
블로그로 돌아가기
AI 스킬Tool UseReActMCP에이전트 AILLM
AI에게 스킬이 필요한 이유: 논문에서 프로토콜까지, 도구를 쥔 AI의 진화
수학 올림피아드를 푸는 AI가 오늘 날씨를 모른다. LLM의 구조적 한계에서 출발해, Toolformer·ReAct·Voyager 등 핵심 논문의 원리를 풀어보고, Function Calling에서 MCP·스킬 시스템까지 이어지는 산업의 대응을 추적한다.
코어닷투데이2026-03-1462분
수학 올림피아드를 푸는 AI가 오늘 날씨를 모른다. LLM의 구조적 한계에서 출발해, Toolformer·ReAct·Voyager 등 핵심 논문의 원리를 풀어보고, Function Calling에서 MCP·스킬 시스템까지 이어지는 산업의 대응을 추적한다.
2025년, AI는 국제수학올림피아드(IMO) 문제를 풀고, 변호사 시험을 통과하며, 분자 구조를 예측하는 수준에 도달했다. 그런데 이 놀라운 AI에게 "오늘 서울 날씨가 어때?"라고 물으면, 자신 있게 — 그리고 종종 틀리게 — 대답한다.
이것은 AI의 실수가 아니라 구조적 한계다. 거대 언어 모델(LLM)은 태생적으로 세 가지 벽에 갇혀 있다. 이 벽을 이해하면, 왜 전 세계 AI 연구자와 기업이 "도구 사용(Tool Use)"과 "스킬(Skill)"이라는 개념에 집중하는지 자연스럽게 보인다.
이 글은 그 여정을 따라간다.
ChatGPT, Claude, Gemini — 이름과 성능은 다르지만, 모든 LLM은 동일한 원리로 작동한다. 다음 단어를 예측하는 것. 방대한 텍스트를 학습한 뒤, 주어진 맥락에서 가장 그럴듯한 다음 토큰을 생성한다. 이 단순한 원리가 놀라운 능력을 만들어냈지만, 동시에 근본적인 한계도 만들었다.

LLM은 특정 시점까지의 텍스트 데이터로 학습된다. 이 시점을 학습 데이터 마감일(knowledge cutoff)이라 한다. 마감일 이후에 일어난 사건, 발표된 논문, 변경된 API — 모델은 이 모든 것을 "모른다."
문제는 모른다는 사실을 모른다는 점이다. LLM은 확률적으로 그럴듯한 텍스트를 생성하기 때문에, 모르는 질문에도 자신 있게 답한다. 이를 환각(hallucination)이라 한다.
사용자: "2026년 3월 19일 코스피 종가가 얼마야?" LLM: "2026년 3월 19일 코스피 지수는 2,847.53포인트로 마감했습니다." — 완전히 지어낸 숫자
실시간 정보가 필요한 모든 업무 — 주가 조회, 날씨 확인, 최신 뉴스 요약 — 에서 LLM 단독으로는 신뢰할 수 없는 답을 내놓는다.
LLM은 텍스트를 토큰 단위로 처리한다. 숫자도 예외가 아니다. "3847"은 수학적 값이 아니라 토큰의 나열이다. 다음 실험 결과를 보자:
사용자: "3,847 × 2,951 = ?" GPT-4: "11,355,897" — 오답 (정답: 11,354,297)
1,600 차이가 난다. 사람이 암산으로 이 곱셈을 해도 비슷한 정도의 실수를 할 수 있다. 하지만 사람과 AI 사이에 결정적 차이가 있다 — 사람은 계산기를 쓸 줄 안다.
이 문제의 근본 원인은 명확하다. LLM의 Transformer 아키텍처는 패턴 인식과 언어 생성에 최적화되어 있지, 정확한 수치 연산을 위해 설계되지 않았다. 아무리 파라미터를 늘려도, 언어 모델이 계산기를 이길 수는 없다.
가장 근본적인 한계다. LLM은 텍스트를 입력받아 텍스트를 출력하는 시스템이다. 아무리 뛰어난 지식을 갖고 있어도, 외부 세계에 작용할 수 없다.
사용자: "내일 오전 10시에 팀 미팅 일정을 잡아줘" LLM: "Google Calendar에서 새 이벤트를 생성하려면..." — 실제로 일정을 생성하지는 못한다
이것은 비유하자면 모든 것을 아는 두뇌가 유리병 안에 갇혀 있는 상태다. 이메일을 보내는 방법, 코드를 배포하는 절차, 데이터베이스를 조회하는 쿼리 — 모든 것을 알고 있지만 실행할 손이 없다.

세 가지 벽의 공통점이 보이는가? 외부 세계와의 연결이 없다는 것이다. 최신 정보를 가져올 검색 엔진, 정확한 답을 내놓을 계산기, 명령을 실행할 API — 이것들만 연결하면 세 가지 벽을 모두 넘을 수 있다.
연구자들도 같은 결론에 도달했다. 그리고 2022년부터, 그 해답을 논문으로 내놓기 시작했다.
