들어가며: AI에게 시험 공부를 시킨다면
당신이 의대생이라고 상상해보자. 일주일 뒤에 해부학 기말시험이 있다.
세 가지 전략이 있다:
- 교과서를 전부 외운다 — 시험장에 아무것도 가져갈 수 없다 (닫힌 책 시험)
- 공부 없이 시험장에 간다 — 대신 교과서를 펼쳐볼 수 있다 (열린 책 시험, 공부 안 함)
- 교과서로 공부한 뒤 시험장에서도 펼쳐본다 — 어디에 뭐가 있는지 이미 안다 (열린 책 시험, 공부 함)
어떤 전략이 가장 좋을까? 당연히 3번이다. 그런데 놀랍게도, 2024년까지 대부분의 AI 시스템은 1번 아니면 2번만 하고 있었다.
2024년 3월, UC Berkeley 연구팀이 이 문제를 정면으로 해결하는 논문을 발표했다.

"RAFT: Adapting Language Model to Domain Specific RAG"
Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, Joseph E. Gonzalez
UC Berkeley · 2024년 3월 ·
arXiv:2403.10131
GitHub:
ShishirPatil/gorilla/raft
RAFT(Retrieval Augmented Fine-Tuning)는 이름부터 직관적이다 — RAG(검색 증강 생성)과 Fine-Tuning(파인튜닝)을 결합한 훈련 레시피다. 아키텍처를 바꾸거나 새로운 모델을 만드는 것이 아니라, 기존 모델을 더 똑똑하게 훈련시키는 방법이다.
이 글에서는 RAFT가 왜 등장했는지, 어떤 원리로 작동하는지, 그리고 2026년 지금 어떤 의미를 갖는지 깊이 파고들어 본다.
1부: 역사 — RAG는 어떻게 태어났고, 왜 한계에 부딪혔나
2020년: RAG의 탄생
모든 것은 2020년 NeurIPS에서 시작됐다. Patrick Lewis 등의 연구팀이 발표한 "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"는 AI 역사의 분기점이었다.
핵심 아이디어는 단순했다: LLM의 파라미터에 저장된 지식(parametric memory)과 외부 문서 데이터베이스(non-parametric memory)를 하나의 시스템으로 결합하자.
