"AI가 정말로 '기억'할 수 있을까?"
여러분이 친구에게 "에릭 호트의 출생지가 속한 카운티가 어디야?"라고 물었다고 상상해보자.
친구는 이렇게 생각할 것이다:
- "에릭 호트... 그 축구선수 말하는 거지?"
- "몬테벨로에서 태어났잖아"
- "몬테벨로는... 뉴욕 주 라마포 타운에 있는 마을이고..."
- "아, 록클랜드 카운티지!"
불과 2초 만에 여러 기억을 연결하여 답에 도달한다. 뇌의 해마(hippocampus)가 흩어진 기억 조각들을 연결고리로 엮어주기 때문이다.
그런데 현재의 AI에게 같은 질문을 하면? 대부분의 RAG(검색증강생성) 시스템은 "에릭 호트"를 키워드로 검색해서 관련 문서를 찾는다. 운이 좋으면 답이 그 문서 안에 있지만, "몬테벨로 → 록클랜드 카운티"처럼 두 단계를 건너뛰는 추론이 필요하면 실패할 확률이 높다.
2025년, 오하이오 주립대학교 연구팀이 이 문제에 정면으로 답하는 논문을 발표했다.
"From RAG to Memory: Non-Parametric Continual Learning for Large Language Models" — RAG를 단순한 검색 도구에서 인간과 유사한 장기기억 시스템으로 진화시키는 프레임워크, HippoRAG 2다.

1. 왜 AI에게 "기억"이 필요한가: 역사적 맥락
인간 지능의 핵심 = 연속 학습
세상은 끊임없이 변한다. 변호사는 새 판례를 파악해야 하고, 의사는 최신 치료 지침을 알아야 하며, 연구자는 매일 쏟아지는 논문을 소화해야 한다. 새로운 지식을 흡수하면서도 기존 지식을 잃지 않는 능력 — 이것이 인간 지능의 근본이다.
AI도 마찬가지다. 아무리 뛰어난 LLM이라도, 학습이 끝난 시점 이후의 세상은 모른다. 이 문제를 해결하는 방법은 크게 세 가지 흐름으로 발전해왔다.
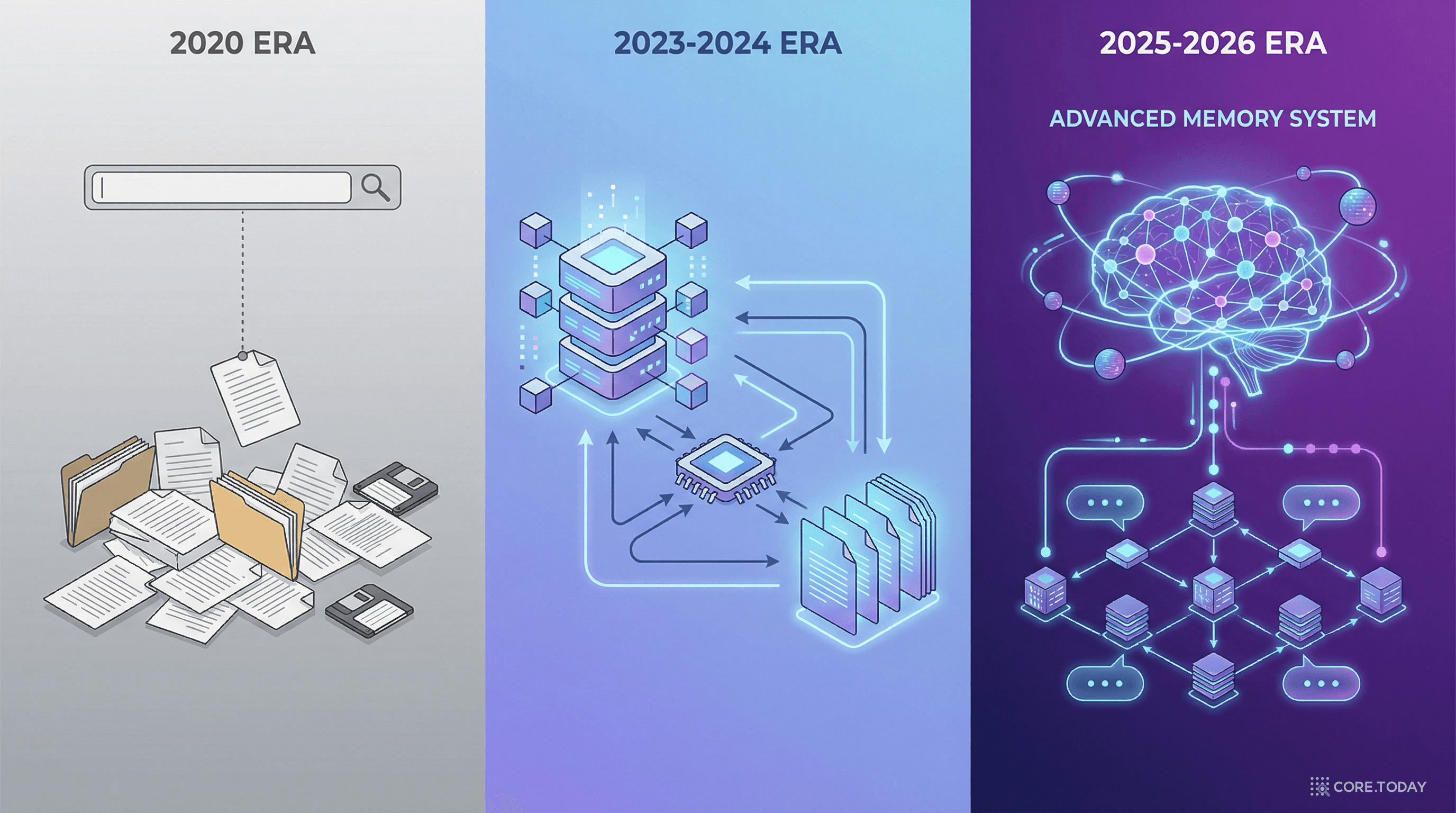
2020~
파라메트릭 업데이트
모델 자체를 재학습시킴 (Fine-tuning, LoRA 등). 비용이 높고, 이전 지식을 잊는 "치명적 망각(catastrophic forgetting)" 위험
2023~
RAG (검색증강생성)
