들어가며: Capital One — "모든 데이터센터를 닫아라"
2012년, 미국 5대 은행 중 하나인 Capital One의 CIO 롭 알렉산더(Rob Alexander)는 경영진에게 충격적인 제안을 했다: "자사 데이터센터 8곳을 전부 폐쇄하고, 모든 워크로드를 퍼블릭 클라우드(AWS)로 이전하겠다."
은행이다. 고객의 신용카드 정보, 대출 기록, 금융 거래 데이터를 다루는 미국 대형 은행이, 자체 서버실을 모두 포기하겠다고 선언한 것이다. 월스트리트와 규제 당국은 의구심을 보였다.
그러나 Capital One은 움직였다. 2015년부터 본격적으로 마이그레이션을 시작했고, 2020년에 마침내 8개 데이터센터를 전부 폐쇄했다. 미국 대형 은행 최초의 100% 퍼블릭 클라우드 전환이었다.
결과는 어땠는가?
Capital One CTO 조지 브래디(George Brady)는 이렇게 말했다:
"클라우드로의 전환은 기술적 결정이 아니었다. 비즈니스 속도에 관한 결정이었다. 데이터센터를 운영하는 것은 우리의 핵심 역량이 아니다. 고객에게 최고의 금융 서비스를 제공하는 것이 우리의 핵심 역량이다."
이것이 클라우드 시대의 핵심 사고 전환이다:
X
과거의 사고
"서버를 만든다" — 하드웨어 구매, 데이터센터 임대, OS 설치, 보안 패치, 장애 대응까지 모두 직접 수행
>
전환의 계기
인프라 관리에 투입되는 시간과 비용이 실제 비즈니스 가치 창출을 압도. 보안 사고 리스크도 자체 관리보다 클라우드가 낮다는 데이터 축적
O
현재의 사고
"서비스를 운영한다" — 인프라는 클라우드에 위임하고, 팀은 비즈니스 로직과 사용자 경험에 집중
이 글은 DX 전문가 로드맵 10편 시리즈의 여섯 번째 편이다. 이전 글에서 시스템 아키텍처의 원리를 다루었다면, 이번 편에서는 그 아키텍처가 실제로 돌아가는 땅 — 클라우드와 인프라의 기술을 총정리한다.
제1장: 클라우드 컴퓨팅의 역사 — "No Software"에서 AI-as-a-Service까지
1999년: Salesforce — "No Software"의 선언
클라우드 컴퓨팅의 역사를 이야기할 때, 기술보다 먼저 등장한 것은 비즈니스 모델이었다.
1999년 3월, 마크 베니오프(Marc Benioff)는 오라클 부사장 자리를 박차고 나와 Salesforce를 창업했다. 그의 아파트에서 시작한 이 회사의 슬로건은 도발적이었다:
"No Software"
당시 기업용 소프트웨어의 구매 방식은 이랬다: 수억 원짜리 라이선스를 구매하고, 자체 서버에 설치하고, 전문 컨설턴트를 고용해 12~18개월간 구축하고, 유지보수 비용을 매년 지불한다. 베니오프는 이 전체 과정을 부정했다. 소프트웨어를 "소유"하지 말고 "사용"하라. 웹 브라우저만 있으면 CRM 시스템을 바로 쓸 수 있게 만들겠다.
이것이 SaaS(Software as a Service)의 상업적 탄생이다. Salesforce는 2004년 NYSE에 상장되었고, 2026년 현재 시가총액 3,000억 달러 이상의 클라우드 거인이 되었다.
2006년: AWS — 인프라를 API로 팔다
Salesforce가 소프트웨어를 서비스화했다면, AWS(Amazon Web Services)는 인프라 자체를 서비스화했다.
아마존 내부에서는 이미 2000년대 초반부터 문제가 있었다. 새로운 기능을 배포하려면 인프라 팀에 서버를 요청해야 했고, 서버 프로비저닝에 수 주에서 수 개월이 걸렸다. 아마존의 엔지니어들은 코드를 짜는 시간보다 인프라를 기다리는 시간이 더 길었다.
이 문제를 해결하기 위해 아마존은 내부 인프라를 API로 추상화하기 시작했다. 그리고 깨달았다 — "이 API를 외부에도 팔 수 있겠다."
2006.03
Amazon S3 출시 — 객체 스토리지. "무제한 저장소"를 API 하나로 제공. 최초의 IaaS.
2006.08
Amazon EC2 출시 — 가상 서버를 분 단위로 대여. "서버를 사는" 시대의 종말 선언.
2008
Google App Engine — 최초의 PaaS(Platform as a Service). 코드만 올리면 인프라를 알아서 관리.
2010.02
Microsoft Azure GA — 마이크로소프트의 클라우드 진출. 기존 엔터프라이즈 고객 기반 활용.
2011
Google Cloud Platform 본격 서비스 시작 — BigQuery, Compute Engine 등.
2014.11
AWS Lambda 출시 — 최초의 서버리스 컴퓨팅. 서버 관리 자체가 사라진다.
2023~
AI-as-a-Service 폭발 — GPT API, Claude API, Bedrock, Vertex AI. GPU 인프라를 API로 소비.
클라우드 서비스 모델의 진화
클라우드의 핵심은 "무엇을 직접 관리하는가"의 범위가 점점 줄어드는 것이다. 이 진화를 한눈에 보자:
| 모델 | 직접 관리 범위 | 대표 서비스 | 등장 시점 |
|---|
| On-Premise | 전부 (하드웨어~애플리케이션) | 자체 데이터센터 | ~2005 |
| IaaS | OS, 미들웨어, 런타임, 앱, 데이터 | AWS EC2, Azure VM, GCE | 2006 |
| PaaS | 앱, 데이터 | Heroku, Google App Engine | 2008 |
| SaaS | 설정만 | Salesforce, Google Workspace | 1999 |
| FaaS | 함수 코드만 | AWS Lambda, Cloud Functions | 2014 |
| AI-aaS | 프롬프트/파인튜닝만 | OpenAI API, AWS Bedrock, Vertex AI | 2023 |
On-Premise에서 AI-aaS까지, 기업이 "직접 관리하는 범위"는 계속 줄어든다. DX 전문가가 이해해야 할 핵심: 관리 범위가 줄어든다는 것은 비즈니스 로직에 투입할 시간이 늘어난다는 뜻이다.
