인사이트
81개의 포스트

2026 AI 트렌드: 더 크게가 아니라 더 똑똑하게
모델은 작아지고, 에이전트는 협업하고, 추론은 현장으로 내려온다. 2026년 AI 산업의 핵심 변화를 관통하는 하나의 키워드 — 실용주의.

AI 정렬(Alignment)과 안전: 우리가 원하는 것을 기계에게 어떻게 전달하는가
1960년 위너의 경고에서 2025년 정렬 위장(alignment faking) 발견까지. AI가 인간의 의도대로 작동하게 만드는 정렬 문제의 역사, 기술, 사건, 그리고 실전적 의미를 추적한다.

Claude Cowork 완전 해부: AI 동료가 출근하자, 400조 원이 증발했다
2026년 1월, Anthropic이 Claude Cowork를 출시하자 소프트웨어 업계에서 약 285조 달러의 시가총액이 증발했다. 개발자가 아닌 일반 지식 노동자를 위한 AI 에이전트가 왜 이토록 큰 충격을 주었는가 — 탄생 배경부터 기술 원리, SaaSpocalypse, 실사용 사례, 센토어 모델까지.

AI 에이전트 생태계 지도 2026: 프로토콜, 프레임워크, 그리고 새로운 전쟁
2026년 3월, AI 에이전트 생태계는 단일 프로젝트가 아니라 산업 전체의 전환이다. 프로토콜(MCP, A2A)에서 프레임워크(OpenClaw, LangGraph, CrewAI), 엔터프라이즈(NemoClaw, Bedrock), 중국 생태계까지 — 전체 지형도를 그린다.

A2A 프로토콜: AI 에이전트의 HTTP가 탄생했다 — Google이 만들고 Linux Foundation이 품은 표준
LangGraph 에이전트와 CrewAI 에이전트가 서로 대화할 수 있다면? A2A(Agent-to-Agent) 프로토콜은 AI 에이전트 간의 발견·통신·협업을 표준화한다. Google이 설계하고, 50개 이상의 기업이 지지하며, Linux Foundation에 기증된 이 프로토콜의 핵심을 풀어본다.

AI에게 스킬이 필요한 이유: 논문에서 프로토콜까지, 도구를 쥔 AI의 진화
수학 올림피아드를 푸는 AI가 오늘 날씨를 모른다. LLM의 구조적 한계에서 출발해, Toolformer·ReAct·Voyager 등 핵심 논문의 원리를 풀어보고, Function Calling에서 MCP·스킬 시스템까지 이어지는 산업의 대응을 추적한다.

Sovereign AI: 왜 각국은 자기만의 AI를 만들려 하는가
130개 프로젝트, 50개 국가, 2.5조 달러. 각국이 앞다투어 자체 AI 인프라를 구축하는 이유 — 데이터 주권, 안보, 경제적 자립. 한국의 7,350억 달러 이니셔티브부터 프랑스 미스트랄, 일본 라쿠텐까지.

합성 데이터와 데이터 플라이휠: 인간의 데이터가 바닥날 때
인류가 만든 텍스트가 2028년이면 소진된다. 합성 데이터는 해답인가 함정인가? 1970년대 데이터 증강에서 2026년 자기 진화 플라이휠까지, 데이터의 미래를 논문과 프로덕션 사례로 추적한다.

AI 시대, 청년들은 왜 커리어를 다시 설계하는가 — 대체 불가능한 일의 조건
보험 사무직이 소방관을 준비하고, 컴퓨터공학도가 전기 기술을 배운다. AI가 화이트칼라의 안전지대를 무너뜨리면서, 젊은 세대는 '대체 불가능한 일'을 찾아 움직이고 있다. 데이터와 역사가 말하는 커리어 전환의 논리.
AI가 '모르는 것을 아는' 법을 배우다 — Process Reward Model의 불확실성 캘리브레이션
수학 문제를 풀 때 AI는 '이 풀이가 맞을 확률'을 심각하게 과대평가한다. MIT 연구팀은 분위수 회귀로 이 과신을 교정하고, 문제 난이도에 따라 연산량을 자동 조절하는 프레임워크를 제안했다. NeurIPS 2025 논문을 쉽게 풀어본다.

