들어가며: 매일 첫 출근하는 비서

당신에게 완벽한 비서가 생겼다고 상상해보자. 어떤 질문에도 즉시 답하고, 이메일을 대신 쓰고, 보고서를 순식간에 정리한다. 단 하나의 문제가 있다 — 매일 아침 기억이 리셋된다.
월요일에 "저는 채식주의자예요"라고 말했는데, 화요일 점심 추천에서 삼겹살 맛집이 나온다. 지난주에 부산으로 이사했다고 했는데, 이번 주에 "서울 날씨가 좋네요!"라고 인사한다. 전 직장에서 있었던 프로젝트를 설명했는데, 다음 대화에서 "그 프로젝트가 뭐였죠?"라고 되묻는다.
2026년 현재, 대부분의 AI 에이전트가 바로 이 상태다.
GPT-4의 컨텍스트 윈도우가 128K 토큰, Claude의 것이 200K 토큰까지 확장되었지만, 이것은 단기 기억(working memory)일 뿐이다. 대화가 끝나면 모든 것이 사라진다. 어제의 대화, 지난주의 맥락, 한 달 전의 약속 — 모두 날아간다.
2025년 1월, Zep 팀의 연구자들(Preston Rasmussen, Pavlo Paliychuk 등)이 이 문제에 대한 근본적인 해답을 제시했다. 논문 제목은 "Zep: A Temporal Knowledge Graph Architecture for Agent Memory" — 시간을 인식하는 지식 그래프로 AI 에이전트에게 진짜 기억을 만들어준다는 것이다.
결과는 놀라웠다. Deep Memory Retrieval 벤치마크에서 94.8%로 MemGPT(93.4%)를 넘었고, LongMemEval에서는 18.5% 정확도 향상에 90% 레이턴시 감소를 달성했다.
이 글에서는 이 논문이 왜 나오게 되었는지, 핵심 아키텍처를 해부하고, 2026년 AI 에이전트 생태계에서 어떤 의미를 갖는지까지 자세히 살펴본다.
제1장: AI 기억의 역사 — 금붕어에서 코끼리로
컨텍스트 윈도우라는 족쇄

LLM(Large Language Model)의 기억력은 컨텍스트 윈도우에 갇혀 있다. 2022년 GPT-3.5의 컨텍스트는 4K 토큰 — 한국어로 약 2,000자, A4 한 장 정도였다. 대화를 나누다 보면 금세 한계에 부딪혔다.
비유하자면, 컨텍스트 윈도우는 칠판이다. 새로운 내용을 적으려면 이전 내용을 지워야 한다. 칠판이 커지면(128K, 200K) 더 많이 적을 수 있지만, 결국 한계가 있다. 그리고 수업이 끝나면(대화 세션이 종료되면) 칠판은 깨끗하게 지워진다.
2022
GPT-3.5: 4K 토큰 (A4 1장)
2023
GPT-4: 8K → 32K → 128K 토큰
2024
Claude 3: 200K, Gemini: 1M 토큰
2025~
여전히 세션 끝나면 리셋 — 장기 기억 없음
RAG의 등장: 외장 하드 연결
2023년, RAG(Retrieval-Augmented Generation)가 이 한계를 돌파하려 했다. 핵심 아이디어는 단순했다: LLM에게 "외장 하드"를 달아주자.
- 문서를 작은 조각(chunk)으로 나눈다
- 각 조각을 벡터로 변환해 데이터베이스에 저장한다
- 질문이 들어오면, 관련 조각을 검색해 LLM에게 함께 전달한다
혁명적이었지만, 한계도 분명했다:
⚠️
RAG의 세 가지 한계
1. 정적 문서 전용: RAG는 PDF, 위키 같은 정적 문서에 최적화됐다. 실시간 대화처럼 계속 변하는 데이터는 다루기 어렵다.
2. 시간 개념 부재: "김지수가 서울에 산다"와 "김지수가 부산으로 이사했다"가 같은 벡터 공간에 공존한다. 어느 것이 최신인지 RAG는 모른다.
3. 관계의 단절: 각 문서 조각은 독립적이다. "김지수 → 서울 거주 → 부산 이사 → MacBook 구매 → A/S 요청" 같은 연결 고리를 파악하지 못한다.
