블로그로 돌아가기
객체 검출논문 리뷰DEIMv2DINOv3STA실시간 AI엣지 AI
DEIMv2 완전 이해: DINOv3와 만난 실시간 검출 — 0.5M에서 50M까지, 하나의 프레임워크
0.49M 파라미터의 초소형 Atto부터 57.8% AP의 거대 X까지 — DINOv3의 강력한 표현력을 STA로 실시간에 녹여낸 DEIMv2가 8개 스케일로 GPU, 엣지, 모바일을 동시에 정복한 이야기.
코어닷투데이2026-03-2432분
0.49M 파라미터의 초소형 Atto부터 57.8% AP의 거대 X까지 — DINOv3의 강력한 표현력을 STA로 실시간에 녹여낸 DEIMv2가 8개 스케일로 GPU, 엣지, 모바일을 동시에 정복한 이야기.
상상해보자. 당신은 객체 검출 AI를 배포해야 한다.
클라우드 GPU 서버에 올릴 최고 성능 모델도 필요하고, 자율주행차의 엣지 디바이스용 모델도 필요하고, 스마트 도어벨의 초소형 모바일 칩용 모델도 필요하다. 지금까지 이 세 가지 시나리오는 각각 다른 프레임워크, 다른 아키텍처, 다른 학습 전략을 요구했다. 고성능에는 RT-DETR/D-FINE, 엣지에는 YOLOv8-S, 모바일에는 NanoDet — 세 개의 별개 시스템을 운영해야 했다.
2026년 1월, Intellindust AI Lab과 샤먼대학교(Xiamen University)의 연구팀이 이 분열을 종식시켰다.
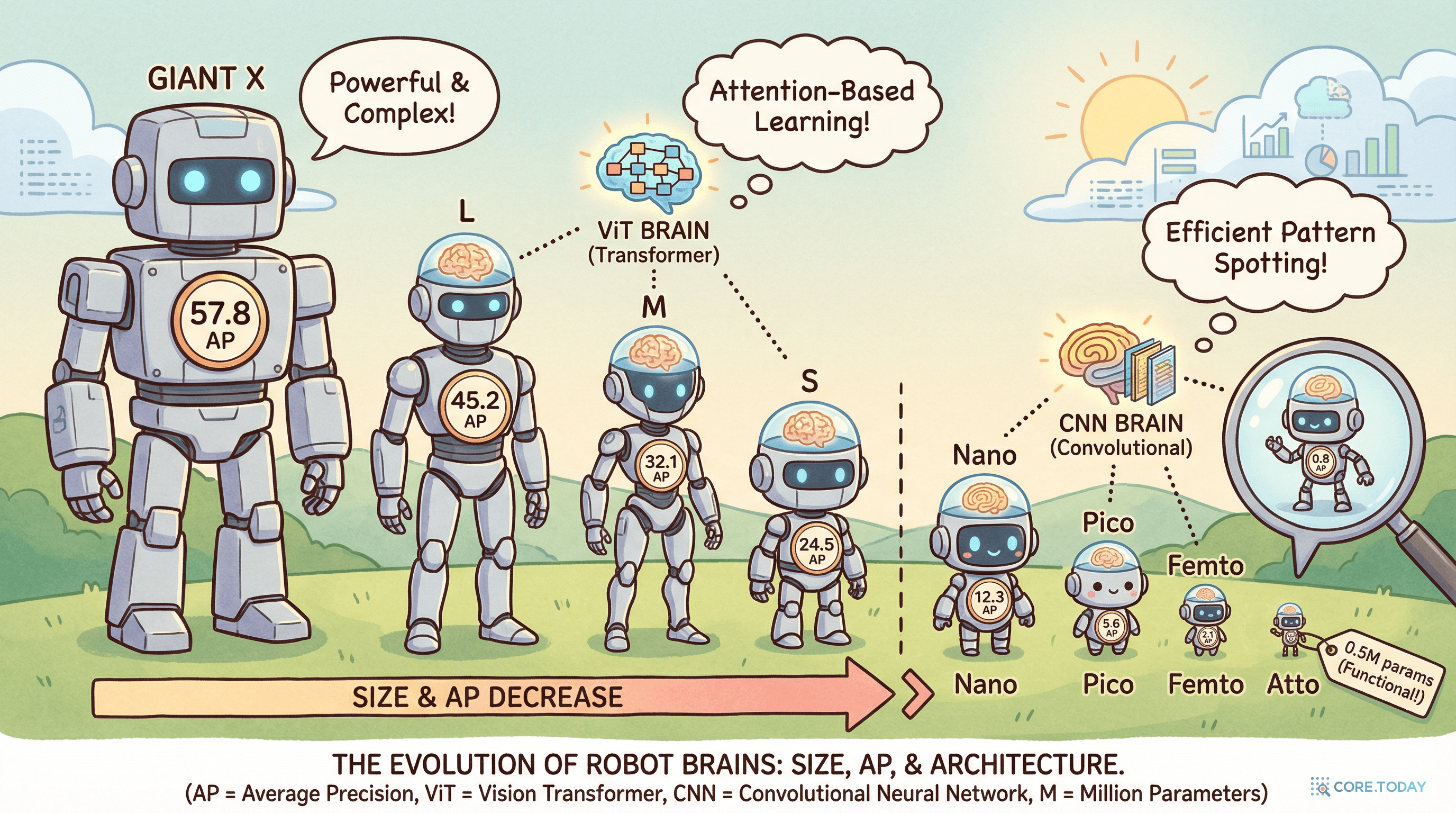
DEIMv2는 단일 프레임워크로 8개의 모델 스케일을 아우른다. 가장 큰 DEIMv2-X는 57.8% AP(50M 파라미터)로 D-FINE-X(55.8%, 62M)를 넘어서고, 가장 작은 DEIMv2-Atto는 0.49M 파라미터(49만 개!)로도 23.8% AP를 달성한다.
사이에는 L(56.0%), M(53.0%), S(50.9%), Nano(43.0%), Pico(38.5%), Femto(31.0%)가 있다. 특히 DEIMv2-S는 10M 미만 파라미터로 50 AP를 돌파한 최초의 모델이다.
비밀은 DINOv3라는 비전 파운데이션 모델과의 만남, 그리고 그 만남을 실시간에 가능하게 한 STA(Spatial Tuning Adapter)에 있다.