외부 문서를 검색하여 참고자료로 제공. 모델 수정 불필요. 단순하지만 강력하여 업계 표준이 됨
2025~
메모리 시스템
RAG를 넘어 인간의 장기기억처럼 지식을 체계화. 사실 기억 + 의미 추론 + 연상 기억을 통합
Fine-tuning의 한계: 왜 "외우게 하는 것"만으로는 안 되는가
LLM에게 새 지식을 가르치는 가장 직관적인 방법은 추가 학습(Fine-tuning)이다. 하지만 여기에는 근본적 문제가 있다.
| 문제 | 설명 | 비유 |
|---|
| 치명적 망각 | 새 지식을 학습하면 이전 지식이 훼손됨 | 한식을 배우다가 양식 레시피를 잊는 요리사 |
| 높은 비용 | 대규모 모델 재학습에 막대한 GPU 비용 | 사전 전체를 다시 인쇄하는 것 |
| 실시간 불가 | 학습에 시간이 걸려 즉시 반영 불가 | 오늘 뉴스를 내일 교과서에 넣을 수 없음 |
| 지식 편집 실패 | 특정 사실만 수정하려 해도 연관 지식까지 영향 | 한 페이지만 고치려 했는데 책 전체가 흔들림 |
Cohen et al. (2024)의 연구에 따르면, 모델 편집(knowledge editing) 기법으로 특정 사실을 수정하면 관련된 다른 지식까지 오염되는 "파급 효과(ripple effect)"가 발생한다. Gu et al. (2024)도 모델 편집이 LLM의 일반 능력을 해친다는 것을 실증적으로 보여주었다.
RAG의 등장과 성공: "요리책을 옆에 두자"
이런 한계 때문에, 모델을 수정하지 않고 외부 지식을 참조하는 방식 — RAG가 사실상의 표준이 되었다.

RAG의 기본 원리는 단순하다:
질문 입력
→
벡터 검색
→
관련 문서 추출
→
LLM이 답변 생성
이 접근법은 2023년부터 폭발적으로 성장했다. Zhong et al. (2023), Xie et al. (2024)의 연구가 RAG의 효과를 입증하면서, 사실상 모든 엔터프라이즈 AI 시스템이 RAG를 채택했다.
하지만 RAG에도 근본적 약점이 있다.
2. RAG의 세 가지 약점: 인간 기억과의 격차
인간의 장기기억 시스템은 세 가지 핵심 기능을 가진다. 표준 RAG는 이 중 하나만 잘 한다.
