
블로그로 돌아가기
객체 검출논문 리뷰RT-DETRDETR트랜스포머실시간 AINMS
RT-DETR 완전 이해: DETR가 YOLO를 이긴 날 — 실시간 트랜스포머 검출의 혁명
NMS 없이 실시간으로 — YOLO의 왕좌에 도전한 최초의 실시간 엔드투엔드 트랜스포머 검출기 RT-DETR가 어떻게 탄생했고, 왜 객체 검출의 패러다임을 바꾸고 있는지를 두 편의 논문과 함께 풀어본다.
코어닷투데이2025-11-0453분
NMS 없이 실시간으로 — YOLO의 왕좌에 도전한 최초의 실시간 엔드투엔드 트랜스포머 검출기 RT-DETR가 어떻게 탄생했고, 왜 객체 검출의 패러다임을 바꾸고 있는지를 두 편의 논문과 함께 풀어본다.
고속도로를 상상해보자.
당신은 시속 200km로 달리는 스포츠카를 운전하고 있다. 도로는 텅 비어 있고, 엔진은 완벽하게 작동하며, 내비게이션은 최적 경로를 안내한다. 목적지까지 10분이면 충분하다 — 만약 톨게이트가 없다면.
그런데 고속도로 출구에 톨게이트가 있다. 차 한 대씩 정차하고, 요금을 계산하고, 바를 올리고, 다시 출발한다. 앞에 차가 많으면 줄이 길어진다. 차가 적으면 빨리 통과한다. 그날그날 다르고, 예측할 수 없다. 아무리 차가 빨라도, 톨게이트에서의 대기 시간은 차의 성능과 무관하다.
2023년까지의 실시간 객체 검출 — 즉 YOLO 시리즈 — 이 바로 이 상황이었다.
YOLO는 놀라울 정도로 빠른 검출기다. YOLOv8-X는 53.9% AP라는 높은 정확도를 달성하고, 신경망 추론 자체는 매우 빠르다. 하지만 YOLO의 출력에는 수천 개의 중복된 바운딩 박스가 포함되어 있다. 한 객체에 대해 여러 개의 박스가 겹쳐서 나온다. 이 중복을 제거하기 위해 반드시 거쳐야 하는 후처리 단계가 있다. 바로 NMS(Non-Maximum Suppression)다.
NMS는 YOLO의 톨게이트다. 아무리 신경망이 빨라도, NMS에서 멈춰야 한다. 그리고 이 대기 시간은 입력 이미지에 따라 달라진다 — 객체가 많으면 느리고, 적으면 빠르다. 더 나쁜 것은, NMS에는 두 개의 하이퍼파라미터(신뢰도 임계값, IoU 임계값)가 있어서, 이 값을 어떻게 설정하느냐에 따라 정확도와 속도가 모두 변한다.
2024년, Baidu의 연구팀이 이 문제를 정면으로 돌파했다.
"DETRs Beat YOLOs on Real-time Object Detection" — 제목부터 대담하다. "DETR가 YOLO를 이긴다." 그들은 트랜스포머 기반 검출기인 DETR를 실시간으로 동작하도록 재설계하여, NMS 없이도 YOLO를 속도와 정확도 모두에서 앞서는 RT-DETR를 만들었다. COCO 데이터셋에서 53.1% AP, 초당 108프레임. YOLO-X 모델들보다 빠르고 정확하며, 동시에 NMS라는 교통체증에서 해방된 최초의 실시간 엔드투엔드 검출기가 탄생한 것이다.
이 글은 RT-DETR의 탄생부터 RT-DETRv2의 진화까지, 두 편의 논문을 깊이 있게 풀어낸다.
2020년, Facebook AI Research의 Nicolas Carion 등이 발표한 DETR(DEtection TRansformer)은 객체 검출 분야에 지각변동을 일으켰다.
DETR의 핵심 아이디어는 단순하지만 혁명적이었다. 앵커 박스도 없고, NMS도 없다. 이미지를 트랜스포머 인코더-디코더에 넣으면, 고정된 수의 객체 쿼리(object query)가 직접 최종 검출 결과를 예측한다. 중복 검출을 제거하는 후처리가 필요 없다. 헝가리안 매칭(Hungarian matching)으로 예측과 실제 객체를 일대일 대응시키기 때문에, 학습 과정에서 이미 중복이 억제된다.