DINOv3는 2025년 발표된 최신 비전 파운데이션 모델이다. 대규모 자기지도학습(self-supervised learning)으로 학습되어, 객체의 윤곽, 질감, 의미론적 관계까지 풍부하게 표현할 수 있다. 하지만 두 가지 근본적 문제가 실시간 검출에서의 직접 사용을 가로막는다.
문제 1: 단일 스케일 출력. DINOv3는 ViT(Vision Transformer) 기반이다. ViT는 이미지를 패치로 나누어 처리하며, 단일 스케일(1/16)의 특징만 출력한다. 하지만 객체 검출에서는 작은 객체(1/8 스케일), 중간 객체(1/16 스케일), 큰 객체(1/32 스케일)를 모두 검출해야 한다. 멀티스케일 특징이 필수적이다.
기존 방법인 ViTDet의 Feature2Pyramid는 디컨볼루션(deconvolution)으로 멀티스케일을 생성하지만, 추가 연산량이 크고 실시간에 적합하지 않다.
문제 2: 높은 연산 비용. DINOv3-ViT-Small만 해도 실시간 검출기의 백본으로 사용하기에는 무겁다. 그대로 사용하면 지연 시간이 실시간 기준을 초과한다.
DEIMv2의 전신인 DEIM(2025, CVPR)은 Dense O2O 매칭과 D-FINE의 FDR/GO-LSD를 결합한 검출기였다. HGNetv2 백본을 사용하여 DEIM-X가 56.5% AP를 달성했지만, CNN 백본의 표현력 한계에 부딪혔다.
연구팀은 묻는다. "DINOv3의 강력한 표현력을 실시간 DETR 프레임워크에 직접 통합할 수 있을까? RT-DETRv4처럼 학습 시에만 사용하는 증류가 아니라, 추론 시에도 DINOv3 백본을 직접 활용하면서 실시간을 유지할 수 있을까?"
답은 STA(Spatial Tuning Adapter)에 있다.
STA의 설계 철학은 놀라울 정도로 단순하다.
ViTDet의 Feature2Pyramid는 ViT의 최종 출력을 디컨볼루션으로 변환하여 멀티스케일을 생성한다. 무겁고 복잡하다.
STA는 다르게 접근한다. DINOv3의 중간 블록들에서 직접 특징을 추출하여 멀티스케일을 구성한다.
