등장
2019년, 당시 ThoughtWorks의 잠악 데흐가니(Zhamak Dehghani)는 중앙집중식 데이터 플랫폼의 근본적 한계를 지적했다:
"모든 데이터를 한 팀이 관리한다는 것은, 모든 애플리케이션을 한 팀이 개발한다는 것만큼 비현실적이다."
데이터 메시(Data Mesh)의 4원칙:
원칙 1
도메인 중심 분산 소유권 — 마케팅팀이 마케팅 데이터를, 물류팀이 물류 데이터를 소유하고 관리한다
원칙 2
데이터 as a Product — 내부 데이터도 "제품"처럼 문서화, 품질 보증, SLA를 적용한다
원칙 3
셀프서비스 데이터 인프라 플랫폼 — 도메인 팀이 인프라 전문가 없이도 데이터를 생산·공유할 수 있어야 한다
원칙 4
연합 거버넌스 — 글로벌 표준(보안, 규정 준수)은 중앙에서, 세부 관리는 각 도메인 자율로
레이크하우스: 데이터 레이크 + 데이터 웨어하우스의 통합
2020년, Databricks의 연구팀은 VLDB(초대규모 데이터베이스 국제학술대회)에 Delta Lake 논문을 발표하면서 레이크하우스(Lakehouse) 아키텍처를 제안했다.
핵심 문제의식: 데이터 레이크(저비용, 유연)와 데이터 웨어하우스(ACID 트랜잭션, 성능)를 왜 따로 운영해야 하는가?
레이크하우스 = 오브젝트 스토리지 + ACID 트랜잭션 레이어(Delta Lake/Iceberg) + 머신러닝 네이티브 지원
제4장: 데이터 품질 — "GIGO"의 56조 원짜리 교훈
GIGO: 1958년부터 이어온 경고
GIGO(Garbage In, Garbage Out) — "쓰레기가 들어가면 쓰레기가 나온다." 이 원칙의 기원은 IBM의 조지 퓨셀(George Fuechsel)로 전해진다. 1958~1959년 뉴욕에서 IBM 305 RAMAC 교육을 하면서 사용한 표현이라고 알려져 있다. 1963년 3월, AP 기자 레이먼드 크라울리가 미국 국세청 데이터 센터를 취재하면서 이 표현을 기사에 처음 인쇄했다.
66년이 지난 지금, GIGO의 현대적 표현은 이렇다: "잘못된 데이터로 학습한 AI는 자신있게 틀린 답을 낸다."
데이터 품질 비용: 연간 12조 원 이상
Gartner의 연구는 명확한 수치를 제시한다:
낮은 데이터 품질로 인한 조직 손실 (Gartner, 연평균)
평균 $12.9M/년
미국 경제 전체 손실 추정 (IBM/Thomas Redman, HBR 2016)
$3.1조/년
IBM이 하버드 비즈니스 리뷰에 발표한 분석에 따르면, 불량 데이터가 미국 경제에 미치는 비용은 연간 3조 1,000억 달러(약 4,300조 원)에 달한다. 이 수치의 신뢰도에 대한 논란은 있지만, 방향성에는 이견이 없다.
데이터 품질의 6차원
데이터 품질 6차원 (DAMA 표준)
정확성 (Accuracy)
데이터가 실제를 정확히 반영하는가
완전성 (Completeness)
필수 데이터가 누락 없이 존재하는가
일관성 (Consistency)
여러 시스템 간 데이터가 일치하는가
적시성 (Timeliness)
필요한 시점에 최신 데이터가 있는가
유일성 (Uniqueness)
중복 데이터 없이 유일하게 식별되는가
유효성 (Validity)
정의된 형식·범위를 준수하는가
마스터 데이터 관리(MDM): 진실의 단일 공급원
MDM(Master Data Management)은 기업의 핵심 참조 데이터(고객, 제품, 공급업체, 지역 등)에 대한 "단일 진실 공급원(Single Source of Truth)"을 만드는 것이다.
글로벌 MDM 시장 규모는 2025년 약 190억 달러(약 27조 원)에서 2032년 약 720억 달러(약 100조 원)로 성장할 전망이다(CAGR 18%).
MDM이 없으면 무슨 일이 생기는가? 현실적인 예시:
- 영업팀 CRM의 "삼성전자" + ERP의 "Samsung Electronics Korea" + 물류 시스템의 "삼성(주)" = 같은 고객인가, 다른 고객인가?