사실 기억 (Factual Memory)
"에릭 호트의 직업은?"
→ 단순 사실 조회
표준 RAG: 강함
의미 추론 (Sense-making)
"신데렐라는 해피엔딩이었나?"
→ 긴 텍스트의 맥락을 종합
표준 RAG: 보통
연상 기억 (Associativity)
"에릭 호트 출생지의 카운티는?"
→ 서로 다른 정보를 연결
표준 RAG: 약함
이 세 가지를 구체적으로 살펴보자.
2.1 사실 기억: RAG가 잘하는 영역
"올리버 배드맨의 직업은?", "조지 랭킨의 직업은?" 같은 단순 사실 질문은 벡터 검색으로 충분하다. 질문과 가장 유사한 문서를 찾으면 답이 거기에 있다. NV-Embed-v2 같은 최신 임베딩 모델은 이런 작업에서 F1 61.9%를 달성한다.
2.2 의미 추론: 긴 이야기를 이해하는 능력
"신데렐라는 해피엔딩에 도달했는가?"라는 질문에 답하려면, 단순히 "신데렐라"가 언급된 문단 하나만 봐서는 안 된다. 왕궁 무도회 → 유리구두 분실 → 왕자의 수색 → 유리구두가 맞음 → 결혼이라는 전체 서사의 흐름을 이해해야 한다.
표준 RAG는 문서를 작은 조각(chunk)으로 나누어 검색하므로, 이런 장거리 맥락 이해에 취약하다. RAPTOR(Sarthi et al., 2024)는 트리 구조 요약으로 이 문제를 해결하려 했지만, 요약 과정에서 노이즈가 발생하여 단순 QA 성능이 크게 하락한다.
2.3 연상 기억: RAG의 아킬레스건
가장 어려운 것이 연상 기억이다. 심리학자 스즈키(Suzuki, 2005)가 정의한 연상 학습(associative learning)이란, 서로 떨어진 정보 조각들을 연결하여 새로운 지식을 도출하는 능력이다.
"에릭 호트의 출생지가 속한 카운티는?" 이 질문에 답하려면:
- 문서 A: "에릭 호트는 몬테벨로에서 태어났다"
- 문서 B: "몬테벨로는 뉴욕 주 록클랜드 카운티에 있다"
이 두 문서를 연결해야 한다. 벡터 검색은 질문과 유사한 문서 하나를 찾는 데 최적화되어 있지, 문서와 문서 사이의 관계를 추론하지 못한다.
Klein et al. (2014)은 인간의 의미 만들기 과정에서 이 "점과 점을 잇는" 능력이 핵심임을 밝혔고, 이것이 바로 인간의 해마(hippocampus)가 담당하는 역할이다.
3. 해마에서 영감을 얻다: HippoRAG의 탄생
해마는 어떻게 기억을 연결하는가
인간의 뇌에서 해마(hippocampus)는 새로운 경험을 기존 기억과 연결하는 핵심 구조다. 해마의 작동 원리를 간단히 정리하면:
1
패턴 분리 (Pattern Separation)
비슷하지만 다른 경험을 구별한다. "어제 간 카페"와 "오늘 간 카페"를 헷갈리지 않는 이유.
2
패턴 완성 (Pattern Completion)
일부 단서만으로 전체 기억을 복원한다. 노래 멜로디만 들어도 그날의 기분까지 떠오르는 것.
3
연합 형성 (Associative Binding)
서로 다른 기억을 연결한다. "에릭 호트 → 몬테벨로 → 록클랜드 카운티"처럼 점들을 잇는 것.
HippoRAG 1: 첫 번째 시도
2024년, Gutiérrez et al.은 이 해마의 원리를 RAG에 적용한 HippoRAG를 발표했다. 핵심 아이디어:
- 지식 그래프(KG) 를 해마의 인덱스로 사용
- Personalized PageRank(PPR) 알고리즘으로 연관 기억을 탐색
이것은 혁신적이었지만, 문제가 있었다.
HippoRAG 1의 한계
1. 쿼리 기반 문맥화가 부족하여 대규모 담화 이해 성능 저하
2. 개체 중심 접근으로 구문(phrase) 수준 정보 손실
3. 사실 기억 같은 단순 작업에서 표준 RAG보다 오히려 낮은 성능
그리고 다른 구조 강화 RAG 방법들도 각각의 약점을 가지고 있었다:
- RAPTOR: LLM 요약 과정의 노이즈가 단순 QA 성능을 크게 떨어뜨림
- GraphRAG: 비용이 너무 높고, 검색 범위가 좁음
- LightRAG: 개체 수준의 세밀함이 부족
모든 기존 방법이 세 가지 기억 유형 중 하나에서 심각하게 뒤처졌다. 사실 기억을 잘하면 연상이 약하고, 연상이 강하면 사실 기억이 떨어졌다.