MemGPT: 운영체제 접근법
2023년 하반기, UC Berkeley의 연구자들이 MemGPT를 발표했다. 아이디어는 대담했다 — LLM을 운영체제의 가상 메모리처럼 운영하자. 메인 컨텍스트(RAM)가 부족하면, 이전 대화를 압축해서 외부 저장소(디스크)에 보관하고, 필요할 때 다시 불러온다.
하지만 MemGPT에도 근본적인 문제가 있었다:
- 요약 손실: 대화를 압축할 때 미세한 디테일이 사라진다. "부산 해운대 근처 아파트"가 "부산 거주"로 뭉뚱그려진다.
- 시간 추론 불가: "지난달에 말씀하신 건..." 같은 시간 기반 질문에 취약하다.
- 관계 단절: 여전히 텍스트 기반이라, 엔티티 간 관계를 구조적으로 파악하지 못한다.
GraphRAG: 지식 그래프의 귀환
2024년, Microsoft Research가 GraphRAG를 발표하면서 새로운 돌파구가 열렸다. 단순히 텍스트 조각을 검색하는 대신, 지식 그래프(Knowledge Graph)를 구축해서 엔티티와 관계를 구조적으로 저장하자는 것이다.
GraphRAG는 Leiden 알고리즘으로 커뮤니티를 감지하고, 각 커뮤니티의 요약을 생성해 "전체 그림"을 파악할 수 있게 했다. 하지만 GraphRAG도 정적 문서 분석에 최적화되어 있었다. 대화처럼 실시간으로 흘러들어오는 데이터를 동적으로 반영하기 어려웠고, 시간 정보를 추적하지 않았다.
제2장: Zep — "시간을 아는 지식 그래프"
핵심 통찰
Zep의 핵심 통찰은 이것이다:
AI 에이전트의 기억은 단순한 텍스트 저장이 아니라, 시간축 위에서 끊임없이 진화하는 지식 그래프여야 한다.
사람의 기억을 생각해보자. 우리는 "김지수가 서울에 산다"를 기억하다가, "부산으로 이사했다"는 새 정보가 들어오면 자동으로 이전 기억을 업데이트한다. "서울에 살았었다(과거)"와 "부산에 산다(현재)"가 시간축 위에 공존하면서, 가장 최신 정보가 기본값이 된다.
Zep은 이 인간의 기억 메커니즘을 Graphiti라는 시간 인식 지식 그래프 엔진으로 구현했다.
