블로그로 돌아가기
GraphRAGRAG지식 그래프벤치마크ICLR 2026GraphRAG-BenchLLM
GraphRAG는 정말 효과적인가? — ICLR 2026 논문이 밝힌 9가지 진실
그래프가 RAG를 377배 비싸게 만든다면, 언제 쓸 가치가 있을까? ICLR 2026에서 발표된 GraphRAG-Bench 논문이 9개 시스템을 체계적으로 벤치마킹하여 밝혀낸 9가지 핵심 발견을 깊이 있게 분석합니다.
코어닷투데이2026-04-0867분
그래프가 RAG를 377배 비싸게 만든다면, 언제 쓸 가치가 있을까? ICLR 2026에서 발표된 GraphRAG-Bench 논문이 9개 시스템을 체계적으로 벤치마킹하여 밝혀낸 9가지 핵심 발견을 깊이 있게 분석합니다.
한 의료 AI 스타트업을 상상해보자. 이 팀은 NCCN(National Comprehensive Cancer Network) 가이드라인을 기반으로 암 환자의 치료 경로를 추천하는 시스템을 만들고 있다. 환자가 "HER2 양성 유방암 3기인데, 이전에 trastuzumab에 내성이 생겼습니다. 다음 치료 옵션은 무엇인가요?"라고 질문하면, 시스템은 이 질문에 답하기 위해 최소 4개의 서로 다른 문서 영역을 연결해야 한다: HER2 양성 유방암의 병기별 치료 프로토콜, trastuzumab 내성 메커니즘, 대체 항체-약물 접합체(ADC)의 임상 데이터, 그리고 환자의 이전 치료 이력과의 상호작용.
기존 RAG 시스템이라면? 벡터 유사도로 "HER2 양성 유방암 치료"와 가장 비슷한 5개 청크를 가져온다. 운이 좋으면 1차 치료 프로토콜은 포함될 것이다. 하지만 trastuzumab 내성 후 2차 치료에 대한 정보는 완전히 다른 섹션에 있고, ADC 약물의 부작용 프로필은 또 다른 챕터에 있다. 이 정보들 사이의 인과적 연결 — "내성이 생겼으니 A 대신 B를 써야 하고, B를 쓸 때는 C를 모니터링해야 한다" — 은 개별 청크에는 존재하지 않는다.
이것이 바로 "단일 패시지 함정(single passage trap)"이다. RAG가 가져오는 각 청크는 그 자체로는 정확하지만, 여러 청크를 논리적으로 연결하는 추론은 검색 단계에서 불가능하다.
GraphRAG는 이 문제를 해결하겠다고 등장했다. 문서에서 개체(entity)와 관계(relation)를 추출하여 지식 그래프를 구축하고, 그래프 순회를 통해 멀리 떨어진 정보를 연결한다. "trastuzumab → 내성 메커니즘 → 대체 치료 → T-DXd → 부작용 모니터링"이라는 경로를 그래프에서 추적할 수 있다.
그런데 문제가 있다. Natural Questions 같은 단순 질의에서 GraphRAG가 일반 RAG보다 정확도가 13.4% 낮고, 지연 시간은 2.3배 길다. 게다가 토큰 비용은 최대 377배. 이것이 그래프의 대가인가, 아니면 뭔가 잘못된 것인가?
2026년 ICLR에서 발표된 "GraphRAG-Bench: Comprehensive Benchmarking for Retrieval-Augmented Generation with Knowledge Graphs" 논문이 바로 이 질문에 체계적으로 답한다. 9개 시스템을 4단계 복잡도의 과제에서 벤치마킹하여, GraphRAG가 언제 빛나고, 언제 오히려 해가 되는지를 수치로 밝혀냈다.
2020년, Facebook AI Research(현 Meta AI)의 Patrick Lewis 등이 발표한 "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"는 LLM의 지식 한계를 돌파하는 패러다임을 제시했다. 모델 파라미터에 모든 지식을 담는 대신, 외부 문서를 검색하여 컨텍스트로 제공하는 것이다. 이 단순한 아이디어가 환각(hallucination) 문제에 대한 가장 실용적인 해법이 되었다.