4. HippoRAG 2: 세 마리 토끼를 잡다
핵심 설계 철학
HippoRAG 2의 목표는 명확하다: 사실 기억, 의미 추론, 연상 기억을 모두 높은 수준으로 달성하는 것. 이를 위해 HippoRAG 1의 뼈대를 유지하면서 네 가지 핵심 개선을 도입했다.
Dense-Sparse 통합
→
깊은 문맥화
→
인식 메모리
→
시드 노드 개선
4.1 전체 아키텍처: 오프라인 인덱싱 + 온라인 검색
HippoRAG 2는 크게 두 단계로 작동한다.
오프라인 인덱싱 (문서를 기억으로 변환)
Step 1
트리플 추출 (OpenIE)
LLM이 각 문서에서 (주어, 관계, 목적어) 트리플을 추출한다. 예: "에릭 호트, 태어난 곳, 몬테벨로"
Step 2
동의어 감지
임베딩 유사도로 같은 개념의 다른 표현을 연결한다. "Montebello" = "몬테벨로". 유사도 0.8 이상이면 동의어 엣지 추가
Step 3
Dense-Sparse 통합
구문 노드(개념)와 문서 노드(맥락)를 하나의 지식 그래프에 통합. 개념의 간결함과 맥락의 풍부함을 모두 확보
온라인 검색 (질문에 답하기)
Step 1
쿼리→트리플 변환
질문을 트리플로 변환하여 KG의 관련 노드를 찾는다. "에릭 호트의 출생지 카운티?" → (에릭 호트, 태어난 곳, 몬테벨로)
Step 2
트리플 필터링 (인식 메모리)
LLM이 검색된 트리플 중 관련 없는 것을 걸러낸다. 인간 기억의 "인식(recognition)" 과정을 모방
Step 3
시드 노드 가중치 설정
필터링된 트리플의 구문 노드와 문서 노드에 PPR 초기 확률을 할당
Step 4
PPR 그래프 탐색
Personalized PageRank로 KG를 탐색하여 가장 관련성 높은 문서를 순위화
Step 5
QA 생성
최종 선택된 문서들을 컨텍스트로 LLM에게 전달하여 답변 생성
4.2 핵심 혁신 1: Dense-Sparse 통합
이것이 HippoRAG 2의 가장 중요한 혁신이다.
문제: HippoRAG 1의 KG는 개체 중심이었다. "에릭 호트", "몬테벨로" 같은 개념 노드만 있었다. 이렇게 하면 연상 기억에는 좋지만, 원본 문서의 풍부한 맥락을 잃어버린다.
영감: 뇌과학에서 말하는 Dense coding과 Sparse coding (Beyeler et al., 2019)
Dense Coding (밀집 코딩)
많은 뉴런이 동시에 활성화되어 분산적으로 정보를 표현한다.
→ 문서 노드: 풍부한 맥락, 하지만 중복적
비유: 소설 한 페이지 전체를 기억하는 것
Sparse Coding (희소 코딩)
소수의 뉴런만 활성화되어 효율적으로 정보를 표현한다.
→ 구문 노드: 간결한 개념, 일반화 용이
비유: "에릭 호트 = 몬테벨로 출생"만 기억하는 것
HippoRAG 2는 두 가지를 모두 사용한다. 각 문서(passage)를 문서 노드로 만들고, 추출된 구문들을 구문 노드로 만들어, 맥락 엣지(context edge)로 연결한다. 이렇게 하면:
- 사실 기억: 문서 노드의 풍부한 맥락으로 정확한 사실 조회 가능
- 연상 기억: 구문 노드의 연결 구조로 멀티홉 추론 가능
- 의미 추론: 문서 노드를 통해 긴 텍스트의 전체 맥락 파악 가능
4.3 핵심 혁신 2: 깊은 문맥화 (Deeper Contextualization)
HippoRAG 1은 NER(개체명 인식)로 쿼리를 처리했다. "에릭 호트의 출생지 카운티?" → "에릭 호트"만 추출.