Graphiti: 시간을 아는 지식 그래프 엔진
Graphiti는 Zep의 핵심 엔진이다. 기존 지식 그래프와 결정적으로 다른 점은 세 가지다:
| 특성 | 기존 RAG | GraphRAG | Zep (Graphiti) |
|---|
| 데이터 소스 | 정적 문서 | 정적 문서 | 대화 + 비즈니스 데이터 (동적) |
| 시간 인식 | 없음 | 없음 | 이중 시간축 (Bi-temporal) |
| 업데이트 | 전체 재인덱싱 | 전체 재구성 | 증분 업데이트 (Incremental) |
| 커뮤니티 감지 | 없음 | Leiden (정적) | Label Propagation (동적) |
| 모순 처리 | 공존 (혼란) | 공존 | 시간적 무효화 (자동 업데이트) |
제3장: 3계층 지식 그래프 해부
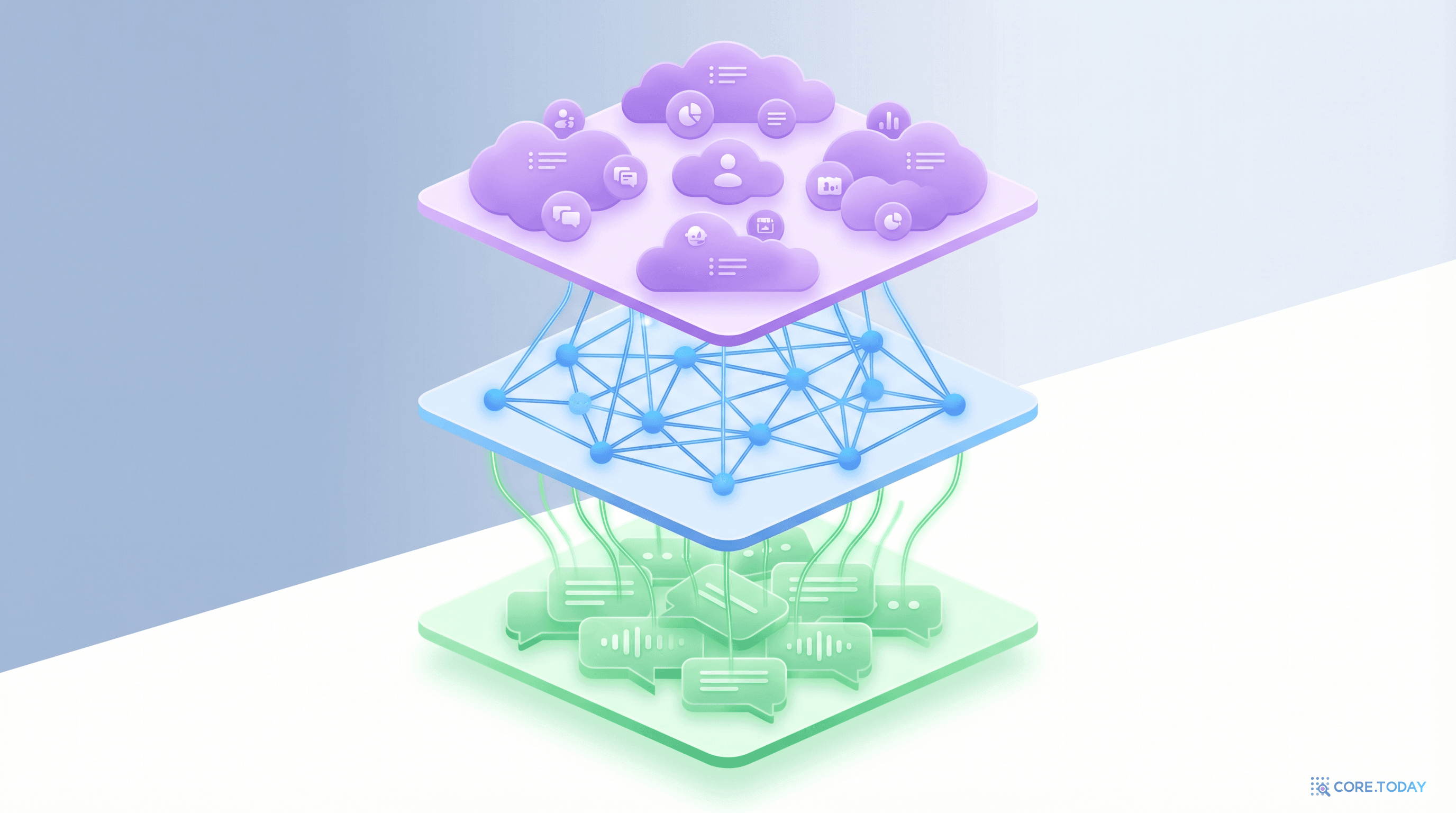
Zep의 지식 그래프 G=(N,E,ϕ)는 세 개의 층으로 이루어진 계층 구조다. 각 층은 서로 다른 추상화 수준에서 정보를 저장한다.
1층: 에피소드 서브그래프 (Ge) — 원본 보관소
가장 아래 층은 에피소드 서브그래프다. 이름 그대로, 대화의 각 에피소드(메시지)를 원본 그대로 저장한다.
Episode #1 [2026-04-13 10:00]
고객: "안녕하세요, 저는 김지수입니다. 서울에 살고 있어요."
Episode #2 [2026-04-13 10:01]
고객: "최근에 부산으로 이사했어요."
Episode #3 [2026-04-13 10:05]
고객: "지난달 주문한 MacBook Pro에 문제가 있어요."
핵심은 비손실(non-lossy) 저장이다. 요약하거나 압축하지 않는다. 원본을 보존함으로써, 나중에 "정확히 뭐라고 했었지?"라는 질문에 원문을 제공할 수 있다. 에피소드 엣지(Ee)는 에피소드 노드를 시맨틱 엔티티 노드에 연결해, 양방향 추적성(bidirectional traceability)을 보장한다.