제2장: 클라우드 시장 — 숫자로 보는 2026년
글로벌 빅3의 지형
2026년 현재, 글로벌 클라우드 인프라 시장은 연간 $4,500억+(약 630조 원) 규모로 성장했다. Synergy Research와 Canalys의 Q4 2025 데이터를 기반으로 시장 점유율을 살펴보자:
Q4 2025 분기 기준 글로벌 클라우드 인프라 지출은 약 $1,190억(약 167조 원)을 기록했다. 전년 동기 대비 약 22% 성장이다.
GenAI 클라우드: 폭발적 성장
가장 눈에 띄는 트렌드는 GenAI 관련 클라우드 지출이다:
GPU 인스턴스 부족 현상은 2024년부터 지속되고 있다. NVIDIA H100/H200 GPU가 장착된 인스턴스의 예약 대기 시간은 여전히 수 주에서 수 개월이다. 이것이 GPU-as-a-Service 시장(CoreWeave, Lambda Labs, Together AI 등)이 급성장한 배경이다.
한국 클라우드 시장
한국 클라우드 시장도 빠르게 성장 중이다. 2026년 기준 약 12조 원 규모이며, 글로벌 빅3와 국내 사업자의 경쟁 구도가 뚜렷하다:
| 사업자 | 강점 | 주요 고객 | 특이사항 |
|---|
| AWS Korea | 서비스 수 200+, 글로벌 생태계 | 쿠팡, 배달의민족, 토스 | 서울 리전 2016년 오픈 |
| NCP (네이버 클라우드) | HyperCLOVA X, 한국어 AI | 공공기관, 네이버 계열 | 금융 클라우드 인증 |
| KT Cloud | 통신 인프라, 하이브리드 | 공공, 통신, 금융 | CSAP 인증 보유 |
| Azure Korea | MS 365 연계, OpenAI 독점 | 대기업, 금융 | 부산 리전 추가 |
한국 정부는 "클라우드 퍼스트(Cloud First)" 정책을 추진 중이다. 2025년부터 공공기관의 신규 정보시스템은 클라우드 도입을 우선 검토하도록 의무화되었다. 이는 한국 클라우드 시장의 구조적 성장 동력이다.
제3장: 핵심 인프라 개념 — VPC부터 오토스케일링까지
클라우드를 "이해한다"는 것은 버튼 몇 번 클릭해서 서버를 만드는 것이 아니다. 네트워크 구조, 보안 경계, 가용성 설계를 이해하는 것이다.
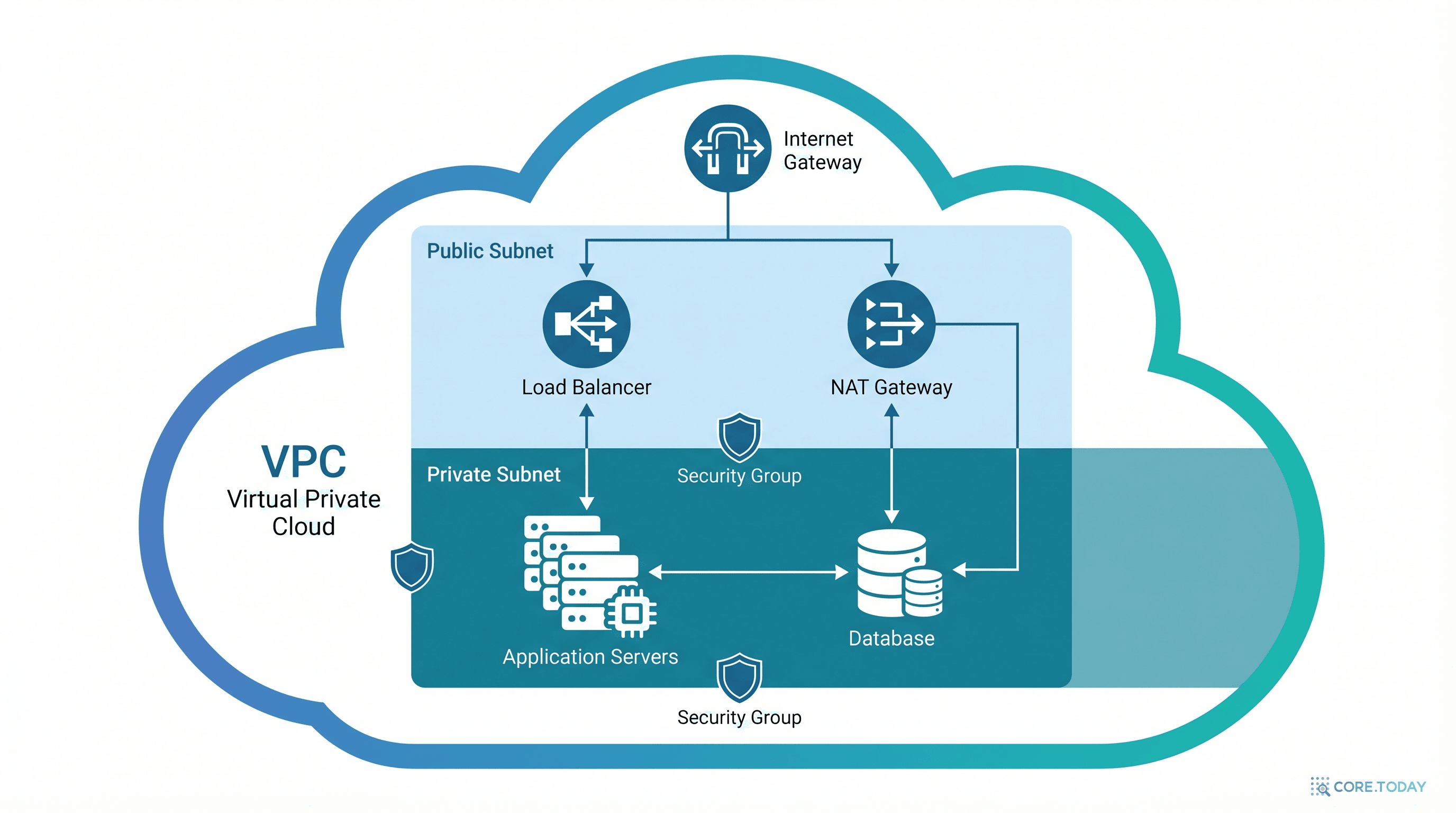
VPC — 클라우드 안의 나만의 네트워크
VPC(Virtual Private Cloud)는 퍼블릭 클라우드 안에 격리된 사설 네트워크를 만드는 개념이다. 아파트 단지(퍼블릭 클라우드) 안에 우리 집(VPC)의 벽과 문을 설계하는 것이다.