DETR는 아름다운 아이디어였지만, 치명적인 문제들이 있었다.
첫째, 학습이 극도로 느렸다. 수렴까지 500 에폭이 필요했다. 같은 COCO 데이터셋에서 Faster R-CNN은 36 에폭이면 충분했다. 약 14배 느린 학습 속도.
둘째, 추론이 느렸다. 멀티스케일 특징을 처리하는 트랜스포머 인코더의 연산량이 막대했다. DINO-Deformable-DETR-R50은 50.9% AP를 달성했지만, 초당 5프레임(FPS)에 불과했다. 실시간(30+ FPS)과는 거리가 먼 속도.
셋째, 작은 객체 검출이 약했다. 원래 DETR는 단일 스케일 특징만 사용했기 때문에, 작은 객체의 정보가 다운샘플링 과정에서 손실되었다.
이후 수많은 연구가 DETR의 문제를 해결하려 시도했다.
| 모델 | 핵심 혁신 | 해결한 문제 |
|---|---|---|
| Deformable DETR (2020) | 변형 가능 어텐션 (Deformable Attention) | 학습 수렴 가속, 멀티스케일 특징 |
| DAB-DETR (2022) | 동적 앵커 박스 쿼리 | 쿼리 초기화 최적화 |
| DN-DETR (2022) | 디노이징 학습 (Denoising Training) | 학습 수렴 가속 |
| DINO (2022) | 혼합 쿼리 선택 + 디노이징 | 정확도 향상 |
| Efficient DETR (2021) | 인코더/디코더 층 수 축소 | 연산 비용 절감 |
| Group-DETR (2022) | 그룹별 일대다 할당 | 학습 수렴 가속 |
이 연구들은 각각 DETR의 한 가지 문제를 개선했지만, 그 어떤 것도 실시간을 달성하지 못했다. 가장 강력한 DINO-Deformable-DETR도 5 FPS에 머물렀다. DETR 계열은 "아름답지만 느린 검출기"라는 인식이 고착되었다.
한편, 같은 시기에 YOLO 시리즈는 v5, v6, v7, v8로 빠르게 진화하며 실시간 검출의 왕좌를 굳건히 지키고 있었다.
질문은 이것이었다. DETR의 엔드투엔드라는 우아한 장점을 살리면서, YOLO와 경쟁할 수 있는 속도를 달성할 수 있을까?
NMS가 정확히 무엇이고 왜 문제인지, 먼저 이해해보자.
YOLO 같은 검출기는 이미지 위에 수천 개의 바운딩 박스를 예측한다. 대부분은 중복이다. 한 마리의 강아지에 대해 30개의 박스가 미세하게 다른 위치와 크기로 겹쳐 있다. NMS는 이 중복을 제거하는 알고리즘이다.
이 과정은 각 클래스별로 반복되어야 하고, 박스가 많을수록 비교 횟수가 기하급수적으로 증가한다.
RT-DETR 논문은 NMS의 문제를 정량적으로 분석한다. YOLOv5(앵커 기반)와 YOLOv8(앵커 프리)에서 신뢰도 임계값에 따른 남은 박스 수를 측정한 결과:
그리고 NMS 임계값에 따른 정확도와 처리 시간의 관계를 분석한다.
| IoU 임계값 (Conf=0.001) | AP (%) | NMS 시간 (ms) |
|---|---|---|
| 0.5 | 52.1 | 2.24 |
| 0.6 | 52.6 | 2.29 |
| 0.8 | 52.8 | 2.46 |
| Conf 임계값 (IoU=0.7) | AP (%) | NMS 시간 (ms) |
|---|---|---|
| 0.001 | 52.9 | 2.36 |
| 0.01 | 52.4 | 1.73 |
| 0.05 | 51.2 | 1.06 |
핵심 관찰 세 가지:
1. NMS 시간은 입력에 따라 달라진다. 신뢰도 임계값이 낮으면(더 많은 박스가 살아남으면) NMS가 느려지고, 높으면 빨라진다. 이것은 실시간 시스템에서 지연 시간을 예측할 수 없다는 뜻이다.
2. 정확도와 속도가 상충한다. 최적의 정확도(52.9% AP)를 얻으려면 낮은 신뢰도 임계값(0.001)이 필요한데, 이때 NMS 시간이 2.36ms로 늘어난다. 빠른 NMS(1.06ms)를 원하면 높은 임계값(0.05)을 써야 하는데, 그러면 정확도가 51.2%로 떨어진다.
