들어가며: 2009년 6월 23일, Velocity 컨퍼런스의 10분
2009년 6월 23일, 캘리포니아 새너제이에서 열린 O'Reilly Velocity 컨퍼런스. Flickr의 엔지니어 John Allspaw와 Paul Hammond가 무대에 올랐다. 발표 제목은 단순했다:
"10+ Deploys Per Day: Dev and Ops Cooperation at Flickr"
당시의 상식으로는 충격적인 주장이었다. 대부분의 기업은 분기에 한 번, 잘해야 월 1회 배포를 했다. 배포 전날은 개발팀과 운영팀이 밤을 새웠고, 배포 당일은 "아무것도 건드리지 마라"가 불문율이었다. 그런데 Flickr는 하루에 10번 이상 배포한다고?
Allspaw와 Hammond의 핵심 메시지는 이것이었다:
🎯
"변경이 두렵다면, 더 자주 변경하라." 배포를 어렵게 만드는 것은 코드의 양이 아니라 Dev와 Ops 사이의 벽이다. 자동화된 인프라, 공유된 버전 관리, 자동화된 모니터링 — 이 세 가지가 갖춰지면 배포는 이벤트가 아니라 일상이 된다.
이 발표 이후 4개월 뒤인 2009년 10월, 벨기에 겐트에서 Patrick Debois가 첫 번째 DevOpsDays 컨퍼런스를 개최했다. Debois는 Allspaw의 발표를 보고 "이것이 바로 내가 말하려던 것"이라고 느꼈다. 트위터 해시태그 #DevOps가 생겨났고, 소프트웨어 역사에서 가장 영향력 있는 운동 중 하나가 시작됐다.
DX(디지털 전환)에서 자동화와 운영은 왜 중요한가? AI 모델을 만들고, 클라우드 인프라를 세팅하고, 멋진 시스템을 설계했다 — 그런데 그것이 매일 안정적으로 돌아가야 비로소 가치가 생긴다. DX는 "한 번 만들고 끝"이 아니라 "계속 돌아가야" 한다.
제1장: DevOps의 역사와 철학
"벽(The Wall)" — Dev와 Ops의 오래된 갈등
전통적 소프트웨어 개발에서 개발(Development)팀과 운영(Operations)팀은 근본적으로 다른 인센티브를 가졌다.
| 구분 | 개발팀 (Dev) | 운영팀 (Ops) |
|---|
| 목표 | 새 기능을 빠르게 출시 | 시스템 안정성 유지 |
| 변경에 대한 태도 | 변경 = 가치 창출 | 변경 = 리스크 |
| 성공 지표 | 기능 출시 속도 | 가동시간 (Uptime) |
| 도구 | IDE, Git, 빌드 도구 | 서버 콘솔, 모니터링 대시보드 |
| 전형적 문구 | "내 컴퓨터에선 되는데?" | "왜 금요일에 배포하는 건데?" |
이 구조적 갈등은 "The Wall of Confusion" 이라 불렸다. 개발팀이 코드를 "벽 너머로 던지면" 운영팀이 받아서 서버에 올린다. 문제가 생기면 서로를 탓했다. 배포는 수개월에 한 번, 긴장 속에 진행됐고, 실패하면 롤백에 며칠이 걸렸다.
DevOps의 탄생과 CALMS 프레임워크
2009년 DevOpsDays 이후, DevOps의 철학은 구체적 프레임워크로 발전했다. Jez Humble과 John Willis가 체계화한 CALMS는 DevOps의 다섯 기둥이다:
Culture
비난 없는 문화. 실패는 학습의 기회. Dev와 Ops가 하나의 팀.
Automation
수동 작업을 자동화. CI/CD, IaC, 자동화된 테스트.
Lean
낭비 제거. 작은 배치. 빠른 피드백 루프. WIP 제한.
Measurement
모든 것을 측정. DORA 메트릭. 데이터 기반 개선.
Sharing
지식과 책임의 공유. 포스트모템. 투명한 커뮤니케이션.
2013년: The Phoenix Project — DevOps의 대중화
2013년, Gene Kim, Kevin Behr, George Spafford가 쓴 소설 《The Phoenix Project》 가 출간됐다. IT 부서의 위기를 DevOps 원칙으로 해결하는 이야기를 소설 형식으로 풀어냈다. 이 책은 DevOps를 기술자들만의 운동에서 경영진이 이해하는 비즈니스 전략으로 격상시켰다. 주인공 Bill Palmer가 공장의 제조 라인에서 Three Ways(흐름, 피드백, 지속적 학습)를 발견하는 서사가 핵심이다.
First Way
흐름(Flow) — Dev에서 Ops로의 작업 흐름을 가속한다. 작은 배치, 자동화, WIP 제한.
Second Way
피드백(Feedback) — Ops에서 Dev로의 피드백을 빠르게 한다. 모니터링, 알림, A/B 테스트.
Third Way
지속적 학습(Continual Learning) — 실험 문화. 실패에서 배운다. 비난 없는 포스트모템.
