블로그로 돌아가기
머신러닝딥러닝AI인공지능신경망기초
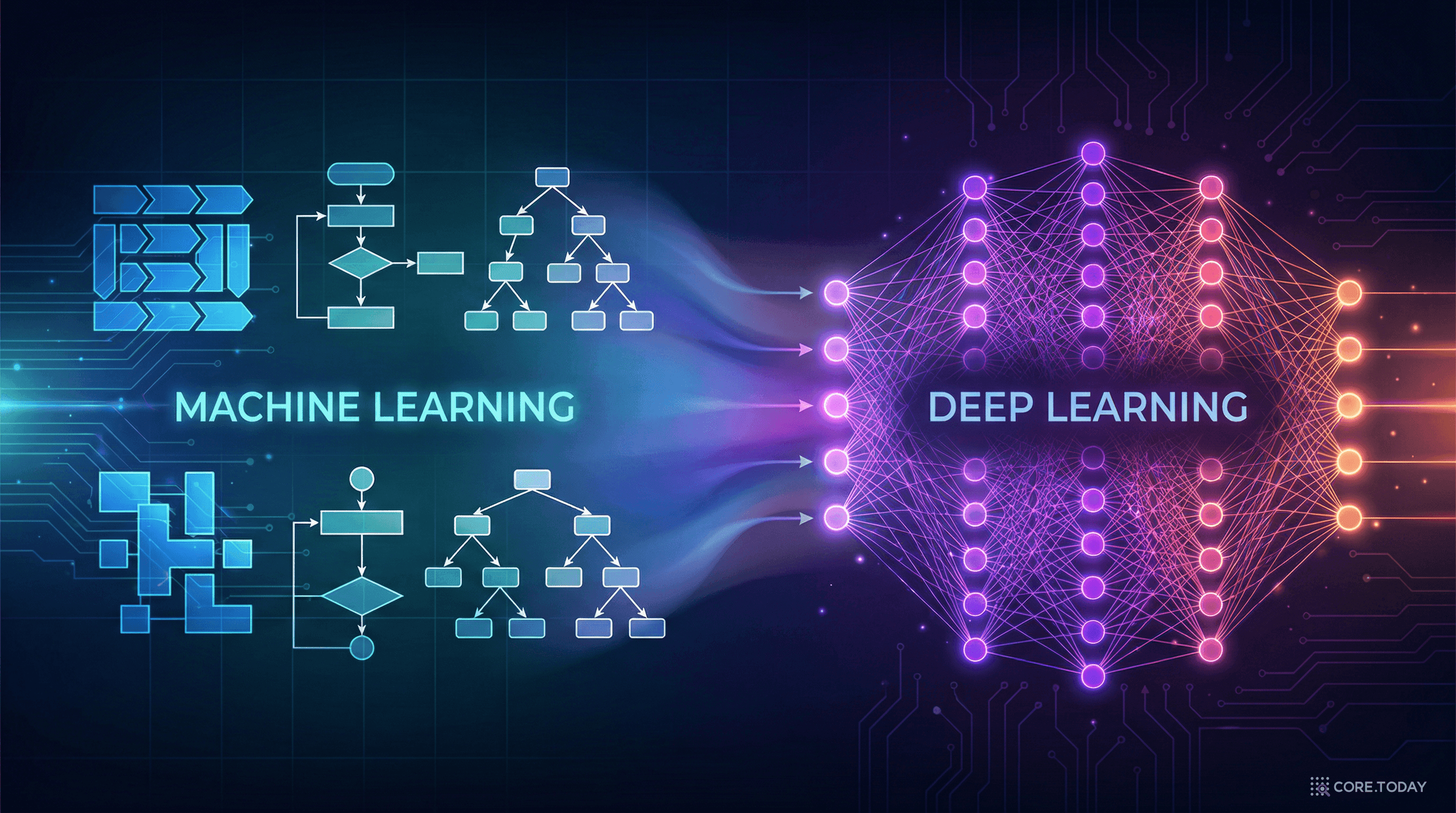
머신러닝 vs 딥러닝: 같은 듯 다른 두 세계를 제대로 이해하기
머신러닝과 딥러닝, 대체 뭐가 다른 걸까요? 1950년대 퍼셉트론부터 2026년 파운데이션 모델까지, 역사와 논문과 사례로 두 개념의 차이를 명쾌하게 정리합니다.
