
블로그로 돌아가기
객체 검출논문 리뷰D-FINEDETRFDRGO-LSD분포 정제
D-FINE 완전 이해: 바운딩 박스를 '확률 분포'로 다듬다 — 실시간 검출의 새로운 경지
고정된 좌표 대신 확률 분포를 반복 정제하고, 깊은 층의 지혜를 얕은 층에 전수하는 자기 증류까지 — D-FINE이 YOLO와 RT-DETR를 모두 넘어서며 실시간 객체 검출의 새로운 기준을 세운 이야기.
코어닷투데이2025-12-1844분
고정된 좌표 대신 확률 분포를 반복 정제하고, 깊은 층의 지혜를 얕은 층에 전수하는 자기 증류까지 — D-FINE이 YOLO와 RT-DETR를 모두 넘어서며 실시간 객체 검출의 새로운 기준을 세운 이야기.
한 장의 사진에 고양이가 있다.
당신에게 "이 고양이의 바운딩 박스를 그려주세요"라고 부탁하면, 당신은 고양이를 둘러싸는 네모 박스를 그릴 것이다. 하지만 가만히 생각해보자 — 그 박스의 오른쪽 가장자리는 정확히 어디인가? 고양이의 꼬리 끝? 수염 끝? 그림자의 끝? 고양이가 털이 복슬복슬하다면, 몸의 경계가 어디인지조차 모호하다.
이것이 바운딩 박스 회귀(bounding box regression)의 본질적인 어려움이다.
2015년부터 2024년까지, YOLO부터 RT-DETR까지, 거의 모든 객체 검출기는 바운딩 박스를 네 개의 고정된 숫자로 예측했다. "왼쪽 가장자리는 x=123.4, 위쪽은 y=45.6, 너비는 w=78.9, 높이는 h=101.2." 마치 모든 경계가 칼로 자른 듯 정확하다는 전제 위에서.
하지만 현실의 객체 경계는 그렇지 않다. 가려진 객체, 흐릿한 사진, 복잡한 배경 — 경계는 종종 불확실(uncertain)하다. 고정 좌표 예측은 이 불확실성을 표현할 방법이 없다. 그리고 고정 좌표는 한 번에 맞추거나 틀리거나 둘 중 하나다. 점진적으로 개선할 여지가 없다.
2024년 10월, 중국과학기술대학교(USTC)의 연구팀이 이 근본적인 문제에 도전했다.
"D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement" — 회귀를 재정의한다. 고정 좌표 대신 확률 분포를 예측하고, 이 분포를 디코더 레이어를 거치며 점진적으로 다듬는다. 그리고 깊은 층이 학습한 정교한 분포를 얕은 층에 자기 증류(self-distillation)로 전수하여, 전체 네트워크의 위치 정확도를 끌어올린다.
결과는? D-FINE-X: COCO에서 55.8% AP, 초당 78프레임. Objects365로 사전 학습하면 59.3% AP — 2024년 기준 모든 실시간 검출기 중 최고 성능. YOLO11, RT-DETR, RT-DETRv2를 모두 능가했다.
전통적인 바운딩 박스 회귀는 디랙 델타 분포(Dirac delta distribution)를 가정한다. 각 가장자리의 위치를 하나의 정확한 숫자로 예측한다는 것이다. 수학적으로, "오른쪽 가장자리의 위치는 정확히 x=153.7이다"라는 예측은 x=153.7에서만 확률 1이고 나머지는 0인 분포에 해당한다.
이 접근의 문제를 구체적으로 살펴보자.
문제 1: 불확실성을 모델링할 수 없다.
가려진 객체의 경계, 모션 블러로 번진 가장자리, 비슷한 색의 배경과 맞닿은 경계 — 이 모든 경우에서 "정확한 위치"는 본질적으로 모호하다. 하지만 디랙 델타는 "여기가 100% 확실하다"고만 말할 수 있다. 모호함을 표현할 방법이 없다.
문제 2: 최적화가 불안정하다.
L1 손실이나 IoU 손실은 예측된 좌표와 실제 좌표의 차이를 줄이는 방향으로 학습한다. 하지만 이 손실들은 각 가장자리를 독립적으로 조정하는 데 충분한 가이드를 제공하지 못한다. 예측이 실제에 매우 가까울 때, 작은 좌표 변화에 대한 기울기가 급변하여 최적화가 불안정해진다.