DORA 메트릭: DevOps를 숫자로 측정하다
2014년부터 시작된 Accelerate State of DevOps Report(Google Cloud의 DORA 팀)는 DevOps 역량을 과학적으로 측정하는 프레임워크를 확립했다. 4가지 핵심 메트릭:
| 메트릭 | Elite | High | Low |
|---|
| 배포 빈도 (Deployment Frequency) | 온디맨드 (하루 수회) | 주 1회 ~ 월 1회 | 월 1회 ~ 반기 1회 |
| 변경 리드 타임 (Lead Time for Changes) | 1시간 미만 | 1일 ~ 1주 | 1개월 ~ 6개월 |
| 변경 실패율 (Change Failure Rate) | 5% 미만 | 10~15% | 46~60% |
| 복구 시간 (MTTR) | 1시간 미만 | 1일 미만 | 1주 ~ 1개월 |
DORA의 2023 보고서에 따르면, Elite 수준의 팀은 Low 수준 대비 배포 빈도 973배, 리드 타임 6,570배, 복구 시간 6,570배 빠르다. 그리고 놀라운 사실 — 속도와 안정성은 트레이드오프가 아니다. 빠르게 배포하는 팀이 오히려 장애도 적고, 복구도 빠르다.
제2장: CI/CD — 코드에서 프로덕션까지의 파이프라인
CI(Continuous Integration)의 역사
CI(지속적 통합) 의 개념은 1991년 Grady Booch가 처음 제안했고, 2000년대 Kent Beck의 eXtreme Programming(XP)이 널리 알렸다. 핵심 원칙은 단순하다: 모든 개발자가 매일 여러 번 코드를 통합하고, 자동화된 빌드와 테스트로 즉시 검증한다.
2001
CruiseControl — ThoughtWorks가 만든 최초의 CI 서버. Martin Fowler가 "Continuous Integration" 개념 정립.
2005
Hudson → Jenkins — Sun Microsystems의 Kohsuke Kawaguchi가 개발. 2011년 Oracle과의 분쟁으로 Jenkins로 포크. 플러그인 생태계 1,800개+.
2011
Travis CI — GitHub 연동 SaaS CI의 시작. 오픈소스 프로젝트를 위한 무료 CI가 생태계를 바꿈.
2017
GitLab CI/CD — 소스 코드 관리와 CI/CD를 하나의 플랫폼에 통합. DevSecOps 개념 도입.
2019
GitHub Actions — YAML 기반 워크플로우. 마켓플레이스에 20,000개+ 액션. 사실상의 표준으로 자리잡음.
CD(Continuous Delivery/Deployment)의 진화
CI가 "코드를 통합하고 테스트하는 것"이라면, CD는 "검증된 코드를 프로덕션에 안전하게 내보내는 것" 이다. Continuous Delivery(지속적 전달)와 Continuous Deployment(지속적 배포)는 미묘하게 다르다:
🔴
전통적 배포
개발 완료 → QA 팀에 전달 → 수주간 테스트 → 변경 관리 위원회(CAB) 승인 → 심야 배포 → 기도. 배포 간격: 3~6개월. 롤백 시간: 수일.
🟡
Continuous Delivery
모든 커밋이 자동으로 빌드·테스트·스테이징 배포. 프로덕션 배포는 버튼 한 번으로 가능한 상태를 항상 유지. 배포 "결정"은 사람이 하지만, 과정은 자동.
🟢
Continuous Deployment
