들어가며: "관계"가 곧 데이터인 세상
2026년, 우리가 매일 접하는 정보의 대부분은 관계로 이루어져 있다.
- 카카오톡에서 "철수"가 "영희"에게 메시지를 보낸다 → 소셜 관계
- 은행에서 A 계좌가 B 계좌로 300만 원을 이체한다 → 금융 거래 관계
- 환자가 "메트포르민"을 복용하고 "당뇨병" 진단을 받는다 → 의학적 관계
- AI 에이전트가 API를 호출하고 결과를 다음 도구에 전달한다 → 도구 호출 관계
이런 데이터를 표(테이블)에 넣으면 어떻게 될까?
| 사람 | 관계 | 대상 |
|---|
| 철수 | 메시지 전송 | 영희 |
| A계좌 | 이체 | B계좌 |
| 환자 | 복용 | 메트포르민 |
한 줄씩 보면 이해되지만, "철수의 친구가 근무하는 회사의 제품을 사용하는 사람들" 같은 질문에 답하려면? 테이블을 몇 번이고 JOIN 해야 하고, 쿼리는 점점 복잡해진다.
그래프 데이터베이스는 이 문제를 해결하기 위해 태어났다. 그리고 2026년, 여기에 뉴럴 네트워크를 결합하려는 새로운 시도가 본격화되고 있다.
이 글에서는 HKUST(홍콩과기대) 연구진이 2026년 2월 발표한 논문 "Towards Neural Graph Data Management"를 중심으로, 이 혁명의 전모를 파헤쳐 본다.
1장. 그래프 데이터베이스의 역사 — 테이블에서 그래프로
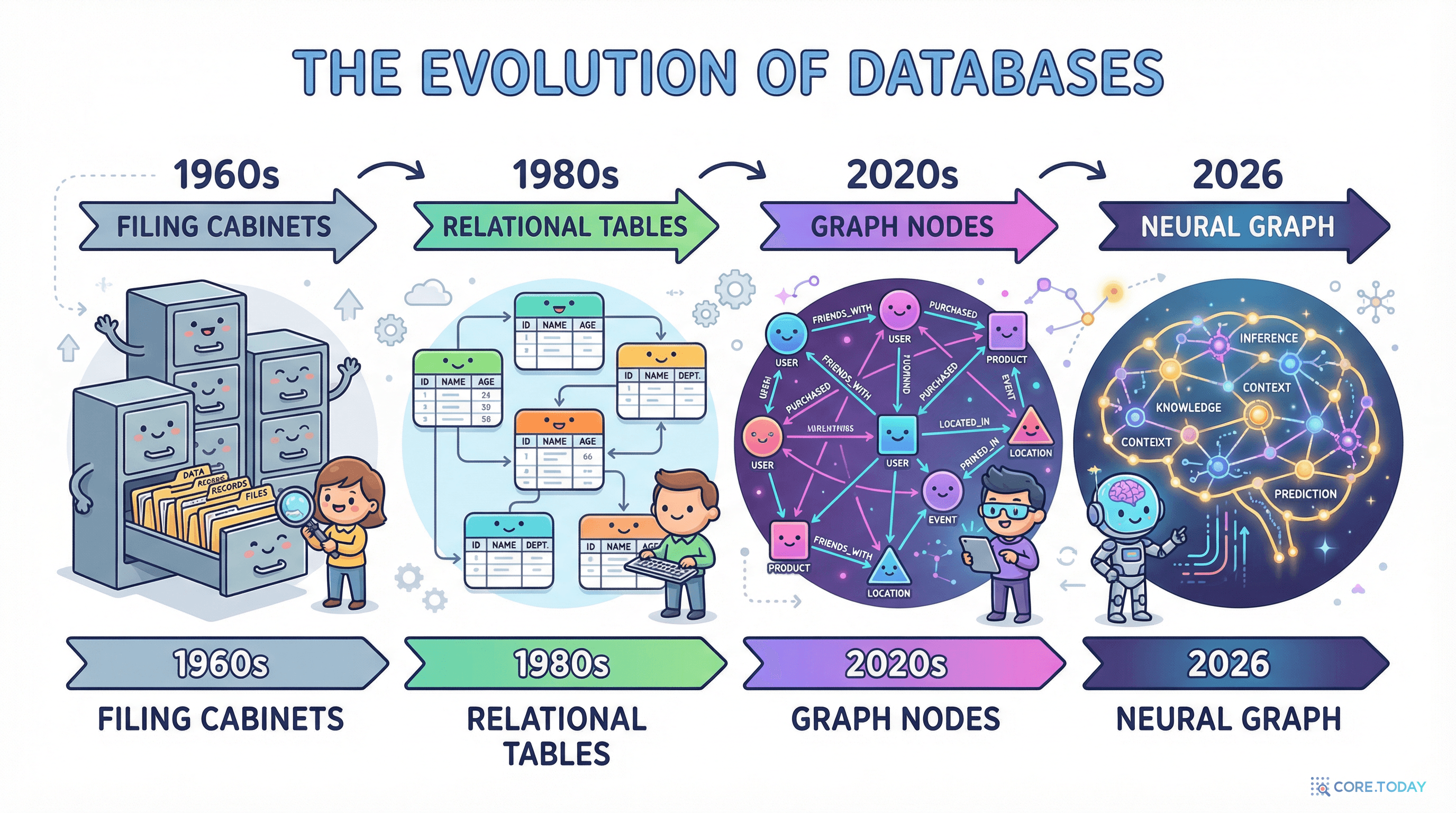