- 제품 코드 "P-001"이 ERP에서는 "가죽 지갑"이고, 창고 시스템에서는 "가죽 벨트"면?
이 혼란이 ERP 도입 실패의 가장 큰 원인 중 하나다.
사례: 의료 데이터 품질 — 한국의 FHIR 도입
한국 보건복지부는 2023년 9월 "보건의료 데이터 용어 및 전송 표준" 고시를 전면 개정했다. 이 고시는 KR CDI(Korea Core Data for Interoperability)와 HL7 FHIR KR Core 표준을 도입했다.
2022년 시범 운영 당시 245개 의료기관으로 시작한 마이헬스웨이(MyHealthWay)는 2023년 9월 600개 이상의 기관으로 확대됐다. 건강 이력, 처방전, 진단 결과 등 12개 표준 카테고리를 통합 관리한다.
현황: 상급 종합병원 기준 CDA(임상문서 아키텍처) 채택률 21%, FHIR 채택률은 아직 10% 수준 — 의료 DX의 데이터 표준화가 아직 진행 중임을 보여준다.
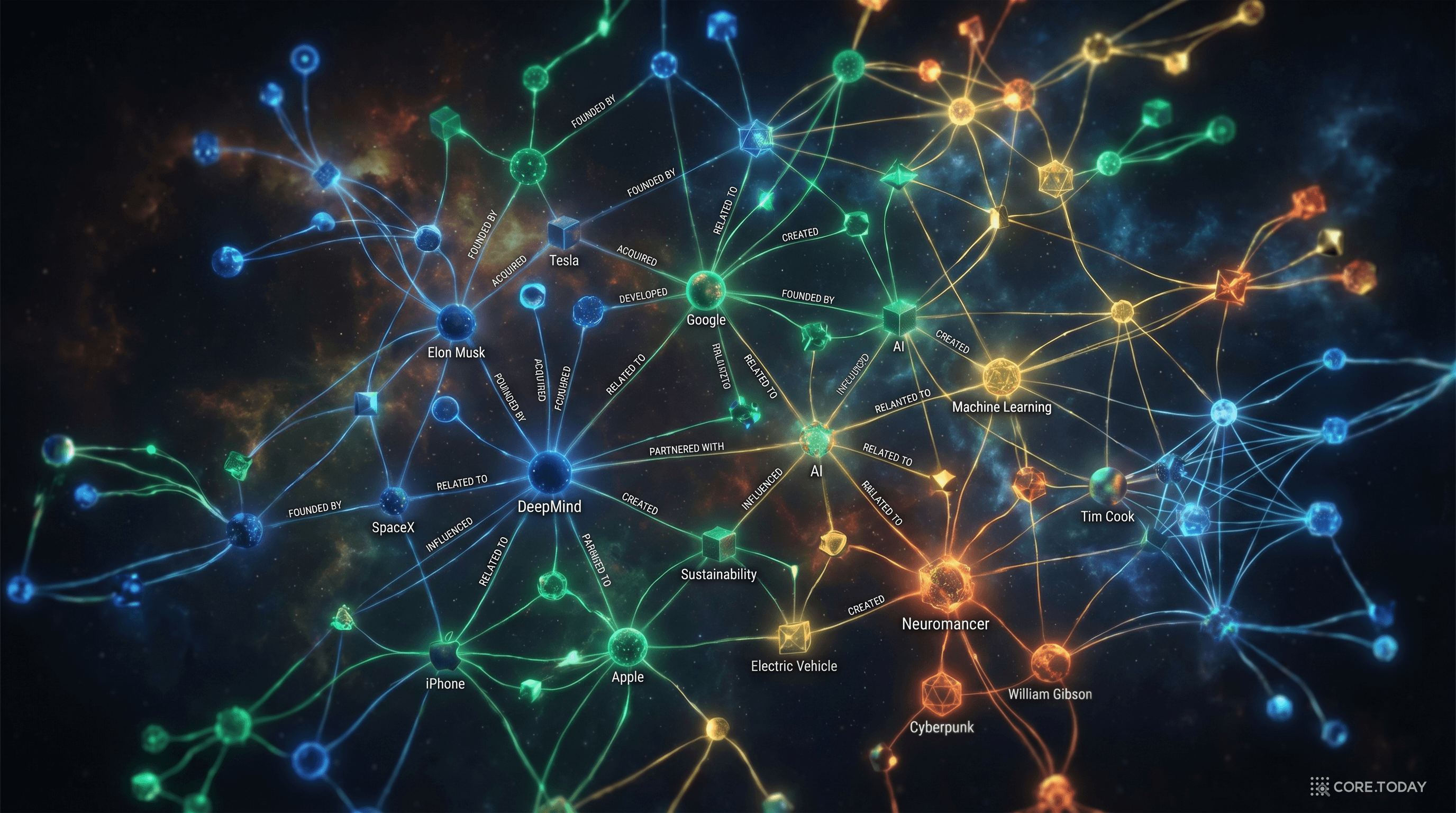
제5장: 지식 그래프와 온톨로지 — 데이터에 "의미"를 입히다
시맨틱 웹에서 엔터프라이즈 지식 그래프까지
팀 버너스-리(Tim Berners-Lee)가 1989년 월드와이드웹을 발명한 것은 잘 알려져 있다. 덜 알려진 것은, 그가 2001년 Scientific American에 기고한 에세이에서 "시맨틱 웹(Semantic Web)"을 제안했다는 사실이다.