초기 RAG는 TF-IDF나 BM25 같은 희소 검색(sparse retrieval)을 사용했다. 키워드 매칭 기반이라 "심장 질환의 위험 요소"를 검색하면 정확히 그 단어가 포함된 문서만 가져왔다.
Dense Retrieval의 등장으로 의미적 유사도 기반 검색이 가능해졌다. "심장 질환의 위험 요소"라는 질문으로 "고혈압은 관상동맥 질환의 주요 원인이다"라는 문장도 찾을 수 있게 된 것이다. 여기에 Cross-Encoder 리랭킹, 하이브리드 검색(희소 + 밀집), 청크 최적화 등의 기법이 추가되면서 검색 품질은 계속 향상되었다.
2023년에는 Anthropic의 Contextual RAG가 등장해 각 청크에 문서 전체의 맥락을 주입하는 방식으로 검색 실패를 줄였다. 하지만 이 모든 발전에도 근본적인 한계가 남았다: 각 청크는 독립적으로 검색되며, 청크 간의 관계는 무시된다.
이미 NLP 분야에서는 지식 그래프를 활용한 QA(KGQA)와 지식 그래프 보강 언어 모델(KELM)이 연구되고 있었다. 2024년 4월, Microsoft Research가 "From Local to Global: A Graph RAG Approach to Query-Focused Summarization"을 발표하며 GraphRAG라는 용어가 대중화되었다. 문서에서 개체와 관계를 추출하고, Leiden 알고리즘으로 커뮤니티를 구성한 뒤, 계층적 요약을 통해 "글로벌" 질문에 답하는 구조였다.
뒤이어 HippoRAG(2024년 5월)가 인간 해마의 기억 메커니즘을 모방한 뉴로바이올로지 접근법을, LightRAG(2024년 10월)가 커뮤니티 계층 없이 듀얼 레벨 키워드 검색으로 GraphRAG의 비용을 1/6000로 줄이는 방법을 제시했다.
GraphRAG에 대한 기대가 높아지면서 혼란도 커졌다. "GraphRAG가 항상 더 좋다"는 주장과 "GraphRAG는 과대광고"라는 반론이 동시에 존재했다. 누가 맞는 것인가? 이 질문에 답하려면 공정하고 체계적인 벤치마크가 필요했다. 2025년 GraphRAG-Bench가 등장하고, 2026년 ICLR에서 정식 발표된 것은 이런 맥락에서다.
GraphRAG-Bench가 등장하기 전, 기존 벤치마크들은 그래프 기반 검색의 효과를 제대로 측정하지 못했다. 저자들이 지적한 세 가지 근본적 한계를 살펴보자.
HotpotQA는 "멀티홉 추론"을 측정한다고 알려져 있지만, 실제로는 대부분의 질문이 2-hop 이내의 단순 연결만 요구한다. "A는 B에서 태어났고, B는 C 나라에 있다. A는 어느 나라 사람인가?"는 두 사실의 연결일 뿐, 진정한 복합 추론이 아니다. 이런 질문은 잘 설계된 Dense Retrieval로도 충분히 해결 가능하기 때문에, 그래프의 실제 가치가 드러나지 않는다.
기존 벤치마크의 코퍼스(대부분 Wikipedia)는 지식 그래프 구축에 적합하지 않다. Wikipedia 문서에서 추출된 개체 간 관계는 희소(sparse)하고, 대부분의 노드가 고립(isolated)되어 있다. 고립 노드 비율이 높은 그래프에서는 그래프 순회가 의미를 가질 수 없다 — 연결 자체가 없으니까.
기존 벤치마크는 최종 답변의 정확도만 측정한다. 그래프가 실제로 검색에 기여했는지, 아니면 그래프 없이도 같은 답을 얻을 수 있었는지를 구분하지 않는다. 이는 "그래프 추가 → 정확도 향상"이라는 인과관계를 주장할 수 없게 만든다.