2022~2023년, AI 연구의 최전선에서 연달아 터진 논문들이 있다. 이 논문들은 각각 다른 각도에서 같은 질문에 답했다: "LLM에게 어떻게 도구를 쥐어줄 것인가?"
도구 사용에 앞서, 먼저 LLM이 "생각하는 방법"을 배워야 했다. Google Brain의 Jason Wei 등이 발표한 Chain-of-Thought(CoT) 프롬프팅은 그 출발점이었다.
핵심 발견은 놀랍도록 단순했다. 답만 요구하는 대신, 추론 과정을 함께 보여달라고 요청하면 정확도가 급등한다.
일반 프롬프팅:
Q: 카페에 23명이 있었다. 12명이 나가고 5명이 들어왔다.
지금 몇 명이 있는가?
A: 16명
Chain-of-Thought 프롬프팅:
Q: 카페에 23명이 있었다. 12명이 나가고 5명이 들어왔다.
지금 몇 명이 있는가?
A: 처음 23명이 있었다. 12명이 나가면 23 - 12 = 11명.
5명이 들어오면 11 + 5 = 16명. 답: 16명
결과는 같지만, 과정이 있을 때 복잡한 문제에서의 정확도가 크게 향상되었다. Google의 PaLM 540B 모델 기준으로, GSM8K(초등학교 수학 문제 벤치마크) 정확도가 약 57%에서 약 74%로 뛰었다.
왜 이런 일이 일어날까? LLM은 한 번에 하나의 토큰을 생성한다. 중간 추론 단계를 텍스트로 출력하면, 그 텍스트가 다시 컨텍스트에 들어가 다음 추론의 입력이 된다. 즉 CoT는 LLM에게 작업 기억(working memory)을 제공하는 셈이다.

CoT는 도구 사용 그 자체는 아니다. 하지만 "LLM이 단계적으로 사고할 수 있다"는 발견은, 이후 모든 도구 사용 연구의 전제가 되었다. 도구를 쓰려면 먼저 "지금 어떤 도구가 필요한지" 판단하는 추론이 선행되어야 하기 때문이다.
CoT가 LLM에게 생각하는 법을 가르쳤다면, Princeton과 Google의 Shunyu Yao 등이 발표한 ReAct는 생각과 행동을 하나의 루프로 엮었다. ReAct는 Reasoning + Acting의 합성어다.
핵심 아이디어는 이렇다:
LLM이 추론 트레이스(Thought)를 생성하고, 그에 따라 외부 행동(Action)을 취하고, 그 결과를 관찰(Observation)로 받아들이는 사이클을 반복한다.

실제 ReAct 트레이스를 보면 직관적으로 이해된다:
질문: "콜로라도 동부 지역의 해발 고도 범위는?"
Thought 1: 콜로라도 동부 지역의 해발 고도를 찾아야 한다.
Action 1: Search["콜로라도 동부 평원 해발 고도"]
Observation 1: 콜로라도 동부 평원(Eastern Plains)은
해발 약 1,021m ~ 2,286m에 걸쳐 있다.
Thought 2: 범위를 계산하면 2,286 - 1,021 = 1,265m이다.
Action 2: Finish["약 1,265m"]
ReAct 이전에도 LLM이 검색 엔진을 호출하는 시도는 있었다. 하지만 ReAct가 다른 점은 추론과 행동이 번갈아 일어나며 서로를 강화한다는 것이다:
논문의 HotpotQA(다단계 질의응답 벤치마크) 실험 결과는 이 구조의 위력을 보여준다:
| 접근법 | 추론 | 행동 | 정확도 (EM) |
|---|---|---|---|
| Standard | 없음 | 없음 | 25.7% |
| CoT (생각만) | 있음 | 없음 | 29.4% |
| Act only (행동만) | 없음 | 있음 | 25.0% |
| ReAct (생각+행동) | 있음 | 있음 | 35.1% |
생각만 하는 것(CoT)보다, 행동만 하는 것(Act only)보다, 생각하면서 행동하는 것(ReAct)이 압도적으로 나았다. 이것은 직관적으로도 납득된다 — 우리도 복잡한 문제를 풀 때 "일단 해보고, 결과를 보고, 다시 생각하고, 다시 시도하는" 루프를 돈다.
ReAct는 사람이 "이 상황에서 이 도구를 써라"고 시범을 보여주는 방식이었다. Meta AI의 Timo Schick 등이 발표한 Toolformer는 한 단계 더 나아갔다: LLM이 스스로 어디에서 어떤 도구를 쓸지 학습하게 했다.
Toolformer의 학습 과정은 네 단계로 이루어진다:
핵심은 Step 3의 퍼플렉시티 필터링이다. 퍼플렉시티(perplexity)는 모델이 텍스트를 얼마나 잘 예측하는지 측정하는 지표다. 값이 낮을수록 예측이 정확하다는 뜻이다.
Toolformer는 이렇게 판단한다:
즉 기준은 단 하나다: "이 도구를 쓰면 텍스트 예측이 더 정확해지는가?"

