블로그로 돌아가기
LLM프롬프트 엔지니어링RAG파인튜닝AI 최적화평가
LLM 정확도 최적화 완전 가이드: 프롬프트부터 파인튜닝까지
LLM이 틀리는 이유는 두 가지뿐이다 — 맥락이 부족하거나, 행동이 불안정하거나. OpenAI의 최적화 프레임워크를 중심으로 프롬프트 엔지니어링, RAG, 파인튜닝의 역사와 원리를 깊이 파헤치고, 실전 사례와 함께 2026년 최적화 전략을 완전 정리한다.
코어닷투데이2026-02-1448분
LLM이 틀리는 이유는 두 가지뿐이다 — 맥락이 부족하거나, 행동이 불안정하거나. OpenAI의 최적화 프레임워크를 중심으로 프롬프트 엔지니어링, RAG, 파인튜닝의 역사와 원리를 깊이 파헤치고, 실전 사례와 함께 2026년 최적화 전략을 완전 정리한다.
2026년, 전 세계 기업의 72%가 LLM을 업무에 활용하고 있다. 고객 서비스 챗봇, 코드 생성, 문서 요약, 법률 검토 — LLM은 이미 "신기한 장난감"이 아니라 비즈니스 인프라다.
그런데 문제가 있다. LLM은 틀린다.
환불 금액 $100을 $1,000으로 안내하는 챗봇. 존재하지 않는 판례를 인용하는 법률 AI. 컴파일조차 안 되는 코드를 자신 있게 내놓는 코딩 어시스턴트. 이런 실패는 단순한 불편이 아니라 실제 비용을 발생시킨다.
OpenAI가 수많은 스타트업과 대기업과 함께 일하면서 발견한 것: LLM 최적화가 어려운 이유는 세 가지로 귀결된다.
- 어디서부터 시작해야 할지 모르겠다
- 어떤 방법을 언제 써야 할지 모르겠다
- 얼마나 정확해야 충분한지 모르겠다
이 글에서는 OpenAI의 "Optimizing LLM Accuracy" 가이드를 뼈대로, 프롬프트 엔지니어링부터 RAG, 파인튜닝까지 — 각 기법이 왜 태어났고, 어떻게 작동하며, 언제 써야 하는지를 역사적 맥락과 풍부한 사례를 곁들여 완전 해부한다. 그리고 2026년 현재, 이 모든 것이 어디로 향하고 있는지까지.
많은 가이드가 LLM 최적화를 "프롬프트 → RAG → 파인튜닝" 이라는 단순한 선형 흐름으로 설명한다. 하지만 OpenAI는 이렇게 말한다:
"이것은 순서가 아니라 매트릭스다. 각 기법은 서로 다른 문제를 해결하는 독립적인 레버다."
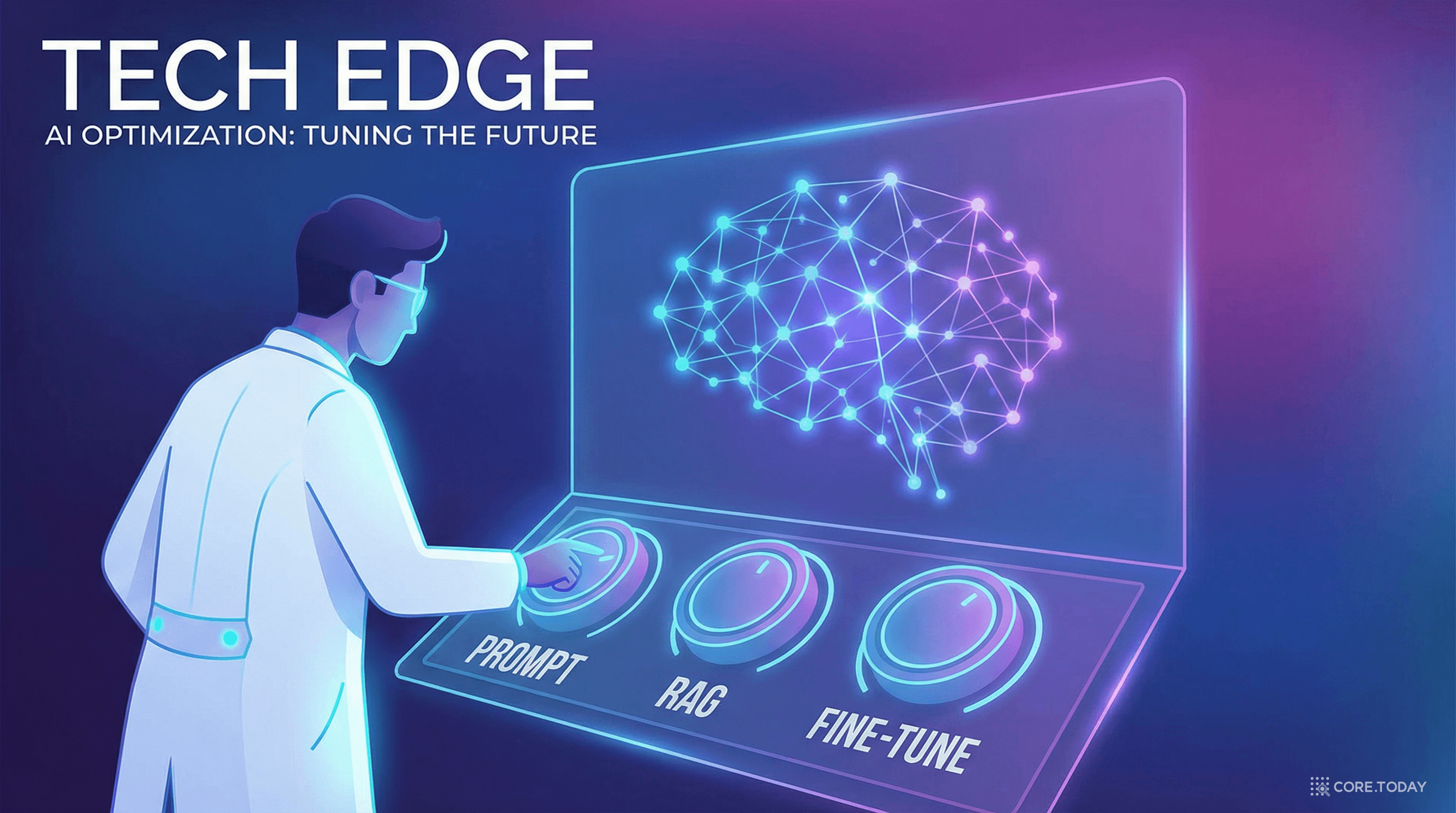
이 두 축을 조합하면 2×2 매트릭스가 만들어진다:
| LLM 최적화 낮음 | LLM 최적화 높음 | |
|---|---|---|
| 맥락 최적화 높음 | RAG 단독 | RAG + 파인튜닝 |
| 맥락 최적화 낮음 | 프롬프트 엔지니어링 | 파인튜닝 단독 |
맥락 최적화가 필요한 경우:
LLM 최적화가 필요한 경우:
핵심은 실패 원인을 진단한 뒤 올바른 레버를 당기는 것이다. 이 매트릭스가 전체 글을 관통하는 프레임워크가 될 것이다.
OpenAI는 LLM의 지식을 시험에 비유한다. 이 비유가 놀라울 정도로 정확하다.
6개월간 수업을 듣고 수백 개의 예제를 풀어본 학생을 떠올려 보자. 시험장에서 이 학생은 교재 없이도 답을 쓸 수 있다. 개념이 내면화되었기 때문이다.
LLM에서 이것이 바로 파인튜닝이다. 수많은 예시로 모델을 추가 학습시켜, 특정 작업의 패턴을 가중치에 새기는 것.
반면 오픈북 시험을 보는 학생이 있다. 이 학생은 매 문제마다 교재에서 관련 페이지를 찾아 읽고 답을 작성한다. 공부하지 않았지만, 올바른 참고 자료만 있으면 정확한 답을 쓸 수 있다.
LLM에서 이것이 RAG (검색 증강 생성)이다. 질문이 들어올 때마다 관련 문서를 검색하여 프롬프트에 동적으로 주입하는 것.
이 두 접근법은 배타적이지 않다 — 둘 다 쓸 수 있고, 많은 경우 함께 써야 한다. 열심히 공부한 학생이 오픈북까지 가져가면 더 정확할 수 있는 것처럼. (단, 항상 그런 것은 아니다 — 이 점은 뒤에서 실험으로 증명한다.)
프롬프트 엔지니어링은 대부분의 경우 유일하게 필요한 방법이기도 하다. 요약, 번역, 코드 생성 같은 작업에서는 잘 설계된 프롬프트 하나만으로 프로덕션 수준의 정확도에 도달할 수 있다.
더 중요한 이유가 있다. 프롬프트 엔지니어링은 "정확도"가 당신의 유스케이스에서 무엇을 의미하는지 정의하도록 강제한다. 입력을 주고 출력을 판단하는 과정에서, 당신은 자연스럽게 성공과 실패의 기준을 세우게 된다.