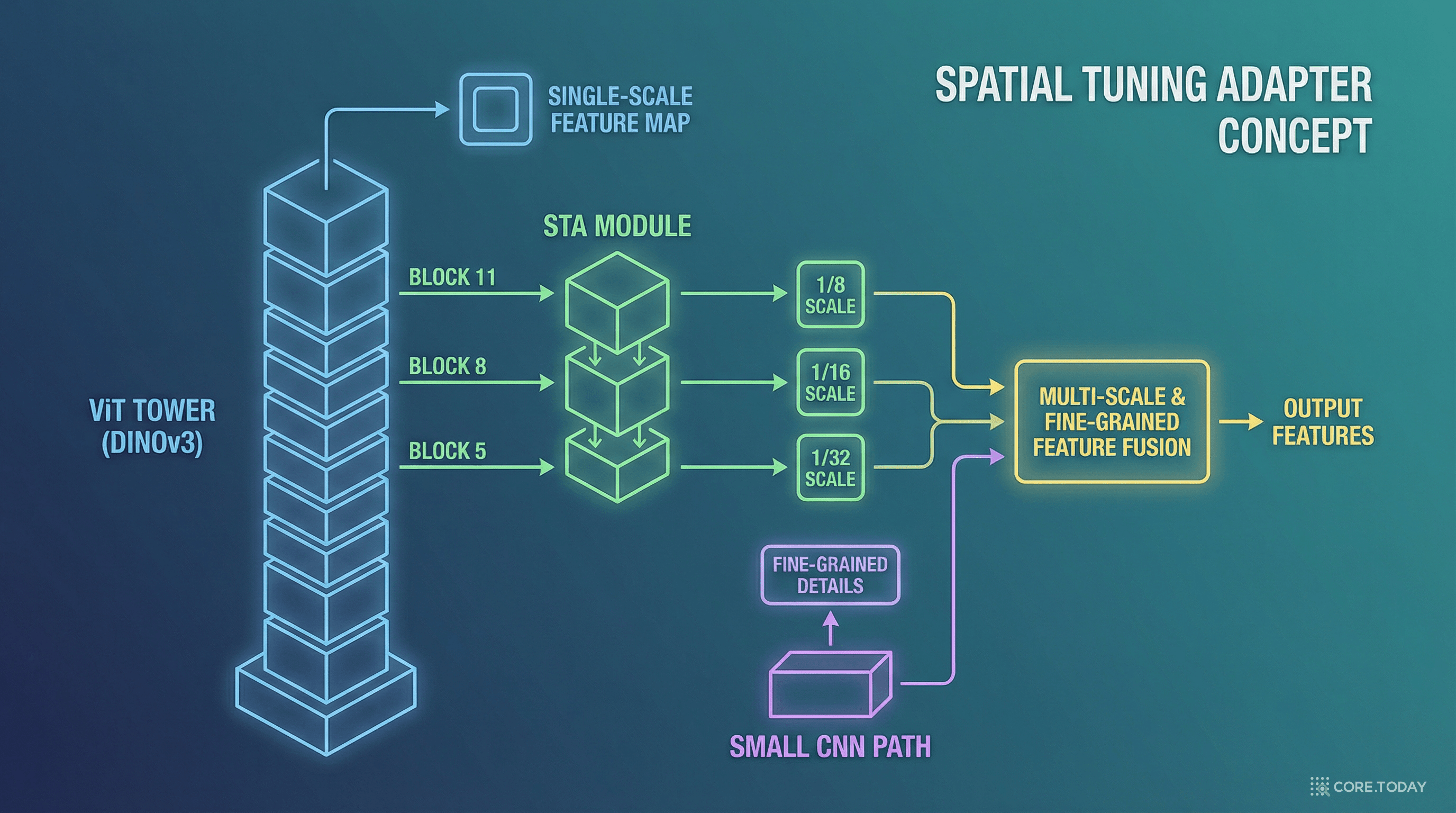
STA의 핵심 구성요소인 Bi-Fusion은 두 가지 경로의 특징을 합친다.
왜 두 경로가 모두 필요한가? DINOv3는 글로벌 의미론에서 탁월하지만, 세밀한 공간 디테일(fine-grained details)은 상대적으로 약하다. 논문의 분석에 따르면, DEIMv2의 주된 성능 향상은 중대형 객체(AP_M, AP_L)에서 나오며, 소형 객체(AP_S)는 DEIM과 유사한 수준이다. 이것은 DINOv3가 글로벌 맥락 파악에는 뛰어나지만, 작은 객체의 세밀한 위치 정보는 CNN이 더 잘 포착한다는 것을 의미한다. STA의 CNN 경로가 바로 이 부족한 부분을 보완한다.