실제 예시를 보자:
원본 텍스트:
"피타고라스는 기원전 570년경에 태어났고, 수학에 혁명적 기여를 했다."
Toolformer가 학습한 텍스트:
"피타고라스는 [QA("피타고라스 출생연도") → 기원전 570년경]에 태어났고,
수학에 혁명적 기여를 했다."
모델이 스스로 "여기에 QA 도구를 쓰면 더 정확한 텍스트를 생성할 수 있다"고 판단하고, 그 패턴을 학습한 것이다. Toolformer가 활용한 도구는 5가지였다:
| 도구 | 용도 | 사용 예시 |
|---|---|---|
| Calculator | 수치 계산 | [Calc(345 * 27)] → 9,315 |
| Q&A | 사실 확인 | [QA("한국의 수도는?")] → 서울 |
| Wikipedia | 배경 지식 검색 | [Wiki("양자역학")] → ... |
| Translator | 번역 | [MT("hello", ko)] → 안녕하세요 |
| Calendar | 날짜·시간 정보 | [Calendar()] → 2023-02-09 |
이것이 중요한 이유는 확장성 때문이다. 사람이 일일이 "여기서 이 도구를 써라"고 가르칠 필요 없이, LLM이 스스로 도구의 가치를 판단하고 사용법을 학습할 수 있다는 것은 — 새로운 도구를 추가할 때마다 전체 시스템을 재설계할 필요가 없다는 뜻이다.