2층: 시맨틱 엔티티 서브그래프 (Gs) — 지식의 정수
가운데 층은 시맨틱 엔티티 서브그래프다. 에피소드에서 추출된 엔티티(사람, 장소, 사물)와 그 관계(사실, 관계)를 구조화한다.
엔티티 추출 과정은 다음과 같다:
추출
현재 메시지 + 이전 4개 메시지를 LLM에 전달하여 엔티티와 관계를 추출
해결
코사인 유사도 + 전문 검색(BM25)으로 기존 엔티티와의 중복을 확인 (1024차원 벡터)
반성
Reflexion 기법으로 할루시네이션을 최소화하고 누락된 엔티티를 재확인
통합
중복 엔티티는 병합, 새 엔티티는 사전 정의된 Cypher 쿼리로 그래프에 추가
예를 들어, "저는 김지수입니다. 서울에 살고 있어요"라는 메시지에서:
- 엔티티:
김지수(사람), 서울(장소)
- 관계:
김지수 → 거주 → 서울
이후 "부산으로 이사했어요"가 들어오면:
- 새 엔티티:
부산(장소)
- 새 관계:
김지수 → 거주 → 부산
- 무효화:
김지수 → 거주 → 서울 관계에 t_invalid 타임스탬프 설정
3층: 커뮤니티 서브그래프 (Gc) — 큰 그림
최상위 층은 커뮤니티 서브그래프다. 강하게 연결된 엔티티들을 자동으로 군집화하고, 각 군집의 고수준 요약을 생성한다.
Zep은 GraphRAG의 Leiden 알고리즘 대신 레이블 전파(Label Propagation) 알고리즘을 사용한다. 이유는 명확하다:
🔴
Leiden (GraphRAG)
새 데이터가 추가될 때마다 전체 그래프를 처음부터 다시 계산해야 한다. 정적 문서에는 괜찮지만, 실시간 대화에서는 비용이 크다.
🟢
Label Propagation (Zep)
새 노드가 추가되면, 이웃 노드들의 커뮤니티를 조사해서 다수결로 배정한다. 전체 재계산 없이 증분 업데이트 가능 — 실시간 대화에 최적화.
💡
트레이드오프
시간이 지남에 따라 전체 Label Propagation 결과와 괴리가 생길 수 있어, 주기적인 전체 새로고침이 필요하다.
아래 시뮬레이터로 대화가 진행되면서 3계층 지식 그래프가 어떻게 구축되는지 직접 체험해보자:
제4장: 시간의 두 축 — 이중 시간 모델 (Bi-temporal Model)
Zep의 가장 혁신적인 기여 중 하나는 이중 시간 모델(Bi-temporal Model)이다. 이것은 데이터베이스 이론에서 가져온 개념인데, Zep이 이를 AI 에이전트 메모리에 최초로 적용했다.
두 개의 시간축
모든 사실(엣지)에는 네 개의 타임스탬프가 붙는다:
| 타임스탬프 | 시간축 T (실제 세계) | 시간축 T' (시스템) |
|---|
| 시작 | t_valid — 사실이 현실에서 참이 된 시점 | t'_created — 시스템에 기록된 시점 |
| 종료 | t_invalid — 사실이 현실에서 거짓이 된 시점 | t'_expired — 시스템에서 무효화된 시점 |
왜 두 개의 시간축이 필요한가?
구체적 사례로 이해해보자:
1월 15일 (현실): 김지수가 서울에서 부산으로 이사
3월 20일 (시스템): 김지수가 대화 중 "부산으로 이사했어요"라고 언급
시간축 T (현실):
• "김지수 → 서울 거주": t_valid=과거, t_invalid=1월 15일
• "김지수 → 부산 거주": t_valid=1월 15일, t_invalid=null (현재 유효)
시간축 T' (시스템):
• "김지수 → 서울 거주": t'_created=최초 대화, t'_expired=3월 20일
• "김지수 → 부산 거주": t'_created=3월 20일, t'_expired=null
현실에서 김지수는 1월 15일에 이사했지만, 시스템은 3월 20일에야 이 사실을 알게 되었다. 두 시간축을 분리함으로써:
- "김지수는 지금 어디 살아?" → 시간축 T의 최신 유효 값: 부산
- "시스템이 이 사실을 언제 알았지?" → 시간축 T': 3월 20일
- "1월 말 기준 김지수 주소는?" → 시간축 T에서 1월 31일 유효값: 부산
- "시스템이 2월에 알고 있던 주소는?" → 시간축 T'에서 2월 기준: 서울 (아직 업데이트 전)
이 구분은 감사(audit), 디버깅, 시간 기반 질의에 핵심적이다. 특히 금융, 의료, 법률 같은 기업 환경에서 "언제 무엇을 알았는가"를 추적하는 것은 컴플라이언스 필수 요건이다.