버너스-리의 비전: 웹의 정보가 기계가 이해할 수 있는 방식으로 연결된다면, 컴퓨터는 단순히 문서를 보여주는 것을 넘어 의미(semantics)를 처리할 수 있다.
이를 위한 W3C 표준들이 2000년대 초 차례로 확정됐다:
1999-2004
RDF (Resource Description Framework) — "주어-술어-목적어" 트리플로 모든 사실을 표현. W3C 권고안 2004년 확정
2004
OWL (Web Ontology Language) — 개념 간 관계와 제약을 형식적으로 정의. 2004년 2월 W3C 권고안
2008
SPARQL — RDF 지식 그래프 쿼리 언어. 2008년 1월 W3C 권고안 (SPARQL 1.1은 2013년)
2012
Google Knowledge Graph — 이 기술들이 상업적으로 실현된 가장 유명한 사례
2012년 5월 16일: "Things, not Strings"
2012년 5월 16일, 구글은 블로그 포스트 하나를 올렸다. 제목: "Introducing the Knowledge Graph: things, not strings."
문자열(string)이 아닌 개체(thing)를 이해하겠다는 선언이었다. "재규어"를 검색하면 자동차인지 동물인지 문자열 매칭으로 추측하는 게 아니라, "재규어"라는 개체가 무엇인지 이해한다는 것이다.
론칭 당시 구글 지식 그래프는 5억 7,000만 개 개체, 180억 개 사실을 담고 있었다. 7개월 만에 3배로 성장했다. 2016년 700억 사실, 2020년 5,000억 사실에 5억 개 개체. 2024년 초 추정: 540억 개 개체, 1조 6,000억 개 사실.
구글 지식 그래프를 구축하는 데 핵심 역할을 한 것은 2010년 구글이 인수한 Freebase — 오픈 소스 협업 지식베이스였다.
온톨로지란 무엇인가
온톨로지(Ontology)는 철학 용어다. 원래 "존재론"을 뜻하지만, 데이터 세계에서는 "특정 도메인의 개념과 그 관계를 형식적으로 정의한 명세"를 의미한다.
예시로 이해하자. 의료 온톨로지에서:
- 개념: 질병, 증상, 치료, 약물
- 관계: "당뇨병은 고혈당 증상을 유발한다", "메트포르민은 당뇨병을 치료한다"
- 제약: "치료는 반드시 의사가 처방한다"
이 형식적 정의가 있어야 컴퓨터가 추론(reasoning)을 할 수 있다.
엔터프라이즈 지식 그래프: 누가 쓰는가
| 기업 | 용도 | 비즈니스 임팩트 |
|---|
| Google | 검색 결과 엔티티 이해, 지식 패널 | 검색 품질 혁신, "Things not Strings" |
| Amazon | 상품 지식 그래프, 공동 구매 추천 | "카메라 케이스 구매 → 화면 보호 필름 추천" 등 맥락 기반 추천 |
| LinkedIn | 경제 그래프(사람-직업-기업-스킬) | 구직 매칭, 스킬 트렌드 인사이트 |
| 의료 기업 | 약물-질환-유전자 관계 그래프 | 신약 후보 발굴 기간 단축 |
| 제조업 | 공급망 디지털 트윈 | 부품 관계 추적, 리스크 경보 |
그래프 데이터베이스 시장
2025년 글로벌 그래프 데이터베이스 시장 규모는 약 33억 달러(약 4.6조 원), 2030년까지 113억 달러로 성장 전망(CAGR 27.9%).