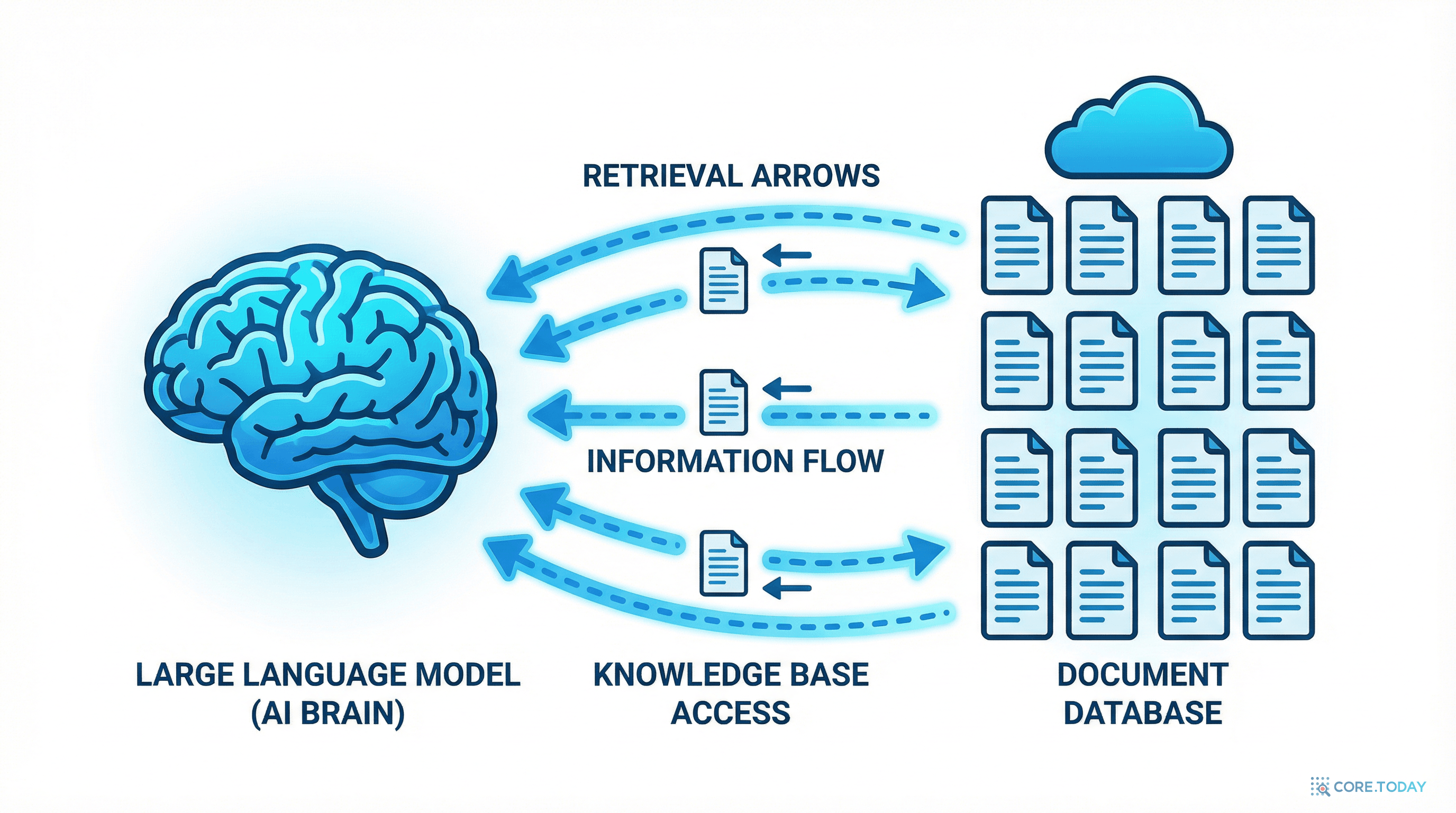
사용자 질문
→
검색 엔진 (Retriever)
→
관련 문서 top-k개
→
LLM 생성
이전까지 LLM은 훈련 시점에 본 데이터만 알 수 있었다. 2023년에 일어난 사건을 물으면 2021년까지의 데이터로 훈련된 모델은 "모르겠습니다"라고 답하거나, 더 나쁜 경우 그럴듯한 거짓말(hallucination)을 만들어냈다.
RAG는 이 문제를 우아하게 해결했다. 질문이 들어오면 먼저 관련 문서를 검색하고, 그 문서를 컨텍스트로 넣어서 답변을 생성한다. 마치 시험 중에 교과서를 펼쳐보는 것과 같다.
2021–2023: RAG의 황금기와 그림자
RAG는 폭발적으로 채택됐다. ChatGPT의 등장(2022.11)과 함께 "RAG 파이프라인"은 엔터프라이즈 AI의 사실상 표준이 되었다. 기업들은 자사 문서를 벡터 데이터베이스에 저장하고, LLM에 검색 결과를 주입하는 시스템을 앞다투어 구축했다.
그러나 실전에서 RAG는 예상보다 많은 문제를 드러냈다:
1
방해 문서 민감성
검색 엔진이 가져온 5개 문서 중 정답이 포함된 것은 1개뿐인데, 나머지 4개의 관련 있어 보이지만 틀린 문서에 모델이 휘둘린다. 검색 정밀도가 100%가 아닌 현실에서 항상 발생하는 문제다.
2
멀티홉 추론 실패
여러 문서의 정보를 조합해야 답할 수 있는 질문(예: "A 영화의 각본가 중 B 영화에도 참여한 사람은?")에서 RAG 모델은 단편적인 정보만 추출하고 종합적 추론에 실패한다.
3
도메인 부적응
범용 LLM이 의료 문헌이나 법률 문서처럼 전문 도메인의 용어와 추론 패턴을 제대로 이해하지 못한다. 문서를 줘도 핵심을 놓치거나 잘못 해석한다.
한편, 파인튜닝은 다른 방향의 한계를 가졌다:
파인튜닝의 딜레마
도메인 특화 파인튜닝(Domain-Specific Fine-tuning, DSF)은 모델을 특정 분야의 전문가로 만들 수 있었다. 의료 문헌으로 파인튜닝하면 의료 지식이 올라가고, 법률 데이터로 훈련하면 법률 추론 능력이 높아진다.
그런데 역설적인 문제가 발생한다: 파인튜닝한 모델에 RAG를 붙이면 오히려 성능이 떨어지는 경우가 있었다.