모든 커밋이 자동으로 프로덕션까지 배포. 사람의 개입 없이 코드가 사용자에게 도달. 자동화된 품질 게이트(테스트, 카나리 분석, 자동 롤백)가 사람을 대신.
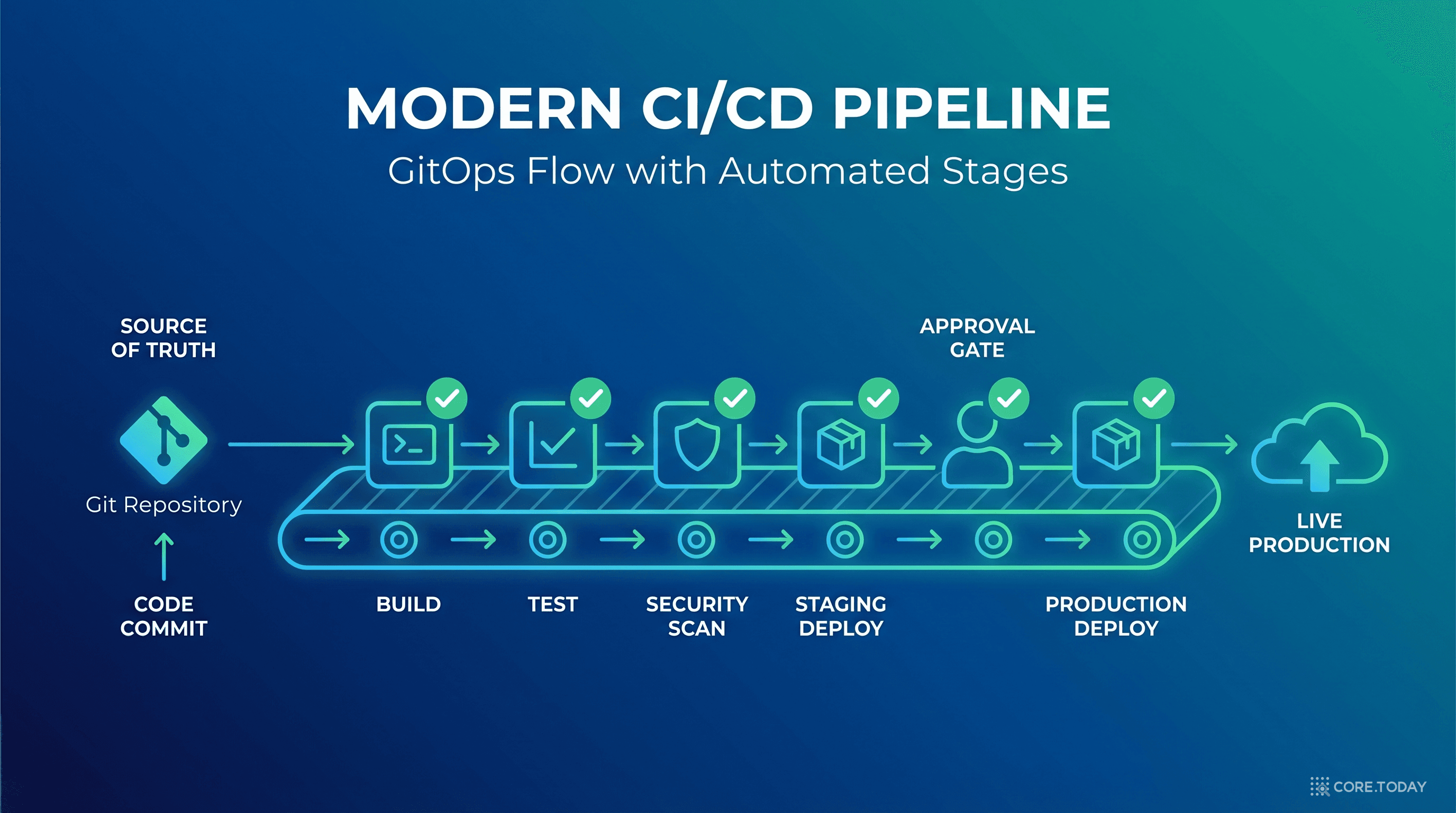
현대 CI/CD 파이프라인의 구조
Code
Git Push
→
Build
컴파일, 의존성
→
Test
Unit, Integration
→
Security
SAST, SCA
↓
Production
카나리 배포
←
Approval
자동/수동 게이트
←
Staging
E2E 테스트
GitOps: Git을 진실의 원천(Single Source of Truth)으로
2017년 Weaveworks의 Alexis Richardson이 GitOps 개념을 제안했다. 핵심 원리는 명확하다: 인프라와 애플리케이션의 원하는 상태(Desired State)를 Git 저장소에 선언적으로 정의하고, 자동화된 에이전트가 실제 상태를 Git의 상태와 일치시킨다.
| 항목 | 전통적 CI/CD (Push) | GitOps (Pull) |
|---|
| 배포 트리거 | CI 서버가 클러스터에 Push | 클러스터 에이전트가 Git을 감시하여 Pull |
| 진실의 원천 | CI 파이프라인 스크립트 | Git 저장소 (선언적 매니페스트) |
| 감사(Audit) | CI 로그 확인 필요 | Git 히스토리가 곧 감사 로그 |
| 롤백 | 별도 롤백 스크립트 실행 | git revert → 자동 반영 |
| 대표 도구 | Jenkins, GitHub Actions | ArgoCD, Flux |
ArgoCD는 GitOps의 대표 도구다. CNCF Graduated 프로젝트로, Kubernetes 클러스터의 상태를 Git 저장소와 자동으로 동기화한다. Intuit에서 시작하여 2024년 기준 GitHub 스타 18,000개 이상, 월간 다운로드 100만+를 기록한다.

제3장: 모니터링과 관찰가능성(Observability)
Monitoring vs Observability
"모니터링"과 "관찰가능성"은 자주 혼동되지만 근본적으로 다른 개념이다.
| 구분 | 모니터링 (Monitoring) | 관찰가능성 (Observability) |
|---|
| 질문 | "알고 있는 문제가 발생했는가?" | "예상하지 못한 문제를 탐색할 수 있는가?" |
| 접근 | 미리 정의한 대시보드와 알림 | 임의의 질문에 답할 수 있는 데이터 |
| 비유 | 자동차 계기판 — 속도, 연료, 엔진 경고등 | 자동차 OBD 포트 — 아무 센서든 조회 가능 |
| 시대 | 모놀리식 시스템 | 마이크로서비스, 분산 시스템 |
Charity Majors(Honeycomb CEO)의 정의가 가장 명확하다: "Observability is about being able to ask arbitrary questions about your production environment without having to deploy new code." — 새 코드를 배포하지 않고도 프로덕션 환경에 아무 질문이나 할 수 있는 능력.
관찰가능성의 세 기둥 (Three Pillars)
Logs (로그)
이산적 이벤트
"무엇이 일어났는가?"에 대한 기록. 구조화된 JSON 로그가 표준. ELK Stack(Elasticsearch, Logstash, Kibana)이 대표 도구.
