Google Research가 ICLR 2026에서 발표한 TurboQuant — AI 모델의 메모리를 6배 줄이면서 정확도 손실은 제로에 가까운 압축 알고리즘의 원리를 역사적 맥락부터 수학적 증명까지 풀어본다.
코어닷투데이2026-04-0538분
들어가며 — "파이드 파이퍼"가 현실이 되다
HBO 드라마 "실리콘밸리(Silicon Valley)"를 기억하는가? 주인공 리처드 헨드릭스가 만든 압축 알고리즘 "파이드 파이퍼"는 정보 이론의 한계를 뛰어넘는 꿈의 기술이었다. 모든 종류의 데이터를 극한까지 압축하면서도 품질 손실이 없는 — 그야말로 SF에나 나올 법한 이야기였다.
2026년 3월, Google Research가 발표한 논문 하나가 인터넷을 뒤집었다. 사람들이 한 첫 번째 반응은? "파이드 파이퍼가 실제로 나왔다." TechCrunch까지 이 밈을 기사 제목에 쓸 정도였다.
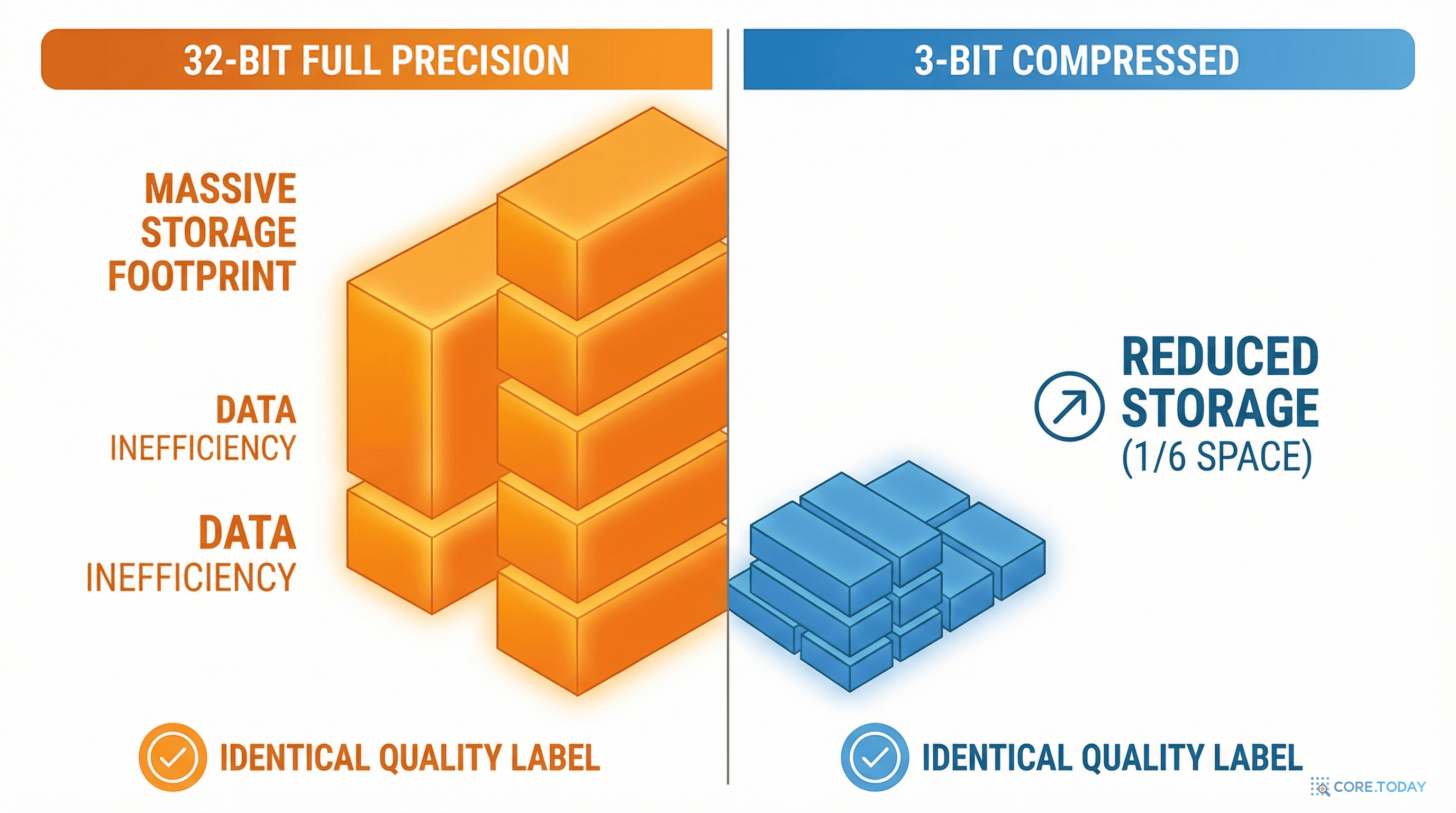
그 논문의 이름은 TurboQuant. AI 모델이 사용하는 고차원 벡터를 정보 이론적 한계에서 단 2.7배 이내로 압축하는 알고리즘이다. 메모리 사용량은 6분의 1로 줄이면서, 정확도 손실은 측정 불가능할 정도로 작다. 학습도 필요 없다. 그냥 꽂으면 된다.