RT-DETRv4와 DEIMv2 모두 DINOv3의 지식을 활용하지만, 접근 방식이 근본적으로 다르다.
| 특성 | RT-DETRv4 | DEIMv2 |
|---|---|---|
| VFM 사용 시점 | 학습 시에만 (증류) | 추론 시에도 직접 사용 |
| 백본 | HGNetv2 (CNN, 고정) | DINOv3-ViT (직접 백본) |
| 추론 시 VFM | 제거됨 (비용 0) | 백본으로 사용 (비용 포함) |
| 멀티스케일 생성 | CCFF (기존 방식) | STA (경량 어댑터) |
| 장점 | 배포 아키텍처 불변 | VFM 표현력 직접 활용 |
RT-DETRv4: "거인(VFM)에게 학습만 받고, 추론 시에는 혼자 달린다" → 배포 비용 제로 DEIMv2: "거인(VFM)을 작게 만들어서 함께 달린다" → VFM 표현력 직접 활용
DEIMv2의 8개 변형은 두 가지 백본 계열로 나뉜다.
ViT 계열 (S, M, L, X): DINOv3 기반
증류를 사용하여 S→M→L→X로 매끄러운 스케일링 경로를 보장한다.
HGNetv2 계열 (Nano, Pico, Femto, Atto): CNN 기반
DEIMv2는 디코더도 경량화했다.
| 기존 디코더 | DEIMv2 디코더 |
|---|---|
| FFN (Feed-Forward Network) | SwiGLUFFN (더 강한 비선형성) |
| LayerNorm | RMSNorm (더 빠른 정규화) |
| 레이어별 개별 위치 임베딩 | 단일 공유 위치 임베딩 (연산 절약) |
쿼리의 위치가 디코더 레이어를 거치면서 크게 변하지 않는다는 관찰에 기반하여, 모든 디코더 레이어에서 하나의 위치 임베딩을 공유한다. 이 단순한 설계가 불필요한 연산을 제거한다.
DEIM의 Dense O2O는 학습 이미지당 객체 수를 늘려 감독 신호를 강화하는 전략이다. DEIMv2는 여기에 Copy-Blend 증강을 추가한다.
기존 Copy-Paste는 객체를 잘라내어 다른 이미지에 붙여넣기(overwrite)한다. DEIMv2의 Copy-Blend는 객체를 혼합(blend)하여 더 자연스러운 합성을 만든다. 이것이 Dense O2O의 효과를 더 높인다.
| S 모델 | 에폭 | 파라미터 | GFLOPs | AP (%) |
|---|---|---|---|---|
| YOLOv10-S | 500 | 7M | 22 | 46.3 |
| YOLO11-S | 500 | 9M | 22 | 46.6 |
| YOLOv12-S-turbo | 600 | 9M | 19 | 47.5 |
| D-FINE-S | 120 | 10M | 25 | 48.5 |
| DEIM-S | 120 | 10M | 25 | 49.0 |
| DEIMv2-S | 120 | 10M | 26 | 50.9 |
DEIMv2-S: 10M 미만으로 50 AP를 돌파한 최초의 모델. DEIM-S(49.0%)를 +1.9%, D-FINE-S(48.5%)를 +2.4% 능가한다. 동일한 파라미터 수에서 ViT 백본이 CNN 백본보다 압도적으로 우수함을 증명한다.
| X 모델 | 에폭 | 파라미터 | GFLOPs | AP (%) |
|---|---|---|---|---|
| YOLO11-X | 500 | 57M | 195 | 54.7 |
| YOLOv12-X-turbo | 600 | 59M | 185 | 55.7 |
| D-FINE-X | 72 | 62M | 202 | 55.8 |
| DEIM-X | 50 | 62M | 202 | 56.5 |
| RT-DETRv2-X | 72 | 76M | 259 | 54.3 |
| DEIMv2-X | 50 | 50M | 151 | 57.8 |
DEIMv2-X: 57.8% AP, 50M 파라미터, 151 GFLOPs. DEIM-X(56.5%, 62M, 202G)보다 +1.3% AP이면서 파라미터 19% 적고 GFLOPs 25% 적다. 더 정확하면서 더 가볍다.