Metrics (메트릭)
시계열 수치
"시스템이 어떤 상태인가?"에 대한 숫자. CPU 사용률, 요청 지연시간, 에러율. Prometheus + Grafana가 사실상 표준.
Traces (트레이스)
요청의 여정
"요청이 어디서 느려졌는가?" 분산 시스템에서 하나의 요청이 거치는 모든 서비스를 추적. Jaeger, Zipkin, OpenTelemetry.
관찰가능성 도구 생태계
관찰가능성 도구 시장점유율 (2025년, Gartner 기준 추정)
OpenTelemetry는 특별히 주목해야 한다. CNCF에서 Kubernetes 다음으로 활발한 프로젝트로, 로그·메트릭·트레이스를 수집하는 통일된 표준을 제공한다. 2024년 기준 11,000명 이상의 기여자, 180개 이상의 수신기(Receiver)를 지원하며, 벤더 종속 없이 관찰가능성 데이터를 수집할 수 있다.
SRE: 구글이 만든 운영의 과학
2003년 구글의 VP of Engineering Ben Treynor Sloss가 "Site Reliability Engineering"이라는 직군을 만들었다. 그의 유명한 정의:
"SRE is what happens when a software engineer is tasked with what used to be called operations."
2016년 구글은 《Site Reliability Engineering》 책을 무료로 공개했다. 이 책은 운영을 "소프트웨어 엔지니어링 문제"로 재정의했다. 핵심 개념 세 가지:
SLI
Service Level Indicator — 서비스 품질을 측정하는 구체적 지표. 예: "요청의 99%가 200ms 이내에 응답". 측정 가능하고 의미 있는 숫자.
SLO
Service Level Objective — SLI의 목표값. 예: "월간 가용성 99.95%". 이 목표가 에러 버짓(Error Budget)을 결정한다. 99.95%면 월 21.6분의 다운타임이 "허용"된다.
SLA
Service Level Agreement — 고객과의 법적 계약. SLO를 못 지키면 크레딧 환불 등 보상이 따른다. AWS EC2 SLA: 월간 가용성 99.99% 미달 시 10~30% 크레딧.
에러 버짓(Error Budget)의 혁신
에러 버짓은 SRE에서 가장 혁신적인 개념이다. "100% 가용성은 목표가 아니다" 라는 전제에서 시작한다.
SLO: 99.95% 가용성 (월간)
총 분: 30일 × 24시간 × 60분 = 43,200분
허용 다운타임: 43,200 × 0.0005 = 21.6분/월
에러 버짓이 남아 있으면 → 새 기능 배포, 실험 가능
에러 버짓을 소진하면 → 배포 동결, 안정성 작업에 집중
→ 속도 vs 안정성의 객관적 균형점
에러 버짓은 Dev와 Ops의 오래된 갈등을 해결한다. "더 빠르게 배포하자" vs "안정성이 먼저다"의 논쟁이 데이터 기반 의사결정으로 바뀐다.
제4장: MLOps — AI 모델의 운영
"모델을 만드는 것"과 "모델을 운영하는 것"은 완전히 다르다
2015년 구글은 논문 "Hidden Technical Debt in Machine Learning Systems" 을 발표했다. 이 논문의 가장 유명한 그림은 ML 시스템의 구조를 보여주는 다이어그램이다. ML 코드(모델 학습 코드)는 전체 시스템의 5% 미만이고, 나머지 95%는 데이터 수집, 검증, 특성 추출, 서빙 인프라, 모니터링으로 이루어진다.
ML 시스템의 실제 구성 (Google, 2015)
특성 추출 (Feature Engineering)
Gartner의 2022년 보고서에 따르면 ML 프로젝트의 85%가 프로덕션에 도달하지 못한다. 모델이 나쁘거나 데이터가 부족해서가 아니다. 모델을 안정적으로 배포하고, 모니터링하고, 업데이트하는 운영 파이프라인이 없기 때문이다.
모델 드리프트(Model Drift): AI 모델은 썩는다
전통 소프트웨어와 ML 시스템의 결정적 차이: 모델은 시간이 지나면 성능이 떨어진다. 코드에 버그가 생긴 것이 아니라, 세상이 변했기 때문이다.
