블로그로 돌아가기
LLMRAG파인튜닝RLHF프롬프트 엔지니어링증류AI 전략
튜닝할 것인가, 말 것인가: LLM에 내 데이터를 연결하는 완전 가이드
프롬프트 엔지니어링, RAG, SFT, RLHF, 증류 — LLM에 내 데이터를 연결하는 5가지 방법의 역사부터 2026년 현재의 활용법까지. 셰익스피어의 질문을 빌려, AI 시대의 가장 실용적인 선택지를 정리한다.
코어닷투데이2026-04-0760분
프롬프트 엔지니어링, RAG, SFT, RLHF, 증류 — LLM에 내 데이터를 연결하는 5가지 방법의 역사부터 2026년 현재의 활용법까지. 셰익스피어의 질문을 빌려, AI 시대의 가장 실용적인 선택지를 정리한다.
"To be, or not to be, that is the question." — 윌리엄 셰익스피어, 《햄릿》 3막 1장
셰익스피어의 햄릿이 존재의 본질을 고민했다면, 2026년의 AI 엔지니어들은 다른 종류의 실존적 질문과 씨름한다.
"이 모델을 튜닝해야 하나, 말아야 하나?"
ChatGPT가 세상에 등장한 지 3년. 이제 대부분의 기업이 "LLM을 써야 한다"는 데는 동의한다. 진짜 어려운 질문은 그다음이다 — 어떻게 우리 데이터를 LLM에 연결할 것인가?

Google Cloud의 AI/ML 스페셜리스트인 Kamilla Kurta와 Filipe Gracio 박사는 이 질문에 대한 명쾌한 의사결정 프레임워크를 제시했다. 이 글에서는 그들의 가이드를 바탕으로, 역사적 맥락부터 2026년의 최신 트렌드까지 — 각 방법이 왜 탄생했고, 언제 써야 하며, 어떻게 조합하는지를 풍부한 사례와 함께 깊이 파헤쳐 본다.
LLM에 데이터를 연결하는 오늘날의 기법들은 하루아침에 나온 것이 아니다. 수십 년간의 연구가 하나의 흐름으로 수렴한 결과다.
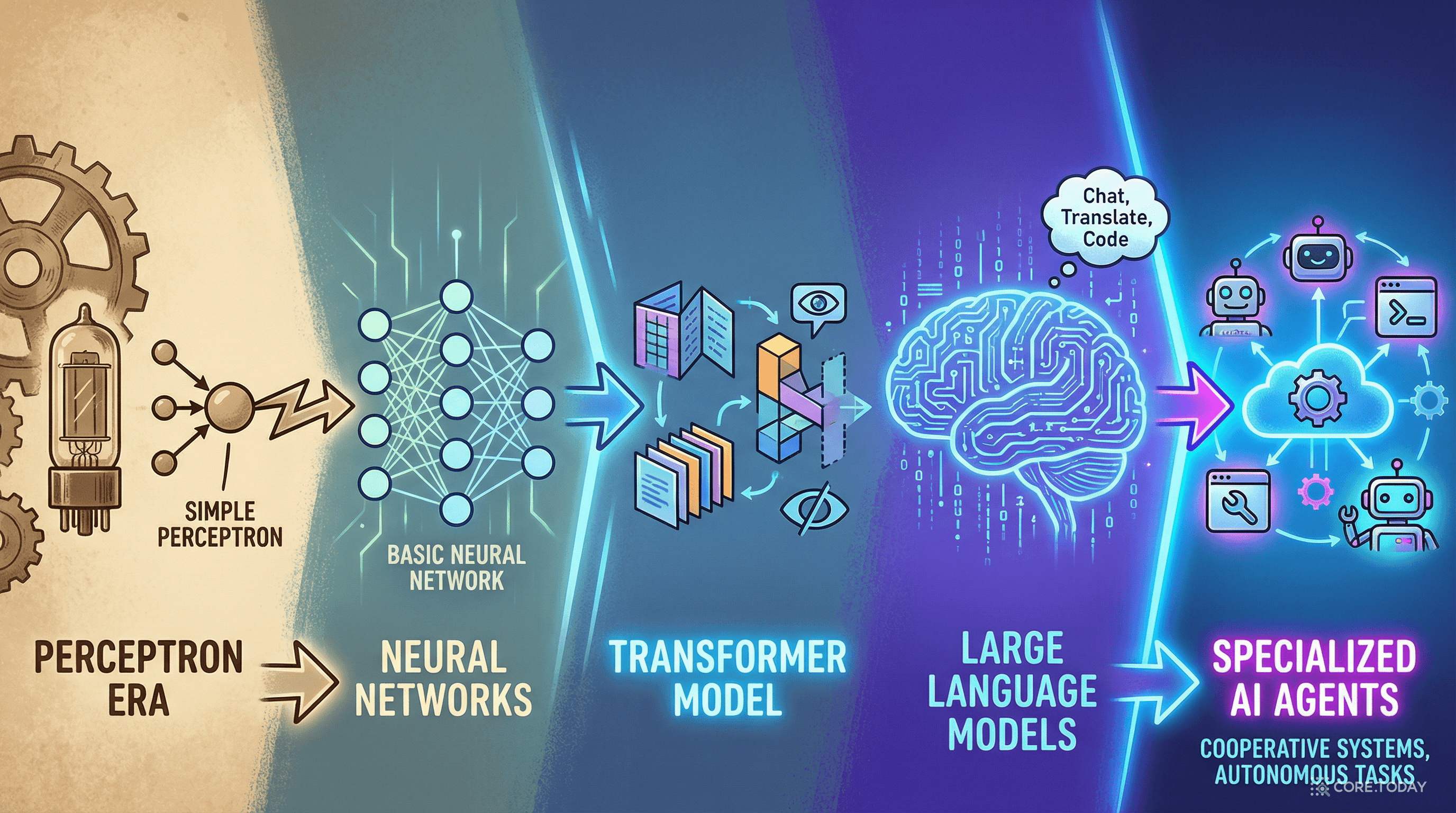