엣지 무효화: 모순을 자동으로 해결하기
Zep의 또 다른 핵심 메커니즘은 자동 엣지 무효화다.
새 사실 입력
→
기존 사실과 비교
→
모순 감지?
↓
YES → 기존 엣지에 t_invalid 설정
|
NO → 새 엣지 추가
LLM이 새로운 엣지와 의미적으로 관련된 기존 엣지를 비교하여, 시간적으로 겹치는 모순을 감지한다. 모순이 발견되면 기존 엣지에 무효화 타임스탬프를 설정한다. 중요한 원칙: Graphiti는 항상 최신 정보를 우선시한다. 하지만 이전 정보를 삭제하지는 않는다 — 역사적 기록으로 보존한다.
제5장: 검색 파이프라인 — 기억 속에서 금을 캐다

지식 그래프를 잘 구축하는 것만큼 중요한 것이 적시에 적절한 정보를 꺼내오는 것이다. Zep의 검색 파이프라인은 세 단계 합성 함수로 표현된다:
f(α)=χ(ρ(ϕ(α)))=β
여기서 α는 입력 쿼리, β는 최종 컨텍스트, ϕ는 검색, ρ는 재순위화, χ는 컨텍스트 구성이다.
단계 1: 검색 (ϕ) — 세 가지 그물 던지기
Zep은 세 가지 서로 다른 검색 방법을 동시에 실행한다. 각각이 포착하는 유사성의 차원이 다르기 때문이다:
코사인 유사도
Semantic
"부산 거주" 검색 시 "해운대 아파트"도 검색됨. 의미적으로 유사한 노드를 찾는다.
Okapi BM25
Lexical
"MacBook Pro" 검색 시 정확히 "MacBook Pro"를 포함하는 노드를 찾는다. 키워드 일치 기반.
너비 우선 탐색 (BFS)
Contextual
"김지수" 노드에서 출발하여 연결된 모든 관계(거주지, 구매, 일정)를 탐색한다.
단계 2: 재순위화 (ρ) — 금과 모래 분리
세 그물에 잡힌 결과를 통합하고 순위를 매긴다. 다섯 가지 재순위화 전략이 결합된다:
| 전략 | 설명 |
|---|
| Reciprocal Rank Fusion | 여러 검색 결과의 순위를 통합하는 앙상블 기법 |
| Maximal Marginal Relevance | 관련성과 다양성의 균형 — 중복 결과 제거 |
| 에피소드 언급 빈도 | 여러 에피소드에서 반복 언급된 엔티티에 가중치 부여 |
| 중심 노드 거리 | 쿼리 중심에서 가까운 노드에 높은 점수 |
| Cross-encoder 스코어링 | BGE-m3 모델로 쿼리-결과 쌍의 관련성을 정밀 평가 |
단계 3: 컨텍스트 구성 (χ) — LLM이 이해할 형태로
최종 선택된 노드와 엣지를 구조화된 텍스트로 변환한다. 이 과정에서 시간적 유효성 정보가 함께 포함되어, LLM이 "이 정보가 현재 유효한지"를 판단할 수 있다.
[엔티티] 김지수 — 고객, 이메일: jisoo.kim@gmail.com
[관계] 김지수 → 부산 거주 [유효: 현재]
[관계] 김지수 → 서울 거주 [무효화: 2026-01-15]
[관계] 김지수 → MacBook Pro 구매 [유효: 현재]
[관계] MacBook Pro → 화면 깜빡임 A/S [유효: 현재]
[일정] 김지수 → 다음 주 해외 출장 [유효: 예정]
[커뮤니티 요약] 김지수는 최근 부산으로 이사한 고객으로,
MacBook Pro 화면 깜빡임 문제로 A/S를 요청했으며,
다음 주 해외 출장 전 처리를 희망합니다.