아래 표는 GraphRAG-Bench의 코퍼스가 기존 벤치마크와 얼마나 다른지를 보여준다:
| 벤치마크 | 평균 개체 수 | 평균 관계 수 | 비고립 비율 | 평균 차수 |
|---|---|---|---|---|
| GraphRAG-Bench (소설) | 19.6 | 20.9 | 0.66 | 2.27 |
| GraphRAG-Bench (의료) | 11.8 | 6.2 | 0.48 | 1.05 |
| UltraDomain | 170.6 | 73.2 | 0.40 | 0.86 |
| MultiHop-RAG | 10.1 | 3.82 | 0.41 | 0.76 |
| HotpotQA | 39.3 | 12.7 | 0.41 | 0.65 |
비고립 비율(Non-isolated Proportion)은 전체 노드 중 최소 하나의 엣지를 가진 노드의 비율이다. GraphRAG-Bench 소설 코퍼스의 0.66은 노드의 66%가 다른 노드와 연결되어 있다는 뜻이다. 평균 차수(Average Degree)는 각 노드가 평균적으로 몇 개의 엣지를 가지는지를 나타낸다. 이 두 수치가 높을수록 그래프 구조가 풍부하고, 그래프 순회를 통한 정보 발견이 더 효과적이다. HotpotQA의 평균 차수 0.65는 대부분의 노드가 사실상 고립되어 있다는 의미이다 — 이런 그래프에서 GraphRAG의 가치를 측정하는 것은 공정하지 않다.
GraphRAG-Bench의 핵심 혁신은 과제 복잡도를 4단계로 세분화한 것이다. 기존 벤치마크가 "쉬움/어려움"으로 나누던 것과 달리, 각 단계가 요구하는 정보의 폭(breadth)과 추론의 깊이(depth)가 정량적으로 정의된다.
Level 1: 사실 검색(Fact Retrieval) — 사전에서 단어 뜻을 찾는 것과 같다. 하나의 문서에서 하나의 사실을 추출하면 된다. "HER2 양성 유방암의 1차 치료제는?" 같은 질문이다. Knowledge Breadth 평균 1.40, Reasoning Depth 평균 1.69. 이런 질문에는 그래프가 필요 없을 가능성이 높다.
Level 2: 복합 추론(Complex Reasoning) — 퍼즐 조각을 맞추는 것과 같다. 여러 문서의 정보를 논리적으로 연결해야 한다. "trastuzumab 내성 환자에게 T-DXd를 사용할 때의 심장독성 모니터링 주기는?" Knowledge Breadth 평균 2.60, Reasoning Depth 평균 6.25. 여기서부터 그래프의 가치가 나타나기 시작한다.
Level 3: 맥락 요약(Contextual Summarization) — 독후감을 쓰는 것과 같다. 넓은 범위의 정보를 종합하여 구조화된 요약을 만들어야 한다. "소설 속 주인공의 성격 변화를 시대 배경과 연결하여 설명하시오." Knowledge Breadth 평균 3.51, Reasoning Depth 평균 4.64.
Level 4: 창의 생성(Creative Generation) — 여러 원작을 읽고 팬픽션을 쓰는 것과 같다. 가장 넓은 범위의 정보를 활용하며, 창의적 재구성이 필요하다. Knowledge Breadth 평균 7.11, Reasoning Depth 평균 7.81. 그래프 기반 검색의 이점이 극대화되는 영역이다.
왜 하필 의료(NCCN 가이드라인)와 소설(Project Gutenberg의 20세기 이전 문학)인가?
의료 도메인은 정보가 계층적으로 구조화되어 있다. 암 유형 → 병기 → 치료 프로토콜 → 약물 → 부작용의 명확한 위계가 존재한다. 이런 구조는 지식 그래프로 변환했을 때 높은 품질의 그래프가 만들어진다.