발표 당일, 삼성전자, SK하이닉스, 마이크론 등 메모리 반도체 기업의 주가가 총 1,000억 달러 이상 하락했다. "GPU 메모리가 덜 필요해진다면, HBM(고대역폭 메모리) 수요도 줄어들 것"이라는 공포가 시장을 덮쳤다. 물론 이 공포가 정당한 것인지에 대해서는 뒤에서 다루겠다.
이 글은 TurboQuant가 무엇이고, 왜 이렇게 큰 반향을 일으켰는지를 처음부터 끝까지 풀어보려 한다. 양자화(quantization)가 뭔지 모르는 독자도 읽을 수 있도록, 역사와 비유와 수식을 섞어가며 설명할 것이다.
제1장: 왜 AI에게 "기억"이 이렇게 비싼가
ChatGPT가 대화를 기억하는 방법
ChatGPT에게 긴 대화를 나눠본 적이 있을 것이다. "아까 내가 말한 프로젝트 이름이 뭐였지?" 같은 질문에도 정확히 답한다. 이것이 가능한 이유는 KV 캐시(Key-Value Cache) 덕분이다.
LLM이 텍스트를 생성할 때, 이전에 처리한 모든 토큰의 Key와 Value 벡터를 메모리에 저장해둔다. 새 토큰을 생성할 때마다 이 캐시를 참조해서 "이전 맥락에서 지금 가장 관련 있는 정보가 뭔가"를 계산한다. 이것이 바로 Attention 메커니즘의 핵심이다.
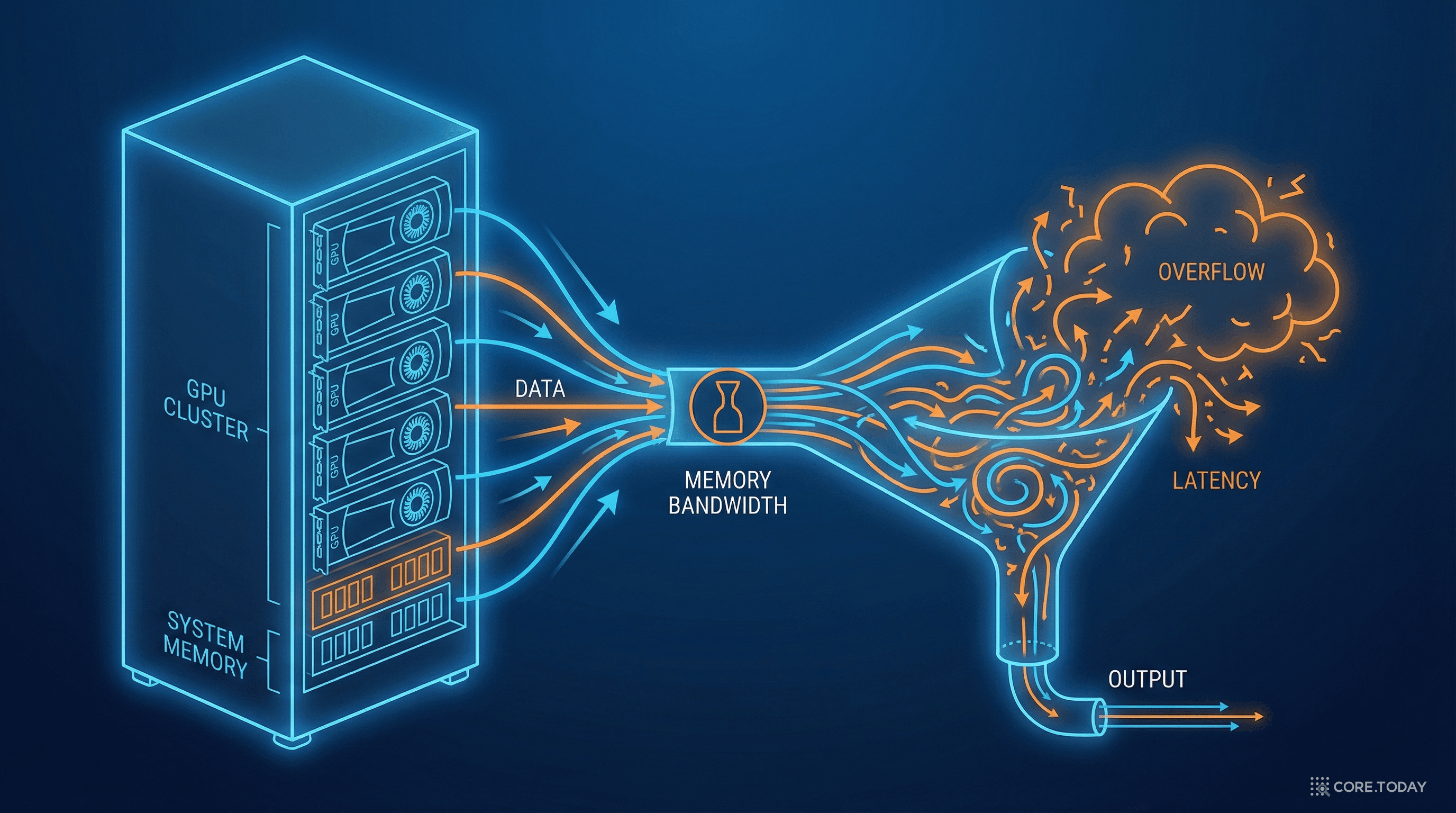
문제는 이 캐시의 크기다.