VPC 아키텍처 구성 요소
VPC (10.0.0.0/16)
격리된 가상 네트워크. IP 대역을 직접 설계한다.
퍼블릭 서브넷
10.0.1.0/24
인터넷 게이트웨이와 연결. 웹 서버, 로드밸런서 배치.
프라이빗 서브넷
10.0.2.0/24
인터넷 직접 접근 불가. DB 서버, 앱 서버 배치.
보안 그룹 (SG)
인스턴스 수준 방화벽. "80번 포트만 열기" 같은 인바운드/아웃바운드 규칙.
NACL
서브넷 수준 방화벽. 보안 그룹의 상위 레이어. Stateless.
로드 밸런서 — 트래픽을 분산하라
사용자가 수천, 수만 명이 되면 서버 하나로는 감당할 수 없다. 로드 밸런서(Load Balancer)가 트래픽을 여러 서버에 분산한다:
| 종류 | 동작 레이어 | 용도 | AWS 서비스명 |
|---|
| ALB | L7 (HTTP/HTTPS) | 웹 애플리케이션. URL 경로 기반 라우팅 가능. | Application Load Balancer |
| NLB | L4 (TCP/UDP) | 고성능, 초저지연. 게임 서버, IoT. | Network Load Balancer |
| CLB | L4/L7 | 레거시. 단순 분산. | Classic Load Balancer |
| GWLB | L3 | 보안 어플라이언스(방화벽, IDS/IPS) 앞단. | Gateway Load Balancer |
오토스케일링 — 수요에 따라 자동으로 늘리고 줄인다
DX에서 클라우드가 결정적인 이유: 수요 예측이 불가능한 상황에서도 인프라가 자동 대응한다.
사용자 트래픽 급증
→
CloudWatch 지표 감지
(CPU 70% 초과)
→
Auto Scaling Group
인스턴스 추가
트래픽 감소
→
냉각 기간(Cooldown) 경과
→
인스턴스 자동 축소
비용 절감
배달의민족은 점심/저녁 피크 시간에 트래픽이 평시 대비 3~5배 급증한다. 금요일 저녁은 더 심하다. 이런 패턴에 온프레미스로 대응하려면 항상 피크 기준으로 서버를 유지해야 하므로, 평시에는 70% 이상의 자원이 놀게 된다. 오토스케일링은 이 낭비를 제거한다.
리전과 가용 영역 — 글로벌 인프라
AWS는 2026년 현재 전 세계 34개+ 리전(Region), 100개+ 가용 영역(Availability Zone)을 운영한다. 각 가용 영역은 물리적으로 분리된 데이터센터다.
AWS 글로벌 인프라 구조
리전 (Region)
지리적 영역. 서울(ap-northeast-2), 도쿄, 버지니아 등. 데이터 주권과 지연시간을 고려해 선택.
가용 영역 A (AZ-a)
독립 전원, 냉각, 네트워크를 가진 데이터센터 클러스터.
가용 영역 B (AZ-b)
AZ-a와 수 km 떨어진 별도 시설. 자연재해 시 동시 영향 최소화.
가용 영역 C (AZ-c)
고대역폭 저지연 전용선으로 다른 AZ와 연결.
핵심 설계 원칙: 멀티 AZ 배포. 한 AZ에 장애가 발생해도 다른 AZ에서 서비스가 계속된다. 이것이 클라우드 아키텍처에서 "고가용성(High Availability)"을 달성하는 기본 단위다.
제4장: 컨테이너와 쿠버네티스 — "한 번 만들면 어디서든 실행"
Docker: 솔로몬 하이크스의 번개 같은 5분
2013년 3월, PyCon 2013에서 솔로몬 하이크스(Solomon Hykes)라는 28세 프랑스 개발자가 5분짜리 라이트닝 토크를 했다. 제목은 "The Future of Linux Containers." 그가 데모한 것이 Docker였다.
Docker 이전의 문제는 이랬다:
?!
"내 컴퓨터에서는 되는데요"
개발자의 맥북에서는 완벽하게 동작하는 코드가, 테스트 서버에 올리면 라이브러리 버전 충돌로 에러. 운영 서버에 배포하면 또 다른 에러. 환경마다 OS 버전, 라이브러리 버전, 설정 파일이 달랐다.
+
Docker의 해법: 컨테이너
애플리케이션과 그것이 필요로 하는 모든 것(런타임, 라이브러리, 설정)을 하나의 "컨테이너"로 패키징. 이 컨테이너는 어디서든 동일하게 실행된다.
!