소설 도메인은 정보가 서사적으로 분산되어 있다. 인물의 감정 변화, 상징적 의미, 복선과 반전 등은 명시적 관계로 추출하기 어렵다. 이런 모호한 도메인에서 그래프 기반 검색이 어떻게 작동하는지를 테스트한다.
GraphRAG-Bench의 질문-답변 쌍은 자동화된 6단계 파이프라인으로 구축된다. 단순히 사람이 질문을 만드는 것이 아니라, 코퍼스의 지식 그래프에서 논리적 경로를 먼저 추출한 뒤, 그 경로를 기반으로 질문을 생성한다. 이렇게 하면 각 질문이 요구하는 정확한 증거 문서와 추론 경로가 보장된다.
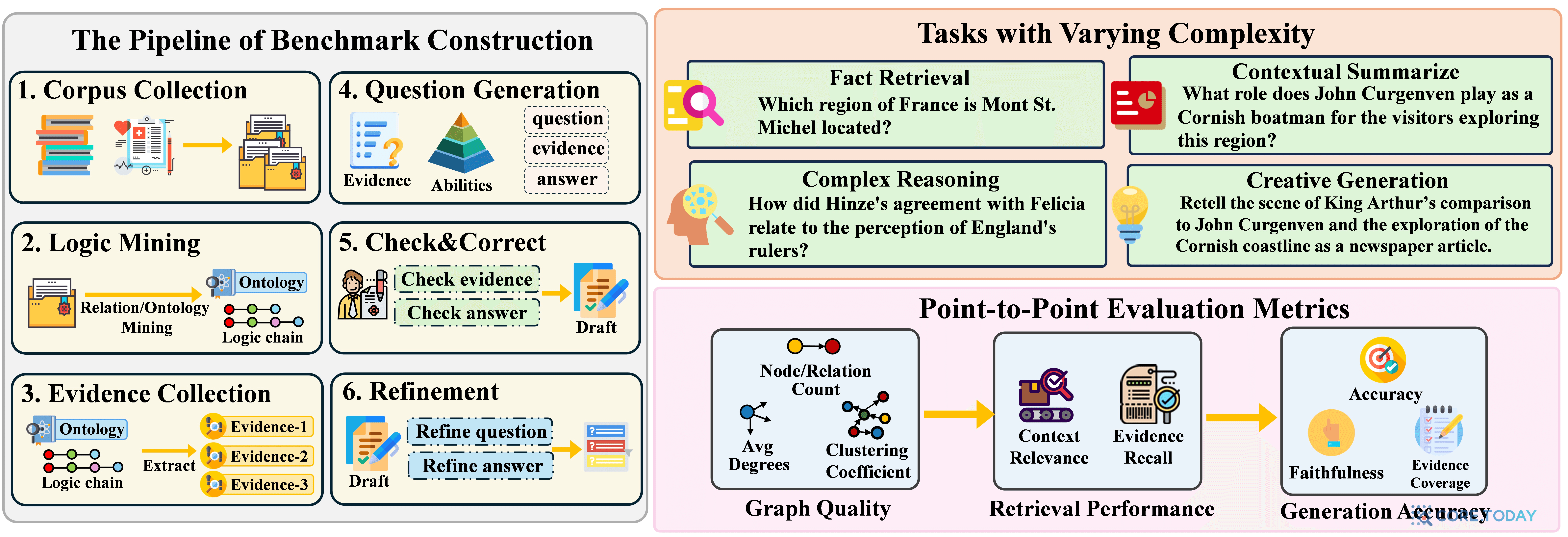
Logic Mining 단계가 핵심이다. 코퍼스에서 구축한 지식 그래프에서 n-hop 경로를 추출하고, 각 경로가 요구하는 추론의 복잡도를 자동으로 분류한다. 이를 통해 Level 1~4 과제가 코퍼스의 실제 구조에 기반하여 생성된다.