숫자로 보는 메모리 병목
Llama-3.1-8B 모델을 예로 들어보자. 이 모델이 128K 토큰(약 10만 자)의 컨텍스트를 처리하려면:
KV 캐시 메모리 사용량 (Llama-3.1-8B, 128K 컨텍스트)
모델 가중치
16 GB
KV 캐시 (FP16)
30 GB
KV 캐시 (TurboQuant 3비트)
5 GB
KV 캐시가 모델 자체보다 거의 2배 더 많은 메모리를 차지한다. A100 GPU 한 장(80GB)으로는 긴 컨텍스트 처리가 빠듯하고, 동시에 여러 사용자를 서비스하려면 GPU를 여러 장 묶어야 한다.
이것이 바로 "AI에게 기억이 비싸다"는 의미다. 기억을 유지하는 데 드는 메모리 비용이 모델 자체를 구동하는 비용보다 더 크다. 기억이 연산보다 비싸다.
비유하자면, 1TB 하드디스크를 가진 컴퓨터에서 Word 문서 하나를 열었는데, "되돌리기(Undo)" 기록이 하드디스크 2TB를 차지하는 셈이다.
벡터 검색도 같은 문제를 겪는다
KV 캐시만의 문제가 아니다. Google 검색, YouTube 추천, Spotify의 음악 추천 — 이 모든 시스템의 뒤에는 벡터 검색(Vector Search)이 있다.
"고양이와 비슷한 이미지를 찾아줘"라고 하면, 시스템은 수십억 개의 이미지를 각각 고차원 벡터(예: 1536차원)로 변환해놓고, 쿼리 벡터와 가장 가까운 벡터를 찾는다. 이 벡터들을 모두 메모리에 올려놓아야 빠른 검색이 가능한데, 수십억 개의 1536차원 FP32 벡터는 수 테라바이트에 달한다.
양쪽 모두 같은 근본 문제를 안고 있다: 고차원 벡터를 적은 비트로 표현하면서도, 원래 벡터 간의 관계(거리, 내적)를 보존해야 한다.
제2장: 압축의 역사 — 섀넌부터 TurboQuant까지
1948년: 정보 이론의 탄생
모든 것은 클로드 섀넌(Claude Shannon)에서 시작된다. 1948년, 벨 연구소에서 발표한 논문 "A Mathematical Theory of Communication"에서 섀넌은 정보를 수학적으로 정의했다. 그가 만든 핵심 개념 중 하나가 율-왜곡 이론(Rate-Distortion Theory)이다.
핵심 아이디어는 간단하다: 데이터를 압축할수록 정보가 손실된다. 주어진 비트 수로 달성할 수 있는 최소 왜곡에는 이론적 한계가 있다.
D(R)≥2πed⋅2d2(h(x)−R)
여기서 D는 왜곡(distortion), R은 비트 수(rate), d는 차원, h(x)는 엔트로피다. 이 부등식은 "아무리 천재적인 압축 알고리즘을 만들어도 이 한계 아래로는 내려갈 수 없다"고 말한다.
78년이 지난 2026년, TurboQuant가 이 한계에 2.7배 이내로 도달했다.
1982년: Lloyd-Max 양자화기
스튜어트 로이드(Stuart Lloyd)가 1957년에 발명하고 1982년에 공식 발표한 Lloyd-Max 알고리즘은 스칼라 양자화(scalar quantization)의 최적 해법이다. 아이디어는 직관적이다.