EU AI Act 완전 가이드: 세계 최초 AI 규제, 한국 기업이 알아야 할 모든 것
2026년 8월, EU AI Act가 전면 시행된다. 한국 기업도 EU에 AI 제품을 판매하면 적용 대상이다. 리스크 기반 4단계 분류, 금지 관행 8가지, 최대 매출의 7% 벌금 — 그리고 한국 AI 기본법과의 비교까지.
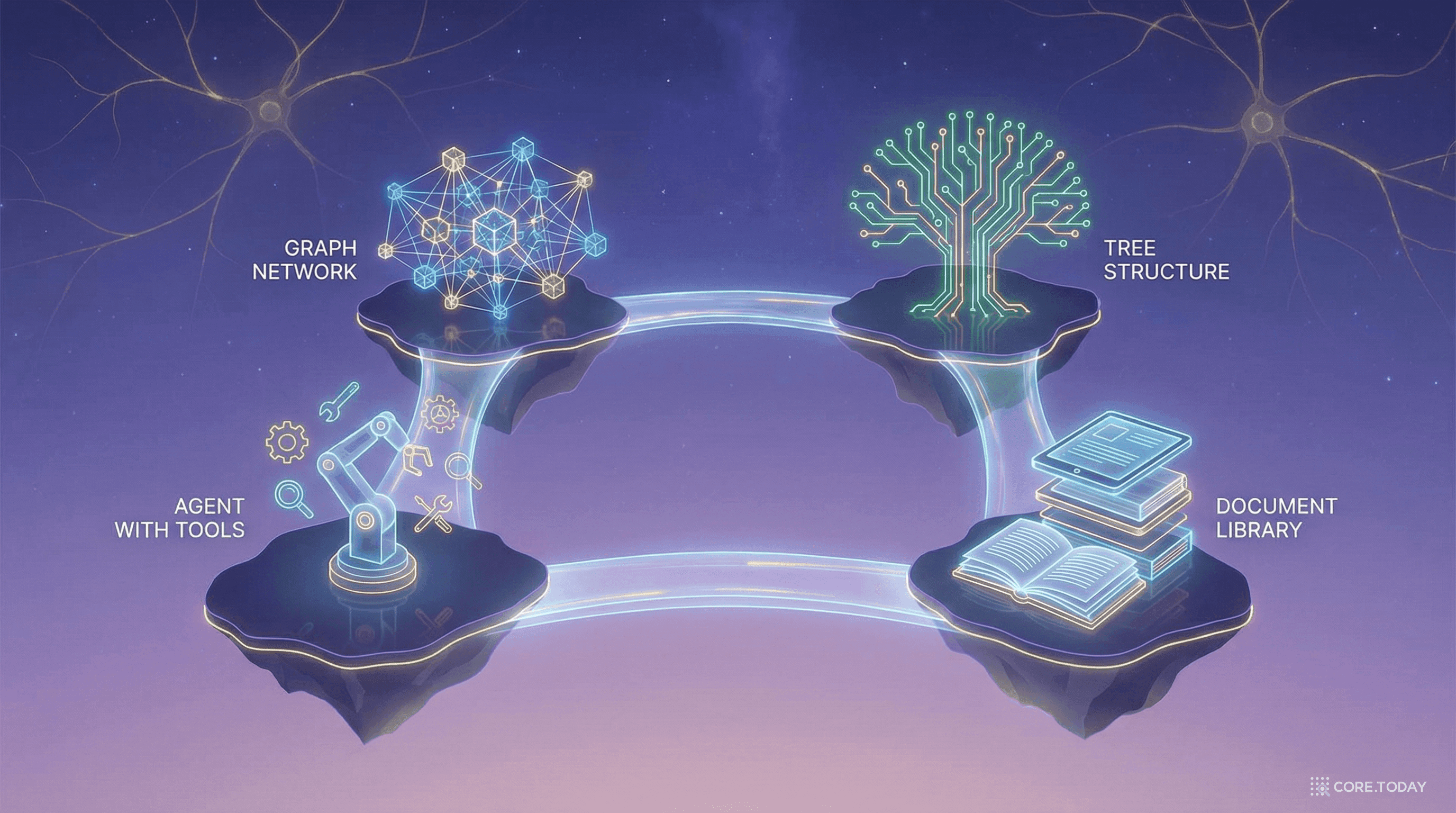
RAG 생태계 완전 가이드: Naive RAG에서 Agentic RAG까지, 언제 무엇을 선택할 것인가
RAG는 이제 하나의 기술이 아니라 하나의 생태계다. 지식 그래프를 활용하는 GraphRAG, 스스로 판단하는 Self-RAG, 에이전트로 진화한 Agentic RAG까지 — 각 접근법이 해결하는 문제와 선택 기준을 논문 기반으로 정리한다.