코어닷투데이2025-06-2435분
머신러닝과 딥러닝, 대체 뭐가 다른 걸까요? 1950년대 퍼셉트론부터 2026년 파운데이션 모델까지, 역사와 논문과 사례로 두 개념의 차이를 명쾌하게 정리합니다.
면접장, 팀 미팅, 혹은 비개발자 동료와의 대화에서 이 질문을 받아본 적 있으신가요? "딥러닝은 머신러닝의 하위 분야입니다"라고 답하면 틀린 건 아니지만, 그 한 문장으로는 왜 이 두 개념이 구분되는지, 언제 어떤 걸 써야 하는지 전혀 감이 오지 않습니다.
이 글에서는 AI 연구의 역사적 맥락부터 시작해서, 핵심 논문들을 짚어가며, 실제 사례를 통해 두 개념의 차이를 진짜로 이해할 수 있도록 정리합니다. 단순한 정의 비교가 아니라, "아, 그래서 이렇게 된 거구나"라는 감각을 갖는 것이 목표입니다.
이야기는 1950년으로 거슬러 올라갑니다. 앨런 튜링(Alan Turing)은 논문 "Computing Machinery and Intelligence"에서 유명한 질문을 던집니다.
"기계가 생각할 수 있는가?(Can machines think?)"
튜링은 이 질문에 직접 답하는 대신, 튜링 테스트라는 우회 전략을 제안합니다. 사람이 기계와 대화하면서 상대가 기계인지 사람인지 구분하지 못하면, 그 기계는 "지능적"이라고 볼 수 있다는 것이죠. 이 아이디어는 이후 70년간 AI 연구의 방향을 결정짓습니다.
1956년, 존 매카시(John McCarthy)는 다트머스 대학에서 역사적인 워크숍을 개최합니다. 이 자리에서 "인공지능(Artificial Intelligence)"이라는 용어가 처음 공식적으로 사용됩니다. 참석자 명단이 화려합니다 — 매카시, 민스키(Marvin Minsky), 섀넌(Claude Shannon), 사이먼(Herbert Simon). 이들은 "기계가 인간처럼 추론하고 학습할 수 있다"는 낙관적 비전을 공유했습니다.
이때의 AI 접근법은 규칙 기반(Rule-based)이었습니다. 전문가가 if-then 규칙을 하나하나 프로그래밍하는 방식이죠.
# 1950-60년대 스타일의 AI: 규칙을 직접 코딩
def diagnose(symptoms):
if "고열" in symptoms and "기침" in symptoms:
return "독감 가능성"
if "두통" in symptoms and "시야흐림" in symptoms:
return "편두통 가능성"
return "추가 검사 필요"
문제는 명확했습니다. 세상의 모든 상황을 규칙으로 표현하는 건 불가능합니다. "고양이 사진을 보고 고양이라고 인식하는" 규칙을 직접 코딩한다고 상상해보세요. 귀가 뾰족하면? 페르시안 고양이는요? 옆모습이면? 규칙이 끝없이 늘어납니다.
프랭크 로젠블랫(Frank Rosenblatt)은 1958년 퍼셉트론(Perceptron)을 발표합니다. 인간의 뉴런을 모방한 최초의 수학적 모델이었습니다. 입력에 가중치를 곱하고, 합산한 뒤, 임계값을 넘으면 활성화되는 단순한 구조입니다.
입력₁ × 가중치₁ ─┐
입력₂ × 가중치₂ ──┼─→ [합산] → [임계값 비교] → 출력
입력₃ × 가중치₃ ─┘
뉴욕타임스는 "해군이 생각하는 기계의 씨앗을 만들었다"고 보도했고, 사람들은 열광했습니다. 하지만 이 열광은 오래가지 못합니다.