이야기는 2020년 5월, OpenAI의 GPT-3 논문에서 시작된다. Brown et al.의 "Language Models are Few-Shot Learners"는 1,750억 파라미터 모델이 가중치를 전혀 업데이트하지 않고, 프롬프트에 몇 개의 예시만 넣어주면 새로운 작업을 수행할 수 있음을 보여주었다.
GPT-3의 Few-Shot은 강력했지만, 수학 문제나 논리 추론 같은 다단계 사고가 필요한 작업에서는 처참하게 실패했다.
2022년 1월, Google Research의 Wei et al.이 혁신적인 발견을 한다. "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models" — 프롬프트의 예시에 중간 추론 과정을 포함시키면, 모델이 복잡한 문제를 단계적으로 풀 수 있다는 것.
이 단순한 차이가 GSM8K (초등 수학) 벤치마크에서 정확도를 17.9% 향상시켰다. 핵심 인사이트: LLM에게 "답을 말해줘"가 아니라 "어떻게 생각하는지 보여줘"라고 요청하면 된다.
Wang et al.은 같은 해에 CoT의 약점을 보완한다. 하나의 추론 경로는 취약하다 — 한 단계가 틀리면 전체 답이 틀려진다. 해결책? 같은 문제를 여러 번 풀게 하고, 가장 많이 나온 답을 선택하는 것.
이것이 Self-Consistency다. 5~10개의 다른 추론 경로를 샘플링하고 다수결로 최종 답을 고른다. 단순하지만, BLEU나 정확도에서 CoT 단독 대비 10~18% 추가 향상을 보여주었다.
OpenAI는 프롬프트 최적화를 위해 6가지 전략을 제시하며, 각각이 맥락/LLM 최적화 중 어느 축에 영향을 미치는지 구분한다:
| 전략 | 맥락 최적화 | LLM 최적화 |
|---|---|---|
| 명확한 지시문 작성 | — | ✓ |
| 복잡한 작업을 하위 작업으로 분리 | ✓ | ✓ |
| 모델에게 "생각할 시간" 주기 (CoT) | — | ✓ |
| 변경 사항을 체계적으로 테스트 | ✓ | ✓ |
| 참고 텍스트 제공 | ✓ | — |
| 외부 도구 활용 | ✓ | — |
OpenAI가 가이드에서 사용한 실제 실험을 살펴보자. 아이슬란드어 오류 교정 — 틀린 아이슬란드어 문장을 받아 최소한의 수정으로 올바른 문장을 반환하는 작업이다.
1단계: 제로샷 프롬프트 (BLEU 62점)
아무 예시 없이 지시문만 제공:
System: The following sentences contain Icelandic sentences which may include errors.
Please correct these errors using as few word changes as possible.
User: "Sorvistolur eru naer halsi og skartgripir kvenna a brjotsti."
결과: BLEU 62점. 나쁘지 않지만 프로덕션에는 부족하다.
2단계: 퓨샷 프롬프트 (BLEU 70점, +13%)
3개의 예시를 프롬프트에 추가하자 BLEU가 70점으로 올랐다. 핵심 관찰: 이 작업은 행동 최적화 문제다. 모델은 이미 아이슬란드어를 알고 있지만, "최소 수정"이라는 행동 패턴을 프롬프트만으로는 완전히 학습하지 못하고 있다.
"여기서 더 나아가려면 어떻게 해야 할까?" — 이 질문에 대한 답이 이 글의 나머지 전체를 구성한다.
2024년부터 128K~1M 토큰의 롱 컨텍스트 모델이 등장하면서, 많은 개발자들이 "모든 문서를 프롬프트에 다 넣으면 되지 않나?"라고 생각했다.
하지만 "Lost in the Middle" 현상이 문제다. LLM은 프롬프트의 처음과 끝에 있는 정보에는 강하지만, 중간에 위치한 정보를 놓치는 경향이 있다. Greg Kamradt의 Needle in A Haystack (NIAH) 실험이 이를 명확히 보여주었다 — 긴 문서 속에 숨긴 정보의 위치에 따라 검색 정확도가 크게 달라졌다.
교훈: 롱 컨텍스트는 만능이 아니다. 반드시 평가(evaluation)와 함께 사용해야 한다.
여기서 잠깐. 프롬프트 다음에 바로 RAG나 파인튜닝으로 넘어가고 싶겠지만, OpenAI가 강조하는 가장 중요한 단계가 있다.
좋은 프롬프트 + 평가 세트(20개 이상의 질문과 정답) + 실패 원인 분석 = 다음 단계로 나아갈 수 있는 최고의 기반.