주요 플레이어:
- Neo4j: 매출 2억 달러 돌파, Azure OpenAI와 통합 — LLM 출력의 환각(hallucination)을 지식 그래프로 교정하는 RAG 파이프라인
- Amazon Neptune: AWS 생태계 내 지식 그래프 서비스
- TigerGraph: 금융·통신 분야 특화, 1억 7,100만 달러 투자 유치
제6장: 실전 사례 — 데이터 구조가 비즈니스를 바꾼다
넷플릭스: 2억 3,000만 명의 데이터가 만드는 "다음 볼 것"
넷플릭스는 콘텐츠 기업인가, 데이터 기업인가?
2024년 기준, 넷플릭스는 2억 3,000만 명 이상의 구독자 프로필을 분석한다. 재생 일시정지 지점, 되감기 횟수, 자막 언어 선택, 썸네일 클릭률까지. 넷플릭스 시청의 80%가 추천 알고리즘에 의해 발생하며, 이 추천 엔진이 연간 10억 달러(약 1조 4,000억 원) 이상의 비용을 절감한다고 추정된다(구독 이탈 감소 효과 포함).
▶
넷플릭스 데이터 아키텍처의 핵심
AWS 기반 모델 학습 + 자체 CDN(Open Connect) 콘텐츠 전달. 매년 약 200회 A/B 테스트 진행. 30만 명을 무작위 선발해 UI부터 추천 알고리즘까지 실험. 기술 스택: SemanticGNN(콘텐츠 의미 이해), 컨텍스트 밴딧(UI 최적화), 멀티태스크 학습(운영 효율화), 인과 추론(편향 제거).
월마트: 72%의 자본 지출을 데이터 공급망에
월마트는 2019~2020년 사이 전략적 자본 지출의 72%를 공급망 전환에 투자했다 — 총 110억 달러(약 15조 원) 이상. 결과:
- 재고 부족률(stockout) 16% 감소
- 경로 최적화로 불필요한 주행 거리 3,000만 마일 절감
- 공급업체 자동 협상: 68% 성공률, 평균 3% 비용 절감
- 수요 예측 기반 재고 관리로 2023년 6,120억 달러 매출 달성 기여
RFID 태그와 IoT 센서를 통한 실시간 재고 추적, 예측 분석 기반 수요 예측 — 이 모든 것의 토대는 공급망 전반의 데이터를 일관된 구조로 연결하는 것이었다.
카카오·네이버의 데이터 인프라
2024년 1분기, 카카오는 첫 자체 데이터센터인 카카오 데이터센터 안산을 공식 오픈했다. 하이퍼스케일 규모 — 4,000개 랙, 최대 12만 대 서버, 6 EB(엑사바이트) 데이터 저장 능력, PUE(전력 효율) 1.3 이하.
네이버의 두 번째 데이터센터 '각 세종'(2023년 11월 완공)은 세종특별자치시에 위치한 국내 최대 하이퍼스케일 — 축구장 41개 면적, 최대 60만 대 서버 수용 가능.
한국 데이터센터 시장은 2025년 16억 5,000만 달러(약 2.3조 원), 2030년 42억 7,000만 달러로 성장 전망 (CAGR 20.95%).
제7장: 2025~2026년 트렌드 — AI가 데이터 구조를 어떻게 바꾸는가
트렌드 1: 벡터 데이터베이스 — AI를 위한 새로운 데이터 구조
LLM(대형 언어 모델)의 폭발적 성장은 벡터 데이터베이스라는 새로운 시장을 만들었다.
벡터 데이터베이스는 텍스트, 이미지, 오디오를 수백~수천 차원의 수치 벡터로 변환해 저장하고, 의미적 유사성(Semantic Similarity) 기반으로 검색한다. "자동차"를 검색하면 "승용차", "차량", "automobile"도 함께 찾아준다 — 단순 키워드 매칭이 아니라 의미로 검색.