1969년, 마빈 민스키(Marvin Minsky)와 시모어 패퍼트(Seymour Papert)는 저서 "Perceptrons"에서 퍼셉트론의 치명적 한계를 수학적으로 증명합니다. 단층 퍼셉트론은 XOR 문제(두 입력이 다를 때만 참)조차 풀 수 없다는 것이었습니다.
이 책 한 권이 신경망 연구에 대한 펀딩을 사실상 끊어버립니다. 첫 번째 AI 겨울(AI Winter)의 시작입니다.
1980년대에는 전문가 시스템(Expert System)이 부상합니다. 특정 분야 전문가의 지식을 규칙 데이터베이스로 구축하는 방식이었죠. DEC의 XCON 시스템은 컴퓨터 주문 설정을 자동화해 연간 4천만 달러를 절약했다는 유명한 사례가 있습니다.
하지만 전문가 시스템도 곧 한계에 부딪힙니다. 규칙이 수천, 수만 개로 늘어나면서 유지보수가 불가능해지고, 학습 능력이 없어 새로운 상황에 대응하지 못했습니다. 두 번째 AI 겨울이 찾아옵니다.
이 두 번의 겨울을 겪으며 연구자들은 깨닫습니다: 규칙을 사람이 직접 만드는 방식은 확장 불가능하다. 기계가 데이터에서 스스로 규칙을 배워야 한다.
이 깨달음이 바로 머신러닝의 출발점입니다.
"머신러닝(Machine Learning)"이라는 용어는 1959년 아서 사뮤엘(Arthur Samuel)이 처음 사용합니다. 그는 IBM에서 체커(Checkers) 프로그램을 만들었는데, 이 프로그램은 수만 번의 자기 대국을 통해 스스로 전략을 개선했습니다. 사뮤엘은 이를 이렇게 정의합니다:
"명시적으로 프로그래밍하지 않고도 학습하는 능력을 컴퓨터에 부여하는 연구 분야" — Arthur Samuel, 1959
핵심을 짚어봅시다. 기존 AI가 "사람이 규칙을 코딩"하는 것이었다면, 머신러닝은 "데이터를 주면 기계가 패턴을 찾는다"는 패러다임 전환입니다.
머신러닝을 이해하는 핵심 키워드는 특징 엔지니어링입니다. 머신러닝 모델에게 데이터를 주기 전에, 사람이 어떤 특징(feature)을 볼지 정해주는 작업입니다.
예를 들어 이메일 스팸 필터를 만든다고 해봅시다:
입력: 이메일 원문
사람이 설계한 특징들:
• 특징 1: "무료", "할인", "당첨" 등 스팸 키워드 개수
• 특징 2: 발신자가 연락처에 있는지 여부
• 특징 3: 링크 개수
• 특징 4: 대문자 비율
• 특징 5: 본문 길이
ML 알고리즘: 이 5개 특징을 보고 스팸/정상 분류 학습
모델이 잘 작동하려면 사람이 좋은 특징을 설계해야 합니다. "대문자 비율"이라는 특징을 생각해내는 건 사람의 몫이고, 그 특징이 스팸과 어떤 관계가 있는지 학습하는 건 기계의 몫입니다.