3. YOLO 벤치마크는 NMS 시간을 빼고 보고한다. 대부분의 YOLO 논문은 신경망 추론 시간만 보고하고, NMS 시간은 제외한다. 이것은 공정한 비교가 아니다. RT-DETR 논문은 이를 지적하며, NMS를 포함한 엔드투엔드 속도 벤치마크를 제안한다.
NMS를 완전히 제거하면 세 가지 이점이 있다.
예측 가능한 지연 시간. 입력이 무엇이든 동일한 처리 시간이 걸린다. 자율주행, 산업 검사 등 지연 시간이 결정적인 응용에서 필수적이다.
하이퍼파라미터 제거. 신뢰도 임계값과 IoU 임계값이라는 두 개의 하이퍼파라미터를 튜닝할 필요가 없다. 시나리오가 바뀌어도 모델을 수정할 필요가 없다.
진정한 엔드투엔드 최적화. 신경망의 출력이 곧 최종 결과다. 전체 파이프라인을 하나의 손실 함수로 최적화할 수 있다.
이것이 RT-DETR가 해결하고자 한 문제의 본질이다. DETR의 NMS-free 아키텍처를 실시간 속도로 끌어올리는 것.
RT-DETR 팀은 두 단계 전략을 세웠다.
1단계: 정확도를 유지하면서 속도를 올린다. → 효율적 하이브리드 인코더 설계 2단계: 속도를 유지하면서 정확도를 높인다. → 불확실성 최소화 쿼리 선택
RT-DETR의 전체 구조는 네 부분으로 이루어진다.
RT-DETR 논문의 가장 예리한 통찰은 인코더의 연산량 대비 기여도 분석이다.
Deformable-DETR에서 인코더는 전체 GFLOPs의 49%를 차지하지만, AP에 대한 기여는 11%에 불과하다. 연산의 절반을 쓰면서 성능의 1/10만 기여하고 있었다. 왜 이런 비효율이 발생할까?
원인은 멀티스케일 특징의 무차별 처리에 있다. 기존 DETR들은 S3(저수준), S4(중간), S5(고수준)의 세 스케일 특징을 하나로 합쳐서(concatenate) 트랜스포머 인코더에 넣었다. 이 합쳐진 시퀀스는 매우 길고, 어텐션의 시간복잡도는 시퀀스 길이의 제곱에 비례하므로, 연산량이 폭발적으로 증가한다.
하지만 직관적으로 생각해보자. 고수준 특징(S5)은 객체의 의미론적 정보(semantic information)를 담고 있다 — "이것은 자동차다", "이것은 사람이다". 저수준 특징(S3)은 세밀한 공간 정보(edge, texture)를 담고 있다. 이 둘을 합쳐서 한꺼번에 처리하는 것은, 마치 기업의 경영 회의에서 전략적 의사결정과 세부 실무를 동시에 논의하는 것과 같다. 비효율적이다.
RT-DETR는 이 문제를 두 가지 역할을 분리하여 해결한다.