벡터 DB 시장 (2030년 전망)
$89.5억 (CAGR 27.5%)
2025년 2월, MongoDB는 임베딩 생성 전문 기업 Voyage AI를 2억 2,000만 달러에 인수 — 시장 통합이 시작됐다. Pinecone, Weaviate, Qdrant, Milvus, pgvector 등 다양한 플레이어가 경쟁 중이다.
트렌드 2: 데이터 패브릭 — AI 시대의 통합 데이터 관리
Gartner는 데이터 패브릭(Data Fabric)을 "데이터 관리 복잡성을 다루는 설계 개념"으로 정의한다. AI/ML이 메타데이터를 자동으로 연결하고 태깅함으로써, 이기종 시스템의 데이터를 마치 하나의 데이터 소스처럼 사용할 수 있게 한다.
Gartner는 2025년까지 주요 기업의 CDAOs(최고데이터분석책임자)가 데이터 패브릭을 데이터 관리 복잡성 해결의 핵심 요소로 채택할 것으로 예측했다. 특히 GenAI 워크로드에 이상적인 아키텍처로 평가받고 있다.
트렌드 3: AI-Ready 데이터 — 데이터 엔지니어링의 새로운 역할
2025년, 기업의 GenAI 지출은 전년 대비 3.2배 증가한 370억 달러에 달했다. McKinsey 2025년 중반 조사에서 88%의 기업이 최소 하나의 비즈니스 기능에 AI를 사용하고 있으며, 72%는 생성형 AI를 채택했다.
그러나 진짜 병목은 AI 모델이 아니다 — 데이터 준비다. LLM이 "쓸 수 있는" 상태의 데이터를 만들기 위해:
원시 데이터
(이메일, 문서, DB)
→
청크(Chunk)
분할
→
임베딩
(Embedding)
→
벡터 DB
저장
→
RAG
검색 + 생성
데이터 엔지니어링 팀이 점점 더 "GenAI 팀에게 엔터프라이즈 레디 데이터를 공급"하는 역할을 맡게 될 것이다.
트렌드 4: 합성 데이터 — 데이터 부족의 해법
합성 데이터(Synthetic Data)는 실제 데이터를 기반으로 통계적 특성은 보존하되, 개인정보를 포함하지 않는 인공 데이터다.
2025년 합성 데이터 시장 규모: 약 6억 달러. 2034년까지 69억~90억 달러로 성장 전망(CAGR 31~35%).
성장 동인:
- GDPR, 한국 개인정보보호법(PIPA) 강화로 실제 데이터 사용 제한
- AI 학습에 필요한 대규모 레이블 데이터 확보 비용
- 의료·금융 등 민감 데이터가 많은 분야의 규제 준수
트렌드 5: 데이터 주권과 규제 강화
2021년 12월 17일, EU는 한국의 개인정보보호 수준이 충분하다는 적정성 결정(Adequacy Decision)을 내렸다 — 한국 기업이 EU-한국 간 데이터를 자유롭게 이전할 수 있게 됐다.
한국 개인정보보호법(PIPA)의 2023~2024년 주요 개정:
- 데이터 이동권 신설 (개인이 자신의 데이터를 다른 서비스로 이동 요청 가능)
- 자동화 의사결정 배제권 신설 (AI 알고리즘 결정에 이의 제기 가능)
- 2024년 3월 15일 시행: AI 관련 자동화 결정 규정 + CPO(개인정보보호책임자) 자격 요건 강화
- 해외 기업 대상 PIPA 적용 가이드라인 발표 (2024년)
제8장: DX 전문가를 위한 데이터 구조 역량 지도
데이터 구조 이해의 3단계
DX 프로젝트에서 데이터 구조를 이해하는 능력은 세 단계로 나눌 수 있다.
기초 (Entry)
데이터 모델 읽기 — ER 다이어그램을 보고 테이블 간 관계를 이해한다. SQL로 JOIN을 구사한다. 정형/비정형 데이터의 차이를 설명할 수 있다.
중급 (Practitioner)
데이터 파이프라인 설계 — ETL/ELT 흐름을 설계하고 dbt로 변환을 구현한다. Airflow로 파이프라인을 오케스트레이션한다. 데이터 품질 검증 로직을 작성한다.