| 드리프트 유형 | 원인 | 예시 | 대응 |
|---|
| 데이터 드리프트 (Data Drift) | 입력 데이터의 분포 변화 | 코로나19로 소비 패턴 급변 → 추천 모델 무용지물 | 입력 분포 모니터링, 자동 재학습 트리거 |
| 개념 드리프트 (Concept Drift) | 입력-출력 관계 자체가 변화 | 부동산 가격 예측 — 금리 정책 변경으로 관계가 바뀜 | 성능 메트릭 모니터링, 모델 재학습 주기 단축 |
| 피처 드리프트 (Feature Drift) | 특정 특성(Feature)의 의미 변화 | "평균 주문 금액" 피처 — 할인 이벤트 시 왜곡 | 피처 스토어 검증, 이상치 탐지 |
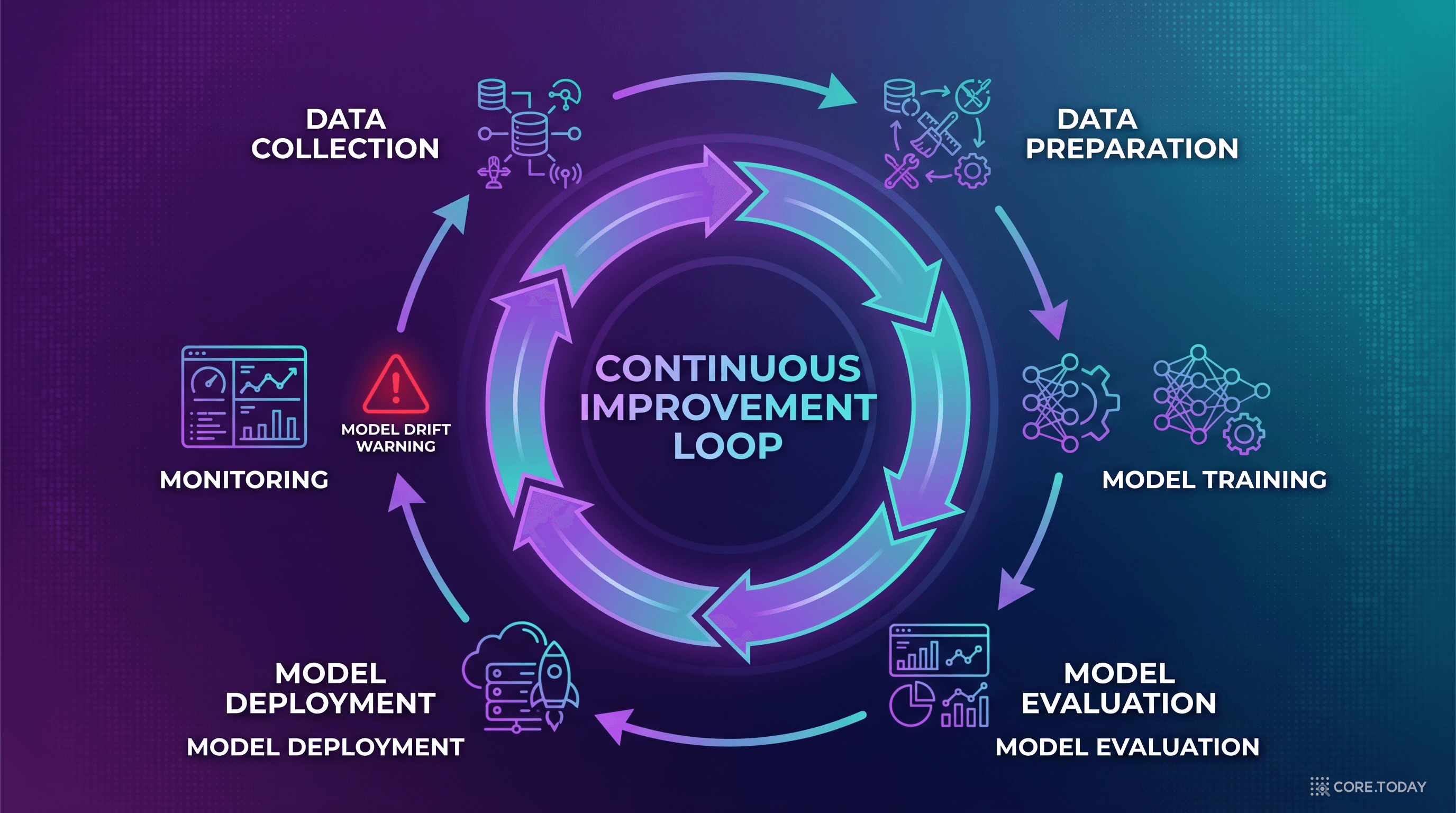
MLOps 파이프라인의 구조
데이터 수집
Feature Store
→
학습
실험 추적
→
검증
모델 평가
→
레지스트리
모델 버전 관리
↓
재학습 트리거
드리프트 감지
←
모니터링
성능/드리프트
←
서빙
A/B, 카나리
MLOps 도구 생태계
| 영역 | 도구 | 특징 |
|---|
| 실험 추적 | MLflow, Weights & Biases | 하이퍼파라미터, 메트릭, 모델 아티팩트 버전 관리 |
| 파이프라인 오케스트레이션 | Kubeflow, Apache Airflow | 학습-평가-배포 파이프라인 자동화 |
| 피처 스토어 | Feast, Tecton, Hopsworks | ML 피처의 저장·공유·서빙. 학습-서빙 불일치 방지 |
| 모델 서빙 | TensorFlow Serving, Triton, vLLM | 실시간 추론 API. vLLM은 LLM 전용 고속 서빙 |
| 통합 플랫폼 | Vertex AI, SageMaker, Azure ML | 클라우드 네이티브 엔드투엔드 MLOps |
MLflow는 특히 주목할 만하다. Databricks에서 시작한 오픈소스로, 2024년 5월 Apache Software Foundation의 인큐베이팅 프로젝트로 선정됐고, GitHub 스타 19,000개 이상을 기록한다. 실험 추적, 모델 레지스트리, 배포를 하나의 도구로 통합한다.