1960~1990년대: 관계형 데이터베이스의 시대
1970년, IBM의 에드거 코드(Edgar Codd)가 관계형 모델을 발표했다. 데이터를 깔끔한 테이블(행과 열)에 넣고, SQL이라는 언어로 조회하는 방식이다. Oracle, MySQL, PostgreSQL — 지금까지도 세계를 지배하는 패러다임이다.
하지만 관계형 DB에는 근본적인 한계가 있었다:
"관계(relationship)"를 표현하려면 별도의 테이블을 만들고 외래 키(FK)로 연결해야 한다. 관계가 복잡해질수록 JOIN이 기하급수적으로 늘어난다.
SNS에서 "친구의 친구의 친구"를 찾으려면? 3단계 JOIN이 필요하고, 데이터가 수백만 건이면 쿼리가 수십 초 걸릴 수 있다.
2000년대: 그래프 데이터베이스의 등장
2000년, 스웨덴의 세 엔지니어 — 에밀 아이프렘(Emil Eifrem), 요한 스벤손, 페테르 노이바우어 — 가 Neo4j의 개발을 시작했다. 핵심 아이디어는 단순했다:
"데이터를 노드(점)와 엣지(선)로 저장하면, 관계 탐색이 JOIN 없이 직접 가능하다."
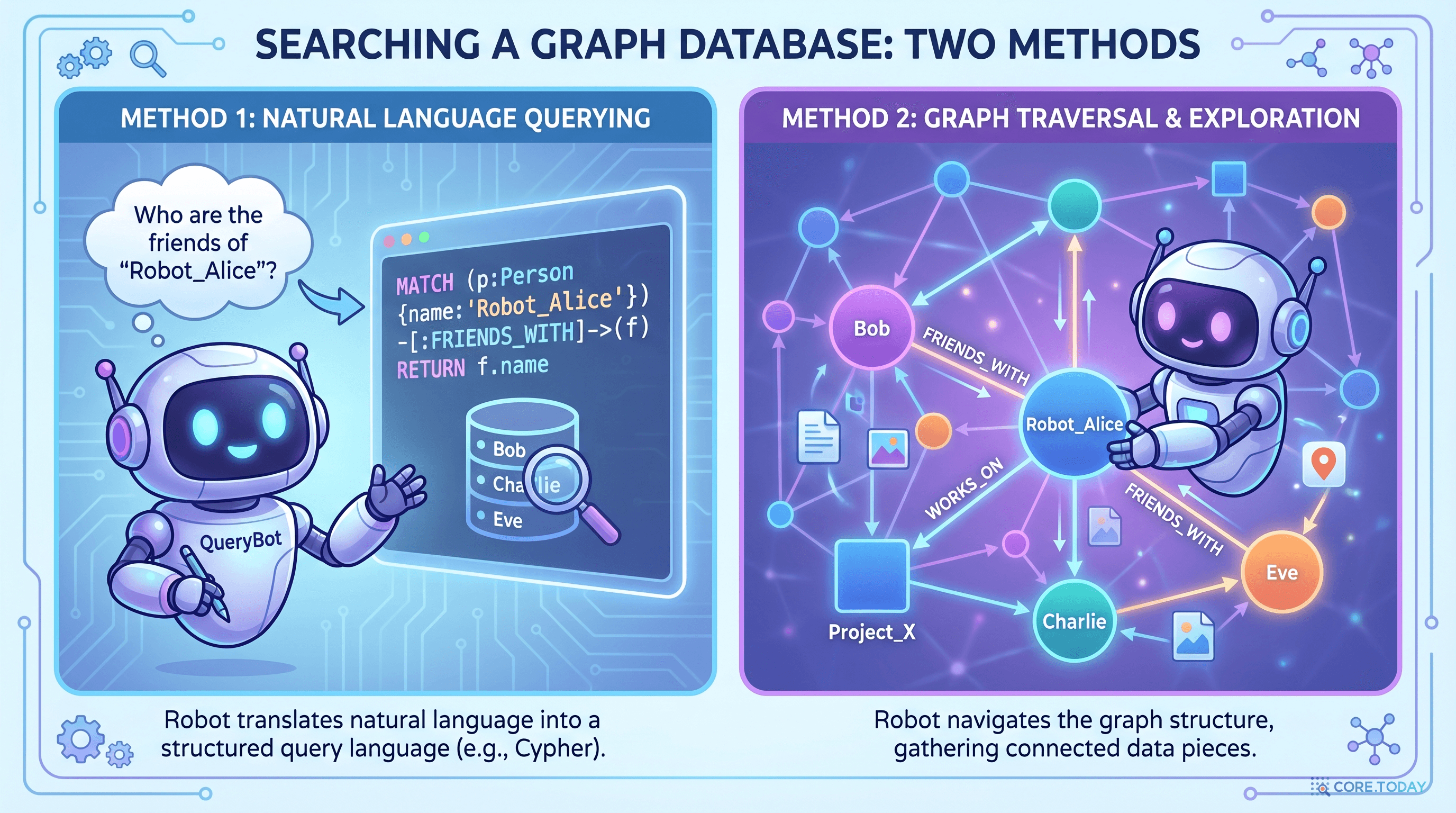
(철수)-[:친구]->(영희)-[:근무]->(코어닷)-[:개발]->(AI 플랫폼)
SQL로 3번 JOIN할 일을 그래프 DB에서는 하나의 경로 탐색으로 끝낸다. 이것이 Cypher 쿼리 언어의 매력이다:
hljs language-cypher
MATCH (a:Person {name: "철수"})-[:친구]->(b)-[:근무]->(c:Company)-[:개발]->(p:Product)
RETURN p.name
시각적이고 직관적이다. 마치 화이트보드에 그림을 그리듯 쿼리를 작성할 수 있다.
2024년: ISO GQL 표준의 탄생
2024년 4월, GQL(Graph Query Language)이 ISO 국제 표준으로 승인되었다. SQL이 관계형 DB의 표준어가 된 것처럼, GQL은 그래프 DB의 국제 표준어가 된 것이다. Cypher와 밀접하게 연계되어 있으며, 이는 그래프 데이터베이스가 더 이상 틈새가 아닌 주류 기술로 자리잡았음을 의미한다.
2장. 문제: 현실 데이터는 "완벽하지 않다"
빈 칸투성이의 현실
그래프 데이터베이스는 훌륭하지만, 한 가지 치명적인 전제가 있다:
"저장된 데이터가 완전하다(complete)"고 가정한다.
현실은 어떨까?
Freebase에 등록된 인물의 94%는 출생지 정보가 없다. Wikidata에 등록된 건물의 99.6%는 높이가 기록되지 않았다. 현실의 지식 그래프는 구멍투성이다.
기존 그래프 DB에 "서울에서 태어난 작가가 쓴 소설의 영화화 작품은?"이라고 질문하면, 출생지가 누락된 작가는 결과에서 완전히 빠진다. 있는 데이터만 찾을 수 있고, 없는 데이터는 존재하지 않는 것으로 처리된다.