문제는 이것이 쿼리의 의도를 반영하지 못한다는 것이다. "에릭 호트의 직업"을 묻는 것과 "에릭 호트의 출생지"를 묻는 것은 완전히 다른 검색이 필요한데, NER로는 둘 다 "에릭 호트"로만 검색한다.
HippoRAG 2는 쿼리→트리플(Query-to-Triple) 방식으로 전환했다:
NER (HippoRAG 1)
질문: "에릭 호트의 출생지가 속한 카운티는?"
추출: [에릭 호트]
→ "에릭 호트" 관련 모든 문서를 동일 가중치로 검색
Query-to-Triple (HippoRAG 2)
질문: "에릭 호트의 출생지가 속한 카운티는?"
추출: (에릭 호트, 태어난 곳, 몬테벨로), (에릭 호트, 태어난 곳, 뉴욕)
→ "출생지"와 관련된 맥락만 집중 검색
이 개선만으로 Recall@5가 평균 12.5% 향상되었다.
4.4 핵심 혁신 3: 인식 메모리 (Recognition Memory)
인간의 기억 과정은 두 단계다 (Uner & Roediger III, 2022):
- 회상(Recall): 관련 정보를 떠올림
- 인식(Recognition): 떠올린 정보가 정말 관련 있는지 판단
기존 RAG는 1단계만 했다. 검색 결과를 그대로 LLM에 전달했다. HippoRAG 2는 2단계 — 인식 메모리를 추가했다.
쿼리→트리플로 추출된 트리플 목록을 LLM에게 보여주고, "이 중에서 질문과 정말 관련 있는 것만 골라줘"라고 요청한다. 이렇게 하면 노이즈가 줄어들고, PPR 알고리즘의 시드 노드가 더 정확해진다.
쿼리 분석
"에릭 호트 출생지의 카운티?" → 트리플 5개 생성
인식 필터링
LLM이 5개 중 관련 있는 2개만 선택: (에릭 호트, born in, 몬테벨로), (에릭 호트, born in, 뉴욕)
PPR 탐색
필터링된 노드를 시드로 그래프 탐색 → 몬테벨로 → 록클랜드 카운티 경로 발견
4.5 핵심 혁신 4: Personalized PageRank의 시드 노드 개선

Personalized PageRank(PPR)는 원래 Google의 웹 페이지 순위 알고리즘인 PageRank의 변형이다. "특정 시작점에서 랜덤 워크를 시작하면, 어떤 노드에 가장 자주 도착하는가?"를 계산한다.
HippoRAG 2에서는 두 종류의 시드 노드를 사용한다:
- 구문 노드: 인식 메모리로 필터링된 트리플에서 추출. 랭킹 점수에 비례하는 초기 확률 부여
- 문서 노드: 임베딩 유사도로 매칭. 구문 노드만으로 부족할 때 보완 역할
문서 노드의 확률에는 가중치 팩터(weight factor = 0.05)를 곱하여, 구문 노드가 주도하되 문서 노드가 보조하는 균형을 맞춘다.
5. 실제로 어떻게 작동하는가: 파이프라인 예시
논문의 Figure 5에서 제시한 실제 파이프라인 예시를 살펴보자.
Step 1: 쿼리 → 트리플 변환
질문에서 5개 트리플 생성:
- (에릭 호트, born in, 몬테벨로)
- (에릭 호트, born in, 뉴욕)
- (에릭 호트, is a, 미국인)
- (에릭 호트, born on, 1987년 2월 16일)
- (에릭 호트, is a, 축구선수)
Step 2: 트리플 필터링 (인식 메모리)
LLM 판단: 출생지 카운티를 묻고 있으므로, 장소 관련 트리플만 유지
→ (에릭 호트, born in, 몬테벨로), (에릭 호트, born in, 뉴욕)
Step 3: PPR 시드 노드 설정
- 구문 노드: 몬테벨로(1.0), 에릭 호트(0.995), 뉴욕(0.989)
- 문서 노드: 에릭 호트 문서(0.05), 호튼 파크 문서(0.031) ...
Step 4: PPR 실행 → 문서 순위화
1위: 에릭 호트 — "에릭 호트(1987.2.16, 몬테벨로, 뉴욕 출생)는 미국 축구선수..."