문제 3: 점진적 개선이 불가능하다.
DETR의 디코더는 여러 층을 거치며 예측을 정제한다. 하지만 고정 좌표를 정제하는 것은 "숫자 하나를 조금씩 고치는" 것에 불과하다. 표현력이 제한적이어서, 디코더 층이 깊어져도 개선 폭이 빠르게 줄어든다.
이 문제를 처음 인식한 것은 GFocal(Generalized Focal Loss, 2020)이다. GFocal은 각 가장자리의 위치를 하나의 숫자가 아닌 이산화된 확률 분포로 예측했다. N개의 구간(bin)에 대해 "이 가장자리가 여기에 있을 확률"을 예측하는 것이다.
하지만 GFocal에는 세 가지 한계가 있었다.
D-FINE은 이 세 가지 한계를 모두 해결한다.
D-FINE의 첫 번째 핵심 구성요소인 FDR(Fine-grained Distribution Refinement)은 바운딩 박스 회귀를 완전히 재정의한다.
기존: "오른쪽 가장자리 = 153.7" (하나의 숫자) D-FINE: "오른쪽 가장자리가 각 위치에 있을 확률 분포" → 이 분포를 매 디코더 레이어에서 정제
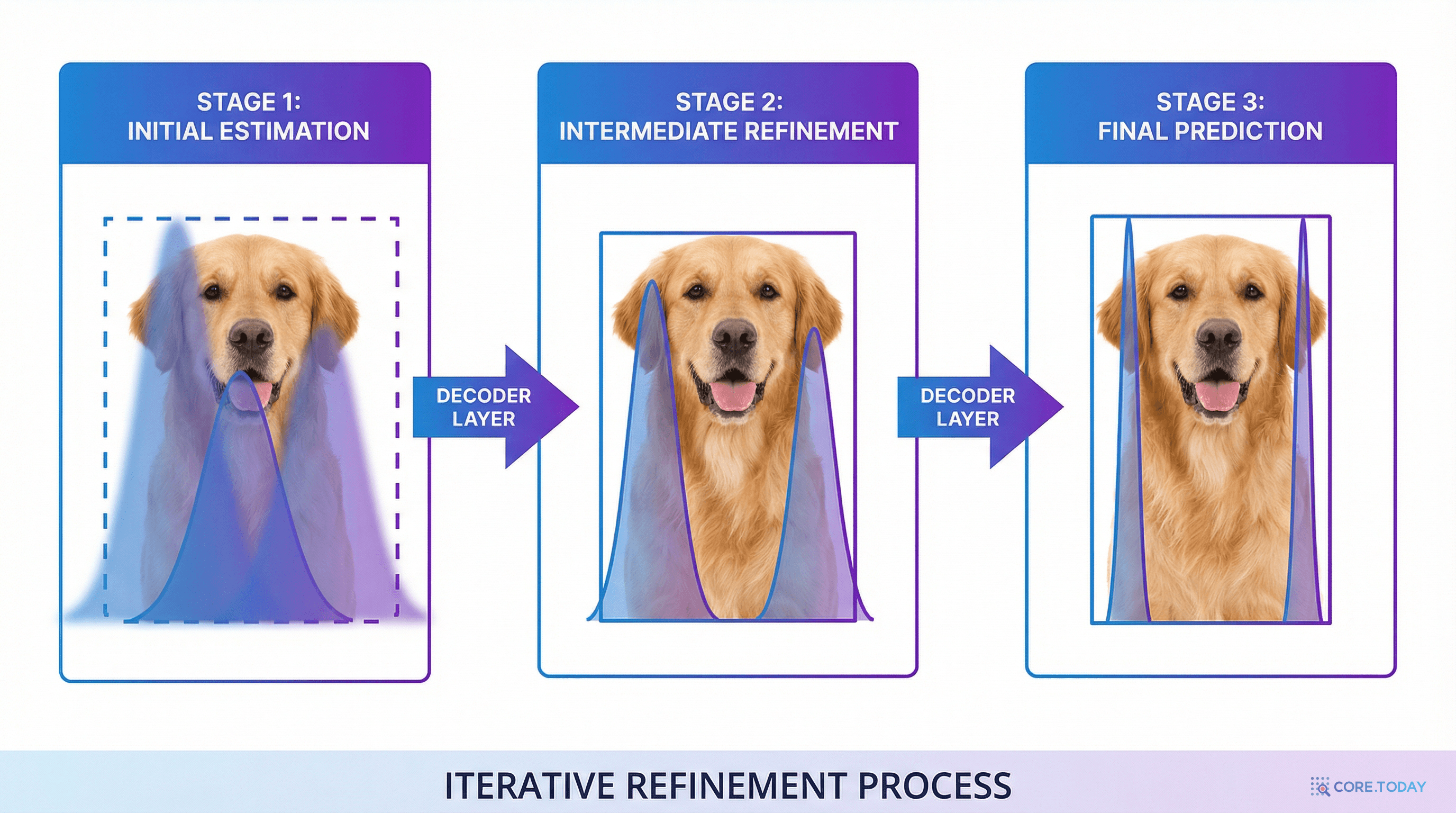
Step 1: 초기 예측. 첫 번째 디코더 레이어가 두 가지를 출력한다.