평가 없이 최적화하는 것은 나침반 없이 항해하는 것과 같다. 어디로 가고 있는지 모르면, 도착했는지도 알 수 없다.
2026년의 합의: 평가는 AI 시스템의 유닛 테스트다. 코드를 작성하기 전에 테스트를 설계하듯, LLM을 최적화하기 전에 평가를 설계해야 한다.
Retrieval-Augmented Generation — 검색 증강 생성. 사용자의 질문과 관련된 문서를 검색(Retrieve)하여 프롬프트를 증강(Augment)한 뒤 답변을 생성(Generate)하는 기법이다.
2020년 5월, Patrick Lewis et al.이 발표한 "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"는 GPT-3 논문과 같은 달에 나왔지만, 완전히 다른 문제를 해결했다.
RAG를 도입하면 새로운 평가 차원이 생긴다: 검색이 올바른 맥락을 가져왔는가?
| 정확한 답변 | 부정확한 답변 | |
|---|---|---|
| 올바른 맥락 제공 | 성공! 검색도 정확, 답변도 정확 | LLM 문제 → 프롬프트 개선 또는 파인튜닝 |
| 잘못된 맥락 제공 | 운 좋은 정답 (위험!) | 검색 문제 → 검색 파이프라인 최적화 |
핵심: RAG 시스템의 실패를 볼 때 검색이 실패했는지 LLM이 실패했는지를 먼저 구분해야 한다. 검색이 잘못된 문서를 가져왔다면 LLM을 아무리 고쳐봐야 소용없다.
파인튜닝은 사전 학습된 LLM을 도메인 특화 데이터셋으로 추가 학습시켜, 특정 작업에서의 성능을 높이는 기법이다. 주로 두 가지 목적으로 사용된다:
ULMFiT (Howard & Ruder)가 NLP에서 최초로 "사전학습 + 파인튜닝" 패러다임을 증명했고, 같은 해 BERT (Devlin et al.)가 이 패러다임을 대중화했다. 핵심 발견: 범용 언어 모델을 만들고, 각 작업에 맞게 마지막 층만 조정하면 된다.
두 가지 혁신이 동시에 일어났다:
FLAN (Wei et al., 2021) — 60개 이상의 NLP 작업을 자연어 지시문으로 설명하여 학습. 137B 모델이 175B GPT-3을 25개 평가 중 20개에서 능가. 핵심: "지시를 따르는 능력"이라는 메타 스킬을 학습시킬 수 있다.
LoRA (Hu et al., 2021) — 전체 가중치를 업데이트하는 대신, 각 트랜스포머 층에 저랭크 분해 행렬을 삽입하여 학습. 학습 파라미터가 10,000배 감소하고 GPU 메모리는 3배 절약. 품질 손실은 없었다.
OpenAI의 InstructGPT 논문 (Ouyang et al., 2022)이 AI 역사를 바꿨다. 3단계 파이프라인:
충격적인 결과: 13억 파라미터의 InstructGPT가 1,750억 파라미터의 GPT-3보다 사람 평가에서 선호되었다. 100배 작은 모델이 정렬(alignment)만으로 더 큰 모델을 이긴 것. "크기가 전부가 아니다"라는 메시지가 이때부터 시작되었다.
RLHF의 3단계 파이프라인은 복잡하고 불안정했다. Rafailov et al.의 DPO (Direct Preference Optimization)는 보상 모델과 RL 루프를 완전히 제거하고, 선호 데이터에 대한 단순한 분류 손실 함수만으로 동일한 성능을 달성했다. RLHF가 3시간짜리 요리라면, DPO는 전자레인지 3분 요리.
OpenAI가 실전에서 관찰한 핵심 원칙 3가지:
1. 프롬프트 엔지니어링부터 시작하라
파인튜닝 전에 반드시 프롬프트로 기본 성능을 측정하라. 이것이 비교 기준(baseline)이 된다.
2. 적게 시작하되, 품질에 집중하라
학습 데이터의 품질이 양보다 중요하다. 50개의 고품질 예시로 시작하고, 평가한 뒤, 정확도 문제가 행동/일관성 때문이라면 그때 데이터 규모를 키워라.
3. 대표성을 보장하라
가장 흔한 함정: 학습 데이터와 프로덕션 데이터의 미묘한 형식 차이. RAG 파이프라인이 있다면, 파인튜닝 데이터에도 RAG로 검색된 맥락을 포함시켜야 한다. 모델이 "맥락이 있는 상황"을 처음 보는 것이어서는 안 된다.