이 타임라인에서 주목할 점이 있다. 2020년을 기점으로 패러다임이 완전히 바뀌었다는 것이다. 이전에는 "데이터로 모델을 학습시킨다"가 유일한 방법이었다. 하지만 GPT-3 이후, 학습 없이도 모델을 활용하는 방법이 등장했다. 이것이 바로 오늘의 이야기가 시작되는 지점이다.
LLM에 데이터를 연결하는 방법은 크게 튜닝하지 않는 방법과 튜닝하는 방법으로 나뉜다.
하나씩 깊이 들어가 보자.

프롬프트 엔지니어링은 가장 단순하고 강력한 방법이다. 모델을 바꾸지 않고, 지시문(프롬프트)에 데이터를 직접 넣어주는 것이다.
비유하자면 이렇다. 당신이 변호사에게 법률 상담을 받으러 갔다고 하자. 변호사는 이미 법에 대한 깊은 지식이 있다(= LLM의 사전학습된 지식). 하지만 당신의 구체적인 상황은 모른다. 그래서 당신은 관련 서류를 건네주며 설명한다(= 프롬프트에 데이터를 포함). 변호사는 자신의 법률 지식과 당신이 건넨 서류를 결합하여 답변을 준다.
프롬프트 엔지니어링의 위력이 처음 증명된 것은 GPT-3 논문(Brown et al., 2020)이다. OpenAI 연구진은 1,750억 개의 파라미터를 가진 모델이 별도의 학습 없이도 프롬프트에 몇 가지 예시를 넣어주기만 하면(few-shot learning) 다양한 태스크를 수행할 수 있음을 보였다.
이것은 혁명적이었다. 그 이전까지 AI를 새로운 태스크에 적용하려면 반드시 학습 데이터를 모아 모델을 재학습시켜야 했다. GPT-3는 "학습 없이도 된다"는 가능성을 처음 보여준 것이다.
컨텍스트 윈도우가 폭발적으로 커졌다. Gemini 2.5는 100만 토큰, Claude 4는 100만+ 토큰을 처리한다. 이것은 프롬프트 엔지니어링의 범위를 극적으로 넓혔다. 예전에는 프롬프트에 문서 2~3페이지밖에 못 넣었지만, 지금은 책 한 권 전체를 넣을 수 있다.
하지만 컨텍스트 윈도우가 커졌다고 해서 프롬프트 엔지니어링이 만능이 된 것은 아니다. 컨텍스트에 너무 많은 정보를 넣으면 "건초 더미에서 바늘 찾기(Needle in a Haystack)" 문제가 발생한다 — 모델이 중요한 정보를 놓치거나, 비용이 폭증할 수 있다.