초기 바운딩 박스를 중심점 와 가장자리 거리 (위, 아래, 왼쪽, 오른쪽)로 변환한다.
Step 2: 분포 정제. 이후 각 디코더 레이어 에서, 바운딩 박스의 네 가장자리가 다음과 같이 정제된다.
핵심은 확률 분포가 잔차(residual) 방식으로 정제된다는 것이다.
현재 레이어는 이전 레이어의 로짓(logits)에 수정값(logits)만 예측하여 더한다. 처음부터 다시 예측하는 것이 아니라, 이전 결과를 기반으로 조금씩 개선하는 것이다. 마치 사진을 편집할 때, 매번 처음부터 그리는 대신 이전 결과 위에 보정하는 것과 같다.
FDR의 핵심 설계 중 하나가 비균일 가중 함수 W(n)이다. 일반적인 접근은 모든 bin에 동일한 가중치를 부여하는 것이지만, D-FINE은 위치에 따라 다른 가중치를 부여한다.
직관적으로, 이것은 카메라의 수동 초점 링과 같다. 초점이 거의 맞았을 때는 미세하게 돌리고, 초점이 크게 빗나갔을 때는 빠르게 크게 돌린다. D-FINE의 W(n)은 바로 이 동적 조절을 수학적으로 구현한 것이다.
아래 탐색기에서 FDR의 분포 정제 과정과 W(n)의 형태를 직접 체험해보자.
D-FINE은 분포 예측을 위한 전용 손실 함수인 FGL(Fine-Grained Localization) Loss도 도입한다. GFocal의 DFL(Distribution Focal Loss)에서 영감을 받았지만, 두 가지 핵심 개선이 있다.
이를 통해 분포가 더 집중되고(concentrated), 불확실성이 낮은 정밀한 예측이 가능해진다.
D-FINE의 두 번째 핵심 구성요소인 GO-LSD(Global Optimal Localization Self-Distillation)는 지식 증류(knowledge distillation)의 새로운 패러다임이다.
전통적인 지식 증류는 큰 교사 모델과 작은 학생 모델이 필요하다. 교사를 먼저 학습시키고, 그 지식을 학생에게 전수한다. 하지만 이는 추가 학습 비용이 크고, DETR의 일대일 매칭과 호환이 어렵다.
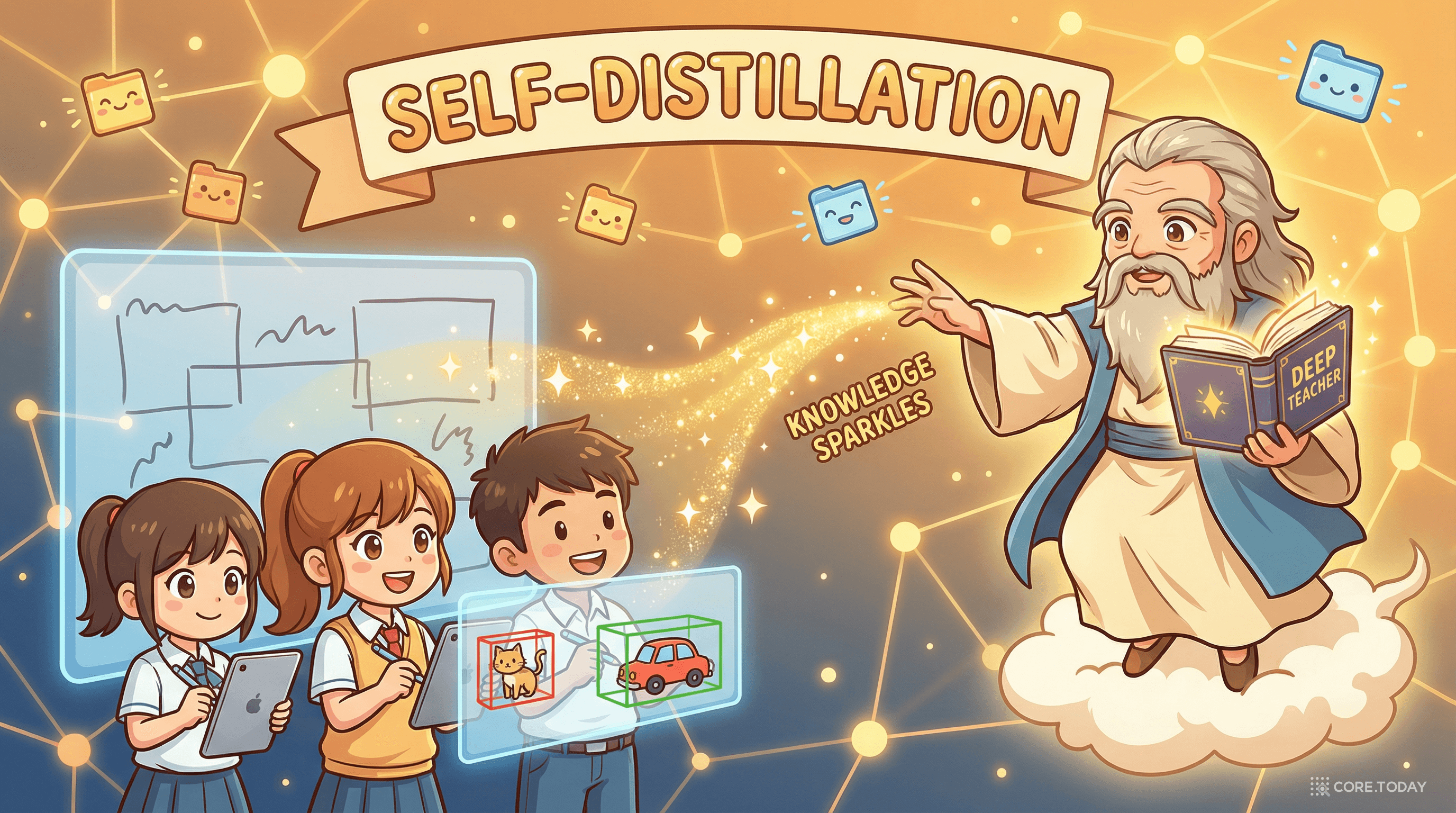
GO-LSD는 별도의 교사 모델 없이, 같은 네트워크의 마지막 디코더 레이어(가장 정교한 분포)를 교사로 사용한다. 이것이 "자기 증류(self-distillation)"의 의미다.
GO-LSD의 핵심 아이디어는 글로벌 유니온 셋(global union set)이다.
DETR은 헝가리안 매칭으로 각 디코더 레이어에서 예측과 실제 객체를 매칭한다. 하지만 각 레이어의 매칭 결과가 다를 수 있다. 레이어 2에서 특정 쿼리가 객체 A와 매칭되었지만, 레이어 5에서는 다른 쿼리가 매칭될 수 있다.
GO-LSD는 모든 레이어의 매칭 인덱스를 합집합(union)으로 모아, 가장 정확한 후보들의 전체 집합을 만든다. 이 유니온 셋에 대해 증류를 수행하면, 모든 레이어가 혜택을 받는다.
유니온 셋에는 매칭된 예측(높은 IoU)과 매칭되지 않은 예측(낮은 신뢰도이지만 정확한 위치)이 공존한다. GO-LSD는 이 둘을 다른 가중치 전략으로 처리하는 DDF(Decoupled Distillation Focal) Loss를 사용한다.
매칭된 예측에는 IoU가 높을수록 큰 가중치를 부여하고, 비매칭 예측에는 분류 신뢰도가 높을수록 큰 가중치를 부여한다. 또한 매칭/비매칭의 수량 비율에 따라 자동으로 균형을 잡는다.
GO-LSD가 만드는 선순환(virtuous cycle)을 이해하는 것이 중요하다.
D-FINE은 RT-DETR-HGNetv2를 기준으로 시작하여, 단계적으로 아키텍처를 개선한다. 논문의 Table 3이 이 여정을 상세히 보여준다.
| 수정 단계 | AP (%) | 파라미터 | 지연 시간 (ms) | GFLOPs |
|---|---|---|---|---|
| 기준: RT-DETR-HGNetv2-L | 53.0 | 32M | 9.25 | 110 |
| 디코더 프로젝션 레이어 제거 | 52.4 | 32M | 8.02 | 97 |
| + 타겟 게이팅 레이어 | 52.8 | 33M | 8.15 | 98 |
| 인코더 CSP → GELAN | 53.5 | 46M | 10.69 | 167 |
| GELAN 히든 차원 축소 | 52.8 | 31M | 8.01 | 91 |
| 비균등 샘플링 포인트 | 52.9 | 31M | 7.90 | 91 |
| RT-DETRv2 학습 전략 | 53.0 | 31M | 7.90 | 91 |
| + FDR | 53.5 | 31M | 8.07 | 91 |
| + GO-LSD (= D-FINE) | 54.0 | 31M (-3%) | 8.07 (-13%) | 91 (-17%) |
최종 D-FINE-L은 기준 대비 AP +1.0%, 파라미터 -3%, 지연 -13%, GFLOPs -17%. 더 정확하면서 더 빠르고 더 작다. 이것이 FDR과 GO-LSD의 위력이다 — 아키텍처를 경량화해서 잃은 성능을, 분포 정제와 자기 증류가 메우고도 넘친다.
D-FINE의 아키텍처 기여 중 하나가 타겟 게이팅 레이어(Target Gating Layer)다. 디코더의 크로스 어텐션 뒤에 배치되며, 기존의 잔차 연결(residual connection)을 대체한다.
기존 잔차 연결의 문제는 레이어 간 정보 얽힘(information entanglement)이다. 이전 레이어의 쿼리가 현재 레이어에 그대로 전달되면, 쿼리가 서로 다른 타겟에 집중하기 어려워진다.
타겟 게이팅은 시그모이드 게이트를 통해 이전 쿼리와 현재 크로스 어텐션 결과를 동적으로 혼합한다. 쿼리가 레이어마다 다른 타겟에 유연하게 집중할 수 있게 해준다.
D-FINE의 실험 결과는 2024년 객체 검출 분야에서 가장 강력한 숫자들이다.
| 엔드투엔드 검출기 | 파라미터 | GFLOPs | 지연 시간 | AP (%) |
|---|---|---|---|---|
| YOLOv10-L | 24M | 120 | 7.66ms | 53.2 |
| YOLOv10-X | 30M | 160 | 10.74ms | 54.4 |
| RT-DETR-R50 | 42M | 136 | 9.12ms | 53.1 |
| RT-DETR-R101 | 76M | 259 | 13.61ms | 54.3 |
| RT-DETRv2-L | 42M | 136 | 9.15ms | 53.4 |
| RT-DETRv2-X | 76M | 259 | 13.66ms | 54.3 |
| RT-DETRv3-X | 76M | 259 | 13.61ms | 54.6 |
| D-FINE-L | 31M | 91 | 8.07ms | 54.0 |
| D-FINE-X | 62M | 202 | 12.89ms | 55.8 |
D-FINE-L vs YOLOv10-L: AP 54.0% vs 53.2% (+0.8%), 파라미터 31M vs 24M, GFLOPs 91 vs 120 (24% 적음), 지연 8.07ms vs 7.66ms. 약간의 지연 증가로 상당한 정확도 향상.
D-FINE-L vs RT-DETR-R50: AP 54.0% vs 53.1% (+0.9%), 파라미터 31M vs 42M (26% 적음), GFLOPs 91 vs 136 (33% 적음), 지연 8.07ms vs 9.12ms (12% 빠름). 모든 지표에서 우세.
D-FINE-X vs 모든 경쟁자: 55.8% AP는 YOLO11-X(54.7%), RT-DETR-HG-X(54.8%), RT-DETRv3-X(54.6%)를 모두 1% 이상 넘어선다.
| 모델 | AP (%) | 파라미터 | 지연 시간 (ms) | GFLOPs |
|---|---|---|---|---|
| D-FINE-N | 42.8 | 4M | 2.12 | 7 |
| D-FINE-S | 48.5 | 10M | 3.49 | 25 |
| D-FINE-M | 52.3 | 19M | 5.62 | 57 |
| D-FINE-L | 54.0 | 31M | 8.07 | 91 |
| D-FINE-X | 55.8 | 62M | 12.89 | 202 |
특히 D-FINE-N은 4M 파라미터, 7 GFLOPs, 2.12ms에 42.8% AP를 달성한다. 초경량 엣지 디바이스를 위한 모델로서, 매우 제한된 자원에서도 의미 있는 성능을 제공한다.
대규모 데이터셋 Objects365로 사전 학습 후 COCO로 파인튜닝하면 성능이 대폭 향상된다.
| 모델 | COCO AP (%) | Objects365+COCO AP (%) | 향상 |
|---|---|---|---|
| D-FINE-S | 48.5 | 50.7 | +2.2 |
| D-FINE-M | 52.3 | 55.1 | +2.8 |
| D-FINE-L | 54.0 | 57.3 | +3.3 |
| D-FINE-X | 55.8 | 59.3 | +3.5 |
D-FINE-X는 59.3% AP — 2024년 기준 모든 실시간 검출기 중 최고 성능이다. YOLOv10-X(54.9%)를 4.4%, RT-DETR-R101(56.2%)을 3.1% 앞선다.
특히 주목할 것은 D-FINE의 사전 학습 효율이다. YOLOv10은 Objects365에서 300 에폭을 학습하지만, D-FINE은 21 에폭만으로 동등 이상의 성능을 달성한다. DETR 계열이 대규모 사전 학습에서 YOLO보다 훨씬 효율적이라는 것을 확인한 결과다.
FDR과 GO-LSD는 D-FINE만을 위한 것이 아니다. 기존의 다양한 DETR 모델에 거의 그대로 적용할 수 있으며, 모두에서 성능이 향상된다.
| 모델 | 원래 AP (%) | + FDR & GO-LSD | 향상 |
|---|---|---|---|
| Deformable-DETR | 43.7 | 47.1 | +3.4 |
| DAB-DETR | 44.2 | 49.5 | +5.3 |
| DN-DETR | 46.0 | 49.7 | +3.7 |
| DINO (12ep) | 49.0 | 51.6 | +2.6 |
| DINO (24ep) | 50.4 | 52.4 | +2.0 |
DAB-DETR에서 +5.3% AP. 추가 파라미터와 학습 비용 없이. 이것이 "범용적이고 효율적인 방법론"의 가치다.
기존 증류 방법들과의 비교는 GO-LSD의 설계가 왜 뛰어난지를 명확히 보여준다.
| 증류 방법 | AP (%) | 학습 시간/에폭 | GPU 메모리 |
|---|---|---|---|
| 기준 (증류 없음) | 53.0 | 29분 | 8552M |
| Logit Mimicking | 52.6 (-0.4) | 31분 | 8554M |
| Feature Imitation | 52.9 (-0.1) | 31분 | 8554M |
| 기준 + FDR | 53.8 | 30분 | 8730M |
| Localization Distill. | 53.7 | 31분 | 8734M |
| GO-LSD | 54.5 | 31분 | 8734M |
놀라운 점:
전통적 증류(Logit Mimicking, Feature Imitation)는 오히려 성능을 떨어뜨린다. DETR의 일대일 매칭 특성 때문에, 분류 로짓이나 특징을 그대로 복사하는 방식이 불안정하다.
GO-LSD는 기준 대비 +1.5% AP를 달성하면서, 학습 시간은 단 6% 증가, 메모리는 2% 증가에 불과하다. 사실상 "공짜"에 가까운 성능 향상이다.
| a, c 조합 | AP (%) | 비고 |
|---|---|---|
| a=1/4, c=1/4 | 52.7 | a가 너무 작음 |
| a=1/2, c=1/4 | 53.3 | 최적 |
| a=1/2, c=1/ε | 53.0 | c가 너무 큼 → 선형에 가까움 |
| a=1/2, c=1/8 | 53.2 | |
| 학습 가능 ã, c̃ | 53.1 | 고정값이 더 안정적 |
| N (bins) | AP (%) |
|---|---|
| 4 | 53.3 |
| 8 | 53.4 |
| 16 | 53.5 |
| 32 | 53.7 |
| 64 | 53.6 |
| 128 | 53.6 |
N=32가 최적. 그 이상은 유의미한 향상이 없다 — 분포의 세밀함에는 한계가 있다.
| T | AP (%) |
|---|---|
| 1 | 53.2 |
| 2.5 | 53.7 |
| 5 | 54.0 |
| 7.5 | 53.8 |
| 10 | 53.7 |
| 20 | 53.5 |
T=5가 최적. 분포를 충분히 부드럽게 하여 효과적인 지식 전달을 하면서도, 너무 부드러워서 정보가 손실되지 않는 균형점이다.
D-FINE의 기여는 단순히 "더 높은 AP"를 넘어선다. 이 논문이 제시하는 방향성 자체가 중요하다.
1. 회귀의 재정의. "좌표를 예측한다"에서 "분포를 정제한다"로의 전환은 객체 검출뿐 아니라, 포즈 추정, 키포인트 검출, 3D 객체 검출 등 모든 회귀 기반 비전 태스크에 적용 가능한 아이디어다.
2. 자기 증류의 효율성. 별도의 교사 모델 없이, 같은 네트워크 안에서 깊은 층이 얕은 층을 가르치는 GO-LSD 패턴은, 학습 비용 증가 없이 성능을 높이는 범용적 기법이 될 수 있다.
3. DETR 계열의 범용 플러그인. FDR과 GO-LSD가 Deformable-DETR, DAB-DETR, DN-DETR, DINO 모두에서 +2~5% AP를 달성한 것은, 이 방법론이 특정 아키텍처에 종속되지 않는 범용적 개선임을 증명한다.
의료 영상: 종양이나 병변의 경계는 본질적으로 모호하다. D-FINE의 확률 분포 기반 접근은 "경계가 여기에 있을 가능성"을 명시적으로 모델링하여, 의사에게 불확실성 정보를 함께 제공할 수 있다.
자율주행: 보행자의 가장자리를 1~2픽셀 더 정확하게 검출하는 것은, 시속 60km에서 수십 센티미터의 판단 차이를 만든다. D-FINE의 위치 정밀도 향상은 안전과 직결된다.
산업 검사: 반도체 웨이퍼의 미세 결함이나 PCB의 작은 불량을 검출할 때, 정확한 위치 정보가 필수적이다. D-FINE-N의 초경량 모델은 엣지 디바이스에서도 높은 위치 정밀도를 제공한다.
D-FINE이 던지는 핵심 메시지는 이것이다.
"바운딩 박스의 가장자리 위치는 하나의 숫자가 아니라, 확률 분포다. 그리고 이 분포는 한 번에 완성되는 것이 아니라, 반복적으로 다듬어져야 한다."
이 통찰은 우아하면서도 실용적이다.
우리가 그림을 그릴 때를 생각해보자. 화가는 처음에 거친 스케치를 그리고, 점점 세밀한 선을 더하며, 마지막에 세부를 다듬는다. 처음부터 완벽한 선을 긋는 화가는 없다. 정밀함은 반복에서 나온다.
D-FINE은 이 원리를 객체 검출에 적용했다. 첫 레이어의 거친 분포에서 시작하여, 매 레이어마다 조금씩 다듬어, 마지막 레이어에서 날카로운 예측에 도달한다. 그리고 그 과정에서 축적된 지혜를, 다시 처음으로 전달하여 다음 반복을 더 쉽게 만든다.
55.8% AP, 59.3% AP. 이 숫자들은 인상적이지만, D-FINE의 진정한 가치는 숫자 너머에 있다. "어떻게 예측하는가"를 근본적으로 바꾸는 것 — 고정에서 분포로, 한 번에서 반복으로, 독학에서 자기 증류로. 이 방향의 전환이 앞으로의 객체 검출, 더 나아가 컴퓨터 비전 전체의 발전을 이끌어갈 것이다.