결과
"Build once, run anywhere." 개발, 테스트, 운영 환경의 차이가 사라졌다. Docker Hub에 이미지를 올리면 전 세계 어디서든 그대로 실행.
Docker가 PyCon 데모 하나로 시작해 불과 2년 만에 업계 표준이 된 것은 소프트웨어 역사에서 유례가 드문 사건이다. 2015년까지 Docker의 GitHub 스타는 40,000개를 돌파했고, 모든 클라우드 벤더가 Docker를 지원하기 시작했다.
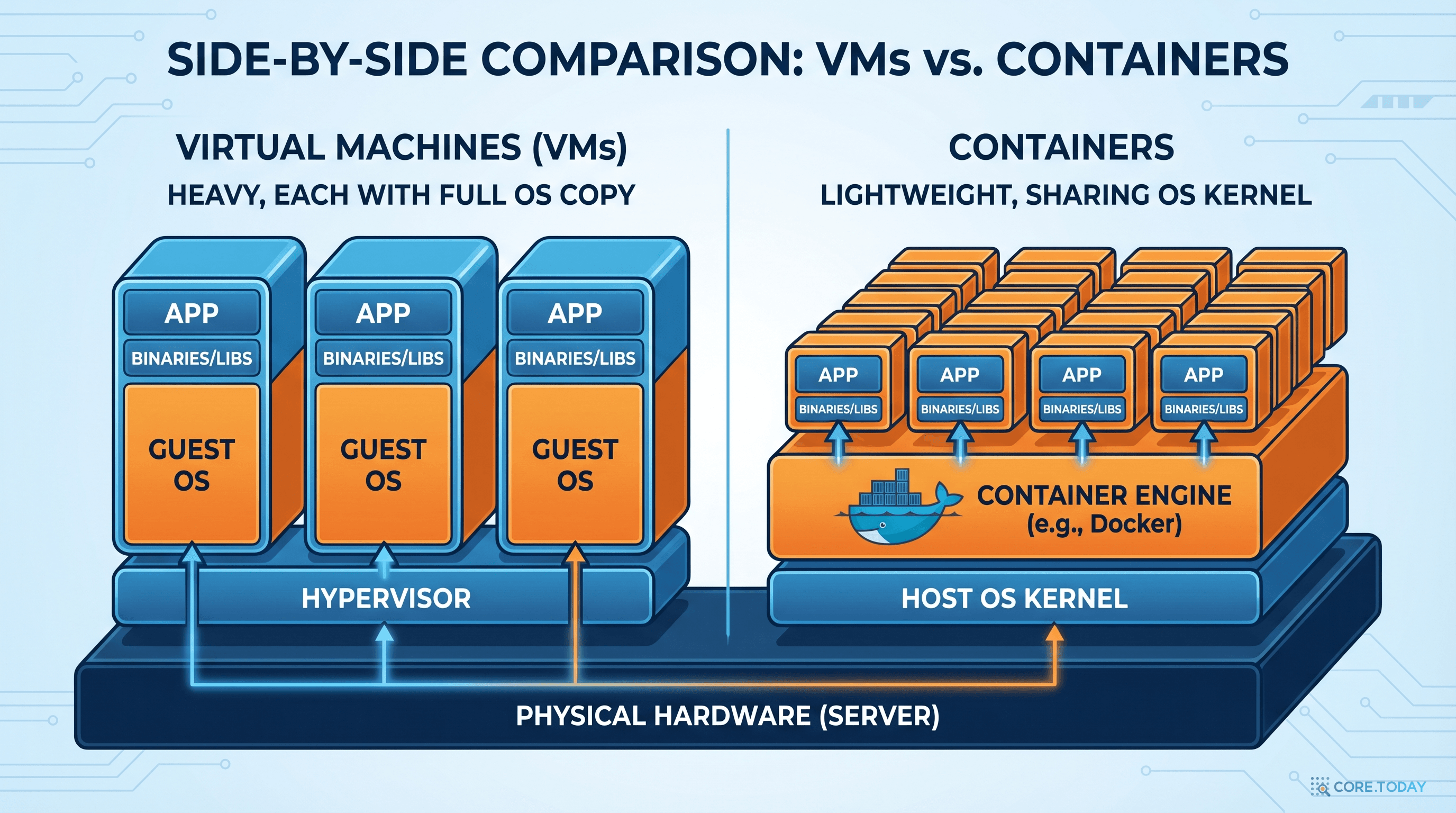
VM vs 컨테이너: 본질적 차이
| 비교 항목 | 가상 머신 (VM) | 컨테이너 (Docker) |
|---|
| 격리 수준 | 하이퍼바이저 기반 완전 격리 | OS 커널 공유, 프로세스 수준 격리 |
| 시작 시간 | 분 단위 | 초 단위 (밀리초 가능) |
| 크기 | GB 단위 (전체 OS 포함) | MB 단위 (필요한 것만) |
| 밀도 | 호스트당 수십 개 | 호스트당 수백~수천 개 |
| 이식성 | 하이퍼바이저 의존 | 어디서든 동일 실행 |
| 보안 | 강한 격리 (별도 OS) | 커널 공유로 상대적 취약 |
| 적합한 용도 | 레거시 앱, 강한 격리 필요 시 | 마이크로서비스, CI/CD, 대규모 배포 |
Kubernetes: Google의 내부 시스템을 세상에 공개하다
Docker가 "컨테이너 하나"를 만드는 도구라면, Kubernetes(K8s)는 "컨테이너 수천 개"를 조율하는 오케스트레이터다.
2014년 6월, Google은 Kubernetes를 오픈소스로 공개했다. 이 프로젝트의 뿌리는 Google이 10년 이상 내부에서 사용해 온 Borg 시스템이다. Google은 매주 수십억 개의 컨테이너를 Borg로 관리해왔고, 그 노하우를 Kubernetes에 녹여냈다.