고급 (Expert)
데이터 아키텍처 결정 — Lakehouse vs. Data Mesh 중 어떤 것이 맞는지 비즈니스 맥락에서 판단한다. 지식 그래프를 설계하고 RAG 파이프라인에 통합한다. 데이터 거버넌스 체계를 수립한다.
기업의 데이터 성숙도 자가 진단
아래 질문에 "예"가 몇 개인가?
| 영역 | 진단 질문 | 성숙도 지표 |
|---|
| 구조 | "우리 회사의 핵심 데이터 모델(ER 다이어그램)이 문서화되어 있는가?" | 예 → 레벨 2 이상 |
| 파이프라인 | "데이터가 어떻게 생성되어 어디로 흘러가는지 추적 가능한가?" | 예 → 레벨 3 이상 |
| 품질 | "데이터 품질 기준이 정의되어 있고 자동 검증이 되는가?" | 예 → 레벨 3 이상 |
| 거버넌스 | "데이터 소유자(Data Owner)가 각 도메인별로 지정되어 있는가?" | 예 → 레벨 4 이상 |
| AI 준비도 | "비정형 데이터(문서, 이메일, 영상)가 AI가 처리할 수 있는 형태로 있는가?" | 예 → 레벨 5 |
0~1개: 데이터 기반 DX 시작 전 단계. 가장 먼저 할 일은 핵심 데이터 목록 작성.
2~3개: 구조화는 됐지만 거버넌스와 AI 준비도가 낮다.
4~5개: 데이터 성숙 조직. AI 도입의 기술적 기반이 갖춰져 있다.
나가며: "데이터를 못 보면 DX 못 한다"의 의미
1970년 Edgar Codd가 8페이지짜리 논문으로 관계형 모델을 제안했을 때, 그 논문이 50년 뒤 전 세계 기업의 의사결정 방식을 바꿀 것이라고 예상한 사람은 많지 않았다.
그로부터 56년 후인 2026년, 우리는 더 복잡한 세계에 살고 있다. 기업 데이터의 90%가 비정형이고, AI는 이 비정형 데이터를 소화해 인사이트를 만들어낼 수 있다. 벡터 데이터베이스는 의미 기반 검색을 가능하게 했고, 지식 그래프는 데이터에 맥락과 관계를 부여한다.
그러나 기술이 아무리 발전해도, 변하지 않는 진리가 있다:
1. 구조 없이 가치 없다
데이터는 구조화될 때 비로소 분석 가능해진다. 비정형 데이터도 결국 "어떤 구조로 표현할 것인가"의 문제다.
2. 품질 없이 신뢰 없다
1억 2,500만 달러짜리 탐사선도, 잘못된 단위 하나로 대기권에서 타버렸다. AI 모델도 마찬가지다.
3. 맥락 없이 의미 없다
"재고 = 500"이 많은 건지 적은 건지는 산업, 계절, 수요 예측이라는 맥락이 있어야 판단할 수 있다. 지식 그래프는 이 맥락을 데이터 구조 안에 담는다.
DX는 기술 도입이 아니라 비즈니스 변혁이다. 그리고 모든 비즈니스 변혁은 "현실을 정확하게 보는 것"에서 시작한다. 데이터 구조를 이해한다는 것은 — 기업의 현실을 디지털로 번역할 수 있는 능력을 갖추는 것이다.
데이터를 못 보면 DX 못 한다. 이것이 세 번째 기둥이다.
다음 편에서는 데이터 위에서 인사이트를 만들어내는 도구 — DX의 네 번째 축, "AI/ML 이해"를 다룬다.
참고 자료
- Edgar F. Codd, "A Relational Model of Data for Large Shared Data Banks," CACM 13(6), June 1970
- Peter P. Chen, "The Entity-Relationship Model," ACM TODS 1(1), March 1976
- Bill Inmon, Building the Data Warehouse (Wiley, 1992)
- Ralph Kimball, The Data Warehouse Toolkit (Wiley, 1996)
- Zhamak Dehghani, "How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh" (2019)
- Armbrust et al., "Lakehouse: A New Generation of Open Platforms," VLDB (2020)
- Google Knowledge Graph, "Introducing the Knowledge Graph" (May 16, 2012)
- Gartner, "The State of Data Quality" (2024~2025)
- IDC, "Worldwide Semiannual Big Data and Analytics Spending Guide" (2025)