AI21 Labs의 Ehud Karpas 등이 제안한 MRKL 시스템은 관점을 바꿨다. 하나의 LLM이 모든 것을 처리하는 대신, LLM을 라우터로 사용하고 실제 작업은 전문가 모듈에게 위임하자는 것이다. MRKL은 Modular Reasoning, Knowledge and Language의 약자다.
MRKL의 이름에 담긴 철학이 중요하다:
이것은 마치 종합병원과 같다. 환자(사용자 질문)가 접수처(LLM 라우터)에 도착하면, 증상에 따라 내과, 외과, 영상의학과 등 전문과(전문가 모듈)로 배정된다. 접수 직원이 모든 진료를 할 필요는 없다 — 어디로 보낼지만 판단하면 된다.
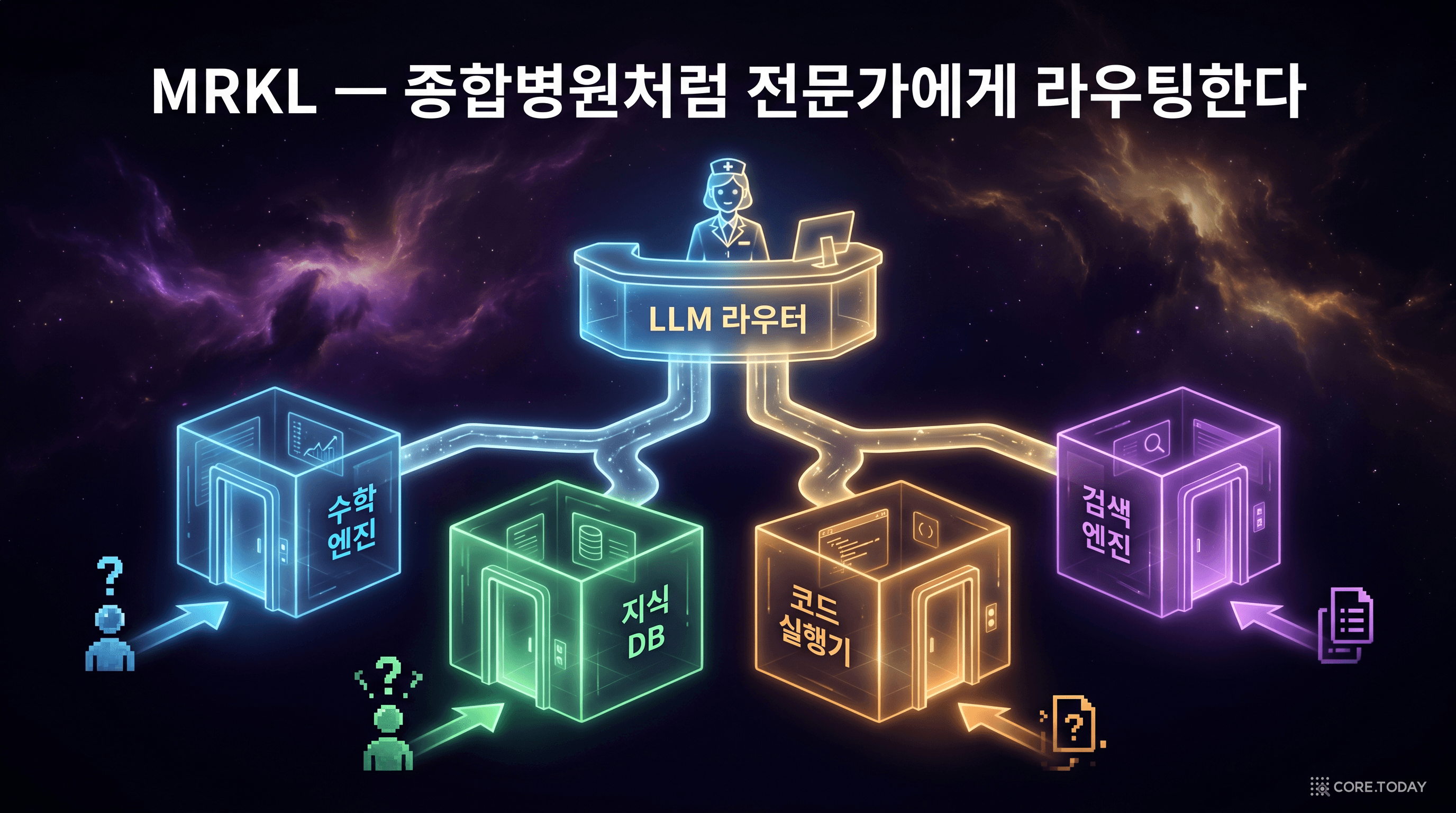
이 발상의 전환이 중요한 이유는, 제1장에서 본 세 가지 벽을 동시에 해결하기 때문이다:
| 벽 | MRKL의 해법 |
|---|---|
| 지식의 벽 | 검색 엔진 모듈이 실시간 정보 제공 |
| 계산의 벽 | 수학 엔진 모듈이 정확한 연산 수행 |
| 행동의 벽 | 코드 실행기 모듈이 외부 API 호출 |
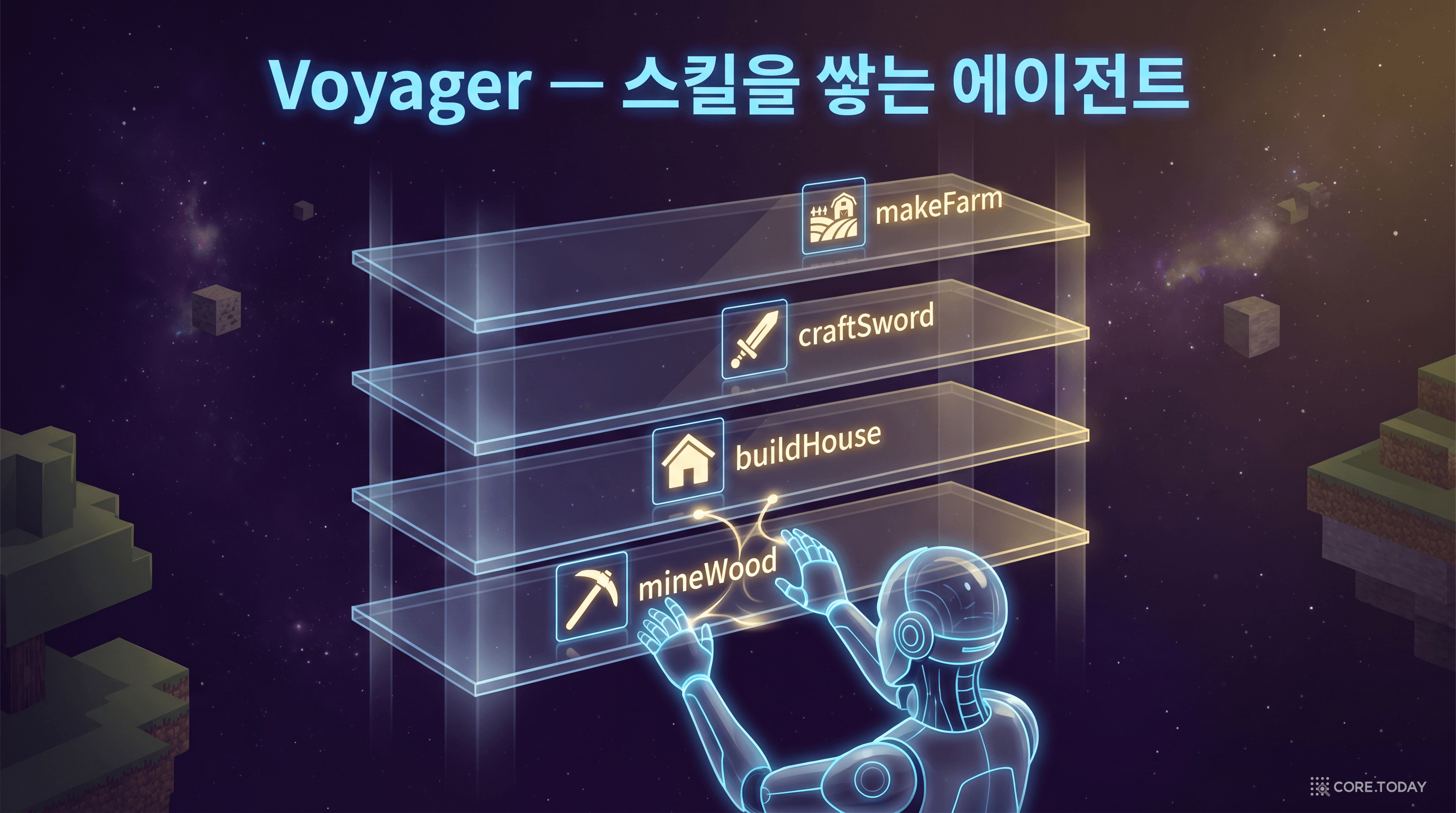
NVIDIA Research의 Guanzhi Wang 등이 발표한 Voyager는 이 글의 핵심 주제와 가장 직접적으로 연결되는 논문이다. 마인크래프트 게임 세계에서 스스로 탐험하고, 성공한 행동을 "스킬"로 저장해 재사용하는 에이전트를 만들었다.