아래 차트는 각 레벨에서 요구되는 지식 폭(Knowledge Breadth)과 추론 깊이(Reasoning Depth)가 어떻게 스케일링되는지를 보여준다:
주목할 점은 Creative 레벨의 Knowledge Breadth(7.11)이 Fact 레벨(1.40)의 5배 이상이라는 것이다. 이는 창의 생성 과제가 평균 7개 이상의 문서에서 정보를 종합해야 한다는 의미다. 이런 과제에서 그래프 없이 벡터 검색만으로 필요한 모든 정보를 찾아오는 것은 거의 불가능에 가깝다.
GraphRAG-Bench는 9개의 검색 증강 생성 시스템을 동일한 조건에서 벤치마킹한다. 이 시스템들은 크게 4가지 접근 방식으로 나뉜다.
전통적 RAG (그래프 미사용):
커뮤니티 기반 GraphRAG:
경량 GraphRAG:
뉴로사이언스 영감 GraphRAG:
트리 기반:

이 9개 시스템은 모두 동일한 GPT-4o-mini를 백엔드 LLM으로 사용하여 공정한 비교를 보장한다. 평가 지표는 LLM-as-a-judge 방식으로, GPT-4o가 0~100점 스케일에서 채점한다.
논문의 Observation 1은 명확하다: "Graph-based methods do not consistently outperform text-based RAG." 모든 과제에서 GraphRAG가 우월한 것이 아니다.
사실 검색에서 RAG가 승리하는 이유는 직관적이다. "HER2 양성 유방암의 1차 치료제는 무엇인가?"라는 질문에 답하려면, 해당 내용이 적힌 정확히 하나의 청크를 찾으면 된다. 리랭킹이 적용된 RAG는 이 작업에 최적화되어 있다.
반면 GraphRAG는 같은 질문에 대해 불필요한 작업을 수행한다: 개체를 추출하고, 그래프에서 관련 노드를 찾고, 이웃 노드를 탐색하고, 이 모든 정보를 종합한다. 이 과정에서 "과도한 맥락(context overflow)"이 발생한다. 질문에 필요한 정보는 한 줄인데, GraphRAG는 관련된 10개의 개체와 20개의 관계를 가져와서 LLM에 전달한다. 노이즈가 시그널을 압도하는 것이다.
이 발견은 실무적으로 중요한 시사점을 가진다. FAQ 응답, 단일 사실 조회, 키워드 기반 검색 같은 유스케이스에서는 GraphRAG를 도입할 이유가 없다. 오히려 잘 튜닝된 RAG + Reranking 파이프라인이 더 빠르고, 더 정확하며, 더 저렴하다.
Observation 2에서 논문은 "Graph-based methods show advantages for tasks requiring multi-hop reasoning"이라고 밝힌다. 이것이 GraphRAG 존재의 핵심 근거다.
복합 추론에서 그래프가 빛나는 이유는 명확하다. "trastuzumab 내성 환자에게 적합한 2차 치료 옵션과 각 옵션의 심장독성 프로필을 비교하시오"라는 질문을 생각해보자. 이 질문은 최소 3개의 추론 단계를 요구한다: (1) trastuzumab 내성 메커니즘 파악, (2) 대체 치료 옵션 식별, (3) 각 옵션의 부작용 비교. 벡터 검색으로는 "trastuzumab 내성"과 유사한 청크를 찾을 수 있지만, 거기서 "T-DXd"를 발견하고, 다시 "T-DXd의 심장독성"으로 이어지는 추론 체인을 자동으로 구성하지 못한다.
그래프 기반 시스템은 "trastuzumab → 내성 → 대체치료 → T-DXd → 심장독성 → 모니터링"이라는 경로를 그래프에서 탐색한다. 이것이 멀티홉 추론의 핵심이다.
의료 도메인으로 좁혀보면 그래프의 우위가 더 뚜렷하다:
Contextual Summarization에서는 MS-GraphRAG(local)의 강세가 눈에 띈다. 커뮤니티 기반 요약이 넓은 범위의 정보를 구조화하는 데 유리하기 때문이다:
또한 논문은 Evidence Recall 지표를 통해 그래프 기반 검색이 실제로 필요한 증거를 더 잘 가져오는지를 측정했다. HippoRAG는 복잡한 과제에서 87.9~90.9%의 증거 재현율을 달성했다. 이는 질문에 답하기 위해 필요한 문서의 약 90%를 성공적으로 검색했다는 뜻이다. 같은 조건에서 RAG의 증거 재현율은 60~70% 수준이었다.