세 가지 근본 문제
논문의 저자들은 기존 시스템의 근본적 한계를 세 가지로 정리했다:
1
제한된 쿼리 표현력
기존 뉴럴 그래프 연구는 대부분 존재 일차논리(EFO)에 갇혀 있다. "A와 B가 연결되어 있는가?" 수준의 패턴 매칭만 가능하고, "평균 이체 금액은?"같은 집계(aggregation) 연산은 지원하지 못한다.
2
노이즈 강건성 부재
금융 사기 탐지에서 공격자는 정상처럼 보이는 허위 거래를 삽입한다. 기존 시스템은 관측된 구조를 그대로 신뢰하여 "거짓 엣지"를 진짜로 받아들인다.
3
동적 업데이트 불가
고빈도 거래나 실시간 추천 시스템에서는 하루에 기가바이트 단위로 그래프가 변한다. 기존 뉴럴 방법은 업데이트마다 전체 재훈련이 필요해 비실용적이다.
3장. 뉴럴 그래프 데이터베이스(NGDB)란?
핵심 아이디어: "빈 칸을 AI로 채우자"
뉴럴 그래프 데이터베이스(Neural Graph Database, NGDB)는 이름 그대로 그래프 데이터베이스 + 뉴럴 네트워크의 결합이다.
기존 그래프 DB가 "저장된 것만 검색"했다면, NGDB는 "없는 것도 추론"한다.
기존 그래프 DB
→
"있는 데이터"만 검색
→
누락 = 존재하지 않음
뉴럴 그래프 DB
→
"있는 데이터" + "없는 데이터" 추론
→
누락 = 추론 가능
두 가지 아키텍처 패러다임
학계에서는 NGDB의 구조를 크게 두 가지로 정의한다:
패러다임 1: 확장형 (Besta et al., 2022)
기존 그래프 DB의 심볼릭 저장소는 유지하면서, 인코더(예: LPG2vec)가 그래프 토폴로지를 임베딩으로 변환한다. 기존 시스템 위에 뉴럴 계층을 얹는 방식.
패러다임 2: 잠재 공간형 (Ren et al., 2023)
아예 잠재 공간(latent space)에서 데이터를 관리하는 시스템:
뉴럴 그래프 저장소
그래프 스토어 + 피처 스토어 + 임베딩 스토어
뉴럴 쿼리 엔진
쿼리 플래너 + 쿼리 실행기 + 검색 모듈
쿼리 자체를 벡터로 인코딩하고, 임베딩 공간에서 가장 가까운 답을 찾는다. 마치 벡터 데이터베이스가 "의미"로 검색하듯, NGDB는 "관계의 의미"로 검색하는 것이다.
NGDB가 지켜야 할 4대 원칙
| 원칙 | 설명 | 비유 |
|---|
| 데이터 불완전성 가정 | 그래프에 빈 곳이 있다고 전제 | 퍼즐에 빠진 조각이 있어도 그림을 추론 |
| 귀납적 일반화 | 새로운 엔티티에도 재훈련 없이 대응 | 처음 보는 배우도 장르와 출연작으로 추천 가능 |
| 표현력 | 일차논리(FOL) 수준의 복잡한 관계 표현 | "A이고 B가 아닌 것 중 C와 관련된 것" |
| 다중모달 지원 | 텍스트, 숫자, 시간, 이미지 등 혼합 | 환자의 CT 이미지 + 진단 텍스트 + 유전자 데이터 |
4장. NGDBench — 뉴럴 그래프 DB 벤치마크의 탄생
왜 새로운 벤치마크가 필요했나?
기존 벤치마크들의 한계를 한눈에 보자:
| 벤치마크 | 쿼리 지원 | 집계 | 다중변수 | 동적 업데이트 |
|---|
| Query2Box | EPFO (AND, OR, ∃) | 미지원 | 미지원 | 미지원 |
| LitCQD | EPFO + 수치 | 지원 | 미지원 | 미지원 |
| EFO_k-CQA | FOL | 미지원 | 지원 | 미지원 |
| NGDBench | Full Cypher | 지원 | 지원 | 지원 |
NGDBench는 최초로 모든 항목을 지원하는 통합 벤치마크다.
5개 도메인, 5가지 현실 세계
NGDBench는 다섯 개의 서로 다른 도메인을 아우른다. 각각의 데이터가 가진 특성과 도전 과제가 다르기 때문에, 모델의 진짜 실력을 다각도로 시험할 수 있다.