Google Borg
(2003, 내부)
→
Omega
(2013, 내부 2세대)
→
Kubernetes
(2014, 오픈소스)
→
CNCF 이관
(2015, 중립 재단)
2026년 현재 Kubernetes는 사실상의 컨테이너 오케스트레이션 표준이 되었다. CNCF(Cloud Native Computing Foundation) 조사에 따르면, 기업의 96%가 Kubernetes를 사용하거나 평가 중이다.
AWS 컨테이너 서비스 비교
AWS에서 컨테이너를 운영하는 방법은 여러 가지다:
| 서비스 | 오케스트레이터 | 서버 관리 | 적합한 경우 | 복잡도 |
|---|
| ECS + EC2 | AWS 자체 | 직접 관리 | AWS 생태계 올인, 세밀한 제어 | 중간 |
| ECS + Fargate | AWS 자체 | 서버리스 | 서버 관리 싫지만 K8s도 싫을 때 | 낮음 |
| EKS + EC2 | Kubernetes | 직접 관리 | K8s 생태계 활용, 멀티클라우드 고려 | 높음 |
| EKS + Fargate | Kubernetes | 서버리스 | K8s API + 서버 관리 불필요 | 중간 |
DX 관점에서의 선택 기준: "팀에 Kubernetes 전문가가 있는가?" 없다면 ECS + Fargate부터 시작하는 것이 현실적이다. K8s는 강력하지만, 학습 곡선이 가파르다. 잘못 운영된 K8s 클러스터는 직접 관리하는 서버보다 더 많은 문제를 만든다.

제5장: 서버리스 — "코드만 쓰면 된다"
AWS Lambda: 함수 단위의 혁명
2014년 11월, AWS Lambda가 등장했다. 패러다임 전환이었다:
1. 서버 관리 제로
OS 패치, 보안 업데이트, 스케일링 — 전부 클라우드 벤더가 처리한다.
2. 이벤트 드리븐
HTTP 요청, 파일 업로드, DB 변경, 스케줄(cron) 등 이벤트가 발생할 때만 실행된다.
3. Pay-per-Invocation
실행한 만큼만 과금. 1ms 단위. 트래픽이 0이면 비용도 0원.
4. 자동 스케일링
동시 요청 1개든 10,000개든 자동으로 확장. 설정 불필요.
Cold Start 문제
서버리스의 아킬레스건은 콜드 스타트(Cold Start)다. Lambda 함수가 일정 시간 호출되지 않으면 실행 환경이 해제되고, 다음 호출 시 환경을 다시 구성해야 한다. 이 지연이 콜드 스타트다.
AWS는 이를 완화하기 위해 Provisioned Concurrency(사전 프로비저닝)와 SnapStart(Java용 스냅샷 복원) 기능을 제공한다. 2025년에는 Lambda의 콜드 스타트가 이전 대비 크게 개선되어, Python/Node.js 기준 100ms 이하도 가능해졌다.
서버리스 vs 컨테이너: 언제 무엇을 쓸 것인가
| 기준 | 서버리스 (Lambda) | 컨테이너 (ECS/EKS) |
|---|
| 실행 시간 | 짧은 작업 (15분 이내) | 긴 작업, 상시 실행 |
| 트래픽 패턴 | 간헐적, 이벤트 기반 | 지속적, 예측 가능 |
| 상태 관리 | Stateless만 가능 | Stateful 가능 |
| 비용 구조 | 사용한 만큼 (호출 단위) | 실행 시간 단위 (유휴 시에도 과금) |
| 커스터마이징 | 런타임 제약 있음 | 자유로운 환경 구성 |
| 콜드 스타트 | 존재 (100~800ms) | 없음 (상시 실행) |
| 운영 복잡도 | 최소 | K8s의 경우 높음 |
엣지 서버리스: Vercel, Cloudflare Workers
서버리스의 최신 진화는 엣지(Edge)에서의 실행이다. Vercel Edge Functions, Cloudflare Workers, Netlify Edge Functions 등은 전 세계 수백 개 엣지 로케이션에서 함수를 실행한다.
기존 Lambda
특정 리전(예: us-east-1)에서만 실행. 한국 사용자가 미국 서버를 왕복하면 높은 지연시간 발생.
CDN 캐싱
정적 콘텐츠는 엣지에 캐싱 가능. 하지만 동적 로직은 여전히 원본 서버에서 처리.
엣지 서버리스
동적 로직 자체를 엣지에서 실행. 사용자와 가장 가까운 PoP에서 처리. 지연시간 50ms 이하.
이 블로그(coredot.today)도 Vercel 위에서 Next.js로 운영되고 있다. 한국 사용자에게는 서울 근처 엣지에서, 미국 사용자에게는 미국 엣지에서 페이지를 생성해 제공한다. 서버를 "만들지" 않아도 글로벌 서비스가 가능한 시대다.