제5장: DataOps — 데이터 파이프라인의 운영
데이터도 "운영"이 필요하다
DevOps가 소프트웨어 배포를 혁신했듯, DataOps는 데이터 파이프라인의 운영을 혁신한다. IBM의 조사에 따르면 데이터 과학자는 업무 시간의 80%를 데이터 수집·정제에 소비한다. 모델링과 분석에는 고작 20%만 쓴다.
🔴
문제: "데이터가 맞는 건가요?"
대시보드의 숫자가 이상하다. 매출이 갑자기 두 배로 뛴다. 조회해보니 결제 시스템 변경으로 중복 레코드가 들어온 것. 아무도 모르고 경영진에게 잘못된 숫자가 보고된다. 데이터 품질 문제는 비즈니스 의사결정을 오염시킨다.
🟡
해결: DataOps 파이프라인
데이터 품질 검증을 파이프라인에 내장. 스키마 변경 자동 감지. 이상치(anomaly) 알림. 데이터에도 CI/CD를 적용하여 변경 이력 추적과 자동 테스트를 수행한다.
🟢
결과: 데이터 신뢰성 확보
"이 숫자가 맞습니까?"라는 질문이 사라진다. 데이터 계약(Data Contract)으로 생산자와 소비자 간 합의가 명확해진다. 데이터 엔지니어는 소방관이 아니라 설계자가 된다.
DataOps의 핵심 구성요소
데이터 품질
스키마 검증, 이상치 탐지, 완결성 검사. Great Expectations, Soda Core.
데이터 계약
생산자-소비자 간 합의. 스키마, SLA, 소유권 명시. API처럼 데이터에도 계약이 필요하다.
데이터 리니지
데이터의 출처와 변환 과정 추적. "이 대시보드 숫자는 어디서 온 것인가?"에 답한다.
ETL에서 ELT로, 배치에서 스트리밍으로
| 세대 | 패턴 | 대표 도구 | 특징 |
|---|
| 1세대 | ETL (Extract-Transform-Load) | Informatica, Talend | 데이터 웨어하우스에 넣기 전에 변환. 배치 중심. |
| 2세대 | ELT (Extract-Load-Transform) | dbt, Fivetran, Airbyte | 먼저 적재하고 웨어하우스 안에서 변환. 클라우드 컴퓨팅의 유연성 활용. |
| 3세대 | 실시간 스트리밍 | Apache Kafka, Flink, Debezium | 이벤트 발생 즉시 처리. CDC(Change Data Capture)로 실시간 동기화. |
dbt(data build tool) 는 DataOps의 상징이다. 2016년 Fishtown Analytics(현 dbt Labs)가 만들었고, "데이터 변환에 소프트웨어 엔지니어링 모범 사례를 적용한다"는 철학을 실현했다. SQL에 버전 관리, 테스트, 문서화, CI/CD를 적용한다. 2025년 기준 dbt Cloud 사용 조직 수는 4만 개 이상이다.
Monte Carlo는 "데이터 관찰가능성(Data Observability)"이라는 카테고리를 개척했다. 데이터 파이프라인의 Datadog이라고 볼 수 있다. 데이터 이상(freshness, volume, schema, distribution, lineage)을 자동으로 감지하고 알린다.
제6장: 실전 사례
Netflix: 하루 수천 번 배포의 비밀
Netflix는 DevOps와 CI/CD의 교과서적 사례다. 2012년 Netflix는 자체 배포 플랫폼 Spinnaker를 구축했고, 2015년 이를 오픈소스로 공개했다. 핵심 수치:
Netflix 엔지니어링 지표 (2024년 기준)
Netflix의 철학: "배포가 무섭다면, 더 자주 배포하라." 배포 한 번의 변경량을 극도로 작게 만들어, 문제가 생기면 즉시 롤백한다. 자동화된 카나리 분석(Kayenta)이 새 버전의 메트릭을 기존 버전과 비교하여 이상이 감지되면 자동으로 롤백한다.
Spotify Backstage: 개발자 포털의 표준
2020년 Spotify는 Backstage를 오픈소스로 공개했다. 내부적으로 "내가 쓰는 서비스가 뭔지, 누가 담당하는지, 어떻게 배포하는지" — 이 질문에 한 곳에서 답하는 개발자 포털(Internal Developer Portal) 이다.
서비스 카탈로그
모든 서비스 목록
→
Backstage
통합 개발자 포털
→
소프트웨어 템플릿
신규 서비스 생성
↑
TechDocs
문서 자동 생성
→
플러그인 생태계
Kubernetes, CI/CD, 비용
Backstage는 2022년 CNCF Incubating 프로젝트가 됐고, 2024년에 Graduated로 승격했다. 2025년 기준 2,900개 이상의 기업이 도입했으며, 100개 이상의 공식 플러그인이 존재한다. Spotify, Expedia, Netflix, IKEA 등이 사용한다.