데이터 구조: Labeled Property Graph (LPG)
NGDBench는 RDF 트리플이 아닌 LPG(Labeled Property Graph)를 선택했다. 그 이유는 명확하다:
- RDF:
(주어, 서술어, 목적어) — 단순한 3요소 구조. 속성을 표현하려면 추가 트리플 필요
- LPG: 노드와 엣지 자체에 속성(property)을 직접 저장 가능
예를 들어, "2026년 3월 15일에 김철수가 A계좌에서 B계좌로 300만 원을 이체했다"를 표현하면:
RDF: 7개의 트리플이 필요
(이체_1, 보내는사람, 김철수)
(이체_1, 보내는계좌, A계좌)
(이체_1, 받는계좌, B계좌)
(이체_1, 금액, 3000000)
(이체_1, 날짜, 2026-03-15)
...
LPG: 하나의 엣지로 표현
(A계좌)-[:TRANSFER {amount: 3000000, date: "2026-03-15", sender: "김철수"}]->(B계좌)
실무에서 Neo4j나 FalkorDB를 쓰는 프로덕션 환경과 직접 호환된다는 것도 큰 장점이다.
5장. 노이즈 — 현실 데이터의 불청객
구조화 데이터의 3단계 노이즈
NGDBench는 세 종류의 노이즈를 데이터에 주입하여 모델의 강건성을 시험한다:
위상 노이즈
엣지가 사라지거나 거짓 엣지가 추가된다. 네트워크의 연결 구조 자체가 훼손.
스키마 노이즈
관계 유형이 뒤바뀌거나 노드 카테고리가 잘못 분류된다. "친구" 관계가 "동료"로 바뀜.
속성 노이즈
OCR 오류, 숫자 편차, 오타 등 세밀한 에러. 이체 금액 300만 원이 330만 원으로.
실제 주입 비율은 약 4.5% 수준이다. 적어 보이지만, 수백만 개의 엣지 중 4.5%면 수십만 개의 오류가 생긴다. 이 정도면 실전에서 충분히 발생하는 수준이다.
비구조화 데이터의 자연 노이즈
NGD-MCP(AI 도구)와 NGD-Econ(기업 보고서) 데이터셋에는 인위적 노이즈를 주입하지 않는다. 왜? 비정형 텍스트에서 자동 추출한 그래프 자체가 이미 노이즈 덩어리이기 때문이다.
- 엔티티 중복 (같은 회사가 다른 이름으로 여러 번 등록)
- 관계 추출 오류 ("투자"와 "지원"을 혼동)
- 불필요한 특수문자나 약어
이것이 현실이다. 완벽하게 정제된 데이터는 연구실에서만 존재한다.
6장. 쿼리 생성 — Cypher의 모든 것을 시험하다
29개 핵심 연산자 추출
Cypher 쿼리 언어에는 100개 이상의 연산자가 있다. NGDBench 팀은 이를 29개의 핵심 기능 연산자로 추상화했다:
탐색/매칭 (7)
Expand, VarLengthExpand, ShortestPath, Optional, Anti...
조인/집합 (5)
HashJoin, CartesianProduct, Union...
필터/프로젝션 (3)
Filter, Project, Distinct
집계/제어 (7)
Aggregate, Sort, Limit, Skip...
데이터 수정 (5)
Create, Merge, Delete, Set, Foreach
3단계 쿼리 템플릿 구축
쿼리 생성은 점진적으로 복잡도를 높이는 3단계로 진행된다:
Phase 1: 기본 템플릿 — 단순 검색과 1-hop 탐색
hljs language-cypher
MATCH (n:Person)
WHERE n.name = "김철수"
RETURN n
Phase 2: 복잡도 확장 (비집계) — 가변 길이 경로, UNION, 중첩 처리
hljs language-cypher
MATCH p = (n:Person)-[:TRANSFER*1..3]->(m)
WHERE n.age > 30 AND m.status = 'Active'
RETURN p
Phase 3: 집계 확장 — SUM, COUNT, MIN, MAX, AVG 추가
hljs language-cypher
MATCH (n:Account)-[:LINKED_TO]->(ip:IP {suspicious: true})
MATCH (n)-[t:TRANSFER]->(m)
RETURN avg(t.amount) AS avg_transfer
섭동 인식 쿼리 샘플링
핵심 전략: 노이즈가 주입된 엔티티와 그 이웃을 우선 타겟으로 하여 쿼리를 생성한다. 이렇게 하면:
- 노이즈 영향을 받는 쿼리 (inconsistent set) — 모델의 노이즈 강건성 테스트
- 노이즈 무관한 쿼리 (consistent set) — 기본 성능 베이스라인
두 세트를 나눠 평가할 수 있어, "이 모델이 노이즈 때문에 못하는 건지, 원래 못하는 건지" 구별이 가능하다.