2위: 호튼 파크 (세인트폴, 미네소타)
3위: 몬테벨로, 뉴욕 — "몬테벨로는 라마포 타운의 마을, 록클랜드 카운티, 뉴욕"
4위: 허트포드셔
5위: 헐 카운티, 퀘벡
최종 답변: 록클랜드 카운티
NV-Embed-v2(벡터 검색)도 "에릭 호트" 문서를 1위로 찾았다. 하지만 "몬테벨로 → 록클랜드 카운티" 연결 문서를 3위 안에 가져오지 못했다. HippoRAG 2는 그래프 구조를 통해 2단계 추론 경로를 자연스럽게 탐색하여 정답 문서를 3위에 배치했다.
6. 실험 결과: 숫자가 증명한다
6.1 벤치마크 구성
연구팀은 세 가지 유형의 기억 능력을 각각 평가하는 벤치마크를 설계했다:
| 기억 유형 | 데이터셋 | 특징 |
|---|
| 사실 기억 | NaturalQuestions (1,000)
PopQA (1,000) | 단순 개체 중심 사실 질문 |
| 연상 기억 (멀티홉) | MuSiQue (1,000)
2WikiMultiHopQA (1,000)
HotpotQA (1,000)
LV-Eval (124) | 여러 문서를 연결하는 추론 필요 |
| 의미 추론 | NarrativeQA (293) | 장편 소설 전체의 이해 필요 |
6.2 QA 성능 (F1 점수)
Llama-3.3-70B-Instruct를 QA 리더로 사용한 결과:
HippoRAG 2
59.8 (평균)
NV-Embed-v2
55.7
HippoRAG 1
53.1
RAPTOR
48.8
GraphRAG
49.6
LightRAG
6.6
주목할 점들:
- HippoRAG 2가 모든 카테고리에서 가장 높은 평균 F1을 달성
- LightRAG의 처참한 결과(F1 6.6) — 이중 수준 검색의 한계
- 구조 강화 RAG 방법들(RAPTOR, GraphRAG, LightRAG, HippoRAG 1)은 각자의 강점 영역 밖에서 급격한 성능 하락
6.3 세부 결과 비교
| 방법 | 사실 기억
(NQ / PopQA) | 연상 기억
(MuSiQue / 2Wiki / HotpotQA) | 의미 추론
(NarrativeQA) |
|---|
| HippoRAG 2 | 63.3 / 51.7 | 74.7 / 90.4 / 96.3 | 78.2 |
| NV-Embed-v2 | 61.9 / 55.7 | 45.7 / 61.5 / 75.3 | 55.7 |
| HippoRAG 1 | 55.3 / 53.9 | 35.1 / 71.8 / 63.5 | 53.1 |
| RAPTOR | 50.7 / 56.2 | 28.9 / 52.1 / 69.5 | 48.8 |
| GraphRAG | 46.9 / 48.1 | 38.5 / 58.6 / 68.6 | 49.6 |
| LightRAG | 16.6 / 2.4 | 1.6 / 11.6 / 2.4 | 6.6 |
핵심 발견:
- HippoRAG 2는 연상 기억(멀티홉)에서 NV-Embed-v2 대비 평균 7% 이상 향상 — LV-Eval에서는 9.5%, 2Wiki에서는 13.9% 향상
- 사실 기억에서도 경쟁력 유지 — NQ에서 63.3으로 NV-Embed-v2(61.9)를 소폭 상회
- 의미 추론에서 압도적 — NarrativeQA에서 78.2로, 2위 NV-Embed-v2(55.7)를 22포인트 이상 격차
6.4 검색 성능 (Passage Recall@5)
QA 성능뿐 아니라 검색 자체의 품질도 확인했다:
HippoRAG 2
87.1 (멀티홉 평균)
NV-Embed-v2 (7B)
73.4
GritLM-7B
72.2
GTE-Qwen2-7B
70.5
RAPTOR
65.6
HippoRAG 2는 7B 파라미터 임베딩 모델들을 최소 9.8% 이상 상회하며, 멀티홉 검색에서 가장 높은 Recall@5를 달성했다.
7. 연속 학습 실험: 지식이 쌓여도 무너지지 않는가

현실에서 RAG 시스템은 지속적으로 새로운 문서가 추가된다. 검색 코퍼스가 커질수록 성능이 유지되는지가 중요하다.
연구팀은 NQ와 MuSiQue 데이터를 4등분하여, 점진적으로 코퍼스를 확장하면서 성능을 측정했다.