이 구조화된 컨텍스트는 전체 대화 115,000 토큰을 단 1,600 토큰으로 압축하면서도 핵심 정보를 보존한다. 이것이 90% 레이턴시 감소의 비밀이다.
제6장: 실험 결과 — 숫자가 말하는 것
Zep은 두 가지 벤치마크에서 평가되었다. 결과를 인터랙티브하게 탐색해보자:
Deep Memory Retrieval (DMR) — "기본은 된다"
DMR은 500개 다중 세션 대화에서 특정 사실을 기억하는 능력을 테스트한다. 각 대화는 5개 세션, 세션당 약 12개 메시지(총 60개)로 구성된다.
Recursive Summarization
35.3%
Conversation Summaries
78.6%
Zep은 94.8%로 1위를 차지했지만, 논문 스스로가 이 벤치마크의 한계를 지적한다. 대화 전체를 그대로 넣는 Full-conversation이 94.4%를 기록한다는 것은, DMR이 실제 엔터프라이즈 시나리오의 복잡성을 충분히 반영하지 못한다는 의미다.
LongMemEval (LME) — "여기서 진짜 차이가 난다"
LME는 평균 115,000 토큰의 장기 대화에서 기억 능력을 테스트한다. 이것이 Zep의 진가를 보여주는 벤치마크다.
| 시스템 | 모델 | 정확도 | 레이턴시 | 컨텍스트 |
|---|
| Full-context | gpt-4o | 60.2% | 28.9s | 115k |
| Zep | gpt-4o | 71.2% | 2.58s | 1.6k |
세 가지 수치가 모두 의미심장하다:
-
정확도 +18.5%: 단순히 전체 대화를 넣는 것보다, 핵심만 추출하는 Zep이 더 정확하다. 이는 LLM의 "needle in a haystack" 문제를 해결한 것이다 — 115K 토큰 속에서 답을 찾는 것보다, 1.6K 토큰의 정제된 컨텍스트에서 찾는 것이 쉽다.
-
레이턴시 -90%: 28.9초 → 2.58초. 사용자가 답을 기다리는 시간이 10분의 1로 줄었다.
-
컨텍스트 98.6% 압축: 115,000 토큰 → 1,600 토큰. API 비용이 극적으로 줄어든다.
질문 유형별 분석: Zep이 빛나는 곳과 약한 곳
LME는 6가지 질문 유형으로 나뉜다. 유형별 성능 차이가 흥미롭다:
temporal-reasoning (시간 추론)
+27.6%
multi-session (교차 세션)
+21.0%
single-session-user
+20.1%
single-session-assistant
-17.7%
Zep이 가장 뛰어난 곳은 선호도 기억(+34.2%)과 시간 추론(+27.6%)이다. "채식주의자라고 했는데 뭐 추천해줄래?", "지난달에 말한 프로젝트 진행 상황은?" 같은 질문에 강하다.
반면, single-session-assistant(-17.7%)에서는 기준선보다 약했다. 이는 AI 에이전트 자신이 이전에 말한 내용을 기억하는 영역인데, 엔티티 추출이 에이전트 발화보다 사용자 발화에 집중되기 때문으로 분석된다.
제7장: 2026년의 의미 — 기업용 AI 에이전트의 게임 체인저
왜 지금 이 기술이 중요한가
2026년은 AI 에이전트가 장난감에서 도구로 전환되는 해다. Claude Code, Cursor, Devin 같은 코딩 에이전트부터, 고객 서비스 봇, 의료 상담 AI, 금융 어드바이저까지 — 에이전트가 실제 업무에 투입되고 있다.
하지만 이 모든 에이전트에 공통된 약점이 있다: 장기 기억의 부재. 사용자와 수십 번 대화를 나눠도, 매번 "처음 뵙겠습니다" 수준이다.
Zep의 기술이 의미하는 것은:
고객 서비스
고객의 이전 문의, 선호도, 불만 이력을 자동으로 기억. "지난번 A/S 건 처리됐나요?"에 즉시 응답.
의료 AI
환자의 증상 이력, 처방 변경, 알레르기 정보를 시간축으로 추적. "3개월 전 약을 바꾼 후 변화는?"
금융 어드바이저
투자 성향, 포트폴리오 변경 이력, 리스크 선호도를 동적으로 관리. 시간에 따른 투자 전략 진화를 추적.
논문이 인정하는 한계
저자들은 정직하게 한계를 인정한다:
-
DMR 벤치마크의 부적절성: 60개 메시지 수준의 대화는 실제 엔터프라이즈 시나리오를 반영하지 못한다. 더 현실적인 벤치마크가 필요하다.
-
비즈니스 데이터 통합 미검증: Zep의 핵심 강점 중 하나인 "대화 + 비즈니스 데이터 통합"이 체계적으로 평가되지 않았다.
-
LLM 의존성: 엔티티 추출, 모순 감지, 커뮤니티 요약 모두 LLM에 의존한다. LLM의 할루시네이션이 지식 그래프의 정확성에 영향을 줄 수 있다.
미래를 향한 방향
Zep 논문이 열어놓은 연구 방향들:
단기
엔터프라이즈 벤치마크 — CX(고객 경험) 태스크 기반 평가 프레임워크 개발
중기
멀티모달 메모리 — 텍스트뿐 아니라 이미지, 음성, 코드를 포함하는 지식 그래프
중기
분산 에이전트 메모리 — 여러 에이전트가 공유하는 지식 그래프 (팀 메모리)
장기
자기 진화 그래프 — 사용 패턴에 따라 스스로 구조를 최적화하는 메모리 시스템
핵심 정리: 한 장으로 보는 Zep
| 개념 | 핵심 내용 |
|---|
| 문제 | AI 에이전트에 장기 기억이 없다. 세션이 끝나면 모두 잊는다. |
| 해법 | 시간 인식 지식 그래프(Temporal KG)로 동적 기억 시스템 구축 |
| 3계층 구조 | 에피소드(원본) → 시맨틱(엔티티+관계) → 커뮤니티(큰 그림) |
| 시간 모델 | 이중 시간축: T(현실 시간) + T'(시스템 시간), 엣지당 4개 타임스탬프 |
| 모순 처리 | 자동 엣지 무효화. 최신 정보 우선, 이력은 보존 |
| 검색 | 코사인 + BM25 + BFS 삼중 검색 → 5중 재순위화 → 구조화 출력 |
| 성능 | DMR 94.8%(1위), LME +18.5% 정확도, 90% 레이턴시 감소 |
| 핵심 기술 | Graphiti 엔진, Label Propagation, Reflexion, BGE-m3 임베딩 |
마무리: 기억은 지능의 기반이다
"기억이 없는 지능은 없다."
이 단순한 진리가 AI 에이전트의 다음 진화 방향을 가리킨다.
Zep 논문은 단순히 "AI에게 기억을 달아주었다"가 아니다. 시간이라는 차원을 기억에 통합함으로써, AI가 "김지수가 어디 사는지"만 아는 것이 아니라 "언제 서울에서 부산으로 이사했는지", "시스템이 언제 그 사실을 알게 되었는지", "지금은 어디에 있는지"까지 파악할 수 있게 만들었다.
2026년, AI 에이전트가 우리의 업무에 깊이 들어오는 이 시점에서, Zep이 제시한 "시간을 아는 기억"은 단순한 기술적 개선이 아닌 패러다임의 전환이다. 매일 첫 출근하는 비서가 아니라, 함께 일한 모든 순간을 기억하는 동료 — 그것이 Zep이 꿈꾸는 AI 에이전트의 미래다.
참고 문헌:
- Rasmussen, P., Paliychuk, P., Beauvais, T., Ryan, J., & Chalef, D. (2025). Zep: A Temporal Knowledge Graph Architecture for Agent Memory. arXiv:2501.13956
- Packer, C., et al. (2023). MemGPT: Towards LLMs as Operating Systems. arXiv:2310.08560
- Edge, D., et al. (2024). From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv:2404.16130