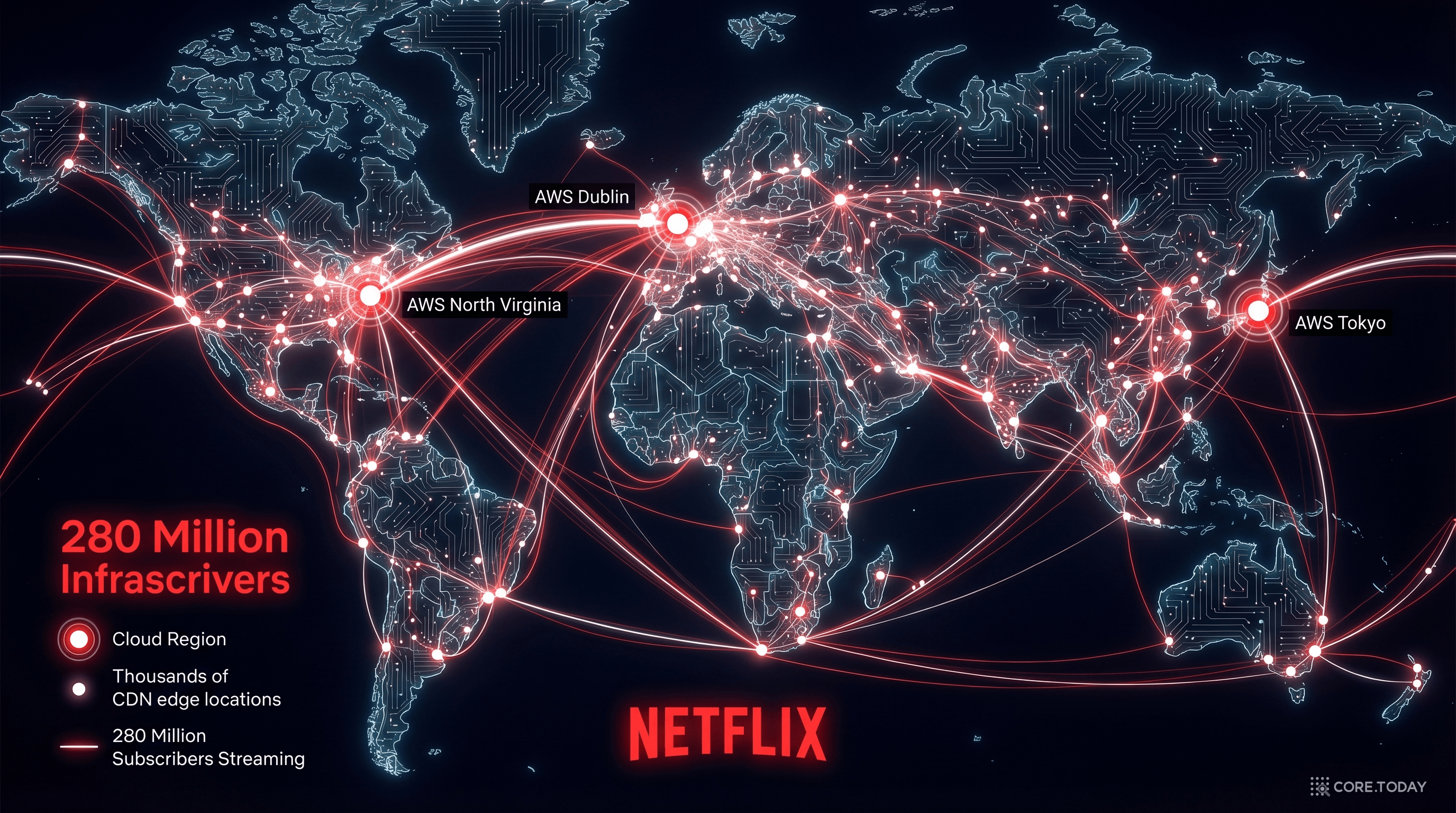
제6장: 실전 사례 — 클라우드 위에서 돌아가는 DX
Netflix: 2.8억 구독자의 인프라
Netflix의 클라우드 여정은 전설적이다. 2008년 자체 데이터센터에서 대규모 장애가 발생한 후, Netflix는 7년에 걸쳐 100% AWS로 마이그레이션했다 (2016년 1월 완료).
구독자: 2.8억+ 명, 190개국
일일 스트리밍: 수억 시간/일
마이크로서비스: 1,000개+ (Spring Boot 기반)
CDN (Open Connect): 전 세계 19,000+ 서버. 전체 인터넷 트래픽의 ~15%
카오스 엔지니어링: Chaos Monkey — 운영 중인 서버를 무작위로 죽여서 시스템의 회복 탄력성 검증
Netflix가 클라우드 업계에 남긴 가장 큰 유산은 오픈소스다. Netflix OSS(Eureka, Zuul, Hystrix, Ribbon 등)는 마이크로서비스 아키텍처의 사실상 표준이 되었다. "클라우드에서 대규모 서비스를 어떻게 운영하는가"의 교과서를 Netflix가 쓴 셈이다.
배달의민족(Baemin): 한국 푸드테크의 클라우드 네이티브
배달의민족은 한국에서 클라우드 네이티브 아키텍처를 가장 적극적으로 도입한 기업 중 하나다:
배달의민족 클라우드 아키텍처 (공개 정보 기반)
AWS 기반
100% 퍼블릭 클라우드. 자체 데이터센터 없음.
마이크로서비스
주문, 결제, 배달, 가맹점 — 수백 개 서비스로 분리.
이벤트 드리븐
Kafka 기반 비동기 메시징. 주문-결제-배달 이벤트 체인.
오토스케일링
점심/저녁 피크 시 자동 확장. 평시 대비 3~5배 트래픽 처리.
Zero-Downtime 배포
Blue-Green / Canary 배포. 24/7 서비스 중단 없이 업데이트.
배달의민족의 기술 블로그에서 반복적으로 강조하는 메시지: "치킨 한 마리 주문에 관여하는 시스템이 수십 개다. 이 수십 개의 시스템이 밀리초 단위로 협업해야 한다." 이것이 클라우드 네이티브 아키텍처 없이는 불가능한 일이다.
토스(Toss): 클라우드 네이티브 핀테크
비바리퍼블리카(토스)는 2015년 창업 때부터 AWS 100%로 시작한 클라우드 네이티브 기업이다:
2015
AWS 위에서 창업 — 간편 송금 서비스. 금융 스타트업이 자체 데이터센터를 구축할 여력이 없었다. 클라우드가 유일한 선택.
2019
MSA 전환 가속 — 서비스가 급성장하면서 모놀리스 한계. Kubernetes 기반 마이크로서비스로 전면 전환.
2021
토스뱅크 출범 — 인터넷 전문 은행. 100% 클라우드 기반 은행. 자체 데이터센터 없는 은행의 탄생.