실수를 k개의 구간으로 나누고, 각 구간의 대표값(centroid)을 정한다. 원래 값을 가장 가까운 대표값으로 바꾸는 것이다. 예를 들어 0.0~1.0 범위의 값을 4개 구간으로 나누면, [0.125, 0.375, 0.625, 0.875]가 대표값이 된다. 이렇게 하면 원래 32비트 부동소수점을 단 2비트로 표현할 수 있다.
원본
0.73 → 32비트 부동소수점
양자화
0.73 → 가장 가까운 대표값 0.625 선택 → 인덱스 2 저장
역양자화
인덱스 2 → 0.625 복원 (오차: 0.105)
하지만 스칼라 양자화에는 근본적인 한계가 있다. 각 숫자를 독립적으로 양자화하기 때문에, 벡터 내 좌표들 간의 상관관계(correlation)를 활용하지 못한다.
1984년: 벡터 양자화와 Product Quantization
벡터 양자화(Vector Quantization, VQ)는 이 한계를 넘기 위해 등장했다. 숫자 하나하나를 양자화하는 대신, 벡터 전체를 하나의 단위로 양자화한다.
그 중 가장 성공적인 방법이 Product Quantization(PQ)이다. 고차원 벡터를 여러 개의 부분 벡터(subvector)로 나누고, 각 부분에 대해 별도의 코드북(codebook)을 학습한다.
1536차원 벡터
→
192차원 × 8개 부분벡터로 분할
→
각 부분벡터를 256개 코드워드 중 하나로 매핑
→
8바이트로 압축!
PQ는 Google, Facebook(현 Meta), Spotify 등에서 대규모 벡터 검색의 표준으로 사용되었다. 하지만 치명적인 문제가 있었다.
기존 양자화의 아킬레스건: 오버헤드
모든 기존 양자화 방법에는 숨은 비용이 있다. 바로 양자화 상수(quantization constants)의 오버헤드다.
양자화를 할 때, 각 블록(보통 32~128개 값)마다 스케일(scale)과 제로포인트(zero-point)를 full precision(FP16 또는 FP32)으로 저장해야 한다. 이것은 역양자화(값을 복원)할 때 필요한 정보다.
!
숨겨진 오버헤드
4비트 양자화에서 블록 크기 32를 사용하면, 스케일(16비트) + 제로포인트(16비트)가 블록당 추가된다. 이는 값 하나당 32÷32 = 1비트의 추가 오버헤드. 실질 비트폭은 4비트가 아니라 5비트다.
→
저비트에서 더 심각
2비트 양자화에서는 오버헤드 1비트가 전체의 33%를 차지한다. 압축률이 올라갈수록 오버헤드의 비중이 커진다. "2비트 양자화"라고 광고하면서 실제로는 3비트를 쓰는 셈이다.
★
TurboQuant의 해법
메모리 오버헤드를 완전히 제거(zero overhead). 3비트라고 하면 진짜 3비트만 사용한다.
또 하나의 문제는 인덱스 구축 시간이다. PQ는 코드북을 학습하기 위해 데이터 전체를 여러 번 스캔해야 한다. 수십억 개의 벡터로 코드북을 만드는 데 37초에서 무려 3,957초(1시간 이상!)까지 걸린다. TurboQuant의 인덱스 구축 시간은? 거의 0초. 데이터를 볼 필요조차 없기 때문이다.
제3장: TurboQuant — 세 가지 마법의 조합
TurboQuant(ICLR 2026)은 세 가지 핵심 구성요소로 이루어져 있다: 랜덤 회전(Random Rotation), PolarQuant(AISTATS 2026), 그리고 QJL(Quantized Johnson-Lindenstrauss). 하나씩 풀어보자.
마법 1: 랜덤 회전 — 고차원의 축복
TurboQuant의 첫 번째 단계는 놀라울 정도로 단순하다. 입력 벡터를 랜덤하게 회전시킨다. 수학적으로는 랜덤 직교 행렬 Π를 곱하는 것이다.
x′=Π⋅x
"그게 뭐가 대단한데?"라고 물을 수 있다. 핵심은 고차원 공간의 특이한 성질에 있다.
우리의 일상적인 3차원 직관과 달리, 고차원 공간에서는 놀라운 일이 일어난다. 구(sphere) 위의 점을 랜덤하게 회전시키면, 각 좌표가 거의 독립적이 되고, Beta 분포를 따르게 된다.
비유: 지구본 위의 한 점을 생각해보자. 위도와 경도는 서로 연관되어 있다(극지방에서는 경도 변화가 작다). 하지만 이 지구본을 랜덤하게 돌려놓으면, 각 좌표축으로 본 분포가 균일해진다. 고차원에서는 이 효과가 극적으로 강해진다.