7장. 두 개의 과제 — 분석과 관리
Task I: 노이즈에 강건한 분석 쿼리 응답
핵심 수식은 이렇다:
minθL(fθ(q,G^),Exec(q,G∗))
- G∗: 깨끗한 원본 그래프 (정답)
- G^: 노이즈가 주입된 관측 그래프 (모델이 보는 것)
- fθ: 모델이 만드는 응답
- Exec(q,G∗): 원본에서의 정확한 실행 결과
모델은 노이즈가 섞인 그래프를 보면서, 원본에서의 정답을 맞춰야 한다. 마치 얼룩이 묻은 지도를 보고 정확한 길을 찾는 것과 같다.
세 가지 평가 설정:
- 비집계 쿼리: 후보 집합을 반환 → Jaccard 유사도, F1 Score
- 불리언 쿼리: 예/아니오 판정 → 정확도
- 집계 쿼리: 수치 계산 → 상대 오차 (MdRE, sMAPE)
Task II: 순차적 인컨텍스트 그래프 편집
더 도전적인 과제다. 모델은 연속적으로 그래프를 수정하고, 매번 정확히 수정되었는지 검증해야 한다.
Step 1
CREATE (n:Person {city: 'Seoul'}) → 노드 생성
검증 1
MATCH (n:Person {city: 'Seoul'}) RETURN count(n) → 1이어야 함
Step 2
CREATE (n)-[:LIVES_IN]->(c:City {name: 'Seoul'}) → 관계 생성
검증 2
MATCH (n:Person)-[:LIVES_IN]->(c:City) RETURN c.name → 'Seoul'이어야 함
Step 3
DELETE n → 노드 삭제... 이전 단계의 오류가 여기서 전파될 수 있다!
5개 단계를 한 배치로, 매 단계마다 수정(CREATE/DELETE/SET)과 검증을 반복한다. 이전 단계에서 오류가 나면 다음 단계에 전파되므로, 모델의 상태 관리 능력이 핵심이다.
8장. 실험 결과 — 충격적인 현실
참가 선수들
| 방법론 | 접근 방식 | 대표 모델 |
|---|
| Text-to-Cypher | 자연어 → Cypher 변환 → DB 실행 | GPT-5.1-Codex, Qwen3-Coder-480B, DeepSeek V3.2 |
| GraphRAG | 임베딩 검색 → LLM 추론 | Qwen3-0.6B 임베딩 + Top-15 트리플 |
| Oracle Cypher | 정답 Cypher를 노이즈 그래프에서 실행 | 이론적 상한선 |
비집계 쿼리 성능: Text-to-Cypher의 압도적 우위
GPT-5.1-Codex (NGD-Prime)
결과는 충격적이다. GraphRAG의 Jaccard 유사도가 0.004 — 사실상 0에 가깝다. 반면 Text-to-Cypher 방식은 0.3~0.5 수준으로, 여전히 부족하지만 GraphRAG보다는 100배 이상 나은 성능을 보인다.
왜 이런 차이가 날까?
Text-to-Cypher는 구조화된 쿼리 메커니즘으로 정보를 완전하게 검색할 수 있다. 반면 GraphRAG는 밀집 벡터 검색으로 상위 후보만 가져오고 나머지는 버린다. 관련 정보가 많을수록 GraphRAG의 재현율(recall)은 급격히 떨어진다.
집계 쿼리: 모두가 고전하다
집계 쿼리(평균, 합계, 개수 등)에서는 모든 모델이 어려워한다:
| 모델 | NGD-Fin MdRE ↓ | NGD-BI MdRE ↓ | NGD-Prime MdRE ↓ |
|---|
| Oracle Cypher | 0.039 | 0.355 | 0.203 |
| Qwen3-Coder | 0.102 | 0.992 | 3.403 |
| GPT-5.1-Codex | 0.111 | — | 0.206 |
| GraphRAG | 161.500 | — | 705.650 |
GraphRAG의 MdRE가 161.5와 705.65라는 것은 정답 대비 161배, 705배 벗어났다는 뜻이다. 집계 연산에서의 "치명적 실패(catastrophic failure)"다.