Voyager의 아키텍처는 세 가지 핵심 요소로 구성된다:
Voyager의 스킬 축적 과정은 이렇다:
mineWood() 같은 함수명으로 스킬 라이브러리에 저장mineWood() 스킬을 검색해 활용핵심 인사이트는 스킬이 누적된다는 것이다. 초기에는 "나무 캐기", "돌 캐기" 같은 기본 스킬만 있지만, 시간이 지나면 이 기본 스킬들을 조합해 "다이아몬드 갑옷 제작", "자동 농장 건설" 같은 고차원 스킬을 만들어낸다.
논문의 실험 결과는 스킬 축적의 효과를 극명하게 보여준다. 160회 반복 탐험 후, Voyager가 발견한 고유 아이템 수는 기존 최고 방법 대비 3.3배에 달했다:
Voyager가 다른 방법들을 압도한 이유는 단순하다. 다른 방법들은 매번 처음부터 문제를 풀었지만, Voyager는 이전에 배운 것을 기억하고 재사용했다.
이것은 인간의 학습과 놀라울 정도로 닮았다. 우리도 처음에는 글자를 배우고, 단어를 배우고, 문장을 만들고, 그 위에 에세이를 쓰고, 논문을 쓴다. 각 단계의 스킬이 다음 단계의 빌딩 블록이 된다.
논문들을 관통하는 진화의 방향이 있다:
| 논문 | 핵심 질문 | 기여 |
|---|---|---|
| Chain-of-Thought | LLM이 추론할 수 있는가? | 단계적 사고의 가능성 입증 |
| ReAct | 추론과 행동을 결합할 수 있는가? | Thought-Action-Observation 루프 |
| Toolformer | 도구 사용을 자동으로 학습할 수 있는가? | 자기지도학습으로 도구 사용 체화 |
| MRKL | 전문가 모듈을 조합할 수 있는가? | 모듈형 뉴로-심볼릭 아키텍처 |
| Voyager | 학습한 스킬을 축적·재사용할 수 있는가? | 스킬 라이브러리 개념 실현 |
이 진화의 끝에서, 산업이 움직이기 시작했다.
논문이 "가능하다"를 증명하면, 기업은 "상품화하다"를 실행한다. 2023년부터 주요 AI 기업들은 도구 사용 기능을 경쟁적으로 출시했고, 2024~2025년에는 이를 표준화하는 단계로 진입했다.
2023년 6월, OpenAI가 GPT-3.5와 GPT-4에 Function Calling 기능을 추가했다. 개발자가 사용 가능한 함수 목록을 JSON Schema로 정의하면, 모델이 대화 맥락을 분석해 적절한 함수를 호출하는 방식이었다.
{
"name": "get_weather",
"description": "특정 도시의 현재 날씨를 조회한다",
"parameters": {
"type": "object",
"properties": {
"city": { "type": "string", "description": "도시 이름" }
},
"required": ["city"]
}
}
사용자가 "서울 날씨 어때?"라고 물으면, 모델은 직접 답하는 대신 get_weather(city="서울") 호출을 생성한다. 개발자의 코드가 실제 날씨 API를 호출하고, 그 결과를 모델에게 돌려주면, 모델이 자연어로 답변한다.
제1장의 "지식의 벽"이 무너지는 순간이었다.
하지만 한계도 명확했다:
2024년 11월, Anthropic이 Model Context Protocol(MCP)을 오픈 소스로 공개했다. MCP의 비전은 명확했다 — AI의 USB-C가 되겠다는 것.
USB-C 이전에는 기기마다 다른 충전 케이블이 필요했다. USB-C 이후에는 하나의 케이블로 모든 기기를 연결한다. MCP는 AI 도구 연결에서 같은 역할을 한다.