2026
월간 활성 사용자 2,300만+ — 금융, 증권, 보험, 결제를 하나의 슈퍼앱으로. 일 수천만 건 트랜잭션 처리.
토스의 교훈: 클라우드는 "비용 절감 도구"가 아니라 "속도의 무기"다. 2015년 토스가 자체 데이터센터를 구축하고 금융 보안 인증을 받으려 했다면, 서비스 출시까지 수년이 걸렸을 것이다. AWS 위에서 시작했기에 수 개월 만에 시장에 나갈 수 있었다.
쿠팡: 30개 도시, 100개+ 물류센터의 인프라
쿠팡은 자체 물류 + 클라우드 인프라의 결합 모델이다:
쿠팡의 "로켓배송"이 가능한 이유는 물류센터의 위치 최적화 알고리즘, 실시간 재고 관리 시스템, 배송 경로 최적화 — 이 모든 것이 클라우드 인프라 위에서 실시간으로 돌아가기 때문이다. 수백만 SKU의 수요 예측, 물류센터 간 재고 재배치, 배송 기사 동선 최적화는 막대한 컴퓨팅 파워를 요구하며, 이를 온프레미스로 처리하는 것은 현실적으로 불가능하다.
Capital One: 다시 한 번 — 은행의 완전한 변환
이 글의 서두에서 다룬 Capital One으로 돌아오자. 8개 데이터센터를 폐쇄한 후, Capital One은 무엇이 달라졌는가?
이전
데이터센터 시대
새로운 기능 배포까지 수 주~수 개월. 하드웨어 구매 프로세스, 보안 승인, 물리적 설치 필요. 인프라 팀이 병목.
전환
8년간의 마이그레이션
2012~2020년. 점진적 이전. 가장 덜 중요한 워크로드부터 시작해 핵심 뱅킹 시스템까지. 마지막 데이터센터 폐쇄.
이후
클라우드 네이티브 은행
배포 빈도 10배 이상 증가. 머신러닝 모델 실시간 배포. 사기 탐지 시간 밀리초 단위. 기술 인력 11,000명+ 확보.
Capital One은 현재 클라우드 기술 기업이 은행 면허를 가진 것이라고 스스로를 정의한다. "금융 기업이 클라우드를 도입한" 것이 아니라, "클라우드 네이티브 기업이 금융을 하는" 것. 이것이 DX의 완성형이다.
제7장: 2026년 트렌드 — 클라우드의 다음 전장
1. 멀티클라우드 / 하이브리드 클라우드
"하나의 클라우드에 올인하는 것은 위험하다"는 인식이 확산되면서, 멀티클라우드(Multi-Cloud) 전략이 주류가 되고 있다:
그러나 현실은 복잡하다. 멀티클라우드가 "벤더 락인을 피하겠다"는 이유만으로 도입되면, 오히려 복잡성과 비용이 증가한다. 각 클라우드의 네이티브 서비스를 포기하고 최소공통분모(Kubernetes 등)로 추상화하면, 각 클라우드의 강점을 활용하지 못한다. 전략적 멀티클라우드(예: AI 워크로드는 GCP, 엔터프라이즈 앱은 Azure, 범용 인프라는 AWS)가 더 현실적이다.
2. FinOps — 클라우드 비용 최적화
클라우드의 역설: "쓴 만큼만 내면 된다"는 약속이, 실제로는 "모르는 사이에 엄청나게 쓰고 있다"로 바뀌는 경우가 많다.
Flexera 2025 State of the Cloud Report에 따르면:
평균 클라우드 낭비율: 약 30%
기업이 지출하는 클라우드 비용의 약 30%가 낭비(미사용 리소스, 과잉 프로비저닝).
비용 최적화 = #1 클라우드 과제
7년 연속 기업의 최우선 클라우드 과제. "더 많이 쓰는 것"이 아니라 "똑똑하게 쓰는 것".
FinOps 채택률: 기업의 35%+
전담 FinOps 팀을 구성한 기업이 빠르게 증가. FinOps Foundation 인증 수요도 급증.
FinOps(Financial Operations)란 클라우드 비용을 엔지니어링, 재무, 비즈니스가 협력해 최적화하는 실천(practice)이다:
Inform
(가시성 확보)
→
Optimize
(비용 최적화)
→
Operate
(지속적 운영)
FinOps의 대표적 절감 기법:
- Reserved Instances / Savings Plans: 1~3년 약정으로 최대 72% 할인
- Spot Instances: 미사용 용량 활용, 최대 90% 할인 (중단 가능성 있음)
- Right-sizing: 과잉 프로비저닝된 인스턴스 크기를 실사용량에 맞게 축소
- 자동 종료: 개발/테스트 환경을 업무 시간 외에 자동 종료
3. 소버린 클라우드와 데이터 주권
EU의 GDPR, 한국의 개인정보 보호법, 중국의 데이터 보안법 — 각국의 데이터 규제가 강화되면서, "데이터가 어디에 저장되는가"가 핵심 이슈가 되었다.
소버린 클라우드(Sovereign Cloud)는 특정 국가/지역의 데이터 주권 요구사항을 충족하는 클라우드 서비스다. AWS, Azure, GCP 모두 소버린 클라우드 옵션을 제공하고 있으며, 유럽에서는 Gaia-X 프로젝트가 유럽 자체의 클라우드 인프라 표준을 수립 중이다.
한국에서는 클라우드 보안 인증제(CSAP)가 공공기관 클라우드 도입의 필수 조건이다. NCP, KT Cloud 등 국내 사업자들이 이 인증을 기반으로 공공 클라우드 시장에서 경쟁 우위를 확보하고 있다.