Oracle Cypher조차 NGD-BI에서 0.355의 오차를 보인다. 이는 노이즈 자체가 만드는 이론적 상한선 — 정답 쿼리를 사용해도 노이즈 데이터에서는 정확한 답을 얻을 수 없다는 뜻이다.
불리언 쿼리: GraphRAG의 반격
흥미로운 반전이 있다. 불리언(예/아니오) 질문으로 전환하면 GraphRAG가 경쟁력 있는 성능을 보인다.
이유: 불리언 쿼리는 후보를 좁혀주기 때문에 RAG의 검색 공간이 줄어든다. 반면 Text-to-Cypher는 불리언 검증을 Cypher로 표현하는 것이 상대적으로 불편하다.
핵심 교훈: 어떤 방법이 "최고"인지는 질문의 유형에 따라 달라진다.
동적 관리 쿼리: 오류 전파의 함정
| 모델 | NGD-Fin MLRE ↓ | NGD-BI MLRE ↓ | NGD-Prime MLRE ↓ |
|---|
| Qwen3-Coder | 2.676 | 0.562 | 3.403 |
| DeepSeek V3.2 | 3.456 | 0.455 | 3.665 |
| GraphRAG | 5.129 | 0.769 | 4.186 |
여기서 또 흥미로운 현상이 나타난다:
- Text-to-Cypher: 명시적 수정 명령을 생성하여 직접 그래프를 업데이트한다. 빠르고 정확하지만, 한 단계의 오류가 다음 단계로 전파된다.
- GraphRAG: 전체 편집 이력을 컨텍스트에 넣고 추론한다. 느리지만, 연쇄 오류를 완화한다.
이것은 마치 엑셀에서 수식을 직접 수정하는 것(Text-to-Cypher)과 수정 이력을 보고 판단하는 것(GraphRAG)의 차이다.
9장. 직접 체험해 보기 — 시뮬레이터
아래 시뮬레이터에서 Text-to-Cypher와 GraphRAG의 차이를 직접 체험해 보자. "시뮬레이션 시작" 버튼을 누르면, 같은 질문에 대해 두 방법이 어떻게 다르게 처리하는지 단계별로 보여준다.

10장. 비구조화 데이터의 도전
GraphRAG vs HippoRAG2
비구조화 데이터(텍스트에서 추출한 그래프)에서는 별도의 실험이 진행되었다:
두 방법 모두 성능이 낮지만, GraphRAG가 HippoRAG2를 일관되게 앞선다. 이유는:
NGDBench의 비구조화 쿼리들이 구조적이고 국소적이기 때문. "이 노드의 직접 후속자는?" 같은 질문은 그래프의 작은 이웃만 보면 되므로, 단순 임베딩 검색의 신호 대 잡음비가 높다. 반면 HippoRAG2는 엔티티 추출 → 다중 홉 검색 과정에서 불필요한 경로가 방해한다.
11장. 2026년, 뉴럴 그래프 DB의 현주소
산업계 동향
현재 그래프 데이터베이스와 AI의 결합은 여러 방향에서 진행 중이다:
Neo4j + LLM
LLM Knowledge Graph Builder로 비정형 텍스트에서 자동으로 지식 그래프 구축. PDF, 이미지, 유튜브 자막까지 처리.
GraphRAG (Microsoft)
2024년 Microsoft 연구소에서 발표. 지식 그래프 구조를 활용해 LLM의 다중 홉 추론과 관계 이해를 향상.
FalkorDB + AI
초고속 인메모리 그래프 엔진. Cypher 호환으로 NGDBench와 직접 호환되는 프로덕션 시스템.