RAG(Retrieval-Augmented Generation, 검색 증강 생성)는 질문이 들어올 때마다 관련 데이터를 실시간으로 검색해서 프롬프트에 넣어주는 방법이다.
비유하자면 이렇다. 시험을 볼 때 오픈 북(open-book) 시험과 같다. 학생(= LLM)이 모든 것을 암기할 필요 없이, 시험 중에 교과서(= 데이터베이스)를 펼쳐서 관련 내용을 찾아 답안을 작성한다. 핵심은 얼마나 빠르고 정확하게 관련 페이지를 찾느냐이다.
RAG라는 개념을 처음 공식화한 것은 Meta AI(당시 Facebook AI Research)의 Patrick Lewis et al. 논문 "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (2020)이다.
이 논문의 핵심 통찰은 명쾌했다:
"LLM이 세상의 모든 지식을 파라미터에 저장할 필요는 없다. 필요할 때 외부에서 가져오면 된다."
이 아이디어가 왜 혁명적이었을까? 당시까지 LLM의 지식은 모두 파라미터에 암기된 것(parametric knowledge)이었다. 학습 데이터에 없는 정보는 알 수 없었고, 학습 후에 세상이 바뀌어도 모델의 지식은 갱신되지 않았다. RAG는 이 근본적 한계를 외부 검색으로 해결했다.
| RAG를 써야 할 때 | RAG가 불필요할 때 |
|---|---|
| 답변에 출처/인용이 필요할 때 | 일반적인 지식만 필요할 때 |
| 데이터가 자주 업데이트될 때 | 데이터가 정적이고 양이 적을 때 |
| 사용자별 접근 권한이 다를 때 | 모든 사용자에게 같은 정보일 때 |
| 할루시네이션이 치명적인 도메인 | 창작/브레인스토밍 용도 |

지도 파인튜닝(Supervised Fine-Tuning, SFT)은 모델에게 "이런 입력이 들어오면 이런 출력을 내놔"라는 입출력 쌍을 직접 가르치는 것이다.
비유하자면, 인턴 교육이다. 인턴(= 사전학습된 LLM)은 대학에서 기본 지식을 배웠지만, 회사의 구체적인 업무 방식은 모른다. 선임(= 학습 데이터)이 "이런 이메일이 오면 이렇게 분류해", "이런 보고서는 이 형식으로 작성해"라고 구체적인 사례를 보여주며 가르친다.
파인튜닝은 사실 딥러닝의 가장 오래된 테크닉 중 하나다. 2018년 BERT 논문(Devlin et al.)이 확립한 "사전학습 → 파인튜닝(pre-train → fine-tune)" 패러다임은 NLP의 표준이 되었다.
하지만 GPT-3 이후 모델 크기가 수십억~수천억 파라미터로 커지면서, 전체 파인튜닝(Full Fine-tuning)은 엄청난 비용이 드는 작업이 되었다. 이에 따라 PEFT(Parameter-Efficient Fine-Tuning) 방법론이 등장했다.
가장 대표적인 것이 LoRA(Low-Rank Adaptation)다(Hu et al., 2021). 핵심 아이디어는 간단하다:
"모델의 전체 가중치를 바꾸지 말고, 작은 행렬 두 개를 추가해서 그것만 학습시키자."
LoRA를 쓰면 학습해야 할 파라미터가 전체의 0.1~1% 수준으로 줄어든다. GPU 비용이 10~100배 절감되면서도 성능은 거의 비슷하다.
학습 파라미터 비율 비교 — LoRA는 전체의 1% 미만만 학습

RLHF(Reinforcement Learning from Human Feedback)는 "정답"을 명확히 정의하기 어려운 경우에 사용한다. 인간의 선호도를 학습시키는 것이다.
비유하자면, 와인 소믈리에 교육이다. "좋은 와인"의 정확한 공식은 없다. 하지만 경험 많은 소믈리에가 두 와인을 비교하며 "이게 더 나아"라고 말해주면, 그 선호도 패턴을 학습할 수 있다. RLHF도 마찬가지다 — 두 개의 답변을 보여주고 "이게 더 좋아"라고 인간이 피드백을 주면, 그 선호도를 모델이 학습한다.