DEIMv2의 가장 인상적인 부분은 초경량 영역이다.
| 초경량 모델 | 파라미터 | GFLOPs | AP (%) |
|---|---|---|---|
| NanoDet-M | 1.0M | 0.7 | 23.5 |
| DEIMv2-Atto | 0.49M | 0.8 | 23.8 |
| PicoDet-S | 1.0M | 1.2 | 30.7 |
| DEIMv2-Femto | 1.0M | 1.7 | 31.0 |
| YOLOv10-N | 2.3M | 6.7 | 38.5 |
| DEIMv2-Pico | 1.5M | 5.2 | 38.5 |
DEIMv2-Pico는 YOLOv10-Nano와 동일한 38.5% AP를 달성하면서, 파라미터는 ~50% 적다 (1.5M vs 2.3M). 모바일과 IoT 디바이스에서 이 차이는 결정적이다.
DEIMv2-Atto는 0.49M 파라미터 — 49만 개. 일반적인 스마트워치나 초소형 MCU에도 올릴 수 있는 크기다. 그러면서도 NanoDet-M(1.0M)보다 높은 23.8% AP를 달성한다.
흥미로운 관찰이 있다. DEIMv2(ViT 백본)와 DEIM(CNN 백본)을 비교하면:
| 지표 | DEIM-S (CNN) | DEIMv2-S (ViT) | 차이 |
|---|---|---|---|
| AP (전체) | 49.0 | 50.9 | +1.9 |
| APS (소형) | 30.4 | 31.4 | +1.0 |
| APM (중형) | 52.6 | 55.3 | +2.7 |
| APL (대형) | 65.7 | 70.3 | +4.6 |
소형 객체에서는 +1.0이지만, 대형 객체에서는 +4.6이나 향상. DINOv3의 강력한 글로벌 의미론이 중대형 객체의 인식을 크게 개선하는 반면, 소형 객체의 세밀한 위치 정보는 여전히 도전적이다. 이것은 STA의 CNN 경로가 중요한 이유이기도 하다 — DINOv3만으로는 부족한 세밀한 디테일을 보완해야 한다.
DEIMv2의 학습 목표는 D-FINE의 유산을 이어받는 다섯 가지 손실의 가중합이다.
주목할 점: FGL과 DDF 손실은 Pico, Femto, Atto에는 적용하지 않는다. 초소형 모델은 용량이 제한되어 자기 증류(self-distillation)의 효과가 떨어지고, 오히려 성능을 저하시킬 수 있기 때문이다. 이 관찰은 모델 크기에 따른 학습 전략의 차별화가 중요하다는 실무적 교훈을 제공한다.
DEIMv2의 진정한 가치는 통합(unification)에 있다.
같은 프레임워크, 같은 학습 파이프라인, 같은 API. 크기만 다를 뿐 설계 철학은 동일하다. 이것은 개발 효율성과 유지보수 용이성에서 큰 장점이다.
이 시리즈의 다섯 번째이자 마지막 글로서, 객체 검출 10년의 여정을 정리하자.
DEIMv2가 보여주는 것은 이것이다.
객체 검출의 미래는 "하나의 거대 모델"이 아니라, "하나의 프레임워크에서 파생되는 다양한 크기의 모델"이다.
0.49M 파라미터의 Atto와 50M 파라미터의 X는 100배의 크기 차이가 있지만, 같은 설계 원리, 같은 학습 파이프라인, 같은 STA 어댑터의 철학을 공유한다. 큰 모델은 DINOv3의 ViT를 직접 백본으로, 작은 모델은 HGNetv2의 CNN을 백본으로 사용하지만, 디코더, 손실 함수, Dense O2O의 핵심은 동일하다.
이 통합의 가치는 실무에서 빛난다. 한 번 익힌 프레임워크로 GPU 서버부터 MCU까지 모든 배포 환경을 커버할 수 있다. 하나의 팀이 하나의 코드베이스로 전체 제품 라인을 관리할 수 있다.
57.8% AP. 50 AP 돌파. 0.49M 파라미터. 이 숫자들은 인상적이다. 하지만 가장 인상적인 것은, 이 모든 것이 하나의 프레임워크에서 나왔다는 사실이다.
크기가 다를 뿐, 눈은 같다. 그것이 DEIMv2의 메시지다.