Amazon: Two-Pizza Teams의 DevOps
Jeff Bezos의 유명한 원칙: "피자 두 판으로 먹일 수 없는 팀은 너무 큰 것이다." 이 원칙은 DevOps의 핵심 — 소규모 팀이 서비스를 처음부터 끝까지 소유한다 — 와 정확히 일치한다.
Amazon의 "You build it, you run it" 철학은 Werner Vogels(CTO)가 2006년에 명시화했다. 개발자가 서비스를 만들면 운영도 그 팀의 책임이다. 별도의 운영팀에 "넘기는" 것이 아니다. 이 구조가 Amazon이 연간 1억 5천만 건 이상의 배포를 가능하게 하는 기반이다.
한국 사례: 카카오와 네이버의 SRE
카카오는 2019년부터 SRE 조직을 운영하고 있다. 2022년 판교 데이터센터 화재 이후, SRE 역량 강화에 대규모 투자를 진행했다. 이중화 인프라, 자동 페일오버, 장애 대응 프로세스를 체계화했다. 카카오의 기술 블로그에 따르면 MTTR(평균 복구 시간)을 80% 이상 단축하는 것을 목표로 했다.
네이버는 자체 SRE 플랫폼을 구축하여 수십 개의 서비스를 통합 모니터링한다. 특히 네이버 검색은 초당 수만 건의 쿼리를 처리하면서 99.99% 이상의 가용성을 유지한다. 2023년부터 Chaos Engineering을 도입하여 의도적으로 장애를 주입하고, 시스템의 회복력을 검증하는 문화를 구축하고 있다.
Etsy: 지속적 배포의 선구자
Etsy는 2010년대 초반 "Just Ship It" 문화로 유명했다. 신입 엔지니어의 첫 업무가 "입사 첫날 프로덕션에 코드 배포하기"였다. 이를 가능하게 한 것은:
Deployinator
자체 개발한 원클릭 배포 도구. 개발자 누구나 즉시 배포 가능. 일일 평균 50회 이상 배포.
Feature Flags
배포와 릴리스를 분리. 코드는 프로덕션에 있지만, 기능은 플래그로 제어. 문제 시 코드 롤백 없이 플래그만 끈다.
Blameless Postmortem
장애가 나면 "누가 실수했나"가 아니라 "시스템이 왜 이것을 방지하지 못했나"를 묻는다. 비난 없는 포스트모템 문화.

제7장: 2026년 트렌드 — 운영의 미래
AIOps: AI가 운영을 돕는다
AIOps(AI for IT Operations) 는 Gartner가 2017년 처음 정의한 개념이다. ML을 활용해 IT 운영 데이터를 분석하고, 이상 탐지·근본 원인 분석·자동 해결을 수행한다.
감지 (Detect)
이상 탐지 AI가 메트릭·로그·트레이스에서 비정상 패턴을 실시간 감지. 수천 개의 알림을 상관분석하여 중복을 제거하고, 핵심 이벤트만 추출.
↓
분석 (Analyze)
근본 원인 분석(RCA) AI가 토폴로지 그래프와 히스토리 데이터를 기반으로 장애 원인을 추론. "이 에러는 3주 전 배포 B-4521과 상관관계가 있습니다."
↓
대응 (Act)
자동 복구(Auto-remediation) — 스케일아웃, 서비스 재시작, 트래픽 리디렉션을 자동 실행. 사람의 승인이 필요한 경우에만 운영자에게 에스컬레이션.
Gartner는 2026년까지 대기업의 40%가 AIOps 플랫폼을 도입할 것으로 전망한다. Dynatrace의 Davis AI, Datadog의 Watchdog, PagerDuty의 AIOps가 대표적이다.
Platform Engineering: 내부 개발자 플랫폼(IDP)
Platform Engineering은 2022년 Gartner가 "주목해야 할 기술 트렌드"로 선정한 이후 급부상했다. 핵심 아이디어: 인프라 복잡성을 추상화하여 개발자가 셀프서비스로 인프라를 사용하도록 한다.
🔴
문제: DevOps의 인지 과부하
DevOps는 "모든 개발자가 운영도 하라"고 했지만, 현실은 달랐다. Kubernetes YAML 수백 줄, Terraform 코드, CI/CD 파이프라인, 보안 설정 — 개발자에게 너무 많은 인지 부하를 줬다. 2023년 Puppet State of DevOps 보고서: 개발자의 60%가 "인프라 도구 학습에 너무 많은 시간을 소비"한다고 응답.
🟡
해결: Internal Developer Platform
플랫폼 엔지니어링 팀이 "골든 패스(Golden Path)" 를 만든다. 개발자는 "서비스 하나 만들어줘"라고 요청하면, 표준화된 인프라·CI/CD·모니터링이 자동으로 세팅된다. Backstage, Port, Humanitec이 대표 도구.
🟢
결과: 개발자 경험(DX) 향상
개발자는 코드 작성에 집중. 인프라는 플랫폼이 알아서 처리. McKinsey 분석: IDP 도입 기업은 개발자 생산성이 20~30% 향상. Gartner 예측: 2026년까지 대기업 80%가 플랫폼 엔지니어링 팀을 운영.
Chaos Engineering: 의도적으로 부수는 기술
Netflix가 2011년 공개한 Chaos Monkey에서 시작된 Chaos Engineering은 2026년 주류 관행으로 자리잡았다.