RLHF의 근간이 되는 아이디어는 OpenAI의 InstructGPT 논문(Ouyang et al., 2022)에서 대중화되었다.
알고리즘의 핵심은 세 단계다:
이 기법이 바로 ChatGPT를 ChatGPT답게 만든 핵심 기술이다. 같은 GPT-3.5 모델도 RLHF 전후로 사용자 경험이 완전히 달랐다.
SFT는 "정답이 하나인 문제"에 강하다. 하지만 현실 세계의 많은 문제는 "정답"이 여럿이거나, 정답의 기준이 주관적이다.
| 측면 | SFT가 잘하는 것 | RLHF가 필요한 것 |
|---|---|---|
| 출력 형태 | 정해진 형식 (JSON, 분류 라벨) | 자연스러운 대화, 설명 |
| 정답 기준 | 객관적 (맞다/틀리다) | 주관적 (더 자연스럽다/덜 자연스럽다) |
| 학습 데이터 | 입출력 쌍 (input → output) | 선호도 쌍 (A vs B, A가 더 좋음) |
| 대표 사례 | 분류, 요약, 구조화 | 브랜드 톤, 안전성, 스타일 |
2026년의 트렌드: RLHF의 비용과 복잡성을 줄이기 위해 DPO(Direct Preference Optimization)(Rafailov et al., 2023)가 빠르게 대안으로 부상했다. DPO는 보상 모델 없이 선호도 데이터만으로 직접 최적화하여, RLHF와 비슷한 성능을 훨씬 간단하게 달성한다.

증류(Distillation)는 두 가지 목표를 동시에 달성하는 영리한 기법이다:
비유하자면, 장인과 도제의 관계다. 대장장이(= 대형 모델)가 수십 년간 쌓은 기술을 도제(= 소형 모델)에게 전수한다. 도제는 대장장이의 모든 기술을 배울 필요는 없고, 칼 만드는 기술(= 특정 태스크)만 집중적으로 배운다. 결과적으로 도제는 칼을 만드는 데에 있어서는 대장장이에 거의 근접한 실력을 갖추게 된다.
지식 증류의 개념은 Geoffrey Hinton이 2015년에 발표한 "Distilling the Knowledge in a Neural Network" 에서 체계화되었다.
핵심 아이디어는 "소프트 타겟(soft target)"이다:
Hard target은 "이건 고양이다"라는 단순한 정답만 알려준다. 하지만 Soft target은 "고양이일 확률 70%, 호랑이일 확률 20%, 개일 확률 10%"라는 풍부한 정보를 전달한다. "고양이와 호랑이는 비슷하다"는 관계까지 학습할 수 있는 것이다. 이것이 큰 모델에서 작은 모델로 "지식을 증류하는" 핵심 메커니즘이다.
이제 다섯 가지 무기를 모두 알게 되었다. 그렇다면 내 상황에는 어떤 방법을 써야 할까? Google Cloud의 Kurta와 Gracio 박사가 제시한 의사결정 프레임워크를 확장하여 정리했다.
| 방법 | 구현 난이도 | 비용 | 속도 | 학습 데이터 필요량 |
|---|---|---|---|---|
| 프롬프트 엔지니어링 | ⭐ 매우 쉬움 | $ 낮음 | 즉시 | 없음 |
| RAG | ⭐⭐ 보통 | $$ 중간 | 수 일 | 문서 DB만 필요 |
| SFT (LoRA) | ⭐⭐⭐ 중상 | $$ 중간 | 수 일~주 | 수백~수천 쌍 |
| RLHF | ⭐⭐⭐⭐ 어려움 | $$$ 높음 | 수 주 | 수천 선호도 쌍 |
| 증류 | ⭐⭐⭐ 중상 | $$$ 높음 (초기) | 수 주 | 수만 건 (교사 출력) |
| Full Fine-tuning | ⭐⭐⭐⭐⭐ 매우 어려움 | $$$$ 매우 높음 | 수 주~월 | 수만~수십만 |
Google Cloud 블로그의 Kurta와 Gracio 박사가 강조하는 핵심 메시지가 있다:
"왜 방법들을 조합하면 안 되나요? 조합이 가능하고, 종종 최선의 선택입니다!"