차원 d가 충분히 크면, 회전된 벡터의 각 좌표 xj는 다음 분포를 따른다:
fX(x)=π⋅Γ((d−1)/2)Γ(d/2)⋅(1−x2)(d−3)/2
이것은 중심극한정리에 의해 N(0,1/d) — 평균 0, 분산 $1/d인정규분포에수렴한다.<strong>좌표들이독립이라는것은,각좌표를따로따로양자화해도된다는뜻이다.</strong>벡터양자화의어려운문제가스칼라양자화의쉬운문제d$개로 분해된다.
이것이 TurboQuant의 핵심 통찰이다: 고차원에서는 랜덤 회전이 좌표 간 상관관계를 없앤다. 복잡한 코드북 학습이 필요 없다.
마법 2: PolarQuant — 극좌표의 힘
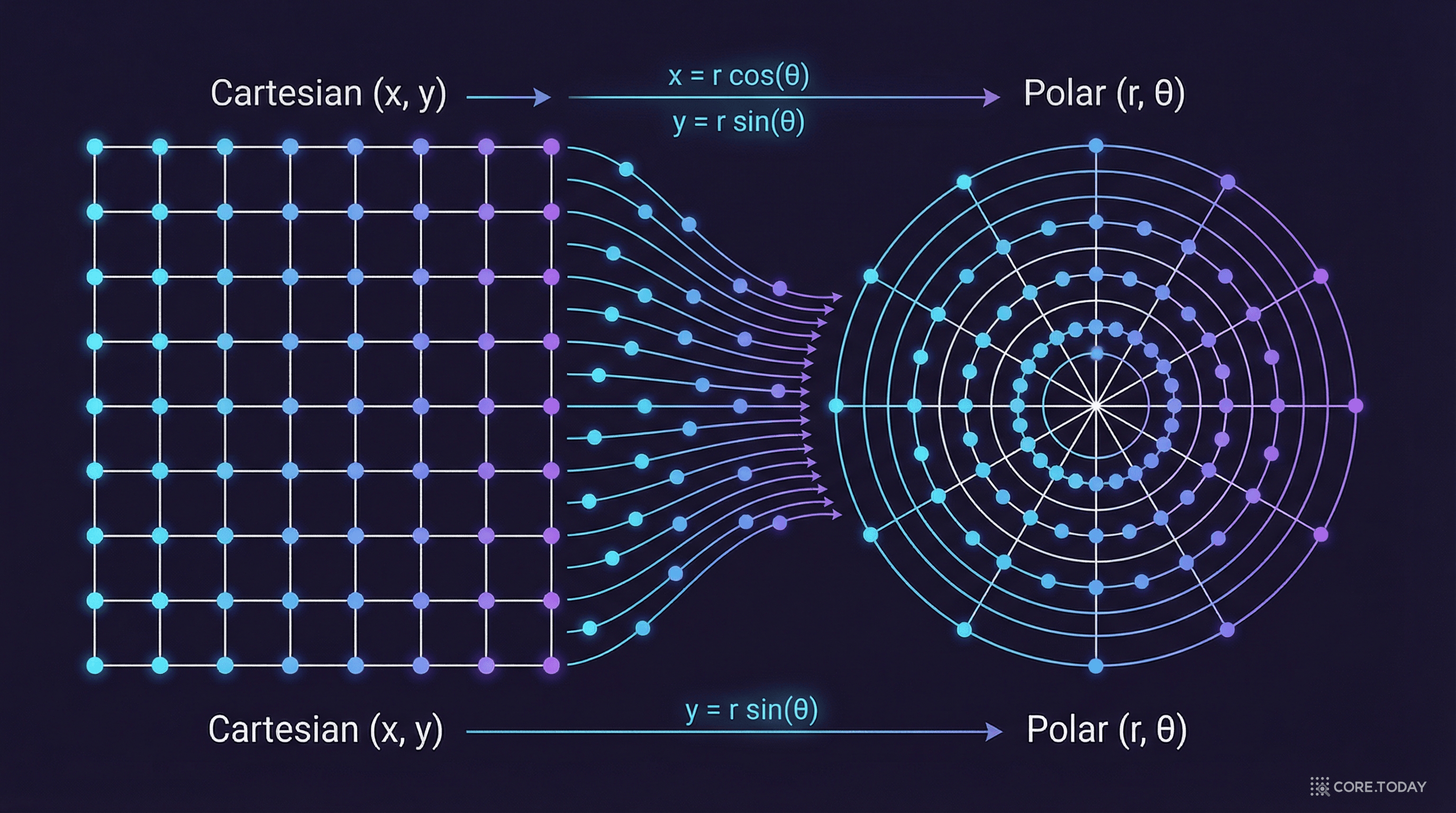
랜덤 회전 후에는 PolarQuant를 적용한다. 이름에서 알 수 있듯, 극좌표(polar coordinates) 변환을 활용하는 방법이다.