성능만 보면 GraphRAG를 쓰지 않을 이유가 없어 보인다. 하지만 비용이라는 현실이 있다.
비유하자면 이렇다. RAG는 경차에 일반 휘발유를 넣는 것이다. 출퇴근에 충분하고, 연비가 좋다. MS-GraphRAG(global)는 우주 왕복선에 로켓 연료를 넣는 것이다. 달까지 갈 수 있지만, 편의점에 가려고 로켓을 발사하는 것은 합리적이지 않다.
논문에서 측정한 쿼리당 토큰 사용량을 시스템별로 비교하면:
| 시스템 | 평균 토큰 | RAG 대비 | 비용 등급 |
|---|---|---|---|
| RAG (w rerank) | 879 | 1.0x | 최저 |
| HippoRAG2 | 962 | 1.1x | 최저 |
| RAPTOR | 1,118 | 1.3x | 낮음 |
| HippoRAG | 1,342 | 1.5x | 낮음 |
| Fast-GraphRAG | 2,816 | 3.2x | 중간 |
| LightRAG | 5,240 | 6.0x | 중간 |
| nano-GraphRAG | 12,890 | 14.7x | 높음 |
| MS-GraphRAG (local) | 28,140 | 32.0x | 높음 |
| MS-GraphRAG (global) | 331,375 | 377.0x | 극도로 높음 |

여기서 HippoRAG2의 효율성이 눈에 띈다. 복합 추론에서 1위를 차지하면서도, 토큰 사용량은 RAG 대비 고작 1.1배다. 이것은 HippoRAG2가 그래프 순회 결과를 효율적으로 압축하여 LLM에 전달하기 때문이다. 반면 MS-GraphRAG(global)는 모든 커뮤니티를 순회하며 각각에 대해 LLM 호출을 하기 때문에 토큰 사용량이 폭발한다.
이 결과가 의미하는 바는 명확하다: GraphRAG의 비용 문제는 아키텍처 선택의 문제이지, 그래프 사용 자체의 문제가 아니다. HippoRAG2처럼 효율적인 그래프 활용 방식을 선택하면, RAG와 거의 같은 비용으로 그래프의 혜택을 누릴 수 있다.
토큰 비용이 과제 복잡도에 따라 어떻게 스케일링되는지도 중요하다. 단순한 Fact Retrieval에서는 모든 시스템의 토큰 사용이 비교적 균일하지만, Creative Generation에서는 MS-GraphRAG(global)의 토큰 사용이 기하급수적으로 증가한다. 이는 질문이 복잡해질수록 더 많은 커뮤니티를 순회해야 하기 때문이다.
논문의 가장 통찰력 있는 발견 중 하나는 "그래프를 쓰느냐 마느냐"보다 "어떤 품질의 그래프를 쓰느냐"가 더 중요하다는 것이다.
같은 소설 코퍼스에서 5개 GraphRAG 시스템이 각각 구축한 그래프의 품질을 비교하면:
평균 차수만 봐도 압도적이지만, 더 중요한 지표는 클러스터링 계수(Clustering Coefficient)다. 이 지표는 한 노드의 이웃들이 서로 얼마나 연결되어 있는지를 나타낸다. 높은 클러스터링 계수는 "밀집된 커뮤니티"가 존재한다는 의미이고, 이는 정보를 주제별로 잘 묶어서 검색할 수 있다는 뜻이다.
HippoRAG2의 클러스터링 계수는 0.657인 반면, 이전 버전 HippoRAG는 0.100에 불과하다. 6.5배의 차이다. HippoRAG2가 전작 대비 큰 성능 향상을 보이는 핵심 이유가 바로 여기에 있다.