현실의 프로덕션 시스템에서는 단일 방법을 쓰는 경우가 오히려 드물다. 가장 강력한 시스템들은 여러 기법을 레이어처럼 쌓는다.
2024년 구글 블로그가 작성된 시점과 지금(2026년)은 불과 2년 차이지만, 변화는 극적이다.
2024년의 "큰 컨텍스트"는 128K 토큰이었다. 2026년에는 100만 토큰이 표준이 되었다. 이것은 프롬프트 엔지니어링의 경계를 크게 넓혔다. 예전에는 RAG가 필수였던 시나리오가 이제는 프롬프트 엔지니어링만으로 해결되기도 한다.
하지만 RAG가 불필요해진 것은 아니다. 100만 토큰이면 책 2~3권 분량이지만, 기업의 지식 베이스는 그보다 훨씬 크다. 또한 RAG의 핵심 가치인 출처 추적과 접근 권한 제어는 컨텍스트 윈도우와 무관하게 필요하다.
2026년의 가장 큰 변화는 에이전트(Agent)의 부상이다. 에이전트는 LLM이 스스로 판단하여 도구를 사용하고, 다단계 작업을 자율적으로 수행하는 시스템이다.
에이전트 시대에서 이 글의 기법들은 새로운 역할을 맡게 된다:
| 기법 | 기존 역할 (2024) | 에이전트 시대 역할 (2026) |
|---|---|---|
| 프롬프트 엔지니어링 | 사용자 질문에 맥락 추가 | 에이전트의 시스템 프롬프트 설계, 도구 사용 지침 정의 |
| RAG | 질문-답변 시 관련 문서 검색 | 에이전트가 자율적으로 지식 검색, 멀티-소스 RAG |
| SFT | 특정 태스크에 모델 특화 | 에이전트의 도구 호출 능력 강화, 출력 형식 특화 |
| RLHF | 톤/스타일 정렬 | 에이전트의 의사결정 품질과 안전성 정렬 |
| 증류 | 비용 절감 | 에이전트 내 경량 서브 모델 운영, 엣지 디바이스 배포 |
Google Cloud 블로그의 마지막 조언은 2026년에도 여전히 유효하다:
실제로 2026년의 베스트 프랙티스는 이렇다:
마지막으로, 이 글에서 다룬 모든 개념을 한 페이지에 정리한다.
| 연도 | 논문 | 핵심 기여 |
|---|---|---|
| 2015 | Hinton et al. "Distilling the Knowledge in a Neural Network" | 지식 증류 개념 확립 |
| 2017 | Vaswani et al. "Attention Is All You Need" | Transformer 아키텍처 |
| 2018 | Devlin et al. "BERT: Pre-training of Deep Bidirectional Transformers" | Pre-train → Fine-tune 패러다임 |
| 2020 | Brown et al. "Language Models are Few-Shot Learners" (GPT-3) | In-Context Learning, 프롬프트 엔지니어링 |
| 2020 | Lewis et al. "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" | RAG 개념 정립 |
| 2021 | Hu et al. "LoRA: Low-Rank Adaptation of Large Language Models" | 효율적 파인튜닝 |
| 2022 | Ouyang et al. "Training language models to follow instructions with human feedback" | RLHF, InstructGPT |
| 2023 | Rafailov et al. "Direct Preference Optimization" | RLHF의 간소화 대안 (DPO) |
"To tune, or not to tune?" — 이 질문에 대한 답은 사실 "둘 다"이다.
2026년의 AI 엔지니어에게 필요한 것은 하나의 정답이 아니라, 상황에 맞는 판단력이다. 프롬프트 엔지니어링으로 시작하고, 필요하면 RAG를 붙이고, 더 필요하면 파인튜닝을 하고, 비용이 부담되면 증류를 한다. 중요한 것은 단순하게 시작하되, 필요에 따라 조합하는 것이다.
햄릿은 고민에 빠져 비극으로 끝났지만, AI 엔지니어에게는 모든 선택지를 조합할 수 있는 행복한 결말이 기다리고 있다. 시작은 단순하게. 그리고 점진적으로 강화하라.
원문 출처: Kamilla Kurta & Filipe Gracio, "To tune or not to tune? A guide to leveraging your data with LLMs", Google Cloud Blog, 2024.05.17.