1990~2000년대에 걸쳐 강력한 알고리즘들이 등장합니다:
| 알고리즘 | 등장 시기 | 핵심 아이디어 | 대표 사용처 |
|---|---|---|---|
| 로지스틱 회귀 | 1958 (Cox) | 확률 기반 분류 | 의료 진단, 신용 평가 |
| 결정 트리 | 1986 (Quinlan, ID3) | if-then 규칙을 자동 생성 | 고객 세분화 |
| 랜덤 포레스트 | 2001 (Breiman) | 여러 결정 트리의 투표 | 사기 탐지, 추천 |
| SVM | 1995 (Cortes & Vapnik) | 최적 경계면 탐색 | 텍스트 분류, 얼굴 인식 |
| XGBoost | 2016 (Chen & Guestrin) | 경사 부스팅의 최적화 | Kaggle 대회 우승 단골 |
실전 사례 1 — 넷플릭스 추천 시스템 (2006~2009)
넷플릭스는 2006년 유명한 Netflix Prize 대회를 개최합니다. 자사 추천 알고리즘(Cinematch)의 정확도를 10% 이상 개선하면 100만 달러를 주겠다는 것이었죠. 최종 우승팀 BellKor's Pragmatic Chaos는 다양한 머신러닝 기법(행렬 분해, 최근접 이웃, 앙상블)을 조합해 목표를 달성합니다. 여기서 핵심은 모두 사람이 설계한 특징(시청 이력, 평점 패턴, 시간대 등)을 기반으로 했다는 점입니다.
실전 사례 2 — 신용카드 사기 탐지
은행들은 랜덤 포레스트와 그래디언트 부스팅을 활용해 사기 거래를 실시간으로 탐지합니다. 특징은 사람이 설계합니다: 거래 금액, 위치, 시간, 과거 패턴과의 편차 등. 이 분야에서 머신러닝이 여전히 강세인 이유는 해석 가능성 때문입니다. "왜 이 거래를 차단했는가?"에 대해 규제 기관에 설명할 수 있어야 하거든요.
실전 사례 3 — 캐글(Kaggle) 정형 데이터 대회
2026년 현재에도, 테이블 형태의 정형 데이터(tabular data)에서는 XGBoost, LightGBM 같은 트리 기반 머신러닝이 딥러닝을 이기는 경우가 많습니다. 2022년 논문 "Why do tree-based models still outperform deep learning on typical tabular data?"(Grinsztajn et al.)은 이 현상을 체계적으로 분석하며, 정형 데이터에서 딥러닝이 아직 결정적 우위를 확보하지 못했음을 보여줍니다.
민스키가 신경망에 사망선고를 내린 지 17년 후, 데이비드 루멜하트(David Rumelhart), 제프리 힌턴(Geoffrey Hinton), 로널드 윌리엄스(Ronald Williams)가 "Learning representations by back-propagating errors"(Nature, 1986)을 발표합니다.
역전파(Backpropagation) 알고리즘은 다층 신경망을 효과적으로 학습시킬 수 있음을 보여줬습니다. 출력의 오차를 뒤에서 앞으로 전파하며 가중치를 조정하는 이 방법은, 민스키가 지적한 "다층 퍼셉트론은 학습시킬 방법이 없다"는 문제를 정면으로 해결합니다.
하지만 당시 컴퓨팅 파워와 데이터의 한계로, 깊은(deep) 신경망은 여전히 실용적이지 않았습니다. 은닉층을 많이 쌓으면 기울기 소실(vanishing gradient) 문제로 학습이 제대로 되지 않았거든요.
제프리 힌턴은 포기하지 않았습니다. 2006년, 그는 "A fast learning algorithm for deep belief nets"(Hinton, Osindero & Teh)을 발표하며, 층별 사전학습(layer-wise pre-training)으로 깊은 신경망을 성공적으로 학습시킬 수 있음을 보여줍니다.
이 논문에서 "딥 러닝(Deep Learning)"이라는 용어가 본격적으로 사용되기 시작합니다. "딥"은 신경망의 은닉층이 깊다(deep)는 뜻입니다. 기존 머신러닝에서도 신경망을 사용했지만, 보통 1~2개 은닉층이 한계였습니다. 힌턴의 연구는 수십, 수백 개의 층을 쌓을 수 있는 길을 열었습니다.
딥러닝의 진짜 빅뱅은 2012년에 일어납니다. 알렉스 크리제프스키(Alex Krizhevsky), 일리야 서츠키버(Ilya Sutskever), 그리고 다시 힌턴이 ImageNet 이미지 인식 대회(ILSVRC)에서 AlexNet을 발표합니다.