TensorFlow Hub 데이터셋:
• DSF만 사용: 86.56%
• DSF + RAG: 60.29% (−26.27%p)
파인튜닝으로 학습한 지식과 검색으로 가져온 문서가 충돌하면, 모델이 혼란에 빠진다. 열심히 외운 학생이 시험장에서 교과서를 펼쳤더니 자기가 외운 내용과 살짝 다른 표현을 보고 당황하는 것과 같다.
이것이 RAFT가 해결하려는 핵심 문제다. RAG와 파인튜닝을 따로 쓰면 각각 한계가 있고, 단순히 합치면 오히려 역효과가 난다. 그렇다면 처음부터 두 기법이 협력하도록 훈련하면 어떨까?
2부: RAFT의 핵심 — 오픈북 시험 준비법
세 가지 시험 시나리오
RAFT 논문의 가장 강력한 무기는 직관적인 비유다. 연구진은 LLM 훈련을 시험 준비에 비유하며 세 가지 시나리오를 제시한다:

시나리오 A: 닫힌 책 시험 (기존 파인튜닝)
모델에게 질문-답변 쌍만 보여주고 훈련한다. 문서는 제공하지 않는다. 이 모델은 모든 것을 외워야 한다.
문제점: 시험(추론 시)에 문서가 주어져도 활용할 줄 모른다. 외운 내용과 문서 내용이 다르면 오히려 혼란스러워진다.
시나리오 B: 열린 책 시험, 공부 안 함 (기존 RAG)
모델에게 사전 훈련된 지식만 있고, 추론 시에 검색된 문서를 컨텍스트로 제공한다. 교과서는 있지만 어디에 뭐가 있는지 모른다.
문제점: 방해 문서에 쉽게 속고, 긴 문서에서 핵심을 찾는 데 서툴다. 특히 전문 도메인에서는 용어 자체를 이해하지 못해 교과서가 있어도 무용지물이다.
시나리오 C: 열린 책 시험, 공부 함 (RAFT)
모델을 훈련할 때 문서와 함께 질문-답변을 학습한다. 더 중요한 것은, 훈련 데이터에 방해 문서(distractor)를 섞어서 "노이즈 속에서 정답 찾기"를 연습시킨다.
결과: 시험장에서 교과서를 펼쳤을 때, 어느 페이지의 어느 단락이 중요한지 즉시 파악하고, 정확히 인용하며, 체계적으로 추론한다.
3부: RAFT는 어떻게 작동하는가
훈련 데이터 구성법
RAFT의 핵심은 훈련 데이터를 구성하는 방식에 있다. 각 훈련 예시는 다음 요소로 구성된다:
Q
질문 — 도메인에 관한 자연어 질문
D*
오라클 문서 — 정답이 포함된 "황금" 문서
D1~Dk
방해 문서 — 주제는 관련 있지만 정답은 없는 문서들
A*
Chain-of-Thought 답변 — 원문 인용 + 추론 과정 + 최종 답
여기서 핵심적인 트릭이 두 가지 있다:
트릭 1: 방해 문서 훈련
모든 훈련 예시에 오라클 문서만 넣으면 모델이 "첫 번째 문서가 항상 정답"이라는 편향(shortcut)을 학습한다. 실제 검색 엔진은 완벽하지 않으므로, 훈련 시에도 불완전한 검색 환경을 시뮬레이션해야 한다.
RAFT는 전형적으로 1개의 오라클 문서 + 4개의 방해 문서 = 총 5개 문서를 사용한다. 모델은 5개 문서 중 어떤 것이 정답을 포함하는지 스스로 판단해야 한다.
트릭 2: P% — 때로는 오라클 없이 훈련
더 놀라운 것은, 훈련 데이터의 일부(1-P%)에서는 오라클 문서를 아예 빼버린다. 이 경우 모델은 방해 문서만 보고도 답을 내야 한다 — 즉, 암기된 지식에 의존해야 한다.
이것이 왜 중요할까? 모델이 "문서에 답이 있으면 인용하고, 없으면 내가 아는 것을 바탕으로 답한다"는 유연한 전략을 학습하기 때문이다.
Chain-of-Thought 답변 형식
RAFT의 또 다른 핵심은 답변 형식이다. 단순히 "정답은 X다"가 아니라, 추론 과정 전체를 포함한다:
QUESTION
오베로이 그룹의 호텔 회사 본사는 어디에 있는가?
CHAIN-OF-THOUGHT
주어진 문서를 분석하면, 문서 3에서 오베로이 그룹에 대한 정보를 찾을 수 있다.