프롬프트 베이킹(Prompt Baking): 파일럿 단계에서 프롬프트 입출력을 광범위하게 로깅한 뒤, 이 로그를 정리하여 학습 데이터로 활용하는 기법. 가장 현실적인 학습 데이터를 만드는 방법.
자, 이제 이 모든 기법을 아이슬란드어 교정 문제에 적용한 OpenAI의 실험 결과를 보자.
가장 흥미로운 결과는 마지막 줄이다. 파인튜닝에 RAG를 추가했더니 오히려 4포인트가 하락했다.
왜 그럴까? 이 문제는 본질적으로 행동 최적화 문제였기 때문이다. 모델은 이미 아이슬란드어를 알고 있었다. 추가 맥락(RAG)은 도움이 되기는커녕, 이미 잘 학습된 행동에 노이즈를 더한 것이다.
이것이 이 글 전체에서 가장 중요한 교훈이다:
올바른 문제에 올바른 도구를 사용하라. 모든 기법에는 장점과 위험이 있으며, 이를 관리하는 유일한 방법은 평가와 반복적 변경이다.
LLM의 정확도 튜닝은 끝없는 전쟁이 될 수 있다. 기성 방법만으로 99.999%에 도달하기는 불가능하다. 그렇다면 언제 프로덕션에 내보내도 되는가?
OpenAI는 고객 서비스 사례로 이 문제를 설명한다:
| 이벤트 | 단건 가치 | 건수 (1,000건) | 총 가치 |
|---|---|---|---|
| AI 성공 (사람 대체) | +$20 | 815 | +$16,300 |
| AI 실패 (에스컬레이션) | -$40 | 175.75 | -$7,030 |
| AI 실패 (고객 이탈, 5%) | -$1,000 | 9.25 | -$9,250 |
| 손익 합계 | +$20 |
이 모델에서 손익분기 정확도는 81.5%다. 즉 85% 정확도만 달성해도, 실패의 15%가 주로 조기 에스컬레이션이라면 충분히 가치 있는 솔루션이다.
핵심 결정 두 가지:
비즈니스가 "85% 정확도면 OK"라고 결정했다면, 기술팀의 역할은 나머지 15%의 영향을 최소화하는 것이다:
2024년 9월 OpenAI의 o1이 게임 체인저였다. 핵심 아이디어: 추론 시점에 더 많은 연산을 투입하면, 더 큰 모델을 학습시키는 것과 비슷한 효과를 낼 수 있다. o3는 AIME에서 96.7%를 기록했다 (o1의 83.3% 대비).
DeepSeek-R1 (2025년 1월)은 이를 순수 강화학습(GRPO)만으로 달성할 수 있음을 보여주었다. 비싼 사람 레이블 없이, 검증 가능한 보상만으로 모델이 스스로 자기 검증, 반성, 전략 적응을 발전시켰다.
2022년에는 "단계별로 생각해 봐"라고 프롬프트에 쓰는 것이 혁신이었다. 2026년에는 모델이 알아서 추론한다. Claude의 Extended Thinking, OpenAI의 o-시리즈 모델은 아키텍처 수준에서 추론 토큰을 사용한다. 프롬프트에 "think step by step"을 쓸 필요가 없다 — 오히려 방해가 될 수 있다.
현재 최전선의 학습 파이프라인은 세 단계로 모듈화되어 있다:
| 실패 패턴 | 1차 해결책 | 왜? |
|---|---|---|
| 모델이 도메인 사실을 모른다 | RAG | 외부 지식을 실시간으로 주입 |
| 정보가 오래되었다 | RAG | 최신 문서를 검색하여 제공 |
| 톤/형식이 불안정하다 | 파인튜닝 | 행동 패턴을 가중치에 각인 |
| 지시를 잘 따르지 않는다 | 프롬프트 먼저, 그 다음 파인튜닝 | 저비용 순서대로 |
| 복잡한 추론이 필요하다 | 추론 모델 (o3, R1) 또는 RL | 테스트 타임 컴퓨팅 |
| 특정 주제에서 환각이 심하다 | RAG + 근거 검증 | 사실 기반 검색 + 출처 확인 |
이 글 전체를 관통하는 하나의 원칙이 있다:
단순한 것부터 시작하고, 평가가 가리키는 방향으로만 복잡도를 높여라.
각 기법의 탄생 배경을 되짚어 보면, 결국 같은 패턴의 반복이다:
매번 기존 접근법의 구체적인 한계가 새로운 기법을 탄생시켰다. 그리고 2026년의 답은: 이 모든 것을, 올바른 순서로, 평가에 기반하여 사용하라.