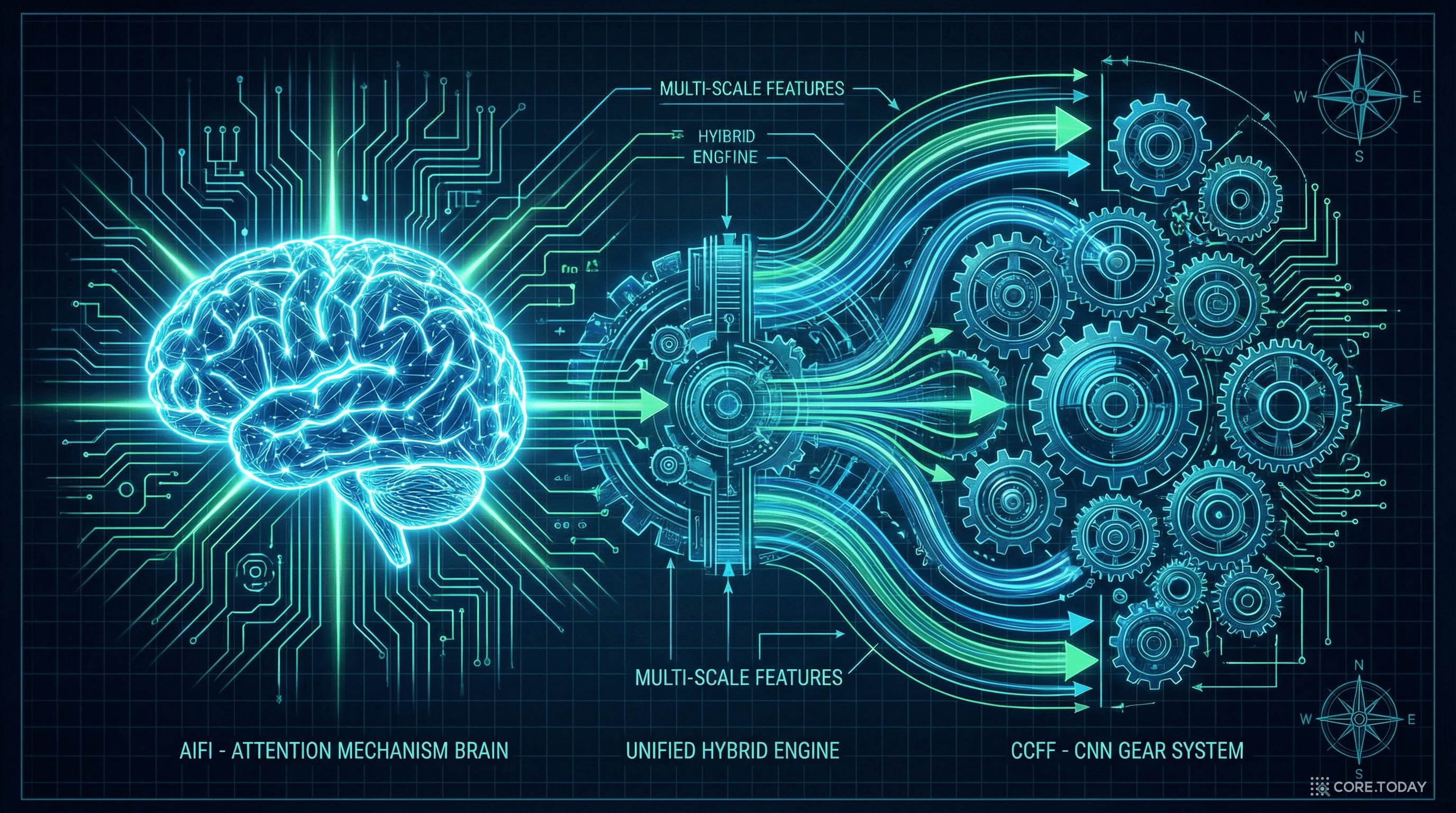
AIFI (Attention-based Intra-scale Feature Interaction):
셀프 어텐션을 S5(가장 고수준) 특징에만 적용한다. S3, S4에는 적용하지 않는다.
왜 S5만? 고수준 특징에는 풍부한 의미론적 개념(semantic concept)이 담겨 있다. 이 개념들 사이의 관계를 파악하는 것 — 예를 들어 "이 자동차 옆에 이 사람이 있다"는 맥락 — 은 후속 모듈의 객체 인식에 직접적으로 도움이 된다. 반면 저수준 특징은 의미론적 정보가 부족하여, 어텐션으로 상호작용시켜도 효과가 적고 오히려 노이즈만 추가할 수 있다.
실험 결과가 이를 확인한다. S5에만 어텐션을 적용하면(variant ) variant D 대비 지연 시간은 35% 감소하면서 AP는 0.4% 오히려 향상된다. 덜 하는 것이 더 나은 결과를 낳은 것이다.