왜 HippoRAG2의 그래프가 이렇게 밀집되어 있을까? 핵심은 개체 추출 전략의 차이다:
이는 "같은 데이터에서도 더 풍부한 구조를 추출하는 능력"이 GraphRAG의 성능을 결정한다는 것을 의미한다. 단순히 "그래프를 쓴다"고 성능이 올라가는 것이 아니라, 좋은 그래프를 만들어야 성능이 올라간다.
논문은 동일한 과제 유형(Complex Reasoning)에서 의료와 소설 도메인의 결과를 비교함으로써, 도메인 특성이 GraphRAG의 효과에 미치는 영향을 분석한다.
NCCN 가이드라인은 태생적으로 계층적 구조를 가진다:
이런 구조는 지식 그래프로 변환했을 때 자연스럽게 밀집된 그래프가 만들어진다. 각 치료 프로토콜은 여러 약물과 연결되고, 각 약물은 여러 부작용과 연결된다. 이 연결들이 그래프에서 명시적으로 표현되므로, 멀티홉 질문에 대한 추론 경로가 명확해진다.
의료 도메인의 Complex Reasoning 결과를 보면, HippoRAG2(61.98%)가 RAG(58.64%)를 3.34%p 앞선다. 절대적인 차이는 작아 보이지만, 의료 도메인에서 이 차이는 임상적으로 유의미할 수 있다.
소설에서는 정보가 암묵적이고 분산되어 있다. "주인공의 성격 변화"는 명시적 서술이 아닌, 대화와 행동의 누적을 통해 드러난다. "사회적 비판"은 작가의 직접 진술이 아닌, 상징과 은유를 통해 전달된다.
이런 정보를 개체와 관계로 추출하는 것은 본질적으로 어렵다. "해밀턴 부인이 차를 마시며 눈물을 흘렸다"에서 추출할 수 있는 관계는 "해밀턴 부인 → 차를 마심" 정도이지만, 이 장면의 진짜 의미 — 사회적 체면과 내면적 고통의 갈등 — 은 관계 추출로 포착되지 않는다.
결과적으로 소설 도메인에서 구축된 그래프는 의료 도메인보다 희소하고 얕다. GraphRAG-Bench 코퍼스의 통계가 이를 보여준다: 소설 코퍼스의 비고립 비율 0.66은 의료 코퍼스의 0.48보다 높지만, 이는 소설에서 인물 간 관계가 많기 때문이지, 그래프의 질이 높다는 의미는 아니다.
이 결과가 실무자에게 주는 메시지는 이것이다: GraphRAG 도입을 고려할 때, 먼저 자신의 데이터가 "의료 도메인 유형"인지 "소설 도메인 유형"인지를 판단하라. 법률 문서, 기술 매뉴얼, 제품 스펙 시트 같은 구조화된 도메인에서는 GraphRAG가 큰 효과를 발휘할 가능성이 높다. 반면 고객 리뷰, SNS 데이터, 자유형식 피드백 같은 비구조화 도메인에서는 그래프 구축의 ROI를 신중히 평가해야 한다.
아래 인터랙티브 탐색기에서 9개 시스템의 벤치마크 결과를 직접 비교해볼 수 있다. 도메인(의료/소설)과 과제 유형(Fact/Reason/Summarize/Creative)을 선택하면 각 시스템의 성능을 시각적으로 확인할 수 있다.
2026년 현재, GraphRAG는 더 이상 실험 기술이 아니다. HippoRAG2, LightRAG 같은 2세대 시스템들은 비용 효율성 문제를 상당 부분 해결했고, GraphRAG-Bench 같은 벤치마크가 등장하면서 "언제 쓸지"에 대한 데이터 기반 가이드라인도 확립되고 있다.
하지만 보편적 해법은 아니다. 논문이 밝힌 바와 같이, 과제 복잡도와 도메인 특성에 따라 최적의 시스템이 달라진다. 이는 "하나의 도구로 모든 문제를 풀겠다"는 접근이 아닌, 적재적소의 도구 선택이 필요하다는 의미다.