##begin_quote##
"The Oberoi Group is a hotel company with its head office in Delhi."
##end_quote##
위 인용에서 "head office in Delhi"라는 명확한 정보를 확인할 수 있다.
ANSWER
오베로이 그룹의 호텔 회사 본사는
델리(Delhi)에 있다.
##begin_quote##와 ##end_quote##로 감싼 원문 직접 인용이 핵심이다. 이 형식으로 훈련하면:
- 모델이 문서에서 정확한 근거를 찾는 능력을 학습한다
- 할루시네이션이 줄어든다 — 인용할 수 없으면 답하기 어렵다
- 감사 추적(audit trail)이 가능해진다 — 답의 근거를 확인할 수 있다
4부: 실험 결과 — 7B 모델이 GPT-3.5를 이기다
RAFT 논문의 가장 충격적인 결과는 LLaMA2-7B(70억 파라미터) 모델이 GPT-3.5+RAG를 대부분의 도메인에서 능가했다는 것이다. 모델 크기가 수십 배 작은데도 말이다.

주요 벤치마크 결과
핵심 발견들:
- HuggingFace API 문서: RAFT(74.00%) vs GPT-3.5+RAG(29.08%) — 44.92%p 차이. 7B 모델이 훨씬 큰 모델을 압도한다
- DSF+RAG의 역설: HotpotQA에서 DSF(6.38%)에 RAG를 붙이면 4.41%로 오히려 하락. 파인튜닝과 RAG의 단순 결합이 위험할 수 있음을 증명
- 의료 분야(PubMed): RAFT(73.30%)가 GPT-3.5+RAG(71.60%)를 넘어섬. 전문 도메인에서의 우위
전체 결과 비교표
| 모델 | PubMed | HotpotQA | HuggingFace | Torch Hub | TF Hub |
|---|
| LLaMA2-7B (0-shot) | 56.50 | 0.54 | 0.22 | 0 | 0 |
| LLaMA2-7B + RAG | 58.80 | 0.03 | 26.43 | 8.60 | 43.06 |
| DSF (파인튜닝) | 59.70 | 6.38 | 61.06 | 84.94 | 86.56 |
| DSF + RAG | 71.60 | 4.41 | 42.59 | 82.80 | 60.29 |
| GPT-3.5 + RAG | 71.60 | 41.50 | 29.08 | 60.21 | 65.59 |
| RAFT (LLaMA2-7B) | 73.30 | 35.28 | 74.00 | 84.95 | 86.86 |
주의: 녹색 강조(highlight)는 각 열에서 최고 성능을, 주황색(warn)은 역효과가 나는 경우를 표시한다. RAFT가 5개 벤치마크 중 5개 모두에서 최고 성능을 기록했다.
5부: 왜 이렇게 작동할까? — 핵심 요인 분석
Chain-of-Thought의 힘
연구진은 CoT(Chain-of-Thought) 답변을 빼고 훈련한 ablation 실험도 수행했다:
Chain-of-Thought 효과 (RAFT vs RAFT w/o CoT)
CoT 포함 시 정확도 향상폭
HuggingFace API 문서에서 +14.93%p의 향상은 엄청나다. API 문서처럼 정확한 매개변수 이름과 형식이 중요한 도메인에서는, "근거를 인용하며 추론하는 능력"이 결정적인 차이를 만든다.
P%의 최적값은 데이터셋마다 다르다
흥미로운 발견: 오라클 문서를 포함하는 비율 P%의 최적값이 데이터셋에 따라 달랐다.
| 데이터셋 | 최적 P% | 해석 |
|---|
| Natural Questions | 40% | 일반 지식은 암기도 중요 → 오라클 없는 훈련이 상당 부분 필요 |
| TriviaQA | 60% | 균형 잡힌 접근이 최적 |
| HotpotQA | 100% | 멀티홉 추론은 항상 문서가 필요 → 오라클 항상 제공이 최적 |
이것은 직관적으로도 이해된다. 단순 사실 질문(Natural Questions)은 외우고 있으면 빠르게 답할 수 있으므로 암기 훈련의 비중이 높아야 하고, 여러 문서를 교차 참조하는 복잡한 질문(HotpotQA)은 항상 문서를 보며 연습해야 한다.
방해 문서 수의 영향
훈련 시 방해 문서 수도 성능에 영향을 미친다:
!
오라클만으로 훈련하면
방해 문서 0개 → 모델이 "문서는 항상 정답을 포함한다"는 잘못된 가정을 학습. 실전에서 방해 문서를 만나면 대응 불가.