4. AI 인프라: GPU-as-a-Service
2023년 이후 GenAI 붐으로 GPU 수요가 폭발했다. 클라우드에서의 AI 인프라 트렌드:
| 서비스 | 제공사 | 핵심 GPU | 특징 |
|---|
| AWS P5/P6 | AWS | NVIDIA H100/H200, GB200 | SageMaker, Bedrock 연계 |
| Azure ND H100 | Microsoft | NVIDIA H100, GB200 | OpenAI 모델 독점 호스팅 |
| GCP A3 | Google | NVIDIA H100, TPU v5p | 자체 TPU + NVIDIA 병행 |
| DGX Cloud | NVIDIA | DGX H100/GB200 | NVIDIA 직접 제공 GPU 클라우드 |
| CoreWeave | CoreWeave | NVIDIA 전 제품군 | GPU 특화 클라우드. AI 스타트업 선호. |
NVIDIA의 DGX Cloud는 특히 주목할 만하다. GPU 칩 제조사가 클라우드 서비스를 직접 제공하는 것이다. 이는 "GPU가 곧 플랫폼"이 되는 시대의 도래를 의미한다.
5. 그린 클라우드 / 지속 가능성
클라우드 데이터센터의 전력 소비는 전 세계 전력의 약 2~3%를 차지한다. AI 붐으로 이 비율은 계속 상승 중이다.
AWS
2025년 100% 재생에너지 목표 달성 선언. Customer Carbon Footprint Tool 제공.
Google
24/7 탄소 제로 에너지 2030년 목표. 모든 데이터센터에서 시간 단위 탄소 제로 운영.
Microsoft
2030년 탄소 네거티브 선언. 2050년까지 설립 이후 배출한 모든 탄소 회수 목표.
DX 관점에서 그린 클라우드의 의미: 기업이 자체 데이터센터를 운영하는 것보다 퍼블릭 클라우드를 사용하는 것이 탄소 발자국을 최대 88% 줄일 수 있다(451 Research 보고서). 클라우드 전환은 비용 절감뿐 아니라 ESG 목표 달성에도 기여한다.
6. 엣지 컴퓨팅 + 5G
모든 것을 중앙 클라우드에서 처리할 수 없는 영역이 있다. 자율주행차의 긴급 제동 판단에 100ms 지연은 치명적이다. 공장의 실시간 품질 검사에 클라우드 왕복 시간은 너무 길다.
엣지 컴퓨팅(Edge Computing)은 데이터가 생성되는 곳(엣지)에서 바로 처리하는 패러다임이다:
디바이스
(센서, 카메라, 차량)
→
엣지 노드
(밀리초 지연, 실시간 처리)
→
클라우드
(분석, 학습, 저장)
2026년 글로벌 엣지 컴퓨팅 시장은 약 $7,100억(약 990조 원) 규모로 추정된다. 5G의 초저지연(1ms 이하) 특성과 결합하면, 엣지 컴퓨팅은 스마트 팩토리, 자율주행, AR/VR, 원격 의료 등 새로운 DX 영역을 열어준다.
AWS의 Outposts(미니 AWS를 고객 사이트에 설치), Wavelength(5G 통신사 네트워크 안에 AWS 배치), Local Zones(도시 단위 미니 리전)는 모두 엣지 전략의 일환이다.
나가며: "서버를 만들지 마라, 서비스를 운영하라"
1999년 Salesforce의 "No Software"부터 2026년 AI-as-a-Service까지, 클라우드의 27년 역사는 하나의 방향을 가리킨다:
기업이 직접 관리하는 인프라의 범위는 계속 줄어들고, 비즈니스 로직에 집중할 수 있는 영역은 계속 넓어진다.
Capital One은 8개 데이터센터를 폐쇄하고 100% 클라우드로 전환했다. Netflix는 2.8억 구독자의 스트리밍을 AWS 위에서 운영한다. 토스는 창업 첫날부터 클라우드 위에서 은행을 만들었다. 배달의민족은 점심 피크 시 수백만 건의 주문을 클라우드 오토스케일링으로 처리한다.
이들의 공통점:
1. 서버를 "소유"하지 마라, "소비"하라
하드웨어 구매, 데이터센터 임대, OS 설치 — 이것은 당신의 핵심 역량이 아니다. 클라우드에 위임하라.
2. 고정 비용을 변동 비용으로 전환하라
수억 원의 서버 구매(CapEx) 대신, 사용한 만큼 지불(OpEx). 실패의 비용이 낮아지면 실험의 속도가 빨라진다.
3. 글로벌을 기본값으로 설계하라
34개 리전, 100개 AZ, 수백 개 엣지 로케이션. 첫날부터 글로벌 아키텍처가 가능하다. "나중에 해외 진출할 때" 가 아니라 "처음부터".
DX는 거의 100% 클라우드 위에서 돌아간다. "서버를 만든다"에서 "서비스를 운영한다"로의 사고 전환 — 이것이 DX 전문가의 여섯 번째 기둥이다.
다음 편에서는 클라우드 위에 올린 시스템을 지속적으로 개선하고 안정적으로 운영하는 기술 — DX의 일곱 번째 축, "자동화 & 운영(DevOps, CI/CD, SRE)"을 다룬다.
참고 자료
- Capital One, "Capital One Completes Migration to the Cloud" (2020)
- Marc Benioff, Behind the Cloud (Jossey-Bass, 2009)
- Werner Vogels, "All Things Distributed" — AWS Architecture Blog
- Synergy Research Group, "Cloud Infrastructure Services Q4 2025" (2026)
- Flexera, "2025 State of the Cloud Report" (2025)
- CNCF, "Cloud Native Survey 2025" (2025)
- Netflix Tech Blog, "Completing the Netflix Cloud Migration" (2016)
- 우아한형제들 기술 블로그 (techblog.woowahan.com)
- 토스 기술 블로그 (toss.tech)
- Gartner, "Forecast: Public Cloud Services, Worldwide" (2025~2026)
- 451 Research / S&P Global, "The Carbon Reduction Opportunity of Moving to the Cloud" (2024)
- FinOps Foundation, "State of FinOps Report" (2025)