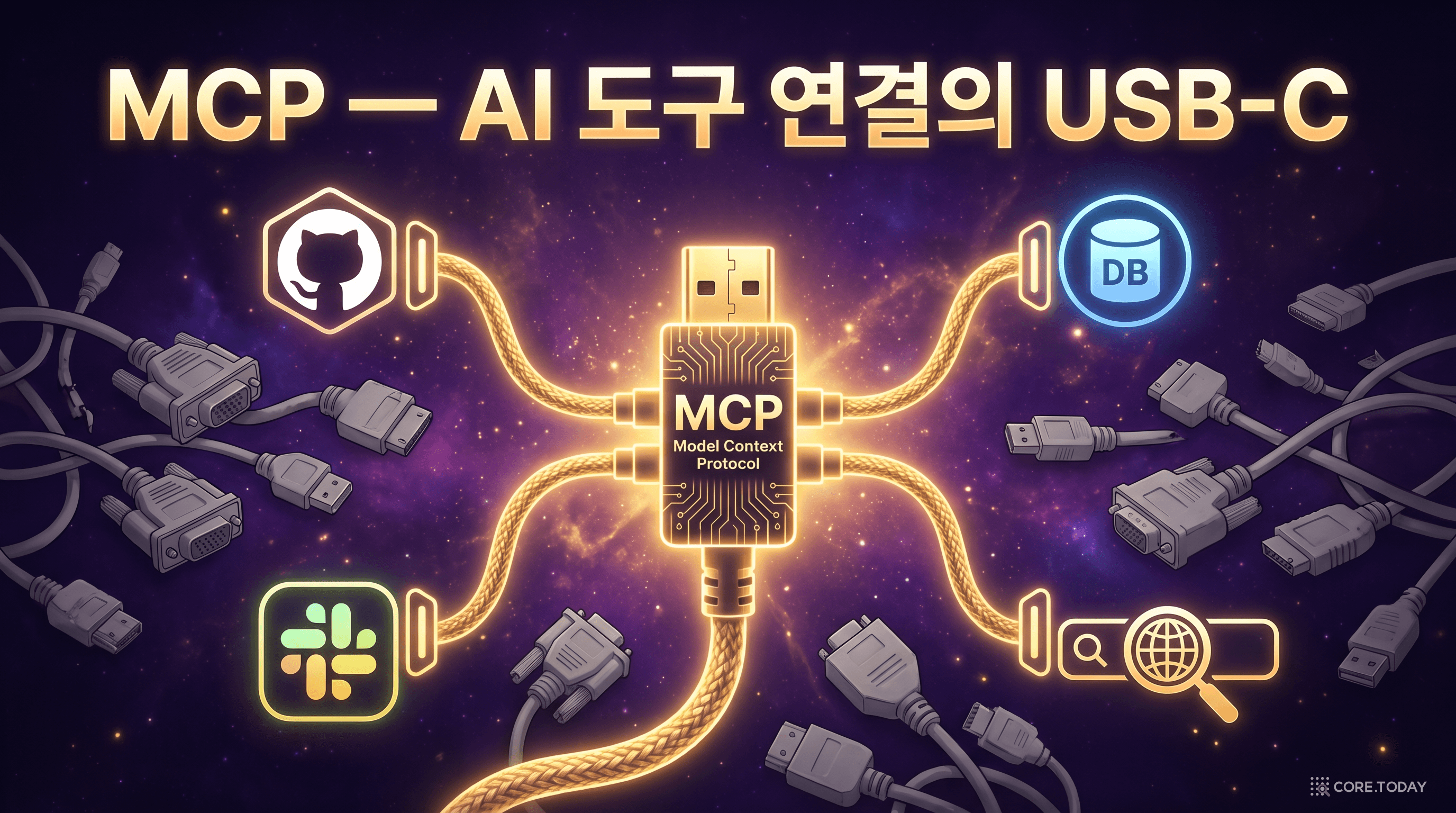
MCP가 Function Calling과 근본적으로 다른 점은 관심사의 분리다:
| 비교 항목 | Function Calling | MCP |
|---|---|---|
| 도구 정의 위치 | AI 모델 호출 시 매번 전달 | 서버가 자체 보유하고 광고 |
| 도구 제공자 | 앱 개발자 | 누구나 (서버만 만들면 됨) |
| 연결 방식 | 모델별 고유 포맷 | 표준 프로토콜 |
| 생태계 | 폐쇄적 | 개방적 (오픈 소스) |
| 비유 | 리모컨 (기기마다 다름) | USB-C (하나로 통일) |
2026년 3월 기준, MCP 생태계에는 수천 개의 서버가 등록되어 있고, Claude, GPT, Gemini 등 주요 모델이 MCP를 지원한다.
MCP가 에이전트 ↔ 도구 연결이라면, Google이 2025년 4월 발표한 A2A는 에이전트 ↔ 에이전트 연결이다. A2A는 Agent-to-Agent Protocol의 약자다.
MCP만으로는 부족한 시나리오가 있다. 예를 들어, 여행 계획을 세우는 상황을 생각해 보자:
이 세 에이전트가 협업하려면, 서로를 발견하고, 능력을 교환하고, 작업을 위임하는 표준이 필요하다. 이것이 A2A의 역할이다.