★
최적의 방해 문서 수
Natural Questions: D* + 3개 방해 문서가 최적. HotpotQA: D* + 1개 방해 문서가 최적. 과제의 복잡성에 따라 달라진다.
✓
핵심 교훈
방해 문서로 훈련한 모델은 테스트 시 문서 수가 변해도 안정적으로 작동한다. 훈련-추론 환경의 불일치에 강건해진다.
6부: 실전 사례 — RAFT가 빛나는 순간들
사례 1: 의료 문헌 Q&A (PubMed)
병원의 AI 시스템이 의사의 질문에 답하는 상황을 생각해보자.
질문
"제2형 당뇨병 환자에서 메트포르민의 심혈관 보호 효과에 대한 최신 근거는?"
RAG만
5개 논문 검색 → 2개는 제1형 당뇨병 문서(방해) → 혼동하여 제1형과 제2형 연구를 혼합 인용 → 부정확한 답변
RAFT
5개 논문 검색 → 제2형 관련 논문만 정확히 식별 → 핵심 통계 직접 인용 → "UKPDS 연구에 따르면..." 체계적 답변
RAFT 훈련을 받은 모델은 PubMed 데이터에서 73.30%의 정확도를 보여, GPT-3.5+RAG의 71.60%를 능가했다. 의료 분야에서 1.7%p의 차이는 잘못된 진단 조언을 줄이는 의미가 있다.
사례 2: API 문서 질의 (HuggingFace Hub)
개발자가 "이미지 분류에 적합한 HuggingFace 모델을 찾아줘"라고 질문하는 경우:
질문
"google/vit-base-patch16-224 모델의 입력 형식과 사용법은?"
GPT-3.5+RAG
정확도 29.08% — API 매개변수명을 자주 틀리고, 비슷한 이름의 다른 모델 정보와 혼동
RAFT (7B)
정확도 74.00% — 정확한 모델 카드 인용, 올바른 파이프라인 코드 생성, 입력 형식 정확
74% vs 29% — 2.5배 이상의 정확도 차이다. RAFT로 훈련된 7B 모델이 GPT-3.5보다 API 문서를 훨씬 잘 이해하고 활용한다는 뜻이다.
사례 3: 멀티홉 추론 (HotpotQA)
질문: "'Evolution' 영화의 각본가 중 니콜라스 케이지와 테아 레오니가 출연한 영화의 각본가는 누구인가?"
✗ DSF 답변: "The Family Man" (영화 제목을 답함 — 각본가를 물었는데)
✓ RAFT 답변: 문서에서 "Evolution"의 각본가 목록을 인용 → 그 중 "The Family Man"에도 참여한 사람을 교차 확인 → "David Weissman"을 정확히 답변
DSF 모델은 질문의 구조를 제대로 파악하지 못하고 영화 제목을 답했지만, RAFT 모델은 두 문서를 교차 참조하여 정확한 인물명을 추출했다.
7부: 실전 구현 가이드
RAFT 훈련 파이프라인
RAFT를 자신의 도메인에 적용하는 과정은 다음과 같다:
STEP 1
문서 준비 — 도메인 문서를 수집하고 512 토큰 단위로 청킹
STEP 2
QA 쌍 생성 — GPT-4 등으로 각 청크에서 질문-답변 쌍을 자동 생성
STEP 3
방해 문서 배치 — 각 QA 쌍에 오라클 청크 + 무작위 방해 청크 4개 결합
STEP 4
CoT 답변 포맷팅 — 인용 + 추론 과정을 포함한 답변으로 변환
STEP 5
파인튜닝 실행 — P% 비율로 오라클 포함/미포함 데이터 혼합 후 훈련
GitHub 코드 사용법
hljs language-bash
git clone https://github.com/ShishirPatil/gorilla.git
cd gorilla/raft
pip install -r requirements.txt
python raft.py \
--datapath ./my_documents/ \
--output ./raft_dataset \
--distractors 4 \
--p 0.6 \
--chunk_size 512 \
--questions 5
python raft_local.py \
--datapath ./my_documents/ \
--output ./raft_dataset
훈련 권장 설정