CCFF (CNN-based Cross-scale Feature Fusion):
서로 다른 스케일의 특징을 합치는 작업은 CNN 기반 퓨전 블록이 담당한다. 각 퓨전 블록은 두 개의 1×1 합성곱과 N개의 RepBlock으로 구성되며, 인접한 두 스케일의 특징을 합성한다.
S5를 셀프 어텐션으로 정제한 뒤, 그 결과를 S3, S4와 함께 CNN으로 퓨전하는 것이다. 어텐션은 글로벌한 관계 파악에 강하고, CNN은 로컬한 특징 융합에 강하다. 둘의 장점을 결합한 것이 "하이브리드"의 의미다.
논문은 5가지 인코더 변형을 단계적으로 실험하여, 각 설계 결정의 효과를 검증한다.
| 변형 | 구조 | AP (%) | 파라미터 (M) | 지연 시간 (ms) |
|---|---|---|---|---|
| A | 인코더 없음 (기준) | 43.0 | 31 | 7.2 |
| B | A + 단일 스케일 트랜스포머 | 44.9 | 32 | 11.1 |
| C | B + 교차 스케일 퓨전 | 45.6 | 32 | 13.3 |
| D | C에서 내부/교차 분리 | 46.4 | 35 | 12.2 |
| DS5 | D에서 S5에만 어텐션 | 46.8 | 35 | 7.9 |
| E (RT-DETR) | AIFI + CCFF | 47.9 | 42 | 9.3 |
A→B: 트랜스포머 인코더를 추가하면 +1.9% AP이지만, 지연이 54% 증가 B→C: 교차 스케일 퓨전 추가 → +0.7% AP, 지연 20% 증가 C→D: 내부/교차를 분리 → +0.8% AP, 지연 8% 감소 (분리하면 더 빠르다!) D→DS5: S5에만 어텐션 → +0.4% AP, 지연 35% 감소 (덜 하면 더 낫다!) D→E: CCFF 적용 → +1.5% AP, 지연 24% 감소
최종 변형 E(RT-DETR)는 기준 A 대비 +4.9% AP이면서 지연은 단 +2.1ms만 증가했다. 효율적인 설계의 승리다.
DETR 시리즈에서 디코더에 넣는 초기 쿼리(query)의 품질은 최종 성능에 직접적인 영향을 미친다. 기존 DETR 변형들(DINO, Deformable-DETR 등)은 인코더 출력에서 분류 점수(classification score)가 가장 높은 상위 K개를 선택하여 초기 쿼리로 사용했다.
하지만 여기에 함정이 있다. 검출기는 "무엇인지(분류)"와 "어디에 있는지(위치)"를 동시에 맞춰야 한다. 분류 점수만 보고 쿼리를 선택하면, 분류는 잘 맞추지만 위치가 부정확한 특징이 선택될 수 있다. 이런 특징은 디코더에 불확실성(uncertainty)을 주입하여 최종 성능을 저하시킨다.
논문은 이 불확실성을 정량적으로 정의한다.
불확실성 U는 분류 예측과 위치 예측의 불일치다. 분류는 "자동차"라고 확신하는데 위치는 부정확하면, 불확실성이 높다. 둘 다 정확하면 불확실성이 낮다.
RT-DETR는 이 불확실성을 손실 함수에 직접 통합한다.
분류 손실을 계산할 때 불확실성을 함께 최적화함으로써, 분류와 위치가 동시에 정확한 특징을 선택하도록 학습을 유도한다.
논문은 두 쿼리 선택 방식의 차이를 시각적으로 보여준다. 분류 점수와 IoU 점수를 축으로 한 산점도에서:
| 쿼리 선택 방식 | AP (%) | 고분류 비율 (Propcls) | 양호 비율 (Propboth) |
|---|---|---|---|
| 기존 (Vanilla) | 47.9 | 0.35 | 0.30 |
| 불확실성 최소화 | 48.7 | 0.82 | 0.67 |
불확실성 최소화 쿼리 선택은 높은 분류 점수를 가진 특징의 비율을 0.35에서 0.82로, 분류와 위치 모두 양호한 특징의 비율을 0.30에서 0.67로 끌어올렸다. 그 결과 AP가 +0.8% 향상되었다. "더 좋은 질문을 던지면 더 좋은 답을 얻는다"는 원리의 정량적 증명이다.
아래의 인터랙티브 탐색기에서 NMS의 영향과 RT-DETR의 디코더 유연성을 직접 체험해보자.
이제 가장 중요한 실험 결과다. COCO val2017 데이터셋에서의 성능을 비교한다.
| 모델 | 파라미터 | GFLOPs | FPS (T4) | AP (%) |
|---|---|---|---|---|
| YOLOv5-L | 46M | 109 | 54 | 49.0 |
| PP-YOLOE-L | 52M | 110 | 94 | 51.4 |
| YOLOv6-L | 59M | 150 | 99 | 52.8 |
| YOLOv7-L | 36M | 104 | 55 | 51.2 |
| YOLOv8-L | 43M | 165 | 71 | 52.9 |
| RT-DETR-R50 | 42M | 136 | 108 | 53.1 |
| 모델 | 파라미터 | GFLOPs | FPS (T4) | AP (%) |
|---|---|---|---|---|
| YOLOv5-X | 86M | 205 | 43 | 50.7 |
| PP-YOLOE-X | 98M | 206 | 60 | 52.3 |
| YOLOv7-X | 71M | 189 | 45 | 52.9 |
| YOLOv8-X | 68M | 257 | 50 | 53.9 |
| RT-DETR-R101 | 76M | 259 | 74 | 54.3 |
핵심 관찰을 정리하면:
RT-DETR-R50 vs YOLOv8-L: 정확도 53.1% vs 52.9% (+0.2%), 속도 108 FPS vs 71 FPS (+52%). 더 정확하면서 52% 더 빠르다.
RT-DETR-R101 vs YOLOv8-X: 정확도 54.3% vs 53.9% (+0.4%), 속도 74 FPS vs 50 FPS (+48%). 역시 더 정확하면서 48% 더 빠르다.
더 충격적인 것은 DETR 계열 내부 비교다.
RT-DETR-R50 vs DINO-Deformable-DETR-R50: 정확도 53.1% vs 50.9% (+2.2%), 속도 108 FPS vs 5 FPS (21.6배 빠르다!).
같은 트랜스포머 기반 검출기인데, 정확도는 2.2% 높으면서 속도는 21배 빠르다. 이것이 효율적 하이브리드 인코더와 쿼리 선택 최적화의 위력이다.
대규모 데이터셋(Objects365, 약 200만 장)으로 사전 학습 후 COCO에서 파인튜닝하면:
이 수치는 당시 실시간 검출기 중 최고 수준이었다.
RT-DETR의 또 다른 핵심 장점은 디코더 레이어 수를 조절하여 속도-정확도 트레이드오프를 조정할 수 있다는 점이다. 그것도 재학습 없이.
RT-DETR는 6개의 디코더 레이어로 학습된다. 하지만 추론 시에는 마지막 몇 개 레이어를 떼어내도 큰 정확도 손실 없이 속도가 향상된다.
| 디코더 레이어 수 | AP (%) | 지연 시간 (ms) | 속도 향상 |
|---|---|---|---|
| 7 | 52.6 | 9.6 | — |
| 6 (기본) | 53.1 | 9.3 | 기준 |
| 5 | 53.0 | 8.8 | 5.4% ↑ |
| 4 | 52.7 | 8.3 | 10.8% ↑ |
| 3 | 52.3 | 7.9 | 15.1% ↑ |
| 2 | 51.3 | 7.5 | 19.4% ↑ |
| 1 | 49.6 | 7.0 | 24.7% ↑ |
주목할 점: 6개에서 5개로 줄이면 AP는 0.1%만 감소하지만 지연은 0.5ms 줄어든다. 정확도 손실은 거의 없으면서 속도가 향상되는 것이다. 이것은 디코더의 마지막 레이어들이 점점 작은 개선만 하기 때문이다.
이 특성은 실무 배포에서 매우 유용하다. 같은 모델을 다양한 하드웨어에 배포할 때:
재학습 없이 디코더 레이어 수만 조절하면 된다. YOLO에서는 이런 유연성이 불가능하다 — 속도를 바꾸려면 아예 다른 크기의 모델(S, M, L, X)을 따로 학습해야 한다.
2024년 7월, 같은 팀이 RT-DETRv2를 발표했다. 부제는 "Bag-of-Freebies" — 직역하면 "공짜 선물 가방". 추론 속도에 영향을 주지 않으면서 성능을 높이는 개선들을 모았다는 뜻이다.
RT-DETRv2의 개선 사항은 크게 세 가지 축으로 나뉜다.
기존 Deformable Attention은 모든 스케일에서 동일한 수의 샘플링 포인트를 사용했다. 하지만 각 스케일의 특징은 본질적으로 다르다. 고해상도(S3)에는 세밀한 공간 정보가 있고, 저해상도(S5)에는 추상적 의미 정보가 있다.
RT-DETRv2는 스케일별로 다른 수의 샘플링 포인트를 설정할 수 있게 했다. 실험 결과, 전체 샘플링 포인트를 86,400에서 21,600으로 75% 줄여도 AP 하락은 0.6%에 불과했다. 이것은 산업 배포에서 연산량을 크게 절약할 수 있다는 의미다.
DETR 계열의 배포가 YOLO보다 어려운 가장 큰 이유 중 하나는 grid_sample 연산자다. 이 연산자는 양선형 보간(bilinear interpolation)을 사용하여 특징 맵에서 비정수 좌표의 값을 추출하는데, 일부 하드웨어(특히 엣지 디바이스)에서 지원되지 않거나 느리다.
RT-DETRv2는 grid_sample을 이산 샘플링(discrete_sample)으로 대체하는 옵션을 제공한다. 양선형 보간 대신 가장 가까운 정수 좌표로 반올림하여 직접 값을 읽는 것이다. 이렇게 하면 하락이 0.1~0.4%로 미미하면서, 배포 제약이 완전히 해소된다.
동적 데이터 증강: 학습 초기에는 강한 증강(RandomPhotometricDistort, RandomZoomOut, RandomIoUCrop, MultiScaleInput)을 사용하여 일반화를 높이고, 학습 후반에는 증강을 줄여 타겟 도메인에 적응시킨다. 구체적으로 마지막 2 에폭에서 증강을 끈다.
스케일 적응형 하이퍼파라미터: 모든 크기의 RT-DETR에 동일한 옵티마이저 설정을 적용하면 차선의 성능이 된다. RT-DETRv2는 모델 크기에 따라 학습률을 다르게 설정한다.
| 모델 | 백본 | lrbackbone | lrdet |
|---|---|---|---|
| RT-DETRv2-S | ResNet18 | 1e-4 (높음) | 1e-4 |
| RT-DETRv2-M | ResNet34 | 5e-5 | 1e-4 |
| RT-DETRv2-L | ResNet50 | 1e-5 | 1e-4 |
| RT-DETRv2-X | ResNet101 | 1e-6 (낮음) | 1e-4 |
직관적으로, 작은 백본(ResNet18)은 ImageNet 사전 학습 품질이 상대적으로 낮으므로 더 적극적으로 학습시키고(높은 학습률), 큰 백본(ResNet101)은 이미 좋은 특징을 가지고 있으므로 조심스럽게 미세 조정한다(낮은 학습률).
| 모델 | APval | AP50val | FPS | v1 대비 AP 향상 |
|---|---|---|---|---|
| RT-DETR-S | 46.5 | 63.8 | 217 | — |
| RT-DETRv2-S | 47.9 | 64.9 | 217 | +1.4 |
| RT-DETR-M | 48.9 | 66.8 | 161 | — |
| RT-DETRv2-M | 49.9 | 67.5 | 161 | +1.0 |
| RT-DETR-L | 53.1 | 71.3 | 108 | — |
| RT-DETRv2-L | 53.4 | 71.6 | 108 | +0.3 |
| RT-DETR-X | 54.3 | 72.7 | 74 | — |
| RT-DETRv2-X | 54.3 | 72.8 | 74 | +0.0 |
핵심: 모든 스케일에서 속도는 동일하면서 정확도가 향상된다. 특히 작은 모델(S, M)에서 개선 폭이 크다. RT-DETRv2-S는 v1 대비 +1.4% AP를 공짜로 얻었다.