| 비교 항목 | MCP | A2A |
|---|---|---|
| 연결 대상 | 에이전트 ↔ 도구 | 에이전트 ↔ 에이전트 |
| 인간 비유 | 사람이 도구를 쓴다 | 사람이 사람과 협업한다 |
| 웹 비유 | REST API | HTTP |
| 핵심 기능 | 도구 발견·호출·결과 수신 | 에이전트 발견·능력 교환·작업 위임 |
2025년 12월, OpenAI, Anthropic, Google, Microsoft, AWS가 Linux Foundation 아래 AAIF(Agentic AI Foundation)를 공동 설립하며, MCP와 A2A를 중심으로 에이전트 생태계의 표준화가 본격화되었다.
하지만 여기서 한 가지 질문이 남는다. 도구를 "쓸 수 있다"는 것과 도구를 "잘 쓴다"는 것은 같은가?
도구를 연결했다. 프로토콜도 표준화했다. 하지만 아직 한 조각이 빠져 있다.
비유로 설명하자. 망치는 도구(Tool)다. 목공은 스킬(Skill)이다.
망치를 누구에게나 줄 수 있다. 하지만 가구를 만들려면 "어떤 나무를 고르는지, 어느 각도로 못을 박는지, 어떤 순서로 조립하는지" — 즉, 도구를 언제, 어떻게, 왜 사용하는지에 대한 전문 지식과 판단 기준이 필요하다. 이것이 스킬이다.

| 구분 | 도구 (Tool) | 스킬 (Skill) |
|---|---|---|
| 정의 | 단일 기능을 수행하는 함수 | 도구 + 전문 지식 + 워크플로우 + 판단 기준 |
| 예시 | search(), calculate(), send_email() | "체계적 디버깅", "TDD 개발", "프론트엔드 디자인" |
| 인간 비유 | 망치, 드라이버, 톱 | 목공, 전기 배선, 가구 디자인 |
| 재사용 방식 | 동일 함수를 반복 호출 | 상황에 맞게 판단하며 적용·변형 |
| 포함 요소 | 입력 → 출력 | 배경지식 + 판단 기준 + 절차 + 도구 조합 |
스킬은 네 개의 계층으로 구성된다:
아래에서 위로 올라갈수록 추상화 수준이 높아진다. 도구 접근은 "무엇을 쓸 수 있는가", 지식은 "무엇을 알아야 하는가", 워크플로우는 "어떤 순서로 하는가", 판단은 "언제 어떤 선택을 하는가"에 대응한다.
스킬이라는 개념은 사실 인간 조직에서 이미 수십 년째 작동하는 방식이다.
신입 개발자가 팀에 합류했다고 하자. 이 개발자에게 무엇을 주는가?
| 계층 | 인간 조직에서의 형태 | AI에게 주는 형태 |
|---|---|---|
| 도구 접근 | 코드 저장소, CI/CD, 모니터링 접근 권한 | MCP 서버 연결, API 키 |
| 지식 | 코딩 컨벤션, 아키텍처 문서, FAQ | 도메인 지식, 패턴 라이브러리 |
| 워크플로우 | PR 리뷰 프로세스, 배포 절차, 인시던트 대응 매뉴얼 | 단계별 절차 정의 |
| 판단 | "이 정도 장애는 혼자, 이 수준이면 에스컬레이션" | 의사결정 기준, 가드레일 |
도구만 주고 나머지를 안 주면? 신입 개발자는 IDE는 열 수 있지만, 무엇을 어떤 순서로 해야 하는지 모른다. AI도 마찬가지다. MCP로 도구를 연결해줘도, "이 상황에서 어떤 도구를 어떤 순서로, 어떤 기준으로 써야 하는지" 모르면 — 도구가 있어도 전문가처럼 행동하지 못한다.
스킬은 바로 이 "매뉴얼"을 AI에게 주는 것이다.
Anthropic의 Claude Code는 스킬 개념을 실제로 구현한 대표적 사례다. 개발자가 스킬을 호출하면, 해당 도메인의 전문 지식과 워크플로우가 에이전트에게 주입된다.
체계적 디버깅 스킬:
이 스킬이 활성화되면 에이전트는 단순히 "오류를 고쳐보겠습니다"가 아니라, 다음과 같은 체계적 절차를 따른다:
이것은 ReAct 논문의 Thought-Action-Observation 루프를 도메인 특화된 형태로 구현한 것이다. 범용 추론 루프를 "디버깅"이라는 특정 작업에 맞게 전문화한 것이다.
TDD 스킬:
코드를 작성하기 전에 테스트부터 작성하라는 워크플로우를 강제한다:
프론트엔드 디자인 스킬:
UI를 구현할 때 "동작하는 코드"에 그치지 않고, 디자인 원칙과 접근성 기준까지 적용한다. 타이포그래피 스케일, 색상 체계, 공간 배치의 원칙을 지식 계층으로 제공하고, "먼저 레이아웃을 잡고, 타이포그래피를 설정하고, 색상을 적용하라"는 워크플로우를 정의한다.
이것이 Voyager의 스킬 라이브러리가 현실 세계로 나온 모습이다. 마인크래프트에서 mineWood()를 저장해 재사용했듯, Claude Code에서 "디버깅 절차"를 스킬로 정의해 모든 대화에서 재사용한다.