일반적인 좌표계(직교좌표)에서 한 점의 위치를 표현하려면 "동쪽으로 3블록, 북쪽으로 4블록"이라고 한다. 극좌표에서는 "37도 방향으로 5블록"이라고 한다. 같은 정보지만 표현 방식이 다르다.
직교좌표 (x₁, x₂)
→
극좌표 (r, θ)
→
r = 벡터의 크기 (데이터의 강도)
placeholder
→
placeholder
→
θ = 벡터의 방향 (데이터의 의미)
PolarQuant는 d차원 벡터의 좌표를 2개씩 짝지어 극좌표로 변환한다. 그런 다음 반지름(radius)을 다시 짝지어 재귀적으로 극좌표 변환을 적용한다. 이 과정이 왜 중요한가?
기존 양자화의 오버헤드가 사라진다. 직교좌표에서는 블록마다 스케일과 제로포인트를 저장해야 했지만, 극좌표로 변환하면 벡터의 크기(norm) 정보가 좌표 자체에 자연스럽게 인코딩된다. 별도의 정규화(normalization) 단계도 필요 없다. PolarQuant의 그리드는 데이터에 의존하지 않는 고정된 원형 격자(fixed circular grid)이기 때문이다.
결과적으로 메모리 오버헤드가 정확히 0이 된다.
마법 3: QJL — 1비트 오류 제거기
TurboQuant의 MSE(평균제곱오차) 양자화기는 훌륭하지만, 한 가지 문제가 있다. 편향(bias)이 존재한다. 양자화된 벡터로 내적(inner product)을 계산하면, 체계적으로 약간 틀린 값이 나온다. KV 캐시에서 Attention 점수를 계산할 때 이 편향이 누적되면 모델 출력이 변질될 수 있다.
여기서 QJL(Quantized Johnson-Lindenstrauss)이 등장한다.
Johnson-Lindenstrauss(JL) 변환은 고차원 데이터를 저차원으로 축소하면서 거리를 거의 보존하는 수학적 도구다. 1984년에 발표된 이 정리는 원래 기하학 문제에서 나왔지만, 현대 데이터 과학의 핵심 도구가 되었다.
QJL은 JL 변환을 극단적으로 단순화한 버전이다:
Qqjl(x)=sign(S⋅x)
여기서 S는 랜덤 가우시안 행렬이다. 각 좌표의 부호(양수/음수)만 저장한다. 딱 1비트.
이 1비트 잔차 양자화가 어떻게 편향을 제거하는가? 수학적으로:
E[⟨y,Qqjl−1(Qqjl(x))⟩]=⟨y,x⟩
내적의 기댓값이 정확히 원래 내적과 같다. 불편 추정(unbiased estimation)이다.
TurboQuant 2단계 파이프라인
Stage 1PolarQuant (b-1 비트) — 랜덤 회전 → 극좌표 변환 → Lloyd-Max 스칼라 양자화. 낮은 MSE로 벡터를 압축한다.
잔차 계산r=x−Qmse−1(Qmse(x)) — 1단계에서 발생한 작은 오차 벡터를 계산한다.
Stage 2QJL (1비트) — 잔차에 부호 함수를 적용. 이 1비트가 1단계의 편향을 수학적으로 상쇄한다.
제4장: 얼마나 좋은가 — 이론과 실험
이론적 보장: 2.7배의 의미
TurboQuant의 핵심 정리를 정리하면:
구분
TurboQuant 상한
정보이론 하한
비율
MSE 왜곡
23π⋅4b1
4b1
≈ 2.72×
내적 왜곡
d3π2∥y∥2⋅4b1
d∥y∥2⋅4b1
≈ 2.72×
b는 비트폭, d는 차원이다. 상수 3π/2≈2.72는 Panter-Dite 고해상도 근사와 Beta 분포의 적분에서 유래한다.
이것이 의미하는 바는: 비트폭이 몇이든, 차원이 몇이든, TurboQuant의 왜곡은 이론적 최소값의 2.7배를 넘지 않는다. 그리고 이 비율은 비트폭이 낮을수록(= 압축이 극단적일수록) 더 좋아진다. 1비트에서는 실제로 1.45배 수준이다.