어디에 쓰이나?
| 분야 | 활용 사례 | NGDB의 가치 |
|---|
| 금융 사기 탐지 | 의심 거래 패턴 탐지, 자금세탁 네트워크 추적 | 허위 거래(노이즈) 속에서도 정확한 패턴 인식 |
| 신약 발견 | 약물-질병-유전자 관계 탐색 | 누락된 상호작용을 추론하여 새 후보 발견 |
| AI 에이전트 관리 | MCP 도구 호출 패턴 분석, 워크플로우 최적화 | 에이전트의 도구 사용 관계를 그래프로 관리 |
| 공급망 관리 | 기업-투자-국가 관계 네트워크 분석 | 크로스 문서 분석으로 숨겨진 의존성 발견 |
| 추천 시스템 | 사용자-상품-리뷰 그래프 실시간 업데이트 | 동적 업데이트로 실시간 개인화 |
Text-to-SQL에서 배우는 교훈
Text-to-SQL 분야에서 2026년에 발견된 "성능 절벽(performance cliff)"은 경고등이다:
- 프론티어 LLM이 깨끗한 데이터에서 70~85% 정확도 달성
- 시맨틱 레이어와 비즈니스 컨텍스트를 더하면 86~95%까지 상승
- 하지만 실제 기업 환경에서는 학술 성과가 재현되지 않는 "성능 절벽" 발생
Text-to-Cypher도 동일한 도전에 직면할 것이다. NGDBench가 보여주듯, 노이즈가 있는 실전 데이터에서의 성능은 클린 벤치마크 성능과 크게 다르다.
12장. 미래 — 어디로 가야 하는가?
연구 로드맵
노이즈 인식 쿼리 전략
→
순차 편집 오류 제어
→
표준화된 평가 프로토콜
심볼릭 + 뉴럴 하이브리드
→
Text-to-Cypher + GraphRAG 결합
→
프로덕션 NGDB 시스템
논문이 제시하는 미래 방향:
- 노이즈 인식 쿼리: 쿼리 실행 시 데이터의 신뢰도를 함께 고려하는 메커니즘
- 오류 제어 전략: 순차 편집에서의 오류 전파를 최소화하는 방법
- 하이브리드 접근: Text-to-Cypher의 정확성과 GraphRAG의 노이즈 강건성을 결합
- 심볼릭 제약 + 뉴럴 저장소: 논리적 일관성을 보장하면서 뉴럴 추론의 유연성 활용
우리에게 남은 질문
이 논문이 우리에게 던지는 근본적인 질문은 이것이다:
"AI가 데이터를 '읽는' 것을 넘어서, '관리'할 수 있는가?"
현재 답은 "아직 멀었다"에 가깝다. 최고 성능의 LLM도 Jaccard 0.5를 넘기 어렵고, 집계 연산에서는 수십~수백 배의 오차를 보인다. GraphRAG는 구조화된 쿼리에서 거의 무용지물이다.
하지만 이것이 바로 NGDBench가 존재하는 이유다. 문제를 정확하게 측정해야 해결할 수 있다. 벤치마크는 나침반이다. 어디가 부족한지 정확히 보여줌으로써, 연구 커뮤니티가 올바른 방향으로 나아가도록 한다.
정리: 핵심 포인트
1
현실 데이터는 불완전하다
지식 그래프의 데이터 누락률은 50~99%에 달한다. 기존 그래프 DB는 이를 처리할 수 없고, NGDB는 AI로 빈 곳을 추론한다.
2
NGDBench = 최초의 통합 벤치마크
5개 도메인, 전체 Cypher 지원, 노이즈 주입, 동적 업데이트 — 기존 벤치마크가 하나도 충족하지 못한 요구사항을 모두 충족.
3
최신 LLM도 아직 부족하다
Text-to-Cypher가 GraphRAG보다 100배 이상 나은 성능을 보이지만, 절대적으로는 여전히 낮다. 노이즈, 집계, 동적 관리 모두 미해결 과제.
참고 자료
- Li, Y. et al. (2026). Towards Neural Graph Data Management. arXiv:2603.05529. 논문 링크
- Ren, H. et al. (2023). Neural Graph Databases. NeurIPS.
- Besta, M. et al. (2022). Neural Graph Databases. KDD Workshop.
- Microsoft Research (2024). GraphRAG: Retrieval-Augmented Generation with Graphs.
- Neo4j (2025). LLM Knowledge Graph Builder.
- ISO/IEC 39075:2024 — Graph Query Language (GQL).
- GitHub: HKUST-KnowComp/NGDBench