2011
Chaos Monkey — Netflix가 프로덕션에서 무작위로 서버를 종료. "서버가 죽어도 서비스는 살아야 한다"는 철학.
2014
Simian Army — Chaos Monkey, Latency Monkey, Conformity Monkey 등 다양한 장애 시나리오 도구 모음.
2017
Principles of Chaos Engineering — Netflix의 Casey Rosenthal 등이 Chaos Engineering의 원칙을 체계화.
2026
AI-Driven Chaos — AI가 시스템 토폴로지를 분석하여 가장 위험한 장애 시나리오를 자동 생성하고 실행.
Self-Healing Infrastructure: 자동 복구 인프라
전통적 인프라: 장애 감지 → 알림 → 당직 엔지니어 확인 → 수동 대응. Self-Healing 인프라: 장애 감지 → 자동 진단 → 자동 복구 → 사후 보고.
시나리오: 메모리 누수로 Pod 성능 저하
- 감지: Prometheus가 Pod 메모리 사용률 90% 초과 감지
- 진단: AI 에이전트가 과거 패턴 분석 → "v2.3.1 배포 이후 메모리 증가 패턴 일치"
- 즉시 대응: Kubernetes HPA가 새 Pod 자동 생성, 트래픽 분산
- 근본 대응: 자동 롤백 → v2.3.0으로 복귀, 관련 개발팀에 Jira 이슈 자동 생성
- 학습: 이 패턴을 학습하여 다음번 유사 배포 시 사전 경고
사람의 개입: 없음 (사후 보고만 확인)
2026년 운영 트렌드 종합
2026년 운영 기술 도입률 전망 (대기업 기준, Gartner/Forrester 종합)
마무리: DX는 계속 돌아가야 한다
이 글을 관통하는 하나의 질문:
"당신이 만든 시스템이 내일 새벽 3시에도 정상 작동한다고 확신하는가?"
DX 프로젝트의 진짜 어려운 부분은 시스템을 만드는 것이 아니라 그것을 매일, 매시간, 매초 안정적으로 운영하는 것이다.
2009년 Allspaw와 Hammond가 Flickr에서 보여준 것은 단순한 배포 자동화가 아니었다. Dev와 Ops의 벽을 허물면, 더 빠르게 그리고 더 안정적으로 서비스를 운영할 수 있다는 것이었다. 속도와 안정성이 트레이드오프가 아니라는 DORA 팀의 10년간의 데이터가 이를 증명한다.
DX 전문가가 자동화와 운영에서 갖추어야 할 역량을 정리하면:
CI/CD 설계
파이프라인 설계, 배포 전략(카나리/블루-그린), 자동화된 품질 게이트 구축
관찰가능성
SLI/SLO 정의, 에러 버짓 운영, 로그·메트릭·트레이스 통합 모니터링 체계 구축
MLOps/DataOps
모델 드리프트 감지, 데이터 품질 자동 검증, 재학습 파이프라인 운영
"한 번 만들고 끝"이 아니라, "계속 돌아가게 만드는 것" — 그것이 DX 자동화와 운영의 본질이다.
다음 편에서는 시스템이 돌아가는 것 너머, 그 시스템을 사람이 쓰는 경험 — UX/사용자 경험 설계를 다룬다.
참고 자료
- John Allspaw & Paul Hammond, "10+ Deploys Per Day: Dev and Ops Cooperation at Flickr" (Velocity Conference, 2009)
- Gene Kim, Kevin Behr, George Spafford, The Phoenix Project: A Novel About IT, DevOps, and Helping Your Business Win (IT Revolution Press, 2013)
- Google, "Site Reliability Engineering: How Google Runs Production Systems" (O'Reilly, 2016)
- DORA Team (Google Cloud), "Accelerate State of DevOps Report 2023" (2023)
- D. Sculley et al., "Hidden Technical Debt in Machine Learning Systems" (Google, NeurIPS 2015)
- Gartner, "Top Strategic Technology Trends 2023: Platform Engineering" (2022)
- Gartner, "Market Guide for AIOps Platforms" (2023)
- CNCF, "OpenTelemetry: The State of Cloud-Native Observability" (2024)
- Puppet, "2023 State of DevOps Report: Platform Engineering Edition" (2023)
- Netflix Tech Blog, "Full Cycle Developers at Netflix" (2018)
- Spotify Engineering, "Backstage: An Open Platform for Developer Portals" (2020)
- Charity Majors, "Observability Engineering" (O'Reilly, 2022)
- Casey Rosenthal & Nora Jones, "Chaos Engineering: System Resiliency in Practice" (O'Reilly, 2020)
- MLflow Documentation, "MLOps with MLflow" (mlflow.org, 2025)
- dbt Labs, "The dbt/Analytics Engineering Guide" (docs.getdbt.com, 2025)
- McKinsey Digital, "Developer Velocity: How Software Excellence Fuels Business Performance" (2023)
- 카카오 기술 블로그, "카카오 SRE 이야기" (tech.kakao.com)
- 네이버 D2 기술 블로그, "네이버 검색 SRE" (d2.naver.com)