비트폭별 왜곡도
아래 인터랙티브 컴포넌트에서 비트폭을 조절하며 압축률, 왜곡도, 속도 향상을 직접 확인해 보자:
실험 결과: KV 캐시 압축
TurboQuant를 Llama-3.1-8B-Instruct와 Ministral-7B-Instruct 모델의 KV 캐시에 적용한 결과:
비트폭
LongBench 점수
Needle-in-Haystack
메모리 절감
16비트 (원본)
기준선
0.997
-
4비트 (TurboQuant)
품질 동일
0.997
4× 절감
3.5비트 (TurboQuant)
품질 동일
0.995
4.6× 절감
3비트 (TurboQuant)
미미한 저하
0.990
5.3× 절감
2.5비트 (TurboQuant)
약간의 저하
0.980
6.4× 절감
4비트 (KIVI 기존)
저하 있음
0.985
4× 절감
주목할 점:
4비트에서 Needle-in-Haystack 점수가 원본과 동일하다 (0.997). 기존 KIVI는 같은 비트폭에서 0.985로 떨어진다.
3비트까지 내려가도 실용적이다. 기존 방법으로는 불가능했던 영역이다.
H100 GPU에서 4비트 TurboQuant는 32비트 대비 최대 8배 속도 향상을 달성했다.
학습(training)이나 미세조정(fine-tuning)이 전혀 필요 없다.
실험 결과: 벡터 검색
GloVe(200차원) 임베딩 데이터셋에서의 최근접 이웃 검색 결과:
1@10 Recall (높을수록 좋음, GloVe-200)
TurboQuant (4비트)
0.95
PQ (LUT256)
0.82
RaBitQ
0.79
인덱스 구축 시간 (낮을수록 좋음)
TurboQuant
~0초
PQ (LUT256)
37~3,957초
RaBitQ
코드북 학습 필요
TurboQuant는 검색 정확도에서 PQ를 13% 이상 앞서면서, 인덱스 구축 시간이 거의 0에 수렴한다. 데이터에 의존하지 않는(data-oblivious) 알고리즘이기 때문이다.
제5장: 직접 체험해보기 — 랜덤 회전의 효과
TurboQuant의 핵심인 "랜덤 회전이 데이터 분포를 균일화한다"는 개념을 2D에서 직접 확인해보자. 아래에서 편향된 데이터에 랜덤 회전을 적용하면 분포가 어떻게 변하는지 관찰할 수 있다:
제6장: 산업적 충격 — 1,000억 달러의 공포와 제본스 패러독스
메모리 반도체 시장의 패닉
2026년 3월 24일, TurboQuant 발표 직후 반도체 시장에 패닉이 왔다. 삼성전자, SK하이닉스, 마이크론, 키옥시아 등 메모리 칩 제조사의 시가총액이 합산 약 1,000억 달러 급락했다.
논리는 단순했다: "AI 모델이 메모리를 6분의 1만 사용하게 되면, HBM(고대역폭 메모리) 수요가 급감할 것이다." HBM은 AI GPU의 핵심 부품으로, SK하이닉스와 삼성전자의 실적을 견인하는 효자 제품이었다.
하지만 이 논리에는 중요한 반론이 있다.
제본스 패러독스: 효율이 소비를 늘린다
1865년, 영국의 경제학자 윌리엄 스탠리 제본스(William Stanley Jevons)는 역설적인 관찰을 했다. 제임스 와트가 증기기관의 효율을 획기적으로 개선했을 때, 석탄 소비가 줄어들기는커녕 오히려 폭발적으로 증가했다. 효율이 좋아지니 증기기관의 활용 범위가 넓어졌고, 총 수요가 늘어난 것이다.
AI 메모리에서도 같은 일이 벌어질 가능성이 높다:
1
압축 전: 32K 컨텍스트가 한계
A100 80GB GPU 한 장으로 Llama-3.1-8B를 서비스할 때, KV 캐시 때문에 컨텍스트 길이가 32K 토큰으로 제한된다.
2
TurboQuant 적용: 같은 GPU에서 192K 컨텍스트
KV 캐시가 6분의 1로 줄면, 같은 GPU에서 6배 긴 컨텍스트를 처리하거나 6배 많은 사용자를 동시 서비스할 수 있다.
3
결과: 더 많은 GPU가 필요해진다
긴 컨텍스트가 가능해지면 새로운 유스케이스(전체 코드베이스 분석, 장편 문서 처리)가 열리고, AI 서비스의 총 수요가 폭발적으로 증가한다. SemiAnalysis의 레이 왕은 "압축된 모델이 새로운 시장을 만들어 하드웨어 수요를 오히려 늘릴 것"이라고 분석했다.
커뮤니티의 반응
Google이 공식 구현체를 공개하지 않았음에도, 발표 후 며칠 만에 오픈소스 커뮤니티에서 Python, Rust, Apple Silicon 구현체가 등장했다. vLLM 통합 PR도 진행 중이다. 커뮤니티의 주요 발견:
비대칭 비트 할당이 최적: 키(Key)에 4비트, 값(Value)에 2비트를 할당하는 것이 균일하게 3비트를 사용하는 것보다 효과적이다.