논문의 결과가 가리키는 가장 유망한 방향은 하이브리드 라우팅이다. 쿼리가 들어왔을 때 그 복잡도를 먼저 분류하고, 단순 질문에는 RAG + Reranking을, 복합 추론에는 GraphRAG를, 글로벌 요약에는 MS-GraphRAG를 적용하는 것이다.
GraphRAG-Bench 리더보드에서는 이미 논문 발표 시점의 9개 시스템을 뛰어넘는 새로운 접근법들이 등장하고 있다:
논문은 벤치마크 결과를 바탕으로 GraphRAG 시스템 설계를 위한 3가지 원칙을 제시한다:
원칙 1: 넓은 맥락보다 정밀한 검색을 우선하라. MS-GraphRAG(global)이 377배의 토큰을 사용하면서도 항상 최고 성능을 내지 못하는 것은, 넓은 맥락이 반드시 좋은 맥락이 아니기 때문이다. 필요한 정보만 정확히 가져오는 것이 불필요한 정보를 많이 가져오는 것보다 낫다.
원칙 2: 그래프의 양보다 질을 추구하라. HippoRAG2가 소수의 밀집된 커뮤니티로 MS-GraphRAG의 수많은 커뮤니티보다 높은 성능을 낸 것이 증거다. 노드 수가 아닌 연결의 밀도가 그래프의 가치를 결정한다.
원칙 3: 맥락 증가를 능동적으로 관리하라. 과제 복잡도가 올라가면 필요한 맥락도 늘어나지만, 그 증가를 통제하지 않으면 토큰 비용이 기하급수적으로 폭발한다. 단계별 맥락 예산(context budget)을 설정하는 것이 중요하다.
2026년 후반부터 주목해야 할 트렌드:
논문의 결과를 실무 의사결정에 적용하기 위한 프레임워크를 정리한다.
질문 1: 당신의 주요 쿼리는 몇 홉의 추론을 필요로 하는가?
질문 2: 당신의 데이터는 구조화되어 있는가?
질문 3: 토큰 예산은 얼마인가?
| 시나리오 | 추천 시스템 | 성능 | 비용 |
|---|---|---|---|
| 고객 FAQ 봇 | RAG + Reranking | 60.92% | 1x |
| 의료 진단 보조 | HippoRAG2 | 61.98% | 1.1x |
| 법률 리서치 | MS-GraphRAG (local) | 64.40% | 32x |
| 기술 문서 요약 | LightRAG | 50%+ | 6x |
| 시장 분석 리포트 | MS-GraphRAG (global) | 최고 | 377x |
아래 퀴즈를 통해 당신의 유스케이스에 가장 적합한 전략을 확인해보자.
GraphRAG-Bench 논문이 전하는 핵심 메시지는 놀라울 정도로 겸손하다: "어떤 시스템도 모든 상황에서 이기지 못한다."
하지만 이 겸손한 결론이 오히려 가장 실용적인 가이드라인이 된다. 단순 사실 검색에는 RAG가, 복합 추론에는 HippoRAG2가, 맥락 요약에는 MS-GraphRAG(local)가 최적이라는 것을 데이터로 증명했기 때문이다. "만능은 없지만, 각 상황에서의 최적은 존재한다."
가장 중요한 교훈은 이것이다: 도구를 선택하기 전에, 먼저 당신의 데이터와 질문을 이해하라. 당신의 코퍼스가 어떤 구조를 가지고 있는지, 사용자의 질문이 몇 홉의 추론을 요구하는지, 토큰 예산이 얼마인지 — 이 세 가지를 알면, 최적의 시스템은 거의 자동으로 결정된다.
GraphRAG-Bench는 일회성 논문이 아니라 지속적으로 업데이트되는 커뮤니티 리소스다. 리더보드는 열려 있고, 새로운 시스템들이 계속 도전하고 있다. 2026년 4월 현재 AutoPrunedRetriever와 G-reasoner가 상위권에 진입하며, GraphRAG의 다음 진화를 예고하고 있다.
참고 자료: