블로그로 돌아가기
RAG청킹리랭킹하이브리드 검색임베딩벡터 검색
Advanced RAG: 기본 RAG의 한계를 넘는 실전 개선 기법 7가지
기본 RAG를 실전에 배포하면 마주치는 문제들 — 엉뚱한 문서가 검색되고, 핵심이 잘려나가고, 답변 품질이 들쭉날쭉하다. 청킹 전략부터 하이브리드 검색, 리랭킹까지, 실무에서 바로 적용할 수 있는 개선 기법을 하나씩 풀어본다.
코어닷투데이2026-03-0540분
기본 RAG를 실전에 배포하면 마주치는 문제들 — 엉뚱한 문서가 검색되고, 핵심이 잘려나가고, 답변 품질이 들쭉날쭉하다. 청킹 전략부터 하이브리드 검색, 리랭킹까지, 실무에서 바로 적용할 수 있는 개선 기법을 하나씩 풀어본다.

이전 글에서 우리는 RAG의 핵심 원리를 다뤘다. 질문이 들어오면 관련 문서를 검색하고, 그 문서를 LLM에 넘겨 답변을 생성하는 3단계 파이프라인 — Retrieve, Augment, Generate.
원리는 단순하다. 하지만 이것을 실전에 배포하는 순간, 예상치 못한 문제들이 쏟아진다.
"분명히 관련 문서가 있는데, 검색이 안 돼요." "검색은 됐는데, 핵심 부분이 아니라 엉뚱한 단락이 들어와요." "같은 질문인데 답변 품질이 들쭉날쭉해요."
이것은 RAG 자체의 문제가 아니라, 기본 RAG(Naive RAG)의 한계다. Gao et al. (2024)의 서베이 논문 "Retrieval-Augmented Generation for Large Language Models: A Survey"는 RAG의 발전 단계를 세 가지로 구분한다:
| 단계 | 특징 |
|---|---|
| Naive RAG | 기본 파이프라인. 검색 → 생성. 빠르게 구축 가능하지만 품질 한계 |
| Advanced RAG | 검색 전·중·후에 개선 기법을 추가. 실무 적용의 핵심 |
| Modular RAG | 파이프라인 자체를 모듈화하여 태스크별로 재조합 |
이 글에서는 Advanced RAG — 기본 RAG의 각 단계에 구체적인 개선 기법을 적용하여 답변 품질을 끌어올리는 방법을 다룬다. 모든 기법은 실무에서 바로 적용할 수 있는 수준으로 설명한다.
기본 RAG가 "검색 → 생성"의 직선 파이프라인이라면, Advanced RAG는 이 파이프라인의 앞(Pre-Retrieval), 중간(Retrieval), 뒤(Post-Retrieval)에 개선 단계를 추가한다.
이 글에서 다루는 7가지 기법을 단계별로 정리하면:
하나씩 살펴보자.
RAG의 첫 번째 단계는 문서를 벡터 데이터베이스에 저장하는 것이다. 이때 문서 전체를 하나의 벡터로 만들면 문제가 생긴다.
100페이지짜리 사내 규정집을 상상해보자. 이것을 통째로 하나의 벡터로 만들면, "재택근무 정책"을 검색했을 때 100페이지 전체가 반환된다. LLM의 컨텍스트 윈도우에 100페이지를 모두 넣을 수도 없고, 넣더라도 핵심을 찾기 어렵다.
반대로 문장 하나씩 쪼개면? "직원은 주 2회 이상 사무실에 출근해야 한다"라는 문장만 반환된다. 맥락이 없다. 왜 주 2회인지, 예외 조건은 무엇인지, 신청 절차는 어떤지 — 주변 정보가 모두 사라진다.
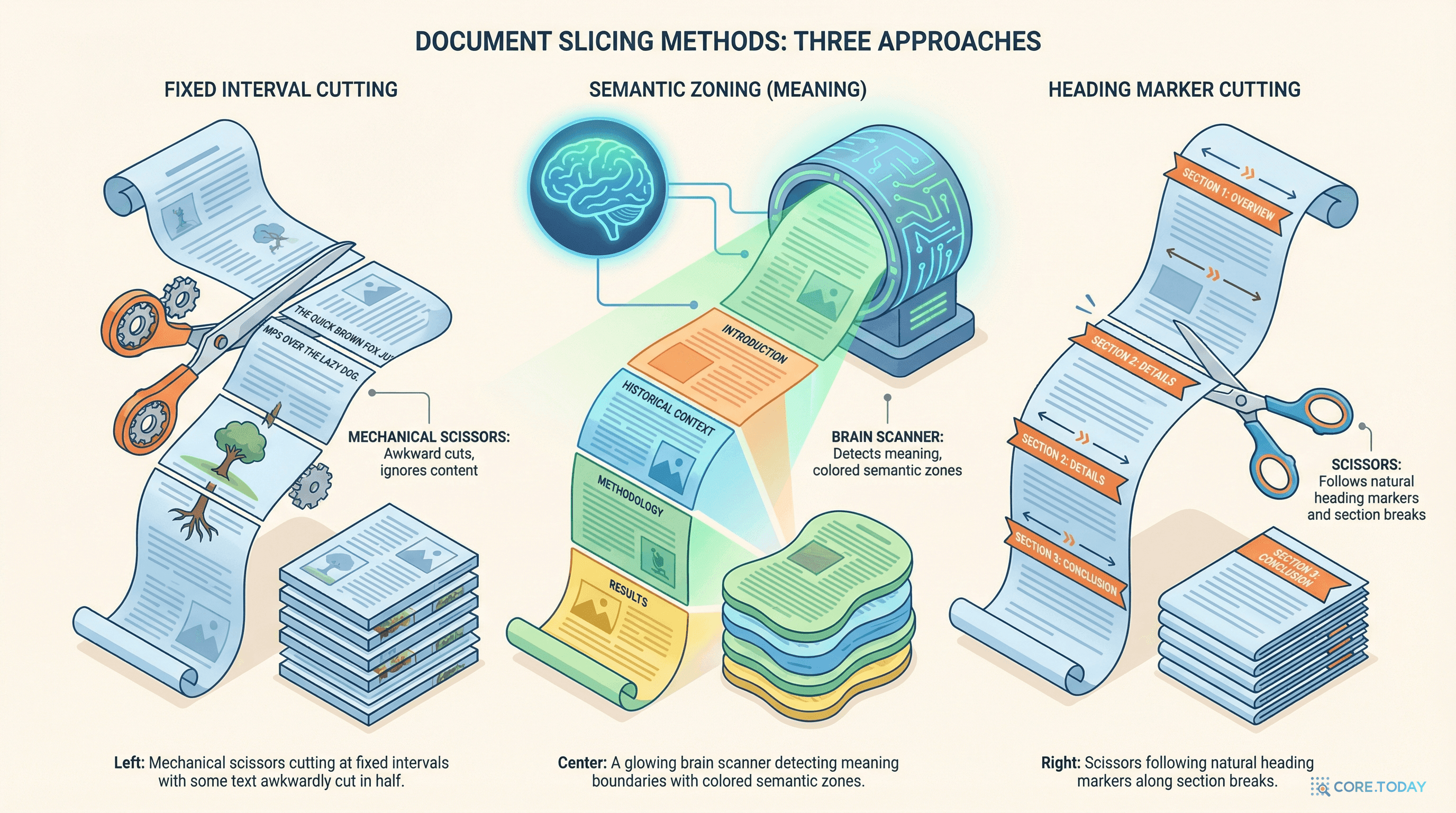
청킹(chunking)은 이 문서를 "적절한 크기"로 나누는 기술이다. 그리고 "적절한 크기"가 무엇인지가 RAG 성능을 좌우하는 첫 번째 관문이다.
가장 단순한 방법. 문서를 일정한 토큰 수(예: 512토큰)로 기계적으로 자른다.
def fixed_size_chunk(text, chunk_size=512, overlap=50):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = " ".join(words[i:i + chunk_size])
chunks.append(chunk)
return chunks
여기서 overlap이 중요하다. 청크 사이에 겹치는 부분을 두어, 문장이 잘리는 것을 완화한다.
Greg Kamradt가 제안한 방법으로, 문장 간 임베딩 유사도를 기준으로 자른다. 의미가 급격히 바뀌는 지점에서 청크를 나누는 것이다.
# 의사 코드
sentences = split_into_sentences(document)
embeddings = embed(sentences)
chunks = []
current_chunk = [sentences[0]]
for i in range(1, len(sentences)):
similarity = cosine_similarity(
embeddings[i-1], embeddings[i]
)
if similarity < threshold: # 의미가 크게 바뀌면
chunks.append(join(current_chunk))
current_chunk = [sentences[i]]
else:
current_chunk.append(sentences[i])
문서의 원래 구조(제목, 소제목, 단락, 목록)를 활용해 자르는 방법이다. Markdown이라면 ## 헤딩 기준, HTML이라면 <h2>, <section> 태그 기준으로 나눈다.
| 문서 유형 | 추천 전략 | 이유 |
|---|---|---|
| API 문서, 기술 문서 | 구조 기반 | 명확한 섹션 구조가 존재 |
| 법률 문서, 계약서 | 의미 기반 + 겹침(overlap) | 조항 간 연관성이 중요 |
| 채팅 로그, 이메일 | 고정 크기 + 시간 기준 | 구조가 불명확, 시간 흐름이 중요 |
| 논문, 보고서 | 구조 기반 + 의미 기반 혼합 | 섹션 내에서도 주제가 전환됨 |
핵심 원칙: 청크의 크기는 "하나의 청크가 하나의 질문에 답할 수 있는 정보를 담고 있는가"로 판단한다. 너무 작으면 맥락을 잃고, 너무 크면 노이즈가 늘어난다. 실무에서는 256~1024 토큰 범위에서 시작해 실험하는 것이 일반적이다.

사용자는 자연어로 질문한다. "요즘 우리 팀에서 쓰는 그 배포 도구 뭐였더라?" 같은 질문에는 모호함, 대명사, 구어체가 가득하다. 이 질문을 그대로 임베딩해서 검색하면 정확한 문서를 찾기 어렵다.
쿼리 변환(query transformation)은 사용자의 원래 질문을 검색에 더 적합한 형태로 바꾸는 기법이다.
Gao et al. (2023)이 제안한 방법으로, 아이디어가 독특하다: 질문에 대한 "가상의 답변"을 먼저 생성하고, 그 답변을 임베딩하여 검색한다.
사용자 질문: "파이썬에서 비동기 처리 어떻게 해?"
→ LLM이 가상 답변 생성:
"파이썬에서 비동기 처리는 asyncio 라이브러리를
사용합니다. async/await 키워드로 코루틴을
정의하고, event loop에서 실행합니다..."
→ 이 가상 답변을 임베딩하여 검색
왜 이것이 효과적인가? 질문과 문서는 형태가 다르다(질문은 의문문, 문서는 서술문). 하지만 "가상 답변"과 실제 문서는 형태가 비슷하다. 따라서 임베딩 공간에서 더 가까운 문서를 찾을 수 있다.
Zheng et al. (2023)이 제안한 방법. 구체적인 질문을 한 단계 추상화하여 더 넓은 범위의 문서를 검색한다.
원래 질문: "Next.js 16에서 서버 액션의 에러 핸들링은?"
Step-back 질문: "Next.js App Router에서 서버 액션은
어떻게 작동하는가?"
구체적 질문으로는 놓칠 수 있는 배경 지식까지 검색할 수 있다.
벡터 검색의 약점이 하나 있다. "의미적 유사성"만으로 판단하기 때문에, 시간이나 출처 같은 구조적 조건을 무시한다.
"2026년 1분기 매출 보고서"를 검색했을 때, 2024년 매출 보고서가 의미적으로 더 유사하다고 판단해 상위에 올라올 수 있다. 내용은 비슷하지만 시점이 다르다.
문서를 벡터 DB에 저장할 때, 벡터와 함께 메타데이터를 붙인다:
vector_store.add(
text="1분기 매출은 전년 대비 12% 성장...",
embedding=embed(text),
metadata={
"source": "finance_report",
"year": 2026,
"quarter": "Q1",
"department": "경영기획",
"doc_type": "보고서"
}
)
검색 시에는 벡터 유사도 검색 전에 메타데이터로 범위를 좁힌다:
results = vector_store.search(
query="매출 성장률",
filter={
"year": 2026,
"quarter": "Q1"
},
top_k=5
)
이렇게 하면 2026년 Q1 문서 안에서만 의미 검색이 이루어진다. 단순하지만 실무에서 검색 정확도를 크게 끌어올리는 기법이다.
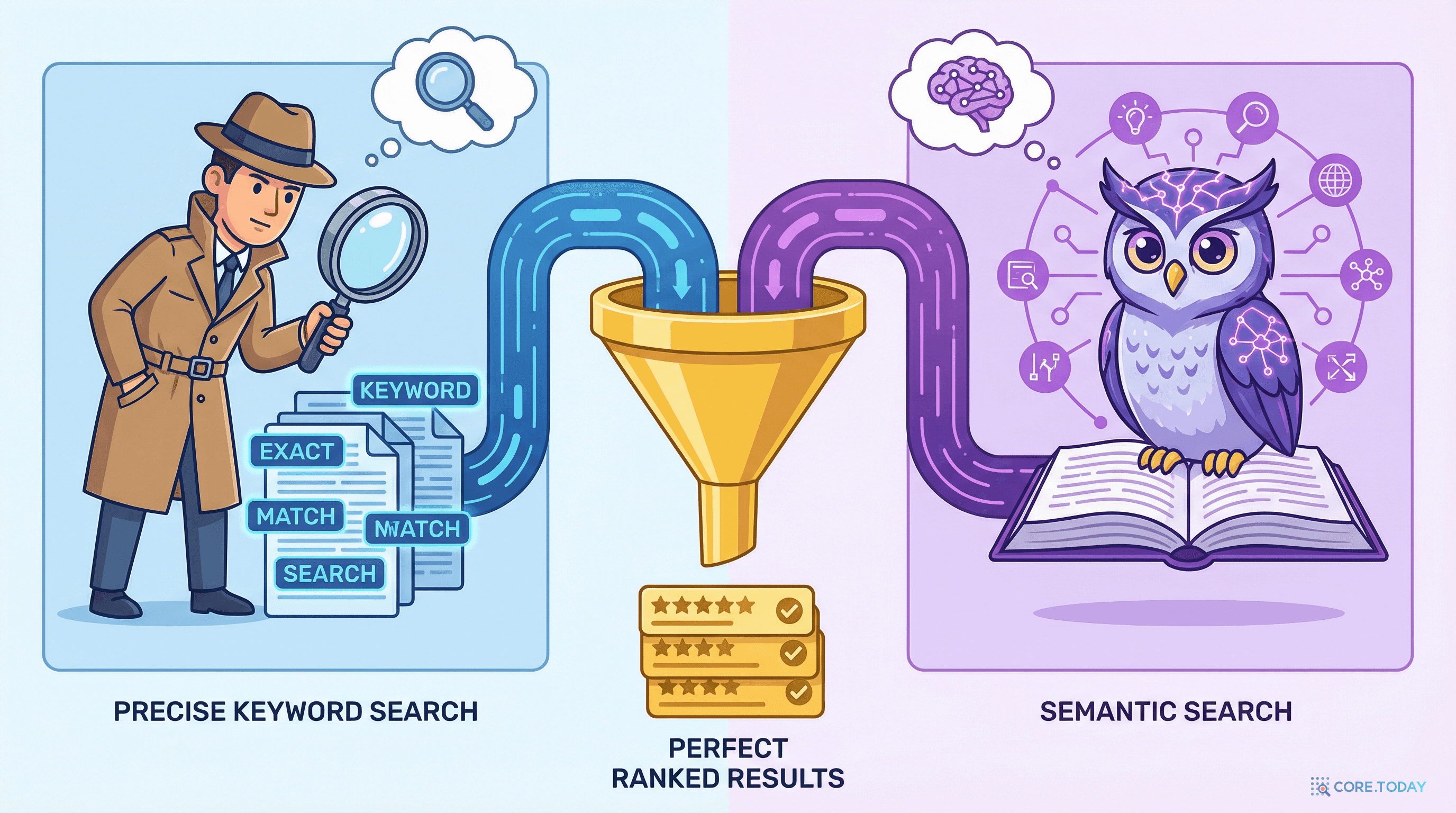
이전 글에서 벡터 검색(의미 검색)이 키워드 검색보다 우수한 경우를 봤다. "재택근무 정책"으로 "원격 근무"가 포함된 문서를 찾을 수 있었다.
하지만 반대로, 벡터 검색이 키워드 검색보다 못한 경우도 있다:
고유명사 검색: "Clerk 미들웨어 설정 방법"을 검색할 때, 벡터 검색은 "인증 미들웨어"나 "보안 설정" 관련 문서를 모두 가져올 수 있다. 하지만 사용자가 원하는 것은 정확히 "Clerk"이라는 특정 라이브러리에 대한 문서다.
에러 코드 검색: "NEXT_REDIRECT 에러"를 검색할 때, 벡터 검색은 리다이렉트 관련 일반 문서를 가져올 수 있다. 하지만 NEXT_REDIRECT라는 정확한 문자열이 포함된 문서가 필요하다.
코드 검색: useActionState라는 함수를 찾을 때, 의미적으로 유사한 "상태 관리 훅" 문서가 아니라, 정확히 이 함수명이 나오는 문서가 필요하다.
하이브리드 검색(hybrid search)은 키워드 검색(BM25)과 벡터 검색을 동시에 수행하고, 두 결과를 결합한다.
BM25는 1994년 Robertson et al.이 제안한 순위 함수로, 30년이 지난 지금도 키워드 검색의 표준이다. 핵심 원리는 직관적이다:
두 검색 결과를 어떻게 합칠까? 가장 널리 쓰이는 방법이 RRF(Reciprocal Rank Fusion)다. Cormack et al. (2009)이 제안한 이 방법은 놀라울 정도로 단순하다:
def reciprocal_rank_fusion(
keyword_results, vector_results, k=60
):
scores = {}
for rank, doc in enumerate(keyword_results):
scores[doc.id] = scores.get(doc.id, 0) \
+ 1 / (k + rank + 1)
for rank, doc in enumerate(vector_results):
scores[doc.id] = scores.get(doc.id, 0) \
+ 1 / (k + rank + 1)
# 통합 점수 기준으로 정렬
return sorted(
scores.items(),
key=lambda x: x[1],
reverse=True
)
각 검색 결과에서의 순위를 역수로 변환하고 합산한다. 두 검색 모두에서 상위에 있는 문서는 높은 통합 점수를 얻고, 한쪽에서만 상위인 문서도 적절히 반영된다.
| 질문 유형 | 키워드만 | 벡터만 | 하이브리드 |
|---|---|---|---|
| 고유명사 ("Clerk 설정") | ✓ 정확 | △ 관련 문서 섞임 | ✓ 정확 |
| 의미 검색 ("재택근무 정책") | ✗ "원격 근무" 누락 | ✓ 정확 | ✓ 정확 |
| 에러 코드 ("NEXT_REDIRECT") | ✓ 정확 | △ 리다이렉트 일반 문서 | ✓ 정확 |
| 개념 질문 ("성능 최적화 방법") | △ 키워드 의존적 | ✓ 다양한 관점 | ✓ 다양 + 정확 |
하이브리드 검색은 두 방식 중 더 나은 쪽의 결과를 자연스럽게 살려준다. 대부분의 프로덕션 RAG 시스템이 하이브리드 검색을 기본으로 채택하는 이유다.
"우리 서비스의 인증 시스템은 안전한가?"라는 질문을 생각해보자. 이 질문에는 여러 측면이 숨어 있다:
하나의 질문으로 하나의 임베딩을 만들면, 이 중 한두 가지 측면의 문서만 검색될 수 있다.
멀티 쿼리 검색(multi-query retrieval)은 원래 질문을 여러 하위 질문으로 분해하고, 각각을 별도로 검색한 뒤, 결과를 합치는 기법이다.
def multi_query_retrieve(question, vector_store, llm):
# LLM이 하위 질문들을 생성
sub_queries = llm.generate(f"""
다음 질문을 서로 다른 관점에서 3개의 하위 질문으로
분해하세요.
원래 질문: {question}
""")
# 각 하위 질문으로 개별 검색
all_results = []
for sub_q in sub_queries:
results = vector_store.search(sub_q, top_k=3)
all_results.extend(results)
# 중복 제거 후 반환
return deduplicate(all_results)
위 예시의 경우:
원래 질문: "우리 서비스의 인증 시스템은 안전한가?"
하위 질문 1: "서비스에서 사용 중인 인증 방식과
프로토콜은?"
하위 질문 2: "인증 관련 보안 설정 및 취약점 점검
결과는?"
하위 질문 3: "사용자 세션 관리와 토큰 만료 정책은?"
세 가지 검색이 각각 다른 각도의 문서를 가져오므로, 하나의 질문으로는 놓쳤을 문서까지 커버할 수 있다.

벡터 검색은 빠르지만, 정확도에는 한계가 있다. 임베딩은 텍스트의 전체적인 의미를 하나의 벡터로 압축하기 때문에, 미세한 관련성 차이를 구분하지 못할 수 있다.
예를 들어 "Next.js에서 서버 컴포넌트와 클라이언트 컴포넌트의 차이"를 검색했을 때:
벡터 유사도에서는 A가 더 높지만, 실제로 질문에 더 잘 답하는 것은 B다.
리랭킹(reranking)은 벡터 검색이 가져온 상위 N개 문서를, 더 정밀한 모델로 다시 순위를 매기는 기법이다.
핵심은 Bi-Encoder와 Cross-Encoder의 차이를 이해하는 것이다.
Bi-Encoder는 질문과 문서를 따로 인코딩한다. 서로를 "보지 않고" 각자의 의미를 벡터로 만든 뒤 비교하는 것이다. 속도가 빠르지만 미세한 관련성을 놓칠 수 있다.
Cross-Encoder는 질문과 문서를 함께 입력으로 넣어 관련도를 직접 판단한다. 질문의 모든 단어가 문서의 모든 단어와 상호작용(attention)하기 때문에 훨씬 정밀하다. 하지만 모든 문서에 대해 이 연산을 하면 너무 느리다.
그래서 실전에서는 2단계 파이프라인을 구성한다:
def retrieve_and_rerank(question, vector_store, reranker):
# 1단계: Bi-Encoder로 빠르게 후보 검색 (top-20)
candidates = vector_store.search(
query=question, top_k=20
)
# 2단계: Cross-Encoder로 정밀 재평가
reranked = reranker.rerank(
query=question,
documents=candidates,
top_k=5 # 상위 5개만 최종 선택
)
return reranked
20개를 빠르게 검색한 뒤, 20개에 대해서만 Cross-Encoder를 적용하여 가장 관련성 높은 5개를 골라내는 것이다.
Nogueira & Cho (2019)의 연구에서, BM25 검색 결과에 BERT 기반 리랭커를 적용하자 MS MARCO 벤치마크에서 MRR@10이 0.167 → 0.365로 대폭 향상되었다. 검색 결과의 순위가 바뀌는 것만으로도 답변 품질이 크게 달라진다는 의미다.
실무에서 자주 쓰이는 리랭커:
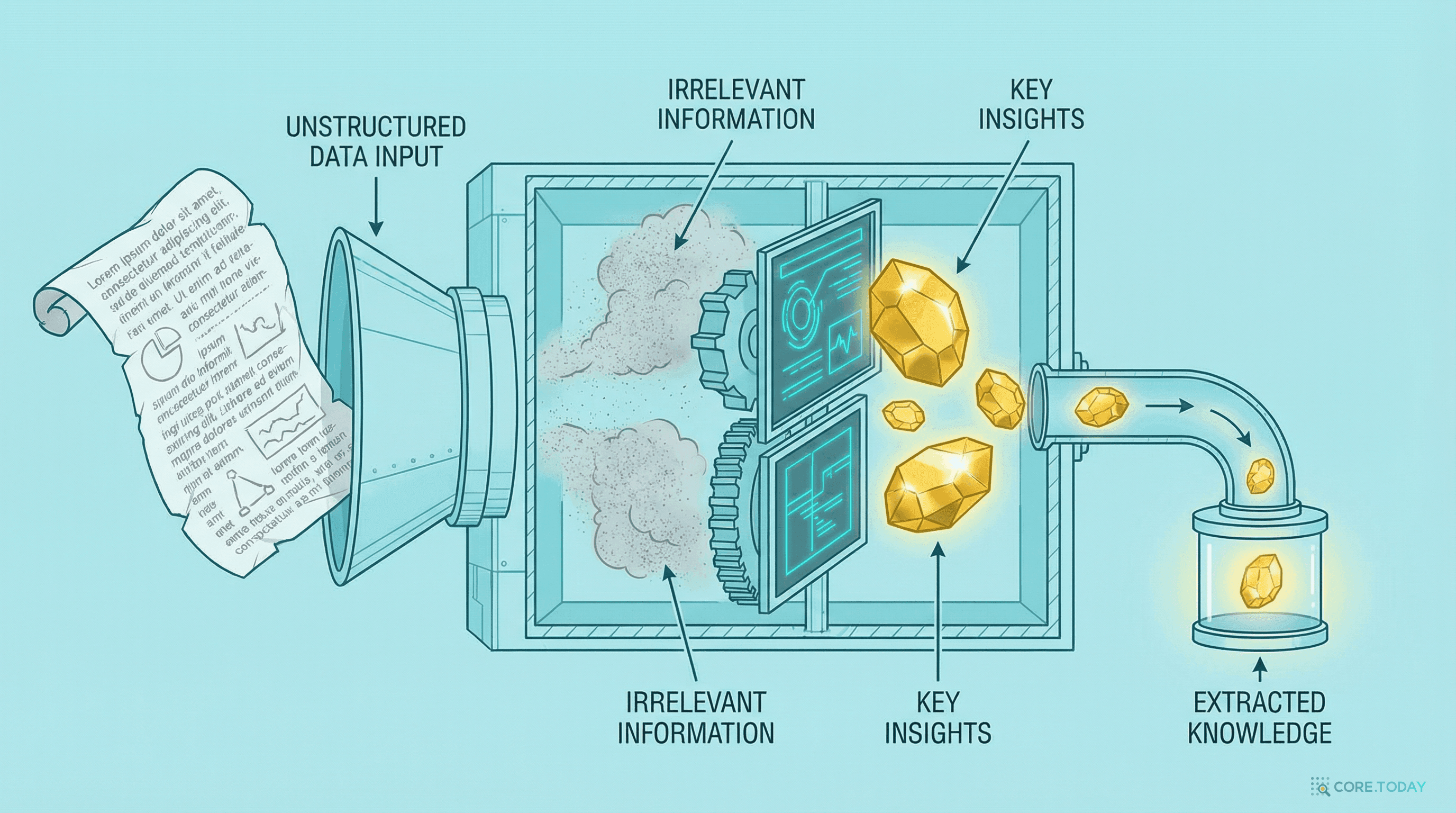
검색이 잘 되어도, 가져온 청크에 질문과 무관한 내용이 섞여 있을 수 있다. 500토큰짜리 청크 중 질문에 관련된 핵심은 2~3문장뿐이고, 나머지는 노이즈다.
이 노이즈가 LLM에 전달되면 두 가지 문제가 생긴다:
Liu et al. (2023)의 연구 "Lost in the Middle"은 중요한 발견을 보고했다. LLM은 긴 컨텍스트에서 처음과 끝에 있는 정보는 잘 활용하지만, 중간에 있는 정보는 놓치는 경향이 있다.
10개의 문서를 넣었을 때, 정답이 1번이나 10번 문서에 있으면 잘 답하지만, 5번이나 6번에 있으면 성능이 급격히 떨어진다. 마치 긴 책의 중간 부분을 대충 읽는 사람처럼.
컨텍스트 압축(context compression)은 검색된 문서에서 질문과 관련된 핵심 부분만 추출하는 기법이다.
def compress_context(question, documents, llm):
compressed = []
for doc in documents:
extraction = llm.generate(f"""
다음 문서에서 질문과 관련된 핵심 정보만 추출하세요.
관련 없는 내용은 제거하세요.
질문: {question}
문서: {doc.text}
핵심 정보:
""")
if extraction.strip():
compressed.append(extraction)
return compressed
500토큰의 청크에서 핵심 2~3문장(50~100토큰)만 추출하면, LLM에 전달하는 컨텍스트가 깔끔해지고 비용도 절감된다.
LLM 호출 없이도 비슷한 효과를 내는 방법이 있다. Small-to-Big(또는 Parent-Child) 검색이다.
아이디어는 이렇다:
원본 문서: [===========전체 섹션===========]
큰 청크: [====Parent A====][====Parent B====]
작은 청크: [C1][C2][C3][C4] [C5][C6][C7][C8]
검색: C3이 매칭됨
→ LLM에는 Parent A를 전달 (C3의 맥락 포함)
작은 청크로 정밀하게 검색하되, 전달할 때는 충분한 맥락을 포함한 큰 청크를 사용하는 것이다. 추가적인 LLM 호출 없이 검색 정밀도와 맥락 보존을 동시에 달성할 수 있다.
지금까지 다룬 7가지 기법을 하나의 파이프라인으로 조합하면 이렇게 된다:
실전 의사 코드로 보면:
def advanced_rag_pipeline(question: str) -> str:
# Pre-Retrieval
transformed_queries = query_transform(question)
metadata_filter = extract_filters(question)
# Retrieval (하이브리드 + 멀티 쿼리)
all_results = []
for query in transformed_queries:
keyword_hits = bm25_search(
query, filter=metadata_filter
)
vector_hits = vector_search(
query, filter=metadata_filter
)
fused = reciprocal_rank_fusion(
keyword_hits, vector_hits
)
all_results.extend(fused)
# Post-Retrieval
deduplicated = deduplicate(all_results)
reranked = cross_encoder_rerank(
question, deduplicated, top_k=5
)
compressed = compress_context(question, reranked)
# Generation
context = "\n\n".join(compressed)
answer = llm.generate(
f"컨텍스트:\n{context}\n\n질문: {question}"
)
return answer
물론 모든 기법을 한꺼번에 적용할 필요는 없다. 자신의 시스템에서 가장 큰 병목이 무엇인지 파악하고, 해당 단계의 기법부터 적용하는 것이 현실적이다.
모든 기법을 한꺼번에 도입하는 것은 비현실적이다. 실전에서 검증된 우선순위를 제안한다:
| 우선순위 | 기법 | 이유 | 난이도 |
|---|---|---|---|
| 1 | 청킹 전략 최적화 | 모든 것의 기초. 청킹이 잘못되면 다른 개선이 무의미 | 낮음 |
| 2 | 하이브리드 검색 | 구현이 간단하면서 효과가 큼. 대부분의 벡터 DB가 지원 | 낮음 |
| 3 | 메타데이터 필터링 | 데이터에 메타데이터만 추가하면 됨 | 낮음 |
| 4 | 리랭킹 | Cohere Rerank 같은 API로 즉시 적용 가능 | 중간 |
| 5 | 쿼리 변환 | LLM 호출이 추가되어 지연 시간 증가 | 중간 |
| 6 | 멀티 쿼리 검색 | 복잡한 질문에 효과적이지만 비용 증가 | 중간 |
| 7 | 컨텍스트 압축 | 효과는 크지만 추가 LLM 호출의 비용/지연 고려 필요 | 높음 |
핵심 원칙: 측정 없이 최적화하지 말 것. 각 기법을 적용하기 전후로 반드시 평가 데이터셋을 만들고, 검색 정확도(Recall@k, MRR)와 답변 품질을 측정해야 한다.
기본 RAG의 원리는 단순하다. "검색해서 넣어주면 된다." 하지만 이 글에서 본 것처럼, 실전에서 좋은 RAG를 만드는 것은 세밀한 엔지니어링의 연속이다.
이 각각의 선택이 최종 답변 품질을 결정한다. 그리고 정답은 하나가 아니다 — 데이터의 특성, 질문의 유형, 응답 시간 요구사항에 따라 최적의 조합이 달라진다.
RAG 연구는 여전히 빠르게 진화하고 있다. GraphRAG, Agentic RAG, Self-RAG 같은 새로운 패러다임이 계속 등장하고 있다. 하지만 이 글에서 다룬 Advanced RAG 기법들은 어떤 새로운 패러다임에서도 기본 도구로 계속 쓰이는 핵심 기법이다. 기본기를 단단히 다져두면, 새로운 기법을 도입할 때도 "왜 이것이 필요한지"를 명확히 판단할 수 있다.
참고 논문 및 자료