| 하이퍼파라미터 | 권장값 | 비고 |
|---|
| 정밀도 | 16-bit (FP16/BF16) | 메모리 효율과 품질의 균형 |
| 에포크 | 최대 3 | 과적합 방지. 중간 체크포인트 저장 |
| 학습률 | 사전훈련의 1/10 | 기존 지식 보존 |
| 배치 크기 | 가능한 크게 | 학습 안정성 향상 |
| P% (오라클 비율) | 40–80% | 도메인별 실험 필요 |
| 방해 문서 수 | 3–4개 | 일반적으로 D* + 4개가 효과적 |
8부: 2026년의 시점에서 — RAFT의 유산과 현재
RAG 진화의 큰 그림
RAFT는 RAG 기술 진화의 한 가지 중요한 갈래를 열었다. 2026년 현재, RAG 생태계는 다음과 같이 분화했다:
2026년 RAG 생태계
Naive RAG
2020–2022
검색 → 삽입 → 생성
Advanced RAG
2023–2024
쿼리 최적화 + 재순위화
RAFT
2024
훈련 + 검색 통합
Agentic RAG
2024–2026
자율 검색 전략 결정
↓
GraphRAG
지식 그래프 기반
구조화된 관계 추론
Modular RAG
조합형 아키텍처
유연한 파이프라인 구성
RAFT + Agents
하이브리드 패러다임
훈련된 읽기 + 자율 검색
RAFT가 2026년에도 유효한 이유
- 실용적 단순성: 아키텍처 변경 없이 훈련 데이터만 바꾸면 된다. 어떤 베이스 모델에서든 적용 가능하다
- 소형 모델의 무기: RAFT로 훈련된 7B 모델이 도메인 내에서 100B+ 모델과 경쟁할 수 있다. 비용과 지연시간 면에서 압도적 이점이다
- 감사 추적 내장:
##begin_quote## 인용 형식은 엔터프라이즈 컴플라이언스(금융, 의료, 법률)에서 필수 요구사항인 근거 추적을 자연스럽게 지원한다
- 방해 문서 강건성: 실세계 검색은 완벽하지 않다. RAFT는 이 현실을 훈련에 반영하는 유일한 접근법 중 하나다
현재 산업에서의 RAFT 활용
| 분야 | 적용 방식 | 효과 |
|---|
| 의료 AI | PubMed/임상 문서로 RAFT 훈련 | 진단 보조 정확도 향상, 근거 추적 가능 |
| 법률 AI | 판례/법령으로 RAFT 훈련 | 관련 조문 정확 인용, 다중 법원 판결 교차 참조 |
| 개발자 도구 | API 문서로 RAFT 훈련 | 코드 어시스턴트 정확도 2.5배 향상 |
| 고객 서비스 | 제품 매뉴얼/FAQ로 RAFT 훈련 | 정확한 답변 + 매뉴얼 페이지 인용 |
| 금융 분석 | 재무제표/보고서로 RAFT 훈련 | 수치 정확성 향상, 출처 명시 의무 충족 |
마치며: 시험 공부의 정석은 AI에게도 통한다
RAFT가 주는 가장 큰 교훈은 단순하다:
참고서를 곁에 두고 시험을 본다면, 참고서를 곁에 두고 공부도 해야 한다.
이것은 너무나 당연한 말 같지만, 2024년까지 AI 분야에서는 이 당연한 원칙이 적용되지 않고 있었다. 파인튜닝은 "참고서 없이 암기"시키고, RAG는 "공부 없이 참고서만 줬다." RAFT는 이 두 세계를 하나로 합쳤다.
핵심을 다시 정리하면:
P
문제
RAG만으로는 방해 문서에 취약하고, 파인튜닝만으로는 새 정보에 대응 불가. 단순 결합은 오히려 역효과.
S
해결
방해 문서를 포함한 훈련 데이터 + 인용 기반 Chain-of-Thought 답변 형식으로 파인튜닝. 오라클 없는 데이터로 암기력도 유지.
R
결과
7B 파라미터 모델이 GPT-3.5를 능가. 5개 벤치마크 전부에서 최고 성능. 할루시네이션 감소 + 감사 추적 가능.
RAFT는 "어떤 새로운 것을 만들었다"기보다 "기존 기법들을 올바르게 결합하는 방법을 발견했다"에 가깝다. 그리고 종종 가장 강력한 혁신은 복잡한 새 기술이 아니라, 당연한 것을 처음으로 제대로 한 것에서 나온다.
2026년의 AI 시스템을 구축하고 있다면, RAFT의 교훈을 기억하자: AI가 실전에서 하는 것을 훈련에서도 하게 하라.
참고 문헌 및 리소스