블로그로 돌아가기
보편 근사 정리신경망딥러닝수학AI 역사
보편 근사 정리: 신경망은 정말로 아무 함수나 흉내 낼 수 있을까?
1969년 '퍼셉트론은 XOR도 못 푼다'는 선고로 AI 겨울이 시작되었다. 20년 뒤, 한 편의 논문이 반격했다 — '뉴런이 충분하면 어떤 함수든 근사할 수 있다.' 보편 근사 정리의 드라마틱한 역사를 레고 블록과 만화로 풀어본다.
코어닷투데이2025-07-0831분
1969년 '퍼셉트론은 XOR도 못 푼다'는 선고로 AI 겨울이 시작되었다. 20년 뒤, 한 편의 논문이 반격했다 — '뉴런이 충분하면 어떤 함수든 근사할 수 있다.' 보편 근사 정리의 드라마틱한 역사를 레고 블록과 만화로 풀어본다.
레고 블록을 생각해 보자. 블록 하나하나는 단순한 직사각형이다. 하지만 충분히 많은 블록을 쌓으면 에펠탑도, 밀레니엄 팰컨도, 심지어 부드러운 곡선도 만들 수 있다.
신경망도 마찬가지다. 뉴런 하나하나는 단순한 함수다 — 입력을 받고, 가중치를 곱하고, 활성화 함수를 통과시킬 뿐. 그런데 뉴런을 충분히 많이 연결하면, 어떤 함수든 원하는 정밀도로 근사할 수 있다.
이것이 바로 보편 근사 정리(Universal Approximation Theorem, UAT) 다.
하지만 이 정리가 나오기까지, AI 연구는 20년간의 겨울을 견뎌야 했다. "신경망은 XOR도 못 푼다"는 저주부터, "충분한 뉴런이 있으면 뭐든 된다"는 구원까지 — 그 드라마틱한 이야기를 시작해 보자.
프랭크 로젠블랫(Frank Rosenblatt) 은 코넬 항공연구소의 연구심리학자였다. 1957년, 그는 IBM 704 컴퓨터에서 최초의 학습 가능한 신경망 — 퍼셉트론(Perceptron) — 을 시뮬레이션했다.
미 해군 연구국(ONR)의 자금 지원을 받은 이 프로젝트의 1958년 기자회견은 대성공이었다. 뉴욕 타임스 헤드라인:
"NEW NAVY DEVICE LEARNS BY DOING: 해군의 새 장치, 스스로 학습하다"
뉴요커는 이를 "인간 뇌의 첫 번째 진정한 라이벌"이라 불렀다. 해군은 이 기계가 "걷고, 말하고, 보고, 쓰고, 자기 자신을 복제하며, 자신의 존재를 의식하게 될 것"이라고까지 발표했다.
지금 기준으로 보면 황당한 과대 광고다. 하지만 퍼셉트론의 핵심 아이디어 — 데이터로부터 스스로 학습하는 기계 — 는 진짜였다.
마빈 민스키(Marvin Minsky) 와 시모어 패퍼트(Seymour Papert) 는 1969년 Perceptrons: An Introduction to Computational Geometry를 출간했다. 이 책은 단층 퍼셉트론의 근본적 한계를 수학적으로 증명했다.
핵심 결론: 단층 퍼셉트론은 XOR(배타적 논리합)을 계산할 수 없다.
XOR은 이런 함수다:
| 입력 A | 입력 B | 출력 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
이걸 2차원 평면에 그려보면, 1을 출력하는 점(0,1)과 (1,0)이 대각선으로 마주한다. 어떤 직선을 그어도 이 두 그룹을 분리할 수 없다 — 이것이 "선형 분리 불가능(not linearly separable)"의 의미다.
단층 퍼셉트론은 본질적으로 "직선 하나를 긋는" 기계다. 직선 하나로 분리 불가능한 문제는 원리적으로 풀 수 없다.
사실, 다층 퍼셉트론이 XOR을 풀 수 있다는 것은 당시에도 알려져 있었다. 그러나 민스키와 패퍼트는 232쪽에서 다층 확장도 "비슷한 한계를 가질 것이라는 직관적 판단"이라는 추측을 적었다. 이 추측은 틀렸지만, 많은 사람이 이를 "신경망 전체의 근본적 한계에 대한 증명"으로 잘못 인용했다.
민스키-패퍼트의 책은 신경망 연구에 대한 사형 선고나 다름없었다:
프랭크 로젠블랫은 1971년 7월 11일 — 자신의 43번째 생일 — 에 체서피크 만에서 요트 사고로 사망했다. 그는 자신의 아이디어가 입증되는 것을 결코 보지 못했다. 그의 Mark I 퍼셉트론은 현재 스미스소니언 박물관에 전시되어 있다.
한편, 민스키는 1980년대 후반 한 신경망 학회에서 이렇게 연설을 시작했다:
"다들 저를 악마라고 생각하는 것 같군요."
그리고 2006년, AI@50 행사에서 테리 세즈노스키가 "신경망 겨울의 책임이 있는 악마가 당신인가?"라고 묻자, 민스키는 대답했다:
"그래요, 나는 악마입니다!"
모두가 신경망을 포기한 건 아니었다:
사실 역전파(backpropagation) 알고리즘은 새 발명이 아니었다:
그러나 이 결과가 세상에 영향을 미치려면 12년이 더 필요했다.
1986년, 루멜하트(Rumelhart), 힌턴(Hinton), 윌리엄스(Williams) 가 Nature에 발표한 "Learning representations by back-propagating errors"가 모든 것을 바꿨다. 이 논문은 역전파가 다층 신경망을 효과적으로 학습시킬 수 있음을 보여주었다. 1960년대 이래의 실질적 장벽 — "다층 네트워크를 어떻게 학습시키나?" — 이 해결된 것이다.
이제 다층 네트워크를 학습시킬 수 있게 되었다. 그러나 근본적 질문이 남아 있었다:
"다층 신경망이 학습할 수 있다는 건 알겠다. 그런데 과연 어떤 함수든 표현할 수 있는 건가? 아니면 XOR처럼 못 하는 게 또 있는 건가?"
사실 비슷한 결과가 신경망과 무관하게 존재했다. 소련 수학자 안드레이 콜모고로프(Andrey Kolmogorov) 는 1957년에 힐베르트의 제13문제에 대한 답으로 이를 증명했다:
어떤 연속 다변수 함수든, 유한 개의 1변수 연속 함수의 합성으로 표현할 수 있다.
수학적으로 우아했지만, 내부 함수가 극도로 불연속적이어서 신경망에 직접 적용하기는 어려웠다.
커트 호르닉(Kurt Hornik), 맥스웰 스틴치콤(Maxwell Stinchcombe), 핼버트 화이트(Halbert White) 가 1989년 Neural Networks에 발표한 "Multilayer feedforward networks are universal approximators"가 공식적인 첫 UAT다.
증명 내용: 하나의 은닉층만 가진 표준 다층 피드포워드 네트워크가, 임의의 "스쿼싱 함수"(시그모이드 등)를 사용할 때, 충분한 은닉 뉴런이 있으면 어떤 보렐 측정 가능 함수든 원하는 정확도로 근사할 수 있다. 증명에 스톤-바이어슈트라스 정리가 사용되었다.
같은 해, 조지 사이벤코(George Cybenko) 가 Mathematics of Control, Signals, and Systems에 발표한 논문이 가장 널리 인용되는 UAT 버전이다 (기술 보고서는 1988년 터프츠 대학교에서 작성).
증명은 한-바나흐 정리와 리즈-마르코프-카쿠타니 표현 정리를 사용한 함수해석학적 방법이다.
"뉴런을 충분히 많이 쓰면, 은닉층 하나짜리 신경망으로도 어떤 연속 함수든 원하는 만큼 정밀하게 흉내 낼 수 있다."
레고 비유로 돌아가면: 레고 블록(뉴런)이 충분하면, 어떤 모양(함수)이든 만들 수 있다.
1989년은 UAT에 관한 여러 그룹이 거의 동시에 결과를 발표한 해다:
커트 호르닉은 1991년 Neural Networks에서 결정적 통찰을 제시했다:
"보편 근사 능력을 부여하는 것은 특정 활성화 함수가 아니라, 다층 피드포워드 구조 자체다."
시그모이드뿐만 아니라, 연속이고 유계이며 상수가 아닌 어떤 활성화 함수든 보편 근사를 가능하게 한다.
모셰 레슈노(Moshe Leshno) 등은 1993년 논문에서 가장 깔끔한 결론을 내렸다:
활성화 함수가 다항식이 아닌 한, 다층 피드포워드 네트워크는 보편 근사기다. 다항식만이 실패하는 유일한 활성화 함수다.
이것은 필요충분조건이다. ReLU, tanh, GELU, Swish — 실제로 사용되는 거의 모든 활성화 함수가 해당된다.
수학적 증명은 함수해석학을 사용하지만, 직관적으로는 훨씬 간단하다. 마이클 닐슨(Michael Nielsen)의 시각적 접근을 따라가 보자.
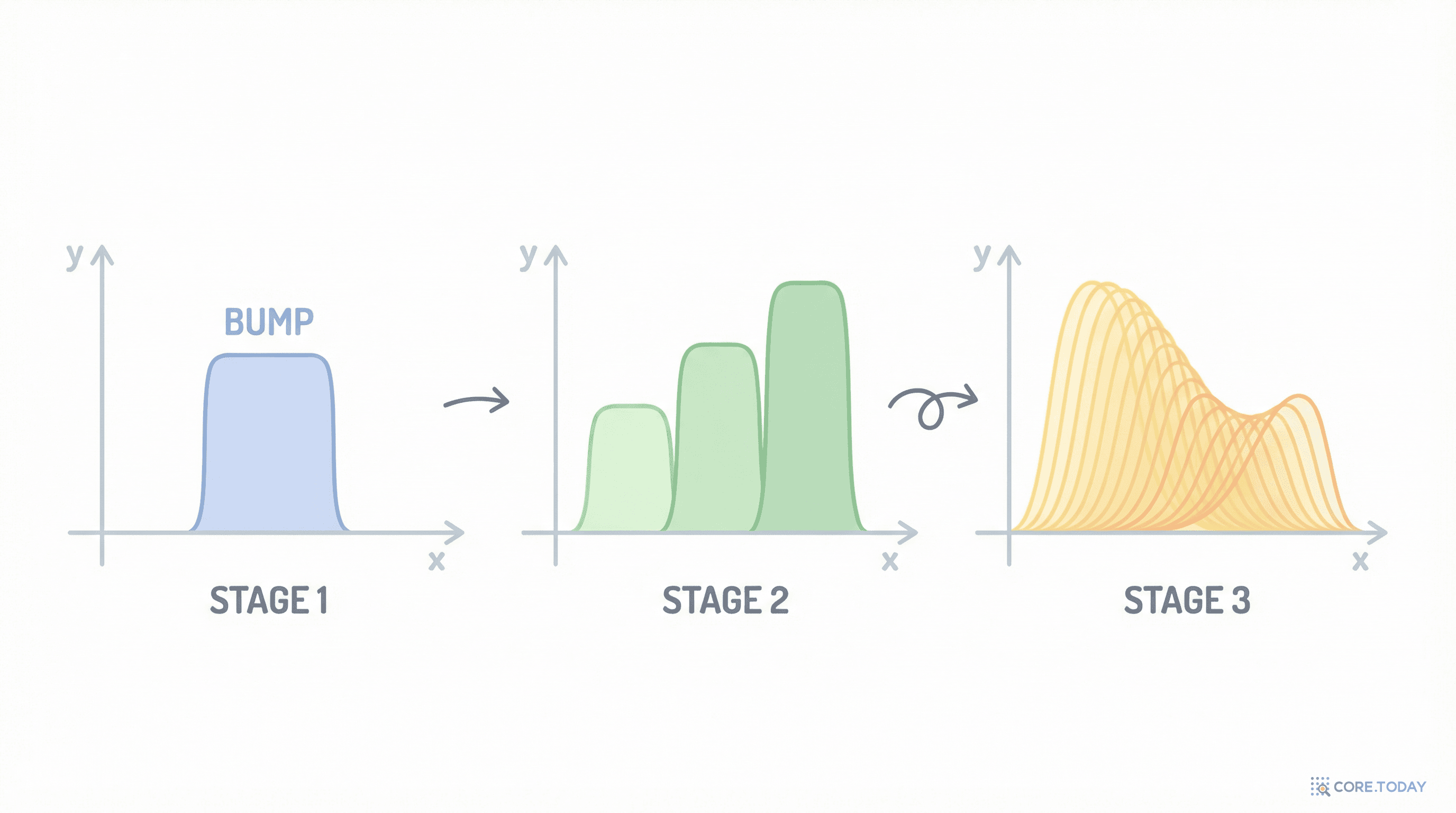
시그모이드 뉴런의 가중치를 매우 크게 올리면, 출력이 0에서 1로 갑자기 튀는 계단 함수(step function) 에 가까워진다. 가중치가 문턱값의 위치를, 바이어스가 문턱값의 높이를 결정한다.
위로 올라가는 계단과 아래로 내려가는 계단을 빼면? 특정 구간에서만 1이고 나머지에서 0인 직사각형 범프(bump) 가 된다. 이 범프의 너비와 위치는 가중치와 바이어스로 조절할 수 있다.
각 범프에 서로 다른 높이(출력층 가중치)를 곱하면, 서로 다른 높이의 기둥이 된다. 이 기둥들은 x축의 서로 다른 위치에 놓인다.
기둥들을 충분히 좁게, 충분히 많이 세우면? 모든 기둥의 합은 원래 곡선의 계단식 근사가 된다. 기둥이 좁아질수록 (= 뉴런이 많아질수록) 근사가 정밀해진다.
이것이 보편 근사 정리의 핵심 직관이다. 각 뉴런이 하나의 "범프"를 담당하고, 충분한 뉴런이 모이면 어떤 연속 곡선이든 원하는 정밀도로 재현할 수 있다.
푸리에 급수와 비슷하다고 느꼈다면 정확하다. 푸리에 급수가 사인파의 합으로 어떤 주기 함수든 표현하듯, 신경망은 범프 함수의 합으로 어떤 연속 함수든 근사한다.
여기서 중요한 반전이 있다. UAT는 강력한 정리지만, 말하지 않는 것이 말하는 것만큼 중요하다.
레고 비유로 정리하면:
"어떤 레고 모양이든 만들 수 있다. 하지만 설명서는 없고, 블록이 몇 개 필요한지 모르며, 블록을 손으로 더듬어가며 맞춰 봐야 한다."
또는 닐슨의 표현:
"중국어를 영어로 번역하는 신경망이 존재한다고 해서, 그런 네트워크를 구축하거나 인식하는 좋은 기법이 있다는 뜻은 아니다."
이것이 현대 딥러닝 이론이 세 개의 별개 문제로 나뉘는 이유다:
UAT는 첫 번째 기둥만 다룬다. 그러나 이 첫 번째 기둥이 없었다면 나머지 두 기둥을 세울 이유조차 없었을 것이다.
UAT가 "은닉층 하나면 충분하다"고 했는데, 왜 현대 딥러닝은 수백 층을 쌓을까?
텔가르스키(Matus Telgarsky) 는 2016년 COLT에서 깊이의 이점을 증명했다:
Θ(k³) 층의 네트워크가 표현할 수 있는 함수를, O(k) 층의 네트워크로 근사하려면 Ω(2^k)개의 노드가 필요하다.
핵심 통찰: ReLU 네트워크의 선형 조각(linear pieces) 수는 너비에 대해서는 다항적으로 증가하지만, 깊이에 대해서는 지수적으로 증가한다.
엘단과 샤미르(Ronen Eldan, Ohad Shamir) 도 2016년에 보완적 결과를 발표했다:
작은 3층 네트워크로 표현할 수 있는 단순한 함수가 존재하되, 2층 네트워크로 근사하려면 너비가 차원에 대해 지수적이어야 한다.
깊이가 1만 증가해도 지수적 이점을 가져올 수 있다.
루(Lu) 등 (2017): n차원 입력에 대해, 너비 n+4인 ReLU 네트워크가 (깊이가 무한이면) 모든 르베그 적분 가능 함수를 근사할 수 있다. 연속 함수에 대해서는 n+1이면 충분하다.
박(Park) 등 (2021): ReLU의 최소 필요 너비를 정확히 결정했다 — max{d_x+1, d_y} (d_x: 입력 차원, d_y: 출력 차원).
| 아키텍처 | UAT 결과 | 연도 |
|---|---|---|
| ResNet | 은닉층당 뉴런 1개 + ReLU로도 보편 근사 가능 | Lin & Jegelka, 2018 |
| 트랜스포머 | 연속 순열 등변 시퀀스-투-시퀀스 함수의 보편 근사기 | Yun et al., ICLR 2020 |
| 단층 트랜스포머 | self-attention 1층 + FFN 1층으로 충분 | 최근 연구 |
프랭클과 칼린(Frankle & Carlin, 2019): 밀집 신경망 안에는 — 학습 전부터 — 독립적으로 학습시켜도 비슷한 성능을 내는 희소 부분 네트워크("당첨 복권")가 존재한다.
더 극단적으로, 말라흐(Malach) 등은 충분히 큰 미학습 네트워크 안에 목표 함수의 근사가 이미 들어 있다는 것을 증명했다. UAT의 가장 극적인 현대적 변형이다 — 학습하지 않아도 네트워크 자체에 답이 존재할 수 있다.
자코, 가브리엘, 옹글레르(Jacot, Gabriel, Hongler, 2018): 무한 너비 극한에서, 신경망의 NTK가 결정론적 커널로 수렴하고 학습 중 상수로 유지된다. 이는 넓은 신경망의 경사하강법 학습이 NTK를 이용한 커널 회귀와 동치임을 보여, 근사 이론과 최적화 이론을 연결했다.
이 글의 제목으로 돌아가자.
"신경망이 진짜 의미 있는 모델인가?"
UAT의 답: 그렇다. 신경망은 원리적으로 어떤 연속 함수든 표현할 수 있는, 보편적 함수 근사기다. 단층 퍼셉트론의 한계는 아키텍처의 한계이지, 신경망 개념 자체의 한계가 아니었다.
"아무 함수나 표현할 수 있는 건가?"
UAT의 답: 예, 하지만... 존재는 보장하지만, 그것을 찾거나 만드는 방법은 보장하지 않는다. 이것은 약점이 아니라, 수학적 정직함이다.
1969년 민스키-패퍼트가 건 저주 — "신경망은 근본적으로 제한된다" — 를 UAT는 정면으로 반박했다. 문제는 아키텍처(단층 vs. 다층)에 있었지, 패러다임에 있지 않았다.
UAT가 열어젖힌 관점에서 보면, 현대 AI의 거의 모든 것이 함수 근사다:
UAT는 이 모든 것에 대해 "원리적으로 가능하다"는 이론적 면허증을 발급해 준 셈이다.
1971년, 프랭크 로젠블랫은 자신의 43번째 생일에 세상을 떠났다. 그가 꿈꾼 "학습하는 기계"는 조롱의 대상이었고, 그의 죽음 이후 신경망 연구는 20년간의 겨울에 접어들었다.
그러나 20년 뒤, 사이벤코와 호르닉이 증명했다 — 로젠블랫의 직관은 옳았다. 뉴런을 충분히 쌓으면 어떤 함수든 근사할 수 있다. 다만, 다층이어야 했고, 역전파라는 학습 알고리즘이 필요했을 뿐이다.
2024년, 힌턴과 홉필드가 노벨 물리학상을 받았다. 로젠블랫이 살아 있었다면 함께 수상했을 것이다. IEEE는 2004년에 그의 이름을 딴 프랭크 로젠블랫 어워드를 제정했다.
레고 블록은 단순하다. 하지만 충분히 모이면 어떤 것이든 만들 수 있다. 신경망의 뉴런도 마찬가지다.
보편 근사 정리가 말하는 것은 결국 이것이다: 단순한 것들의 충분한 조합은, 복잡한 어떤 것이든 될 수 있다.
그리고 그 "충분한 조합"을 찾아가는 여정이 — 바로 딥러닝이다.