스킬이 적용된 코드 에이전트와 그렇지 않은 에이전트의 차이는 극명하다.
| 비교 항목 | 도구만 있는 에이전트 | 스킬이 장착된 에이전트 |
|---|---|---|
| 파일 접근 | 읽고 쓸 수 있다 | 읽고 쓸 수 있다 |
| 명령 실행 | 터미널 명령을 실행한다 | 터미널 명령을 실행한다 |
| 작업 시작 | 어디부터 할지 모른다 | 테스트부터 작성한다 (TDD 스킬) |
| 버그 대응 | 산발적으로 수정을 시도한다 | 재현 → 가설 → 검증 순서로 접근한다 |
| 코드 품질 | 동작은 하지만 일관성 없음 | 컨벤션과 패턴을 따름 |
| 결과 | 회귀 버그, 비효율적 반복 | 체계적 접근, 일관된 품질 |
전통적 챗봇은 미리 정해진 시나리오만 처리한다. 도구가 연결된 AI 에이전트는 실제로 주문을 조회하고, 환불을 처리하고, 배송을 추적할 수 있다.
하지만 스킬 없이 도구만 연결하면 위험하다:
스킬이 각 계층에서 제공하는 것:
| 스킬 계층 | 고객 서비스에서의 역할 |
|---|---|
| 도구 접근 | CRM 조회, 주문 관리, 환불 처리 API |
| 지식 | 환불 정책, 배송 규정, 자주 묻는 질문 답변 |
| 워크플로우 | 사유 확인 → 이력 조회 → 정책 확인 → 처리/에스컬레이션 |
| 판단 | "10만 원 이하 즉시 환불, 이상은 검토", "PII는 마스킹 처리" |
데이터 분석가에게 MCP로 데이터베이스 연결을 제공하면, AI 에이전트가 자연어 질문을 SQL로 변환하고 실행할 수 있다. 하지만 좋은 분석에는 도구 이상의 것이 필요하다.
| 스킬 계층 | 데이터 분석에서의 역할 |
|---|---|
| 도구 접근 | SQL 실행, 차트 생성, 리포트 작성 |
| 지식 | 데이터 스키마 이해, 통계 방법론, 시각화 원칙 |
| 워크플로우 | 탐색적 분석 → 가설 수립 → 검증 → 인사이트 도출 → 리포트 |
| 판단 | "표본 크기가 부족하면 경고", "상관관계와 인과관계를 구분" |
가장 복잡한 사례다. 여러 에이전트가 협업할 때, 각 에이전트의 스킬이 전체 시스템의 품질을 결정한다.
이 구조는 마빈 민스키가 1986년에 제안한 "마음의 사회(Society of Mind)"를 직접적으로 구현한 것이다 — 각 에이전트는 단순하지만, 전문화된 스킬로 무장한 에이전트들의 협업이 복잡한 결과를 만들어낸다.
이 글에서 따라온 여정을 되짚어 보자.
LLM이 유리병 속의 두뇌였다면, 도구는 손을 달아준 것이고, 스킬은 전문 교육을 시킨 것이다. 이 세 가지가 갖춰졌을 때 비로소 AI는 실제 업무를 수행할 수 있는 존재가 된다.
스킬의 진화는 이제 시작이다. 세 가지 방향이 보인다:
1. 스킬의 자동 생성. Voyager가 마인크래프트에서 스킬을 자동 생성했듯, 실제 업무 환경에서도 성공적 작업 패턴을 자동으로 스킬화하는 시도가 진행 중이다. 에이전트가 반복적으로 성공하는 절차를 감지하고, 이를 재사용 가능한 스킬로 정제하는 것이다.
2. 스킬의 공유 생태계. MCP 서버가 누구나 만들어 공유할 수 있듯, 스킬도 "디버깅 스킬", "데이터 분석 스킬", "고객 응대 스킬"로 패키징되어 공유되는 생태계가 형성될 것이다. 도구의 표준화가 MCP로 이루어졌다면, 스킬의 표준화는 그 다음 과제다.
3. 스킬의 조합과 복합화. 기본 스킬을 조합해 고차원 스킬을 만드는 것이다. Voyager의 스킬 라이브러리가 점점 복잡한 행동을 가능하게 했듯, 업무 영역에서도 같은 패턴이 반복될 것이다 — 기획 스킬과 구현 스킬과 리뷰 스킬을 결합해 "풀스택 개발 스킬"을 만드는 식이다.
AI 에이전트의 능력은 결국 어떤 스킬을 가지고 있는가에 의해 결정된다. 모델의 파라미터 수나 벤치마크 점수가 아니라, 도메인에 특화된 스킬의 품질과 다양성이 에이전트의 실질적 가치를 만든다.
이것은 인간에게도 늘 그래왔던 원리다. 가장 똑똑한 사람이 아니라, 적절한 도구를 적절한 때에 적절한 방식으로 사용하는 사람이 가장 많은 것을 해낸다.
AI도 마찬가지다.