RT-DETR의 등장은 단순한 신기록이 아니라, 패러다임 전환의 신호탄이다.
10년간 YOLO가 지배한 실시간 객체 검출 분야에서, 트랜스포머 기반 접근법이 처음으로 속도와 정확도 모두에서 YOLO를 앞선 것이다. 이것이 의미하는 바는:
1. NMS-free가 새로운 표준이 된다. YOLOv10(2024)도 NMS-free 학습을 도입했다. RT-DETR가 보여준 엔드투엔드의 이점에 YOLO 진영도 반응한 것이다.
2. 트랜스포머의 산업 침투가 가속된다. NLP에서 시작한 트랜스포머가 비전 분야에서도 주류가 되고 있다. ViT(Vision Transformer), Swin Transformer에 이어, RT-DETR는 실시간 비전 응용에서도 트랜스포머가 실용적임을 증명했다.
3. 대규모 사전 학습의 이전이 쉬워진다. RT-DETR는 DETR 계열의 디코더를 공유하므로, 대규모 DETR 모델(DINO 등)에서 학습된 지식을 RT-DETR로 증류(distillation)하는 것이 가능하다. 이것은 YOLO 계열에서는 어려운 일이다.
RT-DETR는 특히 다음 시나리오에서 강점을 발휘한다.
지연 시간이 결정적인 환경: 자율주행, 로봇 팔 제어, 실시간 품질 검사 — NMS의 불예측성이 치명적인 곳에서 RT-DETR의 일정한 추론 시간이 빛난다.
다양한 하드웨어 배포: 하나의 모델을 학습한 뒤, 디코더 레이어 수만 조절하여 서버/엣지/모바일에 배포할 수 있다.
스케일 유연성: RT-DETRv2의 이산 샘플링으로 grid_sample이 없는 엣지 디바이스에도 배포 가능하다.
논문이 솔직하게 인정하는 한계도 있다. 작은 객체(APS) 성능이 여전히 YOLO-L/X 모델보다 약간 낮다. RT-DETR-R50의 APS는 34.8%로, YOLOv8-L의 35.3%보다 0.5% 낮다. 이것은 DETR 계열 전반의 고질적 약점이며, 향후 연구 과제로 남아 있다.
이 글의 시작에서 우리는 NMS를 톨게이트에 비유했다. 아무리 차가 빨라도 톨게이트에서 멈춰야 하는 상황.
RT-DETR는 그 톨게이트를 완전히 없앴다.
단순히 톨게이트를 더 빠르게 통과시킨 것이 아니라, 도로 설계 자체를 바꿔서 톨게이트가 필요 없게 만든 것이다. 이것이 진정한 엔드투엔드 설계의 의미다. 문제를 더 빨리 푸는 것이 아니라, 문제 자체를 제거하는 것.
효율적 하이브리드 인코더는 "모든 것을 동등하게 처리하지 않는다"는 지혜를 보여준다. 고수준 특징에는 어텐션을, 교차 스케일 퓨전에는 CNN을 — 각 도구를 가장 적합한 곳에 배치한 설계다.
불확실성 최소화 쿼리 선택은 "더 좋은 질문을 던지면 더 좋은 답을 얻는다"는 원리를 수학적으로 증명한다.
디코더의 유연한 조정은 "하나의 모델로 다양한 상황에 대응할 수 있다"는 실용적 가치를 제공한다.
2026년 오늘, 객체 검출의 지형은 변하고 있다. YOLO가 10년간 쌓아올린 왕좌에 RT-DETR라는 강력한 도전자가 나타났다. 이 둘은 서로를 밀어붙이며, 더 빠르고, 더 정확하고, 더 우아한 검출기를 만들어가고 있다. 그리고 궁극적으로, 이 경쟁의 수혜자는 기술을 사용하는 우리 모두다.
톨게이트 없는 고속도로. 그것이 RT-DETR가 열어젖힌 새로운 시대다.