코퍼스 크기별 F1 점수 (근사치)
단순 QA (NQ)
- 25% → HippoRAG 2: ~62, NV-Embed-v2: ~58
- 50% → HippoRAG 2: ~61, NV-Embed-v2: ~55
- 75% → HippoRAG 2: ~60, NV-Embed-v2: ~52
- 100% → HippoRAG 2: ~59, NV-Embed-v2: ~48
멀티홉 QA (MuSiQue)
- 25% → HippoRAG 2: ~55, NV-Embed-v2: ~48
- 50% → HippoRAG 2: ~50, NV-Embed-v2: ~45
- 75% → HippoRAG 2: ~47, NV-Embed-v2: ~43
- 100% → HippoRAG 2: ~45, NV-Embed-v2: ~40
핵심 발견: 코퍼스가 4배로 커져도 HippoRAG 2의 성능 하락이 NV-Embed-v2보다 완만하다. 특히 단순 QA에서는 HippoRAG 2의 하락률이 더 낮아, 더 로버스트한 연속 학습 능력을 보여준다.
다만, 멀티홉 QA에서는 두 방법 모두 비슷한 비율로 하락하며, 이는 연상 기억 과제에서 코퍼스 규모의 영향이 근본적으로 존재함을 시사한다.
8. 비용과 효율성: 현실적인 트레이드오프
성능이 좋아도 비용이 터무니없다면 실용적이지 않다. 논문은 MuSiQue 코퍼스(11,656 문서) 기준으로 비용을 상세히 비교했다.
| 지표 | NV-Embed-v2 | RAPTOR | LightRAG | GraphRAG | HippoRAG 2 |
|---|
| 인덱싱 토큰 | — | 1.7M (18.5%) | 68.5M (744.6%) | 115.5M (1255.4%) | 9.2M (100%) |
| 인덱싱 시간 | 12.1분 (12.3%) | 100.5분 (101.0%) | 235.0분 (236.2%) | 277.0분 (278.4%) | 99.5분 (100%) |
| 쿼리당 시간 | 0.3초 (25.0%) | 0.6초 (50.0%) | 13.3초 (1008.3%) | 10.7초 (891.7%) | 1.2초 (100%) |
| QA GPU 메모리 | 1.7GB (17.2%) | 1.4GB (14.1%) | 4.5GB (45.5%) | 3.7GB (37.4%) | 9.9GB (100%) |
핵심 인사이트:
- HippoRAG 2는 GraphRAG 대비 인덱싱 토큰 12.5배 절감, LightRAG 대비 7.4배 절감
- 쿼리 응답 시간 1.2초 — LightRAG(13.3초)와 GraphRAG(10.7초)보다 훨씬 빠름
- GPU 메모리 사용량은 다른 방법들보다 높지만, 이는 Dense-Sparse 통합의 대가
- 모든 구조 강화 RAG 중 유일하게 표준 RAG(NV-Embed-v2)를 QA 성능에서 상회하면서도 실용적인 속도 유지
9. 각 개선의 기여도: 어떤 것이 가장 중요한가
연구팀의 어블레이션 실험 결과:
HippoRAG 2 (전체)
87.1
필터링 제거 시
86.4
문서 노드 제거 시
81.0
NER→노드 방식 (구식)
74.6
쿼리→노드 방식
59.6
- 쿼리→트리플 변환이 가장 큰 기여 — NER 방식 대비 12.5% 향상
- Dense-Sparse 통합(문서 노드)이 두 번째 — 제거 시 6.1% 하락
- 인식 메모리(필터링)는 미미한 기여 — 하지만 특정 어려운 질문에서는 중요
10. 2026년, 이 기술은 어디로 가고 있는가
RAG에서 메모리로: 패러다임의 전환
HippoRAG 2가 ICML 2025에 채택된 것은 단순한 학술적 성과가 아니다. 이것은 AI 시스템이 지식을 다루는 방식의 패러다임 전환을 의미한다.
과거
검색 (Search)
질문과 유사한 문서를 찾는다. 문서 간 관계는 무시.
현재
검색증강 (RAG)
검색 결과를 LLM에 전달하여 답변 생성. 구조화된 검색 시도(GraphRAG 등).
미래
기억 (Memory)
지식을 인간 뇌처럼 체계적으로 저장하고, 연상·추론·맥락 이해를 통합하여 활용.