오류율이 25.8%에서 16.4%로 — 약 10%p 가까이 떨어졌습니다. 2등과의 격차가 압도적이었죠. 더 충격적인 건, 3년 뒤 ResNet(He et al., 2015)이 3.6%를 기록하며 인간 수준(약 5%)을 넘어섰다는 것입니다.
이 결과가 AI 역사의 변곡점입니다. AlexNet의 성공에는 세 가지 요소가 결합되었습니다:
머신러닝과 딥러닝의 가장 본질적인 차이는 여기에 있습니다.
이미지 인식을 예로 들면, 머신러닝 방식에서는 사람이 "에지 검출 → 코너 검출 → 눈, 코, 입 위치 → 얼굴 비율" 같은 특징을 직접 정의해야 합니다. 딥러닝(CNN)에서는 신경망이 수백만 장의 이미지를 보면서 어떤 특징이 중요한지 스스로 학습합니다.
실제로 CNN의 은닉층을 시각화하면(Zeiler & Fergus, "Visualizing and Understanding Convolutional Networks", 2014), 초기 층은 에지와 텍스처를, 중간 층은 눈·코·바퀴 같은 부분을, 깊은 층은 "얼굴", "자동차" 같은 고수준 개념을 학습하는 것이 관찰됩니다.
딥러닝의 발전은 새로운 신경망 구조의 발명과 함께했습니다:
CNN (합성곱 신경망) — 이미지의 왕
얀 르쿤(Yann LeCun)이 1998년 발표한 LeNet-5는 손글씨 숫자 인식에서 뛰어난 성능을 보였습니다. 이 아이디어가 AlexNet(2012), VGGNet(2014), GoogLeNet(2014), ResNet(2015)으로 발전하며 컴퓨터 비전을 혁명적으로 변화시킵니다. 이미지를 작은 필터로 훑으며 공간적 패턴을 계층적으로 학습하는 구조입니다.
RNN/LSTM — 시퀀스 데이터의 해결사
순환 신경망(RNN)과 그 개선판인 LSTM(Hochreiter & Schmidhuber, 1997)은 시계열, 텍스트, 음성 같은 순서가 있는 데이터를 처리합니다. 이전 시점의 정보를 기억하며 다음을 예측하는 구조로, 기계 번역과 음성 인식의 수준을 끌어올렸습니다.
GAN (생성적 적대 신경망) — 창조하는 AI
이안 굿펠로우(Ian Goodfellow)가 2014년 발표한 GAN은 두 신경망(생성자 vs 판별자)을 경쟁시켜 사실적인 이미지를 생성하는 혁신적 아이디어였습니다. 얀 르쿤은 이를 "지난 10년간 머신러닝에서 가장 흥미로운 아이디어"라고 평했습니다.
트랜스포머 — 게임 체인저 (2017)
그리고 2017년, 구글 연구팀이 "Attention Is All You Need"(Vaswani et al.)를 발표합니다. 어텐션 메커니즘만으로 시퀀스를 처리하는 트랜스포머(Transformer) 아키텍처는, RNN의 순차 처리 한계를 깨고 병렬 처리를 가능하게 했습니다.
이 논문 하나가 이후 모든 것을 바꿉니다:
사례 1 — 의료 이미지 진단
2017년, 스탠포드 연구팀은 CNN 기반 모델이 피부암 진단에서 피부과 전문의 21명과 동등한 수준의 정확도를 달성했다고 발표합니다(Esteva et al., "Dermatologist-level classification of skin cancer with deep neural networks", Nature 2017). 12만 9천 장의 피부 병변 이미지로 학습한 이 모델은, 사람이 특징을 설계하지 않고도 병변의 시각적 패턴을 스스로 학습했습니다.
사례 2 — 자율 주행
테슬라, 웨이모 등의 자율주행 시스템은 카메라, 라이다, 레이더 데이터를 딥러닝으로 처리합니다. 보행자, 차량, 신호등, 차선을 실시간으로 인식하고 주행 판단을 내리는 이 작업은, 사람이 모든 상황에 대한 규칙을 코딩하는 것이 불가능하기에 딥러닝이 필수적입니다.
