인사이트
81개의 포스트
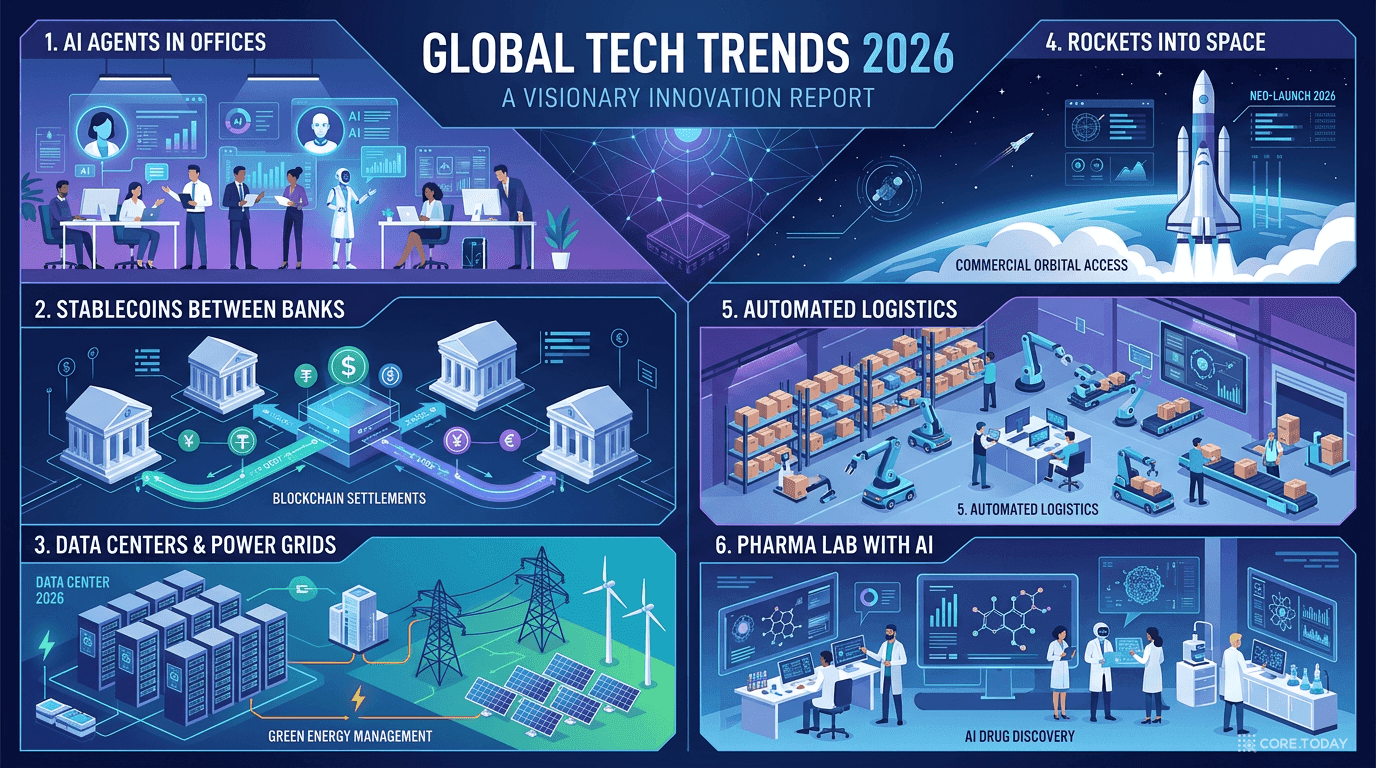
CB Insights 2026 테크 트렌드 완전 해부 — 14개 메가트렌드로 읽는 기술의 미래
CB Insights가 102페이지에 걸쳐 분석한 2026년 14대 테크 트렌드를 완전 해부합니다. AI 에이전트의 ROI 측정부터 매장의 소멸, 데이터센터의 전력망 편입, 로봇 팀워크까지 — 지금 가장 중요한 기술 변화를 풍부한 데이터와 인터랙티브 탐색기로 체험하세요.

P50 vs P95 특집: '평균 사용자'라는 환상을 버려라 — 백분위수가 바꾸는 제품 설계의 모든 것
당신의 '평균 사용자'는 존재하지 않는다. 1885년 골턴이 발명한 백분위수 개념이 2026년 AI 시대에 제품 설계, 성능 최적화, 가격 정책까지 뒤흔드는 이유를 파헤친다.

Docker 특집: 컨테이너 혁명의 영웅은 어쩌다 정체성을 잃었나
컨테이너 혁명을 일으킨 Docker가 2026년, 끊임없는 피벗 속에서 길을 찾고 있다. chroot에서 시작된 격리 기술의 역사부터, Docker의 황금기와 몰락, 그리고 AI 피벗까지 — 기술은 영원하지만 회사는 그렇지 않다는 이야기.
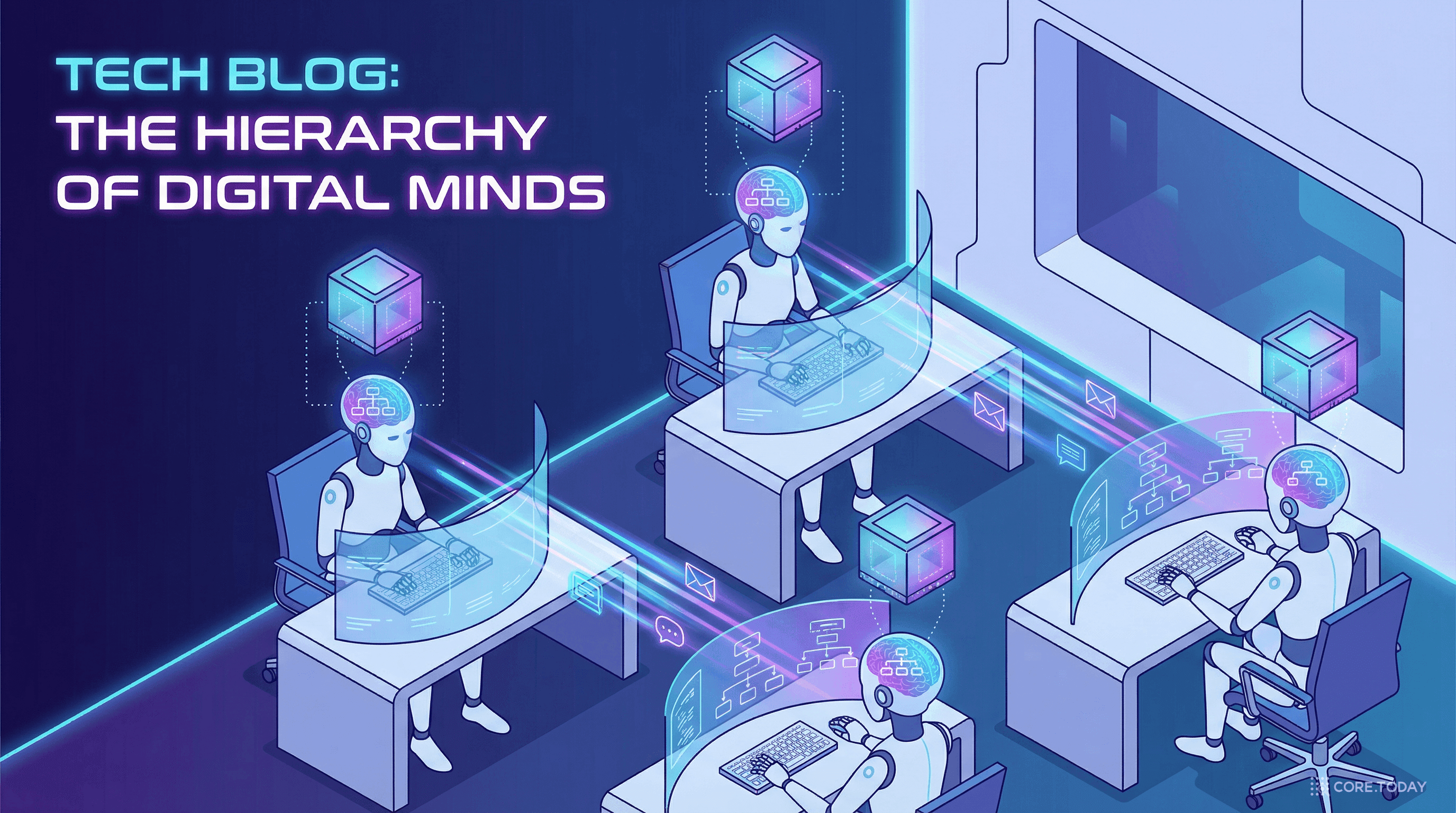
CORPGEN 특집: AI가 사무실에 출근한다면, 멀티태스킹부터 배워야 한다
현실의 지식 노동자는 하루에 수십 개의 업무를 동시에 저글링한다. 그런데 AI 에이전트는 아직 하나도 제대로 못 끝낸다? Microsoft Research의 CORPGEN이 이 문제를 어떻게 해결하는지, 역사부터 아키텍처까지 완전 해부한다.

MIT Missing Semester 완전 가이드 — CS 교육이 빠뜨린 '진짜 실력'
MIT가 만든 전설의 무료 강의 'The Missing Semester'를 완전 해부한다. 왜 세계 최고의 CS 학생들도 터미널 앞에서 헤매는가? 1969년 Unix 쉘부터 2026년 AI 코딩 에이전트까지, CS 교육이 빼먹은 '진짜 실력'의 모든 것.

한국 AI 5인방 완전 해부 — HyperCLOVA X Think, K-EXAONE, Kanana, Gauss, A.X K1
LG의 K-EXAONE은 AIME 2025에서 92.8%로 GPT를 넘었고, SKT의 A.X K1은 519B 파라미터로 국내 최대 규모를 자랑한다. 네이버, 카카오, 삼성까지 — 2026년 한국 AI 5인방의 기술, 벤치마크, 전략을 낱낱이 해부한다.

교과서가 답이다: 작은 AI가 거대한 AI를 이긴 날
1.3B 파라미터 모델이 175B GPT-3.5를 이겼다. 비결은 '교과서 품질' 데이터. 'Textbooks Are All You Need' 논문이 열어젖힌 소형 언어 모델 혁명과, 3년이 지난 2026년 지금 그 논문이 어떻게 현실이 되었는지를 추적한다.

제조업 AI 완전정복: 공장이 스스로 생각하는 시대가 왔다
포드의 조립 라인부터 자율 공장까지 — 제조업 AI의 역사, 핵심 기술 6가지, 글로벌·한국 사례, 그리고 2026년 '공장이 스스로 생각하는 시대'의 실무 가이드를 총정리한다.

NVIDIA GTC 2026 완전 해부: 젠슨 황이 그린 AI의 다음 10년
7개의 칩, 5개의 랙, 1대의 슈퍼컴퓨터. 2026년 3월, 젠슨 황은 '1조 달러의 수주'를 선언하며 AI 컴퓨팅의 새 시대를 열었다. Vera Rubin부터 우주 컴퓨팅까지 — GTC 2026 키노트의 모든 것을 해부한다.

GTC 2026 AI 에이전트 특집: NemoClaw, OpenShell, 그리고 에이전트 보안의 새 기준
2026년 3월 16일, NVIDIA GTC에서 AI 에이전트 생태계의 판도를 바꿀 발표가 쏟아졌다. NemoClaw와 OpenShell로 보안 문제를 정면 돌파하고, Vera Rubin으로 추론 컴퓨팅의 미래를 제시하며, Adobe·Salesforce·SAP 등 17개 기업이 에이전트 도입을 선언했다.

Yann LeCun의 1조원짜리 반란: World Model, JEPA, 그리고 AMI Labs — LLM 시대의 종말을 선언한 남자
튜링상 수상자 얀 르쿤이 12년간 이끌던 Meta FAIR을 떠나 10억 달러를 모아 AMI Labs를 세웠다. 그의 주장: 'LLM으로는 절대 인간 수준 AI에 도달할 수 없다.' 그가 내놓은 대안 — 세계 모델과 JEPA 아키텍처의 원리를, 케이크 비유부터 로봇 제어까지 깊이 있게 풀어본다.

Scaling Laws 특집: AI에 돈을 쏟으면 얼마나 똑똑해질까 — 예측 가능해진 AI의 성장 법칙
AI 모델에 10배의 자원을 투입하면 성능이 얼마나 오를까? 2020년 Kaplan의 법칙은 '모델을 키워라'고 답했고, 2022년 Chinchilla는 '데이터를 키워라'로 뒤집었다. 수십억 달러 투자를 좌우하는 두 법칙의 탄생, 충돌, 그리고 2026년의 새로운 스케일링까지를 추적한다.