2026년의 실무 적용 시나리오
1. 법률 AI 어시스턴트
변호사가 "김씨 사건과 유사한 판례 중, 피해자가 미성년자이고 가해자가 공무원인 것은?"이라고 물으면, 단순 벡터 검색으로는 불가능하다. 하지만 HippoRAG 2 방식이라면:
- "김씨 사건" → 관련 트리플 추출
- "미성년자 피해자" + "공무원 가해자" → 두 조건을 그래프에서 교차 탐색
- 연관 판례를 멀티홉 추론으로 발견
2. 의료 연구 플랫폼
"A 약물과 B 약물의 상호작용이 C 질환에 미치는 영향"을 묻는 질문은 최소 3단계의 연상이 필요하다. 지식 그래프 기반 메모리 시스템이 약물-약물, 약물-질환, 질환-증상 간의 연결을 추적할 수 있다.
3. 기업 지식 관리
수만 건의 내부 문서, 회의록, 슬랙 메시지를 단순 검색이 아닌 연결된 기억으로 관리한다면? "작년에 A 프로젝트에서 B 문제가 발생했을 때 C 팀이 취한 조치는?"같은 복잡한 질문에도 답할 수 있다.
오픈소스와 접근성
HippoRAG 2는 완전한 오픈소스로 공개되어 있다.
- GitHub: OSU-NLP-Group/HippoRAG
- 기본 LLM: Llama-3.3-70B-Instruct (오픈소스)
- 임베딩: NV-Embed-v2 (오픈소스)
- GPT-4o-mini로도 유사한 성능 확인
상용 API 없이도 구현할 수 있다는 것은 실무 적용에 큰 장점이다.
11. 남은 과제와 한계
논문 스스로도 인정하는 한계점이 있다:
1
트리플 필터링의 정밀도
에러 분석 결과, 실패 사례의 26%에서 트리플 필터링 후 관련 구문이 매칭되지 않음. 인식 메모리의 정밀도 개선 필요.
2
그래프 탐색의 한계
PPR이 올바른 시드에서 시작해도, 그래프 구조상 정답 경로를 찾지 못하는 경우 존재. 50%의 실패 사례에서 관련 노드가 그래프에 존재하지만 도달하지 못함.
3
GPU 메모리 비용
Dense-Sparse 통합으로 임베딩을 많이 사용하여, QA 시 GPU 메모리가 9.9GB로 다른 방법들보다 높음.
12. 결론: AI의 기억은 이제 시작이다
HippoRAG 2가 보여준 것은 명확하다:
RAG는 AI에게 참고서를 주는 것이고, 메모리 시스템은 AI가 진정으로 "기억"하는 것이다.
인간의 해마에서 영감받은 이 접근법은, 단순한 벡터 검색으로는 불가능했던 연상 추론, 장거리 맥락 이해, 사실 기억을 모두 달성하는 데 성공했다. 그것도 오픈소스 모델만으로.
2026년 현재, AI 시스템의 "기억력"은 단순히 더 많은 문서를 검색하는 것이 아니라, 정보를 연결하고, 맥락을 이해하고, 추론하는 능력으로 정의되고 있다. HippoRAG 2는 그 첫 번째 완전한 구현체다.
앞으로 이 분야는 에피소드 기억(episodic memory), 작업 기억(working memory), 메타인지(metacognition) 등 인간 기억의 더 많은 측면을 AI에 구현하는 방향으로 발전할 것이다.
우리가 가장 인간다운 것 — 경험을 통해 배우고, 기억하고, 연결하는 것 — 을 기계에 가르치는 여정은 이제 막 시작되었다.
참고 문헌
- Gutiérrez, B. J., Shu, Y., Qi, W., Zhou, S., & Su, Y. (2025). From RAG to Memory: Non-Parametric Continual Learning for Large Language Models. ICML 2025. arXiv:2502.14802
- Gutiérrez, B. J., et al. (2024). HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. NeurIPS 2024.
- Sarthi, P., et al. (2024). RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. ICLR 2024.
- Edge, D., et al. (2024). From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
- Guo, Z., et al. (2024). LightRAG: Simple and Fast Retrieval-Augmented Generation.
- Cohen, R., et al. (2024). Evaluating the Ripple Effects of Knowledge Editing in Language Models. TACL.
- Suzuki, W. A. (2005). Associative Learning and the Hippocampus. Psychological Science Agenda.
- Beyeler, M., et al. (2019). Neural Correlates of Sparse Coding and Dimensionality Reduction. PLoS Comput Biol.
- Uner, O. & Roediger III, H. L. (2022). Do Recall and Recognition Lead to Different Retrieval Experiences? American Journal of Psychology.