사례 3 — AlphaFold와 단백질 구조 예측
2020년, DeepMind의 AlphaFold2는 50년 된 난제인 단백질 접힘 문제를 사실상 해결합니다(Jumper et al., Nature 2021). 아미노산 서열만으로 3D 구조를 예측하는 이 모델은 CASP14 대회에서 실험 결과에 근접하는 정확도를 달성했고, 2억 개 이상의 단백질 구조를 예측해 생물학 연구를 근본적으로 가속화했습니다.
지금까지의 내용을 정리해봅시다. 머신러닝과 딥러닝의 차이는 단순히 "신경망을 쓰냐 마냐"가 아닙니다. 접근 철학 자체가 다릅니다.
하나의 비유로 정리하면:
머신러닝은 숙련된 요리사가 레시피(특징)를 짜고, 조리(학습)는 기계가 하는 것입니다. 딥러닝은 식재료(원시 데이터)만 주면, 기계가 레시피도 만들고 조리도 하는 것입니다.
물론 이 비유에는 함정이 있습니다. 딥러닝도 하이퍼파라미터 튜닝, 아키텍처 설계, 데이터 전처리 같은 사람의 개입이 필요합니다. 완전 자동은 아닙니다. 하지만 "어떤 특징을 볼 것인가"라는 핵심 결정을 기계에 위임한다는 점에서 패러다임이 다릅니다.
이론은 이해했는데, 실제로 프로젝트를 시작할 때 무엇을 선택해야 할까요?
사례: 은행 대출 심사 — 고객의 나이, 소득, 부채 비율, 신용 점수 등 정형 특징이 명확합니다. XGBoost가 딥러닝보다 성능이 좋거나 비슷한 경우가 많고, "왜 대출을 거절했는가?"를 설명해야 하는 규제 요건이 있어 해석 가능성이 중요합니다.
사례: 제조업 불량 예측 — 센서 데이터(온도, 압력, 진동)에서 이상을 탐지합니다. 데이터 양이 상대적으로 적고, 도메인 전문가가 "어떤 센서값이 중요한지" 알고 있어 특징 엔지니어링이 효과적입니다.
사례: 고객 리뷰 감성 분석 — "이 제품 진짜 별로에요 ㅎㅎ"처럼 한국어 리뷰의 풍자, 반어를 이해하려면 문맥 파악이 필수입니다. 사람이 "ㅎㅎ는 긍정" 같은 규칙을 만들 수 없죠. BERT나 GPT 기반 모델이 문맥에서 감성을 자동으로 학습합니다.
사례: 자율주행의 객체 인식 — 비 오는 밤, 역광, 가려진 보행자 등 무한한 변수가 있는 시각 데이터에서 "어떤 특징을 볼 것인가"를 사람이 정의하는 건 불가능합니다. CNN 기반 딥러닝이 유일한 현실적 선택입니다.
실무에서 "ML이냐 DL이냐"는 흑백 선택이 아닙니다. 하나의 시스템 안에서 둘을 함께 사용하는 경우가 대부분입니다.
[추천 시스템 파이프라인 예시]
사용자 행동 로그 ──→ 특징 엔지니어링(ML) ──→ 후보 생성(DL: 임베딩)
│ │
└── 실시간 컨텍스트 ──→ 랭킹 모델(ML: XGBoost) ←─┘
│
└──→ 최종 추천 결과
넷플릭스, 유튜브, 쿠팡 같은 서비스의 추천 시스템은 딥러닝으로 아이템 임베딩(벡터 표현)을 생성하고, 최종 랭킹에는 XGBoost 같은 ML 모델을 사용하는 하이브리드 구조가 일반적입니다.
2026년 현재, 머신러닝과 딥러닝의 경계는 점점 모호해지고 있습니다.