3B 이상 모델에서는 4비트 압축의 품질이 full precision과 구분 불가능하다.
구현이 놀라울 정도로 간단하다. 핵심 알고리즘이 수십 줄의 코드로 구현된다.
학술적 논쟁
한편, ETH Zurich의 RaBitQ 연구팀은 방법론의 유사성에 대해 공개적으로 우려를 표명했다. 빠르게 발전하는 ML 연구에서 기여도 귀속(attribution)은 항상 복잡한 문제다.
제7장: 2026년, 압축이 왜 이렇게 중요한가
AI의 세 가지 병목
2026년 현재, AI 발전을 가로막는 세 가지 병목이 있다:
연산 (Compute)
GPU 칩의 수
→ 더 큰 모델, 더 긴 학습
메모리 (Memory)
GPU 메모리 용량
→ 컨텍스트 길이, 배치 크기 제한
데이터 (Data)
학습 데이터의 양과 질
→ 모델 성능의 궁극적 상한
TurboQuant는 이 중 메모리 병목에 정면으로 도전한다. 그리고 메모리 병목의 해소는 나머지 두 병목에도 간접적으로 영향을 미친다.
메모리가 줄면 → 같은 GPU에서 더 큰 배치를 돌릴 수 있다 → 연산 효율 증가
메모리가 줄면 → 엣지 디바이스에서 LLM 구동이 가능해진다 → AI 접근성 확대
메모리가 줄면 → 더 긴 컨텍스트를 처리할 수 있다 → 데이터 활용도 증가
엣지 AI로의 문
TurboQuant가 특히 흥미로운 이유는 학습이 필요 없는(training-free) 방법이라는 점이다. 기존 양자화 방법(GPTQ, AWQ 등)은 대표 데이터셋으로 보정(calibration) 과정을 거쳐야 했다. TurboQuant는 그냥 적용하면 된다.
이것은 다음을 의미한다:
스마트폰에서 실시간으로 LLM의 KV 캐시를 압축할 수 있다
엣지 디바이스에서 32K 컨텍스트가 가능해진다
클라우드 비용을 즉시 60~80% 절감할 수 있다
정보 이론적 한계에 가깝다는 것의 의미
TurboQuant가 섀넌의 정보이론 하한에서 2.7배 이내에 도달했다는 것은, KV 캐시 압축이라는 문제에서 미래의 발전 여지가 제한적이라는 뜻이기도 하다. 최대 2.7배 더 개선할 수 있을 뿐이다. 이 이상의 효율은 KV 캐시 압축이 아닌 새로운 아키텍처(예: State Space Models, Linear Attention)에서 와야 한다.
이것은 마치 열역학의 카르노 효율에 비견된다. 카르노 사이클은 이론적으로 가장 효율적인 열기관이다. 현대의 내연기관은 카르노 효율의 40~50%에 도달해 있다. 누군가가 90%에 도달하는 기관을 만들었다면, "엔진 효율 연구는 거의 끝판에 가까워졌다"고 말할 수 있다. TurboQuant는 벡터 양자화의 카르노 사이클에 해당한다.
제8장: TurboQuant 논문 요약
논문 정보
제목: TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
TurboQuant의 이야기는 결국 하나의 교훈으로 귀결된다: 잘 설계된 알고리즘이 물리적 하드웨어의 한계를 넘어설 수 있다.
더 많은 메모리를 탑재하는 것은 공학적 한계(비용, 발열, 전력)에 부딪힌다. 하지만 같은 메모리를 더 효율적으로 사용하는 것은 수학의 영역이다. TurboQuant는 78년 전 섀넌이 그어놓은 이론적 한계선에 거의 도달함으로써, 이 방향의 연구가 성숙기에 접어들었음을 보여준다.
동시에 이것은 시작이기도 하다. 압축된 메모리가 열어주는 새로운 가능성 — 모바일 기기에서의 LLM, 실시간 벡터 검색, 수십만 토큰의 컨텍스트 윈도우 — 은 이제 막 탐험을 시작했을 뿐이다.
2026년은 AI가 "더 크게"에서 "더 효율적으로"로 전환하는 해가 될 것이다. TurboQuant는 그 전환의 첫 번째 이정표다.
"물리학에서 가장 아름다운 것은 간결한 수학으로 복잡한 현상을 설명할 때 나타난다." — 리처드 파인만
TurboQuant는 바로 그것이다. 랜덤 회전이라는 단순한 아이디어 하나로, 수십 년간 풀리지 않던 양자화의 최적성 문제를 해결했다.