파운데이션 모델(Foundation Model)의 시대가 열리며, GPT-4, Claude, Gemini 같은 거대 모델이 범용 AI 도구로 자리 잡았습니다. 이 모델들은 딥러닝의 극한이라 할 수 있지만, 이를 활용하는 방식은 전통 ML의 파이프라인과 크게 다르지 않습니다 — 데이터 전처리, 프롬프트 엔지니어링, 파인튜닝, 평가 모두 ML의 체계를 따릅니다.
AutoML과 로우코드 AI 도구(Google AutoML, H2O.ai, Amazon SageMaker Autopilot)는 특징 엔지니어링과 모델 선택을 자동화합니다. "ML이냐 DL이냐"를 사람이 고민할 필요 없이, 도구가 데이터에 맞는 최적 모델을 찾아주는 셈이죠.
SLM(Small Language Model)의 부상도 흥미롭습니다. Phi-3(Microsoft), Gemma(Google) 같은 경량 모델들은 "무조건 크게"가 아닌 "효율적으로"라는 방향으로 딥러닝의 패러다임을 수정하고 있습니다.
이 모든 변화를 관통하는 메시지는 명확합니다:
ML과 DL은 도구입니다. 중요한 건 어떤 문제를 풀고 있는지, 어떤 데이터가 있는지, 어떤 제약 조건이 있는지를 정확히 아는 것입니다.
2026년의 AI 엔지니어에게 필요한 역량은 "PyTorch로 트랜스포머를 처음부터 구현하는 것"이 아닙니다. 물론 원리를 이해하는 건 중요하지만, 실무에서는:
이 네 가지를 갖추면, 새로운 알고리즘이 나오더라도 그 위치를 스스로 파악할 수 있습니다.
만약 지금 AI/ML을 처음 배우고 있다면, 이렇게 접근하는 걸 추천합니다:
먼저 전통 ML을 익히세요. scikit-learn으로 로지스틱 회귀, 결정 트리, 랜덤 포레스트를 돌려보세요. 특징 엔지니어링의 감각을 잡는 게 중요합니다. 데이터를 직접 만지며 "어떤 특징이 예측에 도움이 되는지" 고민하는 과정이 ML/DL 모두의 기초입니다.
그다음 딥러닝의 원리를 이해하세요. PyTorch나 TensorFlow로 간단한 CNN, RNN을 만들어보세요. 역전파가 어떻게 작동하는지, 층을 쌓으면 왜 더 복잡한 패턴을 학습할 수 있는지 직관을 얻으세요.
파운데이션 모델 활용법을 배우세요. 2026년 현재, 많은 실무 작업은 GPT, Claude 같은 모델을 API로 호출하거나 파인튜닝하는 형태입니다. 프롬프트 엔지니어링, RAG(검색 증강 생성), 에이전트 설계 같은 실용적 기술이 중요합니다.
1950년 튜링의 질문에서 시작해, 퍼셉트론의 흥망성쇠, AI 겨울의 좌절, 머신러닝의 부상, 그리고 딥러닝의 폭발적 성장까지 — 70년이 넘는 여정을 함께 살펴봤습니다.
이 여정의 핵심은 결국 하나입니다:
"기계에게 어디까지 맡길 것인가?"
규칙을 사람이 직접 짜던 시대에서, 패턴 학습을 기계에 맡기되 특징은 사람이 설계하던 머신러닝의 시대로, 그리고 특징 추출까지 기계에 위임하는 딥러닝의 시대로. AI의 역사는 인간의 개입을 점점 줄이는 방향으로 진화해왔습니다.
2026년의 파운데이션 모델은 이 흐름의 현재 종착역입니다. 하지만 이것이 끝은 아니겠죠.
중요한 건, 이 두 개념을 "경쟁 관계"로 보지 않는 것입니다. 머신러닝과 딥러닝은 같은 목표를 향한 다른 도구이며, 각각이 빛나는 영역이 있습니다. 좋은 엔지니어는 망치만 들고 모든 걸 못으로 보지 않습니다. 문제를 정확히 진단하고, 상황에 맞는 도구를 선택하는 것 — 그것이 이 글에서 얻어갈 핵심입니다.



